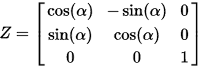tmallfe / tmallfe.github.io Goto Github PK
View Code? Open in Web Editor NEW天猫前端
Home Page: http://tmallfe.github.io
天猫前端
Home Page: http://tmallfe.github.io











































































































































































































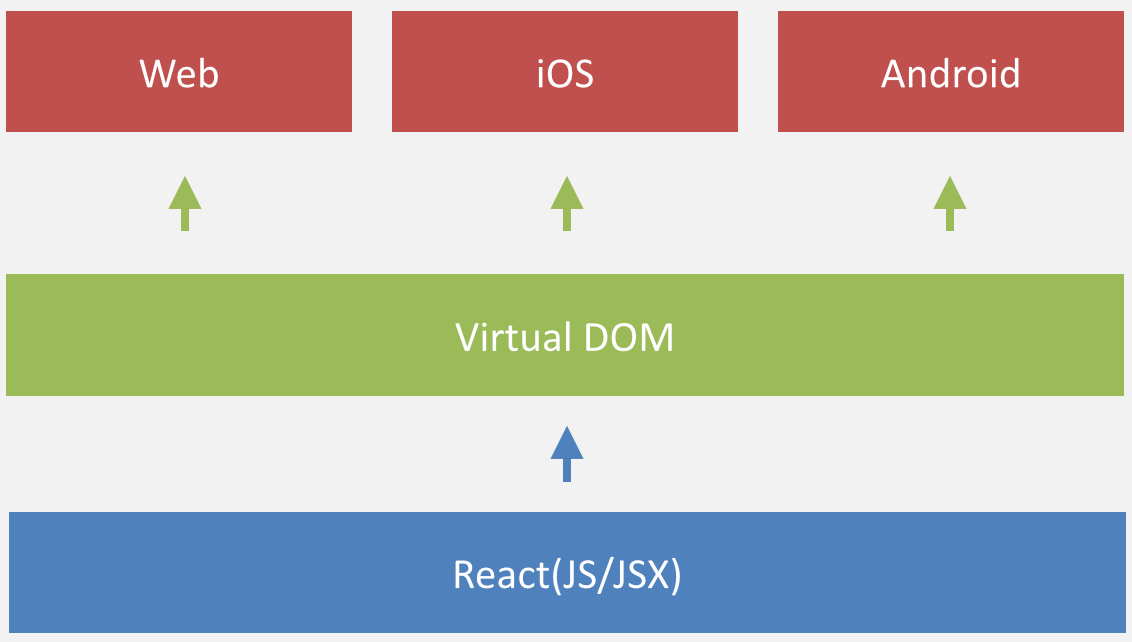
希望能透过 react-native 的动态性,将 react native 的优势带入客户端,如手淘、手猫,让使用客户端浏览体验更佳,并且保持动态性,快速协助响应业务。
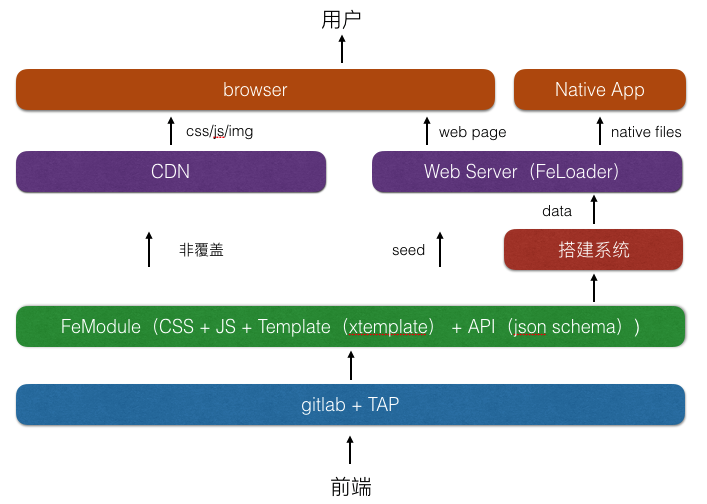
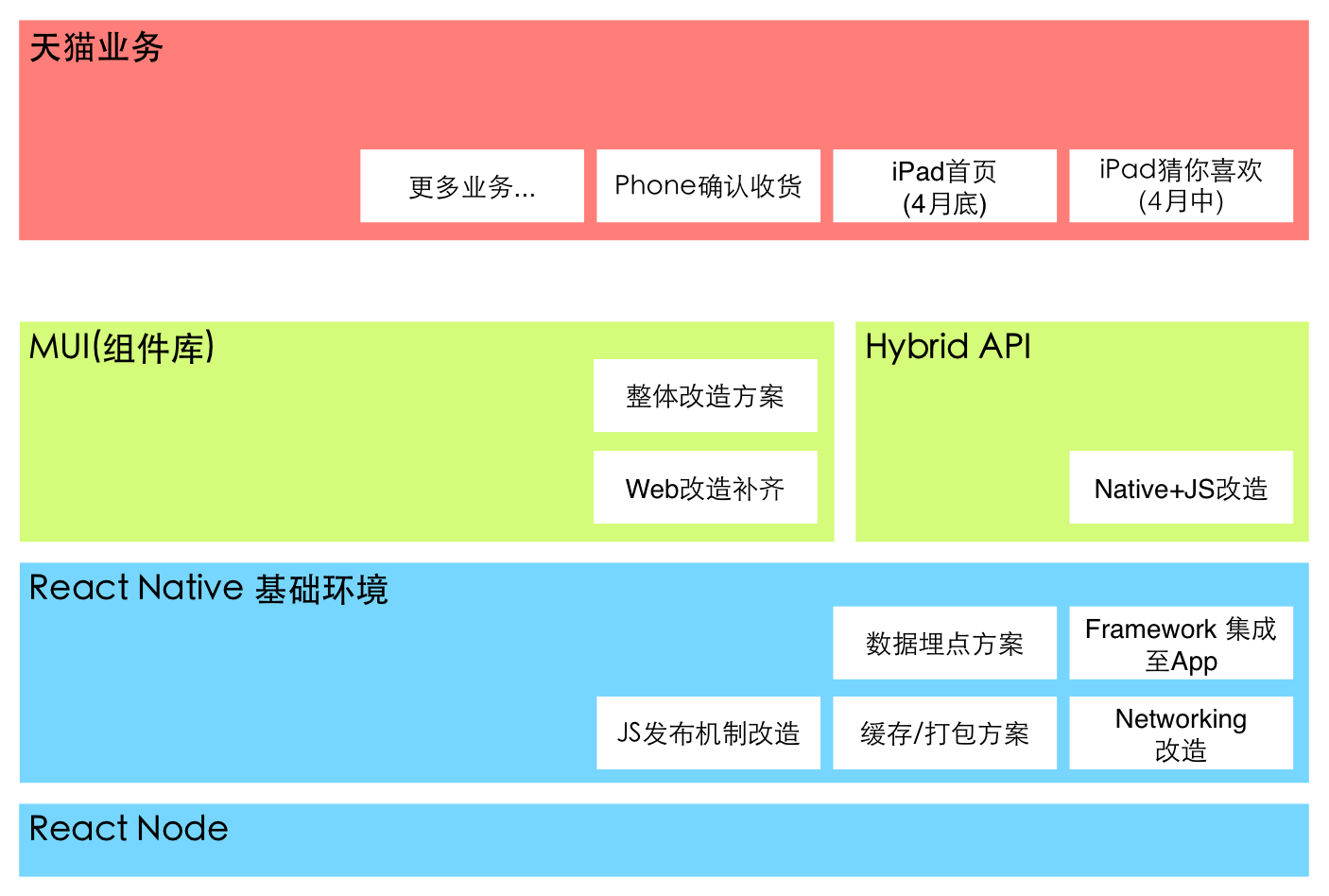
斑马(页面搭建平台) 是一套让非技术人员也能自行搭建页面的 CMS 系统,基于Node实现,由天猫自主开发,此系统支持 PC/Mobile 页面,React Native 整入后,让页面搭建上同步产出 PC/Mobile/Native 版本。
React Native 原设定为应用级别,让整个应用都使用 React Native,但对于手淘、手猫这类应用已经有大量业务跑在线上,无法进行一次性的迁移,在 @一渡、@隐风 等人的努力下,将原先以应用为单位细化以页面为单位,让使用上更佳灵活,让部分页面使用,不需要侵入整个系统。
模块经由服务端 wormhole 透过 xtemplate 模版语言,将页面上使用到的模块、打底数据、 页面基本设置模块合并后让终端载入,客户端 React Native 容器载入后即可渲染页面。一般页面在使用 8~12 个模块含打抵数据文件大小 gzip 后约 80kb,透过 CDN 加载在 3G/4G/WIFI 下都可达到1秒内渲染完成。
React Native 在开发完成到上线这段期间必须要经过打包过程,在与 @正霖 一同努力后将打包工具做了几层细化。
模块开发者专注在高质量模块开发,数据投放交由数据后端系统,运营根据需求选择模块、填入数据,量化产出页面,让各种频道、营销活动快速搭建。同时产出 PC/Mobile web/Native 页面,让不同平台都能拥有最佳使用体验。
目前天猫这边在React的应用中处理了包括容器初始化的监控,接入了与客户端Native一致的业务埋点系统和错误监控系统,可查看每一条 JS 错误完整的 stack 以及 RN 容器错误的详细信息,并且相同的错误会被归类在一起,方便统计错误占比。其中 JS 错误分为严重、不严重两种,其中严重错误可能会影响 UI 崩坏或页面渲染异常,通过报警加上错误信息可以更快速的排错
目前基础组件设计都是以 web 模式靠拢,如 web 的 A 标签,RN 上也有完全相同的组件,在参数、行为上也是完全间容。
目前天猫自己开发了包括:
双11期间ReactNative上线共 30 天,从数据上看来,多数状况下首屏性能是优于 web,尤其在 web 端 缓存未命中状况下。另外在 UI 操作体验上,React Native 基本都能达到 60 fps 的流畅体验。
就双11后也还有很多优化点持续进行:
就双11的这次 React Native ,让我们看到了 React Native 不再只是能够针对应用、页面级别的开发,也可以如 CMS 方式量化的产生内容。当然我们也不满足于当前的状态,还是有相当多的优化点可以进行,让更多业务切入、保持开源、活络的社群,以及最重要的是要能够为业务产生更大价值。
如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
原文发布于infoQ中文版
2014年,整个IT领域发生了许多深刻而又复杂的变化,InfoQ策划了“解读2014”年终技术盘点系列文章,希望能够给读者清晰地梳理出技术领域在这一年的发展变化,回顾过去,继续前行。
本篇是解读系列的前端篇,小编邀请到天猫前端团队的三七、铁军、不四、鬼道这四位专家来解读2014年前端领域最引人注目的几大热点。
2014年10月28日,W3C宣布HTML5正式定稿为标准,这不仅仅标志着历经8年的标准纷争告一段落,也代表着HTML5这个名词会逐步洗去铅华,其技术真正融入到Web开发的每个角落,就像当年Ajax一样,当大家不再大张旗鼓鼓吹概念和商业炒作时,正是其成熟时代到来了。HTML5规范和以前最大区别是让Web最基础架构从Web Page升级到Web Application,正符合主流互联网从桌面端迁移到移动端的趋势,是移动互联网终端碎片化的一剂良方。在移动智能终端性能和网络速度到达消费者需求时,将会是Mobile Web大展跨平台神威时,这从网络基础设施领先的韩国应用从纯Native到大量采用Hybrid形式就可以看出一些端倪。
HTML5在尚未定稿前已有了大量实践,以至于其定稿之日也是成熟之时,同样下一代的JavaScript标准ECMAScript 6虽尚未定稿,但浏览器端Chrome和Firefox等新版本已实现 ES 6 的部分语法(Promise、Generators等),同样在服务器端,Node v0.11 最新版本也已支持部分核心 ES 6 语法。这些 ES 6 新特性,大大地提升了开发者的效率。在 Node.js 中,已经有了非常优秀的基于 ES 6 特性的新框架,并已开始广泛地运用在生产环境中。随着 Regenerator、6to5等转换工具的出现,在前端使用 ES 6 的新特性也完全不是问题,这将大大提高整个JavaScript开发群体的效率,让大规模应用Nodejs的时代更快到来。
HTML和ECMAScript是前端开发的基石,其快速升级和革新意味着这个领域面临的挑战和旺盛的生命力。
2014年8月29日,Yahoo宣布停止开发YUI,如Julien在该博文所说,这几年前端行业越来越活跃,新技术和工具层出不穷,对于大而厚的基础库越来越不适应业务的发展需求。与此同时,单页应用技术符合Web应用化的趋势,一方面随着业务越来越复杂,前端API能力越来越强,数据和展现结合也越来越紧密,另一方面,Mobile的发展对Web人机交互体验有更高要求,效果上要交互体验极致到Native的程度,性能上要前端库的高效且粒度及灵活性精细化,这也是类似reactjs等新型mv*库开始流行的一个原因。
类似问题在jQuery身上也挑战很大,过去小而快的优点在移动时代已没有优势,需要面对移动端新的极致人机交互体验挑战。阿里开源框架KISSY正在使其核心模块粒度更加细小灵活,对低级浏览器的兼容拆分,在Mobile等高级浏览器下加载更少的代码,这是应对这一趋势所必须做的改变。前端框架和类库是为了提升前端开发的效率和品质,当人机交互环境发生重大变革时,这些基础设施都必须敢于大胆提早顺势而变,否则只能被淘汰。
2014年通过指令化/声明式调用前端组件的形式发展迅速:比如Angularjs、Reactjs及新晋的vuejs等各种热议和实践,其中一个特点是Directive的引入。Web Components 规范将组件定义使用标准化,这种标准化正式跨平台跨终端业务急需的,为前端开发方案带来巨大机会。2014年Google IO 上《Polymer and the Web Components revolution》介绍,2014年北京QCON 豆瓣的《DOMO UI》 、百度的《跨终端组件实战》,都是基于Web Component的实践落地(DOMO UI类似Web Component)。究其背后原因:一方面前端开发越来越富交互化,组件共享复用也越来越频繁,如何高效一致地使用是每个组件库需要解决的问题,而Web Commponents的到来让我们看到了机会;另一方面,Mobile的高速发展,让前端开发不仅仅只面对桌面一个终端,更要面对Phone、Pad乃至TV终端,Web和不同的Native开始混用,如何让Native代码也能像Web组件一样方便调用,就需要引入类似HTML之类得声明描述组件,而Web Components 正式符合这一特性的原生标准,为组件的跨终端带来无限想象。面对消费者终端的碎片化,Web Components会成为跨端UI模块化协作的基础。
目前天猫正在构建跨终端高品质UI体系MUI,从设计到客户端和Web前端一起打造一套UI设计规范和模块化组件体系覆盖所有端的天猫业务,从iPhone到Android Phone,从iPad到Android Pad,从Mobile Web到Desktop Web,还有TV等,实现任何标准的UI设计都能够快速覆盖全站,其背后技术**之一就是Web Components。
1989年3月12日,Tim Berners-Lee创立了WWW(Word Wide Web),Web的迅猛发展成为Internet上最重要的内容承载方式,以至于很多人会认为Web就是Internet。亿万互联网用户催生无数的Web开发者和巨无霸网站,Web的规模化促使了前后端的分工,于是2001年雅虎有了全世界第一个前端工程师职位,此时前端专注于HTML、CSS和JavaScript,后端专注于业务和数据,而数据(Data)和展现(View)结合部分由于成本较低和技术难度不高而分工模糊,大部分情况下这部分工作依旧是后端工程师在负责。2007年iPhone诞生,互联网全面向移动快速进化,各种系统和硬件配置的Phone和Pad兴起使得用户访问互联网的终端碎片化,导致互联网产品都需要一套数据(Data)多个展现(View),所以Data和View结合的技术难度和成本剧增使得这部分工作必须从后端向前端转移,前端负责客户端和服务端所有的View及View相关的Control,后端负责业务逻辑和数据并以API服务的方式向前输出,这样前后端彻底分离,对于产品开发而言前端只需要控制View和标准化的Data服务,不存在后端了。
前后端分离技术的难点是在服务端的前端,这个领域一直被后端开发语言和**所**,对于本来就很稀缺的前端工程师在技能和工作量上提出太高的要求,导致进展不顺利,直到Node.js横空出世。Node.js出现,不仅让前端工程师终于有能力自己为自己打造提高工作效率的工具,让前端工程师发挥程序上的想象力,也让前后端分离有了更好的选择,所以整个业界非常多公司在这方面尝试,有些甚至尝试使用Node.js完全取代后端语言,比如Java。目前还处于风起云涌的初期,所以即使在同一个公司如阿里巴巴内部都很多类似尝试,比如淘宝的Midway、支付宝的iChair和天猫的Wormhole等,主因是难点并不在于Node.js技术本身,而在于和原有业务服务体系对接和运维能力上,所以切入点很多且难以标准化,先多点尝试相互竞争,后续在基于实际方案的基础上进行合并统一是我们目前的思路。天猫的首页已经构建在Node.js上,不仅经受了2014双11的考验且性能表现优异,目前正在把这个方案应用到天猫所有活动和频道页面,到2015双11会有相当多的流量运行在Node.js上,那将是激动人心的时刻。
Node.js开始大规模使用和其逐渐成熟完善且社区非常有活力关系密切,但从七月初开始,Node.js 核心开发者与 Node 社区核心参与者认为 Joyent 管理下的 Node 开发进展太慢,且对于社区的需求响应不及时,开始与 Joyent 公司进行谈判,希望将 Node 源码从 Joyent 公司拿出来,放到 Linux 基金会下基于社区来进行维护。最终事件以 Node.js 核心开发者 fork 了 Node 源码,重命名为 io.js 结束。2015年1月13日,io.js发布 1.0 版本,同时,node 也将发布 0.12 版本。 这事件对 Node 社区影响非常之大。首先,造成Node 源码的开发工作停滞了三个月左右,其次,io.js 开发活跃程度已经大于 Node.js,且io.js 和 Node.js 的开发理念不同必然导致之后两者会渐行渐远,但从长远角度来看,竞争虽然带来阵痛但有利于更好的产品出现。
2014 年初,Node.js 当时项目掌门人从 Joyent 离职,基于 npm 创立了 npm, Inc,开始致力于 Node.js 的包管理平台开发和维护。之前 npm 属于社区维护性质,服务不够稳定,随着 Node 社区的发展壮大,npm 服务的稳定性越来越重要,因此 npm, Inc 的成立保障了维系 Node 社区最重要的基础服务设施的稳定性。 2014 年底, npm, Inc 发布新官网,同时重新定义 npm, Inc 为 JavaScript 的包管理工具和平台。此时 npm 已经拥有了接近 12 万个模块,超越了 maven 成为了最大的包管理中心。 随着模块数量的急剧增加,企业使用 npm 的需求也越来越高,npm, Inc 开始将目标瞄准了企业版 npm 市场,现在处于邀请公司试用期。而早在2014年中,阿里巴巴内部的私有 npm 服务已经非常完善,现在已经有每月超过 300 万次的下载,服务于全公司的 JavaScript 程序员。所以,社区驱动了创新和快速发展,企业会推动服务稳定和健壮,两者相互协作和竞争会让整个生态更有旺盛的生命力。
2007年1月9日,iPhone诞生,带来了整个人机交互领域的颠覆式创新,对于前端技术也有了颠覆式改变,初期甚至到了讨论Web is dead的地步,加速Web世界的危机感和积极向移动端转型,同时随着Phone和Pad的严重碎片化和整个互联网都从桌面转向了移动,直接导致移动应用内容的规模化和多元化及连接和整合整个世界,越来越发现仅仅靠Native本身是不够的,需要Web和Native结合起来才能够满足极致人机交互和规模化联通世界的要求,比如微信其实就是这方面的表率。前端的工作就是为人机交互的UI提供工程化方案,当整个互联网向移动转移时,原来的Web体系和工程方案已不适用了,这就是为什么YUI会倒下,而HTML和JavaScript要快速地推出革新版本,同样Web Components必须满足移动终端碎片化的模块化方案才能高速发展,而Node.js的流行恰好迎合上前后端分离前端工程师需要掌控服务端前端的趋势。这一些也仅仅是刚刚开始,TV和Watch等越来越多碎片化的终端进入到日常生活,前端的挑战也刚刚开始且前所未有,这是最好的时代。Web是桌面时代人机交互技术方案的王者,但在移动智能终端时代目前无法及时满足新兴的人机交互能力。这非常类似Ajax到来时,HTML + CSS已经无法很好地满足人机交互UI开发的需要,前端要快速掌握JavaScript一样,移动互联网时代,Web前端工程师需要快速掌握Native开发能力成为跨终端的前端开发工程师,这不是抛弃Web转向Native,而是把Web和Native结合起来,就像当年HTML + CSS + JavaScript结合起来产生巨大的威力一样。这不是1+1 = 2,而是1+1>2的问题,不是简单的技术领域扩充,而是真正的人机交互技术深入探索,前端技术方案从来都不是由稳定的单一技术所能解决的。现在Native开发规模越来越大已开始在探索类似Web的View发布机制和模块化依赖关系管理等等,而Web也正在探索弱网络或不确定网络性能、内存管理及硬件调用的技术方案,两者结合(Hybrid)对于我们的大规模平台化业务来说是事半功倍的正确方向。
ArchSummit2014深圳大会,手淘 Android 负责人无锋分享的手淘 android 架构《手机淘宝的客户端架构探索之路》中提到“像 Web 一样轻盈的 Native App!”。可见从Native同学的角度已开始考虑向Web融合,而在天猫我们定义:前端 = Web + Native,目前天猫已有10%的Web前端同学拥有Native开发的能力,预计不到2015年中会扩大到50%。虽然目前已有大量的Hybrid应用和使用类PhoneGAP的混合开发,但Native和Web的深入融合远远不够,尤其是发布能力和大规模协作的能力上,以及对于组件、性能等方面的相互协作。之前一直讨论Native和Web孰优孰劣,谁取代谁,但经过2014相信更多人已意识到这是个伪命题,真正评判一项技术的价值是在业务场景中,选择合适且面向未来的技术最重要,需要思考如何用技术为用户和业务带来价值,天猫也正在前进的路上,随着越来越多人同时掌握Web和Native,两者的协作会更加深入和相互发展,并作为整个前端的范畴带来更多的技术突破、效率提升和极致体验,而原来的Web前端工程师也会进行技能升级,勇敢地打破自我的壁垒拥抱移动端,尤其是Native技术,前端 = Web + Native。真正成为跨终端的前端工程师。
对于天猫前端而言,在新的一年里,Mobile会变革为主场,主要有三个很明确的方向:跨终端组件、大规模Node、Native 和 Web 融合。
跨终端组件MUI: MUI是天猫统一的跨终端UI组件库,这是设计师、Native开发和Web前端一起协作的全站性质项目。之前已经历了两个版本完成了基础视觉规范和JS组件规范及管理升级机制,新一年的重要方向是:跨终端。目前正在进行的MUI3.0核心是天猫内部称作FEModule的组件体系,就是一个完整的组件规范(包括样式、脚本、模板和数据定义),实现前端、后端一致的组件体系,即一个模块完全独立,加上数据即可渲染,模块既可以前端渲染又可以后端渲染。MUI3.0会基于Web components和Native组件融合规范,实现跨终端的组件体系。
大规模Node:首页在天猫双11中在稳定性及性能上已经被证实表现出色,同时对于前后端分离核心的数据API定义也有了系统化的规范和工具。新一代渲染引擎Wormhole CDN 3.1全网发布,支持 feLoader / feModule / 全局头尾,至此天猫应用、CDN、频道页环境的模版渲染环境基本都已经完善,Node.js在天猫承担更多前端业务的时代已经到来。
Native和Web融合:2014年我们在技术和组织结构上做了很多突破,尤其是组织上把Web和Native前端调整为以业务维度的一个团队,前端 = Native + Web,持续推动团队转型深入到Native。我们要把Native的高性能和系统能力同Web的发布能力和规模协作结合起来,这其中有Native和Web互调的Hybrid API,利用Native的缓存和系统能力把Web的基础打开速度做到Native一样的通用方案等等。
智能移动终端带来人机交互变革不仅仅导致了前端开发这个职位需要自我突破革新、重新审视和定义,更导致UI设计师的设计场景发生翻天覆地的变化,从单一的鼠标键盘大屏幕变成了多终端的触屏声音陀螺仪传感器等,设计需要更透析这些新的人机交互形式和技术才能够面向未来。新的一年里,三七将开始负责天猫的UED团队,把设计和技术结合起来,就像D2前端技术论坛理念那样“好的设计驱动技术创新,好的技术给设计无限想象”,MUI3.0就是设计、客户端开发和Web前端结合的产物,但这只是开始,三七如是说,未来还将继续颠覆、成长、蜕变。
本文作者三七是QCon上海2014“没有后端”专题出品人,不四是该专题讲师。鬼道是QCon北京2015大会移动开发实践专题的讲师。
作为一名前端工程师,恐怕最经常听到的词就是: 改需求。
作为一名产品,恐怕最头疼的就是: 前端排期已经排到两个月后。
想了解首页新架构是怎样仅仅上线15个工作日就为前端节省约3个工作日的开发时间吗?
请听我细细道来~
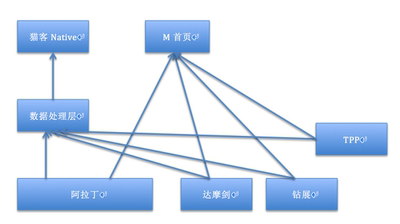
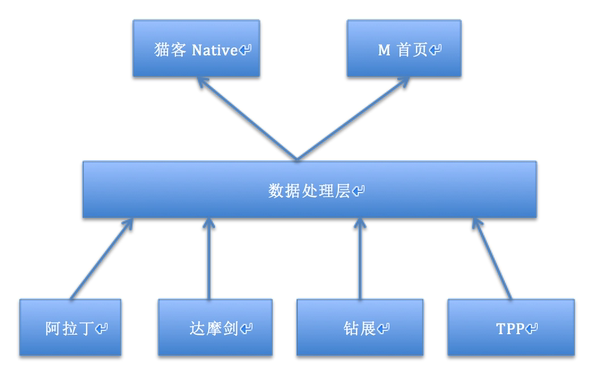
天猫首页是天猫的一项业务,而一项业务的技术架构,与这个业务的特点是息息相关的,所以需要先了解首页的业务,才能更好地理解技术架构的演变。从业务上,首页一直承担着以下两个职能:流量的集散地、拉动用户的留存、门面与标杆。
以上几个特点,对于前端所要面临的挑战就是: 频繁的布局调整、 多系统对接数据来源、 更好的性能与稳定性等几个问题。
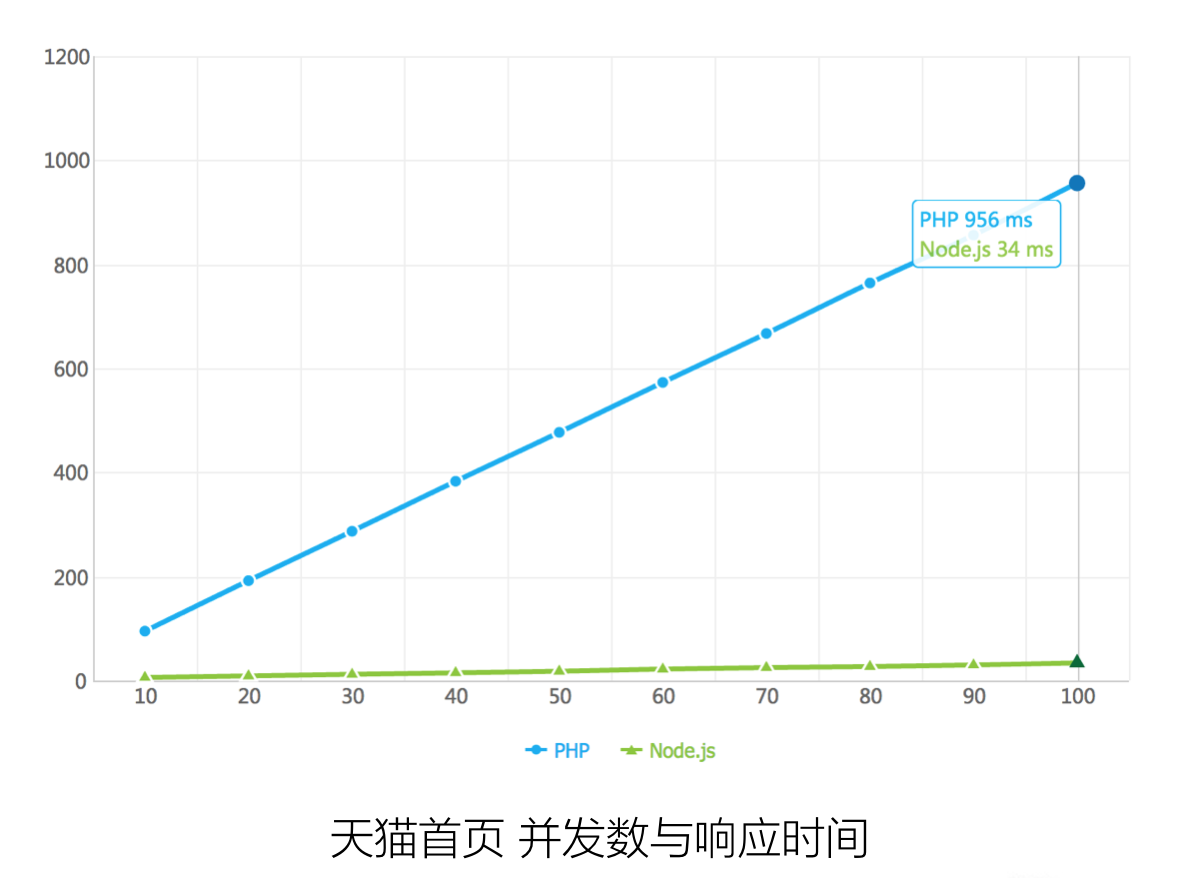
一张图让你感受首页对接多系统的痛苦,还是省略了后续接入其他什么鬼系统的情况下。(不要问我为什么首页没有专门的服务端同学,而是要前端自己对接……)
针对这几个问题,我们则是通过: 动态化布局+ **异步渲染&对接优胜美地(猫客服务端)**来解决。同时本文也对首页升级MUI4.0、埋点、性能、容灾与监控等方面也做了介绍。
解决痛点:你们知不知道双十一期间首页紧急发布多少次啊?
