uolcano / blog Goto Github PK
View Code? Open in Web Editor NEWScriptLife's Blog
License: MIT License
ScriptLife's Blog
License: MIT License











































































































近几天着手在Windows下通过GitHub Pages搭建个人博客,但由于国内网络问题和Windows下安装ruby和bundler的各种证书问题,安装jekyll折腾了好久。无奈,经朋友介绍,通过使用VirtualBox+Vagrant+PuTTY终于可以安装好jekyll并成功搭建示范站点了。本文作为安装记录方便以后有需要的时候再次安装,如能对其他读者有所帮助,不胜荣幸。
**注意:**考虑到国内网络情况,下载box的时候可能会有问题,建议使用迅雷之类的下载工具手动下载box压缩镜像。这里是参考问题和box清单,我这里选择安装的是ubuntu/trusty64系统,版本号是清单中对应的v20160323.1.0,可用的下载链接地址就是:
https://atlas.hashicorp.com/ubuntu/boxes/trusty64/versions/20160323.1.0/providers/virtualbox.box
安装;
开启cmd或者powershell,最好是以管理员权限打开,防止后面vagrant up的时候出状况;
由于不确定init过程中是否会有其他文件释放出来,最好先转到vagrant安装目录下执行(cd ./vagrant),输入以下命令:
vagrant init ubuntu/trusty64
vagrant box add --name BOX virtualbox.box # virtualbox.box是手动下载好的压缩镜像,我是放在vagrant目录下的,如果放在其他地方还要补充完整路径,网络好的情况下可以skip这条
vagrant up # 需要等待挺久的,可以放着干别的事了
vagrant添加box成功后,可以通过vagrant box list查看已经装载的虚拟系统;vagrant装载成功后,可以通过vagrant status查看状态,“running virtualbox”表示正在运行服务,“poweroff”表示已经终止;
使用vagrant ssh-config来查看已经开启的ssh的相关信息,注意一定要是使用vagrant up以后,才会开启服务。记录下相关信息,或者保持这个页面,后面的PuTTY设置需要用。
Vagrant常用命令
vagrant up #启动虚拟机
vagrant halt #关闭虚拟机
vagrant status #查看虚拟机运行状态更多命令可查看Vagrant文档
PuTTY只是一个开启虚拟终端的平台,vagrant可能会推荐使用cygwin/mingw/git等工具,可自己选择,不过我不知道怎么设置主机名和端口。
vagrant ssh-config打印的结果;vagrant,密码不会显示出来,输入完后enter即可。打开终端后,即可使用ubuntu下的linux命令了。如果要使用其他虚拟系统,可以对应box清单,下载对应版本虚拟系统的压缩镜像。
最后,感谢@X!aoTian给与的耐心帮助。
因为虚拟机会占用较大空间建议修改安装路径以及配置BOX的存放路径,详情可参考我的另一篇文章
其实VirtualBox是可以单独载入安装镜像,安装完整的系统
新建虚拟电脑(Ctrl+N),一直下一步;选择新建的虚拟电脑,设置(Ctrl+S),存储->存储树->控制器->添加虚拟光驱(那个有个+号的光碟样图标),从你的电脑里选择一个系统安装盘镜像(ISO)文件添加。最后,最好配置一下,存储空间、内存、显存等等,否则可能会很卡的。
要使用时,只需要打开VirtualBox,选择一个虚拟机打开就可以了。
tags: Vagrant, VirtualBox, PuTTY, Windows, Linux Terminal
前段时间看阮一峰老师的ES6入门的“函数的扩展”部分,发现几个这门语言内置的一些性能优化的功能和算法,觉得挺有意思,想自己试试顺便也总结一下,但是一直没时间,今天抽空来写一写。
尾调优化是为了避免不断保留和创建新的调用栈,而在函数最后一步调用另一个函数。这是ES6才开始出现的概念,常用于尾递归。
最后一步的意义就在于:不需要保留当前函数的执行环境(阮老师的原文讲的是调用帧"call frame",但我的理解是执行环境另一种说法),在调用的下一个函数执行完毕并给出返回值后,直接再返回,类似于pipe。wiki
尾调优化有很多表现形式:
直接作为函数调用
function foo(x) {
return x;
}
function bar(y) {
return foo(y + 1);
}
bar(12);对象方法调用
var obj = { foo: function(x){ return x; } };
function bar(y) {
return obj.foo(y + 1);
}
bar(12);通过函数原型的call或者apply方法来调用函数
function foo(x) {
return x;
}
function bar1(y) {
return foo.call(null, y + 1);
}
function bar2(y) {
return foo.apply(null, [y + 1]);
}
bar1(12);
bar2(12);条件操作符、逻辑操作符和逗号操作符
function t(x){ return x; }
function f(x){ return x; }
function cond (y) {
return y > 0 ? t(y + 1) : f(y - 1); // 两个函数都是尾调
}
function logiAnd (y) {
return t() && f(); // 只有f()是尾调
}
function logiOr (y) {
return f() || t(); // 只有t()是尾调
}
function comma (y) {
return (f(), t()); // 只有t()是尾调
}以上4个操作符简写的尾调形式可以分别等价于如下四个:
function cond (y) {
if(y > 0) {
return t(y + 1);
} else {
return f(y - 1);
}
}
function logiAnd (y) {
if(!t()) {
return f();
}
}
function logiOr (y) {
if(!f()) {
return t();
}
}
function comma (y) {
f();
return t();
}语句中的尾调优化
暂未测试,详情见文末参考链接
尾递归就是利用尾调优化的特性,从语言机制上进行递归操作的优化,防止堆栈溢出(stack overflow)。
好几篇文章都说:尾调优化只有在严格模式下才有效。但是实际上,只不过是arguments和caller不能使用。在chrome和Firefox上测试是否使用严格模式并没有影响到尾调优化的迹象。而且在严格模式下使用ES6的函数默认参数反倒会抛出错误Uncaught SyntaxError: Illegal 'use strict' directive in function with non-simple parameter list。
递归优化,在其他语言——比如C语言,就有递归转迭代的优化,而且递归和迭代是可以相互转换的,但是可能要牺牲空间复杂度,来换取更小的时间复杂度。这个时间复杂度就是递归优化的目的之一。
求自然数阶层:
function factorial (n) {
return n === 1 ? 1 : n * factorial(n - 1);
}经过尾调优化后:
function factorial (total, n) {
return n === 1 ? total : factorial(n * total, n - 1);
}
factorial(1, 5); // 120
factorial(1, 10); // 3628800
factorial(1, 100); // 9.332621544394418e+157
factorial(1, 1000); // Infinity求斐波那契数值:
function fibonacci (n) {
return n <= 1 ? 1 : fibonacci(n - 1) + fibonacci(n - 2);
}
fibonacci(40); // 165580141
// 到n的值为40,浏览器就已经响应很慢了,更大的数值直接就崩了。经过尾调优化后:
function fibonacci (n, ac1, ac2) {
(ac1 = ac1 || 1), (ac2 = ac2 || 1);
return n <= 1 ? ac2 :fibonacci(n - 1, ac2, ac1 + ac2);
}
fibonacci(100); // 573147844013817200000
fibonacci(1000); // 7.0330367711422765e+208
fibonacci(10000); // Infinity经过尾调优化后,每次递归不需要保存其执行环境,只需要将一个末端的递归执行的返回值,逐层返回即可。这样就降低了内存占用,避免了堆栈溢出。
