tourun / blog Goto Github PK
View Code? Open in Web Editor NEW记录点滴
记录点滴

最近一直在使用Flask框架进行开发,虽然在大部分时间都在开发业务服务的相关代码,但是与之前在使用 Django开发一样,还是对其内部的实现逻辑充满好奇,也断断续续通过Flask的源码来了解其内部消息流处理的机制,但还未记录成一个完整的workflow,所以这里就总结下 Flask 在接收到请求之后,其内部消息流的一些处理逻辑。
Flask 是一个Python编写的轻量级web应用框架,其官方定义为微服务框架(micro framework)。这里的轻量级是相较于Django而言的,Django官方对其的定义为: The web framework for perfectionists with deadlines. 而它确实是一个终极杀器,Django内置了很多便捷的模块:DjangoForm、Django csrftoken、Django ORM、Django Cache……能够满足框架的大部分业务场景,能够让使用者更快速的上手,搭建一个功能完整的web application。Flask的设计理念与Django相反,它的设计更为灵活、轻便、易于扩展、可定制性更高,因此Flask只提供了web application的核心功能,其他的需要由用户来做决策,比如使用什么类型的ORM、如何进行Form Validation、或者如何处理用户login以及管理session……实际上这些常见的问题都有成熟解决方案,Flask提供了很多extension模块,在Flask Community上可以看到找到这些不同功能的extension。
回归文章主题,通常将Flask作为web framework时,需要定义一个application对象,实际上它是一个Flask类实例,以下是一个简单的 app 创建方法以及应用程序的启动:
def create_app(config)
app = Flask(__name__)
# 设置跨域资源共享
COSR(app, resources=[r"/external-api/*"], origins=[r"https?:.*"])
# 加载配置文件
app.config.from_pyfile(config)
# 设置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] = construct_db_url(config)
# init extensions
database.init_app(app)
babel.init_app(app)
security.init_app(app)
# 注册各个子模块的路由
register_blueprint(app)
return app
if __name__ == "__main__":
app = create_app("config.py")
app.run("0.0.0.0", port=5000)上面启动了一个简单的Flask web app,监听并处理5000端口的请求,注意这里只是用作演示,而在生产环境中,通常会使用ngixn配合gunicorn或者uwsgi来更加高效的处理http请求,因为Flask框架本身(也即是Python语言)处理并发的能力很弱。Flask 类定义了 __call__方法,所以app是一个可调用对象,当接收到请求时,实现了WSGI协议的gunicorn或者uwsgi的worker会调用app来处理请求:
def __call__(self, environ, start_response):
"""Shortcut for :attr:`wsgi_app`."""
return self.wsgi_app(environ, start_response)wsgi_app 方法是整个Flask数据流处理的核心,定义如下,关于wsgi协议相关内容,以及参数的含义可以参考之前的一篇转载:
def wsgi_app(self, environ, start_response):
ctx = self.request_context(environ)
error = None
try:
try:
ctx.push()
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.make_response(self.handle_exception(e))
except:
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)要搞清楚wsgi_app方法中每个步骤的含义,需要先了解Flask中上下文(context)的概念。在使用Flask框架处理请求(实现API)时,通常会使用current_app对象来获取配置信息,使用request对象来获取请求参数信息,而current_app和request作为全局变量,用户不需要考虑处理单元之间(比如线程)的安全问题,实际上在不同处理单元中,current_app和request是相互独立的,当请求到来时,Flask app会创建处理该请求线程的上下文信息,其中current_app和request分别为应用上下文(App Context)和请求上下文(Request Context)。
The application context keeps track of the application-level data during a request, CLI command, or other activity. Rather than passing the application around to each function, the current_app and g proxies are accessed instead.
The application context is created and destroyed as necessary. When a Flask application begins handling a request, it pushes an application context and a request context. When the request ends it pops the request context then the application context. Typically, an application context will have the same lifetime as a request.
The request context keeps track of the request-level data during a request. Rather than passing the request object to each function that runs during a request, the request and session proxies are accessed instead.
When the Flask application handles a request, it creates a Request object based on the environment it received from the WSGI server. Because a worker (thread, process, or coroutine depending on the server) handles only one request at a time, the request data can be considered global to that worker during that request. Flask uses the term context local for this.
在处理请求过程中,app context用于追踪application-level的数据,比如app的config配置信息,request context用于追踪request-level的数据,比如请求的param、method等。当Flask app收到请求时,它会先后push app context和request context,使context当前的处理单元绑定,当请求处理结束之后,Flask app会先后pop request context和app context,解除context与处理单元的绑定并销毁。在一个处理单元中生命周期中,可以将request、session视为全局变量。
在深入了解wsgi_app方法之前,需要先掌握current_app、request、session这些核心数据类型。查看current_app、request、session的定义,会发现在Flask框架中,它们都是LocalProxy类实例:
# flask/global.py
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))LocalProxy 是werkzeug中定义的代理类,它内部重写了 __setitem__ 和 __getitem__ 等元方法,当对LocalProxy实例进行操作时,都会forward到它所代理的对象上,LocalProxy类的定义如下(这里只展示部分):
class LocalProxy(object):
def __init__(self, local, name=None):
object.__setattr__(self, '_LocalProxy__local', local)
object.__setattr__(self, '__name__', name)
if callable(local) and not hasattr(local, '__release_local__'):
object.__setattr__(self, '__wrapped__', local)
def _get_current_object(self):
if not hasattr(self.__local, '__release_local__'):
return self.__local()
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError('no object bound to %s' % self.__name__)
def __getattr__(self, name):
if name == '__members__':
return dir(self._get_current_object())
return getattr(self._get_current_object(), name)
def __setitem__(self, key, value):
self._get_current_object()[key] = value
__setattr__ = lambda x, n, v: setattr(x._get_current_object(), n, v)
__getitem__ = lambda x, i: x._get_current_object()[i]在__init__方法中,通过 object.__setattr__ 定义了一个名为 __local 的实例属性,它的值指向在创建 LocalProxy 时传入的第一个参数,__local 实际就上LocalProxy的代理实现,定义了 __name__ 属性来与 __local 关联。需要注意的是在python中以双下划线的开头的变量或者方法表示私有,_LocalProxy__local 是python语言对于私有变量的一种特殊的访问方式。对私有变量的访问限制,python并没有C++那样严格:
Python performs name mangling of private variables. Every member with double underscore will be changed to _object._class__variable. If so required, it can still be accessed from outside the class, but the practice should be refrained.
