urlstechie / urlchecker-python Goto Github PK
View Code? Open in Web Editor NEW:snake: :link: Python module and client for checking URLs
Home Page: https://urlchecker-python.readthedocs.io
License: MIT License
:snake: :link: Python module and client for checking URLs
Home Page: https://urlchecker-python.readthedocs.io
License: MIT License

























According to https://github.com/buildtesters/buildtest/runs/6903580431?check_suite_focus=true i am getting failure on this url https://www.hpcwire.com/2019/01/17/pfizer-hpc-engineer-aims-to-automate-software-stack-testing/
It would be nice if there was extra output to explain why these url are breaking. I know this urlchecker does work on most part and i can ignore this from list.

I don't want to use force_pass : true though i do want the action to pass.
I have not tried verbose: true but does this provide the detail for debugging.
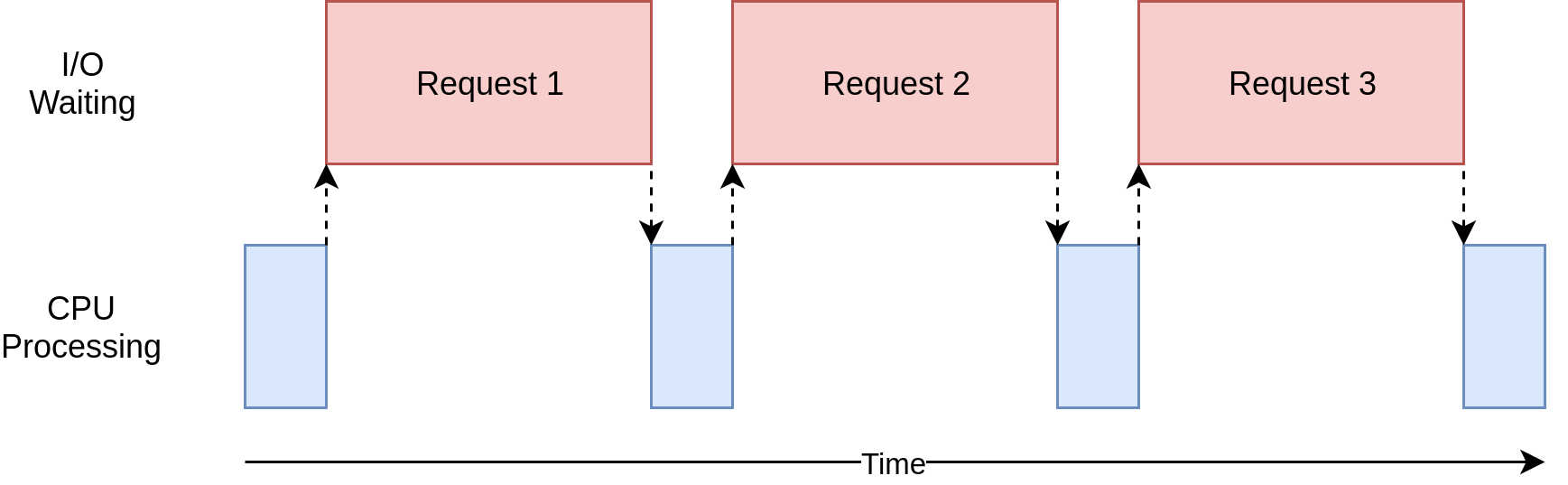
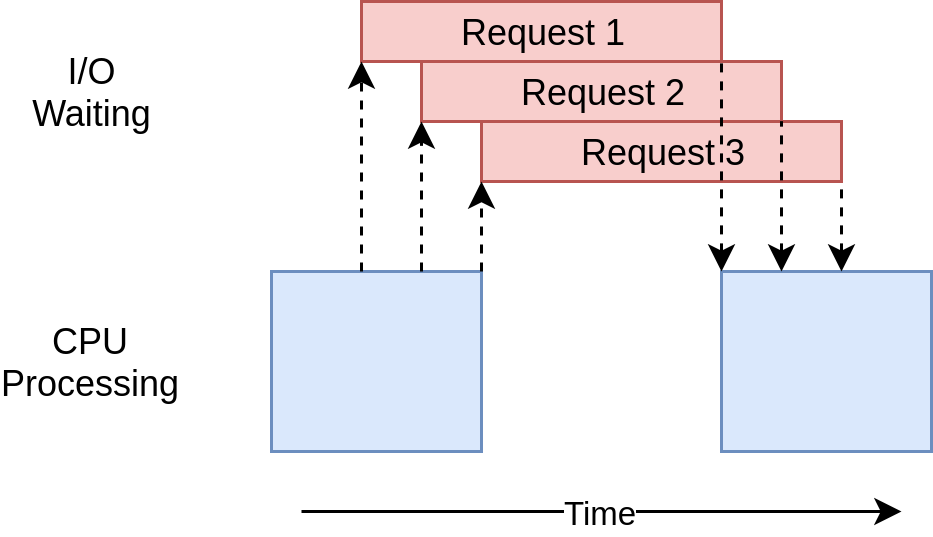
Urls are checked using a loop that tests the response of the requests sequentially, which becomes slow for huge websites.