从以上两个例子可以看出,尾调优化后的递归,获取返回值的逻辑是逆向的。
factorial函数的优化版,多了一个前置参数,但是往往不需要每次输入的,所以可以改写一下,封装起来。
将上面尾调优化后的函数名改为tailFactorial
function tailFactorial (total, n) {
return n === 1 ? total : tailFactorial(n * total, n - 1);
}函数内部调用
function factorial (n) {
return tailFactorial(1, n);
}函数柯理化(currying)
function curry (fn, args) {
if(!isArray(args)) args = [args];
return function (params) {
if(!isArray(args)) params = [params];
return fn.apply(this, args.concat(params));
};
}
var factorial = curry(tailFactorial, 1);ES6函数参数默认值
function factorial (n, total = 1) {
if(n === 1) return 1;
return n * factorial(n - 1, n * total);
}递归优化的最佳实现应该是迭代。这里可以看到几种递归优化的对比表。
对上述factorial和fibonacci函数转换为迭代实现。
function factorial (n) {
var fact = 1;
while (n > 1) {
fact *= n--;
}
return fact;
}
function fibonacci (n) {
var ac1, ac2, tmp,
i = ac2 = ac1 = 1;
while(n > i++) {
(tmp = ac2),
(ac2 = ac1 + ac2),
(ac1 = tmp);
}
return ac2;
}从以上代码可以看出:递归的迭代实现,跟递归实现的逻辑完全不同了;并且,每个递归迭代实现必须单独手动实现,没有统一的实现方式或辅助实现方式。
注意: 蹦床函数和尾调优化函数的尾递归优化实现,是在部分不支持尾调优化的情况下的手动实现。
蹦床函数(trampoline)
顾名思义,蹦床函数就是随着递归执行的开始和结束,调用栈会出现入栈、出栈效果,就像是在弹蹦床。
在使用蹦床函数辅助递归时,每次递归执行时都会保留上一次递归的激活对象(执行环境中的变量对象)的引用,执行本次递归完毕后,返回另一个待执行的递归,然后对上一次递归的激活对象的引用也就结束了。
function trampoline (fn) {
while (fn && fn instanceof Function) {
fn = fn();
}
return fn;
}
function factorial (total, n) {
return n === 1 ? total : () => factorial(n * total, n - 1);
}
function fibonacci (n, ac1 = 1, ac2 = 1) {
return n <= 1 ? ac2 : () => fibonacci(n - 1, ac2, ac1 + ac2);
}可以看到其实就是把前面的尾递归改为,返回一个绑定了下一次递归参数的匿名函数。
尾调优化函数
实际上,蹦床函数并非真正的尾递归优化,以下才是:
function tail (fn) {
var value,
active = false,
stack = [];
return function () {
stack.push(arguments);
if(!active) {
active = true;
while (stack.length) {
value = fn.apply(this, stack.shift());
}
active = false;
return value;
}
};
}
var factorial = tail((total, n) => {
return n === 1 ? total : factorial(n * total, n - 1);
});
factorial(1, 5); // 120
var fibonacci = tail((n, ac1 = 1, ac2 = 1) => {
return n <= 1 ? ac2 : fibonacci(n - 1, ac2, ac1 + ac2);
});上述tail函数的精妙之处在于,第一次调用返回的匿名函数(使用时分别赋值给了factorial和fibonacci)时,变量active会“激活”,导致后续每次要进一步递归时都不成功,返回值都是undefined,但是所有这些参数都被推入了stack数组。
因此,在第一次调用后,每次执行递归,都只是进入递归将这次递归接受的参数列表推入stack数组,直接返回而不进入下一轮递归;而返回以后由于stack数组里有一个数组项,通过while循环又处理新的参数列表,所以就会一直这样“进入递归->获得参数列表->返回->进入递归->...”的轮回,直到某轮递归没有向stack数组推入参数。推入的参数在传入每轮递归时都会变化。
尾调优化,实际上就是指在函数内部,调用另一个函数得到的返回值,不用进行其他操作,直接当做自己的返回值返回的特殊情况。
源码可以查看我的Gist
柯理化函数
function isArray (arg) {
return Object.prototype.toString.call(arg).slice(8, -1) === 'Array';
}
function curry (fn, args) {
if(!isArray(args)) args = [args];
return function (params) {
if(!isArray(args)) params = [params];
return fn.apply(this, args.concat(params));
};
}蹦床函数
function trampoline (fn) {
while (fn && fn instanceof Function) {
fn = fn();
}
return fn;
}尾调优化函数
function tail (fn) {
var value,
active = false,
stack = [];
return function () {
stack.push(arguments);
if(!active) {
active = true;
while (stack.length) {
value = fn.apply(this, stack.shift());
}
active = false;
return value;
}
};
}tags: tail-call optimization, tail-recursion
git虽好,但总会遇到一些不希望的提交,所以就会有增删改某次或某些提交的需求。下面收集一下,修改本地和远程版本历史的一些方法。
由于以下修改本身是对版本历史的修改,在需要push到远程仓库时,往往是不成功的,只能强行push,这样会出现的一个问题就是,如果你是push到多人协作的远程仓库中,会对其他人的远程操作构成影响。通常情况下,建议与项目远程仓库的管理员进行沟通,在完成你强制push操作后,通知其他人同步。
修改最近一次的commit
修改提交的描述
git commit --amend然后会进入一个文本编辑器界面,修改commit的描述内容,即可完成操作。
修改提交的文件
git add <filename> # 或者 git rm
git commit --amend # 将缓存区的内容做为最近一次提交修改任意提交历史位置的commit
可以通过变基命令,修改最近一次提交以前的某次提交。不过修改的提交到当前提交之间的所有提交的hash值都会改变。
变基操作需要非常小心,一定要多用git status命令来查看你是否还处于变基操作,可能某次误操作的会对后面的提交历史造成很大影响。
首先查看提交日志,以便变基后,确认提交历史的修改
git log变基操作。 可以用commit~n或commit^^这种形式替代:前者表示当前提交到n次以前的提交,后者^符号越多表示的范围越大,commit可以是HEAD或者某次提交的hash值;-i参数表示进入交互模式。
git rebase -i <commit range>以上变基命令会进入文本编辑器,其中每一行就是某次提交,把pick修改为edit,保存退出该文本编辑器。
**注意:**变基命令打开的文本编辑器中的commit顺序跟git log查看的顺序是相反的,也就是最近的提交在下面,老旧的提交在上面
**注意:**变基命令其实可以同时对多个提交进行修改,只需要修改将对应行前的pick都修改为edit,保存退出后会根据你修改的数目多次打开修改某次commit的文本编辑器界面。但是这个范围内的最终祖先commit不能修改,也就是如果有5行commit信息,你只能修改下面4行的,这不仅限于commit修改,重排、删除以及合并都如此。
git commit --amend接下来修改提交描述内容或者文件内容,跟最近一次的commit的操作相同,不赘述。
然后完成变基操作
git rebase --continue有时候会完成变基失败,需要git add --all才能解决,一般git会给出提示。
再次查看提交日志,对比变基前后的修改,可以看到的内的所有提交的hash值都被修改了
git log如果过了一段时间后,你发现这次历史修改有误,想退回去怎么办?请往下继续阅读
