你好~ 我是 leon ,生活在广州,是三七互娱集团架构组的一名资深前端工程师。
曾就职于荔枝、凡科、网金,做过前端、后端,是一名全栈技术的实践者。
如果你想聊聊【前端】,可以给我发邮件,也可以直接加我QQ:582104384。
王先生的基地
Home Page: https://wangxiaokai.vip
License: Other
你好~ 我是 leon ,生活在广州,是三七互娱集团架构组的一名资深前端工程师。
曾就职于荔枝、凡科、网金,做过前端、后端,是一名全栈技术的实践者。
如果你想聊聊【前端】,可以给我发邮件,也可以直接加我QQ:582104384。































外部未知的域名持有者,将域名解析到非其所持有的服务器公网IP上,间接或直接造成损害他人利益的行为。
域名的恶意解析,可以用于借刀杀人。
这个手法很*,轻则可以将对手的SEO排名拉低,重则可以让工信部封杀其站点。
具体实现条件如下:
危害如下:
将无效域名的HTTP请求,全部拒绝响应
以下是我的个人站点的nginx配置
server{
listen 80 default_server;
server_name _;
access_log off;
return 444;
}
server{
listen 443 default_server;
server_name _;
ssl_certificate cert/www.wangxiaokai.vip.pem;
ssl_certificate_key cert/www.wangxiaokai.vip.key;
access_log off;
return 444;
}
server_name _;
这个代表的就是无效域名,_符号可以用-或!@#代替,都可以达到相同的效果。
access_log off;
访问日志是需要存储空间的,如果没有设置自动清理脚本,也是可以把服务器存储空间打爆的。
return 444;
444是Nginx服务器扩展的HTTP错误状态码,为非标准HTTP状态码。
它的作用是:服务器不向客户端返回任何信息,并关闭连接, 断开客户端和服务器的连接,防止恶意软件攻击威胁。
这两个server模块,应该放在最前,优先处理。
本文讲述JavaScript中类继承的实现方式,并比较实现方式的差异。
继承,是子类继承父类的特征和行为,使得子类对象具有父类的实例域和方法。
继承是面向对象编程中,不可或缺的一部分。
减少代码冗余 父类可以为子类提供通用的属性,而不必因为增加功能,而逐个修改子类的属性代码复用 同上代码易于管理和扩展 子类在父类基础上,可以实现自己的独特功能耦合度高 如果修改父类代码,将影响所有继承于它的子类影响性能 子类继承于父类的数据成员,有些是没有使用价值的。但是,在实例化的时候,已经分配了内存。所以,在一定程度上影响程序性能。例子以图书馆中的书入库归类为例。
以下是简化后的父类Book(也可称为基类)。
目的是通过继承该父类,产出Computer(计算机)子类。
并且,子类拥有新方法say,输出自己的书名。
function Book(){
this.name = ''; // 书名
this.page = 0; // 页数
this.classify = ''; // 类型
}
Book.prototype = {
constructor: Book,
init: function(option){
this.name = option.name || '';
this.page = option.page || 0;
this.classify = option.classify || '';
},
getName: function(){
console.log(this.name);
},
getPage: function(){
console.log(this.page);
},
getClassify: function(){
console.log(this.classify);
}
};接下来会讲解子类Computer几种继承方式的实现和优化方法。开始飙车~
function Computer(){
Book.apply(this, arguments);
}
Computer.prototype = new Book();
Computer.prototype.constructor = Computer;
Computer.prototype.init = function(option){
option.classify = 'computer';
Book.prototype.init.call(this, option);
};
Computer.prototype.say = function(){
console.log('I\'m '+ this.name);
}function Computer(){
Book.apply(this, arguments);
}Computer的构造函数里,调用父类的构造函数进行初始化操作。使子类拥有父类一样的初始化属性。
Computer.prototype = new Book();使用new操作符对父类Book进行实例化,并将实例对象赋值给子类的prototype。
这样,子类Computer就可以通过原型链访问到父类的属性。
Book的构造函数被执行了2次
Computer的构造函数里Book.apply(this, arguments);Computer.prototype = new Book();Computer.prototype = new Book();,这种实例化方式,无法让Book父类接收不固定的参数集合。function Computer(){
Book.apply(this, arguments);
}
Computer.prototype = Object.create(Book.prototype);
Computer.prototype.constructor = Computer;
Computer.prototype.init = function(option){
option.classify = 'computer';
Book.prototype.init(option);
};
Computer.prototype.say = function(){
console.log('I\'m '+ this.name);
}这里的改进:是使用Object.create(Book.prototype)。它的作用是返回一个继承自原型对象Book.prototype的新对象。且该对象下的属性已经初始化。
用Object.create生成新对象,并不会调用到Book的构造函数。
这种方式,也可以通过原型链实现继承。
由于低版本的浏览器是不支持Object.create的。所以这里简单介绍下兼容版本:
Object.create = function(prototype){
function F(){}
F.prototype = prototype;
return new F();
}原理是定义一个空的构造函数,然后修改其原型,使之成为一个跳板,可以将原型链传递到真正的prototype。
上述两种实现方式,都存在一个问题:不存在私有属性和私有方法。也就是说,存在被篡改的风险。
接下来就用函数化来化解这个问题。
function book(spec, my){
