

![]()
As of 2021 this repo is currently not actively maintained. I do hope to make time for it in the future as there's lots of room for improvement - PRs welcome any time.
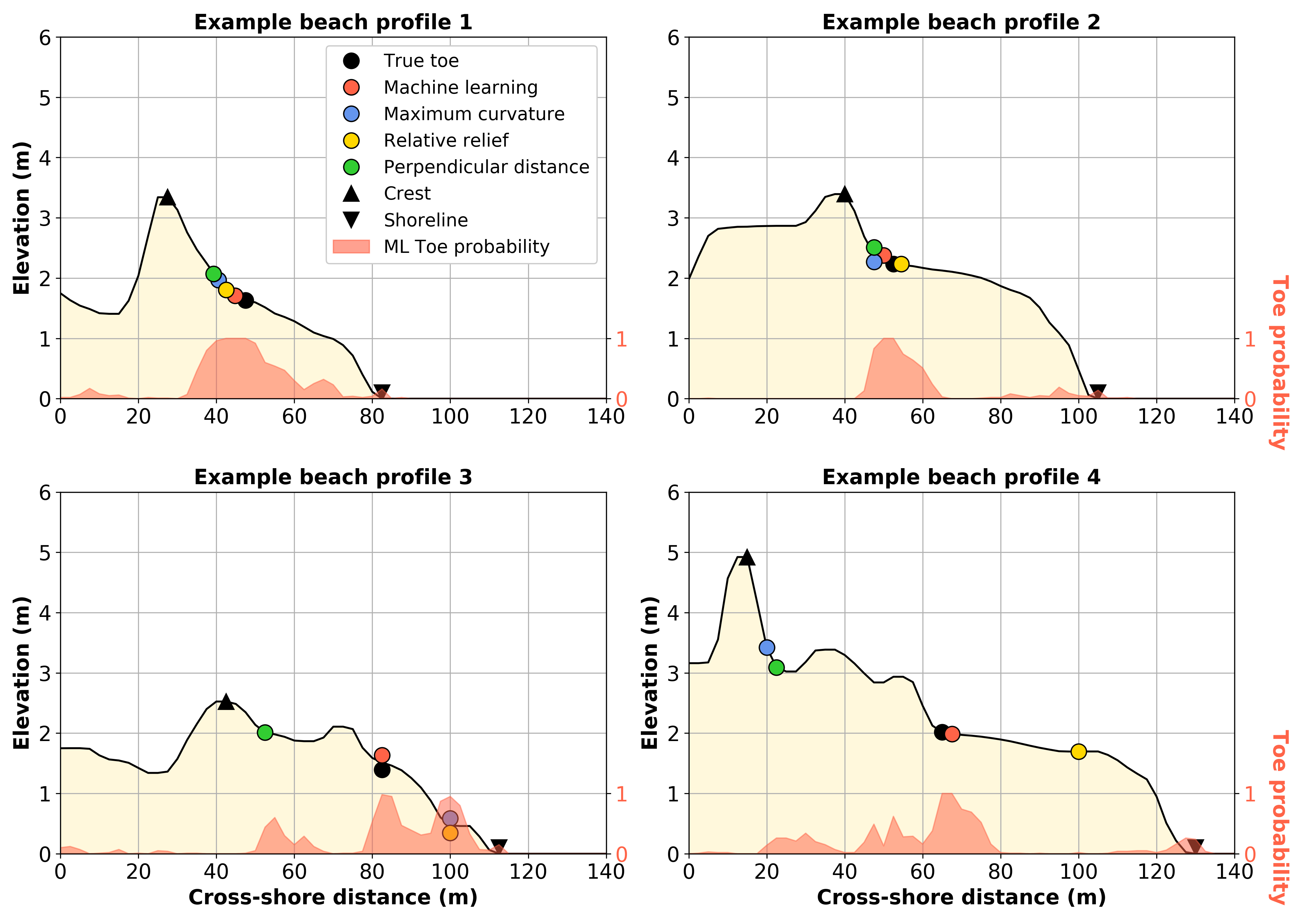
pybeach is a Python package for identifying dune toes on 2D beach profile transects. It includes the following methods:
- Machine learning;
- Maximum curvature (Stockdon et al, 2007);
- Relative relief (Wernette et al, 2016); and,
- Perpendicular distance.
In addition, pybeach contains methods for identifying the shoreline position and dune crest position on 2D beach profile transects. See the pybeach paper for more details about pybeach.
pip install pybeach
from pybeach.beach import Profile
# example data
x = np.arange(0, 80, 0.5)
z = np.concatenate((np.linspace(4, 5, 40),
np.linspace(5, 2, 10),
np.linspace(2, 0, 91)[1:],
np.linspace(0, -1, 20)))
# instantiate
p = Profile(x, z)
# predict dune toe, dune crest, shoreline location
toe_ml, prob_ml = p.predict_dunetoe_ml('wave_embayed_clf') # predict toe using machine learning model
toe_mc = p.predict_dunetoe_mc() # predict toe using maximum curvature method (Stockdon et al, 2007)
toe_rr = p.predict_dunetoe_rr() # predict toe using relative relief method (Wernette et al, 2016)
toe_pd = p.predict_dunetoe_pd() # predict toe using perpendicular distance method
crest = p.predict_dunecrest() # predict dune crest
shoreline = p.predict_shoreline() # predict shorelineSee the example notebook for more details.
Read the pybeach documentation here.
A list of pybeach dependencies can be found in pyproject.toml. Currently, pybeach depends on the following:
- python = "^3.7"
- numpy = "1.17.2"
- scipy = "1.3.1"
- pandas = "0.25.1"
- scikit-learn = "0.21.2"
- joblib = "0.13.2"
Do you have a question that needs answering? Have you found an issue with the code and need to get it fixed? Or perhaps you're looking to contribute to the code and have ideas for how it could be improved. In all cases, please see the Issues page.
Stockdon, H. F., Sallenger Jr, A. H., Holman, R. A., & Howd, P. A. (2007). A simple model for the spatially-variable coastal response to hurricanes. Marine Geology, 238, 1-20. https://doi.org/10.1016/j.margeo.2006.11.004
Wernette, P., Houser, C., & Bishop, M. P. (2016). An automated approach for extracting Barrier Island morphology from digital elevation models. Geomorphology, 262, 1-7. https://doi.org/10.1016/j.geomorph.2016.02.024




