重排或删除某些提交
变基命令非常强大,还可以将提交历史重新手动排序或者删除某次提交。这为某些误操作,导致不希望公开信息的提交,提供了补救措施
git rebase -i <commit range>如前面描述,这会进入文本编辑器,对某行提交进行排序或者删除,保存退出。可以是多行修改。
后续操作同上。
合并多次提交
非关键性的提交太多会让版本历史很难看、冗余,所以合并多次提交也是挺有必要的。同样是使用以上的变基命令,不同的是变基命令打开的文本编辑器里的内容的修改。
将pick修改为squash,可以是多行修改,然后保存退出。这个操作会将标记为squash的所有提交,都合并到最近的一个祖先提交上。
**注意:**不能对的第一行commit进行修改,至少保证第一行是接受合并的祖先提交。
后续操作同上。
分离某次提交
变基命令还能分离提交,这里不描述,详情查看后面的参考链接
终极手段
git还提供了修改版本历史的“大杀器”——filter-branch,可以对整个版本历史中的每次提交进行修改,可用于删除误操作提交的密码等敏感信息。
删除所有提交中的某个文件
git filter-branch --treefilter 'rm -f password.txt' HEAD将新建的主目录作为所有提交的根目录
git filter-branch --subdirectory-filter trunk HEAD回退操作也是对过往提交的一剂“后悔药”,常用的回退方式有三种:checkout、reset和revert
checkout
对单个文件进行回退。不会修改当前的HEAD指针的位置,也就是提交并未回退
可以是某次提交的hash值,或者HEAD(缺省即默认)
git checkout <commit> -- <filename>reset
回退到某次提交。回退到的指定提交以后的提交都会从提交日志上消失
**注意:**工作区和暂存区的内容都会被重置到指定提交的时候,如果不加--hard则只移动HEAD的指针,不影响工作区和暂存区的内容。
git reset --hard <commit>结合git reflog找回提交日志上看不到的版本历史,撤回某次操作前的状态
git reflog # 找到某次操作前的提交hash值
git reset <commit>这个方法可以对你的回退操作进行回退,因为这时候git log命令已经找不到历史提交的hash值了。
revert
这个方法是最温和,最受推荐的,因为本质上不是修改过去的版本历史,而是将回退版本历史作为一次新的提交,所以不会改变版本历史,在push到远程仓库的时候也不会影响到团队其他人。
git revert <commit>对远程仓库的版本历史修改,都是在本地修改的基础上进行的:本地修改完成后,再push到远程仓库。
但是除了git revert可以直接push,其他都会对原有的版本历史修改,只能使用强制push
git push -f <remote> <branch>git commit --amend改写单次commit
git rebase -i <commit range>删改排以及合并多个commit
git checkout <commit> -- <filename>获取历史版本的某个文件
git reset [--hard] <commit>移动HEAD指针
git revert <commit>创建一个回退提交
git push -f <remote> <branch>强制push,覆盖原有远程仓库
tags: git
之前上网瞎逛的时候,发现的一个挺好的自动布局绘图工具Graphviz。倒腾了一番,写下一些笔记,方便以后复习。
Graphviz全称Graph Visualization Software,最早出自AT&T实验室,是基于DOT语言脚本的自动绘图软件。是开源且免费的软件。
相对于ms viso需要手动拖动图标,graphviz只需要通过DOT代码表达各节点的逻辑关系,然后自动布局和输出关系图。最小化复杂关系的连线交叉,增强可读性。
尤其在绘制非常复杂的逻辑关系、组织架构、模块组成、数据结构等图时,可以大大减少工作量,理清思路。
无法绘制需要自定义或者固定布局的图,比如时序图。
官网提供安装包和源码包两种安装方式。安装完成后,最好是将graphviz安装目录下的bin目录设置到环境变量中,以便于随处使用dot命令行。
# windows 设置环境变量
SETX /M PATH "%PATH%;E:\your\graphviz\path\bin"
# 安装和设置完成后,可打开dot命令行帮助提示,验证成功安装
dot -hGraphviz支持两种文件扩展名:*.gv和*.dot,使用*.gv是为了防止与早期的ms word的扩展名冲突。
后文中的DOT文件即表示输入graphviz处理的文件。
Graphviz支持的输出文件格式:
DOT文件可以用任何文本编辑器编辑。但是graphviz自带一个及时输出图像的软件gvedit,软件打开DOT文件,然后按F5及时得到输出图像。这种“所见即所得”的编辑体验非常棒。
在命令行中输入gvedit可打开这个编辑器。
当然,有些Unix/Linux上可以使用的编辑器也支持graphviz及时编辑与输出,比如Emacs的graphviz dot mode和VI/VIM插件
Graphviz除了DOT语言用于描述图像,还有许多渲染生成工具 —— 布局器:
dot -Tv -Kv -O abc.gv这里的-Tv中的v可用graphviz支持的输出格式代替,如:-Tpng、-Tjpg等等。
而-Kv中的v可用布局器代替,如:-Kfdp、-Kcirco等等。dot是默认布局器,因此可以省略-Kv这部分参数。
-O表示自动根据输入文件名来给输出文件命名。
abc.gv即使输入的DOT文件
可以通过dot -h或dot -?来获得命令行帮助
digraph abc {
a -> b;
b -> c;
b -> d;
}
保存为abc.gv
dot -Tpng -O abc.gv利用命令行以dot布局器(默认),输出同名的png格式图像abc.gv.png
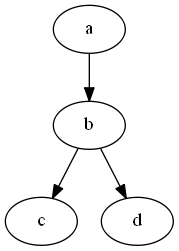
节点示例
digraph node_intro {
graph [label="节点示例 ", fontname="Microsoft Yahei"];
node [fontname="Microsoft Yahei"];
shape1 [shape=box, label="矩形 "];
shape2 [shape=circle, label="圆形 "];
shape3 [shape=ellipse, label="椭圆 "];
shape4 [shape=polygon, sides=4, skew=0.4, label="平行四边形 "];
shape5 [shape=diamond, label="菱形 "];
shape6 [shape=record, label="{记录1|记录2|记录3}"];
shape7 [shape=none, label="无边框 "];
shape1:s -> shape2 -> shape3 -> shape4 -> shape5 -> shape6 -> shape7;
color1 [color=blue, label="蓝色边框 "];
color2 [style=filled, fillcolor=green, label="绿色填充 "];
color3 [color="#0000ff", style=filled, fillcolor="green:red", label="蓝色边框\n+\n由绿到红渐变色填充 "];
color1 -> color2 -> color3;
text1 [shape=box, fontsize=12, label="小字体 "];
text2 [shape=box, fontsize=24, label="大字体 "];
text3 [shape=box, fontcolor=blue, label="蓝色字体 "];
text4 [shape=box, label=<
<table bgcolor="#aa99ff" align="center">
<tr>
<td colspan="3" width="20"><font point-size="24">类HTML标签 </font></td>
</tr>
<tr>
<td color="red"><b>加粗 </b></td>
<td color="green"><u>下划线 </u></td>
<td color="blue"><i>斜体 </i></td>
</tr>
</table>
>];
text1 -> text2 -> text3 -> text4;
}

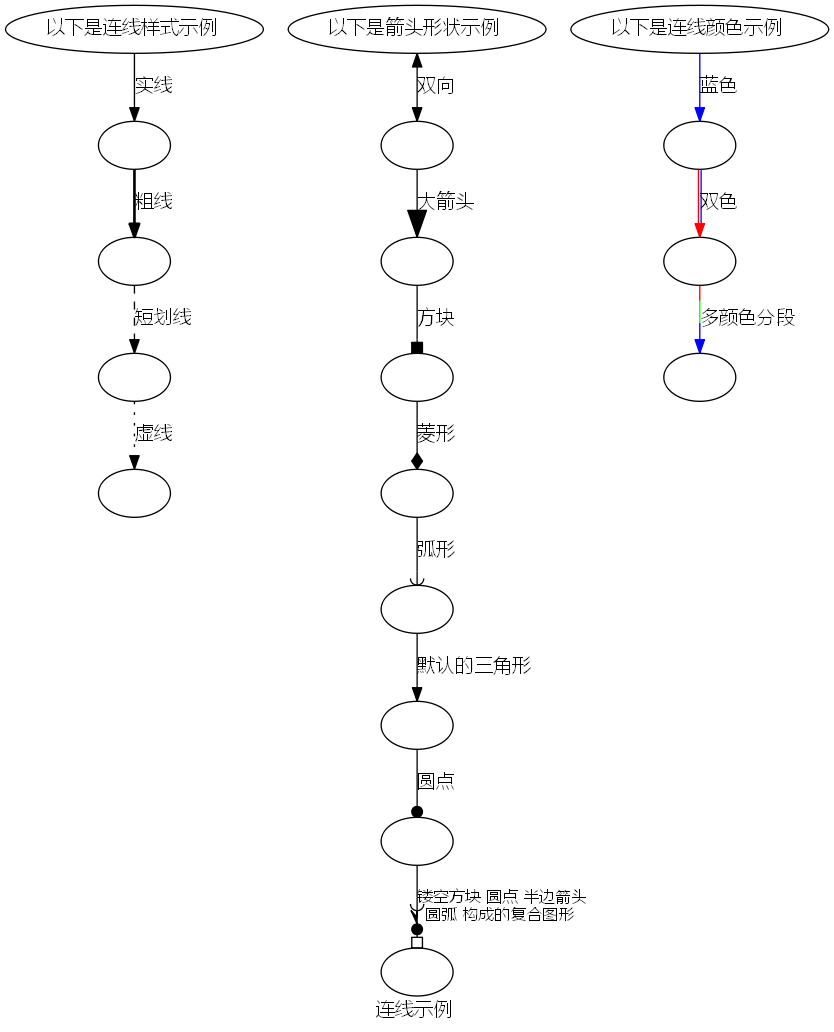
连线示例
digraph edge_intro {
graph [label="连线示例 ", fontname="Microsoft Yahei"];
edge [fontname="Microsoft Yahei"];
node [fontname="Microsoft Yahei"];
style0 [label="以下是连线样式示例 "];
style1, style2, style3, style4 [label=""];
style0 -> style1 [style=solid, label="实线 "];
style1 -> style2 [style=bold, label="粗线 "];
style2 -> style3 [style=dashed, label="短划线 "];