简直要哭了出来。 大部分的需求都是各种模块位置调整、频道增减,虽然Web最大的优势在于发版快捷,可也不能这么搞啊……但俺们工程师的一项主要任务就是 支(皮) 撑(实) 业(耐) 务(操),没办法,只好撸袖子解决这个问题了。
众所周知,改配置的成本和风险要比改代码小得多(前提是配置经过测试)。
所以解决办法就是动态化布局, 指的是抽象一套配置文件,根据配置文件渲染页面。当页面有临时需求变更时,只需更改配置,无需开发。
更进一步,抽离配置后,实现可视化功能更加方便,可以将更改配置的任务交给运营,将解放前端的生产力。
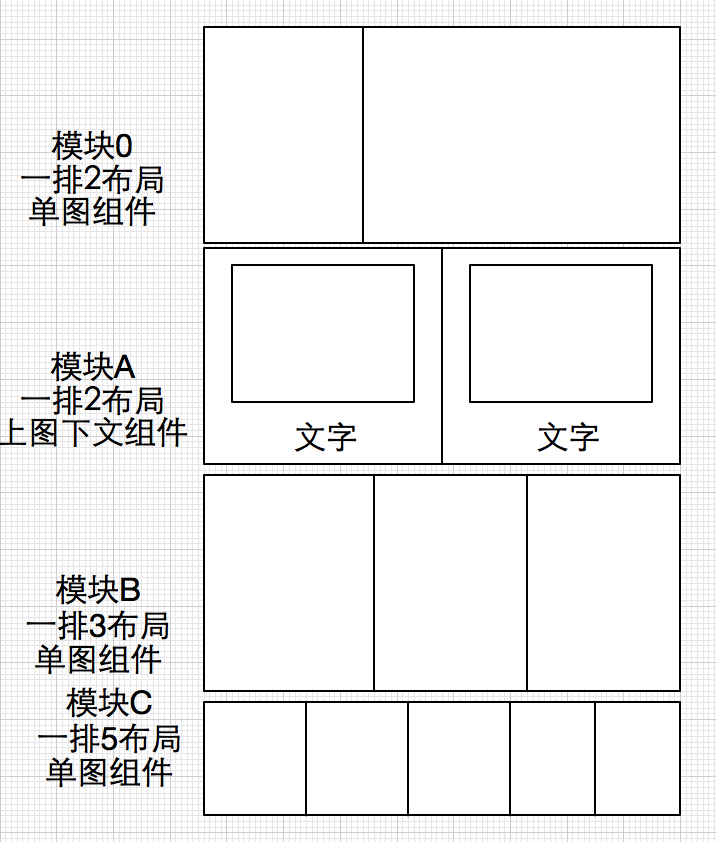
那么问题来了:怎么抽象是一个较为合理的方案呢?当然是以常见的视觉设计稿为依据。
常见的视觉设计稿基本如下:可以抽象为 业务模块、布局、UI组件三个层次(不将组件拆分为更细的层次,控制复杂度)。
从图中可以很清晰地看见, 布局和UI组件是可以自由地组合的,如模块0是由一排二布局和单图组件组成,模块A是由一排二布局和上图下文组件组成。
通过积累布局和UI组件库,当新增一个不是很复杂的模块甚至页面时,可以 快速地更改配置即可上线~(当然它也不是百分百动态配置,假如后续要新增布局类型和组件,那还是要代码实现的,只是绝大部分可以复用)
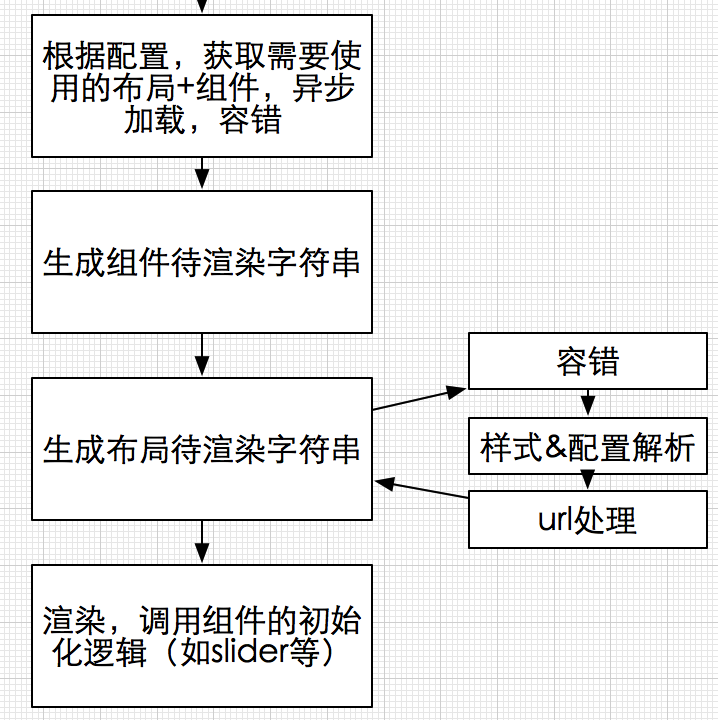
动态化布局的大致**如此,在实现上,每一家都有自己的路数。
后端生成配置系统、运营投放系统暂且略过不表,前端 解析引擎大致流程如下:
1,性能。模板按需加载,模板预编译,优先渲染首屏、图片懒加载支持等等。
2,埋点。包括点击埋点和曝光埋点,具体实现不表。
3,依赖技术选型。例如模板渲染器,因为首页不涉及复杂的逻辑,所以选用的还是较为轻量的xtemplate;还有ES6、模板加载器的选型、工作流的构建等等。
4,文档、脚手架、测试用例等等
一个页面是由数据和模板渲染而成的,同步渲染是指在服务端进行渲染,而异步渲染则是指在浏览器端各自获取数据和模板,再进行拼接渲染的方案。
**前提:**因为手机端的用户习惯较为类似,在视觉设计上,客户端和h5首页也采用了较为一致的方案。部分优点基于此前提。
最后h5首页的架构简化为下图,对于前端而言,对比之前的是不是清晰很多?

时代总在进步,MUI规范(天猫前端组件规范)也来到了4.0版本。
MUI4.0 主要有两个特点:
首页作为一个轻逻辑但具有一定复杂性的页面和技术标杆,自然率先对MUI4.0规范进行了落地尝试。虽然也踩了一些坑,如所有依赖组件并未都立刻升级到MUI4.0,所以也采用了一些兼容方案。结果也使得首页向极致的性能优化更近一步。
数据是业务的指南针,因此丰富的埋点信息格外重要。
埋点通常分为点击埋点和曝光埋点,首页改版后,为了更好地支撑业务,针对每一个模块进行了细粒度的曝光埋点,同时针对slider轮播的每一帧进行了曝光埋点。与内部某系统对接,曝光埋点参数的产生、解析逻辑由服务端控制。
的确做了一些事情,只不过暂时还没有达到最终目标,暂时允许我先卖个关子,后续完成了会再发文分享~
其实还有很多由其他同学协助完成的内容,如迈入ES6的时代、工作环境的构建等等,但那又是另一个话题了总而言之,技术架构是根据业务特性、某一段时期和有限资源下决定的,也会不断地演变,所以本文仅供参考
Hey
我是三七,目前负责天猫前端团队,热烈欢迎你来到美丽杭州实习。
天猫前端团队负责天猫所有的Web前端开发,这意味着只要通过Web访问天猫,那都是我们的作品,请以挑剔的眼光去看待它们,欢迎提出任何问题。这次实习意味着你的代码会运行在天猫上,供亿万人使用,你还能告诉父母、恋人、同学和朋友,TA正在享受你编写的代码来进行购物。如果实习时间足够,你还会经历独一无二的双11,体会近亿人同一时刻涌上天猫带来的挑战和刺激,这会对代码在健壮性、性能和模块化及可维护性等上提出非常苛刻的要求。
随着移动互联网的发展,移动已经成为用户的首要状态,移动开发能力已是前端的必备要求,这是继ajax提出之后对于前端而言最激动人心最大的改变,我们幸运赶上了转变。所以除了HTML、CSS和JavaScript这些传统的前端技能必须扎实之外,Native、动画(虚拟现实)和Nodejs的开发能力也成为前端的必备,所以天猫前端团队非常早就提出并实践推动了跨终端的前端工程师(http://www.infoq.com/cn/news/2013/01/qcon-beijing-web-interview ),这里有一份我4月份在成都大学的分享来介绍关于跨终端的前端工程师我们为什么做,做什么(http://tmallfe.github.io/slide/cross-end-fe.pdf ),分享给你。
至于天猫前端怎样,欢迎去知乎去讨论(http://www.zhihu.com/question/22933704 ),这里我要和你谈谈天猫前端团队的理念和设计**,这些思考和想法至少会悄悄地贯穿你在天猫的整个实习期:
是不是看起来有点晕?不用担心,你是我们精心挑选出来的,邀请来实习表示认可你过去的努力和所取得的成绩,也非常看好你的未来,所以我们会给你配备优秀的天猫前端作为师兄,全方位从技术、项目和生活来协助你,内部称之为“新人成长计划”,有3个目标:
接下来,忘记前面这些文字对你意味着什么,你需要计划好实习时间,等待HR和师兄的联系,下周肯定会联系上你。在和师兄建立联系之前,有任何问题都可以回复这封邮件。
PS,本次实习地点位于阿里巴巴杭州西溪园区,我认为这是**最美丽的办公园区,最近为了做一个健康的前端,我基本每天早上练太极,晚上在园区健身房跑步练力量,这封邮件是今天跑完步之后整理完发出的。分享一下我用手机在园区的随拍,最后一张是今天晚上在健身房拍的:










三七
2014.05.17
Canvas Cache就是使用一个额外的Canvas来保存已经绘制过的内容,下一次使用的时候直接从这个Canvas上读取,这样就可以大大减少Canvas的绘制次数,例如原先首屏绘制次数约为75左右,使用cache后的次数约为28,减少了62.67%,在三四环会更明显,因为没有动画,所有内容都可以cache。
实测设备越低端性能提升越明显,下面是一个页面在不同平台下的消耗时间对比:
| 设备 | 不使用cache | 使用cache | 比值 |
|---|---|---|---|
| PC | 16ms | 14ms | 87.5% |
| Moto X | 75ms | 56ms | 74.67% |
| Moto G | 246ms | 127ms | 51.62% |
| iPhone5 | 170ms | 45ms | 26.47% |
从结果看效果还是很明显的,而且这个只是缓存了6次绘制的结果,实际使用中会缓存个数约为50左右,效果会更明显。
一开始使用一个Canvas直接缓存所有内容,后来发现Canvas大小是有限制的,然后就实现了一个自动切片成多个Canvas Cache的方案,这套cache方案后面会集成到Hilo中。
针对Canvas的最主要优化方案就是尽量减少Canvas API的调用,在对狂欢城做了大量profile后,发现Hilo中每次drawImage都会调用ctx.save();ctx.translate(x, y);ctx.drawImage(...);ctx.restore();,这里Hilo主要是为了保证在所有情况(例如缩放,旋转等)下均不出错,所以才这样处理,但是再狂欢城中并不需要做旋转等复杂的变换,所以将这里的绘制直接改为使用ctx.drawImage来实现。这样可以节省大量运行时间,因为在狂欢城基本上全是图片!
实测性能提升非常明显,下面是消耗时间对比:
| 设备 | 优化前 | 优化后 | 比值 |
|---|---|---|---|
| PC | 30ms | 15ms | 50% |
| Moto X | 138ms | 76ms | 55.07% |
| Moto G | 435ms | 216ms | 49.66% |
| iPhone5 | 225ms | 152ms | 67.56% |
在低端设备上使用1倍图片,减少内存占用,并且不显示动画。
background-image: cdn-url('island-brand-bg-pc.png');这样最后会变成background-image: url('//gw.alicdn.com/tfscom/TB1urfGKXXXXXXBaXXX_pYDSXXX-937-595.png');,这样写less的时候就不需要关心图片地址问题,图片上传问题,图片压缩等问题。如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
在刚刚过去的 15 年天猫双十一中,Node.js(后文简称 node) 大放异彩,不仅帮助前端团队快速、高效的解决双十一各个业务上的页面渲染问题,同时在性能和稳定性上也表现非常出色,大大降低了双十一硬件成本的同时,在整个双十一期间未出现任何一起由 node 引发的线上故障。
经过一年时间的改造和推进,到 15 年双十一的时候,已经有大量的业务都有了 node 的身影,基本上天猫大部分的 web 页面都是通过 node 渲染出来:
在上述覆盖了 node 的业务中,node 在其中扮演了多种角色:
天猫页面搭建平台即是一个由 node 负责整个 web 端包括业务逻辑和模板渲染等工作的应用。基于支付宝的 node web 框架 chair,通过 hsf 调用和淘宝共建的页面数据存储的接口,用 node 完成业务逻辑处理、页面渲染和前端接口。
通过 node 整合前端的天猫组件规范 MUI,开发了一套专注于模板渲染的 node 容器(wormhole),通过这个 node 容器,前端可以专注于展现层的开发,统一前端的本地和线上的代码运行环境,也让后端摆脱了繁琐的套模板工作,专注于提供数据接口。同时这套容器基于天猫的模块化规范,横向打通了各个业务和应用之间的模块共享。
基于这个模板容器,我们完成了商品详情、店铺、搜索页以及超市等业务线上的前后端分离工作,大大提升了前端的开发效率,并有效降低了前后端沟通成本。
同样基于天猫前端的组件规范 MUI 和模板渲染的 node 容器,我们完成了一套模块化搭建页面的系统,同时开发并运维了一个用来渲染基于模块搭建的页面的服务,同时这个服务和阿里的 cache CDN 打通,在保证满足业务需求的前提下,降低消耗的计算资源。
基于这个服务,在双十一中提供了 900+ 活动页面的渲染,以及天猫首页和各个频道页的渲染工作,天猫的所有营销引流页面基本都由这个服务提供页面。
上面讲了许多我们用 node 做了什么,以及覆盖了那些业务,现在我们来看看,到底我们是怎样用 node 解决实际的业务需求的。
拿这次双十一的会场页举例:
在上述流程中,我们看到同一个 url 对应到后端其实是完全不同的页面输出内容,为了达到这个目的,我们和 CDN 团队一起做了许多工作:
user-agent 以及约定的一些 cookie 信息,判断用户的终端类型。并部署到 CDN 上,让 CDN 拥有了终端判断的能力。detector: pc 表明这个请求的终端设备是 PC 上的浏览器。vary 为 detector,保证 CDN 根据不同的设备类型缓存不同页面。上面提到会根据终端类型对于同一个 url 返回不同的页面,而这些页面其实都是通过一个基于 node 开发的天猫页面搭建平台用模块搭建的。在这个平台上,超过 95% 的模块都拥有 pc 和无线两个版本,本次双十一所有用到的模块都有 react native 的版本。运营只需搭建 PC 上的页面,就会自动生成无线以及 react native 的页面。基于这套方案,我们通过 70+ 高质量的模块,让运营同学完成了超过 900+ 活动页面的搭建。
再深入一点,我们如何来完成这些页面或者是模块的呢?首先,我们希望让前端开发做什么?
我们在 xtemplate 模板引擎的基础上进行扩展,让前端通过编写 xtemplate 模板,在 context 中注入一些必需的页面上下文,扩展 xtemplate 的语法,支持引入前端资源。基于这套模板,我们可以在拿到数据后渲染得到完整的页面,基本满足了开发页面在功能上的所有需求。
但是页面中其实有非常多重复性的内容,我们完全可以把他们抽象成一个个的模块,让页面通过模块化的方式来基于模块搭建,在这个过程中我们需要解决几个问题。
seed 来进行依赖版本的管理,每一个模块在发布的时候都会打包好自身的依赖关系,而在将所有的模块组合成页面的时候,将所有模块的依赖表重新进行合并和去重,最终保证页面引用的模块和静态资源唯一。同时我们在模板中通过扩展引入了 FELoader(天猫的静态资源加载器),收集页面的所有静态资源,combo 后插入到页头(css)或者页尾(js)。解决完上述问题之后,我们将每一个页面都变成了以下几个部分:
最终,我们的渲染服务会根据 URL 和请求的终端环境,找到对应的页面描述文件,请求相应的数据,合并所有的模板渲染成为 HTML 页面。
当我们完成了 web 页面的模块化搭建之后回头再看,是不是 react native(RN) 的页面也能够搭建呢?我们只需要所有的模块都有对应的 react native 版本,就可以像搭建 web 的 html 一样搭建渲染出 RN 需要的 js 了!所以本次双十一使用的所有模块都有 RN 版本,并有多个会场采用了 RN 进行搭建,取得了非常不错的效果,在接下来的双十二中,我们所有的会场都会支持 RN,而这一切对于搭建会场的运营来说都是完全透明的。
在阿里,所有的双十一相关应用都需要面临的一个大问题就是稳定性,为了保证能够在几亿用户买买买的时候不掉链子,任何一个应用都需要花很大的精力来保障它的稳定性,node 的应用也一样。
对于 node 应用自身而言,我们首先要保证它有充足的测试,通过 mocha + istanbul ,尽可能让测试覆盖每一个功能点和边缘情况。
需要有完善的监控和报警。在阿里内部,我们已经有了内部的监控系统,对于 node 应用而言,只需要按照要求的格式打印的日志,或者通过自己编写日志采集脚本,就可以轻松的搞定监控和报警。
同时,对于 node 应用,我们可以使用阿里云团队提供的 alinode ,他们可以提供更多 node 的日志和监控,并提供了在线的 profiler 和快照功能,方便排查线上异常和性能优化。
尽管我们可以对自身的代码做各种测试、各种监控,但是在一个复杂的系统中,各种上下游依赖非常复杂,网络情况也很复杂,这个时候为了保证稳定性,我们还有许多的工作要做。
假设一个机房的光缆被挖断了,或者机房所在的城市大规模断电了,然后整个天猫的大部分页面都不能访问了,这明显不能接受,所以我们需要在多个城市的多个机房部署我们的服务。如果存放模板文件或者数据文件的服务挂了怎么办?多个节点,主备读取,同时对所有的文件都加上磁盘文件容灾。对外提供服务的整条链路上的每一个依赖都不能够出现单点问题。
在排除完单点问题之后,我们再来审视我们的服务,是不是所有的依赖在挂掉后就无法正常服务了?是否我们对于每个依赖异常都有容灾的方案,弱化掉整条链路上的依赖。
对于每一个可能出现问题的环节,我们都需要有针对性的预案,如果这个预案需要人工去执行,就需要思考能否做到自动化。在 node 渲染服务中,可能有各个缓解出问题,链路上的所有预案都要能够自动切换:
再回过头来看看在天猫我们使用 node 做的事情,不一定很牛逼,但是确实是在天猫现在的业务场景下,一个相对较优的使用方案,不论是在解决前端开发效率、还是提升服务质量方面,都发挥了很重要的作用。而经过了这次双十一的考验,我们也认为它**已经是一个很成熟的工具**,可以帮助我们更好的完成我们的工作。
node 只是工具,在每一个具体的业务场景下都有最合适的使用方法,而随着业务的发展,node 能做的事情也在变化,我们期望它能在之后能在更多的场景下落地。:)
如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
2015年年底,天猫和淘宝一起推动完成了IE6/7不支持项目,当时不支持的主要原因有:
除此之外,以上这些用户还会因为不支持HSTS(非常容易被劫持)、前向加密(也就是RSA交换的密钥未来可以被破解)、TLS1.2(更安全)、SNI(方便运维,否则需要维护很多ip地址)、session ticket(提高性能,降低服务器消耗), OCSP stapling(获取证书状态,提高性能和安全性)等特性,给我们在安全、性能、运维上带来很大的麻烦。
当时的总结里,我们写了这样一句话:
期待IE8/9也成为历史的那一天
看起来,这一天比我们想象的来的早一点。
2016年双11结束了,回顾2016年,天猫前端彻底从KISSY时代迁移到了符合Web标准的开发模式,也在业务中落地了包括Weex、React及周边的配套,尝试将整体的技术方案和开源社区做更多的结合。这部分可以参考《天猫前端基础技术体系MAP简介》
。
而随着整体技术方案的推进,IE8慢慢也变成了一个问题,从Promise里的.catch()和IE8的关键词冲突,到IE8 defineProperty/getOwnPropertyDescriptor的问题,还有部分版本的uglify打包的时候打出了类似var a = function a(){}这样的代码,导致的IE8下各种变量混乱。这些问题的暴露一部分原因是工具和配套没有跟上,在开发期没有暴露问题出来,另一方面也说明了社区对于IE8的降级及复杂方案的简化态度。
这些积累的问题,可以通过增加各种兼容手段,各种工具在打包的时候做各种检查进行规避。但是反过来思考,这些问题也是一个契机,是否到了不支持IE8的时机了?
接下来,就是明确不支持IE8这个事情要不要执行了。其中,对于技术上的益处,显而易见,但是对于用户的影响也是必须要考虑的。所以,还是需要各种考虑目前的数据和微软官方的策略,这些对于决策来说非常重要,基于数据和事实描述问题也更能说服业务方。
基于2016年11月份对天猫整体浏览器分布的分析和统计,目前IE8的占比情况已经非常类似2015年IE6/7的情况,加上无线端流量远超PC端流量,对于大盘来说,IE8这部分的数据已经非常小。
微软对自己的产品都定义了明确的生命周期,而IE的生命周期则是和所对应的windows操作系统绑定。
从 2016 年 1 月 12 日开始,仅适用于受支持操作系统的最新版本的 Internet Explorer 才能获得技术支持和安全更新,如下表所示:
| Windows 桌面操作系统 | Internet Explorer 版本 |
|---|---|
| Windows Vista SP2 | Internet Explorer 9 |
| Windows 7 SP1 | Internet Explorer 11 |
| Windows 8.1 更新 | Internet Explorer 11 |
| Windows 10* | Internet Explorer 11 |
其他浏览器终止支持意味着不再提供安全更新、非安全更新、免费或付费的协助支持选项或联机技术内容更新。
2016.1.1 之后不再签发SHA-1证书,证书到期后,xp用户(包含xp ie8)访问将安全alert
目前天猫首页已经在页面顶部对IE8的用户进行了即将不支持的提示。
在双12结束之后,将开始部署IE8覆盖全屏的浮层进行用户引导,浮层也将不能关闭。由于天猫页面&系统繁多,确认各个具体业务的影响及进行业务部署将花费较长的一段时间。
目前除了IE8之外,我们在IE9/10上也放了建议用户升级浏览器的提示。接下来也期待一下IE9/10成为历史的那一天。
作为前端,提供用户更好的体验的手段不仅仅是提升页面性能,能够引导用户,推动用户选择更合适的访问终端,也是重要的方式之一。
如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
很多技术同学都是游戏玩家,3D游戏无疑是画面最棒、投入感最真实、最让人投入的。
说起3D,前端工程师们应该都很熟悉,CSS3对3D支持非常好,除部分低端Android机器外,性能和效果都不错。今天来分享下如何基于HTML5陀螺仪,来实现3D虚拟现实效果。
虚拟现实大家肯定都了解。VR视觉增强的电影、游戏,市面上已经有很多了。
我们这里的VR,就是简单的用手机屏幕来当 虚拟摄像机,让你来“观察”四周,感觉仿佛置身于虚拟环境里。我们团队有两个互动应用
星辰大海:http://www.tmall.com/go/chn/common/tgp-startui.php (把活动取消的提示叉掉就行:) )

汽车内景: http://m.laiwang.com/market/laiwang/tmall-vr-car.php?carid=2
这是天猫互动在 “陀螺仪感应” 结合 “虚拟3D技术” 的一次尝试,事实证明在某些特定商品(比如汽车)上效果非常好。
如果你看完Demo很感兴趣,那接下来让我一步一步分解这里面涉及到的所有内容。
计算机3D图形和矩阵密切相关,图形API接口也都直接使用矩阵,下面简单列举下矩阵一些简单概念
Transform2d/3d 封装了最基本的变换操作。每个变换都可以转化为矩阵。我们只说虚拟现实涉及的几个3D变换
rotateX()
rotateY()
rotateZ()
scale3d(sx, sy, sz)
以上都是正交矩阵,简单说就是坐标系原点不变。
详细信息可查看https://developer.mozilla.org/en-US/docs/Web/CSS/transform-function
以汽车内景Demo为例,旋转+透视点距离,使用了rotate+translateZ,手指缩放使用了scale3d。
多个矩阵变换叠加起来,就是是矩阵相乘。一个很重要的概念:矩阵不满足乘法交互率!这就意味着变换顺序的不同,直接导致最终结果千差万别。
通俗的讲就是:每一次变换都是相对上一次变换来做的,参考的坐标系时刻都在变化,无论2D、3D里都一样;
所以:translateZ() rotateX() rotateY() 和 rotateY() rotateX() translateZ() 得出的结果完全相反。
下一步我们要做的就是:如何将手机陀螺仪的数据正确反映出来!
说陀螺仪之前,一定要先说这个概念 欧拉角。 欧拉角广泛应用于 航空航天领域,当然还有我们最熟悉的 手机陀螺仪方位感应器 deviceorientaiton
欧拉角描述3D空间里的方位,陀螺仪监听接口返回 alpha、beta、gamma 就是标准欧拉角方位。(这是手机端,欧拉角官方名称是 heading,pitch、bank)
两个不同的旋转顺序:(heading:45,bank:90) 和(bank:90,pitch:45)在效果是一致的,一个刚体的方位,可以表示成欧拉角多种不同的旋转顺序。也因为欧拉角的不唯一性,会产生“万向锁”的问题。
为了保证唯一性,就有了“限制性欧拉角”这个概念。任何一个方位的描述,是按 alpha, beta, gamma 顺序旋转来得出的方位角度的。可以看成三个旋转正交矩阵,顺序相乘得出变换后的坐标,看下面的动态图,来帮助理解
先绕蓝色Z轴旋转,得出alpha,然后绕绿色轴旋转,得出beta,最后绕红色轴旋转,得出gamma;
最后这张示意图一目了然:
限制性欧拉角有一些特性:
欧拉角可参考这本书:3D数学基础:图形与游戏开发 第十章
前面全是介绍概念,接下来才是正题。相信我,真正的代码远没有你想象中复杂。
现在我们已知了限制性欧拉角三个方位:alpha、beta、gamma,接下来的工作就是转换成矩阵,提供给你所使用的图像API。
我们使用 CSS3 rotate3d,来操作一个已建模的正立方体,关于如何使用DIV+ Perspective3d 来构建一个3D立方体,又是另外一个话题了,但其实也很简单。大家可以看上面汽车Demo的样式。相关内容会在下期“伪3D”专题中说明
alpha、beta、gamma 一一对应 rotateZ()、rotateX()、rotateY(),相对于我们的Z轴向上的世界坐标系而言。
所以欧拉角方位最终的矩阵变换公式是:
使用CSS3就意味着不用关心矩阵,除非你想用 matrix3d()。但矩阵相乘是顺序相关的,所以你必须关注每个变换的顺序。代码超简单就是这样.....
style.webkitTransform = ['rotateZ(Zdeg) ','rotateX(Xdeg) ','rotateY(Ydeg)'].join('');
最终的效果应该是,你所看的立方体相对于环境,位置是不变的。
发现不对?呵呵,没错,因为陀螺仪返回的是手机相对于世界坐标系的方位。
何为虚拟现实,就是你在屏幕中看到的物体,相对于环境是不动的,只是你的摄像机角度变了而已。而图形API所做的变换,都是相对手机屏幕的。下面是一段比较绕的逻辑:
陀螺仪的矩阵变换最终是 ZXY 相乘。这是相对世界坐标系,你的手机屏幕按照这个矩阵变换到现在的方位,但是屏幕中的物体,被施加的矩阵变换是相对屏幕坐标系的,为了让它相对于世界坐标系保持不变。所以最终图形API所需要的矩阵变换,是ZXY相反的方向,也就是它的逆矩阵!
ZXY将顺序颠倒相乘,YXZ 就能得到相应的逆矩阵。所以!我们最终的代码应该是:
Style.webkitTransform = ['rotateY(Ydeg) ', 'rotateX(Xdeg) ', 'rotateZ(Zdeg)'].join('');
大功告成!
Android同学可能发现上面的汽车Demo,只能用滑屏操作,因为大部分Android机器的陀螺仪非常不稳定+不精确,抱歉了!
手指滑动逻辑也很简单,因为只改变了两个轴的旋转,代码如下:
style.webkitTransform = 'rotateZ(0) rotateX(Xdeg) rotateY(Ydeg)';
注意这里的变换顺序也是不能改的,不然直接影响到你的交互。然后给X轴角度做个+-90°的取值范围就能防止颠倒效果。
如果你不使用CSS3,那这些矩阵计算都得自己代码实现。我们完全可以使用webGL来渲染整个立方体,除了图形API不同,webGL所需要的变换矩阵完全一致;
WebGL是不二的选择,而且可以构建更加复杂的球体来渲染全景,这时候素材就需要一张全景图片。不使用框架的话,会有点复杂,我们采用Three.js来构建我们的webGL版本
上代码:
var geometry = new THREE.SphereGeometry(perspective, 100, 100);
geometry.applyMatrix( new THREE.Matrix4().makeScale( -1, 1, 1 );
var material = new THREE.MeshBasicMaterial({
map: texture,
overdraw: 1,
side: THREE.BackSide
});
var mesh = new THREE.Mesh(geometry, material);
euler.set( beta * Degree, alpha * Degree, gamma * Degree,'YXZ' );
camera.quaternion.setFromEuler( euler );
http://g.alicdn.com/tmapp/vr-car/1.1.1/demo/webgl.html
以上就是基于手机陀螺仪的虚拟现实原理。我数学功底不扎实,很多描述不是很详细,如果你还是不太理解,欢迎随时来讨论。
前端工程师作为一个产品中人机交互的第一道门槛,创造性的交互方式、富有画面感的效果,能起对产品起到很积极的作用。个人认为掌握前沿的图形显示技术,对产品体验、技能提升都有很大帮助的。
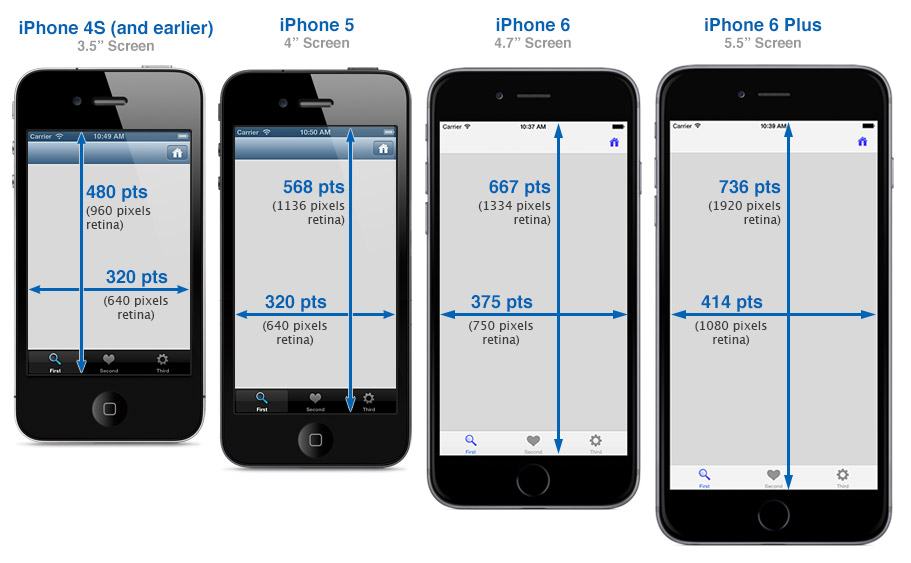
react的宽度不支持百分比,设置宽度时不需要带单位 {width: 10}, 那么10代表的具体宽度是多少呢?
