v8hid / infinite-zoom-automatic1111-webui Goto Github PK
View Code? Open in Web Editor NEWinfinite zoom effect extension for AUTOMATIC1111's webui - stable diffusion
License: MIT License
infinite zoom effect extension for AUTOMATIC1111's webui - stable diffusion
License: MIT License



















































































































It would be nice to get a sense of how to get good results and what models do a good job.
venv "stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Commit hash: 00dab8f10defbbda579a1bc89c8d4e972c58a20d
Installing requirements for Web UI
Installing requirements 1 for Infinite-Zoom
#######################################################################################################
Initializing Dreambooth
If submitting an issue on github, please provide the below text for debugging purposes:
Python revision: 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Dreambooth revision: 43ae9d55531004f1dedaea7ac2443e9b16739913
SD-WebUI revision: 00dab8f10defbbda579a1bc89c8d4e972c58a20d
Checking Dreambooth requirements...
[+] bitsandbytes version 0.35.0 installed.
[+] diffusers version 0.10.2 installed.
[+] transformers version 4.25.1 installed.
[+] xformers version 0.0.16rc425 installed.
[+] torch version 1.13.1+cu117 installed.
[+] torchvision version 0.14.1+cu117 installed.
#######################################################################################################
Launching Web UI with arguments: --xformers
[AddNet] Updating model hashes...
0it [00:00, ?it/s]
[AddNet] Updating model hashes...
0it [00:00, ?it/s]
SD-Webui API layer loaded
Loading weights [e6415c4892] from stable-diffusion-webui\models\Stable-diffusion\realisticVisionV20_v20.safetensors
Creating model from config: stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying xformers cross attention optimization.
Model loaded in 6.4s (create model: 0.5s, apply weights to model: 1.1s, apply half(): 1.3s, load VAE: 1.2s, move model to device: 0.9s, load textual inversion embeddings: 1.2s).
Traceback (most recent call last):
File "\stable-diffusion-webui\launch.py", line 361, in
start()
File "\stable-diffusion-webui\launch.py", line 356, in start
webui.webui()
File "\stable-diffusion-webui\webui.py", line 202, in webui
app, local_url, share_url = shared.demo.launch(
File "\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1337, in launch
raise ValueError("Progress tracking requires queuing to be enabled.")
ValueError: Progress tracking requires queuing to be enabled.
Press any key to continue . . .
Describe the bug
A clear and concise description of what the bug is.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
A clear and concise description of what you expected to happen.
Screenshots of error
If applicable, add screenshots to help explain your problem. Or just dump the error.
Desktop (please complete the following information):
Additional context
Add any other context about the problem here.
Error completing request
Arguments: ([[0, 'Jungle with lush green trees and clear blue sky'], ['3', 'Jungle with tall brown trees and orange sunset sky'], ['5', 'Jungle with sparse trees and dark stormy sky'], ['10', 'Jungle with yellow autumn trees and purple twilight sky']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur bad-artist', 14, 7, 50, None, None, 30, 0, 0, 0, 1, 0, 2, False, 0, 1, 512, 512, 1, 'Euler a', False, 'None', 1) {}
Traceback (most recent call last):
File "E:\tools\stable\novelai-webui-aki-v3A\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "E:\tools\stable\novelai-webui-aki-v3A\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 242, in create_zoom
result = create_zoom_single(
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 330, in create_zoom_single
processed = renderTxt2Img(
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 132, in renderTxt2Img
processed = process_images(p)
File "E:\tools\stable\novelai-webui-aki-v3A\modules\processing.py", line 503, in process_images
res = process_images_inner(p)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\sd-webui-controlnet\scripts\batch_hijack.py", line 39, in processing_process_images_hijack
cn_is_batch, batches, output_dir, input_file_names = get_cn_batches(p)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\sd-webui-controlnet\scripts\batch_hijack.py", line 184, in get_cn_batches
units = external_code.get_all_units_in_processing(p)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\sd-webui-controlnet\scripts\external_code.py", line 104, in get_all_units_in_processing
return get_all_units(p.scripts, p.script_args)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\sd-webui-controlnet\scripts\external_code.py", line 113, in get_all_units
cn_script = find_cn_script(script_runner)
File "E:\tools\stable\novelai-webui-aki-v3A\extensions\sd-webui-controlnet\scripts\external_code.py", line 280, in find_cn_script
for script in script_runner.alwayson_scripts:
AttributeError: 'NoneType' object has no attribute 'alwayson_scripts'
Traceback (most recent call last):
File "E:\tools\stable\novelai-webui-aki-v3A\py310\lib\site-packages\gradio\blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\tools\stable\novelai-webui-aki-v3A\py310\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "E:\tools\stable\novelai-webui-aki-v3A\py310\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "E:\tools\stable\novelai-webui-aki-v3A\py310\lib\site-packages\gradio\blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f