style3 -> style4 [style=dotted, label="虚线 "];
arrow0 [label="以下是箭头形状示例 "];
arrow1, arrow2, arrow3, arrow4, arrow5, arrow6, arrow7, arrow8 [label=""];
arrow0 -> arrow1 [dir=both, label="双向 "];
arrow1 -> arrow2 [arrowsize=2, label="大箭头 "];
arrow2 -> arrow3 [arrowhead=box, label="方块 "];
arrow3 -> arrow4 [arrowhead=diamond, label="菱形 "];
arrow4 -> arrow5 [arrowhead=curve, label="弧形 "];
arrow5 -> arrow6 [arrowhead=normal, label="默认的三角形 "];
arrow6 -> arrow7 [arrowhead=dot, label="圆点 "];
arrow7 -> arrow8 [arrowhead=oboxdotrveecurve, label="镂空方块 圆点 半边箭头\n圆弧 构成的复合图形 ", fontsize=12];
color0 [label="以下是连线颜色示例 "];
color1, color2, color3 [label=""];
color0 -> color1 [color=blue, label="蓝色 "];
color1 -> color2 [color="red:blue", label="双色 "];
color2 -> color3 [color="red:green;0.4:blue", label="多颜色分段 "];
}
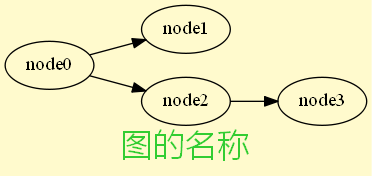
图示例
digraph graph_intro {
graph [bgcolor=lemonchiffon, fontsize=24, fontcolor=limegreen, rankdir=LR, fontname="Microsoft Yahei", label="图的名称"];
node0 -> {node1, node2};
node2 -> node3;
}
【注意】后文中的示例大多需要通过命令行DOT或者gvedit输出图像,不再外加说明。
DOT只有图graph、节点node和连线edge三个主要结构。graph、node和edge三个关键字还能用于全局属性定义,后面细讲。
图分为有向图和无向图。无向图声明的时候使用关键字graph,有向图使用digraph。
node:定义全局节点属性时使用edge:定义全局连线属性时使用graph:定义全局图属性,或声明一个无向图时使用digraph:声明一个有向图时使用subgraph:声明一个子图时使用,如果父图是有向图则子图是有向图,如果父图是无向图则子图也是无向图strict:用于防止相同的两个节点间使用重复的连线。ID是编辑者自定义的字符串,相当于C语言中的标识符。
[a-zA-Z\200-\377],下划线_,数字[0-9](但不能数字开头),如:Version_3;[-]?(.[0-9]+|[0-9]+(.[0-9]*)?),如:-.1或1.414;"...",字符串中的双引号需要转义\",如:"DOT language";<...>,如:<<b>Welcome</b> <u>to</u> <i>China.</i>>;实际上甚至可以插入表格。HTML-Like LabelsID主要是作为图和节点的命名字符串
graph ID{
label="A empty graph";
}
简单的DOT代码中的图名ID可以省略,这就有了匿名图
graph {
a_node [label="this is a anonymous graph"]
}
作为子图的图的ID一定要以cluster开头命名,否则graphviz不识别。
因为父图的图ID和子图的图ID,共享相同命名空间,父图和子图、子图与子图间的图的ID命名一定要不同。
digraph abcd{
subgraph cluster_ab{
bgcolor=mintcream;
a b;
}
subgraph cluster_cd{
bgcolor=chartreuse;
c d;
}
a -> b;
b -> c -> d;
}
【注意】如果ID中间包含空格一定要用双引号包裹。
DOT支持类似C++的注释,单行注释//,多行或部分注释/*和*/。
分号;和逗号,都不是必须的,可以用空格替代。
竖杠|在节点的属性shape=record时,作为划分分组内部的分隔符。后面有举例
长字符串换行,类似C语言,如:
graph {
greeting [label="hello \
everyone, \
welcom \
to China.
"];
}
DOT还支持拼接操作符+,如:
graph {
"hello "+"world, "+"welcome";
}
【注意】这里描述的字符串都是指以双引号"包裹的
字符串中的字符,只有双引号\"和反斜杠\\需要转义。
字符串支持还HTML式的实体符号,如:&表示&,<表示<,β表示β。
当节点的属性shape=record时,竖杠\|、花括号\{ \}、方括号\[ \]和尖括号\< \>都需要转义。
前面介绍了两种包裹字符串的符号,双引号"..."和<...>;
另外还有两种包裹分组的符号:方括号[...]和花括号{...}。
用于属性定义,给图、节点和连线添加各种样式。如:
digraph {
graph [label="graph with styles", bgcolor=mintcream, fontsize=24, fontcolor=green];
a [color=blue, fontsize=12, style=filled, fillcolor=yellow];
}
用法1,图的声明,,包括有向、无向图以及子图的声明
graph {
a -- b -- c;
}
用法2,某个节点连接到多个节点时的简写方式
digraph {
a -> {b c d};
}
用法3,只有在节点的属性shape=record时,包裹节点内部的分组
digraph {
node [shape=record];
group1 [label="{a|b|c}"];
group2 [label="{x|{α|β|γ|{L|M|N}}|y|z}"];
}
一个图的声明,需关键字graphv或digraphv和{...}两部分
digraph {
// 这里添加节点声明、连线声明以及图、节点和连线的属性设置
}
另外,在关键字graph或digraph前面可以添加一个空格隔开的关键字strict用来防止两节点间重复连线
strict graph {
a -- b;
a -- b [label="repetitive edge", style=bold];
b -- c;
a -- b [color=red, style=dashed];
}
节点可以不声明直接在连线声明时使用。
一般提前声明节点的情况有两种:
给节点定义属性
graph {
a, b [color=red];
a -- b;
}
节点被分组到子图中
graph {
subgraph cluster {
a, b;
}
a -- b;
}
连线的声明需要连接两个节点。
对于有向图,连线使用->;无向图,连线使用--。
digraph {
a -> b;
}
graph {
c -- d;
}
两种连线都可以简写
digraph {
a -> b -> c -> d;
}
等价于
digraph {
a -> b;
b -> c;
c -> d;
}
属性定义可以给节点、连线和图渲染上不同的样式,使得最终得到的关系图更加美观,提升可读性。
属性均是以名值对attr=val的方式出现。属性值val,可用双引号或尖括号包裹,但是可选的;不过,如果属性值中间包含DOT无法直接解析的字符,就必须用双引号或尖括号包裹,甚至转义。
图
直接定义
graph {
label="A graph directly \ndefined attributes";
bgcolor=skyblue;
fontname="Microsoft Yahei";
fontsize=24;
rankdir=LR;
a -- b -- c -- a;
}
使用关键字graph
graph {
graph [label="an undirected graph"];
a -- b -- c -- a;
}
节点
使用关键字node
digraph {
graph [label=<<b>styled</b> graph> fontname=Vardana fontsize=20];
node [shape=doublecircle, style=filled, fillcolor=orange];
a -> {b d};
b -> c;
}
连线
使用关键字edge
digraph {
edge [style=bold, color=blue:red];
a -> {b d};
b -> c;
}
局部设置属性,除了可以对一个一个的节点或者连线设置,也可以同时对多个节点或者多个连线进行设置
节点
graph {
a, b [shape=Mdiamond];
c [shape=doublecircle];
a -- c -- b;
}
连线
digraph {
a -> {b d} [arrowhead=olnormalol];
b -> c [style=dashed, color=red, arrowhead=obox];