不知道是官网文档不全还是我眼瞎,反正是没找到,那做一个实验自己找吧:
var Dimensions = require('Dimensions');
<Text style={styles.welcome}>
window.width={Dimensions.get('window').width + '\n'}
window.height={Dimensions.get('window').height + '\n'}
pxielRatio={PixelRatio.get()}
</Text> 默认用的是iphone6的模拟器结果是:
window.width=375
window.height=667
pxielRatio=2我们知道iphone系列的尺寸如下图:
可以看到iphone 6的宽度为 375pt,对应了上边的375,由此可见react的单位为pt。 那如何获取实际的像素尺寸呢? 这对图片的高清化很重要,如果我的图片大小为100*100 px. 设置宽度为100 * 100. 那在iphone上的尺寸就是模糊的。 这个时候需要的图像大小应该是 100 * pixelRatio的大小 。
react 提供了PixelRatio 的获取方式https://facebook.github.io/react-native/docs/pixelratio.html
var image = getImage({
width: 200 * PixelRatio.get(),
height: 100 * PixelRatio.get()
});
<Image source={image} style={{width: 200, height: 100}} />我们知道一个div如果不设置宽度,默认的会占用100%的宽度, 为了验证100%这个问题, 做三个实验
<Text style={[styles.text, styles.header]}>
根节点上放一个元素,不设置宽度
</Text>
<View style={{height: 20, backgroundColor: '#333333'}} />
<Text style={[styles.text, styles.header]}>
固定宽度的元素上放一个View,不设置宽度
</Text>
<View style={{width: 100}}>
<View style={{height: 20, backgroundColor: '#333333'}} />
</View>
<Text style={[styles.text, styles.header]}>
flex的元素上放一个View,不设置宽度
</Text>
<View style={{flexDirection: 'row'}}>
<View style={{flex: 1}}>
<View style={{height: 20, backgroundColor: '#333333'}} />
</View>
<View style={{flex: 1}}/>
</View>结果可以看到flex的元素如果不设置宽度, 都会百分之百的占满父容器。
css 里边经常会做的事情是去讲一个文本或者图片水平垂直居中,如果使用过css 的flexbox当然知道使用alignItems 和 justifyContent . 那用react-native也来做一下实验
<Text style={[styles.text, styles.header]}>
水平居中
</Text>
<View style={{height: 100, backgroundColor: '#333333', alignItems: 'center'}}>
<View style={{backgroundColor: '#fefefe', width: 30, height: 30, borderRadius: 15}}/>
</View>
<Text style={[styles.text, styles.header]}>
垂直居中
</Text>
<View style={{height: 100, backgroundColor: '#333333', justifyContent: 'center'}}>
<View style={{backgroundColor: '#fefefe', width: 30, height: 30, borderRadius: 15}}/>
</View>
<Text style={[styles.text, styles.header]}>
水平垂直居中
</Text>
<View style={{height: 100, backgroundColor: '#333333', alignItems: 'center', justifyContent: 'center'}}>
<View style={{backgroundColor: '#fefefe', width: 30, height: 30, borderRadius: 15}}/>
</View>网格布局实验, 网格布局能够满足绝大多数的日常开发需求,所以只要满足网格布局的spec,那么就可以证明react的flex布局能够满足正常开发需求
<View style={styles.flexContainer}>
<View style={styles.cell}>
<Text style={styles.welcome}>
cell1
</Text>
</View>
<View style={styles.cell}>
<Text style={styles.welcome}>
cell2
</Text>
</View>
<View style={styles.cell}>
<Text style={styles.welcome}>
cell3
</Text>
</View>
</View>
styles = {
flexContainer: {
// 容器需要添加direction才能变成让子元素flex
flexDirection: 'row'
},
cell: {
flex: 1,
height: 50,
backgroundColor: '#aaaaaa'
},
welcome: {
fontSize: 20,
textAlign: 'center',
margin: 10
},
} <View style={styles.flexContainer}>
<View style={styles.cellfixed}>
<Text style={styles.welcome}>
fixed
</Text>
</View>
<View style={styles.cell}>
<Text style={styles.welcome}>
flex
</Text>
</View>
<View style={styles.cellfixed}>
<Text style={styles.welcome}>
fixed
</Text>
</View>
</View>
styles = {
flexContainer: {
// 容器需要添加direction才能变成让子元素flex
flexDirection: 'row'
},
cell: {
flex: 1,
height: 50,
backgroundColor: '#aaaaaa'
},
welcome: {
fontSize: 20,
textAlign: 'center',
margin: 10
},
cellfixed: {
height: 50,
width: 80,
backgroundColor: '#fefefe'
}
}通常网格不是一层的,布局容器都是一层套一层的, 所以必须验证在real world下面的网格布局
<Text style={[styles.text, styles.header]}>
嵌套的网格
</Text>
<View style={{flexDirection: 'row', height: 200, backgroundColor:"#fefefe", padding: 20}}>
<View style={{flex: 1, flexDirection:'column', padding: 15, backgroundColor:"#eeeeee"}}>
<View style={{flex: 1, backgroundColor:"#bbaaaa"}}>
</View>
<View style={{flex: 1, backgroundColor:"#aabbaa"}}>
</View>
</View>
<View style={{flex: 1, padding: 15, flexDirection:'row', backgroundColor:"#eeeeee"}}>
<View style={{flex: 1, backgroundColor:"#aaaabb"}}>
<View style={{flex: 1, flexDirection:'row', backgroundColor:"#eeaaaa"}}>
<View style={{flex: 1, backgroundColor:"#eebbaa"}}>
</View>
<View style={{flex: 1, backgroundColor:"#bbccee"}}>
</View>
</View>
<View style={{flex: 1, backgroundColor:"#eebbdd"}}>
</View>
</View>
<View style={{flex: 1, backgroundColor:"#aaccaa"}}>
<ScrollView style={{flex: 1, backgroundColor:"#bbccdd", padding: 5}}>
<View style={{flexDirection: 'row', height: 50, backgroundColor:"#fefefe"}}>
<View style={{flex: 1, flexDirection:'column', backgroundColor:"#eeeeee"}}>
<View style={{flex: 1, backgroundColor:"#bbaaaa"}}>
</View>
<View style={{flex: 1, backgroundColor:"#aabbaa"}}>
</View>
</View>
<View style={{flex: 1, flexDirection:'row', backgroundColor:"#eeeeee"}}>
<View style={{flex: 1, backgroundColor:"#aaaabb"}}>
<View style={{flex: 1, flexDirection:'row', backgroundColor:"#eeaaaa"}}>
<View style={{flex: 1, backgroundColor:"#eebbaa"}}>
</View>
<View style={{flex: 1, backgroundColor:"#bbccee"}}>
</View>
</View>
<View style={{flex: 1, backgroundColor:"#eebbdd"}}>
</View>
</View>
<View style={{flex: 1, backgroundColor:"#aaccaa"}}>
</View>
</View>
</View>
<Text style={[styles.text, styles.header, {color: '#ffffff', fontSize: 12}]}>
{(function(){
var str = '';
var n = 100;
while(n--) {
str += '嵌套的网格' + '\n';
}
return str;
})()}
</Text>
</ScrollView>
</View>
</View>
</View>好在没被我玩儿坏,可以看到上图的嵌套关系也是足够的复杂的,(我还加了一个ScrollView,然后再嵌套整个结构)嵌套多层的布局是没有问题的。
首先我们得知道图片有一个stretchMode. 通过Image.resizeMode访问
var keys = Object.keys(Image.resizeMode).join(' ');打印出来的是 contain, cover, stretch 这几种模式, (官方文档不知道为什么不直接给出)
<Text style={styles.welcome}> 100px height </Text>
<Image style={{height: 100}} source={{uri: 'http://gtms03.alicdn.com/tps/i3/TB1Kcs5GXXXXXbMXVXXutsrNFXX-608-370.png'}} />100px 高度, 可以看到图片适应100高度和全屏宽度,背景居中适应未拉伸但是被截断也就是cover。
<Text style={styles.welcome}> 100px height with resizeMode contain </Text>
<View style={[{flex: 1, backgroundColor: '#fe0000'}]}>
<Image style={{flex: 1, height: 100, resizeMode: Image.resizeMode.contain}} source={{uri: 'http://gtms03.alicdn.com/tps/i3/TB1Kcs5GXXXXXbMXVXXutsrNFXX-608-370.png'}} />
</View>
contain 模式容器完全容纳图片,图片自适应宽高
<Text style={styles.welcome}> 100px height with resizeMode cover </Text>
<View style={[{flex: 1, backgroundColor: '#fe0000'}]}>
<Image style={{flex: 1, height: 100, resizeMode: Image.resizeMode.cover}} source={{uri: 'http://gtms03.alicdn.com/tps/i3/TB1Kcs5GXXXXXbMXVXXutsrNFXX-608-370.png'}} />
</View>cover模式同100px高度模式
<Text style={styles.welcome}> 100px height with resizeMode stretch </Text>
<View style={[{flex: 1, backgroundColor: '#fe0000'}]}>
<Image style={{flex: 1, height: 100, resizeMode: Image.resizeMode.stretch}} source={{uri: 'http://gtms03.alicdn.com/tps/i3/TB1Kcs5GXXXXXbMXVXXutsrNFXX-608-370.png'}} />
</View>stretch模式图片被拉伸适应屏幕
<Text style={styles.welcome}> set height to image container </Text>
<View style={[{flex: 1, backgroundColor: '#fe0000', height: 100}]}>
<Image style={{flex: 1}} source={{uri: 'http://gtms03.alicdn.com/tps/i3/TB1Kcs5GXXXXXbMXVXXutsrNFXX-608-370.png'}} />
</View>随便试验了一下, 发现高度设置到父容器,图片flex的时候也会等同于cover模式
<View style={{flex: 1, height: 100, backgroundColor: '#333333'}}>
<View style={[styles.circle, {position: 'absolute', top: 50, left: 180}]}>
</View>
</View>
styles = {
circle: {
backgroundColor: '#fe0000',
borderRadius: 10,
width: 20,
height: 20
}
}和css的标准不同的是, 元素容器不用设置position:'absolute|relative' .
<View style={{flex: 1, height: 100, backgroundColor: '#333333'}}>
<View style={[styles.circle, {position: 'relative', top: 50, left: 50, marginLeft: 50}]}>
</View>
</View>相对定位的可以看到很容易的配合margin做到了。 (我还担心不能配合margin,所以测试了一下:-:)
我们知道在css中区分inline元素和block元素,既然react-native实现了一个超级小的css subset。那我们就来实验一下padding和margin在inline和非inline元素上的padding和margin的使用情况。
*padding *
<Text style={[styles.text, styles.header]}>
在正常的View上设置padding
</Text>
<View style={{padding: 30, backgroundColor: '#333333'}}>
<Text style={[styles.text, {color: '#fefefe'}]}> Text Element</Text>
</View>
<Text style={[styles.text, styles.header]}>
在文本元素上设置padding
</Text>
<View style={{padding: 0, backgroundColor: '#333333'}}>
<Text style={[styles.text, {backgroundColor: '#fe0000', padding: 30}]}>
text 元素上设置paddinga
</Text>
</View>在View上设置padding很顺利,没有任何问题, 但是如果在inline元素上设置padding, 发现会出现上面的错误, paddingTop和paddingBottom都被挤成marginBottom了。 按理说,不应该对Text做padding处理, 但是确实有这样的问题存在,所以可以将这个问题mark一下。
margin
<Text style={[styles.text, styles.header]}>
在正常的View上设置margin
</Text>
<View style={{backgroundColor: '#333333'}}>
<View style={{backgroundColor: '#fefefe', width: 30, height: 30, margin: 30}}/>
</View>
<Text style={[styles.text, styles.header]}>
在文本元素上设置margin
</Text>
<View style={{backgroundColor: '#333333'}}>
<Text style={[styles.text, {backgroundColor: '#fe0000', margin: 30}]}>
text 元素上设置margin
</Text>
<Text style={[styles.text, {backgroundColor: '#fe0000', margin: 30}]}>
text 元素上设置margin
</Text>
</View>我们知道,对于inline元素,设置margin-left和margin-right有效,top和bottom按理是不会生效的, 但是上图的结果可以看到,实际是生效了的。所以现在给我的感觉是Text元素更应该理解为一个不能设置padding的block。
算了不要猜了, 我们看看官方文档怎么说Text,https://facebook.github.io/react-native/docs/text.html
<Text>
<Text>First part and </Text>
<Text>second part</Text>
</Text>
// Text container: all the text flows as if it was one
// |First part |
// |and second |
// |part |
<View>
<Text>First part and </Text>
<Text>second part</Text>
</View>
// View container: each text is its own block
// |First part |
// |and |
// |second part|也就是如果Text元素在Text里边,可以考虑为inline, 如果单独在View里边,那就是Block。
下面会专门研究一下文本相关的布局
首先我们得考虑对于Text元素我们希望有哪些功能或者想验证哪些功能:
/*==========TEXT================*/
Attributes.style = {
color string
containerBackgroundColor string
fontFamily string
fontSize number
fontStyle enum('normal', 'italic')
fontWeight enum("normal", 'bold', '100', '200', '300', '400', '500', '600', '700', '800', '900')
lineHeight number
textAlign enum("auto", 'left', 'right', 'center')
writingDirection enum("auto", 'ltr', 'rtl')
} <Text style={[styles.text, styles.header]}>
文本元素
</Text>
<View style={{backgroundColor: '#333333', padding: 10}}>
<Text style={styles.baseText} numberOfLines={5}>
<Text style={styles.titleText} onPress={this.onPressTitle}>
文本元素{'\n'}
</Text>
<Text>
{'\n'}In this example, the nested title and body text will inherit the fontFamily from styles.baseText, but the title provides its own additional styles. The title and body will stack on top of each other on account of the literal newlines, numberOfLines is Used to truncate the text with an elipsis after computing the text layout, including line wrapping, such that the total number of lines does not exceed this number.
</Text>
</Text>
</View>
styles = {
baseText: {
fontFamily: 'Cochin',
color: 'white'
},
titleText: {
fontSize: 20,
fontWeight: 'bold',
}
}从结果来看1,2,3得到验证。 但是不知道各位有没有发现问题, 为什么底部空出了这么多空间, 没有设置高度啊。 我去除numberOfLines={5} 这行代码,效果如下:
所以实际上, 那段空间是文本撑开的, 但是文本被numberOfLines={5} 截取了,但是剩余的空间还在。 我猜这应该是个bug。
其实官方文档里边把numberOfLines={5}这句放到的是长文本的Text元素上的,也就是子Text上的。 实际结果是不生效。 这应该又是一个bug。
Text元素的子Text元素的具体实现是怎样的, 感觉这货会有很多bug, 看官文
<Text style={{fontWeight: 'bold'}}>
I am bold
<Text style={{color: 'red'}}>
and red
</Text>
</Text>Behind the scenes, this is going to be converted to a flat
NSAttributedString that contains the following information
"I am bold and red"
0-9: bold
9-17: bold, red好吧, 那对于numberOfLines={5} 放在子Text元素上的那种bug倒是可以解释了。
实际上React-native里边是没有样式继承这种说法的, 但是对于Text元素里边的Text元素,上面的例子可以看出存在继承。 那既然有继承,问题就来了!
到底是继承的最外层的Text的值呢,还是继承父亲Text的值呢?
<Text style={[styles.text, styles.header]}>
文本样式继承
</Text>
<View style={{backgroundColor: '#333333', padding: 10}}>
<Text style={{color: 'white'}}>
<Text style={{color: 'red'}} onPress={this.onPressTitle}>
文本元素{'\n'}
<Text>我是white还是red呢?{'\n'} </Text>
</Text>
<Text>我应该是white的</Text>
</Text>
</View>结果可见是直接继承父亲Text的。
pt为单位, 可以通过Dimensions 来获取宽高,PixelRatio 获取密度,如果想使用百分比,可以通过获取屏幕宽度手动计算。alignItems, 垂直居中用justifyContentImage.resizeMode来适配图片布局,包括contain, cover, stretchnumberOfLines 需要放在最外层的Text元素上,且虽然截取了文字但是还是会占用空间在天猫浏览商品时,假使一个商品有多个选择,且是图片,.tb-prop .tb-img li a这个元素hover上去后有个border: 2px solid #be0106;margin: -1px;的效果,造成布局混乱,给.tb-prop .tb-img li a添加box-sizing:border-box以及去除hover后的'margin:-1px'布局恢复,这是bug吗

这些都是异步加载填充进去的。
请问,这些模块是如何组织的,我大概能想到的是,模块写好之后,都放服务器上,然后调用的时候,combo模块,模块中又自带模板。然后请求模板数据,之后再render成页面。

我现在的页面大概我想的这样写的,不过不是很确定,想问一下具体细节和实现,这个解决方案是怎样的?谢谢大神了~
残酷 KPI 下的极致优化——淘宝天猫首页优化实践 @步天 2013.08.21 @Velocity China 2013
前端基础技术体系是一个非常宽泛的概念,涉及到非常多的点,前端这个行业本身易入门难精通的一部分原因也是每一次的技术深入都需要技术广度上有提升,这些广度以前覆盖了HTTP、其他后端语言、操作系统、印刷设计等,现在由于移动设备的兴起,广度要求的点做了更多的扩充,移动设备多样化、国际化、Native技术等等。列举这些不是想说明前端有多复杂,而是技术体系本身就不是一个独立的存在,需要结合更多其他领域才能有更好的发展,其实其他技术的发展也是类似。
在我2011年刚加入口碑前端团队的时候,三七一直在强调,我们现在的前端团队是国内最棒的。得益于当时YUI成熟的体系,我们在业务中落地了在当时非常“潮”的技术。比如本地的模块构建和发布工具att、CDN的combo服务,YUI的模块版本化管理机制(KISSY模块规范的原型),基于Base/Attribute/Plugin/Widget的模块生命周期管理等等。而使用YUI3开发web应用这篇文章里对web模块开发的思考在现在依然不会过时。
YUI和jQuery的最大区别就是体系和库的区别,对于庞大的淘系业务,只有体系化的技术方案才能保证研发效率和工作流的稳定,保证线上质量和用户体验。YUI体系在传统库的基础上,涵盖了YQL(浏览器端类sql实现)、YETI(浏览器端自动测试)、YUI-Target-Environments等等。
当时前端基础体系强调的核心是兼容性和性能,我们需要大量的复杂庞大的库来保证一套代码能够多浏览器运行,而低效的浏览器执行能力和缓慢的网速也让前端展现部分称为用户访问速度的瓶颈。于是有了:
2012年,天猫启动了MAP项目(Tmall Front-end Architechture & Publish Mechanism)。
当时团队面临了一些大部分前端团队都困扰的难题,这部分阶段称为MAP 1.0。
基于上述MAP1.0时代的问题,MAP2.0做了针对性的调整:
因为智能终端设备的普及,原来的前端目标环境从多浏览器变成了多终端,整个I/O交互的变化对前端体系提出了多端构建的要求。
跨终端的MAP 3.0计划启动,为了保证一致的模块体系和模块快速开发和落地,跨终端组件的技术方案基础还是KISSY 1.4(KISSY 1.3升级1.4),大批组件开始支持移动端,各类频道活动也开始全面覆盖移动端。
同时,基于Node渲染服务在经历2014双11的考验后,开始全面走向业务,前端的模块渲染不满足于当前简单的异步渲染,毕竟同步输出渲染结果始终是最快的方式,于是我们对前端模块的规范进行了扩充:前端模块应该是包含js+css+模板+schema
关于Node服务的介绍可以参考文章:天猫双11前端分享系列(四):大规模 Node.js 应用
其中,模板可以在发布的时候编译成模板文件和一个模板脚本,分别支持在服务端渲染和浏览器端异步渲染。渲染所依赖的数据格式根据schema文件来约束。
还有一些其他的变更包括:
还有,ReactNativ在2015双11落地,实现了同个模块多端构建的能力。前端模块的规范变成:js+css+模板+native模板+schema。独立native模板的主要原因还是目前没有好的解决方案来实现普通web模板到native模板的编译,或者换个顺序也不行,所以还是独立维护一份Native的版本。
模块的规范基本成形,现在我们的模块开发目录大概是这样的:
- build
- src
--- index-pc.js
--- index.js
--- index-native.js
--- index-pc.less
--- index.less
--- schema.json
--- seed.json
关于ReactNative的详细可以参考:天猫双11前端分享系列(三):浅谈 React Native与双11
同时Native组件在web中调用也是正在尝试的方向,将web中一些非常复杂容易有性能问题的模块直接替换成Native,可以实现页面切换时部分组件不刷新等功能,提升用户体验。
MAP 3.0对于2015年来说是相对比较完善的方案了,但是暴露了大量的问题。
比如文章2015天猫双11前端分享系列(一):活动页面的性能优化里的描述,统一基于KISSY 1.4的模块在无线端已经成为性能瓶颈,引用文章里的一句话:脚本体积过大,目前基础脚本文件大小在100k上,占了我们规范标准的一半以上体积。
当时而言,最简单的实现方案就是无线的模块独立一套基础库,比如使用zepto或者kissy mini,而pc的模块继续沿用KISSY。但是,一方面KISSY本身相对社区解决方案已经不够新鲜,pc/无线不一致的技术体系对开发效率来说也是一个负担,更会造成大量的技术方案重复实现。
团队的第一反应是React,一方面是社区的成熟,另一方面ReactNative实践下来确实能满足业务需求,如果基于React构建模块,然后编译结合ReactNative,解决模块在Native下运行的方案,看起来非常美好。也算是真正实现了一次开发,多端运行的能力。
但是问题依然也比较明显:
审视React的过程中,最大的收获其实是Babel。通过gulp-babel + babel-polyfill的方案,我们可以在本地开发最新ES标准的代码,并在IE8及以上都能顺利运行(虽然有一些坑)。刚好2015双11之后,天猫已经彻底抛弃IE6/7,于是babel的引入就成为最先敲定的方案。
同时,基于commonjs规范进行本地开发也是一个共识,基于有编译过程,本地开发完全可以和Node一致采用commonjs规范,至于最后编译成amd、cmd或者是其他浏览器模块运行规范可以由构建工具决定。
接下来,引入Babel之后,前端是不是可以完全基于规范开发,不要再引入各种框架/库什么的?
然而,基本不可能,没有公共库就没有复用,就会有大量重复代码,而社区有大量的lib库,显然比内部写的公共库更加完善。参与社区模块的建设显然比闷声造轮子更有意义。而React本身也可以作为模块库中的一个模块存在,复杂业务可以使用React,简单业务也可以基于原生开发。
于是最后,我们确定:
问题并没有结束,引入社区lib是不是意味着要引入类似webpack的打包机制?KISSY 6已经拥抱npm,这也是社区模块的最佳实践。下面是一些对比。
npm的优势对比:
| npm | cdn combo |
|---|---|
| 模块内聚性高,对外API统一 | 模块被调用方式不可控 |
| 执行期无seed,降低运行期复杂度 | seed体积庞大,也是性能上的负担 |
cdn combo的优势对比:
| npm | cdn combo |
|---|---|
| 无法按需加载,页面公共部分无法动态更新 | 支持按需加载、多端加载 |
| 组件间存在重复代码 | 颗粒化拼装,少重复代码,可跨页面缓存 |
combo还是打包本质的区别是 动态打包 还是 静态打包;combo其实也是一种打包,只是是一种url显性表达合并配置的打包方案。
从模块颗粒化及页面性能考虑,cdn combo还是主要的方案,毕竟对于天猫的活动、频道页面来说,保证首屏体验是性能优化非常重要的一部分,只有基于combo才能动态按需地实现首屏同步加载,非首屏动态异步加载。npm方式也能做但是对于页面级需要有一个构建过程,而cdn combo只需要模块构建,页面只是一个模块的组合而不需要构建。
基于CDN combo,未来可以做更多的优化:
同时,基于npm打包的优势也需要考虑引入到体系中。 比如一个组件内不需要暴露外面的util.js 一定是和组件其他文件被外界使用,此时被combo反而带来的合并及读取的开销,此时更适合打包对外统一暴露一个文件出口。所以有复用价值的combo才合适
综合下来其实是combo和打包配合的方案,combo用来完成有复用价值部分的管理,打包用来完成无复用价值的内聚。
而seed体积精简可以通过服务端的动态seed合并及去掉已同步加载模块的seed来实现,保证页面上seed的内容一定是会使用到的。
由于开发期引入了babel,调试时就不能简单绑定host到本地了,需要引入source map,但是sourcemap对combo后的url无法解析,所以需要在机制上实现调试时解combo,客户端和服务端都支持一下就可以了,具体实现可以见后面加载机制里的设计。
如上面描述,确认了前端工作流的大部分细节:
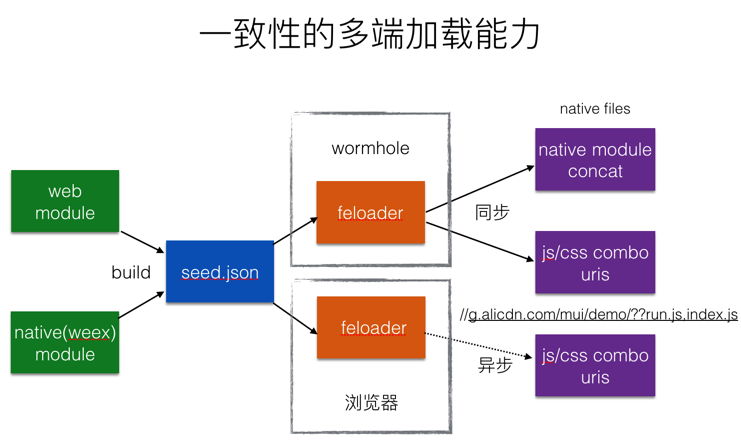
接下来就是多端加载的解决了。
第一步就是需要一个Loader,这里需要把Native组件一起考虑进来,于是我们提供了这样的Loader加载策略,feloader是目前加载器的名字,wormhole是服务端模板渲染服务。
无论是开发Native还是Web,都采用一样的方式生成配置文件,基于配置文件,模块之间的调用关系就可以明确,然后服务端可以根据依赖表输出combo uri及直接对Native模块进行组合。
浏览器端目前由于无法直接运行commonjs规范的脚本,解决方案也非常简单,在构建工具打包的时候,包上一层define(modName, deps, function(require, exports, module))即可。
Node渲染服务也需要实现基于模块配置的依赖分析,生成combo uri,如果是native模块,则直接分析完依赖后,将模块内容拼接成一个大的脚本返回。
1)从KISSY迁移到目前的开发模式,改动很大,以后还会不会有这样的大范围升级?
答案是,升级肯定会有,保持依赖模块和使用技术的新鲜才能提升业务效率,毕竟用户环境、外部社区也是在不断升级。但是不会有大范围的升级:一方面我们采用基于浏览器标准规范的方式开发,这一部分属于相对比较稳定,变化不会对研发造成负面影响,另一方面模块本身颗粒化,升级一样也是颗粒化,快速迭代的方式,而不是所有模块一起选一个特定时间集中式改造,减少对业务的影响,让升级融入到业务开发中。
2)基础体系变化怎么大,如何解决兼容问题?
兼容问题确实比较大,首先Node容器和本地开发工具都需要向前兼容,这个是必须的。
而对于前端开发的模块,我们提供了一个kissy-polyfill方案让AMD模块在KISSY页面上运行,这样可以让大家快速开始基于新的方式开发模块,然后这个模块可以在老页面上运行。
具体实现也很简单
其他就是一些加载器细节的patch,比如已经加载模块的配置可以重写什么的。
3)目前MUI体系引入了zepto作为基础DOM/event的解决方案,如何支持IE8/9?是不是依然需要无线PC两套基础库?