Alternatively, we can use concurrency to process requests& responses asynchronously and speed up the system.
I already integrated this concept in my local repo using the asyncio and AIOHTTP libraries and the results look promising. The speed difference is notable based on various blogs (Python and fast HTTP clients, HTTP in Python: aiohttp vs. Requests, Making 1 million requests with python-aiohttp) and so far my tests confirm that.
Img source
The new libraries are slightly different from requests and so the following is true:
I managed to almost replicate the same features we have in the current version but I will definitely need your feedback. Anyway, these differences bring me to my major question @vsoch : Do you think that we should add this feature as an option --accelerated-run or replace the current implementation with it
hey @SuperKogito - it occurred to me today that we don't support checking internal links, meaning that if we render a jekyll site, we aren't able to see if something that starts with a / in an img src or link href works (internally). I think this is something that would be needed, and also would mimic the functionality of html-proofer. What do you think? How would it work?
As discussed in #2 , Travis currently runs twice (for PR and branch pushes) and it might make sense to only run for PR, since pushing to master won't be a thing (but always done via a pull request). A note from @SuperKogito :
Well you make a good point about travis running twice. Technically, travis is running once on the new branch and once on the PR. I think we should drop the branch run and settle for one run for the PR? if you think it is slow, we can use pytest-xdist (like I did initially) but the logs won't be as detailed as now :P
I’ll work on this later today.
@vsoch I came across this while reviewing the latest PR.
urlchecker-python/urlchecker/core/urlproc.py
Line 182 in 1f9bd5c
How important is the filter using http? shouldn't the REGEX deliver that already?
Right now (it looks like) there is a clone being done to the PWD where the repo is / tests are run, I will fix this up in my current (WIP) PR #31 probably tomorrow.
For the next round of updates, see https://github.com/danger89/fake-useragent/issues/7#issuecomment-1287427894
So far, pip install urlchecker was everything needed to install the package. With version 0.0.33, this fails with:
(env) ~$ pip install urlchecker
Collecting urlchecker
Downloading urlchecker-0.0.33.tar.gz (30 kB)
Preparing metadata (setup.py) ... done
ERROR: Packages installed from PyPI cannot depend on packages which are not also hosted on PyPI.
urlchecker depends on fake-useragent@ git+https://github.com/danger89/fake-useragent@master#egg=fake-useragentIf I follow the installation instructions in your README file, I get this:
(urlchecker) ~$ pip install git+https://github.com/danger89/fake-useragent.git
Collecting git+https://github.com/danger89/fake-useragent.git
Cloning https://github.com/danger89/fake-useragent.git to /tmp/pip-req-build-qvfvjz9m
Running command git clone --filter=blob:none --quiet https://github.com/danger89/fake-useragent.git /tmp/pip-req-build-qvfvjz9m
Resolved https://github.com/danger89/fake-useragent.git to commit a8f2b57910cdb496dcebd4a828f6e33984b2124f
Preparing metadata (setup.py) ... done
Building wheels for collected packages: fake-useragent
Building wheel for fake-useragent (setup.py) ... done
Created wheel for fake-useragent: filename=fake_useragent-0.1.12-py3-none-any.whl size=13815 sha256=b897ee62f3d8cd7f726d523aa4e2b5d99a18fdaba36804312bd778f797651233
Stored in directory: /tmp/pip-ephem-wheel-cache-asneomg1/wheels/4a/80/0e/42b3e4541f3f2e603f91cf7c5c83b5342621e45a46d45b98ed
Successfully built fake-useragent
Installing collected packages: fake-useragent
Successfully installed fake-useragent-0.1.12
(urlchecker) ~$ pip install urlchecker
Collecting urlchecker
Using cached urlchecker-0.0.33.tar.gz (30 kB)
Preparing metadata (setup.py) ... done
ERROR: Packages installed from PyPI cannot depend on packages which are not also hosted on PyPI.