}
可用于节点、连线和图的名称设置,如:
graph {
graph [label=G];
edge [label=E];
node [label=N];
a -- b -- {c, d};
e[color=red];
}
属性值的形式:"val"、<val>和val。
用于节点的形状修改,如:
graph {
a [shape=doublecircle];
b [shape=polygon, skew=0.6];
c [shape=diamond];
a -- {b, c};
}
常用属性值:box矩形、circle圆形、polygon多边形、ellipse默认的椭圆、record记录式、diamond菱形等等。
其中shape=polygon结合倾斜度属性skew=0.4可以将节点设置成平行四边形;shape=record可以将节点设置成记录表的样式。
用于节点样式和连线样式设置,如:
graph {
node [style=filled];
a [fillcolor="green:red"];
b, c [fillcolor=skyblue];
a -- b [style=dashed];
a -- c [style=dotted];
}
常用属性值:
filled填充节点背景色,需要结合填充色属性fillcolor;solid默认的实线、bold粗线、dashed短划线、dotted虚线。设置节点边框线颜色和连线颜色,如:
graph {
a, b [color=blue];
c [color=red];
a -- b [color=green];
a -- c [color=yellow];
}
颜色值有3种形式:
red green blue yellow orange navy white black等等"#ff0000"等同于red,注意因为DOT不直接识别#,一定要用双引号或尖括号包裹"red:blue"和"red:green;0.4:blue",同样因为不直接识别:,需要包裹成字符串用于填充图的背景色,如:
graph {
bgcolor=yellow;
subgraph cluster {
bgcolor="green:red";
a b;
}
a -- b -- c;
}
属性值类似color,但是渐变色只支持2种色构成的渐变。
用于填充节点的背景色,用法同bgcolor
可设置节点、连线和图的ID的字体,相当于CSS中的font-family。
【注意】使用中文时,fontname一定要设置系统支持的中文字体,否则graphviz输出图片的中文会乱码。而且,图的名称、连线的名称以及节点的名称只要使用了中文就都应该设置fontname属性,比如:fontname="Microsoft Yahei"。另外,最好是在中文字符后留有一个空格,防止乱码后,英文字符也被修改。
设置节点、连线和图的字体大小,属性值可以是纯数字或者是数字字符串
设置字体的颜色,用法类似color,但是不支持渐变色
设置图的绘制方向,如:
digraph {
rankdir=LR;
subgraph cluster {
b, c;
}
a -> b -> c;
a -> d;
}
属性值: 默认由上至下TB、由下至上BT、由左至右LR和由右至左RL
设置连线的箭头方向,如:
digraph {
rankdir=LR;
client [shape=tab];
server [shape=box3d];
client:e -> server:w [dir=both, style=bold, color="blue:green", arrowhead=r, arrowtail=r];
}
属性值:向前forward(有向图默认)、向后back、双向both以及无none(无向图默认)
设置无向图或有向图的连线头部箭头形状,如:
digraph {
a -> b [arrowhead=curve]
}
属性值:箭头形状有很多变种,而且可以同时设置多个形状,基本组合是[是否镂空][左右边][基础形状]。字母o决定箭头形状是否镂空open,l和r分别表示只出现左边left和右边right,基础形状有box、crow、curve、icurve、diamond、dot、inv、none、normal、tee以及vee。
graph {
a -- b [dir=both, arrowtail=curve, arrowhead=teeoldiamond];
}
解读teeoldiamond:第一个形状tee紧跟着第二个形状是镂空的o取左边的l钻石形状diamond。
设置无向图或有向图的连线尾部箭头形状,与arrowhead用法相同
设置连线箭头大小
digraph {
a -> b [arrowsize=2];
}
节点上的端口,类似于指针。在节点上确定端口以后,再连接两个节点时可以找到节点上准确的位置。
罗盘也就是确定八个方位,罗盘端口就是方位端口。
方位端口是每个节点隐藏自带的,可以直接使用。
每个节点都有八个方位:北n、东北ne、东e、东南se、南s、西南sw、西w和西北nw。
利用方位可以指定连线从哪个位置连接节点,如:
digraph {
node [shape=box];
subgraph cluster {
c, d;
}
a:e -> b:n;
a:nw -> c:n;
c:w -> d:sw;
b:sw -> d;
}
不同于默认情况下的自动连线,利用方位可以手动指定连线的位置。
命名端口需要在节点中手动设置端口,并且位置命名。
一般在节点的属性shape=record时,对于节点内分组中的单元进行端口设置。
digraph {
rankdir=LR;
fontsize=12;
node [shape=record];
struct1 [label="{<head>* int|float|<next>* int}"];
struct2 [label="{<prev>int|* char|<next>* int}"];
struct3 [label="{<prev>int|* char|* int}"];
struct1:next -> struct2:prev;
struct2:next -> struct3:prev;
struct1:head:s -> int;
}
struct1:next中的next和struct2:prev中的prev都是命名端口,通过这两个端口可以将节点struct1的* int单元与节点struct2的int单元连接起来。而struct1:head:s则即使用了命名端口head,又使用了罗盘端口s。
以上可以看出,命名端口的设置出现在节点声明时,使用尖括号<...>包裹,命名端口和罗盘端口都是在节点ID后面加冒号:来引用。
主要是指子图会从父图继承图、连线和节点的所有属性定义
digraph abc{
graph [bgcolor=pink];
edge [color=blue];
node [shape=hexagon];
a -> b;
subgraph cluster {
c -> d;
}
b -> c;
}
DOT中的属性可以多次定义,后面定义的会覆盖前面定义的。
但是要注意如果一个声明在两个属性定义之间,声明的节点或者连线只会获得前一个属性定义。
digraph {
node [shape=doublecircle, fontcolor=blue];
edge [style=bold, color=blue];
a b e;
a -> b;
node [shape=box3d];
edge [style=dotted, color=red];
a -> c ->d;
c -> e;
}
节点a、b和e获得了属性shape=doublecircle,而节点c和d的属性被覆盖为了shape=box3d,但是五个节点有相同的属性fontcolor=blue。可见shape属性被覆盖了。同理,连线a -> c -> d的属性style=bold也被style=dotted覆盖,而a -> b却没有变。
当然图的属性定义也能覆盖,不过是父图与子图之间
digraph abc{
graph [bgcolor=pink];
edge [color=blue];
node [shape=box];
subgraph cluster1 {
graph [bgcolor=chartreuse];
edge [color=red];
node [shape=hexagon];
a -> b;
}
subgraph cluster2 {
c -> d;
}
b -> c;
}
对比cluster1和cluster2两个子图,前者把父图abc定义的图、连线和节点的属性全部覆盖了;而后者是继承自父图。
另外,匿名子图还能够在视觉上不出现子图效果的情况下,覆盖父图定义的属性
digraph {
graph [bgcolor=pink];
edge [color=blue];
node [shape=triangle];
a;
subgraph {
node [shape=tripleoctagon];
b;
}
c;
node [shape=doublecircle];
d;
a -> b -> {c d};
}
很明显,这里的节点b的shape属性被修改为了tripleoctagon,而节点c却没有被修改。
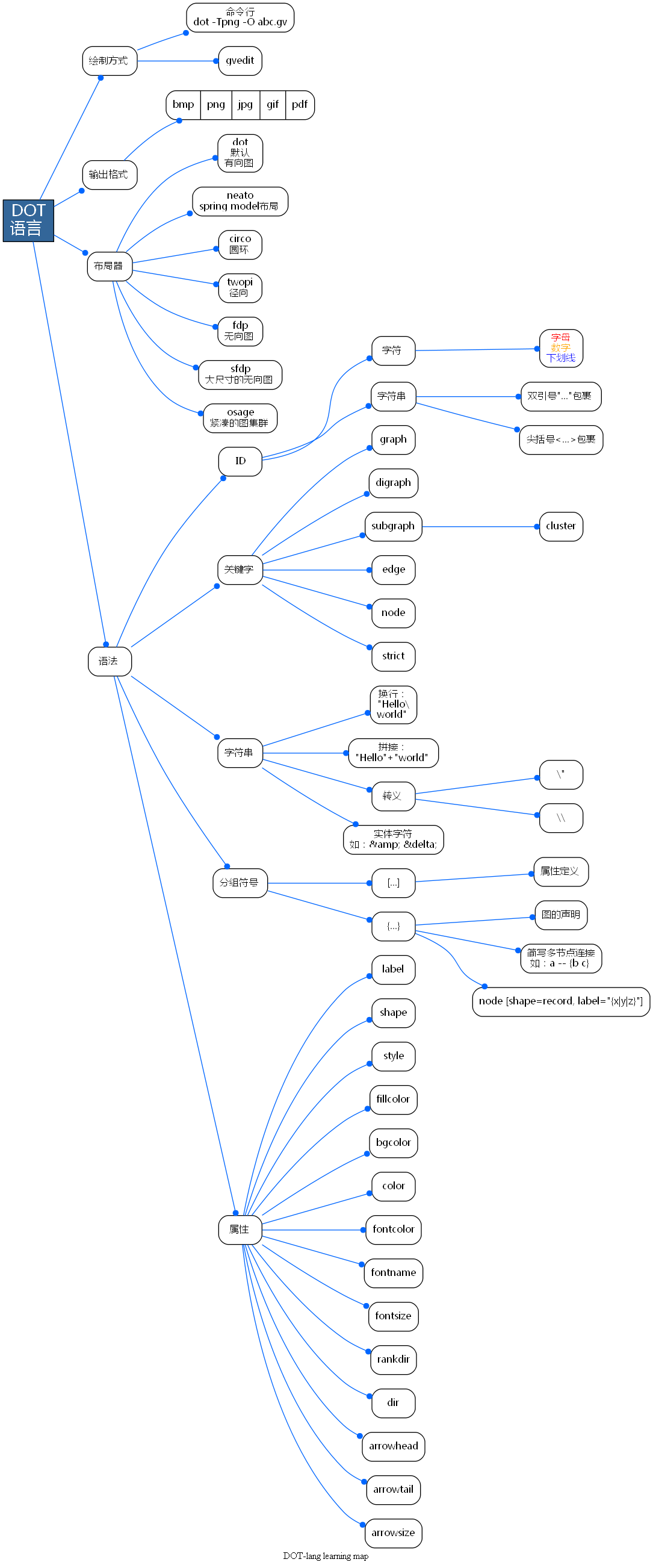
现学现卖,用Graphviz做个思维导图
自从今年6月开始,部署在GitHub Pages上的站点开始支持https协议GitHub Blog,很多博主们都欢呼雀跃。但是当你需要建立http协议的网站时,该怎么办呢?
GitHub Pages一旦开启https,就无法关闭了的。所以到底有何方式去退回到http呢?