I'm having an issue upscaling with 4x-Ultrasharp in postprocessing. This is the total progress after after batch 1 and then the error:
Batch 1/1
0% 0/50 [00:00<?, ?it/s]
2% 1/50 [00:00<00:07, 6.55it/s]
4% 2/50 [00:00<00:07, 6.64it/s]
6% 3/50 [00:00<00:07, 6.62it/s]
8% 4/50 [00:00<00:06, 6.68it/s]
10% 5/50 [00:00<00:06, 6.72it/s]
12% 6/50 [00:00<00:06, 6.72it/s]
14% 7/50 [00:01<00:06, 6.67it/s]
16% 8/50 [00:01<00:06, 6.70it/s]
18% 9/50 [00:01<00:06, 6.70it/s]
20% 10/50 [00:01<00:05, 6.70it/s]
22% 11/50 [00:01<00:05, 6.71it/s]
24% 12/50 [00:01<00:05, 6.72it/s]
26% 13/50 [00:01<00:05, 6.72it/s]
28% 14/50 [00:02<00:05, 6.70it/s]
30% 15/50 [00:02<00:05, 6.70it/s]
32% 16/50 [00:02<00:05, 6.71it/s]
34% 17/50 [00:02<00:04, 6.69it/s]
36% 18/50 [00:02<00:04, 6.68it/s]
38% 19/50 [00:02<00:04, 6.68it/s]
40% 20/50 [00:02<00:04, 6.67it/s]
42% 21/50 [00:03<00:04, 6.67it/s]
44% 22/50 [00:03<00:04, 6.65it/s]
46% 23/50 [00:03<00:04, 6.67it/s]
48% 24/50 [00:03<00:03, 6.69it/s]
50% 25/50 [00:03<00:03, 6.68it/s]
52% 26/50 [00:03<00:03, 6.68it/s]
54% 27/50 [00:04<00:03, 6.66it/s]
56% 28/50 [00:04<00:03, 6.69it/s]
58% 29/50 [00:04<00:03, 6.67it/s]
60% 30/50 [00:04<00:02, 6.67it/s]
62% 31/50 [00:04<00:02, 6.67it/s]
64% 32/50 [00:04<00:02, 6.69it/s]
66% 33/50 [00:04<00:02, 6.64it/s]
68% 34/50 [00:05<00:02, 6.64it/s]
70% 35/50 [00:05<00:02, 6.63it/s]
72% 36/50 [00:05<00:02, 6.67it/s]
74% 37/50 [00:05<00:01, 6.64it/s]
76% 38/50 [00:05<00:01, 6.64it/s]
78% 39/50 [00:05<00:01, 6.63it/s]
80% 40/50 [00:05<00:01, 6.65it/s]
82% 41/50 [00:06<00:01, 6.65it/s]
84% 42/50 [00:06<00:01, 6.59it/s]
86% 43/50 [00:06<00:01, 6.60it/s]
88% 44/50 [00:06<00:00, 6.54it/s]
90% 45/50 [00:06<00:00, 6.53it/s]
92% 46/50 [00:06<00:00, 6.42it/s]
94% 47/50 [00:07<00:00, 6.43it/s]
96% 48/50 [00:07<00:00, 6.54it/s]
98% 49/50 [00:07<00:00, 6.60it/s]
100% 50/50 [00:07<00:00, 6.65it/s]
Error completing request
Arguments: ([[0, ' ((Best quality)), ((masterpiece)),((realistic)),lord of the rings hobbit village, blue sky on top, scenic, masterpiece'], ['3', '((Best quality)), ((masterpiece)),((realistic)),lord of the rings lush green mountain forest with small river, blue sky on top, scenic, masterpiece'], ['6', '((Best quality)), ((masterpiece)),((realistic)),lord of the rings mountain valley in the alps, blue sky on top, scenic, masterpiece']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur bad-artist', 8, 7, 50, None, None, 30, 1, 0, 0, 1, 0, 2, False, 0, 2, 512, 512, 1, 'Euler a', True, '4x-UltraSharp', 2) {}
Traceback (most recent call last):
File "/content/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/content/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/content/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/infinite-zoom.py", line 242, in create_zoom
result = create_zoom_single(
File "/content/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/infinite-zoom.py", line 352, in create_zoom_single
do_upscaleImg(current_image, upscale_do, upscaler_name, upscale_by)
File "/content/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/infinite-zoom.py", line 102, in do_upscaleImg
ups.process(
File "/content/stable-diffusion-webui/scripts/postprocessing_upscale.py", line 94, in process
upscaled_image = self.upscale(pp.image, pp.info, upscaler1, upscale_mode, upscale_by, upscale_to_width, upscale_to_height, upscale_crop)
File "/content/stable-diffusion-webui/scripts/postprocessing_upscale.py", line 64, in upscale
image = upscaler.scaler.upscale(image, upscale_by, upscaler.data_path)
File "/content/stable-diffusion-webui/modules/upscaler.py", line 63, in upscale
img = self.do_upscale(img, selected_model)
File "/content/stable-diffusion-webui/modules/esrgan_model.py", line 154, in do_upscale
img = esrgan_upscale(model, img)
File "/content/stable-diffusion-webui/modules/esrgan_model.py", line 225, in esrgan_upscale
output = upscale_without_tiling(model, tile)
File "/content/stable-diffusion-webui/modules/esrgan_model.py", line 204, in upscale_without_tiling
output = model(img)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/modules/esrgan_model_arch.py", line 62, in forward
return self.model(feat)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/container.py", line 204, in forward
input = module(input)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/stable-diffusion-webui/extensions-builtin/Lora/lora.py", line 201, in lora_Conv2d_forward
return lora_forward(self, input, torch.nn.Conv2d_forward_before_lora(self, input))
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/conv.py", line 459, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Given groups=1, weight of size [64, 3, 3, 3], expected input[1, 4, 192, 192] to have 3 channels, but got 4 channels instead
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/gradio/routes.py", line 337, in run_predict
output = await app.get_blocks().process_api(
File "/usr/local/lib/python3.9/dist-packages/gradio/blocks.py", line 1018, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "/usr/local/lib/python3.9/dist-packages/gradio/blocks.py", line 935, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
I use a colab. I don't know if that has anything to do with it. I have already created other infinite zoom videos, so this the next thing I am testing.