目前我们是这么解决的:
很多人其实觉得前端基础技术体系已经很难有突破,但是虽然MAP升级了那么多版本,ES规范也在不停升级,但是很多背后的**还是一致,只是在原来的基础上不断优化细节,然后提高扩展性。这也是为什么前端一直在强调基础的重要性,CSS2,ES3依然是基础的重要组成部分,工具框架只是外壳,理解为什么这么设计远重要于知道如何使用。
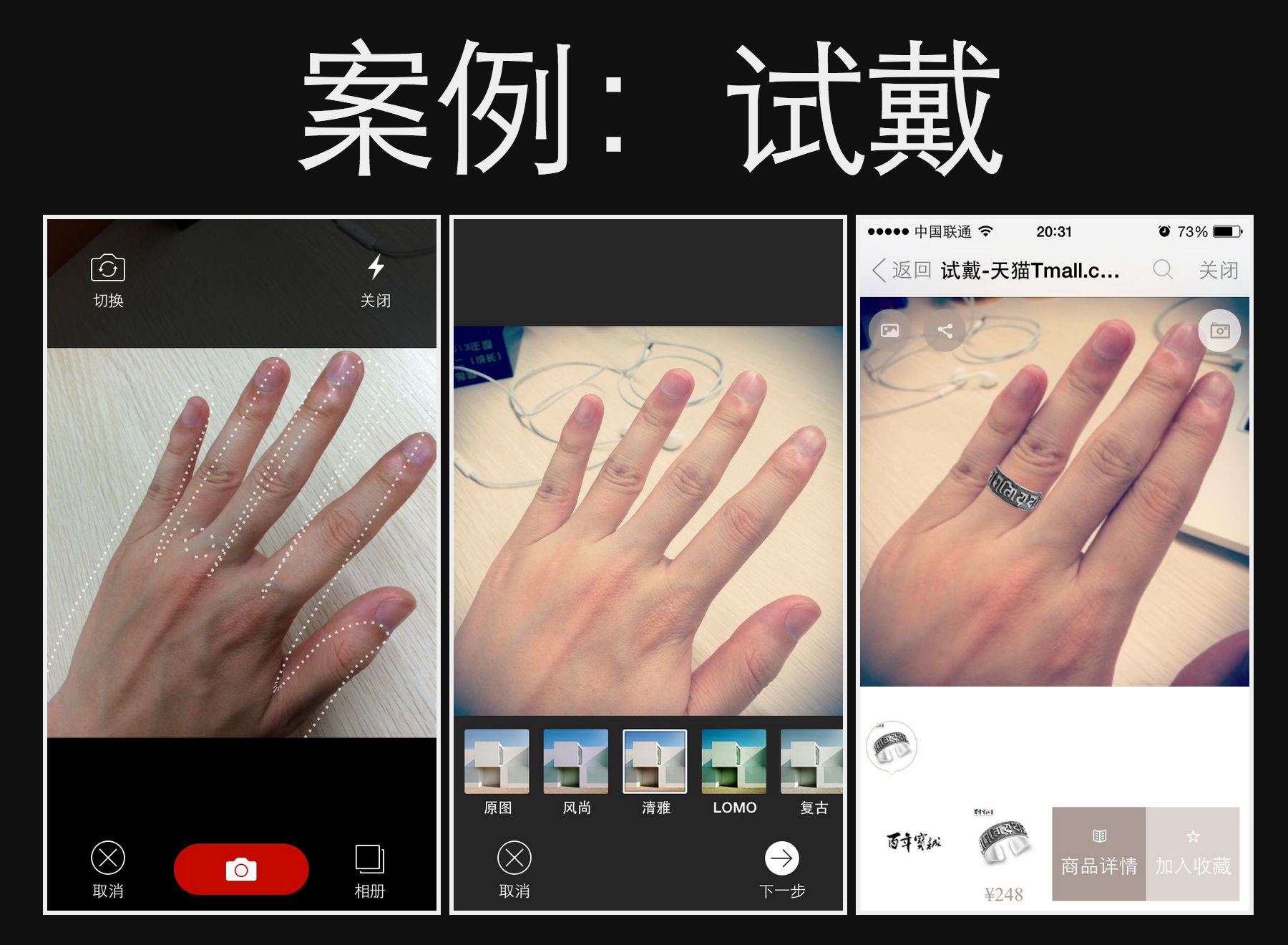
请先扫码体验(天猫app体验最佳):
体验完产品,具体讲下技术实现方案,整体的实现过程可以分为:
拍照->获得图片数据->将商品与图片合成->生成效果图->用户保存图片
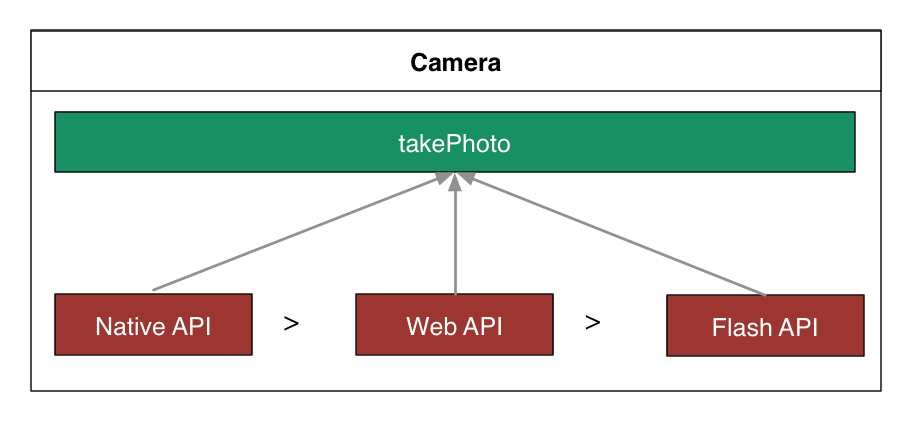
这是试戴的关键一步,考虑到需要支持到各个终端,所以优先想到使用标准的web方案来实现:WebRTC-getUserMedia
基于getUserMedia,面向mobile 快速尝试,基本完成了主要的功能
但getUserMedia的支持情况并不理想,尤其是sarfari的不支持让广大ios/mac用户无法体验,这里就需要PC、mobile的兼容处理,以跨终端mobile first及优雅退化的思路设计兼容API:
对于戒指的试戴,手机上我们期望优先调用后置摄像头,在web中启动时就需要设置优先后置摄像头,W3C文档还处于Draft阶段,相对还不是特别完善,可以通过如下设置:
{
video:{
optional: [
{
sourceId: $sourceId
}
]
}
}
通过MediaStreamTrack.getSources可获得设备的所有sourceId,注意:考虑设备可能没有外设如台式机或外设设备不可用(在虚拟机或远程),这种情况下会报错,所以需要try&catach容错。
不同的终端,摄像头拍摄的图片照片尺寸是不同的,如果我们只需要获得某一部分图像,就需要对图像做剪裁,在WEB中为了不引起用户疑惑,展现给用户拍照界面时,所见最好就是所需要的部分
举个栗子:我们期望获得一个正方形的图片,但是rmbp中摄像原始是16:9的图像,考虑方案有:
需要注意的是:video API中有 videoHeight及videoWidth两个属性,当video play时理论这两个属性就是当前图像的宽高,但实际情况Mozilla存在一个bug#926753,play时仍无法准确获取,兼容的方案轮训监听:
Event.on(video,"play",function(){
if(this.videoHeight===0){
return S.later(arguments.callee,100,false,this);
}
// now width/height ok
}
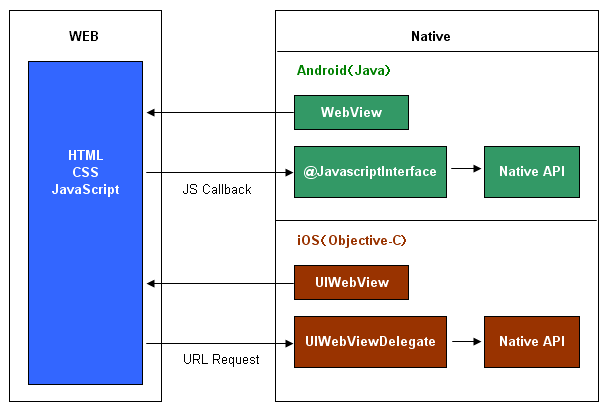
在拍照完成native中需要把图片数据传递给web,另外用户保存图片到本地时,web又需要把合成好的图片数据传递给native让其保存,这边涉及native与web的传递大数据通讯:
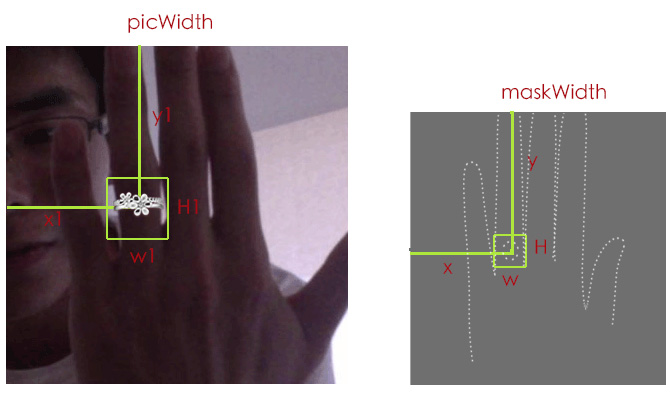
WebView#addJavascriptInterface()向web注入js方法 ,UIWebView#stringByEvaluatingJavaScriptFromString()执行js函数,两种方式向web传递大数据都没有问题比较简单,用图片说明: picWidth/maskWidth = x1/x = w1/w
知道了具体位置,生成图片便可以简单的调用 canvas.toDataURL获得图片数据,但这里涉及一个图片跨域问题:
Canvas获取图片数据会有跨域的限制,之前有:imageProxy flash来做代理的方案,但是这个方案仍然不够高效和简洁,尤其是对于mobile更无能为力
最好的方案是web标准的CORS,通过让服务器返回allow-origin的header,让canvas可以正常处理:
// http response header: Access-Control-Allow-Origin: *
img.crossOrigin = "Anonymous";
img.onload = function() {
ctx.drawImage( img, 0, 0 );
canvas.toDataURL("image/png");
}
在整个开发的过程中是以组件化的思路分层处理,并封装成了具体的组件,通过封装的组件,后续拍照、试戴可以快速搭建完成,除了天猫自身业务特色的组件外,比较通用的有:
再设计跨终端有组件时,经验是优先面向mobile设计,这样逻辑及交互流程更加简洁,可以让API涉及更加清晰,后续正对PC适当兼容。
最后简单聊下这个业务:这是一个技术驱动业务的项目,从初期的业务重点在频道,中间经历几次业务调整,到目前把试戴作为业务后续的重点,可以说这个产品在其中起到了很多的作用,其中几点经验:
后续试戴还有很多地方可以发力,比较重要的一些方向:
首先,要先说声抱歉,因为,其实目前我们还没有做到精确地做到识别99%的终端设别,其中原因,一部分是因为终端类型和UA实在难以覆盖,另外一部分原因也是因为使用了一些错误的识别策略。
注1:后面会大量出现detector,其实就是我们给内部终端识别工具起的一个名字。
注2:天猫页面一直在实施一个url对应多份不同终端的页面,所以终端识别非常重要。
由于当时处于业务mobile页面发展的初期,且大部分页面还在基于php进行开发,所以诞生了detector的第一个版本,php版本。识别逻辑也比较简单,纯正则匹配UA。
后来,node业务渐渐的增加,我们又重写了一份node版本,其中为了保持终端识别能力的一致,用于匹配UA的正则统一放到了一份json文件里,php和node都统一来读这一份文件。
正则主要还是收集了github上各种比较成熟的识别方案综合出来的。
在2014年底,为了保证pad用户的访问质量,我们对终端识别的工具进行了非常大的改造。其中,一直在坚持的一点就是将识别能力放到服务端进行。
当时面临的一个难题是,安卓pad和安卓phone之间的UA并没有差异,特别是4.2之前的版本,无法通过UA进行识别,但是又希望能够让用户在安卓pad上看到更合适的PC版本,我们设计并产出了MED的终端硬件信息获取方案。
MED的运行逻辑其实很简单:用户第一次访问的时候,在nginx端插入一个脚本,计算设备宽高、像素宽高、是否支持触摸等信息,然后记录到cookie中,第二次访问的时候,nginx就可以拿到用户的终端信息了。
于是,我们就可以知道用户的物理宽度了。可惜这里埋了一些坑。
由于nginx端包含了拿到终端硬件信息的能力,那么这里就有两个选择
其实,这里并没有太多的纠结,服务端语言太多,针对各种不同的语言维护一份实在不太现实。于是,我们选择在nginx层做这些事情,这里用到了开源的tengine模块http_user_agent。
具体的识别规则也是从正则切换到了nginx配置文件。整个流程就优化为
这个方案逐渐部署到了各个应用上,支持了包括频道、活动、搜索等应用的终端识别,也顺利经过了双11的考验。
nginx层做解析带来一个惊喜,就是原本只有一个url一份缓存的方案,由于天猫一个url对应的是多个端不同的内容,无法进行缓存。
在nginx层面能够识别用户终端后,我们可以让一个url针对多份缓存副本,从而实现在cdn上可以直接经过nginx转发请求到用户终端对应的副本。
双11结束之后,我这边对已有方案进行了梳理,nginx方案已经暴露了一些问题,更新nginx配置文件成本相对发布前端文件或者后端文件都略高,且很多安卓phone都反馈了访问时看到了pc版本的页面。
前者的问题在于维护成本,后者的原因是来自前面提到的浏览器提供数值问题。
目前识别策略还是遵守安卓UA规范,包含android + mobile则判断是Phone,android不带phone就是pad,也算是面对未来的解决方案了。
最后,如果有更好的识别方案或者建议,欢迎找我沟通。
详见:


无线优先从去年开始推行,今年更是全面无线化,双11无线业务成交拿到了不错的结果,性能也迈出了一大步,对比去年双十一页面整体load时间提升了2s秒左右,秒开率达到了70%;
去年双11活动会场埋点几个页面的性能,onload均值在4.7s左右(实际情况应该在3-4秒),导致跳失率非常高。
今年双十一后的数据情况:
| 2G平均加载完成时间 | 3G平均加载完成时间 | 4G平均加载完成时间 | Wi-Fi平均加载完成时间 | wifi页面秒开占比 |
|---|---|---|---|---|
| 4s | 4s | 2s | 2s | 70% |
对比去年双11和以往活动提升最明显的地方在于,针对所有图片均作了裁剪压缩处理,由于活动业务的特殊性,和目前在源头没能控制住图片的大小,往往一张页头图片或运营从detail页提取的商品图片就能达到300k,整体页面体积能超过1M(首屏600k左右),而现在通过CDN的裁剪压缩后一张图片大小能缩小70%左右,针对所有图片处理后页面整体体积和效率缩减至少一半,以一个简单双十一页面为例:
预加载是这次手淘新发起的解决方案,将页面中静态资源预加载到手淘客户端,减少这些静态资源请求,这套方案也正好解决了,天猫目前繁杂的业务下诞生的一些固定大资源的问题。详细会在相关文章中再详细介绍
目前天猫的页面基本上都还在基于KISSY搭建,原来的目的是为了保持PC/Mobile端技术的一致性和简单性,提高工作效率和工程化能力。而这在全面无线化的今天,已经成为一个瓶颈,这也是天猫后续技术发展需要解决的一个非常重要的问题。
性能这块活动目前做的远远不够,看向手淘,还有太多太多的东西要做,相比繁杂的业务压力,确实需要缓缓,放慢手中的业务,将性能和品质提升上去。
如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
Hilo,一套HTML5跨终端的互动游戏解决方案。Hilo支持了多届淘宝&天猫狂欢城等双十一大型和日常营销活动。内核极简,提供包括DOM,Canvas,Flash,WebGL等多种渲染方案,满足全终端和性能要求。支持多种模块范式的包装版本以及开放的扩展方式,方便接入和扩展。提供对2D物理,骨骼动画的内建和扩展支持。另外,Hilo提供丰富的周边工具及开发案例。
目前,Hilo已经开源,并入到Hilo Team中。开源地址 https://github.com/hiloteam/Hilo (欢迎Star)
Hilo的特点:
Hilo采用极简的内核。核心模块包括基础类工具(Class),事件系统(EventMixin),渲染(Render)和可视对象(View),如下图所示。
首先,我们来看看如何接入Hilo。
Hilo是模块化的架构,且每个模块尽量保持无依赖或最小依赖。在Hilo的源码中,你看不到一般的模块定义的范式:
define(function(require, exports, module){
var a = require('a'),
b = require('b');
//something code here
return someModule;
}
);
取而代之的是,Hilo的每个模块都会有这样的注释定义:
/**
* @module hilo/view/Sprite
* @requires hilo/core/Hilo
* @requires hilo/core/Class
* @requires hilo/view/View
* @requires hilo/view/Drawable
*/
我们使用注释标签@module来标记模块名称,用@requires标记模块的依赖。
在编译阶段,我们会根据这些标记获取模块的相关信息,然后编译生成符合不同的模块范式定义的代码。比如:
define(function(require, exports, module){
var Hilo = require('hilo/core/Hilo');
var Class = require('hilo/core/Class');
var View = require('hilo/view/View');
var Drawable = require('hilo/view/Drawable');
//some code here
return Sprite;
};
我们除开提供一个独立无依赖的版本外,还提供AMD、CommonJS、CMD、CommonJS、Kissy等多种模块范式的版本。开发者可以根据自己的习惯,下载Hilo的不同范式版本使用。
hilo/
└── build/
├── standalone/
├── amd/
├── commonjs/
├── kissy/
└── cmd/
接下来,我们来看看Hilo如何做扩展。
Class.create 是Hilo里创建类的主要方法,如下:
var SomeClass = Class.create({
Extends: ParentClass,
Mixes: SomeMixin,
Statics: SomeStatics,
constructor: Constructor,
propertyName: propertyValue,
methodName: methodValue
});其中:
Extends - 指定一个父类。Mixes - 指定混入对象。可以是一个Object或Array。Statics - 指定静态属性。constructor - 创建类的构造函数。此外 Hilo 使用 Class.mix(target, [mixinObject]),可以为target混入属性和方法。
代码示例:
var EventMixin = {
on: function(type, handler){ },
off: function(type, handler){ },
fire: function(type, detail){ }
}
Class.mix(object, EventMixin);再以扩展Hilo的可视对象的基础类View为例。View在表现上就是一个个矩形,无论图片还是文字都可以使用一个最小的矩形包裹。在这些可视对象上做平移,旋转,缩放,透明处理等操作就可以实现普通动画的绝大部分。
如上图所示,View解决了可视对象展示的基本问题。
利用Hilo提供创建类和扩展类的方法,我们可以扩展出可视对象所属管理的Container类:
类似地,根据不同View的其他展示特性,Hilo扩展出舞台Stage,位图Bitmap,画图Graphic,精灵动画Sprite等类型。
我们知道一个游戏运行的核心流程——在一个Loop循环内,接受输入并完成对所有可视对象的游戏属性更新,然后渲染。下面是单个可视对象的一个循环过程:
作为一个可视对象,包含了位置,大小,缩放,旋转等自然信息,如下图所示:
Update是个计算过程,后面赛车案例会讲通过Update我们可以做一些特殊的效果出来。在这之前,我们先看看渲染,即如何根据可视对象的自然信息来把他们 “画”出来。那么如何实现View的render函数呢?如上图所示,在render函数中主要解决两个问题:
render: function(renderer, delta){
//不同的View renderer方式可以多样,相同的View也可以根据renderer的类型不同而呈现差异化
...
}
Hilo首次提出了特别的渲染方案——即提供DOM 、Canvas、 Flash或者WebGL 四种渲染的方式来实现render,目前该方案已经申请专利。这四种渲染方式是和View独立分开的,View在做自身属性更新时完全不需要考虑怎么被“画”出来,同样,拿到View后我们可以使用不同的“画笔”把它描绘出来。如果你有更好的绘制方式,也可以扩展出更多的渲染方案。如下图所示:
View可以粗略分为普通类的View,文字类View(Text)和画图类View(Graphic)几种类型。不同类型的View“长相”不尽相同,在做Update和Render时也要针对处理。
普通类的View,如Bitmap,Container,Button,Sprite,在渲染层面主要处理图片的展示问题。单从图片展示的技术实现上讲,DOM渲染可以通过设置元素的background样式实现,Canvas也有绘图方法drawImage,WebGL则可以通过shader做纹理绑定。
特别地,在Flash的渲染模式下,Hilo首先将View所有和绘图相关的方法通过JSBridge的方式交由适配器FlashAdapter,FlashAdapter来翻译成对应Flash工程实现绘制的方法,如下图所示:
由于Flash在PC浏览器上的广泛支持,特别是IE的支持,使用Flash渲染额外好处就是跨终端,这个终端包括所有主流PC浏览器(包括IE 6,7,8)在内。
另外,在一些低端的手机浏览器上,可以选择DOM渲染模式来代替其他的渲染方式。在Canvas支持不好的机器上或者互动游戏场景本身比较耗性能情况下,DOM渲染模式可以很好地胜任渲染的工作。2015年天猫年中大促的赛车互动,我们就在Android机器上使用DOM渲染的方案。
除了多种渲染模式,Hilo还提供给一些其他衍生能力。这些衍生能力或者来自每次项目的技术改进,或者来自对其他优秀引擎的能力的吸收。例如Hilo支持主流骨骼动画和自建骨骼动画系统(Tahiti),狂欢城多图片下高性能优化,主流物理引擎无缝支持和一些特殊物理效果实现。
相比较精灵动画(Sprite Animation),骨骼动画(Skeletal animation)使用一套资源就可以完成千万种动作变化。
目前做骨骼动画比较成熟的产品有Spine和DragonBones 。两者在功能上已经接近,考虑DragonBones免费,可自由使用,Hilo实现了对DragonBones的支持。
Hilo也实现了自己的动画编辑器(目前仅内部使用)——Tahiti。Tahiti通过Flash插件的方式实现,目前可以支持CSS3 animation,DOM,Canvas,Hilo动画导出。
骨骼动画将可视对象进行分解,得到一个个可视组件。很显然,这些一个个可视组件本身就是一个个View,只要调整相应的时间片内调整这些View的transform属性,把他们组合起来就是一套完整的动作。
Tahiti将分离出的可视对象扁平化管理,各个部件处于同一层级。借助我们自己实现Flash 插件就可以导出如下的动画数据格式:
{
//图层数据,按层级从上到下排列
"layers":[
{
"name":"head",
//关键帧数据
"frames":[
{
"tween": true, //是否缓动
"duration": 10, //持续帧数
"image":"img1",//对应texture中的键值
"elem": {
"scaleX": 1,
"scaleY": 1,
"rotation": 30,
"originX": 46.5,
"originY": 76.5,
"x": 108.5,
"y": 507.5,
"alpha": 100 //透明度,范围0~100,0完全透明,100完全不透明
}
}
]
}
],
//素材数据
"texture":{
"img1":{
"x":20, //在大图中的位置x
"y":50, //在大图中的位置y
"w":100,
"h":200
}
},
//舞台数据
"stage":{
"width":550, //动画容器宽
"height":400, //动画容器高
"fps":24 //帧频
},
//动作数据
"actions":{
"anim_die":12 //{动作名:帧数}
}
}
Tahiti实现了对导出数据的解析,再借助Hilo的渲染,就可以把设定的动画运行起来了。特别地,Tahiti不仅对接了Hilo的渲染,还可以对接了CSS3 animation,独立JS模式(Canvas)的渲染。
一年一度的双十一狂欢城是检验性能的大考。以2015年双十一狂欢城为例,在性能方面主要面临的挑战:
狂欢城预估图片总数为200张 ( 252*296),为了优化性能,我们首先对整体画面做了三个分层:
下面主要看看地图部分的优化。
地图部分多为静止画面,为TiledMap的拼块。由于Canvas大小有限制,同时为了性能考虑,我们把8屏狂欢城界面按512*512分解成多个块,分解方式如下图:
把这些分块独立成一个个Canvas,他们只在首次加载时和内容更改时(比较低的频率)进行渲染,渲染结果保存在这些Cache List中。这个List同时被图示地图Container管理,每次更新时只需要对这些缓存在内存中的List做一次整体渲染即可,这样就避免了成百个view单独渲染的问题,大大的降低了draw的次数。
此外,这些分块在有内容更新时,如上图的脏矩形更新所示,View 2在某一帧有内容更新,那么先找出和View 2 所有相交的view,然后把这些View按照Z轴次序从远及近更新,且只更新其相交部分。这样,便可以最大限度的只渲染需要渲染的部分。
概括地说,我们首先从结构上保证性能,大的方面上做了分层,抽出那些“动”和“不太动”的。其次,我们把view做了分块,把多个的view 更新渲染变成了一个512*512 大小的view 渲染,组成Cache List,然后在交互范围内把Cache List里需要输出的对象渲染到手机真实物理屏。与此同时,在更新Cache List时,为了避免Cache List 内 view对象的全部更新,我们尝试了更新引起变化的最小矩形块。
考虑到性能和库的精简,Hilo选择Chipmunk 作为自己的默认2D物理引擎。
我们知道物理世界非常丰富,不可能通过一个物理引擎就把物理世界全部展现的。不同材质,刚体或非刚体,流体或者布料这些在物理表现上差别巨大。物理引擎帮助我们解决一些基本问题,就像Hilo里的基础类View解决可视对象的基础问题。
面向业务,我们可以扩展出更多的物理效果。如2015年天猫年中大促的赛车项目,我们自己实现了一套赛车漂移的效果,改写的就是View Update计算方式。具体实现在后续介绍文章中推出。
以上,从动画,性能,物理三个方面案例阐述了Hilo可以做更多的事情,相信在业务支持和技术推动下,Hilo可以更加完善,非常希望对互动感兴趣的同学加入到Hilo开源队伍中,完善Hilo能力,提高Hilo开发效率,同时产出更多令人欣喜的作品。
Hilo 从阿里前端委员会建议立项到开发完成,得到许多关注和帮助,也同时支持到共享、阿里通信、手淘、天猫、城市生活、国际UED、阿里妈妈多个BU。因技术推广这里就不一一感谢。 留下两位主要作者的花名 @正霖 @墨川
前一篇文章讲述了我们是怎样应用 Node.js 解决模板渲染的实际问题的,而这一篇我们来看看天猫是如何一步步将 node 推广到各个业务线上的。
前面讲述了我们通过 node 在今年双十一中承担了大量的页面渲染工作,包括:
单单看上面列出来的内容可能无法很直观的感受到到底 node 在天猫覆盖了多少业务。大家拿出手机,用浏览器打开天猫首页:
_从天猫无线首页上点进的任何一个天猫的链接,包括搜索后的列表页、每一个店铺或者商品详情页,都经由 node 渲染产生。_
罗马不是一天建成的,天猫将 node 覆盖到如此广的业务范围也是通过一年多的时间慢慢的渗透改造完成。这篇文章想和大家分享一下天猫是如何一步步将页面渲染部分通过 node 替换掉 php 和 java 的。
在一年半之前,天猫的所有的活动页面、首页和频道页都是基于 TMS 搭建,由 php 在一个独特的 CDN 集群上进行渲染,然而由于之前 php 系统已经没有人维护了,且各种业务共享同一个环境导致 php 版本一直停留在很老的版本无法升级,性能和安全性上有各种问题。
此时亟需一个新的系统来取代旧的 php 体系,而 node 当时已经在业界和公司内慢慢的被应用起来了,特别是在阿里内部,已经有较为成熟的开发环境(包括私有 npm 服务、与内部其他系统的打通、与发布和监控体系的打通),而在做模板渲染层而言,node 可以很容易的做到前后端共享模板语言,加上性能也不差,前端又比较熟悉,所以最终我们选择了基于 node 进行改造。
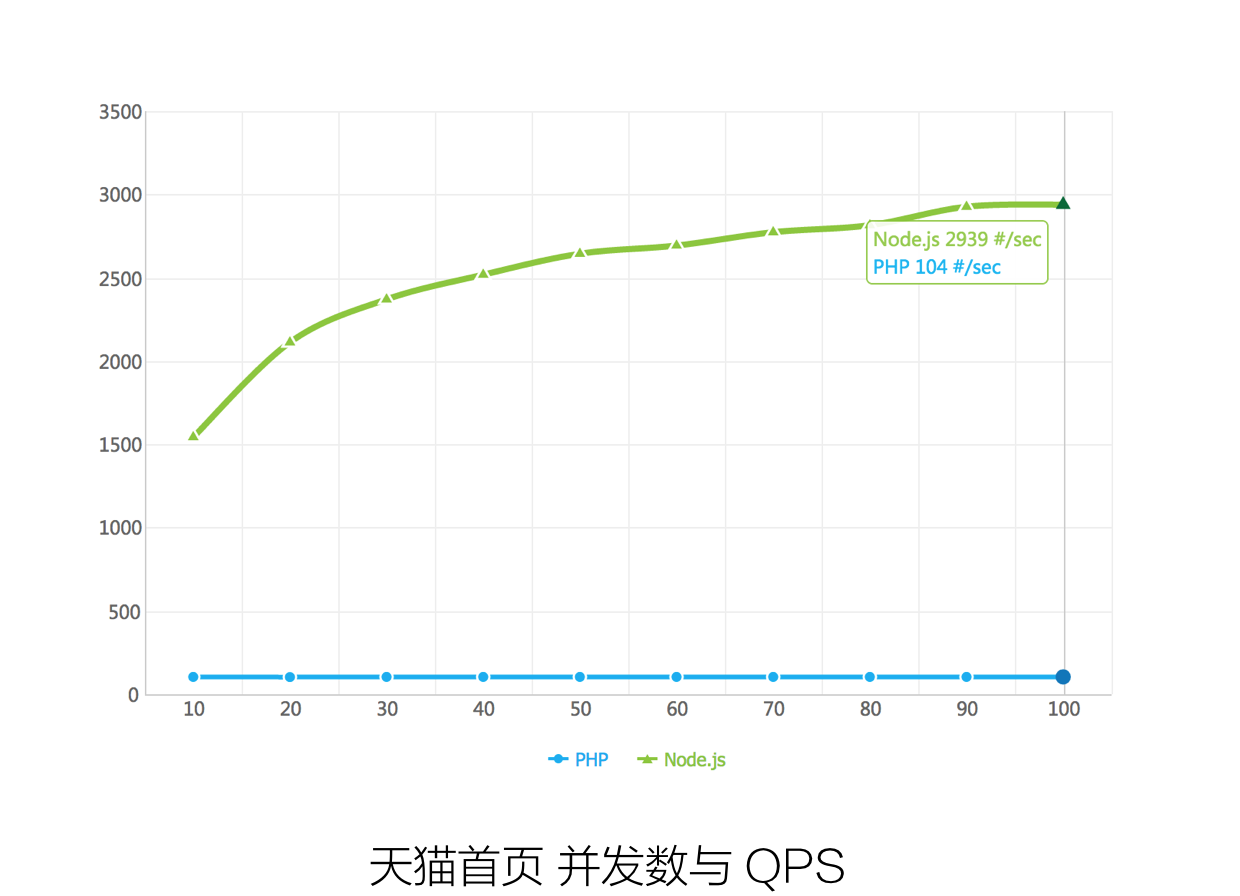
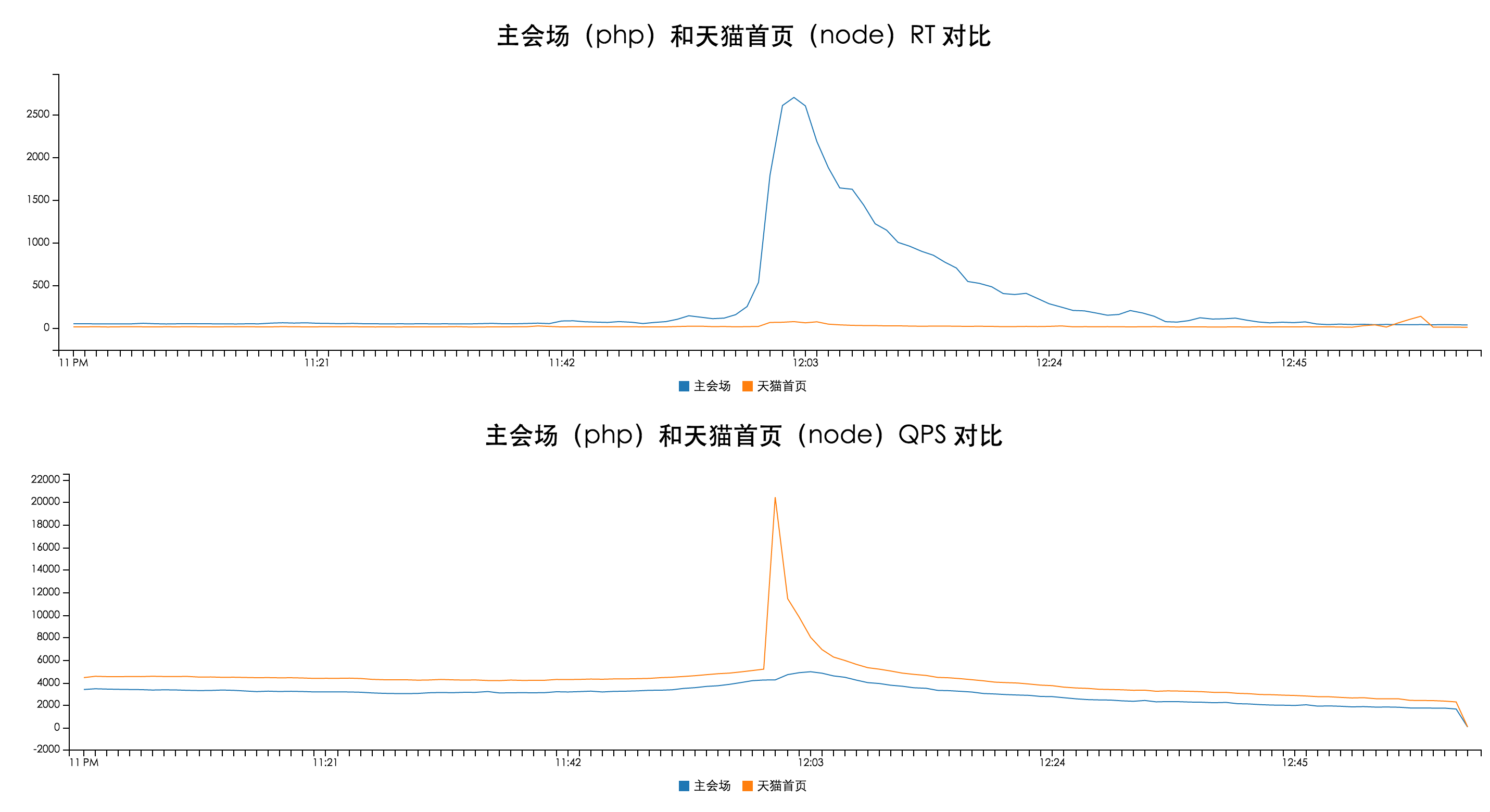
于是我们基于 node 快速的开发了第一个版本的 wormhole(node 渲染容器),并将天猫的首页迁移到了这套系统上。迁移完成之后,我们对新(node)老(php)首页做了一个性能对比:
尽管这个结果有一部分因素是因为老系统功能上比新系统要复杂,但是也在很大一定程度上说明了采用 node 的新架构来做这件事情是没有问题的。
每年的双十一都是对天猫整个技术架构的一次考验,而 2014 年的双十一对于天猫的 node 来说也是一次非常重要的小考:我们在双十一前把天猫首页改成了 node 版本并全量发布了。当时我们在 CDN 的一个独立集群上同时部署了 php 和 node 两套系统,将天猫首页的业务迁移上了 node,而其他的页面仍然采用 php 进行渲染。
在双十一当天零点的流量高峰中,node 的表现非常稳定,在同样的环境下,可以说是完胜之前的 php 系统。在此之后,我们终于有足够的底气对老板说:我们要把天猫的 view 这一层全部交给 node。
在天猫首页上经过了 14 年双十一的考验之后,我们对 node 是否能够支撑天猫的业务场景已经没有疑虑了,剩下的问题就是如何大规模的将 node 应用到天猫的各个业务上去。
首先我们解决的第一件事情是将天猫前端的模块化开发体系和资源加载方案融入到 node 中,然后推广到各个业务线上,然后又基于 node 构建了一个模块化页面搭建平台,打通前端、运营和后端数据产出系统,承接了天猫所有活动页和频道页等强运营需求的页面。具体的技术方案大家可以查看前一篇文章:天猫双11前端分享系列(四):大规模 Node.js 应用。
通过这一系列的技术改造之后,我们**把所有新的业务需求全部使用 node 进行渲染**,然后将之前所有用 php 渲染的页面迁移到 node 之上,仅仅用了几个月时间,基本将天猫移动端的 web 页面和所有的活动页、频道页都迁移完成。
经过大半年时间的重构和迁移,到今年年中的时候,天猫的大部分消费者端的页面都已经跑在了 node 之上,这时又要开始准备新一年的双十一了,比起去年只有一个天猫首页而言,对 node 的压力大了不止一个数量级。
我们评估基于今年的访问量,如果我们再把天猫首页、活动页直接放在 CDN 上进行渲染,对于 CDN 的机器成本来说是不可接受的,而且随着机器数量的增加,对于文件同步系统的压力也越来越大,效率越来越低。因此我们和 CDN 团队合作,将所有的活动页面从直接渲染模式迁移到缓存化 CDN + 源站的模式,并在这个模式下对 node 应用的监控和稳定性上做了非常多的工作。
而对于那些应用集群上的业务,我们也统一做了版本更新、监控完善和性能压测容量评估,保证各个业务方使用的 node 容器的稳定性。
最终,在今年的双十一中,node 支撑了天猫消费者端在无线设备上绝大多数的 web 页面渲染,PC 上除了核心链路外的绝大部分页面渲染工作,并且表现非常稳定,未出现任何一起由 node 引发的线上故障,而基于缓存化 CDN 的活动页面渲染服务,支撑双十一零点高峰的访问量也毫无压力,用少量的机器完成了去年双十一巨量投入才解决的问题。
记得在去年刚开始在天猫推动 node 的时候做了一个 slide 和大老板汇报,中间有一页是介绍业界是如何使用 node 的:
在一年多之后的今天,天猫的 node 应用经过这次双十一的考验之后,相信也完全有资格出现在这页 slide 之上了!