urlchecker depends on fake-useragent@ git+https://github.com/danger89/fake-useragent@master#egg=fake-useragentI've just seen
urlchecker-python/urlchecker/core/urlproc.py
Line 182 in 7fd0886
urlchecker is sweet. It would be great if it was easier to run. Lots of projects use pre-commit (https://pre-commit.com/).
I think all that's required is to create a file like Black provides:
https://github.com/psf/black/blob/master/.pre-commit-hooks.yaml
According to urlstechie/urlchecker-action#93, it seems that the checker is not able to check doi and sciencedirect link. A quick inspection shows that a simple 'Accept': 'application/json' in the headers should fix this. You can amend this to #72, I think. Unfortunately I cannot test or help much here these days.
This fails:
import requests
agent = (
"Mozilla/5.0 (X11; Linux x86_64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/63.0.3239.108 "
"Safari/537.36"
)
timeout = 5
url_doi = 'https://doi.org/10.1063/5.0023771'
url_sci = 'https://www.sciencedirect.com/science/article/pii/S0013468608005045'
r = requests.get(url_sci,
headers={"User-Agent": agent})
print(f"Status Code: {r.status_code}")
This works:
import requests
agent = (
"Mozilla/5.0 (X11; Linux x86_64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/63.0.3239.108 "
"Safari/537.36"
)
timeout = 5
url_doi = 'https://doi.org/10.1063/5.0023771'
url_sci = 'https://www.sciencedirect.com/science/article/pii/S0013468608005045'
r = requests.get(url_sci,
headers={"User-Agent": agent, 'Accept': 'application/json'})
print(f"Status Code: {r.status_code}")
you can test the code online here
Not sure if this belongs to the library or action. Would it be possible (and make sense) to have the filename relative to the folder in which the URL checks are run?
The library should implement an option to export results to file, which will support urlstechie/urlchecker-action#23
No rush here, but I really like pre-commit over manually running each tool.
Preconditions:
Steps to reproduce:
cd documentationurlchecker check . --timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"Actual result:
❯ urlchecker check . --timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"
original path: .
final path: /home/sturivny/git-cki/documentation
subfolder: None
branch: main
cleanup: False
file types: ['.md', '.py']
files: ['content/docs/hacking/contributing/documentation/index.md']
print all: True
verbose: False
urls excluded: []
url patterns excluded: []
file patterns excluded: []
force pass: False
retry count: 5
save: None
timeout: 60
https://gitlab.com/cki-project/documentation/
https://gohugo.io/
https://www.docsy.dev/
https://gohugo.io/content-management/page-bundles/
https://cki-project.org/
https://www.gnu.org/software/stow/
2022-08-04 12:42:32,421 - urlchecker - ERROR - Error running task
ERROR:urlchecker:Error running task
🤔 There were no URLs to check.
Exception ignored in: <function Pool.__del__ at 0x7fd954e7eee0>
Traceback (most recent call last):
File "/usr/lib64/python3.9/multiprocessing/pool.py", line 268, in __del__
self._change_notifier.put(None)
File "/usr/lib64/python3.9/multiprocessing/queues.py", line 377, in put
self._writer.send_bytes(obj)
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 205, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 416, in _send_bytes
self._send(header + buf)
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 373, in _send
n = write(self._handle, buf)
OSError: [Errno 9] Bad file descriptor
Expected result:
No Errors
@vsoch Once again, here is another attempt at improving our long and forgiving nice regex 😄
A little background, the current regex is something I found online and after testing it along with other links I deemed it to be good enough. However, I was never comfortable with how long it was.