After following the simple install steps, now:

I think it needs to wait for model loading
I am getting the error above after I run the generate button but the video still appears in the output.
Steps to reproduce:
Use default setting
Things I tried:
I am able to see the version of ffmpeg when I do ffmpeg -version in cmd so I am not sure what the problem is exactly. Hoping that someone has the solution to this.
Here is a snippet of the error:
Outpaint step: 1 / 2
100%|██████████████████████████████████████████████████████████████████████████████████| 50/50 [00:34<00:00, 1.44it/s]
Outpaint step: 2 / 2
100%|██████████████████████████████████████████████████████████████████████████████████| 50/50 [00:34<00:00, 1.44it/s]
Traceback (most recent call last):
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\ffmpy.py", line 93, in run
self.process = subprocess.Popen(
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\subprocess.py", line 971, in init
self._execute_child(args, executable, preexec_fn, close_fds,
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\subprocess.py", line 1440, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] The system cannot find the file specified
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\gradio\blocks.py", line 1012, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\gradio\components.py", line 1979, in postprocess
and not processing_utils.video_is_playable(y)
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\gradio\processing_utils.py", line 783, in video_is_playable
output = probe.run(stderr=subprocess.PIPE, stdout=subprocess.PIPE)
File "C:\Users\nicky\AppData\Local\Programs\Python\Python310\lib\site-packages\ffmpy.py", line 98, in run
raise FFExecutableNotFoundError(
ffmpy.FFExecutableNotFoundError: Executable 'ffprobe' not found
Loading weights [8db0e00911] from C:\Users\xxxx\Deep\stable-diffusion-webui\models\Stable-diffusion\Jelli.ckpt
Applying scaled dot product cross attention optimization.
Weights loaded in 9.4s (load weights from disk: 8.6s, apply weights to model: 0.2s, move model to device: 0.6s).
Error completing request
Arguments: ([['A psychedelic hyper-realistic photo of Jellili person in space, fractal-like patterns, a close up of Jelliperson eye, galaxy in space hyper futuristic, 8k resolution, hyper realistic', '']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur', 8, 7, 50, None, 30, 0, 0, 0, 1, 0, 2, False, 0) {}
Traceback (most recent call last):
File "C:\Users\xxxx\Deep\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "C:\Users\xxxx\Deep\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "C:\Users\xxxx\Deep\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\inifnite-zoom.py", line 132, in create_zoom
prompts[min(k for k in prompts.keys() if k >= 0)],
ValueError: min() arg is an empty sequence
Traceback (most recent call last):
File "C:\Users\xxxx\Deep\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\xxxx\Deep\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\xxxx\Deep\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "C:\Users\xxxx\Deep\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f
Describe the bug
Returns error, not working. It used to work before.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Should generate video.