详见 跨终端的前端工程师 @三七 2014.03.20 @电⼦子科技⼤大学,2014.03.21 @四川⼤大学
简历投递方式:重要的事情写最前面,直接发简历到 [email protected]
也可以扫码提交简历

下面图上有比较详细的岗位描述和要求,这里就用文字说一些面向校园的同学的岗位介绍和建议
更多可以看淘系前端对外的博客:https://fed.taobao.org/

以前不喜欢写测试,主要是觉得编写和维护测试用例非常的浪费时间。在真正写了一段时间的基础组件和基础工具后,才发现自动化测试有很多好处。测试最重要的自然是提升代码质量。代码有测试用例,虽不能说百分百无bug,但至少说明测试用例覆盖到的场景是没有问题的。有测试用例,发布前跑一下,可以杜绝各种疏忽而引起的功能bug。
自动化测试另外一个重要特点就是快速反馈,反馈越迅速意味着开发效率越高。拿UI组件为例,开发过程都是打开浏览器刷新页面点点点才能确定UI组件工作情况是否符合自己预期。接入自动化测试以后,通过脚本代替这些手动点击,接入代码watch后每次保存文件都能快速得知自己的的改动是否影响功能,节省了很多时间,毕竟机器干事情比人总是要快得多。
有了自动化测试,开发者会更加信任自己的代码。开发者再也不会惧怕将代码交给别人维护,不用担心别的开发者在代码里搞“破坏”。后人接手一段有测试用例的代码,修改起来也会更加从容。测试用例里非常清楚的阐释了开发者和使用者对于这端代码的期望和要求,也非常有利于代码的传承。
说了这么多测试的好处,并不代表一上来就要写出100%场景覆盖的测试用例。个人一直坚持一个观点:基于投入产出比来做测试。由于维护测试用例也是一大笔开销(毕竟没有多少测试会专门帮前端写业务测试用例,而前端使用的流程自动化工具更是没有测试参与了)。对于像基础组件、基础模型之类的不常变更且复用较多的部分,可以考虑去写测试用例来保证质量。个人比较倾向于先写少量的测试用例覆盖到80%+的场景,保证覆盖主要使用流程。一些极端场景出现的bug可以在迭代中形成测试用例沉淀,场景覆盖也将逐渐趋近100%。但对于迭代较快的业务逻辑以及生存时间不长的活动页面之类的就别花时间写测试用例了,维护测试用例的时间大了去了,成本太高。
对于Node.js的模块,测试算是比较方便的,毕竟源码和依赖都在本地,看得见摸得着。
测试主要使用到的工具是测试框架、断言库以及代码覆盖率工具:
以如下的Node.js项目结构为例
.
├── LICENSE
├── README.md
├── index.js
├── node_modules
├── package.json
└── test
└── test.js
首先自然是安装工具,这里先装测试框架和断言库:npm install --save-dev mocha should。装完后就可以开始测试之旅了。
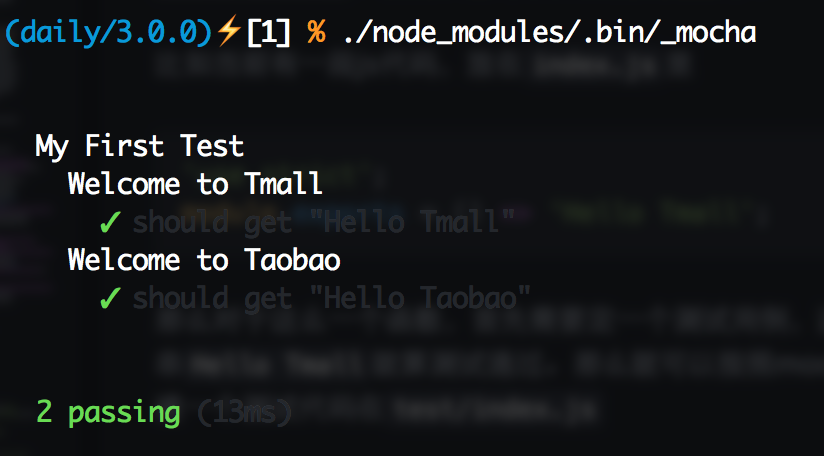
比如当前有一段js代码,放在index.js里
'use strict';
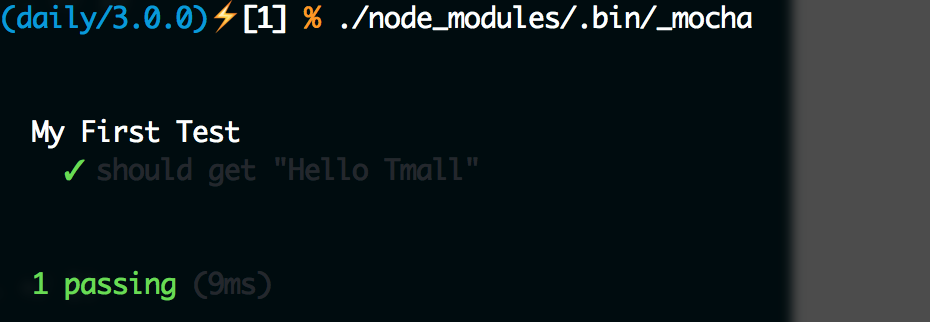
module.exports = () => 'Hello Tmall';那么对于这么一个函数,首先需要定一个测试用例,这里很明显,运行函数,得到字符串Hello Tmall就算测试通过。那么就可以按照Mocha的写法来写一个测试用例,因此新建一个测试代码在test/index.js
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Tmall"', () => {
mylib().should.be.eql('Hello Tmall');
});
});测试用例写完了,那么怎么知道测试结果呢?
由于我们之前已经安装了Mocha,可以在node_modules里面找到它,Mocha提供了命令行工具_mocha,可以直接在./node_modules/.bin/_mocha找到它,运行它就可以执行测试了:
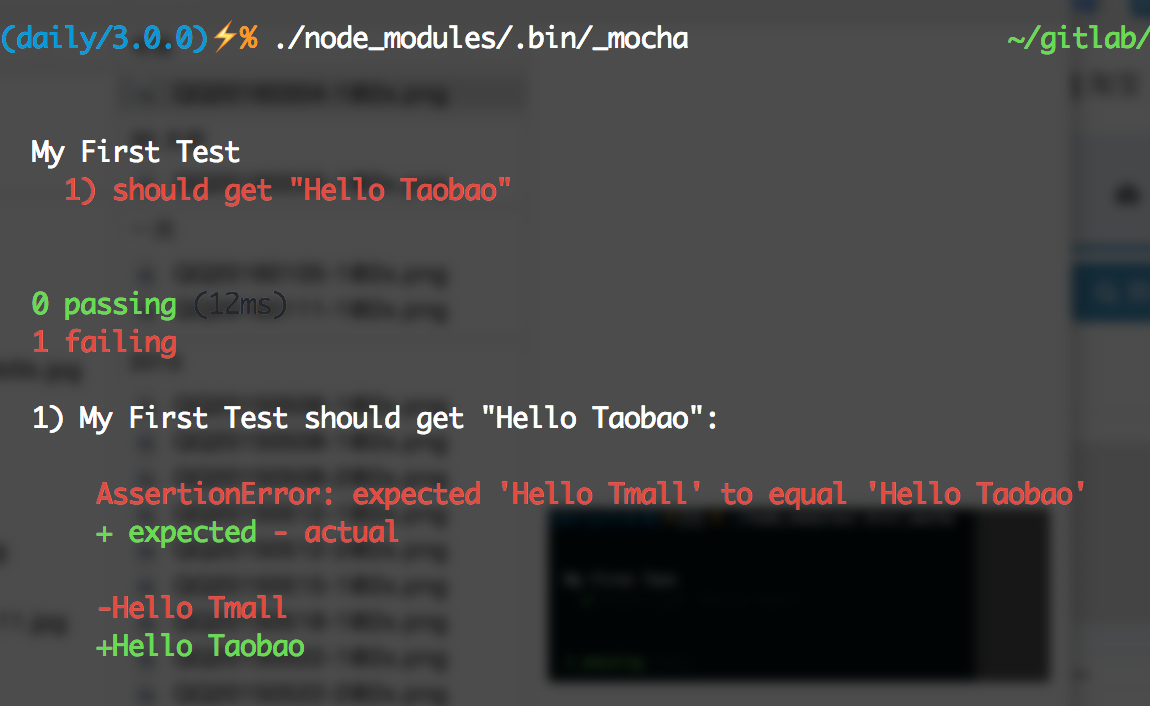
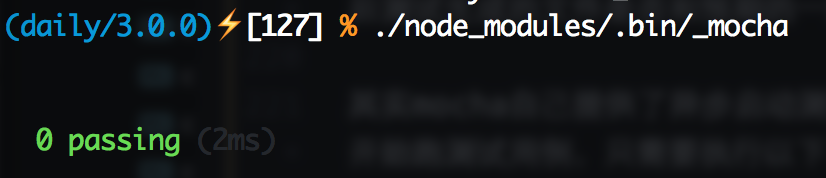
这样就可以看到测试结果了。同样我们可以故意让测试不通过,修改test.js代码为:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Taobao"', () => {
mylib().should.be.eql('Hello Taobao');
});
});就可以看到下图了:
Mocha实际上支持很多参数来提供很多灵活的控制,比如使用./node_modules/.bin/_mocha --require should,Mocha在启动测试时就会自己去加载Should.js,这样test/test.js里就不需要手动require('should');了。更多参数配置可以查阅Mocha官方文档。
那么这些测试代码分别是啥意思呢?
这里首先引入了断言库Should.js,然后引入了自己的代码,这里it()函数定义了一个测试用例,通过Should.js提供的api,可以非常语义化的描述测试用例。那么describe又是干什么的呢?
describe干的事情就是给测试用例分组。为了尽可能多的覆盖各种情况,测试用例往往会有很多。这时候通过分组就可以比较方便的管理(这里提一句,describe是可以嵌套的,也就是说外层分组了之后,内部还可以分子组)。另外还有一个非常重要的特性,就是每个分组都可以进行预处理(before、beforeEach)和后处理(after, afterEach)。
如果把index.js源码改为:
'use strict';
module.exports = bu => `Hello ${bu}`;为了测试不同的bu,测试用例也对应的改为:
'use strict';
require('should');
const mylib = require('../index');
let bu = 'none';
describe('My First Test', () => {
describe('Welcome to Tmall', () => {
before(() => bu = 'Tmall');
after(() => bu = 'none');
it('should get "Hello Tmall"', () => {
mylib(bu).should.be.eql('Hello Tmall');
});
});
describe('Welcome to Taobao', () => {
before(() => bu = 'Taobao');
after(() => bu = 'none');
it('should get "Hello Taobao"', () => {
mylib(bu).should.be.eql('Hello Taobao');
});
});
});同样运行一下./node_modules/.bin/_mocha就可以看到如下图:
这里before会在每个分组的所有测试用例运行前,相对的after则会在所有测试用例运行后执行,如果要以测试用例为粒度,可以使用beforeEach和afterEach,这两个钩子则会分别在该分组每个测试用例运行前和运行后执行。由于很多代码都需要模拟环境,可以再这些before或beforeEach做这些准备工作,然后在after或afterEach里做回收操作。
这里很显然代码都是同步的,但很多情况下我们的代码都是异步执行的,那么异步的代码要怎么测试呢?
比如这里index.js的代码变成了一段异步代码:
'use strict';
module.exports = (bu, callback) => process.nextTick(() => callback(`Hello ${bu}`));由于源代码变成异步,所以测试用例就得做改造:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', done => {
mylib('Tmall', rst => {
rst.should.be.eql('Hello Tmall');
done();
});
});
});这里传入it的第二个参数的函数新增了一个done参数,当有这个参数时,这个测试用例会被认为是异步测试,只有在done()执行时,才认为测试结束。那如果done()一直没有执行呢?Mocha会触发自己的超时机制,超过一定时间(默认是2s,时长可以通过--timeout参数设置)就会自动终止测试,并以测试失败处理。
当然,before、beforeEach、after、afterEach这些钩子,同样支持异步,使用方式和it一样,在传入的函数第一个参数加上done,然后在执行完成后执行即可。
平常我们直接写回调会感觉自己很low,也容易出现回调金字塔,我们可以使用Promise来做异步控制,那么对于Promise控制下的异步代码,我们要怎么测试呢?
首先把源码做点改造,返回一个Promise对象:
'use strict';
module.exports = bu => new Promise(resolve => resolve(`Hello ${bu}`));当然,如果是co党也可以直接使用co包裹:
'use strict';
const co = require('co');
module.exports = co.wrap(function* (bu) {
return `Hello ${bu}`;
});对应的修改测试用例如下:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Hello Tmall');
});
});Should.js在8.x.x版本自带了Promise支持,可以直接使用fullfilled()、rejected()、fullfilledWith()、rejectedWith()等等一系列API测试Promise对象。
注意:使用should测试Promise对象时,请一定要return,一定要return,一定要return,否则断言将无效
有时候,我们可能并不只是某个测试用例需要异步,而是整个测试过程都需要异步执行。比如测试Gulp插件的一个方案就是,首先运行Gulp任务,完成后测试生成的文件是否和预期的一致。那么如何异步执行整个测试过程呢?
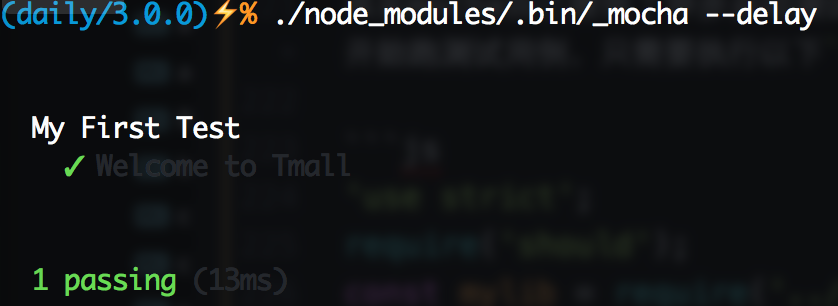
其实Mocha提供了异步启动测试,只需要在启动Mocha的命令后加上--delay参数,Mocha就会以异步方式启动。这种情况下我们需要告诉Mocha什么时候开始跑测试用例,只需要执行run()方法即可。把刚才的test/test.js修改成下面这样:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Hello Tmall');
});
});
run();
}, 1000);直接执行./node_modules/.bin/_mocha就会发生下面这样的杯具:
那么加上--delay试试:
熟悉的绿色又回来了!
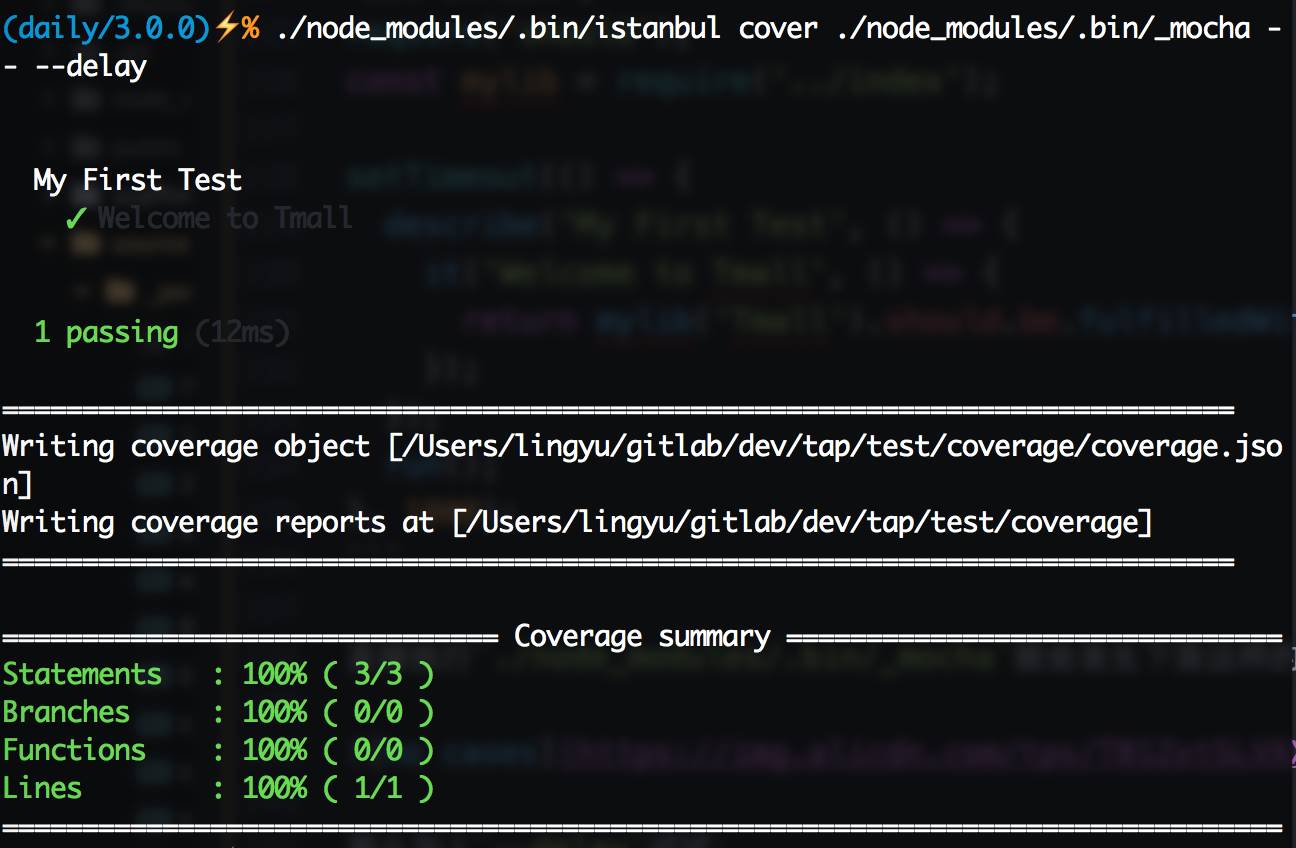
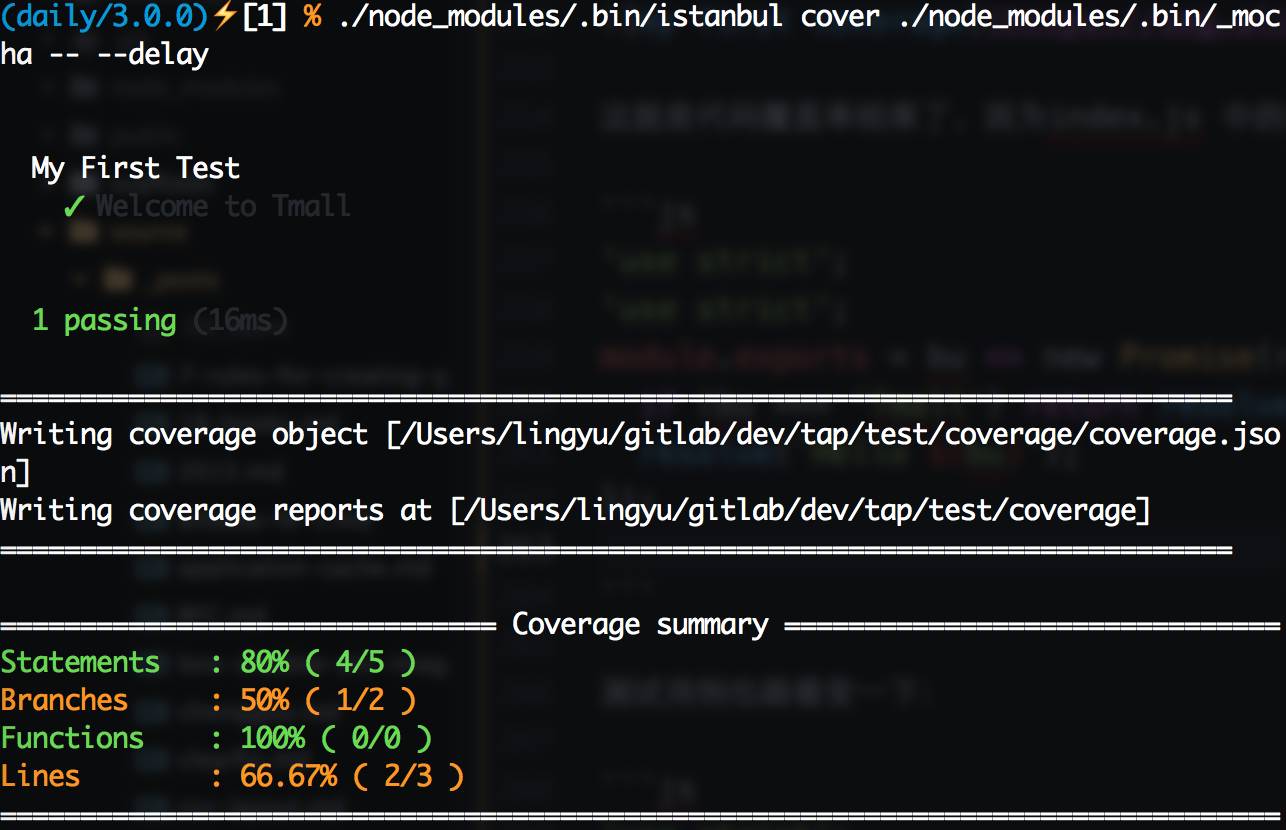
单元测试玩得差不多了,可以开始试试代码覆盖率了。首先需要安装代码覆盖率工具istanbul:npm install --save-dev istanbul,istanbul同样有命令行工具,在./node_modules/.bin/istanbul可以寻觅到它的身影。Node.js端做代码覆盖率测试很简单,只需要用istanbul启动Mocha即可,比如上面那个测试用例,运行./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,可以看到下图:
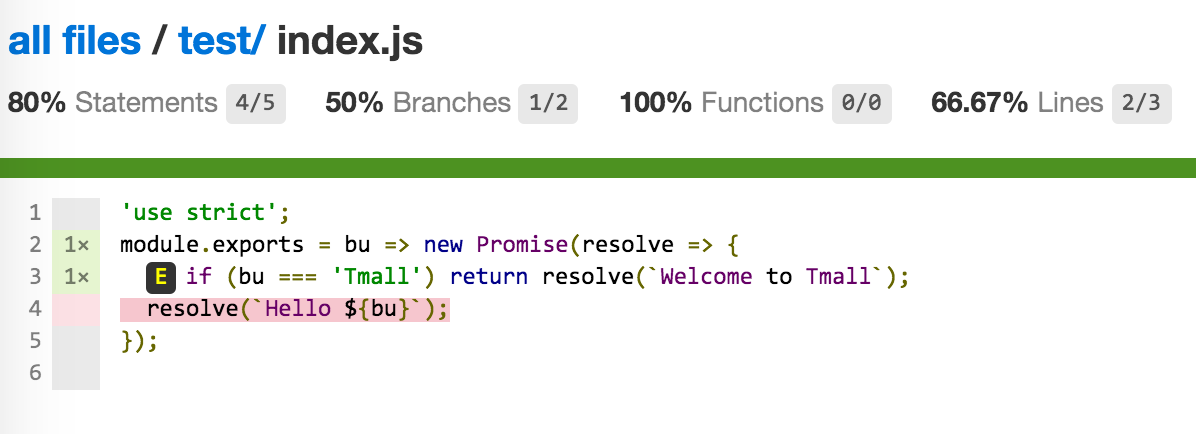
这就是代码覆盖率结果了,因为index.js中的代码比较简单,所以直接就100%了,那么修改一下源码,加个if吧:
'use strict';
module.exports = bu => new Promise(resolve => {
if (bu === 'Tmall') return resolve(`Welcome to Tmall`);
resolve(`Hello ${bu}`);
});测试用例也跟着变一下:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Welcome to Tmall');
});
});
run();
}, 1000);换了姿势,我们再来一次./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,可以得到下图:
当使用istanbul运行Mocha时,istanbul命令自己的参数放在
--之前,需要传递给Mocha的参数放在--之后
如预期所想,覆盖率不再是100%了,这时候我想看看哪些代码被运行了,哪些没有,怎么办呢?
运行完成后,项目下会多出一个coverage文件夹,这里就是放代码覆盖率结果的地方,它的结构大致如下:
.
