Its a solution for 99 place (top 5%) of Jigsaw Rate Severity of Toxic Comments competition.
Main idea: unite 3 datasets in one, then fit some different models in different modes.
- https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/data
- https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data
- https://www.kaggle.com/rajkumarl/ruddit-jigsaw-dataset
- https://www.kaggle.com/c/jigsaw-toxic-severity-rating/data
git clone [email protected]:vilka-lab/JigsawRate.git
cd JigsawRate
You need to download 1-3 datasets in ./JigsawRate/data folder. Download 4 dataset and place validation_data.csv in root of the project. After downloading data folder structure should be like this (without 4 dataset):
📦data
┣ 📂jigsaw-toxic-comment-classification-challenge
┃ ┣ 📜sample_submission.csv.zip
┃ ┣ 📜test.csv.zip
┃ ┣ 📜test_labels.csv.zip
┃ ┗ 📜train.csv.zip
┣ 📂jigsaw-unintended-bias-in-toxicity-classification
┃ ┣ 📜all_data.csv
┃ ┣ 📜identity_individual_annotations.csv
┃ ┣ 📜sample_submission.csv
┃ ┣ 📜test.csv
┃ ┣ 📜test_private_expanded.csv
┃ ┣ 📜test_public_expanded.csv
┃ ┣ 📜toxicity_individual_annotations.csv
┃ ┗ 📜train.csv
┣ 📂ruddit
┃ ┣ 📂Dataset
┃ ┃ ┣ 📜ReadMe.md
┃ ┃ ┣ 📜Ruddit.csv
┃ ┃ ┣ 📜Ruddit_individual_annotations.csv
┃ ┃ ┣ 📜Thread_structure.txt
┃ ┃ ┣ 📜create_dataset_variants.py
┃ ┃ ┣ 📜identityterms_group.txt
┃ ┃ ┣ 📜load_node_dictionary.py
┃ ┃ ┣ 📜node_dictionary.npy
┃ ┃ ┣ 📜post_with_issues.csv
┃ ┃ ┣ 📜ruddit_with_text.csv
┃ ┃ ┗ 📜sample_input_file.csv
┃ ┣ 📂Models
┃ ┃ ┣ 📜BERT.py
┃ ┃ ┣ 📜BiLSTM.py
┃ ┃ ┣ 📜HateBERT.py
┃ ┃ ┣ 📜README.md
┃ ┃ ┣ 📜create_splits.py
┃ ┃ ┗ 📜info.md
┃ ┣ 📜LICENSE
┃ ┣ 📜README.md
┃ ┣ 📜requirements.txt
┃ ┗ 📜ruddit-comment-extraction.ipynb
┣ 📜convert_jigsaw.py
Create environment, for example for anaconda:
conda create --name Jigsaw --no-default-packages
conda activate Jigsaw
pip install -r requirements.txt
You can download model weights from here: https://www.kaggle.com/ivanilyushchenko/jigsawtoxic202199thplace
I used sparse toxicity score fot it and pretrained GroNLP/hateBERT. As a loss function - binary cross entropy. Sparse mean that most of toxicity scores grouped in some ranges. Dataset scores histogramm (without 0 scores, that are majority class):
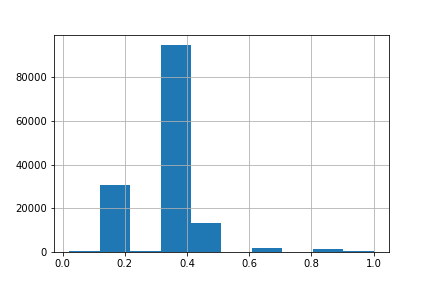
Create dataset. It contains about 2 195 487 samples.
cd data
python convert_jigsaw.py --text_process --preprocess_type=sparse
cd ../
Training:
python train.py --lr=1e-3 \
--freeze \
--weight_decay=1e-3 \
--epochs=3 \
--batch_size=128 \
--num_workers=2 \
--max_length=256 \
--optimizer=Adam \
--model_name=GroNLP/hateBERT \
--objective=bce \
--text_process
After finetuning last layer, we tune all the net. Change optimizer to SGD.
!python train.py \
--lr=1e-5 \
--no-freeze \
--weight_decay=1e-3 \
--epochs=5 \
--batch_size=32 \
--num_workers=2 \
--max_length=256 \
--optimizer=SGD \
--force_lr \
--resume \
--model_name=GroNLP/hateBERT \
--objective=bce \
--text_process
Store model:
mkdir models
mv experiment/last.pth models/hatebert_1.pth
rm -r experiment
I got validation score: 0.6971
Validation scores histogram:

For this model i changed sequence length to 512, loss function to MarginRankingLoss, text preprocess and way of datasets union to dense. Dataset hist:

Recreate dataset.
cd data
python convert_jigsaw.py --no-text_process --preprocess_type=dense
cd ../
Training:
python train.py --lr=1e-3 \
--freeze \
--weight_decay=1e-3 \
--epochs=3 \
--batch_size=128 \
--num_workers=2 \
--max_length=256 \
--optimizer=AdamW \
--model_name=GroNLP/hateBERT \
--objective=margin \
--no-text_process
Unfreeze the Bert.
!python train.py \
--lr=1e-5 \
--no-freeze \
--weight_decay=1e-3 \
--epochs=4 \
--batch_size=16 \
--num_workers=2 \
--max_length=512 \
--optimizer=SGD \
--force_lr \
--resume \
--model_name=GroNLP/hateBERT \
--objective=margin \
--no-text_process
Store model:
mv experiment/last.pth models/hatebert_2.pth
rm -r experiment
I got validation score: 0.6910
Validation scores histogram:

Here i changed model to cardiffnlp/twitter-roberta-base-hate. Preprocess text with dense scores.
Recreate dataset.
cd data
python convert_jigsaw.py --text_process --preprocess_type=dense
cd ../
Training:
python train.py --lr=1e-3 \
--freeze \
--weight_decay=1e-3 \
--epochs=3 \
--batch_size=256 \
--num_workers=2 \
--max_length=128 \
--optimizer=Adam \
--model_name=cardiffnlp/twitter-roberta-base-hate \
--objective=margin \
--text_process
Unfreeze the Bert.
!python train.py \
--lr=1e-5 \
--no-freeze \
--weight_decay=1e-3 \
--epochs=5 \
--batch_size=64 \
--num_workers=2 \
--max_length=256 \
--optimizer=SGD \
--force_lr \
--resume \
--model_name=cardiffnlp/twitter-roberta-base-hate \
--objective=margin \
--text_process
Store model:
mv experiment/last.pth models/roberta_1.pth
rm -r experiment
I got validation score: 0.6897
Validation scores histogram:

After ensembling this models (scale scores to [0; 1] range and just sum) i got 0.6988 score on validation. Scores:

It give me 0.79784 private score (was my first submission, 157 place and bronze zone)
For the second submission i ensebmle models with other open solutions same way without weights. But this two solutions are ensembles themselfs.
- https://www.kaggle.com/yuzhoudiyishuai/robertabase5fold2-linear-256
- https://www.kaggle.com/saurabhbagchi/pytorch-w-b-jigsaw-starter
So the weights: model_1, model_2, model_3, 1st ensemble, 2nd ensemble - each for 20% contributions in final result.
Validation score of 5 models: 0.7190. It was my second submission, 0.80153 on private and 99th place.
from model import JigsawModel
from pathlib import Path
from transformers import AutoTokenizer
from data.convert_jigsaw import process_text
from tqdm import tqdm
import pandas as pd
tqdm.pandas()
from dataset import get_loaderdef load_model(model_weight: Path, model_name: str) -> JigsawModel:
model = JigsawModel(model_name=model_name)
model.load_model(model_weight, load_train_info=False)
return model
def load_tokenizer(length: int, model_name: str) -> AutoTokenizer:
tokenizer = AutoTokenizer.from_pretrained(model_name, model_max_length=length)
return tokenizer
def get_val_loaders(test_df: pd.DataFrame, full_process: bool, batch_size: int, tokenizer: AutoTokenizer) -> list:
# full process mean --text_process on the training script
val_loaders = [
get_loader(test_df['less_toxic'].progress_apply(process_text, full_process=full_process), tokenizer, num_workers=2,
batch_size=batch_size),
get_loader(test_df['more_toxic'].progress_apply(process_text, full_process=full_process), tokenizer, num_workers=2,
batch_size=batch_size)
]
return val_loadersmodel_name = 'GroNLP/hateBERT'
model = load_model(model_weight=Path('models').joinpath('hatebert_1.pth'), model_name=model_name)
tokenizer = load_tokenizer(length=256, model_name=model_name)
test_df = pd.read_csv('validation_data.csv')
val_loaders = get_val_loaders(test_df, full_process=True, batch_size=64, tokenizer=tokenizer)
less_toxic = model.predict(val_loaders[0])
more_toxic = model.predict(val_loaders[1])For the final inference of single model:
df = pd.read_csv(competition_path.joinpath('comments_to_score.csv'))
loader = get_loader(df['text'].progress_apply(process_text, full_process=True), tokenizer, num_workers=2, batch_size=64)
df['score'] = model.predict(loader).flatten()