对LoalProxy对象的操作,并不直接forward到其 __local 属性上,而是先调用 _get_current_object() 方法,然后将对LocalProxy的操作forward到前者返回结果上。回到current_app、request、和session的定义,会发现它们代理的对象都是方法而非对象,current_app代理的是 _find_app 方法,request和session代理的是 _lookup_req_object 的偏函数。再结合LocalProxy中 _get_current_object() 方法的定义,可以看出,它返回的是这些函数的执行结果,这一点对于Flask中全局变量(current_app、request等)的在处理单元中的相互隔离非常重要,稍后会提到。
接着来看下current_app、request、session代理的方法是如何定义的:
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
def _lookup_app_object(name):
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return getattr(top, name)
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))
g = LocalProxy(partial(_lookup_app_object, 'g'))current_app 代理的方法 _find_app 返回 _app_ctx_stask.top.app,request和session代理的 _lookup_req_object 偏函数分别返回 _request_ctx_stack.top中名为request和session的属性。从命名即可看出,_app_ctx_stack 和 _request_ctx_stack 分别表示上文提到的应用上下问和请求上下文,它们都是LocalStack类型,这是一种后进先出的数据结构,且在栈顶进行操作,定义如下:
class LocalStack(object):
def __init__(self):
self._local = Local()
def __release_local__(self):
self._local.__release_local__()
def _get__ident_func__(self):
return self._local.__ident_func__
def _set__ident_func__(self, value):
object.__setattr__(self._local, '__ident_func__', value)
__ident_func__ = property(_get__ident_func__, _set__ident_func__)
def __call__(self):
def _lookup():
rv = self.top
if rv is None:
raise RuntimeError('object unbound')
return rv