├── coverage.json
├── lcov-report
│ ├── base.css
│ ├── index.html
│ ├── prettify.css
│ ├── prettify.js
│ ├── sort-arrow-sprite.png
│ ├── sorter.js
│ └── test
│ ├── index.html
│ └── index.js.html
└── lcov.info
这里open coverage/lcov-report/index.html可以看到文件目录,点击对应的文件进入到文件详情,可以看到index.js的覆盖率如图所示:
这里有四个指标,通过这些指标,可以量化代码覆盖情况:
下面代码部分,没有被执行过得代码会被标红,这些标红的代码往往是bug滋生的土壤,我们要尽可能消除这些红色。为此我们添加一个测试用例:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Welcome to Tmall');
});
it('Hello Taobao', () => {
return mylib('Taobao').should.be.fulfilledWith('Hello Taobao');
});
});
run();
}, 1000);再来一次./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,重新打开覆盖率页面,可以看到红色已经消失了,覆盖率100%。目标完成,可以睡个安稳觉了
好了,一个简单的Node.js测试算是做完了,这些测试任务都可以集中写到package.json的scripts字段中,比如:
{
"scripts": {
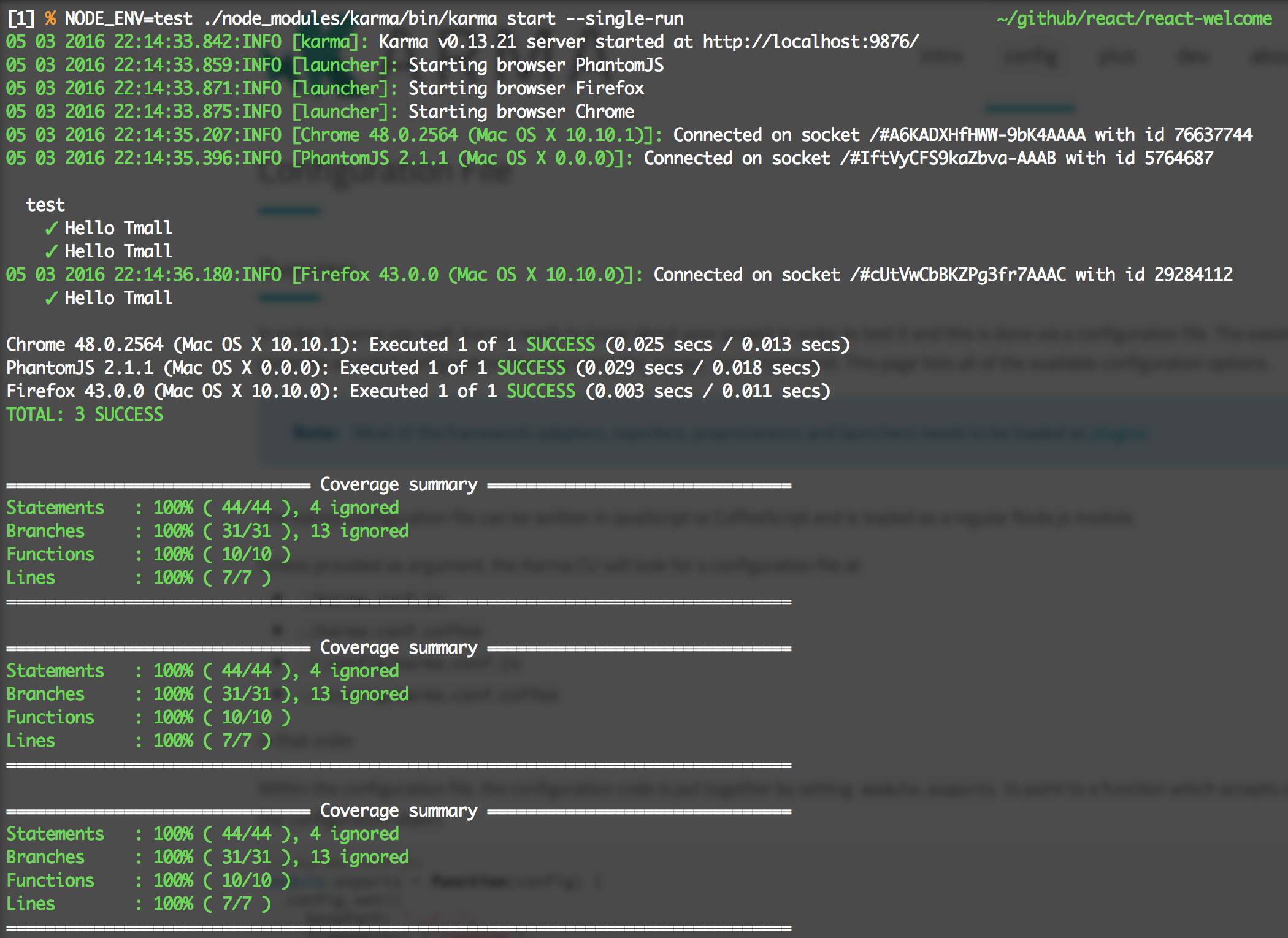
"test": "NODE_ENV=test ./node_modules/.bin/_mocha --require should",
"cov": "NODE_ENV=test ./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay"
},
}这样直接运行npm run test就可以跑单元测试,运行npm run cov就可以跑代码覆盖率测试了,方便快捷
通常我们的项目都会有很多文件,比较推荐的方法是对每个文件单独去做测试。比如代码在./lib/下,那么./lib/文件夹下的每个文件都应该对应一个./test/文件夹下的文件名_spec.js的测试文件
为什么要这样呢?不能直接运行index.js入口文件做测试吗?
直接从入口文件来测其实是黑盒测试,我们并不知道代码内部运行情况,只是看某个特定的输入能否得到期望的输出。这通常可以覆盖到一些主要场景,但是在代码内部的一些边缘场景,就很难直接通过从入口输入特定的数据来解决了。比如代码里需要发送一个请求,入口只是传入一个url,url本身正确与否只是一个方面,当时的网络状况和服务器状况是无法预知的。传入相同的url,可能由于服务器挂了,也可能因为网络抖动,导致请求失败而抛出错误,如果这个错误没有得到处理,很可能导致故障。因此我们需要把黑盒打开,对其中的每个小块做白盒测试。
当然,并不是所有的模块测起来都这么轻松,前端用Node.js常干的事情就是写构建插件和自动化工具,典型的就是Gulp插件和命令行工具,那么这俩种特定的场景要怎么测试呢?
现在前端构建使用最多的就是Gulp了,它简明的API、流式构建理念、以及在内存中操作的性能,让它备受追捧。虽然现在有像webpack这样的后起之秀,但Gulp依旧凭借着其繁荣的生态圈担当着前端构建的绝对主力。目前天猫前端就是使用Gulp作为代码构建工具。
用了Gulp作为构建工具,也就免不了要开发Gulp插件来满足业务定制化的构建需求,构建过程本质上其实是对源代码进行修改,如果修改过程中出现bug很可能直接导致线上故障。因此针对Gulp插件,尤其是会修改源代码的Gulp插件一定要做仔细的测试来保证质量。
比如这里有个煎蛋的Gulp插件,功能就是往所有js代码前加一句注释// 天猫前端招人,有意向的请发送简历至[email protected],Gulp插件的代码大概就是这样:
'use strict';
const _ = require('lodash');
const through = require('through2');
const PluginError = require('gulp-util').PluginError;
const DEFAULT_CONFIG = {};
module.exports = config => {
config = _.defaults(config || {}, DEFAULT_CONFIG);
return through.obj((file, encoding, callback) => {
if (file.isStream()) return callback(new PluginError('gulp-welcome-to-tmall', `Stream is not supported`));
file.contents = new Buffer(`// 天猫前端招人,有意向的请发送简历至[email protected]\n${file.contents.toString()}`);
callback(null, file);
});
};对于这么一段代码,怎么做测试呢?
一种方式就是直接伪造一个文件传入,Gulp内部实际上是通过vinyl-fs从操作系统读取文件并做成虚拟文件对象,然后将这个虚拟文件对象交由through2创造的Transform来改写流中的内容,而外层任务之间通过orchestrator控制,保证执行顺序(如果不了解可以看看这篇翻译文章Gulp思维——Gulp高级技巧)。当然一个插件不需要关心Gulp的任务管理机制,只需要关心传入一个vinyl对象能否正确处理。因此只需要伪造一个虚拟文件对象传给我们的Gulp插件就可以了。
首先设计测试用例,考虑两个主要场景:
// 天猫前端招人,有意向的请发送简历至[email protected]的头对于第一个测试用例,我们需要创建一个流格式的vinyl对象。而对于各第二个测试用例,我们需要创建一个Buffer格式的vinyl对象。
当然,首先我们需要一个被加工的源文件,放到test/src/testfile.js下吧:
'use strict';
console.log('hello world');这个源文件非常简单,接下来的任务就是把它分别封装成流格式的vinyl对象和Buffer格式的vinyl对象。
构建一个Buffer格式的虚拟文件对象可以用vinyl-fs读取操作系统里的文件生成vinyl对象,Gulp内部也是使用它,默认使用Buffer:
'use strict';
require('should');
const path = require('path');
const vfs = require('vinyl-fs');
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
vfs.src(path.join(__dirname, 'src', 'testfile.js'))
.pipe(welcome())
.on('data', function(vf) {
vf.contents.toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至[email protected]\n'use strict';\nconsole.log('hello world');\n`);
done();
});
});
});这样测了Buffer格式后算是完成了主要功能的测试,那么要如何测试流格式呢?
方案一和上面一样直接使用vinyl-fs,增加一个参数buffer: false即可:
把代码修改成这样:
'use strict';
require('should');
const path = require('path');
const vfs = require('vinyl-fs');
const PluginError = require('gulp-util').PluginError;
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
// blabla
});
it('should throw PluginError when stream', done => {
vfs.src(path.join(__dirname, 'src', 'testfile.js'), {
buffer: false
})
.pipe(welcome())
.on('error', e => {
e.should.be.instanceOf(PluginError);
done();
});
});
});这样vinyl-fs直接从文件系统读取文件并生成流格式的vinyl对象。
如果内容并不来自于文件系统,而是来源于一个已经存在的可读流,要怎么把它封装成一个流格式的vinyl对象呢?
这样的需求可以借助vinyl-source-stream:
'use strict';
require('should');
const fs = require('fs');
const path = require('path');
const source = require('vinyl-source-stream');
const vfs = require('vinyl-fs');
const PluginError = require('gulp-util').PluginError;
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
// blabla
});
it('should throw PluginError when stream', done => {
fs.createReadStream(path.join(__dirname, 'src', 'testfile.js'))
.pipe(source())
.pipe(welcome())
.on('error', e => {
e.should.be.instanceOf(PluginError);
done();
});
});
});这里首先通过fs.createReadStream创建了一个可读流,然后通过vinyl-source-stream把这个可读流包装成流格式的vinyl对象,并交给我们的插件做处理
Gulp插件执行错误时请抛出PluginError,这样能够让gulp-plumber这样的插件进行错误管理,防止错误终止构建进程,这在gulp watch时非常有用
我们伪造的对象已经可以跑通功能测试了,但是这数据来源终究是自己伪造的,并不是用户日常的使用方式。如果采用最接近用户使用的方式来做测试,测试结果才更加可靠和真实。那么问题来了,怎么模拟真实的Gulp环境来做Gulp插件的测试呢?
首先模拟一下我们的项目结构:
test
├── build
│ └── testfile.js
├── gulpfile.js
└── src
└── testfile.js
一个简易的项目结构,源码放在src下,通过gulpfile来指定任务,构建结果放在build下。按照我们平常使用方式在test目录下搭好架子,并且写好gulpfile.js:
'use strict';
const gulp = require('gulp');
const welcome = require('../index');
const del = require('del');
gulp.task('clean', cb => del('build', cb));
gulp.task('default', ['clean'], () => {
return gulp.src('src/**/*')
.pipe(welcome())
.pipe(gulp.dest('build'));
});接着在测试代码里来模拟Gulp运行了,这里有两种方案:
spawn或exec开子进程直接跑gulp命令,然后测试build目录下是否是想要的结果开子进程进行测试有一些坑,istanbul测试代码覆盖率时时无法跨进程的,因此开子进程测试,首先需要子进程执行命令时加上istanbul,然后还需要手动去收集覆盖率数据,当开启多个子进程时还需要自己做覆盖率结果数据合并,相当麻烦。
那么不开子进程怎么做呢?可以借助run-gulp-task这个工具来运行,其内部的机制就是首先获取gulpfile文件内容,在文件尾部加上module.exports = gulp;后require gulpfile从而获取Gulp实例,然后将Gulp实例递交给run-sequence调用内部未开放的APIgulp.run来运行。
我们采用不开子进程的方式,把运行Gulp的过程放在before钩子中,测试代码变成下面这样:
'use strict';
require('should');
const path = require('path');
const run = require('run-gulp-task');
const CWD = process.cwd();
const fs = require('fs');
describe('welcome to Tmall', () => {
before(done => {
process.chdir(__dirname);
run('default', path.join(__dirname, 'gulpfile.js'))
.catch(e => e)
.then(e => {
process.chdir(CWD);
done(e);
});
});
it('should work', function() {
fs.readFileSync(path.join(__dirname, 'build', 'testfile.js')).toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至[email protected]\n'use strict';\nconsole.log('hello world');\n`);
});
});这样由于不需要开子进程,代码覆盖率测试也可以和普通Node.js模块一样了
当然前端写工具并不只限于Gulp插件,偶尔还会写一些辅助命令啥的,这些辅助命令直接在终端上运行,结果也会直接展示在终端上。比如一个简单的使用commander实现的命令行工具:
// in index.js
'use strict';
const program = require('commander');
const path = require('path');
const pkg = require(path.join(__dirname, 'package.json'));
program.version(pkg.version)
.usage('[options] <file>')
.option('-t, --test', 'Run test')
.action((file, prog) => {
if (prog.test) console.log('test');
});
module.exports = program;
// in bin/cli
#!/usr/bin/env node
'use strict';
const program = require('../index.js');
program.parse(process.argv);
!program.args[0] && program.help();
// in package.json
{
"bin": {
"cli-test": "./bin/cli"
}
}要测试命令行工具,自然要模拟用户输入命令,这一次依旧选择不开子进程,直接用伪造一个process.argv交给program.parse即可。命令输入了问题也来了,数据是直接console.log的,要怎么拦截呢?
这可以借助sinon来拦截console.log,而且sinon非常贴心的提供了mocha-sinon方便测试用,这样test.js大致就是这个样子:
'use strict';
require('should');
require('mocha-sinon');
const program = require('../index');
const uncolor = require('uncolor');
describe('cli-test', () => {
let rst;
beforeEach(function() {
this.sinon.stub(console, 'log', function() {
rst = arguments[0];
});
});
it('should print "test"', () => {
program.parse([
'node',
'./bin/cli',
'-t',
'file.js'
]);
return uncolor(rst).trim().should.be.eql('test');
});
});PS:由于命令行输出时经常会使用colors这样的库来添加颜色,因此在测试时记得用uncolor把这些颜色移除
Node.js相关的单元测试就扯这么多了,还有很多场景像服务器测试什么的就不扯了,因为我不会。当然前端最主要的工作还是写页面,接下来扯一扯如何对页面上的组件做测试。
对于浏览器里跑的前端代码,做测试要比Node.js模块要麻烦得多。Node.js模块纯js代码,使用V8运行在本地,测试用的各种各样的依赖和工具都能快速的安装,而前端代码不仅仅要测试js,CSS等等,更麻烦的事需要模拟各种各样的浏览器,比较常见的前端代码测试方案有下面几种:
这里以gulp为构建工具做测试,后面在React组件测试部分再介绍以webpack为构建工具做测试
前端代码依旧是js,一样可以用Mocha+Should.js来做单元测试。打开node_modules下的Mocha和Should.js,你会发现这些优秀的开源工具已经非常贴心的提供了可在浏览器中直接运行的版本:mocha/mocha.js和should/should.min.js,只需要把他们通过script标签引入即可,另外Mocha还需要引入自己的样式mocha/mocha.css
首先看一下我们的前端项目结构:
.
├── gulpfile.js
├── package.json
├── src
│ └── index.js
└── test
├── test.html
└── test.js
比如这里源码src/index.js就是定义一个全局函数:
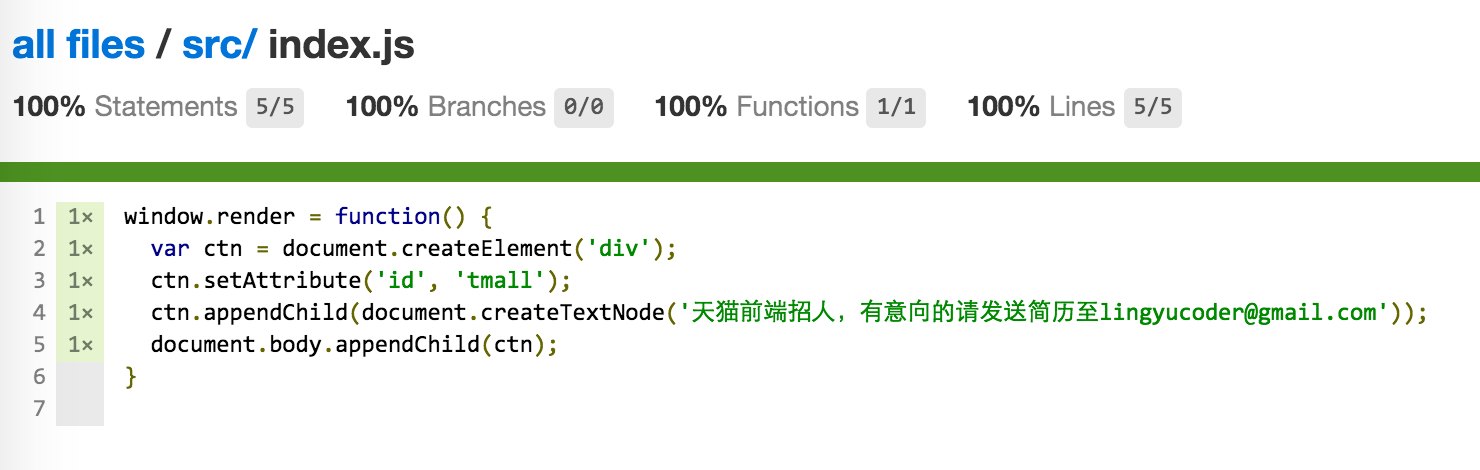
window.render = function() {
var ctn = document.createElement('div');
ctn.setAttribute('id', 'tmall');
ctn.appendChild(document.createTextNode('天猫前端招人,有意向的请发送简历至[email protected]'));
document.body.appendChild(ctn);
}而测试页面test/test.html大致上是这个样子:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="../node_modules/mocha/mocha.css"/>
<script src="../node_modules/mocha/mocha.js"></script>
<script src="../node_modules/should/should.js"></script>
</head>
<body>
<div id="mocha"></div>
<script src="../src/index.js"></script>
<script src="test.js"></script>
</body>
</html>head里引入了测试框架Mocha和断言库Should.js,测试的结果会被显示在<div id="mocha"></div>这个容器里,而test/test.js里则是我们的测试的代码。
前端页面上测试和Node.js上测试没啥太大不同,只是需要指定Mocha使用的UI,并需要手动调用mocha.run():
mocha.ui('bdd');
describe('Welcome to Tmall', function() {
before(function() {
window.render();
});
it('Hello', function() {
document.getElementById('tmall').textContent.should.be.eql('天猫前端招人,有意向的请发送简历至[email protected]');
});
});
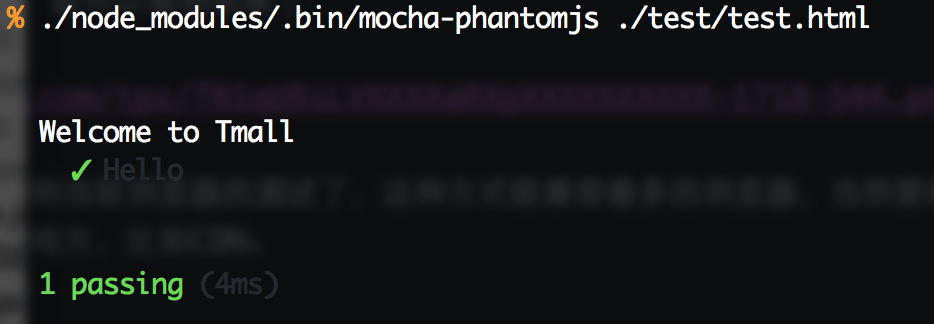
mocha.run();在浏览器里打开test/test.html页面,就可以看到效果了:
在不同的浏览器里打开这个页面,就可以看到当前浏览器的测试了。这种方式能兼容最多的浏览器,当然要跨机器之前记得把资源上传到一个测试机器都能访问到的地方,比如CDN。
测试页面有了,那么来试试接入PhantomJS吧
PhantomJS是一个模拟的浏览器,它能执行js,甚至还有webkit渲染引擎,只是没有浏览器的界面上渲染结果罢了。我们可以使用它做很多事情,比如对网页进行截图,写爬虫爬取异步渲染的页面,以及接下来要介绍的——对页面做测试。
当然,这里我们不是直接使用PhantomJS,而是使用mocha-phantomjs来做测试。npm install --save-dev mocha-phantomjs安装完成后,就可以运行命令./node_modules/.bin/mocha-phantomjs ./test/test.html来对上面那个test/test.html的测试了:
单元测试没问题了,接下来就是代码覆盖率测试
首先第一步,改写我们的gulpfile.js:
'use strict';
const gulp = require('gulp');
const istanbul = require('gulp-istanbul');
gulp.task('test', function() {
return gulp.src(['src/**/*.js'])
.pipe(istanbul({
coverageVariable: '__coverage__'
}))
.pipe(gulp.dest('build-test'));
});这里把覆盖率结果保存到__coverage__里面,把打完点的代码放到build-test目录下,比如刚才的src/index.js的代码,在运行gulp test后,会生成build-test/index.js,内容大致是这个样子:
var __cov_WzFiasMcIh_mBvAjOuQiQg = (Function('return this'))();
if (!__cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__) { __cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__ = {}; }
__cov_WzFiasMcIh_mBvAjOuQiQg = __cov_WzFiasMcIh_mBvAjOuQiQg.__coverage__;
if (!(__cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js'])) {
__cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js'] = {"path":"/Users/lingyu/gitlab/dev/mui/test-page/src/index.js","s":{"1":0,"2":0,"3":0,"4":0,"5":0},"b":{},"f":{"1":0},"fnMap":{"1":{"name":"(anonymous_1)","line":1,"loc":{"start":{"line":1,"column":16},"end":{"line":1,"column":27}}}},"statementMap":{"1":{"start":{"line":1,"column":0},"end":{"line":6,"column":1}},"2":{"start":{"line":2,"column":2},"end":{"line":2,"column":42}},"3":{"start":{"line":3,"column":2},"end":{"line":3,"column":34}},"4":{"start":{"line":4,"column":2},"end":{"line":4,"column":85}},"5":{"start":{"line":5,"column":2},"end":{"line":5,"column":33}}},"branchMap":{}};
}
__cov_WzFiasMcIh_mBvAjOuQiQg = __cov_WzFiasMcIh_mBvAjOuQiQg['/Users/lingyu/gitlab/dev/mui/test-page/src/index.js'];
__cov_WzFiasMcIh_mBvAjOuQiQg.s['1']++;window.render=function(){__cov_WzFiasMcIh_mBvAjOuQiQg.f['1']++;__cov_WzFiasMcIh_mBvAjOuQiQg.s['2']++;var ctn=document.createElement('div');__cov_WzFiasMcIh_mBvAjOuQiQg.s['3']++;ctn.setAttribute('id','tmall');__cov_WzFiasMcIh_mBvAjOuQiQg.s['4']++;ctn.appendChild(document.createTextNode('天猫前端招人\uFF0C有意向的请发送简历至[email protected]'));__cov_WzFiasMcIh_mBvAjOuQiQg.s['5']++;document.body.appendChild(ctn);};这都什么鬼!不管了,反正运行它就好。把test/test.html里面引入的代码从src/index.js修改为build-test/index.js,保证页面运行时使用的是编译后的代码。
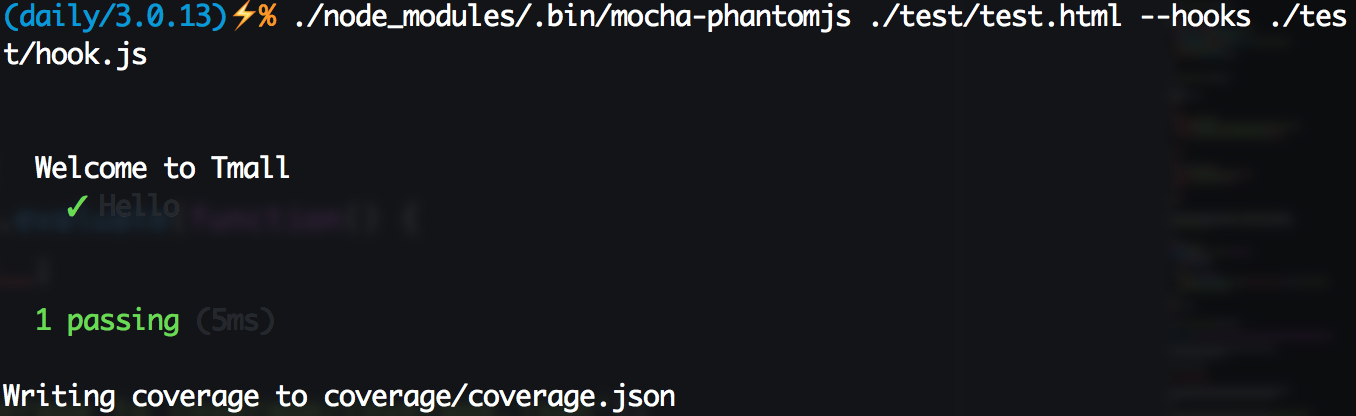
运行数据会存放到变量__coverage__里,但是我们还需要一段钩子代码在单元测试结束后获取这个变量里的内容。把钩子代码放在test/hook.js下,里面内容这样写:
'use strict';
var fs = require('fs');
module.exports = {
afterEnd: function(runner) {
var coverage = runner.page.evaluate(function() {
return window.__coverage__;
});
if (coverage) {
console.log('Writing coverage to coverage/coverage.json');
fs.write('coverage/coverage.json', JSON.stringify(coverage), 'w');
} else {
console.log('No coverage data generated');
}
}
};这样准备工作工作就大功告成了,执行命令./node_modules/.bin/mocha-phantomjs ./test/test.html --hooks ./test/hook.js,可以看到如下图结果,同时覆盖率结果被写入到coverage/coverage.json里面了。
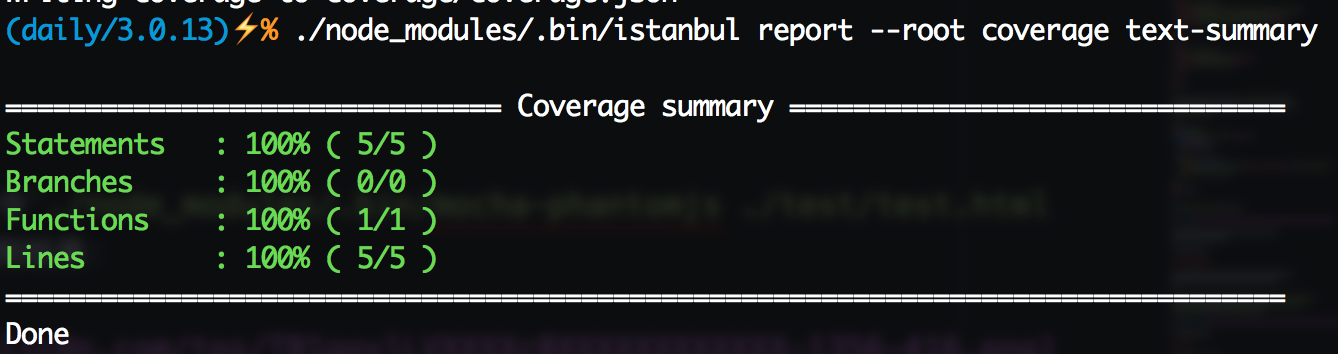
有了结果覆盖率结果就可以生成覆盖率页面了,首先看看覆盖率概况吧。执行命令./node_modules/.bin/istanbul report --root coverage text-summary,可以看到下图:
还是原来的配方,还是想熟悉的味道。接下来运行./node_modules/.bin/istanbul report --root coverage lcov生成覆盖率页面,执行完后open coverage/lcov-report/index.html,点击进入到src/index.js:
一颗赛艇!这样我们对前端代码就能做覆盖率测试了
Karma是一个测试集成框架,可以方便地以插件的形式集成测试框架、测试环境、覆盖率工具等等。Karma已经有了一套相当完善的插件体系,这里尝试在PhantomJS、Chrome、FireFox下做测试,首先需要使用npm安装一些依赖:
安装完成后,就可以开启我们的Karma之旅了。还是之前的那个项目,我们把该清除的清除,只留下源文件和而是文件,并增加一个karma.conf.js文件:
.
├── karma.conf.js
├── package.json
├── src
│ └── index.js
└── test
└── test.js
karma.conf.js是Karma框架的配置文件,在这个例子里,它大概是这个样子:
'use strict';
module.exports = function(config) {
config.set({
frameworks: ['mocha'],
files: [
'./node_modules/should/should.js',
'src/**/*.js',
'test/**/*.js'
],
preprocessors: {
'src/**/*.js': ['coverage']
},
plugins: ['karma-mocha', 'karma-phantomjs-launcher', 'karma-chrome-launcher', 'karma-firefox-launcher', 'karma-coverage', 'karma-spec-reporter'],
browsers: ['PhantomJS', 'Firefox', 'Chrome'],
reporters: ['spec', 'coverage'],
coverageReporter: {
dir: 'coverage',
reporters: [{
type: 'json',
subdir: '.',
file: 'coverage.json',
}, {
type: 'lcov',
subdir: '.'
}, {
type: 'text-summary'
}]
}
});
};这些配置都是什么意思呢?这里挨个说明一下:
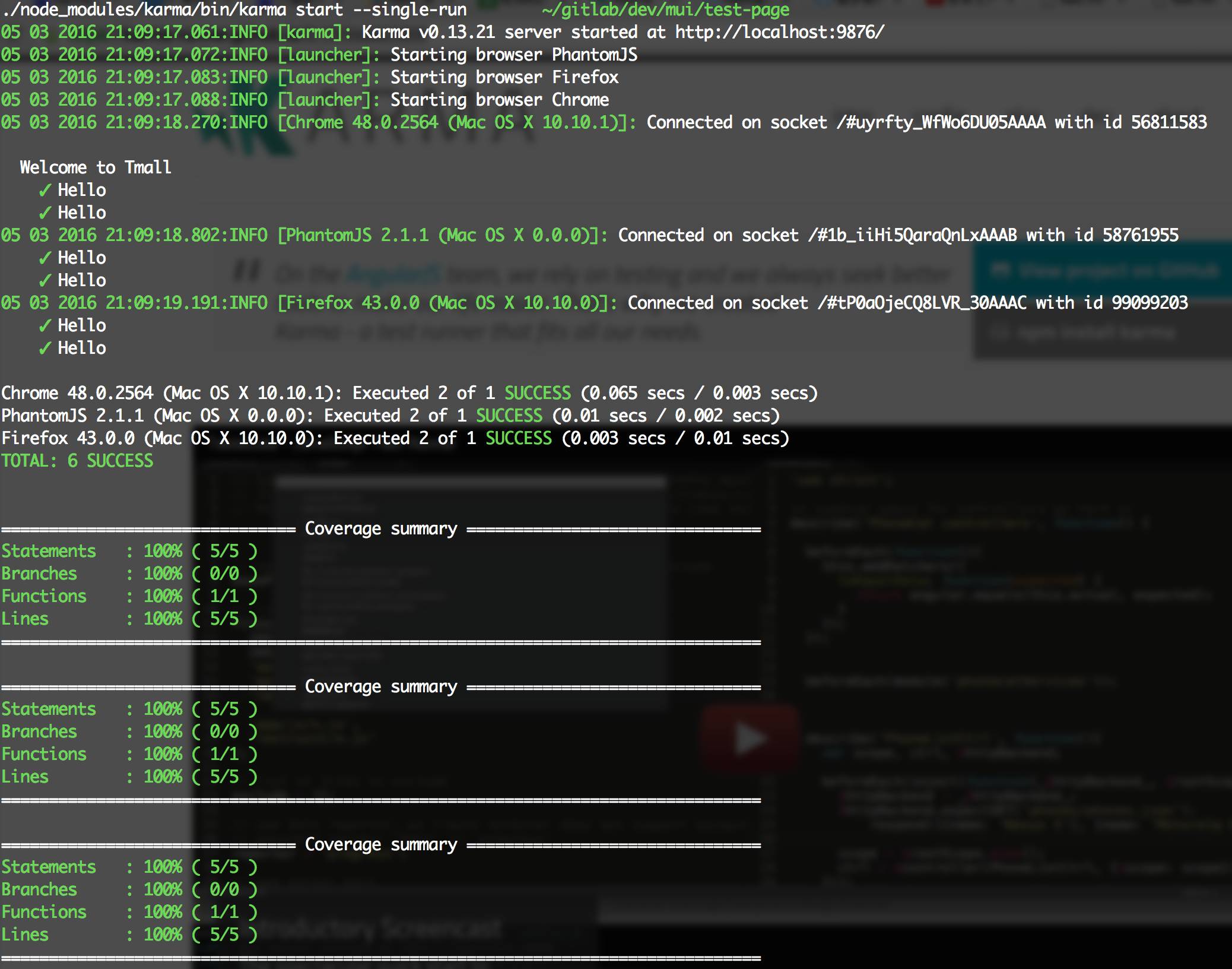
好了,配置完成,来试试吧,运行./node_modules/karma/bin/karma start --single-run,可以看到如下输出:
可以看到,Karma首先会在9876端口开启一个本地服务,然后分别启动PhantomJS、FireFox、Chrome去加载这个页面,收集到测试结果信息之后分别输出,这样跨浏览器测试就解决啦。如果要新增浏览器就安装对应的浏览器插件,然后在browsers里指定一下即可,非常灵活方便。
那如果我的mac电脑上没有IE,又想测IE,怎么办呢?可以直接运行./node_modules/karma/bin/karma start启动本地服务器,然后使用其他机器开对应浏览器直接访问本机的9876端口(当然这个端口是可配置的)即可,同样移动端的测试也可以采用这个方法。这个方案兼顾了前两个方案的优点,弥补了其不足,是目前看到最优秀的前端代码测试方案了
去年React旋风一般席卷全球,当然天猫也在技术上紧跟时代脚步。天猫商家端业务已经全面切入React,形成了React组件体系,几乎所有新业务都采用React开发,而老业务也在不断向React迁移。React大红大紫,这里单独拉出来讲一讲React+webpack的打包方案如何进行测试
这里只聊React Web,不聊React Native
事实上天猫目前并未采用webpack打包,而是Gulp+Babel编译React CommonJS代码成AMD模块使用,这是为了能够在新老业务使用上更加灵活,当然也有部分业务采用webpack打包并上线
这里创建一个React组件,目录结构大致这样(这里略过CSS相关部分,只要跑通了,集成CSS像PostCSS、Less都没啥问题):
.