我想到了,新建的仓库要建http协议的站,肯定是不行的。但是可以找以前的旧仓库,腾出来用啊。
cd hello_world
git checkout --orphan 'todelete'git rm -r *
git add .
git commit -m 'to delete branch'
git push origin todeletetodelete分支设置为默认分支,删除master分支(也可以不删除,或者创建一个分支备份原有的master分支的数据),将远程仓库的名称改成新项目的名称gh-pages分支到远程仓库cd ../new_repo
git remote remote set-url origin [email protected]:username/new_repo.git
git checkout -b 'gh-pages'
git push origin gh-pagesgh-pages分支设置为默认分支,删除todelete分支done,但是当我访问这个新建站点时,它的协议仍旧是https的。
从前面的尝试,我得到一个猜测:不仅是6月份之前的建仓库,还需要时6月前建立的gh-pages分支作为站点,才能仍然使用http协议。
所以,只能将新站的数据,搬到某个旧仓库中以前的创建好的gh-pages分支下
cd ../old_repo
copy ../new_repo/* ./ # Windows cmd
cp ../new_repo/* ./ # Linux bash
git add .
git commit -m 'add a new repo site data'[√] That's done.
tags: GitHub Pages, HTTPS
关于GitHub Pages建站的文章我以前写过,不过,写的比较乱,今天整理了一下。
为了更好地学习和记录自己的前端经历,搭建一个便捷、稳定的个人站点挺有必要的;而通过GitHub Pages来展示自己的作品,更是不错的选择。
**注意:**需要保证已经安装好git并且已经关联到git远程平台账户
打开git shell,创建一个名为gh-pages的分支,GitHub Pages默认为这个分支创建页面
git checkout --orphan gh-pages将项目的展示页面文件放在项目仓库的gh-pages分支的根目录下,并且命名为index.html,必须以html为扩展名。
http://userName.github.io/repoName访问你的项目demo页面了。补充:
因为GitHub Pages上托管的页面都是静态页面,所有有服务器响应需求的页面无法实现。但是可以通过插入第三方代码来实现,诸如评论、分享、代码示例等动态的木块。
GitHub Pages官方是推荐使用jekyll来部署个人网站的,而比较简单上手的则是hexo,各有其优点和缺点
| 对比 | jekyll | hexo |
|---|---|---|
| 文档 | 只有英文 | 多语言,有中文 |
| 操作 | 需要手动push到GitHub | 文章模板,生成,部署,自动push |
| 自定义 | 结构清晰,较少的说明,也能理解某些功能的作用和文件位置,适合深入自定义 | 适合拿现有的模板直接用,但是新手自定义有难度 |
| 功能 | 插件多,功能完整,但略有bug | 有更多更能待补充,比如post相对引用 |
| 安装 | 因为需要ruby,在大陆可能会有网络限制 | 需要node,大陆的网络环境似乎没问题 |
安装ruby
在Windows下,从 http://rubyinstaller.org/downloads/ 下载rubyinstaller.exe和`DevKit ,两个要对应版本,且对应操作系统。
执行rubyinstaller.exe,安装ruby。
将DevKit执行,并解到一个指定命名文件夹,如:RubyDevKit
管理员权限打开cmd/PowerShell
ruby dk.rb init
dk.rb install从 https://rubygems.org/pages/download/ 下载RubyGems,解压缩出来的文件夹,如:rubygems
管理员权限打开cmd/PowerShell
cd rubygems
ruby setup.rb在Ubuntu下,安装ruby比较简单,可参考我的另一篇文章
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
curl -L https://get.rvm.io | bash -s stable --autolibs=enabled --ruby
sudo apt-get install libgdbm-dev libncurses5-dev automake libtool bison libffi-dev
source ~/.rvm/scripts/rvm配置ruby
由于国内网络受限,可能需要修改ruby的源为国内的镜像:淘宝镜像(https://ruby.taobao.org/)或者ruby**镜像(https://gems.ruby-china.org/)。
依次执行以下命令,在Ubuntu和Windows下都如此,以下如未特别说明,命令都是两平台均适用
gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/
gem sources -l在Windows下,如果出现证书失败,就去下载一个证书
curl http://curl.haxx.se/ca/cacert.pem -o cacert.pem将下载的cacert.pem移到ruby安装目录的/bin这个目录下,并且在系统环境变量中新建SSL_CERT_FILE,值为刚才的/bin目录的绝对路径,管理员权限打开cmd/PowerShell
SETX /M SSL_CERT_FILE "/bin目录的绝对路径"bundler是一款ruby工具,可以通过配置Gemfile文件来快速安装gems包或者解决已安装包的依赖。
gem install bundler在Windows下,如果网络环境不允许,可以选择不安装bundler,或者安装虚拟机VirtualBox。如果连ruby安装都困难可以选择使用chocolatey来装jekyll。
安装jekyll
gem install jekyll创建一个名为Gemfile的文件,无扩展名,添加如下行
source 'https://rubygems.org'
gem 'github-pages', group: :jekyll-plugins
然后在需要的时候就可以执行以下命令
bundle install # 自动安装gems包和依赖
bundle update # 更新gems包依赖
bundle exec jekyll build # 执行jekyll build,常用于解决一些jekyll的依赖等问题
bundle exec jekyll serve # 执行jekyll serve,常用于解决一些jekyll的依赖等问题常用jekyll命令
jekyll new <dir> # 初始化一个站点目录
jekyll build -s <dir> -d <dir> # 生成编译后的静态站点文件
jekyll serve # 用于本地预览和调试,地址是127.0.0.1:4000建立站点仓库
有两种选择:一是自己从零开始一步一步建站,二是直接使用别人的模板
自己建站
jekyll new blog
cd blog修改Gemfile文件
source 'https://ruby.taobao.org/' # 更改gem源可能要设置环境变量
'jekyll', '3.2.1' # 注释掉这行
gem 'github-pages', group: :jekyll_plugins # 去掉这行的注释井号#
安装插件和依赖
bundle install使用别人的模板
克隆一个模板,官方jekyll模板列表
git clone git@github.com:someone/jekyll-theme.git # 克隆一个的模板拷贝到自己的站点仓库目录,注意区分Windows和Ubuntu的命令
mkdir blog
cp jekyll-theme/* blog # 这是Ubuntu的命令
copy jekyll-theme/* blog # 这是Windows的命令删除克隆的模板中的git记录
rm -rf blog/.git # Ubuntu
rd /s blog/.git # Windows我是直接使用的现成模板,所以后面的内容都是以现成模板的修改来讲述
初始化本地站点仓库
cd blog
git init
git remote add origin git@github.com:userName/blog.git # 与你的github blog仓库建立联系
git checkout --orphan gh-pages配置站点
站点仓库的目录结构如下
/blog
|-- _config.yml # 站点配置文件
|-- _layouts # 用户构成页面区域的模板,default或post一般是发布的文章的模板,page则是主页面的模板比如说边栏
| |-- default.html
| |-- post.html
| \-- page.html
|-- _includes # 页面的小组件,比如分享、评论、访问统计等等
| |-- share.html
| \-- sidebar.html
|-- _posts # 你的markdown原文件存放的目录
|-- _site # jekyll build 默认生成已编译站点文件的目录
|-- _plugins # 使用的jekyll插件的存放目录
\-- index.html # 站点首页
**注意:**只要是按照各目录结构,这个站点仓库直接push到GitHub的仓库里,就可以建立起站点了,当然要设置作为GitHub Pages站点的分支(一般是gh-pages,不过现在可以是master分支,甚至是master分支下的docs目录了)。但是有时候需要把编译后的文件作为站点页面文件(比如你使用了jekyll插件来实现页面,而不是用JavaScript),这时候就需要把blog目录的源文件和编译后的站点文件(一般默认是_site)分开来push了。
建议在blog目录下新增一个.gitignore文件,其中写入_site来忽略对这个目录的提交。将blog目录作为远程仓库的source分支,而_site目录作为远程仓库的gh-pages分支或者master分支
git checkout -b source
git branch -D master # 删除分支
git branch -D gh-pages # 删除分支
cd _site # 切换到_site目录
git init
git remote add origin git@github.com:userName/blog.git # 与同意github blog仓库建立联系
git checkout -b gh-pages修改_config.yml文件,整个站点的配置主要是在这个文件中修改
name: '博客名'
description: '博客简述'
encoding: 'utf-8'
url: 'http(s)://your.site.com'
baseurl: '/your/project/path or blank'
defaults:
-
scope:
path: ''
type: 'posts'
value:
layout: '在_layouts目录下的post.html或者default.html的文件名,不带扩展名'
author: '作者'
comments: true
share: true
social:
github: 'github用户名'
codepen: 'codepen用户名'
rss: feed.xml
disqus: '在disqus上设置的你的站点名或博客名'
comments: true创建/修改_include和_layouts目录下的文件,使用Liquid语法
安装jekyll插件以及更多jekyll配置信息请阅读jekyll官方文档
撰写博文
因为jekyll是使用kramdown来解析markdown,与常见markdown略有区别,建议参考kramdown的官方语法,如果需要更换其他markdown解析器需要在_config.yml文件中设置,并且安装插件