return LocalProxy(_lookup)
def push(self, obj):
rv = getattr(self._local, 'stack', None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
stack = getattr(self._local, 'stack', None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
@property
def top(self):
try:
return self._local.stack[-1]
except (AttributeError, IndexError):
return NoneLocalStack对外提供了push、pop、top三个方法,其内部实现是将操作委托给内部成员 _local ,以 _local.stack 属性来模拟栈的行为,_local 是在初始化时会新建的一个Local类型的成员对象。LocalStack 类中定义了 __call__ 方法,因此它是一个可调用对象。在LocalStack的定义中引入了Local类型,再简单看下Local类的定义(部分):
class Local(object):
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __call__(self, proxy):
return LocalProxy(self, proxy)
def __release_local__(self):
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}Local内部维护了一个名为 __storage__ 的字典结构,其内容都由这个字典结构来进行存储。Local类设计的巧妙之处在于,它定义了一个 __ident_func__ 属性,其值指向get_ident的方法,后者返回一个unique non-zero integer,用以标识当前的处理单元,处理单元可以是线程,也可以是协程(greenlet)。Local类重写了 __getattr__ 和 __setattr__,当访问或修改Local对象属性时,会分别调用这两个方法,且这两个方法都是先通过 __ident_func__ 属性获取到当前处理单元的标识,然后对当前处理单元指向的数据结构(也是字典类型)进行操作。正是因为 __ident_func__ 属性能够标识当前的处理单元,所以在 getter/setter 时,操作的数据只对本处理单元有效,而对其他处理单元不可见,能够保证线程(处理单元)安全,不需要进行加锁或者其他同步操作。
回到Flask框架,在API或者视图函数中会经常使用current_app、request、session这三个全局变量,这里的全局表示在进程的处理单元(比如线程/协程)**享,当以单进程多线程的方式来启动Flask应用时,打印current_app、request、session变量的id,会发现总是相同的,这常常会让初学Flask的人感到非常疑惑(至少我当时是这样的):为什么不同的线程,可以使用同一个变量来读取不同的上下文,处理不同请求,同时不需要处理线程安全问题。原因正是因为这些全局变量在实现时,使用了werkzeug定义的Local相关的数据结构,通过代理或者懒加载的技术与当前处理单元绑定,使接口变得更简单,也能让开发者更专注与业务逻辑的处理。
