![]()




Libraries and scripts for crawling the TYPO3 page tree. Used for re-caching, re-indexing, publishing applications etc.
You can include the crawler in your TYPO3 project with composer or from TER
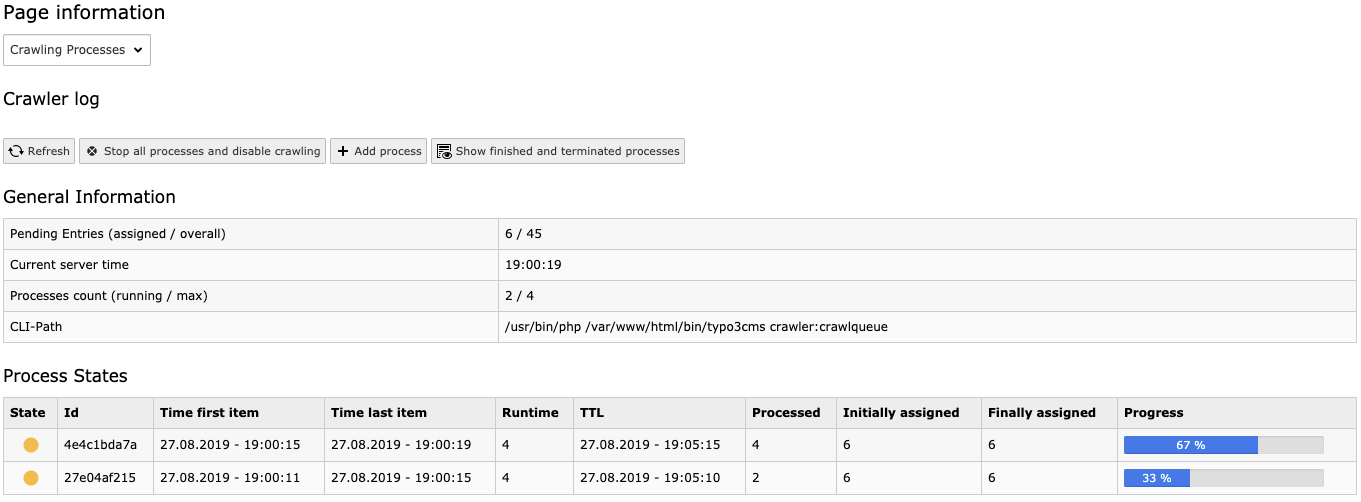
composer require tomasnorre/crawlerCrawler processes
| Release | TYPO3 | PHP | Fixes will contain |
|---|---|---|---|
| 12.x.y | 12.4 | 8.1-8.3 | Features, Bugfixes, Security Updates |
| 11.x.y | 10.4-11.5 | 7.4-8.1 | Bugfixes, Security Updates, Since 11.0.3 PHP 8.1 |
| 10.x.y | 9.5-11.0 | 7.2-7.4 | Security Updates |
| 9.x.y | 9.5-11.0 | 7.2-7.4 | As this version has same requirements as 10.x.y, there will be no further releases of this version, please update instead. |
| 8.x.y | Releases do not exist | ||
| 7.x.y | Releases do not exist | ||
| 6.x.y | 7.6-8.7 | 5.6-7.3 | Security Updates |
Please read the documentation
To render the documentation locally, please use the official TYPO3 Documentation rendering Docker Tool. https://github.com/t3docs/docker-render-documentation
Please see CONTRIBUTING.md
- Kasper Skaarhoj
- Daniel Poetzinger
- Fabrizio Branca
- Tolleiv Nietsch
- Timo Schmidt
- Michael Klapper
- Stefan Rotsch













































































