├── demo
├── karma.conf.js
├── package.json
├── src
│ └── index.jsx
├── test
│ └── index_spec.jsx
├── webpack.dev.js
└── webpack.pub.js
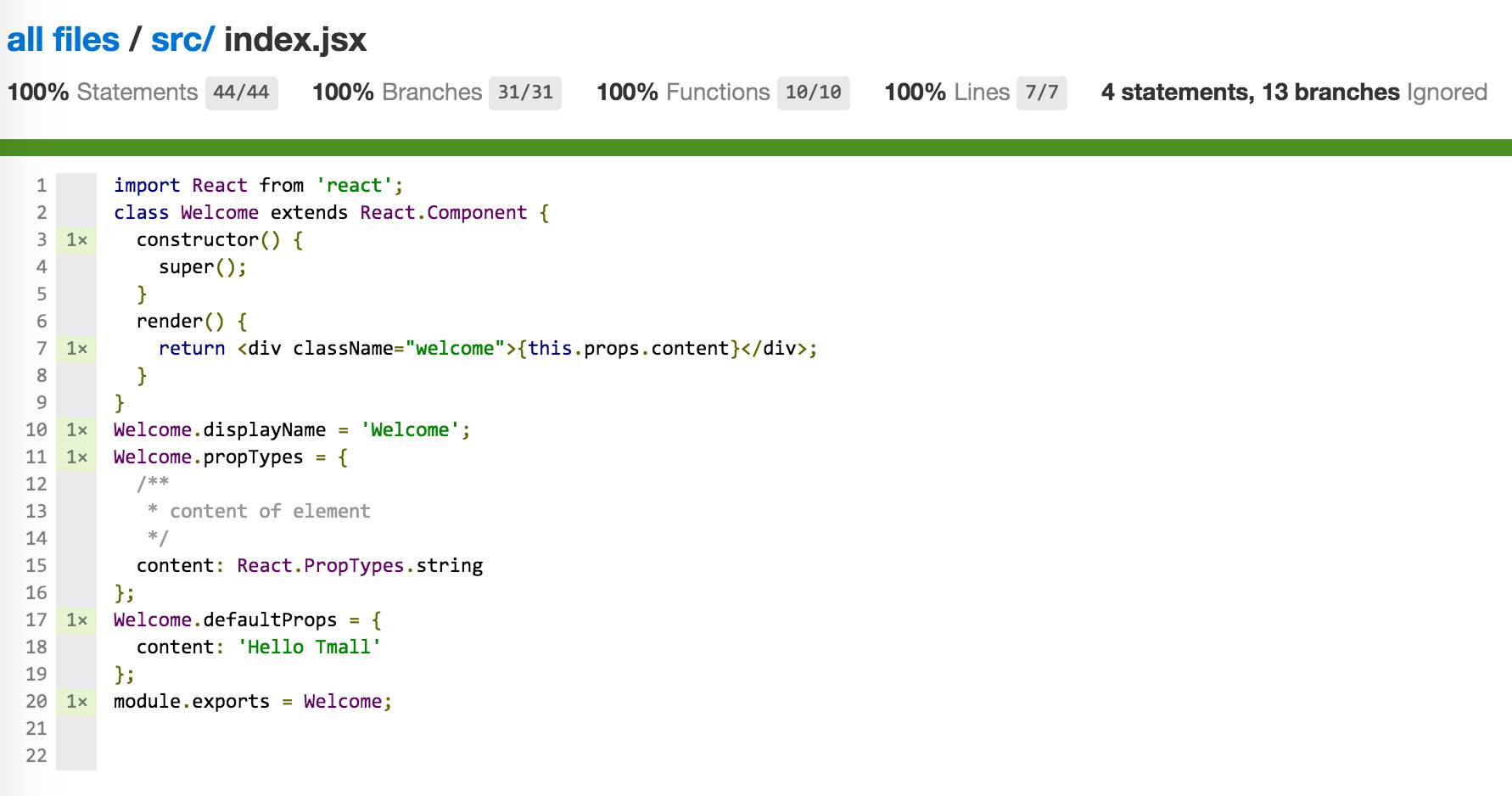
React组件源码src/index.jsx大概是这个样子:
import React from 'react';
class Welcome extends React.Component {
constructor() {
super();
}
render() {
return <div>{this.props.content}</div>;
}
}
Welcome.displayName = 'Welcome';
Welcome.propTypes = {
/**
* content of element
*/
content: React.PropTypes.string
};
Welcome.defaultProps = {
content: 'Hello Tmall'
};
module.exports = Welcome;那么对应的test/index_spec.jsx则大概是这个样子:
import 'should';
import Welcome from '../src/index.jsx';
import ReactDOM from 'react-dom';
import React from 'react';
import TestUtils from 'react-addons-test-utils';
describe('test', function() {
const container = document.createElement('div');
document.body.appendChild(container);
afterEach(() => {
ReactDOM.unmountComponentAtNode(container);
});
it('Hello Tmall', function() {
let cp = ReactDOM.render(<Welcome/>, container);
let welcome = TestUtils.findRenderedComponentWithType(cp, Welcome);
ReactDOM.findDOMNode(welcome).textContent.should.be.eql('Hello Tmall');
});
});由于是测试React,自然要使用React的TestUtils,这个工具库提供了不少方便查找节点和组件的方法,最重要的是它提供了模拟事件的API,这可以说是UI测试最重要的一个功能。更多关于TestUtils的使用请参考React官网,这里就不扯了...
代码有了,测试用例也有了,接下就差跑起来了。karma.conf.js肯定就和上面不一样了,首先它要多一个插件karma-webpack,因为我们的React组件是需要webpack打包的,不打包的代码压根就没法运行。另外还需要注意代码覆盖率测试也出现了变化。因为现在多了一层Babel编译,Babel编译ES6、ES7源码生成ES5代码后会产生很多polyfill代码,因此如果对build完成之后的代码做覆盖率测试会包含这些polyfill代码,这样测出来的覆盖率显然是不可靠的,这个问题可以通过isparta-loader来解决。React组件的karma.conf.js大概是这个样子:
'use strict';
const path = require('path');
module.exports = function(config) {
config.set({
frameworks: ['mocha'],
files: [
'./node_modules/phantomjs-polyfill/bind-polyfill.js',
'test/**/*_spec.jsx'
],
plugins: ['karma-webpack', 'karma-mocha',, 'karma-chrome-launcher', 'karma-firefox-launcher', 'karma-phantomjs-launcher', 'karma-coverage', 'karma-spec-reporter'],
browsers: ['PhantomJS', 'Firefox', 'Chrome'],
preprocessors: {
'test/**/*_spec.jsx': ['webpack']
},
reporters: ['spec', 'coverage'],
coverageReporter: {
dir: 'coverage',
reporters: [{
type: 'json',
subdir: '.',
file: 'coverage.json',
}, {
type: 'lcov',
subdir: '.'
}, {
type: 'text-summary'
}]
},
webpack: {
module: {
loaders: [{
test: /\.jsx?/,
loaders: ['babel']
}],
preLoaders: [{
test: /\.jsx?$/,
include: [path.resolve('src/')],
loader: 'isparta'
}]
}
},
webpackMiddleware: {
noInfo: true
}
});
};这里相对于之前的karma.conf.js,主要有以下几点区别:
这样配置基本上就完成了,跑一把./node_modules/karma/bin/karma start --single-run:
很好,结果符合预期。open coverage/lcov-report/index.html打开覆盖率页面:
鹅妹子音!!!直接对jsx代码做的覆盖率测试!这样React组件的测试大体上就完工了
前端的代码测试主要难度是如何模拟各种各样的浏览器环境,Karma给我们提供了很好地方式,对于本地有的浏览器能自动打开并测试,本地没有的浏览器则提供直接访问的页面。前端尤其是移动端浏览器种类繁多,很难做到完美,但我们可以通过这种方式实现主流浏览器的覆盖,保证每次上线大多数用户没有问题。
测试结果有了,接下来就是把这些测试结果接入到持续集成之中。持续集成是一种非常优秀的多人开发实践,通过代码push触发钩子,实现自动运行编译、测试等工作。接入持续集成后,我们的每一次push代码,每个Merge Request都会生成对应的测试结果,项目的其他成员可以很清楚地了解到新代码是否影响了现有的功能,在接入自动告警后,可以在代码提交阶段就快速发现错误,提升开发迭代效率。
持续集成会在每次集成时提供一个几乎空白的虚拟机器,并拷贝用户提交的代码到机器本地,通过读取用户项目下的持续集成配置,自动化的安装环境和依赖,编译和测试完成后生成报告,在一段时间之后释放虚拟机器资源。
开源比较出名的持续集成服务当属Travis,而代码覆盖率则通过Coveralls,只要有GitHub账户,就可以很轻松的接入Travis和Coveralls,在网站上勾选了需要持续集成的项目以后,每次代码push就会触发自动化测试。这两个网站在跑完测试以后,会自动生成测试结果的小图片
Travis会读取项目下的travis.yml文件,一个简单的例子:
language: node_js
node_js:
- "stable"
- "4.0.0"
- "5.0.0"
script: "npm run test"
after_script: "npm install [email protected] && cat ./coverage/lcov.info | coveralls"language定义了运行环境的语言,而对应的node_js可以定义需要在哪几个Node.js版本做测试,比如这里的定义,代表着会分别在最新稳定版、4.0.0、5.0.0版本的Node.js环境下做测试
而script则是测试利用的命令,一般情况下,都应该把自己这个项目开发所需要的命令都写在package.json的scripts里面,比如我们的测试方法./node_modules/karma/bin/karma start --single-run就应当这样写到scripts里:
{
"scripts": {
"test": "./node_modules/karma/bin/karma start --single-run"
}
}而after_script则是在测试完成之后运行的命令,这里需要上传覆盖率结果到coveralls,只需要安装coveralls库,然后获取lcov.info上传给Coveralls即可
更多配置请参照Travis官网介绍
这样配置后,每次push的结果都可以上Travis和Coveralls看构建和代码覆盖率结果了
项目接入持续集成在多人开发同一个仓库时候能起到很大的用途,每次push都能自动触发测试,测试没过会发生告警。如果需求采用Issues+Merge Request来管理,每个需求一个Issue+一个分支,开发完成后提交Merge Request,由项目Owner负责合并,项目质量将更有保障
这里只是前端测试相关知识的一小部分,还有非常多的内容可以深入挖掘,而测试也仅仅是前端流程自动化的一部分。在前端技术快速发展的今天,前端项目不再像当年的刀耕火种一般,越来越多的软件工程经验被集成到前端项目中,前端项目正向工程化、流程化、自动化方向高速奔跑。还有更多优秀的提升开发效率、保证开发质量的自动化方案亟待我们挖掘。
详见 另一个角度看前后端分离 @不四 2014.10 @QCon 上海
five-lines (深入浅出 node 命令行工具) @不四 2014.06 @2014 杭JS
详见 Native和Web融合 @鬼道 2015.04 @QCon北京2015
“Native 和 Web 融合”已经在阿里生根发芽。以前提得较多的是 Hybrid,Hybrid 是融合的一面,更多是指 Web 融合 Native 能力,更窄一点指的就是 Hybrid API(类 Phonegap);另一面是 Native 融合 Web 的能力,尤其是 Web 的发布能力和大规模协作的能力。作者尝试理清 Native 和 Web 的亮点和痛点,借鉴对方亮点解决自身的痛点,并给出淘系 App 在这些方面的实践。
Native 诸多亮点中,流畅体验和系统调用是最多被提及的。Native 的流畅体验体现在页面滚动和动画的流畅性,背后是更好的内存管理和更接近原生的性能;Web 痛点集中在资源首次下载、长页面内存溢出和滚动性能。Native 有丰富的系统 API 可供调用灵活度较高,Web 痛点在于 W3C 标准太慢,有限的设备访问能力,API 兼容性问题较严重。
Web 最大的亮点是发布能力,合适的缓存机制下一天更新率可超过 99%,iOS 能达到一周更新率 60%-80%,Android 同样的更新率要一个月甚至更长。iOS Hotpatch 可用于修复紧急问题,受限商店政策难以走得更远,Android 自由度会更大。Mobile Web 的协作能力底层来自 Webkit,上层有 html/js/css 控制页面的结构/行为/样式 URI 连接不同的资源,这样的机制可以被 Native 借鉴,构建 Native 的分层架构。
鬼道的新书《跨终端 Web》开始预售了。本篇是三七为本书写的推荐序,已将“跨终端 Web”的由来说得比较清楚了。提供了本书的样章 ,欢迎鉴赏。
如果本书可能对你或你的朋友有帮助,可以:
2012年底,我从云OS运营团队转岗到天猫前端团队,之前和手机硬件厂商、Mobile OS及App市场的合作经历让我重新思考前端的未来和电子商务的技术方向。除了在天猫内部实践基于移动优先(Mobile First)的设计研发外,还和infoQ合作把QConbeijing 2013的前端议题定为“跨终端Web”,于是就有了采访稿《从可编程到跨终端——QCon北京2013“跨终端的Web”专题出品人鄢学鵾专访》 ,阐述当时的认知和想法。现在“跨终端Web”已经诞生一年半了,鬼道同学把这些想法和实践都编写成书实在让人惊喜和敬佩,我有幸成为这个成就的见证人,并再次有机会和大家谈谈跨终端Web的初心和思考。
1991年诞生了World Wide Web、HTTP和HTML,1995年诞生了JavaScript、Java和PHP,1996年诞生了CSS,1998年CSS2.1正式发布,1999年CDN诞生且HTTP1.1和HTML4.01正式发布,2000年ECMA-262 3rd正式发布,2001年IE6发布。作为Web开发者和前端工程师的我们应该对这些大事件相当不陌生,但如果你仔细看看这些年份就会发现我们所使用的绝大部分技术和方案都比IE6老。在那个时期没有真正意义的前端,常见情况是美工切图,后端嵌套模板,也没有所谓的前端架构,前后端的发布机制几乎一样,那就是门户盛行的时代,Yahoo、新浪、搜狐和网易当道。
IE6是第一轮浏览器大战的胜者,垄断式的胜利直接导致Web基础设施至少10年的缓慢发展,标准的意义也就不那么明显了。其实1994年就有了W3C,但民间为了解决W3C面对浏览器厂商不给力的混乱状况于1998成立了WaSP(The Web Standards Project),其中一个创始人于2003年发表了影响力巨大的著作《Design with The Standards(网站重构)》,当然在**产生了估计作者都没有想到额外影响,那就是出现了重构工程师。2004年Firefox 1.0、Gmail和Google Sugguest发布,2005年AJAX横空出世和Google Maps发布,2006年jQuery和YUI发布。这些事件的到来显示出了低成本的Web在跨浏览器上巨大威力和人机交互的显著改善,导致当时互联网99%以上内容都是使用Web来呈现,所以对于当时绝大部分人而言,WWW就是互联网。巨大的需求导致Web开发的规模化和专业分工,这就是前端工程师开始出现,并大量集结于以Web业务为主的互联网公司的原因。
我们可以称这个时代为前端工程师1.0,比如在Google、Facebook、Yahoo、阿里巴巴、百度、腾讯等公司中,前端团队小有规模且以Web开发为主,此时的前端工程师们大量使用HTML、CSS、JavaScript开发基于桌面浏览器的网页和应用。这个时代的前端工程师主要具备三个方面的能力,一是跨浏览器的兼容能力,需要理解渐进增强和优雅退化的**,深入Web标准并结合环境数据制定GBS (Graded Browser Support 浏览器分级标准);二是富交互Web的开发能力,能够基于甚至开发JavaScript库去实现人和机器的复杂互动;三是性能优化能力,实践表明前端占Web 性能80%,类似CDN和按需加载等各种性能优化方案深度地影响了前端架构和发布机制。
虽然今日市面上大部分前端工程师招聘条件还是基于前端工程师1.0的,但我们的环境自2007年iPhone发布起就在悄然却快速地变革,我们可能是家里唯一使用电脑的那个人,而手机在吃饭、走路、约会、上厕所等等时都已经成为不可或缺的陪伴。当我还在云OS做运营时便学到了一个令人震惊的发现:人类发展五千年到现在的最大共同点可能是每人都有移动智能设备。人们已经处于各种各样碎片化的智能移动设备上,这些设备有触摸屏、相机、麦克风、陀螺仪、加速计等等特性使得人同机器交互的方式发生了巨大的革命,更重要的是它们都和网络连接没有了离线状态。于是,当一个人在大街上看到奇闻异事随手用手机拍下来并发到微博上,TA的朋友可能在手机、平板电脑或普通电脑的微博上看到并转发,也可能被TA的朋友转到微信或IM等等,TA朋友的朋友同样可能在手机、平板电脑或普通电脑的另一种软件上看到这个信息,更甚至信息被电视媒体或平面媒体发现并造成更大范围的传播,更多TA不认识的电视或平面媒体通过扫描报道时的二维码又找到TA的微博,这一切可能在瞬间完成。这个小场景告诉我们人和信息是在智能终端(Phone、Pad、Desktop、TV等设备)、软件终端(浏览器、SNS、IM等应用)和传统终端(电视、广播、平面等媒体)间交叉流动的,这是一个去中心的网状结构,也是互联网的本质特性,所以跨终端不仅仅是跨越设备(device)更是跨越人机交互的场景入口(end)。
面对这种终端碎片化的潮流,前端工程师怎么办?解决方案就是基于最重要的前端开发**渐进增强和优雅退化得出的移动优先:一是毫无疑问绝大部分用户已经或正在成为智能设备用户,我们要为80%的目标用户服务;二是专注于核心业务需求,人的本性、业务本质和商业模式本质基本上不会随着终端改变而改变,所以相同业务在手机、平板、桌面和电视上呈现的本质和商业模式不会有不同,小屏幕终端是我们重新思考业务本质和核心人机交互流程的机会,其挖掘出的本质会改变其他终端;三是针对未来人机交互,现在移动设备引领人机交互的变革潮流,通过必备特性虚拟或增强现实,并逐步引入到桌面和电视等等设备中。所以,选择哪个具体技术方案,是响应式Web,还是服务端响应式Web(URL不变,通过服务端在不同设备展现不同模板),还是多个URL Web(不同的终端不同的URL),还是Hybrid应用(Native和Web混合使用,比如iOS App Store一直就是引用壳里面套个网站),还是Native应用,是依据业务本质、人性需求和人机环境趋势来综合判断的。由于Web的本质特性就是低成本跨平台但对设备先进特性支持不够,而Native应用能够充分利用硬件先进特性但受限于系统平台,导致开发者没有发布能力,所以大多数情况下,可以把跨终端Web作为默认选择。
在跨终端的时代,渐进增强和优雅退化依旧是最重要的前端开发**,但前端工程师们不能像以前一样仅仅固守在Web上,Web和客户端应用的融合已经成为必然,Web从页面(page)到应用(application)反应了人机交互革命带来新的体验趋势,客户端和动画开发成为了前端工程师的基本功。移动优先的跨终端解决方案核心是一套数据有多个高品质低成本展现方式, 这促使前后端分离成为必须,前端工程师不仅仅要关心客户端环境也要关心服务端环境,所以GBS需要升级到GTE(Graded Target Environments,分级目标环境),工程师更关注端到端的数据接口约定(比如正文中的IF就是这种**下的一种实践方案),这会彻底改变前端的开发方式、架构和发布机制,也会导致前端团队快速膨胀直到前后端比率趋于一致。这是一个巨大的挑战,也是一个前所未有的机会,更是时势的要求。我把这个时代叫着前端工程师2.0。
这篇推荐序被我拖延了很久很久,结尾之时恰逢鬼道同学入职天猫一周年,就拿老乔的话来zhuangbility一下:“你如果出色地完成了某件事,那你应该再做一些其他的精彩事儿。不要在前一件事上徘徊太久,想想接下来该做什么。”这应该是最好的礼物之一。
三七
2014.4.8
详见 从实验出发的移动端性能优化 @由校 2014.08.12 @Velocity
Facebook在3.26 F8大会上开源了React Native,本文是对React Native的技术背景、规划和风险的概述。看得比较仓促,问题处请直接回复。
组里的同学于4.2完成了天猫iPad客户端“猜你喜欢”业务的React Native改造(4月中发版)。本周开始陆续放出性能/体验、稳定性、扩展性、开发效率等评估结果。
图1 - 4.2已完成React Native改造的业务
What we really want is the _user experience_ of the _native mobile_ platforms, combined with the _developer experience_ we have when building with _React_ on the web.
摘自3.26 React Native的发布稿,加粗的关键字传达了React Native的设计理念:_既拥有Native的用户体验、又保留React的开发效率_。这个理念似乎迎合了业界普片存在的痛点,开源不到1周github star破万,目前是11000+。
图1 - React Native github
React Native项目成员Tom Occhino发表的React Native: Bringing modern web techniques to mobile(墙外)详细描述了React Native的设计理念。Occhino认为尽管Native开发成本更高,但现阶段Native仍然是必须的,因为Web的用户体验仍无法超越Native:
Occhino没提到的还有Native能实现更丰富细腻的动画效果,归根结底是现阶段Native具有更好的人机交互体验。笔者认为这些例子是有说服力的,也是React Native出现的直接原因。
图2 - Occhino在F8分享了React Native(Keynote)
“Learn once, write anywhere”同样出自Occhino的文章。因为不同Native平台上的用户体验是不同的,React Native不强求一份原生代码支持多个平台,所以不提“Write once, run anywhere”(Java),提出了“Learn once, write anywhere”。
图3 - “Learn once, write anywhere”
这张图是笔者根据理解画的一张示意图,自下而上依次是:
前文多处提到的React是Facebook 2013年开源的Web开发框架,笔者在翻阅其2013年发布稿时,发现这么一段:
图4 - 摘自React发布稿(2013)
React本身也是个庞大的话题不再展开,详见React wiki。
笔者认为“Write once, run anywhere”对提升效率仍然是必要的,并且和“Learn once, write anywhere”也没有冲突,我们内部正在改造已有的组件库和HybridAPI,让其适配(补齐)React Native的组件,从而写一份代码可以运行在iOS和Web上,待成熟后开源出来。
持续更新
下图展示了业务和技术为React Native所做的改造:
图5 - 业务和技术改造
自下而上:
更多详细规划和进展,以及性能、稳定性、扩展性的数据随后放出。
React Native相对于Webview和Native的优势和劣势 @berg 也给出了较详细的描述,可以相互参照。
持续更新...
鬼道
2015.4.6
这个问题也许不是技术问题,但如果不是天猫有意为之,那就是网站被95095恶意篡改了?? 不可能吧 ?
First,我是在天猫给爷爷买东西(医疗类),后来看到有优惠券,就点到该店铺了。。
然而实际上付款的时候并不能用该优惠券,(根本不存在,这算不算恶意引导用户呢?)。

刚开始我还纳闷儿,这天猫的前端怎么还会有bug呢?细心的同学会发现 “菜单有错位”。

后来乍一看,原来这不是tmall,域名竟然是另一个网站(当然满屏都是“天猫”,也拿到了我在天猫的所有数据),好奇心让我输入了一级域名: 95095.com

天猫的技术支持下,竟然还会有这样的页面?
这其实都是小事,重要的是优惠券那事,天猫如何解释?
会场活动页,承载了促销商品导流功能,是消费者的购物入口,在双11活动中的地位可谓重中之重。保障活动页的快速稳定可用,是非常非常重要的。这次天猫双11会场页面渲染由wormhole来承担(wormhole本身会在后续的文章中详细介绍),下面介绍一下wormhole的容灾方案。
wormhole主要消耗性能的地方就在模板引擎渲染这部分,在并发访问量大的情况下,频繁的模板渲染会导致系统负载急剧飙升,导致响应延迟。为了保证大并发量下,足够快速的响应,针对的做了动态降频方案,具体的见下图:
整个渲染策略就是,定时备份页面到OSS集群,每次请求过来,都会去判断当前系统Load是否过载,若果过载则直接读取上次备份的页面返回,而不使用模板引擎渲染,达到动态降低系统负载,快速响应的目的。
动态降频能够保证大部分情况下的快速响应;但是,如果wormhole集群全部当机,则也无能为了。为了确保双11万无一失,还得有一招后手。为此,我们做了一个兜底方案,见下图:
同样类似于第一个方案,也会定时备份页面到OSS集群,不同的是,这次备份到另一个异地的OSS机房,以防止OSS服务因不可抗力挂掉;如果发生了最极端的情况,源站全部挂掉,由当天的值班人员,手工切换CDN指向已经备份了的OSS文件,保障页面可访问。
wormhole基于Node平台开发,我们知道Node平台长期以来,对内存使用监控这块一直很薄弱;对线上服务内存泄露排查基本无从入手;Node服务就像一个黑盒,只能祈祷不要出错,出错也只能使用万能的重启大法。为了弥补这一块,alinode团队推出了监控系统,重点解决这些痛点问题。
如果你看了这篇文章,对加入天猫前端团队有意向的,可以发简历到[email protected],招聘要求见:https://job.alibaba.com/zhaopin/position_detail.htm?positionId=3504
对于react-native在实际中的应用, facebook官方的说法是react-native是为多平台提供共同的开发方式,而不是说一份代码,多处使用。 然后一份代码能够多处使用还是很有意义的,我所了解到的已经在尝试做这件事情的:
现阶段大家都是在摸索中,且react-native 还不够成熟,为此我也想通过一个实际的例子提前探究一下共享代码的可行性。
下面是我以SampleApp做的一个简单demo, 先奉献上截图:
web 版本
react-native版本
react-native基本上是View套上Text这样来布局,为了做web和native的兼容,我们得提供继承版本的View ,针对不同的平台返回不同做兼容,我们将提供:
我们知道react-native的样式是css很小的一个子集,大概支持50种属性,为了做到web和native使用同样地样式,那么我的想法是:
这样做的另外一个原因是,因为css是全集,react-native是子集,全集到子集可以通过删减来处理,但是如果想通过子集到全集就会很麻烦(react-style就是通过react-native来生成css)。 且这样做还有很多好处,例如我们可以支持react-native里边不支持的css写法,例如padding: a b c d; 这种写法很容易得到兼容。
其实这里,无论react-native还是react-web都支持
style={}这样的写法. 上面例子中的web截图其实是没有引用css的,但inline样式对于web来说并不是优选。 后面也做了通过react-native的css到web的css的尝试, 那种方案在样式上可以完全基于react-native来写,直接兼容web。
首先大概整理一下我们需要解决的问题:
react-native 里边会有window变量吗?我试了一下,是有的,那window变量里边不可能有location,document之类的吧, 借着这种想法,可用如下方法来区分native和web
var isNative = !window.location;对于react-native,是通过packager来打包的,具体的实现和逻辑可以随时查看packager的readme文档。 那我们怎么将适用于native的代码打包成web的代码,首先想到的是browserify, webpack。 都是遵循commonJs规范,个人更喜欢前者, 用它来应该足以满足需求。
前面提到了native-css , 可以用它来帮助我们完成打包。
web和native的代码都写在同一个地方,如何做区分呢? 这个问题当然最好就是不做区分,或者就像女生的衣服,期望是越少越好,但永远不可能木有(猥琐了:-】)。
我设想中的一个最简模型的目录结构,web和ios有不同的入口,web和ios有单独的目录, 组件共享, 如下:
├── compo.js // 我们会使用到得公共组件
├── styles.css // compo的样式文件
├── index.web.js // web 入口
├── index.ios.js // ios 入口
├── shared.js // 做兼容的共享变量文件
├── ios // ios 目录
└── web // web 目录
├── index.html // web 页面
├── index.web.js // 打包过后的js
└── react.js // react.js依赖
好像很复杂的样子, 其实相对于原本的SampleApp,只是多了index.web.js , web目录, shared三者。 然后style通过style.css来描述。
我们已经整理了具体的实现思路,下面是我就会直接吐出我的实现代码, 重点的地方都会在源码里边有注释
ios入口:index.ios.js
/**
* Sample React Native App
* https://github.com/facebook/react-native
*/
'use strict';
var React = require('react-native');
var Compo = require('./compo');
React.AppRegistry.registerComponent('ShareCodeProject', () => Compo);web入口:index.web.js
/**
* for web
*/
var Compo = require('./compo');
React.render(<Compo />, document.getElementById('App'));样例组件:compo.js
// 依赖的公共库,通过它获取兼容的组件
var Share = require('./shared');
// styles是style.css build过后生成的style.js
var styles = require('./styles');
var React = Share.React;
var {
View,
P,
Span
} = Share;
var Compo = React.createClass({
render: function() {
return (
<View style={styles.container}>
<P style={styles.welcome}>
Welcome to React Native!