总结下三个Local数据结构的作用,首先Local类将其内部的存储结构 __storage__ 属性与 __ident_func__ 绑定,使各个处理单元之间的操作互不干扰,相互隔离。LocalStack类内部定义了一个Local类的属性,并将对LocalStack实例的操作forward到其内部Local属性上,因此它也可以实现与Local类似的功能,区别在于LocalStack是一个后进先出的栈类型,所有操作都在栈顶。LocalProxy类的作用是对其代理的对象实现延迟绑定(懒加载)。比如,request是LocalProxy对象,它代理partial(_lookup_req_object, 'request')这个偏函数,当每次访问或操作request时会调用上述的偏函数,返回_request_ctx_stack.top.session,我们已经知道 _request_ctx_stack 是LocalStack类型,所以对它的访问都会绑定到当前处理单元。试想,如果request不通过LocalProxy对象来代理 partial(_lookup_req_object, 'request') 方法,而是直接指向 partial(_lookup_req_object, 'request') 返回的对象:
request = partial(_lookup_req_object, 'request') 那么request的值始终是固定的,即始终指向首次访问它时的 _request_ctx_stack.top.request 。同理,如果session对象也使用上面的方式定义,那么不同处理单元便无法关联其自身上下文session。 下图展示了LocalProxy的运行原理:
再次回到wsgi_app方法,我们来逐一看下它都完成了哪些操作。首先 ctx = self.request_context(environ),就是根据environ环境变量,为当前的处理单元创建一个RequestContext对象,它包含了所有与当前请求相关的信息。接着调用RequestContext的push方法(ctx.push),将其绑定到当前处理单元的上下文,push 方法实现如下:
class RequestContext(object):
# other methods
def push(self):
top = _request_ctx_stack.top
if top is not None and top.preserved:
top.pop(top._preserved_exc)
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
app_ctx = self.app.app_context()
app_ctx.push()
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