Screenshots of error
Batch 1/1
0%| | 0/50 [00:01<?, ?it/s]
Error completing request
Arguments: ([[0, 'Huge spectacular Waterfall in a dense tropical forest,epic perspective,(vegetation overgrowth:1.3)(intricate, ornamentation:1.1),(baroque:1.1), fantasy, (realistic:1) digital painting , (magical,mystical:1.2) , (wide angle shot:1.4), (landscape composed:1.2)(medieval:1.1), divine,cinematic,(tropical forest:1.4),(river:1.3)mythology,india, volumetric lighting, Hindu ,epic, Alex Horley Wenjun Lin greg rutkowski Ruan Jia (Wayne Barlowe:1.2) <lora:epiNoiseoffset_v2:0.6> ']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur bad-artist', 8, 7, 50, None, None, 30, 0, 0, 0, 1, 0, 2, False, 0, 1, 512, 512, 1, 'Euler a', False, 'None', 1) {}
Traceback (most recent call last):
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 242, in create_zoom
result = create_zoom_single(
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 330, in create_zoom_single
processed = renderTxt2Img(
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 132, in renderTxt2Img
processed = process_images(p)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 503, in process_images
res = process_images_inner(p)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\batch_hijack.py", line 42, in processing_process_images_hijack
return getattr(processing, '__controlnet_original_process_images_inner')(p, *args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 653, in process_images_inner
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength, prompts=prompts)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\processing.py", line 869, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 358, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 234, in launch_sampling
return func()
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 358, in <lambda>
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\sampling.py", line 145, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py", line 126, in forward
x_out = self.inner_model(x_in, sigma_in, cond=make_condition_dict([cond_in], image_cond_in))
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py", line 167, in forward
return self.get_v(input * c_in, self.sigma_to_t(sigma), **kwargs) * c_out + input * c_skip
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py", line 177, in get_v
return self.inner_model.apply_model(x, t, cond)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_utils.py", line 17, in <lambda>
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_utils.py", line 28, in __call__
return self.__orig_func(*args, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py", line 797, in forward
h = module(h, emb, context)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py", line 84, in forward
x = layer(x, context)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 334, in forward
x = block(x, context=context[i])
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 269, in forward
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\util.py", line 121, in checkpoint
return CheckpointFunction.apply(func, len(inputs), *args)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\util.py", line 136, in forward
output_tensors = ctx.run_function(*ctx.input_tensors)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\attention.py", line 273, in _forward
x = self.attn2(self.norm2(x), context=context) + x
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\modules\sd_hijack_optimizations.py", line 332, in xformers_attention_forward
k_in = self.to_k(context_k)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions-builtin\Lora\lora.py", line 305, in lora_Linear_forward
lora_apply_weights(self)
File "D:\Graphics\stable-diffusion-webui\stable-diffusion-webui\extensions-builtin\Lora\lora.py", line 273, in lora_apply_weights
self.weight += lora_calc_updown(lora, module, self.weight)
RuntimeError: The size of tensor a (1024) must match the size of tensor b (768) at non-singleton dimension 1
Traceback (most recent call last):
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "d:\Graphics\stable-diffusion-webui\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f
Desktop (please complete the following information):
Additional context
I was able to use it before, seems something broke after updates.
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/gradio/routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "/usr/local/lib/python3.9/dist-packages/gradio/blocks.py", line 1075, in process_api
result = await self.call_function(
File "/usr/local/lib/python3.9/dist-packages/gradio/blocks.py", line 884, in call_function
prediction = await anyio.to_thread.run_sync(
File "/usr/local/lib/python3.9/dist-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/usr/local/lib/python3.9/dist-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/usr/local/lib/python3.9/dist-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/infinite-zoom.py", line 154, in create_zoom
result = create_zoom_single(
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/infinite-zoom.py", line 357, in create_zoom_single
write_video(
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/iz_helpers/video.py", line 35, in write_video
writer.append_data(np_frame)
File "/usr/local/lib/python3.9/dist-packages/imageio/core/format.py", line 590, in append_data
return self._append_data(im, total_meta)
File "/usr/local/lib/python3.9/dist-packages/imageio/plugins/ffmpeg.py", line 591, in _append_data
raise ValueError("All images in a movie should have same size")
ValueError: All images in a movie should have same size
Is it possible to also have last image same as first image making an infinite loop?
Hi, I get following errors and don't know what to do:
Error loading script: infinite-zoom.py
File "D:\AI\stable-diffusion-webui-master\stable-diffusion-webui-master\scripts\infinite-zoom.py", line 2, in
from iz_helpers.ui import on_ui_tabs
ModuleNotFoundError: No module named 'iz_helpers'
Error loading script: infinite-zoom.py
File "D:\AI\stable-diffusion-webui-master\stable-diffusion-webui-master\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 2, in
from iz_helpers.ui import on_ui_tabs
File "D:\AI\stable-diffusion-webui-master\stable-diffusion-webui-master\extensions\infinite-zoom-automatic1111-webui\iz_helpers\ui.py", line 2, in
from .run import create_zoom
File "D:\AI\stable-diffusion-webui-master\stable-diffusion-webui-master\extensions\infinite-zoom-automatic1111-webui\iz_helpers\run.py", line 6, in
from modules.paths_internal import script_path
ModuleNotFoundError: No module named 'modules.paths_internal'
Describe the bug
when i create a vieo is error;
Traceback (most recent call last):
File "/Users/cgd/cgd/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/routes.py", line 408, in run_predict
output = await app.get_blocks().process_api(
File "/Users/cgd/cgd/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 1318, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "/Users/cgd/cgd/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 1221, in postprocess_data
self.validate_outputs(fn_index, predictions) # type: ignore
File "/Users/cgd/cgd/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 1196, in validate_outputs
raise ValueError(
ValueError: An event handler (f) didn't receive enough output values (needed: 5, received: 4)
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Screenshots of error
Desktop (please complete the following information):



Additional context
The InfZoom Extension is nice to create panorama videos, when using a 360-panorama-LORA or just prompt "360 full panorama view"
My extension has a 360-panorama-viewer integrated and I added a sento-button, see screenshot.
360 Panoramas need much resolution. Is there an UI-setting planned to setup resolution? and or include an upscaler? nice if details could be added while upscaling.
https://github.com/GeorgLegato/sd-webui-panorama-viewer

One issue with outpainting an image without a mask_blur is that it can result in a noticeable frame around the edges of the image. While using an inpainting model can help to reduce this effect, there may still be instances where the frame is visible or there is a noticeable color shift.