博文源文件的命名,前时间后文章名:2016-09-01-how-to-build-a-site-on-github-pages.md
博文结构主要是指头部,头部结构如下:
layout: post # 默认是default,跟_layouts目录下的default.html文件对应,可以通过_config.yml的defaults字段配置默认设置
author: 作者名 # 可以_config.yml默认配置
title: 博文标题
date: yyyy-mm-dd
categories:
- category1
- category2
tags:
- tag1
- tag2
comments: true # 开启第三方评论模块,可以_config.yml默认配置
share: true # 开启第三方分享模块,可以_config.yml默认配置
写好的markdown文件存储于_posts目录下即可。
做好源文件的版本控制
对站点源文件进行提交,以便进行版本控制,进入blog目录
git add --all
git commit -m 'some revisions'
git push origin source部署站点
生成编译后的静态站点文件,并且push到远程仓库
jekyll build
cd _site
git add --all
git commit -m 'some descriptions'
git push origin gh-pages以后每次有新的文章发布,需要重复7~9步的操作。
补充:添加disqus评论功能
安装node
在Windows下,从 https://nodejs.org/en/ 下载以.msi为扩展名的安装包,如果不需要进行node相关开发的话,选LTS版本就够用了。
在Ubuntu下,可以利用nvm装node
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash # 安装nvm
nvm install node # 安装最新版本node
nvm ls # 查看已安装的版本
nvm use node # 使用node安装hexo
npm install -g hexo-cli
npm install hexo-deployer-git --save # 安装部署站点的node功能包,hexo deploy命令需要建立站点仓库
hexo init blog # 初始化一个站点目录
cd blog
npm install配置站点
一般hexo初始化后的站点目录结构如下
/blog
|-- _config.yml # 站点配置文件
|-- scaffolds # 页面模板存放的目录
| |-- post.html # 博文模板
| |-- page.html # 分页模板
| \-- draft.html # 草稿模板
|-- source # 博文源文件目录
| |-- _posts # 存放博文的目录
| \-- _drafts # 存放草稿的目录
|-- themes # 存放主题文件夹的目录
|-- package.json
|-- node_modules # 功能依赖包
\-- .gitignore # push的时候忽略node_modules文件夹等
修改_config.yml文件,整个站点的配置主要是在这个文件中修改
title: 博客名
description: 博客简述
author: 作者名
url: http(s)://your.site.com
root: /your/project/path or /
deploy:
type: git
repo: [email protected]:userName/blog.git
branch: gh-pages
message: [自定义的提交信息]撰写博文
每当需要撰写心得博文时,只需要执行以下命令,就可以得到一个标题和日期已经设置好的markdown文件
hexo new [layout] '博文标题' # layout是可选项,表示使用哪种模板来创建页面文件,默认是post博文结构的头部
title: 博文标题
date: yyyy-mm-dd # 日期是创建博文源文件时自动生成的
categories:
- category1
- category2
tags:
- tag1
- tag2
comments: true
做好源文件的版本控制
由于hexo是自动将站点文件自动部署到GitHub Pages上的,所以不需要自己另外push,但是建立生成站点页面的分支,还是有必要的。
git init
git remote add origin git@github.com:userName/blog.git # 与你的github blog仓库建立联系
git checkout --orphan source
git push origin source部署站点
hexo的站点部署很简单
hexo g # 生成编译后的静态站点文件
hexo d # 部署到远程仓库或者可以结合起来,生成静态文件后直接部署,下面两条命令使用一条即可
hexo g -d # 生成后部署
hexo d -g # 部署前生成以后每次有新的文章发布,只需要如下操作
hexo new '博文标题'
hexo g -d常用hexo命令
hexo init <站点仓库的目录> # 初始化一个站点目录
hexo clean # 用于主题切换等涉及站点整体布局效果改变的行为时,清楚hexo原有缓存
hexo new '博文标题' # 新增一篇博文
hexo generate # 可简写为 hexo g ,编译生成静态页面文件
hexo server # 可简写为 hexo s ,开启本地服务器预览与测试编译生成的静态页面效果
hexo delpoy # 可简写为 hexo d ,部署站点到远程仓库
hexo generate -d # 可简写为 hexo g -d ,编译生成静态页面文件并部署到远程仓库
hexo deploy -g # 可简写为 hexo d -g ,同上修改主题
从hexo themes找到何意的主题,clone下来,放到站点本地仓库的themes目录下,修改_config.yml文件的theme字段为对应的主题名
theme: light更多插件等功能,建议去hexo 官网查看。
tags: GitHub Pages, jekyll, hexo
安装jdk
安装指定版本的jdk
sudo apt-get install openjdk-7-jdk或安装默认版本的jdk
sudo apt-get install default-jdk下载Android SDK
wget http://dl.google.com/android/android-sdk_r24.2.1-linux.tgz 安装sdk包
tar -xvf android-sdk_r24.2.1-linux.tgz
cd android-sdk-linux/tools
./android update sdk --no-ui # 安装所有sdk包设置环境变量
如果是在64位Ubuntu上装,要安装32位的库文件
sudo apt-get install lib32z1 lib32ncurses5 lib32bz2-1.0 lib32stdc++6vi ~/.zshrc << EOT
export PATH=${PATH}:$HOME/sdk/android-sdk-linux/platform-tools:$HOME/sdk/android-sdk-linux/tools:$HOME/sdk/android-sdk-linux/build-tools/22.0.1/
EOTtags: Android SDK
因为国内网络管制的问题,gem的源经常连不上,会出现各种问题,所以可以考虑使用这个方案。
安装chocolatey,以管理员权限开启cmd/PowerShell
@powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://chocolatey.org/install.ps1'))" && SET PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin安装ruby,以管理员权限重启cmd/PowerShell
choco install ruby -y # 自动安装ruby2.2.4安装jekyll,管理员权限重启cmd/PowerShell
gem install jekyll至此,可以使用jekyll命令行:
jekyll new myblog
cd myblog
jekyll build # 生成页面文件
jekyll serve # 本地预览tags: Windows, chocolatey, jekyll
由于Vagrant和VirtualBox实在太占空间了,用WinDirStat检测,单文件最占空间的是虚拟机文件,所以决定改下路径。有两个路径要修改,Vagrant的VAGRANT_HOME和VirtualBox的文件默认生成路径。我是直接全部重装,把程序也都换了路径了。
设置单个用户的环境变量
setx VAGRANT_HOME "X:/your/path"
设置系统的环境变量
setx VAGRANT_HOME "X:/your/path" /M
或者可以从系统视图中找到:控制面板->所有控制面板项目->系统->高级系统设置->环境变量,上面是用户环境变量,下面是系统环境变量。
**注意:**还需要把%userprofile%/.vagrant.d/路径下的所有文件移动到前面环境变量设置的路径X:/your/path中。
VirtualBox,管理->全局设定(Ctrl+G),修改默认虚拟电脑位置
这里顺便把之前没完成的PuTTY的自动登录来完成了。当然先开Vagrant是免不了的。
**注意:**每次刚打开PAGEANT时,都需要PAGEANT->Add Key(如果设置了passphrase,还需要输入passphrase)。如果觉得麻烦,在生成私钥文件(扩展名为.ppk)时,不设置passphrase即可。
.vagrant\machines\default\virtualbox找到private_key(注意要手动选择文件类型,All Files(*.*)),打开。Key comment来作为这个Key的描述,键入Key passphrase和Comfirm passphrase作为这个Key文件的加密密钥(如果设置了passphrase,后面用PAGEANT时会需要用到,文件夹下的chm文档是说建议用随机字符串作为这个密钥,但是一定要自己另外记下来),然后点击Save private key,生成扩展名为.ppk的私钥,自己取名。公钥存不存都无所谓(暂时用不到),因为这个生成的私钥里已经包含了,如有需要,直接在PuTTYGEN再load->Save public key就好了。.ppk私钥文件vagrant)即可。需要关闭PAGEANT,直接右键->Exit这样一来,之后只要PAGEANT没Exit,登录虚拟机时就只需要输入用户名不需要输入密码了。
Vagrant自动生成的登录密钥文件,通过vagrant ssh-config命令输出的IdentityFile字段可以看到。
tags: Vagrant, VirtualBox, PuTTY
我们知道,有时候使用原生JavaScript要准确判断数据类型,并不容易,比如说跨框架脚本。所以,我们可以做一些工具来准确获取数据类型。
typeof的局限原生JavaScript提供了typeof来获取一些内置类型数据的数据类型,但是它并不能检测所有的数据类型。来看看下面的测试代码
typeof undefined // 'undefined'
typeof 123 // 'number'
typeof Infinity // 'number'
typeof NaN // 'number'
typeof true // 'boolean'
typeof 'abc' // 'string'
typeof function(){} // 'function'
typeof {name: 'uolcano'} // 'object'
typeof null // 'object'
typeof [1,2,3] // 'object'