_request_ctx_stack.push(self)
self.session = self.app.open_session(self.request)
if self.session is None:
self.session = self.app.make_null_session()我们已经知道 _request_ctx_stack 和 _app_ctx_stack 分别表示请求上下文和应用上下文,那么push方法进行了以下操作:
在绑定请求上下文和应用上下文之后,调用Flask.full_dispatch_request对request进行分发处理:
def full_dispatch_request(self):
self.try_trigger_before_first_request_functions()
try:
request_started.send(self)
rv = self.preprocess_request()
if rv is None:
rv = self.dispatch_request()
except Exception as e:
rv = self.handle_user_exception(e)
return self.finalize_request(rv)通过分析代码,在dispatch方法中,主要进行了如下操作:
在上述步骤执行完成之后,意味着当前处理单元的一次任务结束了,所以 wsgi 方法最后一步使用 ctx.pop 方法,将当前的上下文信息退栈,与入栈(push)相对应。
通过源码分析了Flask处理http请求的过程,简单总结,主要有以下步骤:
用简单的UML图表示如下:
实际上,Flask在处理消息流时,完成的操作比上述更加复杂,比如在处理消息的不同阶段,支持信号量的发送,方便其他模块完成一些异步操作,提高扩展性,比如在绑定AppContext时,会创建request级别的全局变量g,用来支持request级别的数据共享。
离上次post已经过去好久了,直到今天才整理完成一篇新的,文章只有5000字的篇幅,且半数都是源码,但是整理的过程却花费了很多的时间和精力。同时也越发觉得,就技术而言,相较于自己的知晓或者掌握,通过文字的方式记录下来并且能够使他人在阅读时,清晰的理解你所要表达的观点并从中得到收货,这种软技能也是自己所非常欠缺的,以后在这方面还是需要多加锻炼,提高自己的文字能力。
要建立一个Dashboard来进行数据的可视化,需要针对不同的数据,来选择更合适的图表,这样展示的效果更加直观。数据以适合的方式进行展示才更有价值。要建立Dashboard,除了要选择合适的可视化图表之外,考虑它的受众群体同样重要,不同受众所关心的内容不用,需要获取的的信息不同,所以呈现的内容也不同,因此需要了解你的受众,来作出更明智的选择。
这里结合项目中一些的应用场景,来谈谈数据可视化时,图表选择的经验,以及可视化数据背后的analytics api对应的 dimensions 和 metrics 之间的关系。
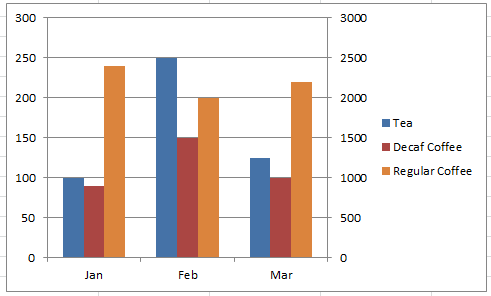