The possible solution I came up with is to crop the initial image from the second generated image and replace the first frame with it. And repeat it for every iteration.
I think it is not used in code and that intentionally, is it just a numbering?
@v8hid we could remove it, right?
I have the same problem and found some manual workaround; if not solution.
My setup is Windows, SD is latest version (22bcc or so)
ffrpobe is still not found.
I "pip install ffprobe", did not help.
The pyffprobe is only a wrapper for some ffprope.exe, which has to be
So, I downloaded from github latest ffmpeg release (https://github.com/BtbN/FFmpeg-Builds/releases) and
upacked somewhere.
Now, you need to extend the PATH variable in the context where you SD-Webui is started; either manually
set PATH=%PATH%;C:\Users\YOU\Downloads\ffmpeg-master-latest-win64-gpl\bin
Pros put that in their web-user.bat...
@v8hid You could solve that more elegant by provide a Settings-property "PathToFFMPEG" and set OS.Path accordingly
Originally posted by @GeorgLegato in #3 (comment)
I can make Zoom In videos that have no initial image, but when I included an initial image, I got an error message. However, I WAS still able to retrieve the Zoom In video with initial image in Outputs>>img2img-images>>infinite-zooms, so I was good with it. But now I can't. The resulting Zoom In video with initial image only has the first frame. I have the pictures that make this Zoom In video in img2img-images folder in the today's date folder. If you can point me to something to can put these images together for the Zoom In video for the time being I'll be happy.
Whenever I have chrome open and infinite zoom is processing GPU load specifically shoots up like crazy. However if I minify a1111 chrome window a lot of usage drops and processing is working as it should. I noticed this only happening with infinite zoom.
This is weird, I'm assuming some kind of UI reporting code is written in a blocking way?
Hi, thanks for extension!
Is it possible to add another slider that controls the zoom speed?
I want to make a video with this effect, but at a much slower speed...
Describe the bug
The program can't generate the video, I keep getting missing .ddl files, and when I download them I get new missing ones. No errors in console. I also added the path to the executables (ffmpeg.exe, ecc).
To Reproduce
Steps to reproduce the behavior:
Screenshots of error
No errors in console, just missing files (there were other ones too, but I downloaded them...).
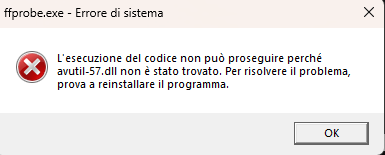
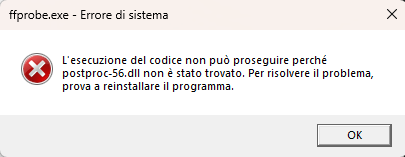


Desktop (please complete the following information):
Additional context
I had this problem even before the main webui update, so I don't think is a torch 2.0.0 or something else error.
Don't see tab after starting
Log:
Error executing callback ui_tabs_callback for D:\Soft\StableD\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py
Traceback (most recent call last):
File "D:\Soft\StableD\modules\script_callbacks.py", line 93, in ui_tabs_callback
res += c.callback() or []
File "D:\Soft\StableD\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 433, in on_ui_tabs
importPrompts_button = gr.UploadButton(
AttributeError: module 'gradio' has no attribute 'UploadButton'
Hi folks, sorry if I'm doing this wrong but I noticed that after a recent update my default prompts box was showing an error and telling me to check the settings. In the settings menu the default prompt was all on one long line and had some Loras and a bunch of other stuff in it, so I copied the example prompts from your Wiki page into the prompt boxes, exported them, and then copied them neatly into the settings menu as new defaults and sort of tidied it all up a bit. I closed everything and relaunched, and it works perfectly now.
I'm not sure if I'm the only one having this problem, but if anyone is interested here is how I setup the defaults in the settings menu, maybe it will help anyone else with the same problem. I wasn't sure about where to put the linebreaks so I just did it however, probably isn't quite proper but it works now :D I did lose the default negative somehow tho, sorry. Oh by the way, is there any way to add the number of steps to the default options menu, or have it exported with saved prompts? I tried sticking a "20" in there in a few different places but it didn't work lol.
Edit: When I pasted it into here it seems to have messed up the indents and stuff, no idea how to fix that sorry! Looks good while I'm editing and then gets flattened out when I'm done, gross lol
{"prompts":
{"data":
[
[0,"jungle with lush green trees and clear blue sky"],
["5","jungle with tall brown trees and orange sunset sky"],
["10","jungle with sparse trees and dark stormy sky"],
["15","jungle with yellow autumn trees and purple twilight sky"]
],
"headers":
["Steps","Prompts"]
},
"negPrompt":
"blur, blurry, split frame, drawing, painting, illustration, sketch, watermark, logo, monochrome"
}
Hi, and thanks for the cool extension! I figured I'd let you know that I've been getting an error message in the console on every run regardless of settings, and it's been persisting through the recent updates. The error doesn't seem to actually hurt anything as far as I can tell, but I don't know hardly anything about Python so all I can see in the error message is that it looks like SD is trying to talk to my system Python, rather than my venv Python, but I have no idea really, sorry! In any case here's the error message copied from the console, it shows up after every generation when I use Infinite Zoom;
Exception in callback _ProactorBasePipeTransport._call_connection_lost(None)
handle: <Handle _ProactorBasePipeTransport._call_connection_lost(None)>
Traceback (most recent call last):
File "C:\Users\blast\AppData\Local\Programs\Python\Python310\lib\asyncio\events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "C:\Users\blast\AppData\Local\Programs\Python\Python310\lib\asyncio\proactor_events.py", line 165, in _call_connection_lost
self._sock.shutdown(socket.SHUT_RDWR)
ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host
Edit: Forgot to add any relevant info, but if it helps I'm on the latest build of Auto's and I'm using the latest version of this extension as well. I've got a 2070 Super with 8 gigs, and if there's anything else that might help then please let me know, thanks!