Here is a simplified (domain extensions are replaced with ... except .com and .org) graph of what we have at the moment:

So after hacking and tweaking for a couple of days, I think I came up with an improved regex, that is shorter which means faster and simpler. Here how it looks:

Here is a small idea on how it performs: https://regex101.com/r/zvnFp6/1
Unfortunately I couldn't run the same thing for our current regex cuz it is too long. However, I did run a the following comparison locally:
import re
import time
domain_extensions = "".join(
(
"com|net|org|edu|gov|mil|aero|asia|biz|cat|coop|info|int|",
"jobs|mobi|museum|name|post|pro|tel|travel|xxx|",
"ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|",
"ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|",
"ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cs|cu|cv|cx|cy|cz|",
"dd|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|",
"fi|fj|fk|fm|fo|fr|",
"ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|",
"hk|hm|hn|hr|ht|hu|",
"id|ie|il|im|in|io|iq|ir|is|it|",
"je|jm|jo|jp|ke|kg|kh|ki|",
"km|kn|kp|kr|kw|ky|kz|",
"la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|",
"ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|",
"na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|",
"om|",
"pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|",
"qa|",
"re|ro|rs|ru|rw|",
"sa|sb|sc|sd|se|sg|sh|si|sj|Ja|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|",
"tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|",
"ua|ug|uk|us|uy|uz|",
"va|vc|ve|vg|vi|vn|vu|",
"wf|ws|",
"ye|yt|yu|",
"za|zm|zw",
)
)
URL_REGEX1 = "".join(
(
"(?i)\\b(",
"(?:",
"https?:(?:htt/{1,3}|[a-z0-9%]",
")",
"|[a-z0-9.\\-]+[.](?:%s)/)" % domain_extensions,
"(?:",
"[^\\s()<>\[\\]]+|\\([^\\s()]*?\\([^\\s()]+\\)[^\\s()]*?\\)",
"|\\([^\\s]+?\\)",
")",
"+",
"(?:",
"\\([^\\s()]*?\\([^\\s()]+\\)[^\\s()]*?\\)",
"|\\([^\\s]+?\\)",
"|[^\\s`!()\\[\\];:'\".,<>?«»“”‘’]",
")",
"|",
"(?:",
"(?<!@)[a-z0-9]",
"+(?:[.\\-][a-z0-9]+)*[.]",
"(?:%s)\\b/?(?!@)" % domain_extensions,
"))",
)
)
CURRENT_REGEX = r"""(?i)\b((?:https?:(?:/{1,3}|[a-z0-9%])|[a-z0-9.\-]+[.](?:com|net|org|edu|gov|mil|aero|asia|biz|cat|coop|info|int|jobs|mobi|museum|name|post|pro|tel|travel|xxx|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cs|cu|cv|cx|cy|cz|dd|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|Ja|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw)/)(?:[^\s()<>{}\[\]]+|\([^\s()]*?\([^\s()]+\)[^\s()]*?\)|\([^\s]+?\))+(?:\([^\s()]*?\([^\s()]+\)[^\s()]*?\)|\([^\s]+?\)|[^\s`!()\[\]{};:'".,<>?«»“”‘’])|(?:(?<!@)[a-z0-9]+(?:[.\-][a-z0-9]+)*[.](?:com|net|org|edu|gov|mil|aero|asia|biz|cat|coop|info|int|jobs|mobi|museum|name|post|pro|tel|travel|xxx|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cs|cu|cv|cx|cy|cz|dd|de|dj|dk|dm|do|dz|ec|ee|eg|eh|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mm|mn|mo|mp|mq|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|Ja|sk|sl|sm|sn|so|sr|ss|st|su|sv|sx|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw)\b/?(?!@)))"""
NEW_REGEX = "(http[s]?:\/\/)(www\.)?([a-zA-Z0-9$-_@&+!*\(\),\/\.]+[\.])([a-zA-Z]+)([\/\.\-\_\=?#a-zA-Z0-9@&_=:%+~\(\)]+)"
# read file content
file_path = "links.txt"
with open(file_path, "r") as file:
content = file.read()
links = [ l for l in content.split("\n") if "http" in l ]
# 1st regex
t01 = time.time()
for i in range(1000):
urls0 = re.findall(URL_REGEX1, content)
t02 = time.time()
print("DT0 =", t02-t01)
print("LEN0 = ", len(urls0))
# final regex
t11 = time.time()
for i in range(1000):
urls1 = re.findall(CURRENT_REGEX, content)
t12 = time.time()
print("DT1 =", t12-t11)
print("LEN1 = ", len(urls1))
# 2nd regex
t21 = time.time()
for i in range(1000):
urls2 = ["".join(x) for x in re.findall(NEW_REGEX, content)]
t22 = time.time()
print("DT2 =", t22-t21)
print("LEN2 = ", len(urls2))links.txt is a file with 755 urls, each on a seperate line. These urls are collected from the logs of buildtest and us-rse. The results of the previous comparison are the following:
DT0 = 2.3765275478363037
LEN0 = 748
DT1 = 0.7541322708129883
LEN1 = 755
DT2 = 0.6342747211456299
LEN2 = 755
As you can see the long beautifully formatted regex takes a lot of time and is worse than the others. The newest regex is the fastest and it returns urls that for sure has http or https in them.