数可视化据分析,还有很多其他的展示方式,以上是我在项目中常用的一些,在今后如果会用到其他的图表,也会更新在这里。
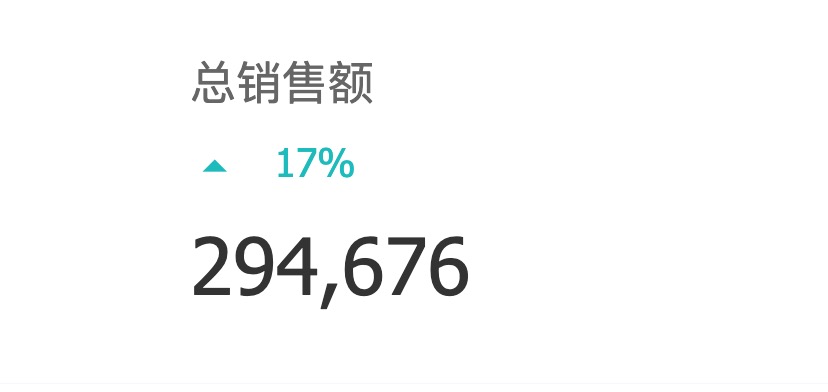
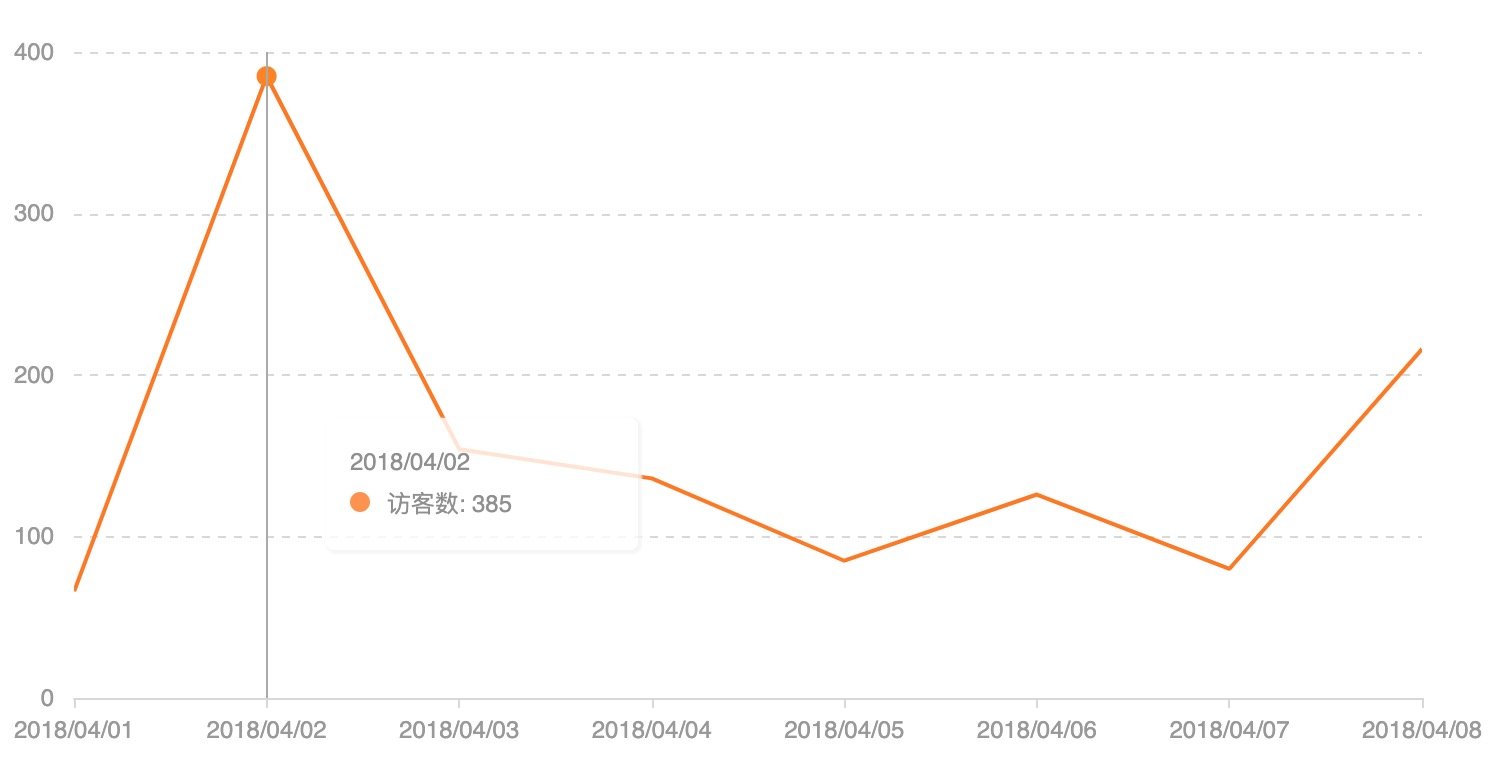
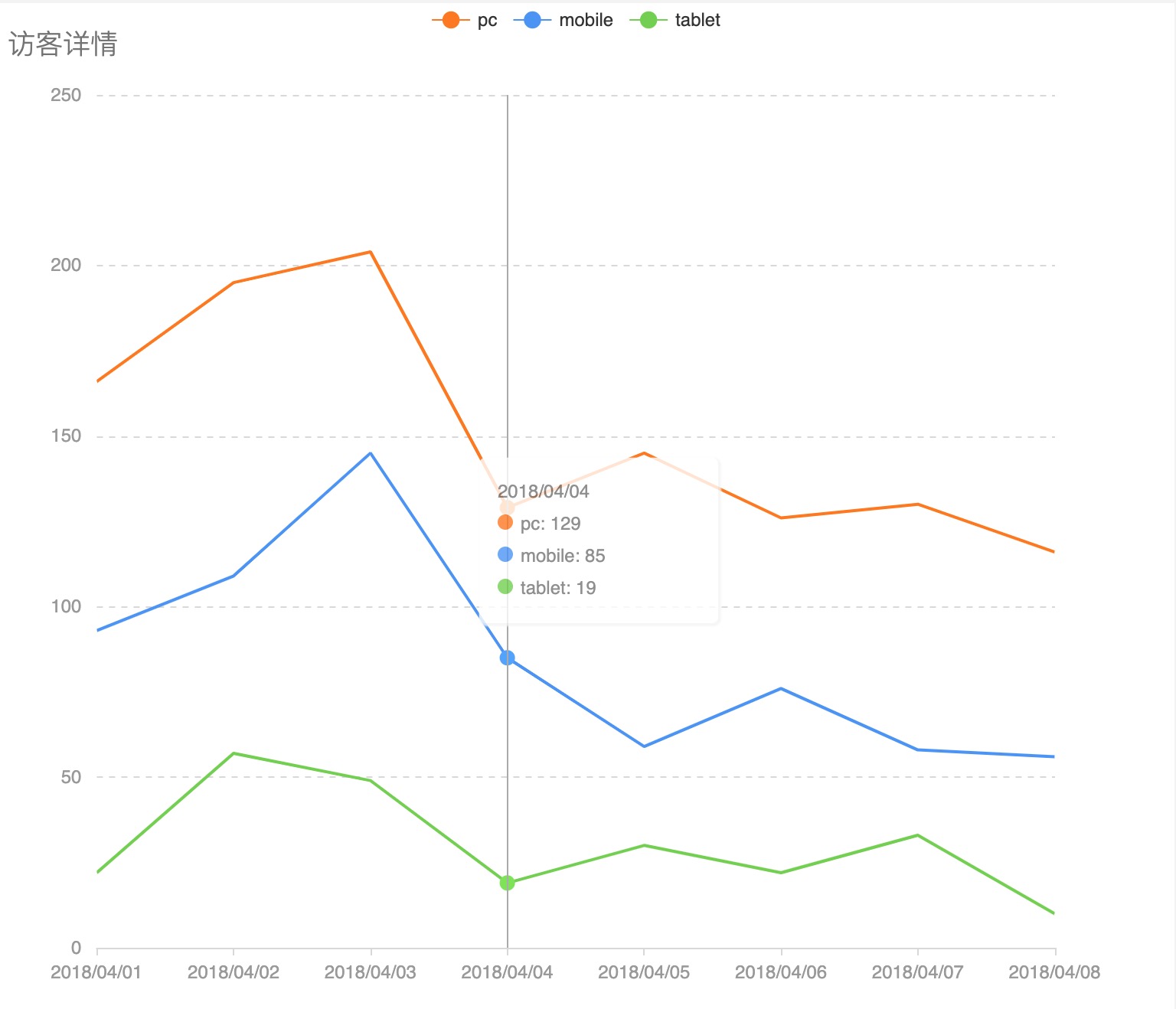
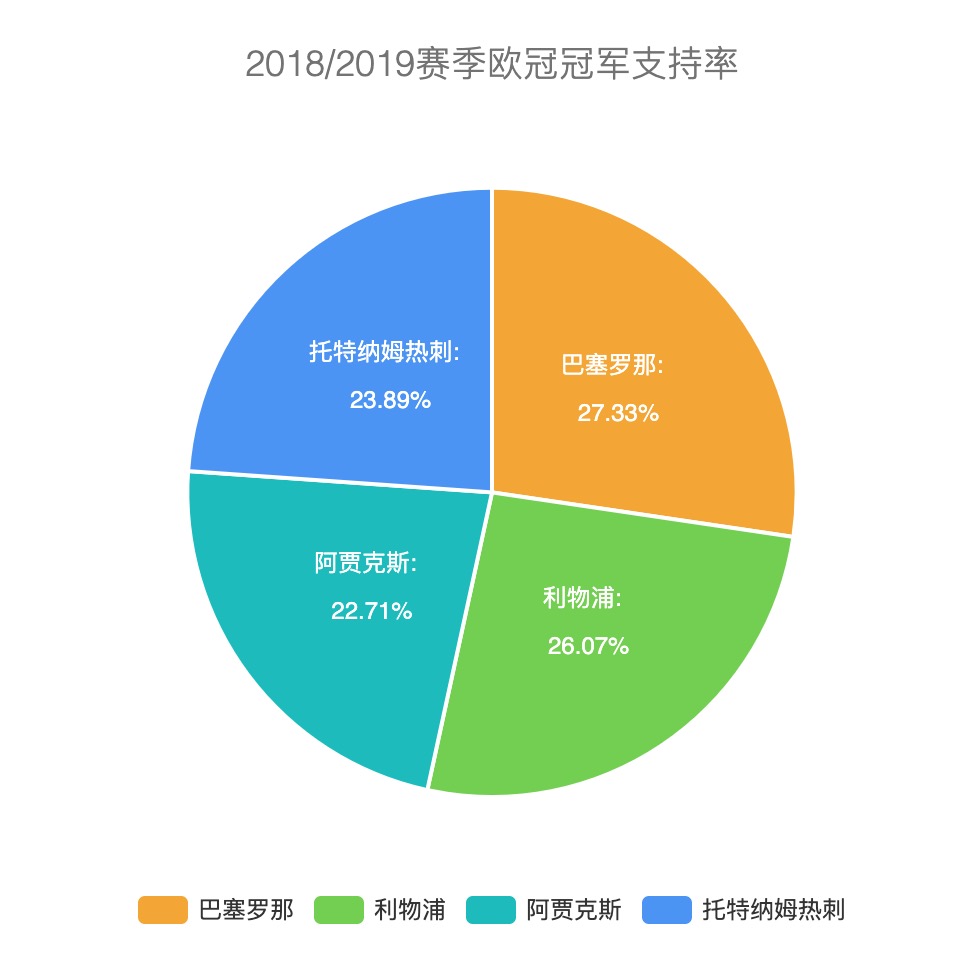
最近一段时间都在做数据平台相关的工作,期间参考Google Analytics API中的一些概念,实现数据平台的analytics-api。GA中最重要的两个概念是dimensions(维度)和metrics(指标),GA Report的展示,大部分都是由dimensions和metrics组合而成的,先来看几个图例:
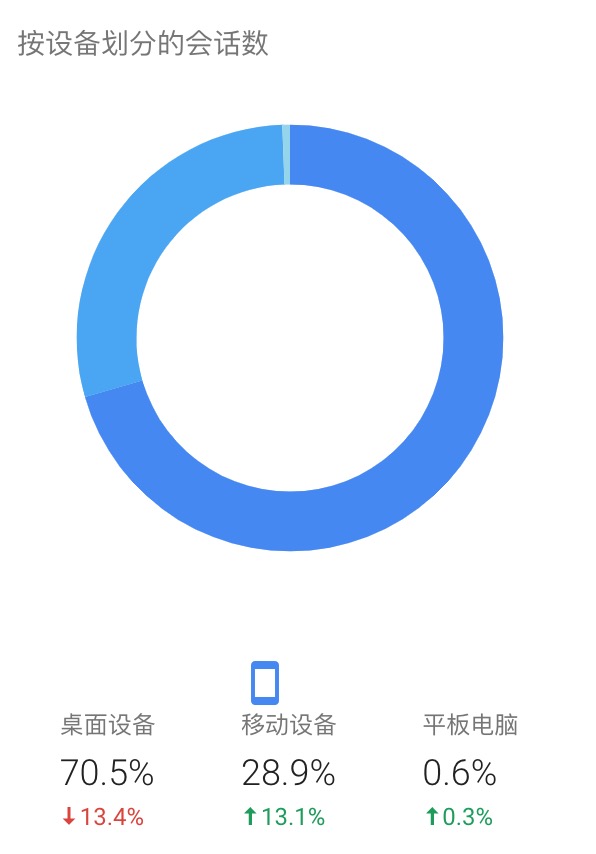
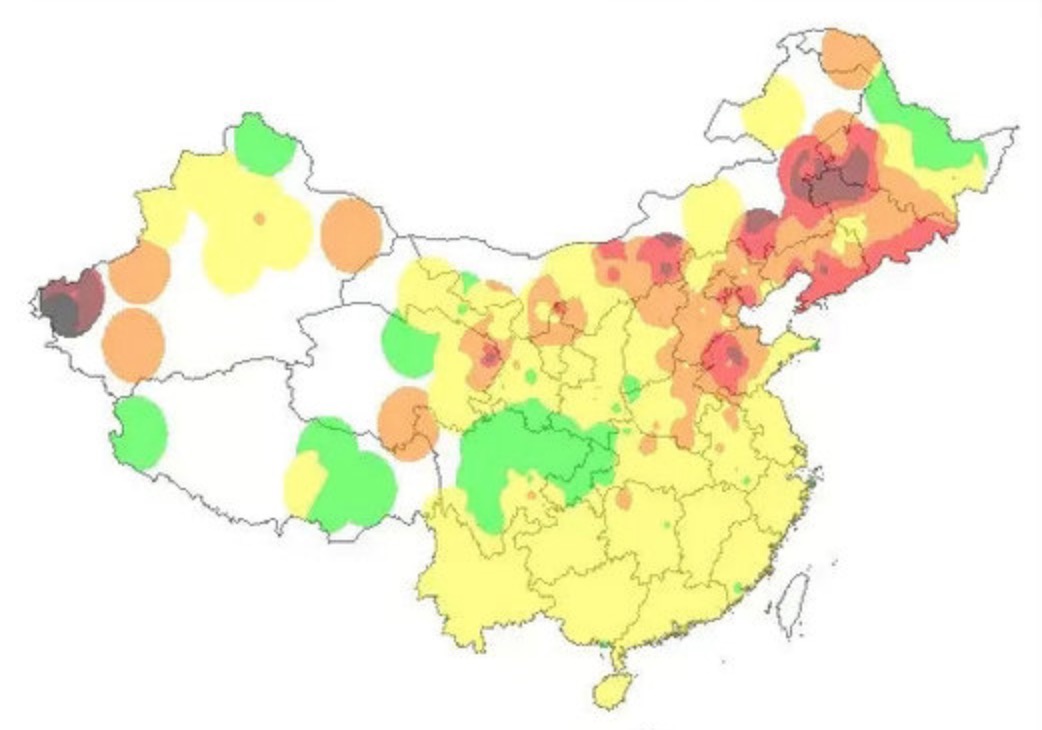
图中展示了网站通过不同设备访问产生的会话数
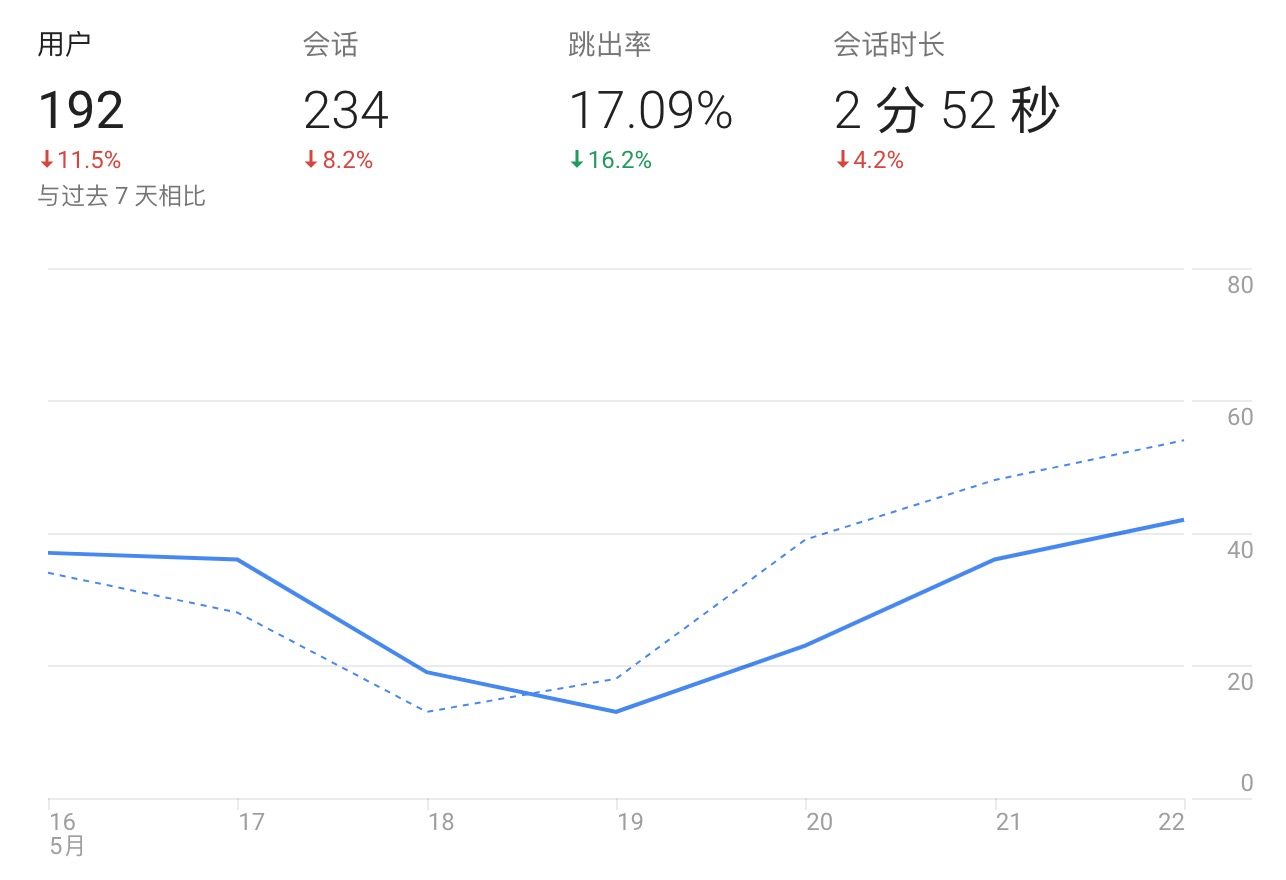
图中展示了网站最近一周每天的流量信息
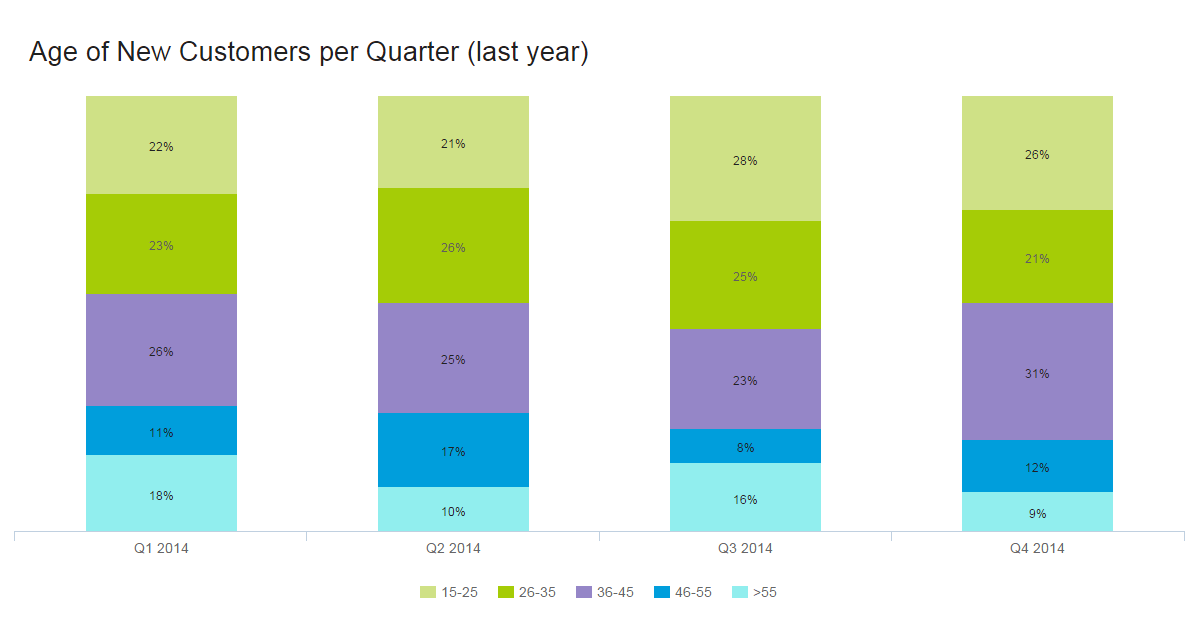
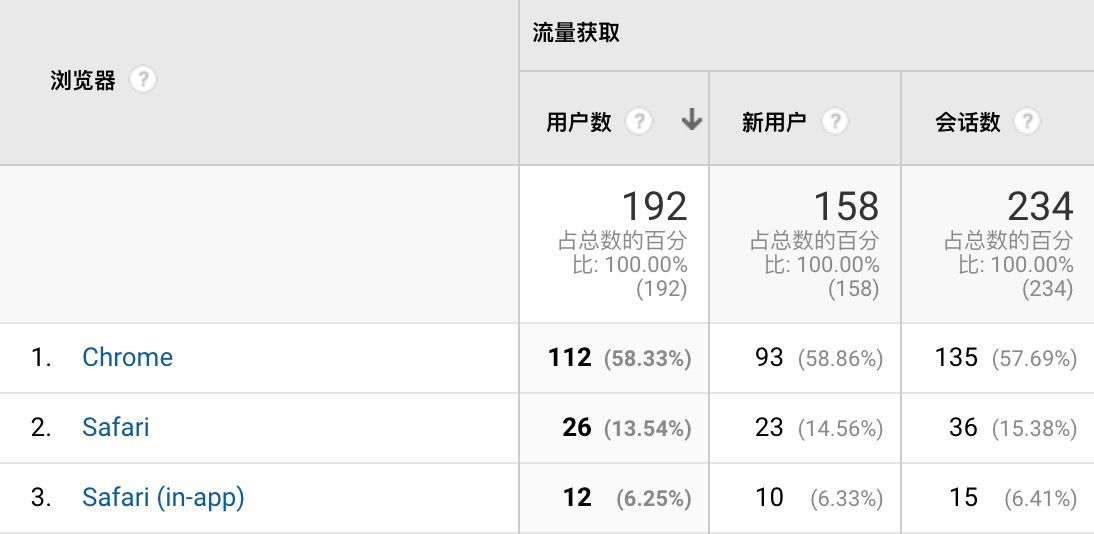
图中展示了网站在不同浏览器访问时产生的流量信息
虽然上面各图的展示方式不同(分别为饼图、折线图、表格),但是从数据分析的角度来看,它们都根据某一dimension的不同分类,聚合算出某一或某些metric的值。比如图一按设备分类,分别计算出桌面、移动和平板的会话数(single metric),图二按天(分类)计算每天的用户数等信息(multiple metrics),图三按浏览器分类,计算出chrome、safiri、app的用户数情况。
对于网站来说,dimensions通常包含用户的一些属性,比如用户的身份、使用的设备、来自于哪里等,而metrics常用来体现用户产生的动作和行为。在数据分析中,metrics是必须的,可以为一个或多个,而dimensions可以不指定,它展示的是metrics的总量,此时往往会加上一个时间区间的filter条件。当有多个dimensions时,次级dimension是其父级在细分的结果,比如下图展示了网站不同角色根据不同设备的访问情况,其次级dimension(设备)的metric之和就是其父级dimension(角色)的metric:
| 角色(dimension) | 设备(次级dimension) | 访问量(metric) |
|---|---|---|
| 学生 | 手机 | 6,379 |
| 电脑 | 14,713 | |
| 教师 | 手机 | 1,822 |
| 电脑 | 6,409 | |
| 管理员 | 手机 | 341 |
| 电脑 | 1,423 |
并非所有dimensions和metrics都可以组合在一起,每个dimension和metric都有各自的范围,只有当它们的范围相同时,组合在一起才有意义。例如,平台中有出勤率的metric,它需要与院系(或者课程)一级的dimension来搭配使用,如果将出勤率与设备或者浏览器等dimension组合,就不合逻辑,让人费解。