hi @v8hid,
thank you for working on this, the ui looks great!
I'm not sure if you were previously aware some others were also working on infinite zoom:
https://github.com/coolzilj/infinite-zoom
https://github.com/juanigsrz/sd-fractal-zoom
And there seems to be a problem with webui's outpainting itself, noted - https://github.com/coolzilj/infinite-zoom#known-issues
You may notice a distinct frame or seam around the image, although it's less noticeable in the original diffusers version.
There are some experts in webui discussions posts who may know the reason, I don't.
Maybe we could see what @coolzilj thinks about this issue, and which extension is better to be maintained
How to set duration?
I try adding extra prompts and add 0, 75, 125 etc.. but it gets ignored and same exact duration stay no matter how many prompt i add.
The other question is why am I getting boxes without smooth inpaint? I am using offical SD 1.5 inpainting model.
sample below:
https://user-images.githubusercontent.com/4099839/232152364-b41ac254-a29a-4bdc-a14a-6f4c1b2f614a.mp4
2nd sample:
https://user-images.githubusercontent.com/4099839/232153736-97fe50d8-d037-4844-9500-819f73f0037d.mp4
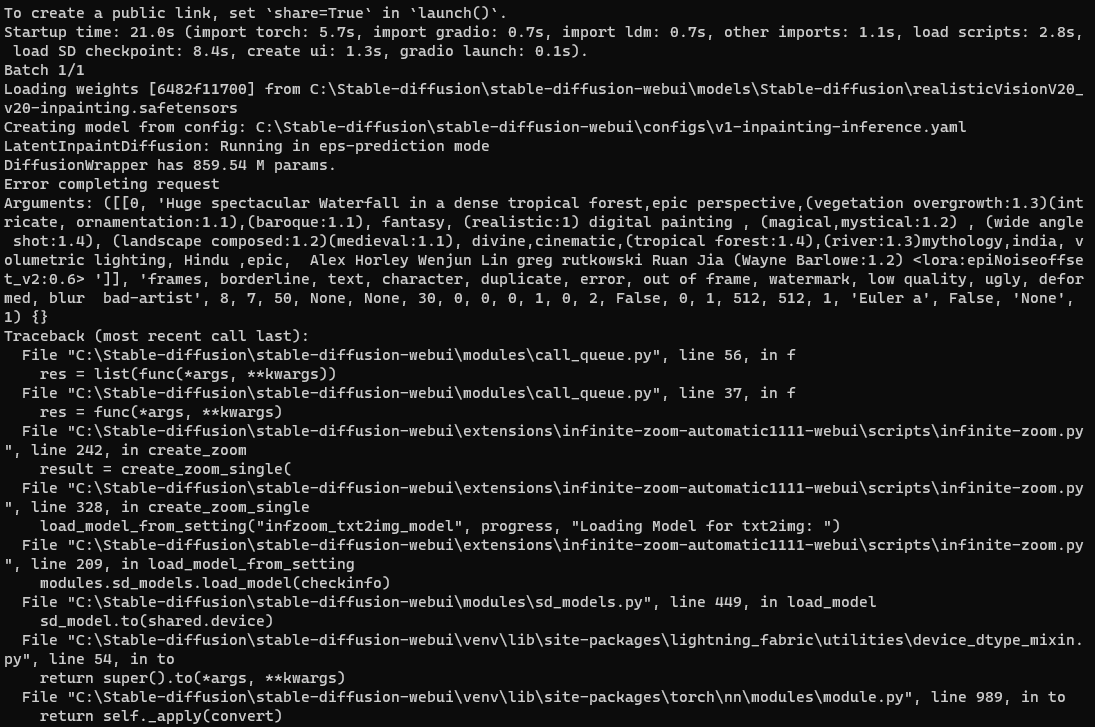

If you encounter a ValueError while using Infinite Zoom to generate, as shown in the screenshot, it could be due to insufficient VRAM. You can solve this issue by following these steps: add --xformers --medvram after COMMANDLINE_ARGS= in your Launch.bat file:
set COMMANDLINE_ARGS= --xformers --medvram
By doing this, you will reduce the VRAM usage, allowing the generation process to proceed smoothly. However, it may take longer than before.
This may seem like a minor issue, but once it occurs, it can cause the entire Stable Diffusion process to become paralyzed until you restart it. Therefore, if you don't have a large amount of VRAM, you can use the aforementioned method to reduce its usage during generation.