</P>
<P style={styles.instructions}>
To get started, edit index.ios.js
</P>
<P style={styles.instructions}>
Press Cmd+R to reload,{'\n'}
Cmd+Control+Z for dev menu
</P>
</View>
);
}
});
module.exports = Compo;组件样式: style.css
/**
* 大家可能发现了css的写法还是小驼峰,是的不是横杠,暂时我们还是以这种方式处理
* native-css 目测不支持横杠,(自己重写native-css相对来说是比较容易的,完全可以做到css兼容到react-native的css子集)
*/
.container {
flex: 1;
justifyContent: center;
alignItems: center;
backgroundColor: #F5FCFF;
}
.welcome {
fontSize: 20;
textAlign: center;
margin: 10;
}
.instructions {
textAlign: center;
color: #333333;
marginBottom: 5;
}index.html
<!DOCTYPE html>
<html>
<head>
<title>Hello React!</title>
<script src="./react.js"></script>
<!-- No need for JSXTransformer! -->
</head>
<body>
<div id="App"></div>
<script src="./index.web.js"></script>
</body>
</html>shared.js
var Share = {};
var React = require('react-native');
var isNative = !window.location;
/**
* 判断是web的时候,重新赋值React
*/
if (window.React) {
React = window.React;
}
Share.React = React;
/**
* 做底层的兼容, 当然这里只是做了一个最简demo,具体实现的时候可能会对props做各种兼容处理
*/
if (!isNative) {
Share.View = React.createClass({
render: function() {
return <div {...this.props}/>
}
});
Share.P = React.createClass({
render: function() {
return <p {...this.props}/>
}
});
Share.Span = React.createClass({
render: function() {
return <span {...this.props}/>
}
});
} else {
// alert('isNative')
Share.View = React.View;
Share.P = React.Text;
Share.Span = React.Text;
Share.Text = React.Text;
}
module.exports = Share; var fs = require('fs');
var nativeCSS = require('native-css'),
var cssObject = nativeCSS.convert('./styles.css');
toStyleJs(cssObject, './styles.js');
buildWebReact();
/**
* native-css获取到得是一个对象,需要将cssObject转化为js代码
*/
function toStyleJs(cssObject, name) {
console.log('build styles.js \n');
var tab = ' ';
var str = '';
str += '/* build header */\n';
str += 'var styles = {\n';
for(var key in cssObject) {
var rules = cssObject[key];
str += tab + key + ': {\n';
for(var attr in rules) {
var rule = rules[attr];
str += tab + tab + attr + ': ' + format(rule) + ',\n'
}
str += tab + '},\n'
}
str += '};\n'
str += 'module.exports = styles;\n'
fs.writeFile(name, str)
function format(rule) {
if (!isNaN(rule - 0)) {
return rule;
}
return '"' + rule + '"';
}
}
/**
* 构造web使用的react
*/
function buildWebReact() {
console.log('build web bundle');
var browserify = require('browserify');
var b = browserify();
b.add('./index.web.js');
// 添加es6支持
b.transform('reactify', {'es6': true});
// ignore掉react-native
b.ignore('react-native')
var wstream = fs.createWriteStream('./web/index.web.js');
b.bundle().pipe(wstream);
}display: flex; 在web上必须要做这样的声明, 所以我们需要让设置了flex:*的元素的父元素display: flex; 。webkit-box styles = StyleSheet.create({
mod: {
flexDirection: 'row',
item: {
flex: 1
}
}
});这样的写法有些像less,我们可以知道元素的层级关系, 这样我可以遍历这个对象,查找子元素有设置flex的,父元素加上display:flexbox。
var GridSystem = require('GridSystem');
var {
Row,
Grid,
Grid6,
Grid4
} = GridSystem;
<Row ...>
<Grid/>
<Grid/>
</Row>通过标签的方式, 相当于给react-native或者react添加了一个网格系统,同时我们可以直接在Row上设置display:flex.
完全同react-native原生的写法,直接在web中兼容,遍历所有有flex样式的节点,直接做兼容。
componentDidMount: function() {
var $node = this.getDOMNode();
var $parent = $node.parentNode;
var $docfrag = document.createDocumentFragment();
$docfrag.appendChild($node);
var treeWalker = document.createTreeWalker($node, NodeFilter.SHOW_ELEMENT, {
acceptNode: function(node) {
return NodeFilter.FILTER_ACCEPT;
}
}, false);
while(treeWalker.nextNode()) {
var node = treeWalker.currentNode;
if (node.style.flex) {
flexChild(node);
flexParent(node.parentNode);
}
};
$parent.appendChild($docfrag);
}
function flexChild(node) {
if (node.__flexchild__) {
return;
}
node.__flexchild__ = true;
var flexGrow = node.style.flexGrow;
addStyle(node, `
-webkit-box-flex: ${flexGrow};
-webkit-flex: ${flexGrow};
-ms-flex: ${flexGrow};
flex: ${flexGrow};
`);
node.classList.add('mui-flex-cell');
}
function flexParent(node) {
if (node.__flexparentd__) {
return;
}
node.__flexparentd__ = true;
node.classList.add('mui-flex');
} .mui-flex {
display: -webkit-box!important;
display: -webkit-flex!important;
display: -ms-flexbox!important;
display: flex!important;
-webkit-flex-wrap: wrap;
-ms-flex-wrap: wrap;
flex-wrap: wrap;
-webkit-box-orient: vertical;
-webkit-box-direction: normal;
-webkit-flex-direction: column;
-ms-flex-direction: column;
flex-direction: column;
}
.mui-flex-cell {
-webkit-flex-basis: 0;
-ms-flex-preferred-size: 0;
flex-basis: 0;
max-width: 100%;
display: block;
position: relative;
}这个demo很简单,实际应用中应该会有很多地方的坑, 比如:
对于write once, run anywhere 这个观点. 相信不同的人会有不同的看法,但无论如何,如果兼容成本不大,这样的兼容技术方案对业务开发是有极大意义的。
ps0: 这里仅仅做可行性方案的分析,不代表我认同或不认同这种方案。
ps1: 大家如果有更好的方案,求教,求讨论。
今年的双十一电商大战完满结束,各大电商也随后相继公布了各自的订单数量和销售总额。在这一次的电商大战中,各大公司已经从单纯的价格较量延伸到平台稳定性和用户体验上的竞争,而这些较量背后需要有相应的强大技术做支撑。其中,Web前端直接和用户交互,它的稳定性、流畅性直接决定着整个系统的用户体验。InfoQ也采访了天猫的前端架构负责人鬼道,以期与读者分享天猫在Web前端方面的成熟经验。
InfoQ:我们可以看到在整个双十一的过程中,与用户打交道的前端页面访问基本都很流畅。能介绍下天猫Web端的架构么?
鬼道: MAP(tMall fe Architecture & Publication)是天猫 Web 端的架构代号。MAP涵盖了一张页面的代码管理、开发环境、模板、数据接口、发布、终端判断、线上监控、性能标准等各个方面。在本次双十一中,我们全链路的性能都处于竞品的顶尖水平,如首页第一、搜索结果页第二、商品详情页第一。
另外,在移动端,我们使用了一项叫Dynative的技术,当使用天猫客户端访问双十一的Web页面时,客户端会自动生成一个Native实现的View,大大提升交互的流畅性和加载性能。另外我们也有同学在负责研究跨终端的组件方案,让一套组件可以同时运行在手机、Pad和PC上,当然在客户端下时它同样能转换成一个Native组件,从而保证一致和优秀的用户体验。
在性能监控上,我们不但能区分不同地域用户的性能情况,还能以网络类型、客户端、访问类型(直接访问、刷新、返回)、网络协议(HTTP/1、HTTP/2、SPDY)、操作系统等过滤条件分析应用性能。在性能指标上,不但有首字节时间、首次渲染时间、Dom ready、onload这些常规指标,还提供重定向、DNS查询、TCP链接建立、服务端响应、动画帧数、内存占用等指标。对于应用的加载性能除了能提供以上提到的关键性指标外,我们还能提供应用加载过程截图以及基于全网真实用户环境的加载瀑布图。
InfoQ:为了保证业务峰值时用户顺滑的用户体验,淘宝对前端页面做了哪些特殊处理?
鬼道: 如何保证在峰值时的用户体验,这也是我们最近重点的事情。从大的方面来说,主要有两方面。一是业务降级,通过监控重要接口的访问情况,一旦访问量超过警戒值,为保证核心链路的稳定性,会将其他来源的访问按照预设的方案进行降级。二是CDN,CDN 是静态资源的主要载体,阿里前端的静态资源默认都部署在 CDN 上,这个我一会再谈。另外后端系统针对系统读写特性也有相应的动静分离策略、容灾策略和异常隔离策略。
InfoQ:不管是在首页还是商品页中,图片都占了很大一部分,在如此大的高并发访问情况下,网站的图片仍然可以在短时间内显示出来,真是一件不可思议的事情,图片这块,淘宝有用什么先进技术么?
鬼道:我们在全国各个省部署了大量的CDN服务器,把短时间内高并发的请求转化成了分布式的处理,由每个省市本地的服务器来处理各自的请求,避免了大量数据跨长途骨干网往返;另外,我们在操作系统的内核和TCP协议栈层面也针对网络拥塞、丢包的情况做了优化,快速发现丢包缩短TCP协议的应变时间;通过精准的IP库区分用户区域,确保用户访问到离自己最近的服务器。
同时,天猫客户端会根据网络状态展示不同质量的图片,如Wi-Fi下展示高清图片,非Wi-Fi网络下展示普通图片,这个策略在图片质量和响应速度上做了很好的折中。另外,减少图片请求在移动端上效果尤其明显。Icon Font 用于维护一组图标,在享受矢量图形缩放和文字颜色可变的优势上,也是减少图片请求的一种方式;未使用 Icon Font 的图标会通过 split 工具自动合并成大图,同样可以减少图片请求数量。天猫的主要页面上都已经做到在高清屏(移动和PC设备)上展示高清图片,非高清屏上降级展示普通图片。图片格式方面,我们也有新的尝试,在天猫商品详情页面上也部分启用了WebP,主要是考虑WebP相对JPG有更高的压缩率,但WebP在移动端解压速度的问题也不容忽视。
InfoQ:不同地区的用户可能访问的速度也不一样,天猫在前端这块有相应的监控手段么?
鬼道:有监控手段,我们会实时分析访问日志,上报各个区域的用户请求响应时间,在发现异常时通过DNS调度将用户导流到正常的服务器上。
InfoQ:用户可能会在不同的屏幕上访问天猫,天猫是如何保证跨终端的一致性的?
鬼道:在一致性上我们有一个很重要的基础设施Detector。随着无线互联网的发展,业务上需要在不同的端给用户呈现不同的内容,前端所面临的终端环境也越来越复杂和碎片化,这就要求前端开发具备方便获取准确、一致的各种终端信息的能力,为了解决跨终端一致性问题,在双十一之前,我们就设计和开发了多终端判断基础模块Detector,通过Detector,我们实现了双十一期间成百上千页面的一致终端判断,逻辑跳转,不同终端内容输出的艰巨任务。
Detector是技术基础,用户感知到的一致性需要依靠上层应用在设计层面的一致性保证,由于天猫不同终端上的界面来自同一个设计团队,这有利于设计风格和理念保持一致。为了更好地延续设计风格,天猫内部有一个MUI项目,就是将常用的界面元素封装成组件库。
InfoQ:在本次双十一活动中,有哪些好的经验可以分享给我们的读者?
鬼道:经验有很多,我挑些重点的来分享给大家。首先Hybrid API的应用可以降低跨客户端开发成本。双十一前我们推动发布了阿里 Hybrid API 1.0,它提供一套能够运行在阿里多个客户端和独立浏览器的 18 组共26个API,目前已支持天猫、淘宝、支付宝客户端,既包括常用的传感器API也有窗口管理、登录、支付等 API。双十一期间应用于天猫狂欢城、天猫店铺互动、手机淘宝互动分会场等多个业务。
游戏引擎 Hilo。Hilo 是阿里研发的互动游戏引擎,支持 PC 端和移动端几乎所有主流浏览器,也通过Flash支持IE 6、7。Hilo可以极大降低互动游戏的开发成本,适合阿里的业务场景。双十一期间应用于天猫狂欢城、天猫店铺互动、手机淘宝互动分会场等多个业务。
应用稳定性监控。对于应用的稳定性,我们有覆盖所有端的监控系统,在Native端我们有实时的Crash监控平台,在Web端我们有实时的JS报错监控平台。任何客户端的报错都能实时体现,例如我们发现iPhone客户端在双11时Crash率大幅上升,我们当晚立刻修复了问题,Crash率恢复到了正常水平。
双十一天猫首页开闭幕式。相比去年而言,本次开幕式的的挑战主要是动画变得更加复杂,根据场景选用合适的动画:CSS 3 动画用于处理开始出现时的头像波浪,CSS 3动画适用于大批量处理、动画方式较为简单的场景;JS动画用于处理中间两个场景,JS动画使用了KISSY框架的Anim模块,比较方便;Canvas动画主要应用于倒计时阶段的粒子效果。
关注上下游系统及链路。双十一需要保证是对客户的整体体验稳定、流畅,任何一个环节出错都对这个目标有影响;前端处于用户体验的最前端,用户的体验从这里开始,任何的差错也会从这里产生;加上前端是所有后面系统服务的“消费者”,从消费者的角度关注和检查,而不仅仅依赖服务方自身的监控和保证,能最大限度减少出问题的概率。
充分的预演和测试。随着移动的浪潮,前端所面临的终端环境也越来越复杂,不再是仅仅关注几种浏览器,加上系统碎片化的问题,所需要测试的客户端越来越多,仅仅依赖于QA和前端的自测在日常中基本能保证主流的终端稳定,但在双十一这样的场景中,就显得不足。
依赖于程序而非系统或人。双十一其他每个时间段都有一定的状态变化,从预热到正式到下线,每个阶段的操作我们都靠程序控制,提前上线,而不是依赖于人或者系统的定时发布。没有人可以做到100%不出错,没有系统可以保证100%稳定,将出问题的几率控制到最小。
为什么淘宝 天猫不使用rest开发模式,而要使用node服务的渲染?
跨终端的 Web @舒文 2013.04.12 @QCon成都2013大会
详见:
企业级 NPM 在阿里的实践 @不四 2014.10 @D2
最近在学习React.js,之前都是直接用最原生的方式去写React代码,发现组织起来特别麻烦,之前听人说用Webpack组织React组件得心应手,就花了点时间学习了一下,收获颇丰
一个组件,有自己的结构,有自己的逻辑,有自己的样式,会依赖一些资源,会依赖某些其他组件。比如日常写一个组件,比较常规的方式:
- 通过前端模板引擎定义结构
- JS文件中写自己的逻辑
- CSS中写组件的样式
- 通过RequireJS、SeaJS这样的库来解决模块之间的相互依赖,
那么在React中是什么样子呢?
在React的世界里,结构和逻辑交由JSX文件组织,React将模板内嵌到逻辑内部,实现了一个JS代码和HTML混合的JSX。
在JSX文件中,可以直接通过React.createClass来定义组件:
var CustomComponent = React.creatClass({
render: function(){
return (<div className="custom-component"></div>);
}
});通过这种方式可以很方便的定义一个组件,组件的结构定义在render函数中,但这并不是简单的模板引擎,我们可以通过js方便、直观的操控组件结构,比如我想给组件增加几个节点:
var CustomComponent = React.creatClass({
render: function(){
var $nodes = ['h','e','l','l','o'].map(function(str){
return (<span>{str}</span>);
});
return (<div className="custom-component">{$nodes}</div>);
}
});通过这种方式,React使得组件拥有灵活的结构。那么React又是如何处理逻辑的呢?
写过前端组件的人都知道,组件通常首先需要相应自身DOM事件,做一些处理。必要时候还需要暴露一些外部接口,那么React组件要怎么做到这两点呢?
比如我有个按钮组件,点击之后需要做一些处理逻辑,那么React组件大致上长这样:
var ButtonComponent = React.createClass({
render: function(){
return (<button>屠龙宝刀,点击就送</button>);
}
});点击按钮应当触发相应地逻辑,一种比较直观的方式就是给button绑定一个onclick事件,里面就是需要执行的逻辑了:
function getDragonKillingSword() {
//送宝刀
}
var ButtonComponent = React.createClass({
render: function(){
return (<button onclick="getDragonKillingSword()">屠龙宝刀,点击就送</button>);
}
});但事实上getDragonKillingSword()的逻辑属于组件内部行为,显然应当包装在组件内部,于是在React中就可以这么写:
var ButtonComponent = React.createClass({
getDragonKillingSword: function(){
//送宝刀
},
render: function(){
return (<button onClick={this.getDragonKillingSword}>屠龙宝刀,点击就送</button>);
}
});这样就实现内部事件的响应了,那如果需要暴露接口怎么办呢?
事实上现在getDragonKillingSword已经是一个接口了,如果有一个父组件,想要调用这个接口怎么办呢?
父组件大概长这样:
var ImDaddyComponent = React.createClass({
render: function(){
return (
<div>
//其他组件
<ButtonComponent />
//其他组件
</div>
);
}
});那么如果想手动调用组件的方法,首先在ButtonComponent上设置一个ref=""属性来标记一下,比如这里把子组件设置成<ButtonComponent ref="getSwordButton"/>,那么在父组件的逻辑里,就可以在父组件自己的方法中通过这种方式来调用接口方法:
this.refs.getSwordButton.getDragonKillingSword();看起来屌屌哒~那么问题又来了,父组件希望自己能够按钮点击时调用的方法,那该怎么办呢?
父组件可以直接将需要执行的函数传递给子组件:
<ButtonComponent clickCallback={this.getSwordButtonClickCallback}/>然后在子组件中调用父组件方法:
var ButtonComponent = React.createClass({
render: function(){
return (<button onClick={this.props.clickCallback}>屠龙宝刀,点击就送</button>);
}
});子组件通过this.props能够获取在父组件创建子组件时传入的任何参数,因此this.props也常被当做配置参数来使用
屠龙宝刀每个人只能领取一把,按钮点击一下就应该灰掉,应当在子组件中增加一个是否点击过的状态,这又应当处理呢?
在React中,每个组件都有自己的状态,可以在自身的方法中通过this.state取到,而初始状态则通过getInitialState()方法来定义,比如这个屠龙宝刀按钮组件,它的初始状态应该是没有点击过,所以getInitialState方法里面应当定义初始状态clicked: false。而在点击执行的方法中,应当修改这个状态值为click: true:
var ButtonComponent = React.createClass({
getInitialState: function(){
//确定初始状态
return {
clicked: false
};
},
getDragonKillingSword: function(){
//送宝刀
//修改点击状态
this.setState({
clicked: true
});
},
render: function(){
return (<button onClick={this.getDragonKillingSword}>屠龙宝刀,点击就送</button>);
}
});这样点击状态的维护就完成了,那么render函数中也应当根据状态来维护节点的样式,比如这里将按钮设置为disabled,那么render函数就要添加相应的判断逻辑:
render: function(){
var clicked = this.state.clicked;
if(clicked)
return (<button disabled="disabled" onClick={this.getDragonKillingSword}>屠龙宝刀,点击就送</button>);
else
return (<button onClick={this.getDragonKillingSword}>屠龙宝刀,点击就送</button>);
}这里简单介绍了通过JSX来管理组件的结构和逻辑,事实上React给组件还定义了很多方法,以及组件自身的生命周期,这些都使得组件的逻辑处理更加强大
CSS文件定义了组件的样式,现在的模块加载器通常都能够加载CSS文件,如果不能一般也提供了相应的插件。事实上CSS、图片可以看做是一种资源,因为加载过来后一般不需要做什么处理。
React对这一方面并没有做特别的处理,虽然它提供了Inline Style的方式把CSS写在JSX里面,但估计没有多少人会去尝试,毕竟现在CSS样式已经不再只是简单的CSS文件了,通常都会去用Less、Sass等预处理,然后再用像postcss、myth、autoprefixer、cssmin等等后处理。资源加载一般也就简单粗暴地使用模块加载器完成了
组件依赖的处理一般分为两个部分:组件加载和组件使用
React没有提供相关的组件加载方法,依旧需要通过<script>标签引入,或者使用模块加载器加载组件的JSX和资源文件。
如果细心,就会发现其实之前已经有使用的例子了,要想在一个组件中使用另外一个组件,比如在ParentComponent中使用ChildComponent,就只需要在ParentComponent的render()方法中写上<ChildComponent />就行了,必要的时候还可以传些参数。
到这里就会发现一个问题,React除了只处理了结构和逻辑,资源也不管,依赖也不管。是的,React将近两万行代码,连个模块加载器都没有提供,更与Angularjs,jQuery等不同的是,他还不带啥脚手架...没有Ajax库,没有Promise库,要啥啥没有...
那它为啥这么大?因为它实现了一个虚拟DOM(Virtual DOM)。虚拟DOM是干什么的?这就要从浏览器本身讲起
如我们所知,在浏览器渲染网页的过程中,加载到HTML文档后,会将文档解析并构建DOM树,然后将其与解析CSS生成的CSSOM树一起结合产生爱的结晶——RenderObject树,然后将RenderObject树渲染成页面(当然中间可能会有一些优化,比如RenderLayer树)。这些过程都存在与渲染引擎之中,渲染引擎在浏览器中是于JavaScript引擎(JavaScriptCore也好V8也好)分离开的,但为了方便JS操作DOM结构,渲染引擎会暴露一些接口供JavaScript调用。由于这两块相互分离,通信是需要付出代价的,因此JavaScript调用DOM提供的接口性能不咋地。各种性能优化的最佳实践也都在尽可能的减少DOM操作次数。
而虚拟DOM干了什么?它直接用JavaScript实现了DOM树(大致上)。组件的HTML结构并不会直接生成DOM,而是映射生成虚拟的JavaScript DOM结构,React又通过在这个虚拟DOM上实现了一个 diff 算法找出最小变更,再把这些变更写入实际的DOM中。这个虚拟DOM以JS结构的形式存在,计算性能会比较好,而且由于减少了实际DOM操作次数,性能会有较大提升
道理我都懂,可是为什么我们没有模块加载器?
所以就需要Webpack了
事实上它是一个打包工具,而不是像RequireJS或SeaJS这样的模块加载器,通过使用Webpack,能够像Node.js一样处理依赖关系,然后解析出模块之间的依赖,将代码打包
首先得有Node.js
然后通过npm install -g webpack安装webpack,当然也可以通过gulp来处理webpack任务,如果使用gulp的话就npm install --save-dev gulp-webpack
Webpack的构建过程需要一个配置文件,一个典型的配置文件大概就是这样
var webpack = require('webpack');
var commonsPlugin = new webpack.optimize.CommonsChunkPlugin('common.js');
module.exports = {
entry: {
entry1: './entry/entry1.js',
entry2: './entry/entry2.js'
},
output: {
path: __dirname,
filename: '[name].entry.js'
},
resolve: {
extensions: ['', '.js', '.jsx']
},
module: {
loaders: [{
test: /\.js$/,
loader: 'babel-loader'
}, {
test: /\.jsx$/,
loader: 'babel-loader!jsx-loader?harmony'
}]
},
plugins: [commonsPlugin]
};这里对Webpack的打包行为做了配置,主要分为几个部分:
[name]会由entry中的键(这里是entry1和entry2)替换.js结尾的文件都是用babel-loader做处理,而.jsx结尾的文件会先经过jsx-loader处理,然后经过babel-loader处理。当然这些loader也需要通过npm install安装当然Webpack还有很多其他的配置,具体可以参照它的配置文档
如果通过npm install -g webpack方式安装webpack的话,可以通过命令行直接执行打包命令,比如这样:
$webpack --config webpack.config.js这样就会读取当前目录下的webpack.config.js作为配置文件执行打包操作
如果是通过gulp插件gulp-webpack,则可以在gulpfile中写上gulp任务:
var gulp = require('gulp');
var webpack = require('gulp-webpack');
var webpackConfig = require('./webpack.config');
gulp.task("webpack", function() {
return gulp
.src('./')
.pipe(webpack(webpackConfig))
.pipe(gulp.dest('./build'));
});Webpack使得我们可以使用Node.js的CommonJS规范来编写模块,比如一个简单的Hello world模块,就可以这么处理:
var React = require('react');
var HelloWorldComponent = React.createClass({
displayName: 'HelloWorldComponent',
render: function() {
return (<div>Hello world</div>);
}
});
module.exports = HelloWorldComponent;等等,这和之前的写法没啥差别啊,依旧没有逼格...程序员敲码要有geek范,要逼格than逼格,这太low了。现在都ES6了,React的代码也要写ES6,babel-loader就是干这个的。Babel能够将ES6代码转换成ES5。首先需要通过命令npm install --save-dev babel-loader来进行安装,安装完成后就可以使用了,一种使用方式是之前介绍的在webpack.config.js的loaders中配置,另一种是直接在代码中使用,比如:
var HelloWorldComponent = require('!babel!jsx!./HelloWorldComponent');那我们应当如何使用Babel提升代码的逼格呢?改造一下之前的HelloWorld代码吧:
import React from 'react';
export default class HelloWorldComponent extends React.Component {
constructor() {
super();
this.state = {};
}
render() {
return (<div>Hello World</div>);
}
}这样在其他组件中需要引入HelloWorldComponent组件,就只要就可以了:
import HelloWorldComponent from './HelloWorldComponent'怎么样是不是更有逼格了?通过import引入模块,还可以直接定义类和类的继承关系,这里也不再需要getInitialState了,直接在构造函数constructor中用this.state = xxx就好了
Babel带来的当然还不止这些,在其帮助下还能尝试很多优秀的ES6特性,比如箭头函数,箭头函数的特点就是内部的this和外部保持一致,从此可以和that、_this说再见了
['H', 'e', 'l', 'l', 'o'].map((c) => {
return (<span>{c}</span>);
});其他还有很多,具体可以参照Babel的学习文档
我是一个强烈地Less依赖患者,脱离了Less直接写CSS就会出现四肢乏力、不想干活、心情烦躁等现象,而且还不喜欢在写Less时候加前缀,平常都是gulp+less+autoprefixer直接处理的,那么在Webpack组织的React组件中要怎么写呢?
没错,依旧是使用loader
可以在webpack.config.js的loaders中增加Less的配置:
{
test: /\.less$/,
loader: 'style-loader!css-loader!autoprefixer-loader!less-loader'
}通过这样的配置,就可以直接在模块代码中引入Less样式了:
import React from 'react';
require('./HelloWorldComponent.less');
export default class HelloWorldComponent extends React.Component {
constructor() {
super();
this.state = {};
}
render() {
return (<div>Hello World</div>);
}
}Webpack的loader为React组件化提供了很多帮助,像图片也提供了相关的loader:
{ test: /\.png$/, loader: "url-loader?mimetype=image/png" }更多地loader可以移步webpack的wiki
Webpack和React结合的另一个强大的地方就是,在修改了组件源码之后,不刷新页面就能把修改同步到页面上。这里需要用到两个库webpack-dev-server和react-hot-loader。
首先需要安装这两个库,npm install --save-dev webpack-dev-server react-hot-loader
安装完成后,就要开始配置了,首先需要修改entry配置:
entry: {
helloworld: [
'webpack-dev-server/client?http://localhost:3000',
'webpack/hot/only-dev-server',
'./helloworld'
]
},通过这种方式指定资源热启动对应的服务器,然后需要配置react-hot-loader到loaders的配置当中,比如我的所有组件代码全部放在scripts文件夹下:
{
test: /\.js?$/,
loaders: ['react-hot', 'babel'],
include: [path.join(__dirname, 'scripts')]
}最后配置一下plugins,加上热替换的插件和防止报错的插件:
plugins: [
new webpack.HotModuleReplacementPlugin(),
new webpack.NoErrorsPlugin()
]这样配置就完成了,但是现在要调试需要启动一个服务器,而且之前配置里映射到http://localhost:3000,所以就在本地3000端口起个服务器吧,在项目根目录下面建个server.js:
var webpack = require('webpack');
var WebpackDevServer = require('webpack-dev-server');
var config = require('./webpack.config');
new WebpackDevServer(webpack(config), {
publicPath: config.output.publicPath,
hot: true,
historyApiFallback: true
}).listen(3000, 'localhost', function (err, result) {
if (err) console.log(err);
console.log('Listening at localhost:3000');
});这样就可以在本地3000端口开启调试服务器了,比如我的页面是根目录下地index.html,就可以直接通过http://localhost:3000/index.html访问页面,修改React组件后页面也会被同步修改,这里貌似使用了websocket来同步数据。图是一个简单的效果:
React的组件化开发很有想法,而Webpack使得React组件编写和管理更加方便,这里只涉及到了React和Webpack得很小一部分,还有更多的最佳实践有待在学习的路上不断发掘
移动优先的跨终端 Web @[鬼道][luics] 2013.07.14 ADC D2 2013,2013.11.23 @W3CTECH 2013
天猫作为阿里双11的主战场,承担了数以百计的页面,亿级的访问及各类复杂的系统包括搜索、商品详情、交易等。
为了双11,我们做了N多的准备,包括
虽然由于XX的原因,每一项技术都不能讲到特别细致,但是我们会努力做到让你们看完有所收获。
目录:
接下来这几天,我们会把内部整理出来的总结分享到这边,尽请期待。
有兴趣来天猫一起提升技术的,可以发简历到[email protected],招聘要求
为什么天猫和淘宝的js和图片等一些静态资源都不缓存成304或者form cache呢。。现在状态码全是200
赵雷终究还是火了,靠的《成都》和带不走的‘你’!总觉得这歌写的不是成都,而是杭州:
在那座飘雨的小城里,
我从未忘记你,
杭州,带不走的只有阿里。
。。。
你会挽着我的衣袖,
我会把手揣进你裤兜,
走到文一路的西头,
坐在阿里巴巴门口。
被你看穿了,这是招聘帖!
春天,是阿里巴巴的招聘季;天猫前端,向你抛来了橄榄枝!
春天,是阿里巴巴的招聘季;天猫前端,向你抛来了橄榄枝!
春天,是阿里巴巴的招聘季;天猫前端,向你抛来了橄榄枝!
先谈薪资福利
再谈人生理想
不逼逼,你继续看图!
吃腻了1、2。。7、8号食堂的美味?不想去园区里面的同乐会、弄堂里,那就吃点不一样的!(记住,一定要叫上买单的boss!)
杭州地铁比不过上海,如果上下班不想坐公交,又觉得打车太贵,那就靠公司数百名顺风车司机免费接送吧。
跑跑步?真的很没劲!
园区走走?看看美景!
打篮球?你也不能一个人!
是单身?证婚人都给你选好了,伴郎伴娘同样不差人!
够牛?有货?你就来做我们的super star!
在天猫,业务&技术双驱动,组件化、模块化、工程化开发模式!
在天猫,追求完美,追求极致,专注前端前沿技术,无限制的知识共享!
在天猫,就是要做出精彩做出价值!就连各种吃喝玩乐都那么与众不同!
来杭州,来阿里,来天猫!我在西溪等你!
听一听赵雷的歌曲,品一品西湖的龙井;过一过阿里的日子,摘一朵‘带不走’的花儿!
相关文章:
@天猫前端:[email protected]
please add one css rule for .img-circle : max-width:100%;
最近在做h5的性能优化,方案是想通过大数据打点了解真实用户情况,我们也是通过performance.timing来获取页面性能数据,可以很方便知道页面load完的时间,但是我们更想知道页面首屏时间。
目前我们大部分页面和天猫类似,采用前端异步渲染,同时为了性能优化,部分页面开始尝试做node端渲染直出。
目前我们这边有个想法,前端异步当模板生成的dom插入body时候,我们通过performance.now()来打点一个数据,获取首屏渲染时间,node端渲染的时候,底部 标记为async的js执行就通过performance.now()打一个点,不知道这种方式是否准确?
最后想了解下天猫团队是通过什么样的方式来比较准确获取页面的首屏时间,而不是页面load完的时间?
求密码
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.