当多个dimension可以组合在一起时,metric是dimension一级一级drill down的结果,每一级dimension的metric之和是其上级dimension的metric值。而metric通常来说是独立的,要同时展示多个metric,那么需要metric各自的dimension范围一致,比如访问量、访客数两个指标,都可以通过设备维度进行展示,但是如果要同时展示访问量和出勤率,则无法通过一个表格完成,因为访问量可以从设备dimension计算,但出席率不行。
异常处理时任何一种高级语言都会涉及到的议题。在编码过程中,正确高效的异常处理,来避免一些错误导致的应用程序中止,使得程序更健壮,同时能够更快的定位且修复问题。在Python中通过 try/except/[else]/[finally] 语句来捕获异常,其中 else 和 finally 关键字可以省略。要抛出异常,需要使用 raise 关键字。关于python 中异常处理的更多内容可以查看官方文档,这里不再赘述。
python异常的根类是 BaseException,在标准库中还有四种builtin异常类直接继承自 BaseException,分别是 GeneratorExit,SystemExit,KeyboardInterrupt 以及 Exception 类。其他builtin的异常类,都继承自 Exception,查看python标准库中异常类的层次结构。即使python官方提供了有很多builtin的异常类,但是在编写应用程序时,仍然需要我们自定义与业务相关的异常类。在自定义异常时,
python官方推荐其继承自Exception或者Exception的子类而非BaseException。这是因为Exception表示应用程序中最普遍且并非系统退出导致的异常出错,其他三个BaseException的子类都有特殊的含义,GeneratorExit在生成器执行close()方法抛出的,而它从技术上讲并非是一种错误,KeyboardInterrupt通常在用户执行中断操作如Control-C时抛出的,它继承自BaseException可以避免被捕获Exception的代码意外捕获,从而阻止python解释器的退出,SystemExit在执行sys.exit()方法时抛出,与KeyboardInterrupt一样,它也不会被捕获Exception的代码意外捕获。应用程序在捕获异常时,更关注的是Exception类而非BaseException类,因此自定义的异常应该继承自Exception。
在现实中,应尽量避免直接使用*raise Exception()*来抛出异常,因为它不够具体,没有实际的意义。正确的做法时根据业务逻辑,来自定义不同的异常。我们知道,定义异常需要继承自Exception,定义最简单的异常类:
class MyException(Exception):
"""customize exception"""
pass捕获所有的异常:
try:
do_something()
except Exception:
# catch any exception !
handle_exception()在自定义异常类时,通常需要一些额外信息,来表明当前异常发生的上下文,那么需要来了解下异常类的初始化方法。奇怪的是,尽管通过pycharm查看python typeshed,在builtins.pyi文件中可以找到BaseException和Exception的声明如下(每个Python模块都由扩展名为 .pyi 的 "stub file" 表示,它是一个普通的python文件,只包含模块的公共接口的描述,不包含任何实现,类似于java的接口类):
class BaseException:
def __init__(self, *args: object, **kwargs: object) -> None: ...
class Exception(BaseException): ...实际上异常基类并不支持关键字参数,而只支持位置参数,网上查了下已经有issue了:
In [1]: e = Exception("trivial", error_code=-1)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-67c4664d4f81> in <module>
----> 1 e = Exception(error_code=-1)
TypeError: Exception does not take keyword arguments因此要在自定义的异常类中,调用其基类的初始化方法,不能传递关键字参数。调试程序时,常常使用 print(exception) 来输出异常的内容,print方法会调用异常类的 __str__方法。查看cpython源码,在exception.c文件中找到其定义:
static PyObject *
BaseException_str(PyBaseExceptionObject *self)
{
switch (PyTuple_GET_SIZE(self->args)) {
case 0:
return PyUnicode_FromString("");
case 1:
return PyObject_Str(PyTuple_GET_ITEM(self->args, 0));
default:
return PyObject_Str(self->args);
}
}switch语句决定输出的内容,并且使用到了位置参数args,转化为python语法如下:
def __str__(self):
str_len = len(self.args)
if str_len == 0:
return ""
elif str_len == 1:
return str(self.args[0])
else:
return str(self.args)因此如果要使用默认的 _str_ 输出异常信息时,自定义异常类最好将需要输出的内容以单个参数形式来初始化Exception基类。当然,子类也可以复写基类的 str方法。
当需要异常提供的更多细节时,可以在初始化异常实例时传递更多的参数,如:
class CarError(Exception):
"""Basic exception for errors raised by cars"""
def __init__(self, car, msg=None):
if msg is None:
# Set some default useful error message
msg = "An error occured with car %s" % car
super(CarError, self).__init__(msg)
self.car = car
class CarCrashError(CarError):
"""When you drive too fast"""
def __init__(self, car, other_car, speed):
super(CarCrashError, self).__init__(
car, msg="Car crashed into %s at speed %d" % (other_car, speed))
self.speed = speed
self.other_car = other_car
try:
drive_car(car)
except CarCrashError as e:
# If we crash at high speed, we call emergency
if e.speed >= 30:
call_911()实现一个library时,定义一个继承自Exception的异常基类,会让使用者更容易的捕获从这个library中抛出的任何异常,比如sqlalchemy中的异常定义:
class SQLAlchemyError(Exception):
"""Generic error class."""
class ArgumentError(SQLAlchemyError):
"""Raised when an invalid or conflicting function argument is supplied.
This error generally corresponds to construction time state errors."""
class ObjectNotExecutableError(ArgumentError):
"""Raised when an object is passed to .execute() that can't be
executed as SQL."""
class NoForeignKeysError(ArgumentError):
"""Raised when no foreign keys can be located between two selectables
during a join."""
# other exceptions这样,在使用SQLAlchemy可以简单的通过 except SQLAlchemyError 来捕获任何SQLAlchemy相关的异常。查看sqlalchemy/exc.py,会发现很多异常的定义都很简单,不同的类名代表不同异常抛出的含义,这是因为对不同类型的异常,并非平等对待,事实上更希望以不同的方式来对它们做出反应或者处理。这样就需要不同的 except 语句,来捕获不同的异常,同时要注意except语句的顺序,保证子类异常的捕获总在父类之前。当然,并不需要捕获所有异常,好的做法是只捕获您愿意处理的异常。
在何时何处定义异常并无限制,与其他类型一样,可以定义在任何模块,函数,类甚至闭包中。大部分library将它们的异常类都定义在同一个模块中,比如SQLAlchemy的异常定义在exc.py中,Requests定义在exceptions.py中。在使用这些library时,很容易就能import它们的异常模块,并且在编写处理异常的代码时,知道它们是在何处定义的。这种方式并非强制性的,当library的规模很小时,没有必要将异常与其他模块分割为不同的文件。
一些应用程序往往由不同的子系统组合而成,而每个子系统又有各自的异常模块。这种情况下,将这些子系统的异常统一到同一个模块,比如都放在myapp.exceptions,并不是一种好的做法。例如,当应用程序有两个子系统组成,分别是定义在myapp.http模块的HTTP REST API服务,和定义在myapp.tcp模块的TCP服务。这两个服务都可以定义与自己的协议相关的异常。如果这些异常都定义在一个myapp.exceptions模块,那么只会为了一些无用的一致性,而使得代码分散。如果在子系统中维护各自的异常模块,只需要将它们定义在文件顶部某处,这样会简化代码的维护。
包装异常是将一个异常封装到另一个异常之中的做法。为什么不直接抛出异常,而要在其上封装一层呢?试想当我们在开发自己的lib时,在其中使用了 requests,且未将requests的异常类封装到自定义的lib异常类中,这样就会出现layer violation。任何应用程序在使用到我们定义的lib时,可能会收到 requests.exceptions.ConnectionError类似的异常,这正是问题所在:
因此在任何场合,务必将异常从其他模块封装到自己的异常处理中,就像下面这样:
class MylibError(Exception):
"""Generic exception for mylib"""
def __init__(self, msg, original_exception):
super(MylibError, self).__init__(msg + (": %s" % original_exception))
self.original_exception = original_exception
try:
requests.get("http://example.com")
except requests.exceptions.ConnectionError as e:
raise MylibError("Unable to connect", e)A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

