Ro is a command line assistant, meaning a monolithic combination of personal CLI tools into a single application.
Ro can be broken into tools, which provide cli functionality, and characters, which expose common functionality to Ro and the tools.
The tools are contained in the aptly named "tools" directory, and implement functionality that can be used through the command line interface.
gcp is a tool for quick operations on the Google Cloud Platform.
The cluster command sends a request to create a Dataproc cluster with some useful configurations.
Command usage follows the pattern:
ro gcp cluster [-name <clusterName>] -project <projetId> -bucket <bucketName> -cred <credentialPath> -w <numWorkers> -c <numCores> [--highmem]
The parameters have the following effects:
n,name: The name of the cluster. Defaults to "ro-cluster" if not given.b,bucket: The name of the bucket for cluster setup and Jupyter notebook files.r,cred: Path to the JSON credentials file.w,workers: The number of workers.c,cores: The number of cores per worker.h,highMem: Flag indicating if cores should have higher memory than default.
This command attempts to compute appropriate master node configuration depending on the number of workers, and also provides better default settings for spark configurations than Dataproc's. It also enables HTTP port access and Jupyter notebooks by default.
The upload command uploads either a file or directory (recursively) to a Google Cloud Storage bucket.
Command usage follows the pattern:
ro gcp upload <srcPath> <dstPath> -bucket <bucketName> -cred <credentialPath>
The parameters have the following effects:
srcPath: Path of the source file or directory to be uploaded.dstPath: Relative path of the destination file/directory relative to the bucket root.bucket: Name of the target bucket.cred: Path to the JSON credential file.
blogo is the tool used to compile my blog's source files into the appropriate structure.
It expects both a source directory and a target directory, either passed as
ro blogo <srcDir> <dstDir> or allowing for the invocation ro blogo with blogo fetching these parameters from the environment variables BLOGO_SOURCE_DIRECTORY and
BLOGO_TARGET_DIRECTORY.
The source directory is expected to have five items:
posts- A directory containing the blog posts.static- A directory containing posts that will be deployed as static pages.templates- A directory with HTML templates, managed by thepagessubmodule.resources- A directory with various resources that are recursively copied into the website's root.config.json- A JSON file containing blog configuration.
A --local flag can be appended to generate locally linked pages for testing.
Posts are written in Markdown, with the first five lines being prefixed by an exclamation mark and having the following meanings:
- Title.
- Date string: e.g.
February 1st, 2019. - Post tags with css colors: e.g.
old:lightcoral dev:burlywood. - Preview: a paragraph in Markdown describing the post's contents, used when indexing the posts.
- Flags: space separated flags that have special behavior.
Regular posts are indexed in a /posts.html page and the most recent posts are indexed in the home page.
These posts are stored in a /posts/ directory. Static posts are not indexed and are stored directly on
the root directory, for example, /about.html. As a result, static pages have the third and fourth lines
empty as they do not apply.
The configuration holds four different settings:
title: The blog title, to be embedded in the head section.base_url: The blog's base URL.image_dir: The name of the resources subdirectory where post images are included.num_home_posts: How many of the most recent posts are indexed in the home page.
Ro has direct submodules, named after fictional characters, that handle a lot of basic functionality, and are used both by Ro and by the included tools, meaning that tools share common functionality through them.
Donna handles command line arguments.
It separates command line arguments into two different types: parameters and regular arguments.
Parameters are arguments passed with dash prefix (commonly single or double): these can either be flags, where their presence/absence indicates their value, or options, which have an associated value. Args are regular names which indicate ro's execution path.
Options and flags can either be global, relating to Ro's own operations, or command specific. Global flags/options precede the Args and command flags/options come after all Args. To illustrate, this is Ro's invocation map:
ro [global Parameters] <Args> [command Parameters]
Flags and options are validated, meaning invalid flags/options will cause Donna to return an error.
Note that developer errors, such as attempting to fetch an unregistered flag, will result in a panic to
facilitate debugging during development. Each tool must specify which options and flags they expect to
receive through Donna's func ExpectFlag(alias, name, desc string), func ExpectStrOption(alias, name, desc, defaultValuestring)
and func ExpectIntOption(alias, name, desc string, defaultValue int). The tool's entry point must call Donna's
func Parse() after setting out its expectations for command parameter parsing and validation.
Besides, Donna also provides an automatic --help display, and stating expected arguments through
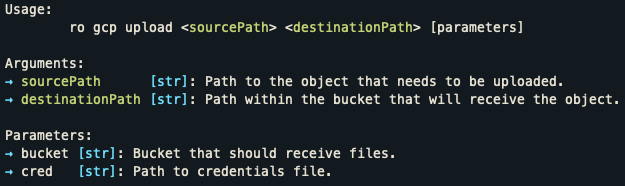
func ExpectArg(name, desc string) can help building a more informative output. An example of the help
command output is shown below for the upload command of the gcp tool.
Presence of flags can be checked with Donna's func HasFlag(string) bool and options values can be checked
with Donna's func GetStrOption(name string) (string, bool) and func GetIntOption(name string) (string, bool)
where the second value indicates whether the option was passed and the first value is its associated value,
the one passed or the default one.
Args are consumed as tokens, one by one, by invoking Donna's func NextArg() (string, bool), where the second
value indicates whether there are still arguments to be consumed, and the first value is the consumed argument in
case it was available.
Weems provides a Logger type from which basic, thread-safe and informative logging operations are exposed.
Weems has five different logging levels, in increasing order of importance: TRACE, INFO, WARN, ERROR, and FATAL.
These levels affect three different things:
- Whether the logged message is shown or not, based on the Logger's own setting. I.e., one can set up the logger to only shown messages of certain importance or above.
- The output itself, which will make the log level of the message explicit.
- Control flow, as FATAL logs will result in the program exiting after logging the message, with a return code of 1.
Besides the level setting used to filter out unimportant messages, a Logger also have an associated io.Writer
indicating where messages should be logged and a name. The default io.Writer is os.Stderr.
The output format o Weems' Loggers use ANSI color escape codes for ease of reading, and have the following, fixed,
format H:M:S LEVEL NAME FILENAME:LINE_NUMBER MESSAGE. The filename and line number are fetched at runtime through
Go's own runtime standard library module.
Logging operations are thread-safe, sharing a global mutex. Meaning that two different Loggers can safely share the
same io.Writer.
The default io.Writer and logging levels for Loggers which have their default values can be changed at runtime
through the func SetGlobalLevel(int) and the func SetGlobalWriter(io.Writer) functions.
Bran remembers things for Ro.
Any given source file can have a permanent cache with value accessed by bran.Get(key string) string and
bran.Set(key, value string).Runtime information is used to determine the caller of the Get and Set
functions, meaning keys are kept in a namespace for each source file.
The permanent memory is implemented by requesting Nemec to save a JSON
for each namespace within a folder named cache. A simple hash is used instead of the actual path of caller.
Go's standard library includes various functions spread across multiple files that enables one to perform various file system operations. Some operations however, such as reading a file as a slice of strings, or recursively copying one directory into a new path, are not implemented by default.
Linus exposes these quality of life file system functionalities.
Nemec abstracts away managing and creating files internal to Ro.