I suggest you take a look at all this, and maybe test the regex too with different urls and different ideas to check its robustness and if your results are positive too then I can submit a PR 😉 This blog post: In search of the perfect URL validation regex is a good inspiration. I think we rank somewhat third according to their test.
Hello, I've observed what seems to be a regression in the latest release.
With version 0.0.30, the URLs in the test file I have there are correctly flagged as problematic but 0.0.31 doesn't appear to work at all.
crd@raspberrypi:~ $ python3 -m venv uc
crd@raspberrypi:~ $ . uc/bin/activate
(uc) crd@raspberrypi:~ $ cd uc
(uc) crd@raspberrypi:~/uc $ mkdir foo
(uc) crd@raspberrypi:~/uc $ cat > foo/foo.md
* Principal Lead Software Engineer -- https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997
* Senior Software Engineer -- https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999
* Associate Software Engineer -- https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005
(uc) crd@raspberrypi:~/uc $ pip install urlchecker==0.0.30
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Collecting urlchecker==0.0.30
Using cached https://www.piwheels.org/simple/urlchecker/urlchecker-0.0.30-py3-none-any.whl (26 kB)
Collecting fake-useragent
Using cached https://www.piwheels.org/simple/fake-useragent/fake_useragent-0.1.11-py3-none-any.whl (13 kB)
Collecting requests>=2.18.4
Using cached https://www.piwheels.org/simple/requests/requests-2.28.1-py3-none-any.whl (62 kB)
Collecting certifi>=2017.4.17
Using cached https://www.piwheels.org/simple/certifi/certifi-2022.6.15-py3-none-any.whl (160 kB)
Collecting idna<4,>=2.5
Using cached https://www.piwheels.org/simple/idna/idna-3.3-py3-none-any.whl (64 kB)
Collecting charset-normalizer<3,>=2
Using cached https://www.piwheels.org/simple/charset-normalizer/charset_normalizer-2.1.0-py3-none-any.whl (39 kB)
Collecting urllib3<1.27,>=1.21.1
Using cached https://www.piwheels.org/simple/urllib3/urllib3-1.26.11-py2.py3-none-any.whl (139 kB)
Installing collected packages: urllib3, idna, charset-normalizer, certifi, requests, fake-useragent, urlchecker
Successfully installed certifi-2022.6.15 charset-normalizer-2.1.0 fake-useragent-0.1.11 idna-3.3 requests-2.28.1 urlchecker-0.0.30 urllib3-1.26.11
(uc) crd@raspberrypi:~/uc $ urlchecker check foo/
original path: foo/
final path: foo/
subfolder: None
branch: main
cleanup: False
file types: ['.md', '.py']
files: []
print all: True
verbose: False
urls excluded: []
url patterns excluded: []
file patterns excluded: []
force pass: False
retry count: 2
save: None
timeout: 5
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997
HTTPSConnectionPool(host='uwhires.admin.washington.edu', port=443): Max retries exceeded with url: /ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1123)')))
https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997
🤔 Uh oh... The following urls did not pass:
❌️ https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=210005
❌️ https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209999
❌️ https://uwhires.admin.washington.edu/ENG/Candidates/default.cfm?szCategory=jobprofile&szOrderID=209997
(uc) crd@raspberrypi:~/uc $ pip install --upgrade urlchecker==0.0.31
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Collecting urlchecker==0.0.31
Using cached https://www.piwheels.org/simple/urlchecker/urlchecker-0.0.31-py3-none-any.whl (28 kB)
Requirement already satisfied: fake-useragent in ./lib/python3.9/site-packages (from urlchecker==0.0.31) (0.1.11)
Requirement already satisfied: requests>=2.18.4 in ./lib/python3.9/site-packages (from urlchecker==0.0.31) (2.28.1)
Requirement already satisfied: charset-normalizer<3,>=2 in ./lib/python3.9/site-packages (from requests>=2.18.4->urlchecker==0.0.31) (2.1.0)
Requirement already satisfied: idna<4,>=2.5 in ./lib/python3.9/site-packages (from requests>=2.18.4->urlchecker==0.0.31) (3.3)