typeof new (function F(){}) // 'object'以上代码说明了三件事:
null在语义上并不是一个对象后两种情况,值得改善、扩展和增强。
typeof不能准确检测到Infinity和NaN,所以我们需要将这两个分别出里。
好在从ES3开始,window对象就提供了两个方法来检测这两个特别的数值——window.isNaN和window.isFinite,分别检测一个变量是否为“不是一个数值”,以及一个变量是否有穷。
所以,我们只需要将这两个单独处理,其他的typeof检测为数值的,就是我们真正认识的数值了。
var type = typeof arg;
if(type === 'number') {
if(isNaN(arg)) return 'NaN';
if(!isFinite(arg)) return 'Infinity';
return type;
}有两种方式去获取一个某个类型实例的准确类型:
Object.prototype.toString能够得到JavaScript内置对象的类型,不包括BOM、DOM的对象
每个对象都有的constructor属性,存储了在最近的原型链上对构造器的引用,但是对于自定义继承的类型,可能无法获得这个属性,因为往往构造函数的prototype属性是直接被赋值覆盖了的
你有可能会认为,既然对象的constructor属性能够检测到Object.prototype.toString不能检测到的类型为何还要用两个。因为像null这样的值,是没有constructor属性的,只能通过Object.prototype.toString来获取。
因此,我们可以分两步:首先,判断内建对象的类型,然后,判断其他非JavaScript原生对象
if(typeof arg === 'object') {
var type = Object.prototype.toString.call(arg).slice(8, -1).toLowerCase();
switch(type){
case 'number':
case 'string':
case 'boolean':
return 'object ' + type; // 扩展包装类型对象的类型,添加object前缀
case 'null':
case 'date':
case 'regexp':
return type;
default:
return arg.constructor.toString().match(/function\s*([^\(\s]*)/)[1].toLowerCase();
}
}完整代码,查看我的Gist
tags: JavaScript, typeof
下载证书
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3安装稳定版rvm以及最新版的ruby
curl -L https://get.rvm.io | bash -s stable --autolibs=enabled --ruby安装依赖,初始化并立即执行
sudo apt-get install libgdbm-dev libncurses5-dev automake libtool bison libffi-dev
source ~/.rvm/scripts/rvm修改rubygems的源为淘宝ruby源,并查看确认
gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/
gem sources -l**注意:**淘宝源如果有问题fetch error的话,可以改用 https://gems.ruby-china.org/ 替换。
以sudo安装rubygems-update
gem install rubygems-update
update_rubygems
gem update --system安装bundler
gem install bundler安装rails
gem install rails安装nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash安装最新版nodejs
nvm install 5.0常用命令
nvm ls # 查看已安装的版本
nvm use node # 使用node安装git
sudo apt-get install git配置git
配置基本信息,并生成ssh公钥
git config --global color.ui true
git config --global user.name "YOUR NAME"
git config --global user.email "[email protected]"
git config -l #查看配置信息
ssh-keygen -t rsa -C "[email protected]" # 一直敲回车查看生成的公钥,并复制之
cat ~/.ssh/id_rsa.pub # id_rsa 应该是ubuntu系统分配的,只能用这个文件名到github settings->SSH and GPG keys->SSH keys->new SSH key,给SSH key写个名字作为Title,在key下粘贴从id_rsa.pub里复制公钥。然后Add SSH key即可。
将本地git与github账号建立连接
ssh -T [email protected]显示一下信息,即表示连接成功
Hi YOUR NAME! You've successfully authenticated, but GitHub does not provide shell access.tags: Ubuntu, rvm, nvm, git, java
JRE是常见Java运行环境,JDK是开发需要再安装
sudo apt-get update
java -version # 检查是否已安装
sudo apt-get install default-jre
sudo apt-get install default-jdk有时候这步可以跳过,但是如果JRE/JDK安装后,没有自动配置环境变量,就需要手动配置了。
执行以下代码检查,是否安装且配置成功
java -version如果显示了版本号说明,已配置成功,安装完成。
否则,继续下面的操作。
找到Java安装路径
sudo update-alternatives --config java这可能会返回如下提示
There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java那么/usr/lib/jvm/java-7-openjdk-amd64就是你安装的Java的路径,记录下来后面用。
打开/etc/environment文件
sudo nano /etc/environment在JAVA_HOME后的值中添加刚才记录的Java安装路径,并且以英文冒号:与其他已有路径隔开
JAVA_HOME="your/other/paths:/usr/lib/jvm/java-7-openjdk-amd64"重新加载/etc/environment文件
source /etc/environment再次检查配置是否成功
java -versiontags: JRE/JDK, Ubuntu
最近把原来的ST3卸了,去官方下载了最新的重装。也装了好多插件和snippets,ST3文件夹变成了200+M,装太多:sweat_smile:。
把插件清单列出来,方便以后重装。诶,烦不烦啊,你哪那么多闲工夫重装啊(ノಠ益ಠ)ノ彡┻━┻,说笑了;P
清单如下:
| 插件名 | 推荐级别 | 描述 |
|---|---|---|
| 基础插件 | —— | —— |
| PackageControl | A+ | 包管理插件 |
| SideBarEnhancements | A+ | 边栏 |
| DocBlockr | A+ | 注释助手 |
| Encoding Helper | A+ | 文本转码为UTF-8 |
| ConvertToUTF8 | A+ | 扩展ST3的编码,支持中文编码 |
| Colorsublime | B | 切换主题并且实时查看主题效果 |
| 语法高亮 | —— | —— |
| Babel | B | Babel支持的ES6语法高亮 |
| JavaScriptNext-ES6 | B+ | 支持ES6语法高亮 |
| HTML5 | B+ | 支持HTML5语法高亮 |
| CSS3 | B+ | 支持CSS3语法高亮 |
| Pug/Jade | B | 支持Jade模板语法高亮 |
| LESS | B | 支持LESS预处理语法高亮 |
| coding提速 | —— | —— |
| Emmet | A | 强大的snippet工具,提高码字效率 |
| Emmet livestyle | A | 实时呈现修改的CSS效果 |
| jQuery | A | jQuery代码片段 |
| Nodejs | B+ | 支持nodejs语法,自带snippet |
| AutoFileName | A | 文件路径自动填充 |
| Autoprefixer | B+ | 自动添加不同浏览器厂商的CSS前缀 |
| 拾色 | —— | —— |
| ColorPicker | B+ | 拾色器 |
| Color Highlighter | A | 颜色代码实时显色 |
| Git | —— | —— |
| GitGutter | B+ | git界面,实时git diff提示 |
| Git | C | git命令插件 |
| Side Bar Git | C | 边栏git命令插件 |
| Markdown | —— | —— |
| Markdown Preview | B | 本地渲染markdwon文件生成页面,支持GFM |
| Markdown TOC | B+ | 给markdown文件生成目录,且监听自动更新目录变更,可设置目录深度 |
| MarkdownEditing | A+ | 非常好用的markdown工具,不仅能高亮markdown语法,支持GFM,还有方便的快捷键 |
| 代码处理 | —— | —— |
| JsFormat | A | 代码格式化 |
| Minifier | A | 需要安装uglify-js |
| SublimeCodeIntel | B | 代码提示和自动填充 |
| SublimeLinter | B+ | 错误检测 |
| SublimeLinter-jshint | B+ | 扩展SublimeLinter,需要安装jshint |
| LiveReload | A | 配合chrome扩展LiveReload可以实时预览代码效果,不过就个人的使用体验来说,经常卡顿 |
| 编辑器增强 | —— | —— |
| PlainTasks | B | 任务清单,TODO list |
| Gist | A+ | 直连GitHub Gist,方便记录和查看,可以做云笔记用,结合roughdraft.io、Gistboxapp |
| Terminal | B+ | 通过边栏,直接在指定目录启动终端或PowerShell |
| less2css | B | less转css,需要安装less.js-windows |
| GraphvizPreview | C | 关系图绘制软件graphviz的代码绘制预览,支持DOT语言,不过个人体验的效果不好 |
由于大多代码自动补完会弹出很长一个列表,非常降低编程体验,轻量的snippets用起来更舒适,以下列出片段建议clone到st3\Data\Packages\User\这个目录下
| 插件名 | 推荐级别 | 描述 |
|---|---|---|
| Text Snippets | A+ | 支持jQuery、Bootstrap和PHP等代码片段 |
| JavaScript Snippets | A+ | 非常方便的snippets |
| JavaScript Patterns snippets | A+ | 作为JavaScript Snippets的补充和进阶,包含throttle和debounce等技术片段 |
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.