When I tried InfiniteZoom together with upscaling, I found that it upscales every each frame of the video, which is unnecessary in this case. It would be enough to upscale only the main generated frames and do the zooming on the upscaled ones. That would save a lot of time.
The implementation seemed simple to me, so I wanted to take it on and code this feature directly. However, I found out that there is already the optimize_upscale branch by @GeorgLegato that does exactly this.
I want to ask, what does the future look like with this feature? If that branch isn't in the development, I'd be happy to take it on, I just find the modifications unnecessarily complicated. My idea is more simple:
Thank you for the wonderful work! Zooming in and zooming out works very well. How about adding an option to move the image horizontally and vertically in addition to zooming in and out?
Would be great to have a constantly scrolling scene
Assigning to me. to avoid races or concurrent implementations
Any guide on how to generate 360 Panorama?
Users can now choose their desired sampler from the main settings page with our new Sampler Selection Field.
p.s: now it uses Euler A
is super annoying. I am not sure if it's gradio, my system or what but if I try to copy/paste, type or whatever the prompt box gets cleared and I have to click several times. it just seems janky.
Can you just make it a standard text box?
Launching Web UI with arguments: --disable-safe-unpickle --xformers
Error loading script: infinite-zoom.py
Traceback (most recent call last):
File "C:\Users\RTX01\stable-diffusion-webui\modules\scripts.py", line 205, in load_scripts
module = script_loading.load_module(scriptfile.path)
File "C:\Users\RTX01\stable-diffusion-webui\modules\script_loading.py", line 13, in load_module
exec(compiled, module.dict)
File "C:\Users\RTX01\stable-diffusion-webui\extensions\infinite-zoom-automatic1111-webui\scripts\infinite-zoom.py", line 23, in
from scripts import postprocessing_upscale
ImportError: cannot import name 'postprocessing_upscale' from 'scripts' (unknown location)
As the title suggests, the Automatic 1111 WebUI Extension for Infinite Zoom is missing after I updated it. I used it yesterday for many hours. No problems. The update has caused some sort of issue. I still see Infinite Zoom in my extensions folder and it is active but the tab is nowhere to be found. I reinstalled Infinite Zoom and restarted "webui-user.bat". It did not make a difference. Any solutions or a way to rollback to the previous version?
If upscale factor * output pixel-size => odd width => ffmpeg dies:
720 px width * 1.66 upscale => 1195.2 => 1195 crash
Inputs:



[swscaler @ 0000022737ce1000] Warning: data is not aligned! This can lead to a speed loss
[libx264 @ 0000022737c8d400] width not divisible by 2 (1195x849)
Error initializing output stream 0:0 -- Error while opening encoder for output stream #0:0 - maybe incorrect parameters such as bit_rate, rate, width or height
gradio call: OSError
╭───────────────────────────────────────────────────────────────────────── Traceback (most recent call last) ─────────────────────────────────────────────────────────────────────────╮│ S:\KI\Vladmandic1111\venv\lib\site-packages\imageio_ffmpeg_io.py:630 in write_frames ││ ││ 629 │ │ │ try: ││ ❱ 630 │ │ │ │ p.stdin.write(bb) ││ 631 │ │ │ except Exception as err: │╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯BrokenPipeError: [Errno 32] Broken pipe
During handling of the above exception, another exception occurred:
╭───────────────────────────────────────────────────────────────────────── Traceback (most recent call last) ─────────────────────────────────────────────────────────────────────────╮│ S:\KI\Vladmandic1111\modules\call_queue.py:61 in f ││ ││ 60 │ │ │ │ pr.enable() ││ ❱ 61 │ │ │ res = list(func(*args, **kwargs)) ││ 62 │ │ │ if shared.cmd_opts.profile: ││ ││ S:\KI\Vladmandic1111\modules\call_queue.py:39 in f ││ ││ 38 │ │ │ try: ││ ❱ 39 │ │ │ │ res = func(*args, **kwargs) ││ 40 │ │ │ finally: ││ ││ ... 4 frames hidden ... ││ ││ S:\KI\Vladmandic1111\venv\lib\site-packages\imageio\plugins\ffmpeg.py:600 in _append_data ││ ││ 599 │ │ │ # Write. Yes, we can send the data in as a numpy array ││ ❱ 600 │ │ │ self._write_gen.send(im) ││ 601 ││ ││ S:\KI\Vladmandic1111\venv\lib\site-packages\imageio_ffmpeg_io.py:637 in write_frames ││ ││ 636 │ │ │ │ ) ││ ❱ 637 │ │ │ │ raise IOError(msg) ││ 638 │╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯OSError: [Errno 32] Broken pipe
FFMPEG COMMAND:
S:\KI\Vladmandic1111\venv\lib\site-packages\imageio_ffmpeg\binaries\ffmpeg-win64-v4.2.2.exe -y -f rawvideo -vcodec rawvideo -s 1195x849 -pix_fmt rgb24 -r 30.00 -i - -an -vcodec
libx264 -pix_fmt yuv420p -v warning S:\KI\Vladmandic1111\infinite-zooms\infinite_zoom_1682034171.mp4
FFMPEG STDERR OUTPUT:
Traceback (most recent call last):
File "S:\KI\Vladmandic1111\venv\lib\site-packages\gradio\blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "S:\KI\Vladmandic1111\venv\lib\site-packages\gradio\routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "S:\KI\Vladmandic1111\venv\lib\site-packages\gradio\blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "S:\KI\Vladmandic1111\venv\lib\site-packages\gradio\blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f
1 - Can we have frame size or aspect ratio? so we can have it 1:1 or 16:9 etc..