Requirement already satisfied: certifi>=2017.4.17 in ./lib/python3.9/site-packages (from requests>=2.18.4->urlchecker==0.0.31) (2022.6.15)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in ./lib/python3.9/site-packages (from requests>=2.18.4->urlchecker==0.0.31) (1.26.11)
Installing collected packages: urlchecker
Attempting uninstall: urlchecker
Found existing installation: urlchecker 0.0.30
Uninstalling urlchecker-0.0.30:
Successfully uninstalled urlchecker-0.0.30
Successfully installed urlchecker-0.0.31
(uc) crd@raspberrypi:~/uc $ urlchecker check foo/
original path: foo/
final path: foo/
subfolder: None
branch: main
cleanup: False
file types: ['.md', '.py']
files: []
print all: True
verbose: False
urls excluded: []
url patterns excluded: []
file patterns excluded: []
force pass: False
retry count: 2
save: None
timeout: 5
2022-07-26 20:55:30,171 - urlchecker - ERROR - Error running task
🤔 There were no URLs to check.
(uc) crd@raspberrypi:~/uc $
Maybe I'm doing something wrong?
@SuperKogito we are currently using your personal site for most tests, and there are quite a few files! What do you think about creating a dummy (smaller version of it) here, and then using that for consistent testing?
Hi there,
I was playing around with your library, and had to dig into your code to see how exclude patterns work. I think I understand correctly that they're substrings (not glob/regex) that can appear in a URL to exclude it from consideration.
Might I suggest that their format and use is clarified in the docs?
See https://github.com/r-hub/docs/runs/576617965?check_suite_focus=true
force pass is false, so this should not be successful.
Sorry I'm breaking my promise to no longer comment for a while!
I've run urlchecker via the action on a website, https://github.com/r-hub/docs/runs/576617965?check_suite_focus=true
I get false positives for e.g. https://www.r-pkg.org/badges/version/ that's actually escaped in my content file (as code) https://github.com/r-hub/docs/blob/master/content/badges/_index.md#cran-versions I'm guessing it's because of regex?
To extract links (in R) I use the commonmark package that uses cmark. Post about URL cleaning, Post about commonmark. There seems to be a Python commonmark library. That said a limitation of this approach is that it wouldn't recognize URLs in text (that e.g. Hugo would transform to links).
I saw that you are included the urlstechie logo but I think it is better to using something unique for the lib. After playing with some stuff today I came up with this, what do you think of it?

it is a link logo as two snakes with the colors of python xD
The article @vsoch wrote on her blog along with her tweet should help spread the world about the urlstechie tools. This issue is a place to brainstorm and collect suggestions and ideas on how to gain more attention for the project. We should also discuss pacing and maybe construct a tilmeline for the actions we will take, cuz too much posting can be spamming and that way the actions we take will backfire :/
Here is my list of things I intend to do the up-coming days that I hope to help us get more attention:
I partially tried the previous steps with other projects I have. In all fairness, they did help boost some projects a little but nothing major with the exception of submitting a paper to JOSS. That seemed to be the most successful action, I did. However, for our tools, I don't think a research paper is an option.
As you can see, there is little experience here about promoting the tools. So any suggestions are welcome. The tool is very useful thanks to the additions of @vsoch and it should be able to prove itself, that imo is the best promotion eventually cuz a good tool is reliable. So the aim here is not do advertisement but rather give the tool a little push so we can take this project to the next level ;)
Could there be an option to only print the URLs for which there was a failure? This way it'd be easier to go through them for a website that has many URLs?
We currently have a bug that urls represented in yaml / json (or another data structure) that end in } are not being correctly parsed. Here is an example:

@SuperKogito can you take a look soon?
urlchecker-python/urlchecker/core/urlproc.py
Line 114 in 04c8462
And along with this, an example CI run on CircleCI, which would allow us to save an html report and then render it (in the browser) directly as an artifact. Related #38
@vsoch How do you feel about adding type hints to our code?
This seems to be the trend these days and it will provide us with some type security and it doesn't seem to be that much of a hassle.
sample markdown text like "输入foo https://example.com,然后", extracted url is "https://example.com`,然后", expected is "https://example.com"
This is a followup to urlchecker-action #72: The misspelling "whitetlist" (note extra T) is in the python script.
check.py line 66
README.md lines 115, 192
I was going to create a PR, but then I thought you might be considering changing "white(_)list(ed)" options to "exclude(d)" to match the change in urlchecker-action, in which case much more than these lines would be getting changed.
As I noted in the title, this is a minor fix, just wanted to follow up since I mentioned it in the original issue and figured out where it was from.
Preconditions:
Steps to reproduce:
cd documentationurlchecker check . --timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"Actual result:
❯ urlchecker check . --timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"
original path: .
final path: /home/sturivny/git-cki/documentation
subfolder: None
branch: main
cleanup: False
file types: ['.md', '.py']
files: ['content/docs/hacking/contributing/documentation/index.md']
print all: True
verbose: False
urls excluded: []
url patterns excluded: []
file patterns excluded: []
force pass: False
retry count: 5
save: None
timeout: 60
https://gitlab.com/cki-project/documentation/
https://gohugo.io/
https://www.docsy.dev/
https://gohugo.io/content-management/page-bundles/
https://cki-project.org/
https://www.gnu.org/software/stow/
2022-08-04 12:42:32,421 - urlchecker - ERROR - Error running task
ERROR:urlchecker:Error running task
🤔 There were no URLs to check.
Exception ignored in: <function Pool.__del__ at 0x7fd954e7eee0>
Traceback (most recent call last):
File "/usr/lib64/python3.9/multiprocessing/pool.py", line 268, in __del__
self._change_notifier.put(None)
File "/usr/lib64/python3.9/multiprocessing/queues.py", line 377, in put
self._writer.send_bytes(obj)
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 205, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 416, in _send_bytes
self._send(header + buf)
File "/usr/lib64/python3.9/multiprocessing/connection.py", line 373, in _send
n = write(self._handle, buf)
OSError: [Errno 9] Bad file descriptor
Expected result:
No Errors
heyo! So this will take a bit more time to develop, but I'm working on the action refactor and I think we can really streamline it if we release a build for the container here. For a quick solution I'm going to build the container and manually push to Docker Hub to use as a base, but I wanted to open this issue so we can discuss:
Let's say I wanted to check all .html files, but also ALL dotfiles -- that is, files that have no filename, only an extension (.editorconfig, say, or .pylintrc).
Why would I want to do that? Because sometimes I use comments in these files to source where I got something, and I want to check URLs there to know if/when they break.
I'm sure this is an edge case, but is there a syntax for file_types that would include all dotfiles (not just specific ones)? I tried a few different things but none of them worked.
Thanks!
Preconditions:
Steps to reproduce:
cd documentation--timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"Actual result:
❯ urlchecker check . --timeout 60 --retry-count 5 --files "content/docs/hacking/contributing/documentation/index.md"
original path: .
final path: /home/sturivny/git-cki/documentation
subfolder: None
branch: main
cleanup: False
file types: ['.md', '.py']
files: ['content/docs/hacking/contributing/documentation/index.md']
print all: True
verbose: False
urls excluded: []
url patterns excluded: []
file patterns excluded: []
force pass: False
retry count: 5
save: None
timeout: 60
Expected result:
No Errors
The link provided by maelle in urlstechie/urlchecker-action#61 gave me an idea, so I am just laying this out here to get your input on it. So far we only provide urls checks/tests results, but wouldn't it be also nice to provide a summary of the tests and some stats, something like:
Urls checks summary
-----------------------------
Total count of tested files : 10
Total count of tested urls : 51
Total count of working urls : 48
Total count of failed urls : 3
etc.
last question from me for a while I promise :-)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.