2 - Can we open up the duration Total Outpaint Steps over 100? something to be set by user
currently its maxed with 100.
From Vlad1111
ValueError: File cannot be fetched: C:/Users/ME/AppData/Local/Temp/58e814e546d2366335af49716872cea2e9c0407c/infinite_zoom_1682344331.mp4. All files must
contained within the Gradio python app working directory, or be a temp file created by the Gradio python app.
Current element
<video src="http://localhost:7860/file=C:\Users\ME\AppData\Local\Temp\58e814e546d2366335af49716872cea2e9c0407c\infinite_zoom_1682344331.mp4" preload="auto" class="svelte-1vnmhm4" style="opacity: 1; transition: all 0.2s ease 0s; position: relative;"><track kind="captions"><iframe style="display: block; position: absolute; top: 0; left: 0; width: 100%; height: 100%; overflow: hidden; border: 0; opacity: 0; pointer-events: none; z-index: -1;" aria-hidden="true" tabindex="-1" src="about:blank"></iframe></video>
Solution:
a) add the path to video srs
b) use data url (I know firefox has problems reading such)
Is it possible to add a field with settings to overlay a transparent png-file like a watermark? With the ability to adjust the position (centre, top corner, diagonal)? Instead of editing in video editors.
Feature request: allow to control for the seed used.
There is a promising new outpainting method, see this whole thread here: Mikubill/sd-webui-controlnet#1464 (comment)
Maybe it can be incorporated? Works with non-inpainting models and doens't need a prompt.
I see some warrning in the log as showing below:
Infinite Zoom: Corrupted Json structure: {
"prompts":{
...
I try removing the extention and installing again and I still get the same warrning
to avoid rewriting prompts, have a
*save button
Format: dont know, what the gradio table is able to read/write
I can check progress from the command line, but the UI progress bar is not updated. Any chance this can be integrated?
Error completing request1:05, 3.69s/it]
Arguments: ([[0, 'cyberpunk themed world'], ['', ''], ['', '']], 'frames, borderline, text, character, duplicate, error, out of frame, watermark, low quality, ugly, deformed, blur', 8, 7, 50, None, 30, 0, 0, 0, 1, 0, 2, False, 0, 1, 512) {}
Traceback (most recent call last):
File "/Users/xxxx/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/Users/xxxx/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/Users/xxxx/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/scripts/inifnite-zoom.py", line 227, in create_zoom
write_video(
File "/Users/xxxx/stable-diffusion-webui/extensions/infinite-zoom-automatic1111-webui/iz_helpers/video.py", line 35, in write_video
writer.append_data(np_frame)
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio/core/format.py", line 590, in append_data
return self._append_data(im, total_meta)
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio/plugins/ffmpeg.py", line 587, in _append_data
self._initialize()
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio/plugins/ffmpeg.py", line 648, in _initialize
self._write_gen.send(None)
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio_ffmpeg/_io.py", line 509, in write_frames
codec = get_first_available_h264_encoder()
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio_ffmpeg/_io.py", line 125, in get_first_available_h264_encoder
compiled_encoders = get_compiled_h264_encoders()
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio_ffmpeg/_io.py", line 59, in get_compiled_h264_encoders
cmd = [get_ffmpeg_exe(), "-hide_banner", "-encoders"]
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/imageio_ffmpeg/_utils.py", line 33, in get_ffmpeg_exe
raise RuntimeError(
RuntimeError: No ffmpeg exe could be found. Install ffmpeg on your system, or set the IMAGEIO_FFMPEG_EXE environment variable.
Traceback (most recent call last):
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 987, in postprocess_data
if predictions[i] is components._Keywords.FINISHED_ITERATING:
IndexError: tuple index out of range
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/routes.py", line 394, in run_predict
output = await app.get_blocks().process_api(
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 1078, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "/Users/xxxx/stable-diffusion-webui/venv/lib/python3.10/site-packages/gradio/blocks.py", line 991, in postprocess_data
raise ValueError(
ValueError: Number of output components does not match number of values returned from from function f
Describe the bug
Everything I generate using the extension after updating both SD and IZ comes out greyscale. The first generation is in colour but from then onwards they are all black and white for some reason. I've tried prompting against this and using various different options but I can't seem to get this to change.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
I expect it to return colour generations















Screenshots of error
If applicable, add screenshots to help explain your problem. Or just dump the error.
Desktop (please complete the following information):
Additional context
Add any other context about the problem here.
Describe the bug
Make Save and ZIP button working
To Reproduce
create any movie
see you have frames in the gallery shown
click SAVE or ZIP
check console for error from webui-framework, we doe not set information properly needed to store Zip file
Expected behavior
Frame should be saved or zipped as output
Screenshots of error

Desktop (please complete the following information):
Automatic 1111 latest (1.1)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.