var that = {};
// 私有变量
spec.name = spec.name || ''; // 书名
spec.page = spec.page || 0; // 页数
spec.classify = spec.classify || ''; // 类型
var getName = function(){
console.log(spec.name);
};
var getPage = function(){
console.log(spec.page);
};
var getClassify = function(){
console.log(spec.classify);
};
that.getName = getName;
that.getPage = getPage;
that.getClassify = getClassify;
return that;
}
function computer(spec, my){
spec = spec || {};
spec.classify = 'computer';
var that = book(spec, my);
var say = function(){
console.log('I\'m '+ spec.name);
};
that.say = say;
return that;
}
var Ninja = computer({name: 'JavaScript忍者秘籍', page: 350});函数化的优势,就是可以更好地进行封装和信息隐藏。
也许有人疑惑为什么用以下这种方式声明和暴露方法:
var say = function(){
console.log('I\'m '+ spec.name);
};
that.say = say;其实是为了保护对象自身的完整性。即使that.say被外部篡改或破坏掉,function computer内部的say方法仍然能够正常工作。
另外,解释下that、spec和my的作用:
that是一个公开数据存储容器,暴露出去的数据接口,都放到这个容器spec是用来存储创建新实例所需的信息,属于实例之间共同编辑的数据my是用来存储父类、子类之间共享的私密数据容器,外部是访问不到的。最后,看下现代版ES6的类继承。不禁感慨以前的刀耕火种,是多么折磨人🌚
class Book {
constructor(){
this.name = ''; // 书名
this.page = 0; // 页数
this.classify = ''; // 类型
}
init(option) {
this.name = option.name || '';
this.page = option.page || 0;
this.classify = option.classify || '';
}
getName() {
console.log(this.name);
}
getPage (){
console.log(this.page);
}
getClassify (){
console.log(this.classify);
}
}
class Computer extends Book{
constructor(...args){
super(...args);
}
init(option) {
super.init(option);
this.classify = 'computer';
}
say() {
console.log('I\'m '+ this.name);
}
}虽然ES5终究会被淘汰,但是了解下其工作原理,还是很有必要。因为很多源码还是有用到里面的模式。
附带的价值就是,ES5的继承玩到飞起,ES6的继承就是小菜一碟。
虽然现在已经是ES6的时代,但是,还是有必要了解下ES5是怎么写一个类的。
本文详述JavaScript面向对象编程中的类写法,并分步骤讲述如何写出优雅的类。
例子为一个轻提示组件Toast。
需要实现的功能:
on方法,显示提示off方法,隐藏提示init方法,初始化提示语function Toast(option){
this.prompt = '';
this.elem = null;
this.init(option);
}
Toast.prototype = {
// 构造器
constructor: Toast,
// 初始化方法
init: function(option){
this.prompt = option.prompt || '';
this.render();
this.bindEvent();
},
// 显示
show: function(){
this.changeStyle(this.elem, 'display', 'block');
},
// 隐藏
hide: function(){
this.changeStyle(this.elem, 'display', 'none');
},
// 画出dom
render: function(){
var html = '';
this.elem = document.createElement('div');
this.changeStyle(this.elem, 'display', 'none');
html += '<a class="J-close" href="javascript:;">x</a>'
html += '<p>'+ this.prompt +'</p>';
this.elem.innerHTML = html;
return document.body.appendChild(this.elem);
},
// 绑定事件
bindEvent: function(){
var self = this;
this.addEvent(this.elem, 'click', function(e){
if(e.target.className.indexOf('J-close') != -1){
console.log('close Toast!');
self.hide();
}
});
},
// 添加事件方法
addEvent: function(node, name, fn){
var self = this;
node.addEventListener(name, function(){
fn.apply(self, Array.prototype.slice.call(arguments));
}, false);
},
// 改变样式
changeStyle: function(node, key, value){
node.style[key] = value;
}
};
var T = new Toast({prompt:'I\'m Toast!'});
T.show();JavaScript的类,是用函数对象来实现。
类的实例化形式如下:
var T = new Toast();其中的重点,就是Function的编写。
类分为两部分:constructor+prototype。也即构造器+原型。
构造器从直观上来理解,就是写在函数内部的代码。
从Toast例子上看,构造器就是以下部分:
function Toast(option){
this.prompt = '';
this.elem = null;
this.init(option);
}这里的this,指向的是实例化的类。
每次通过new Toast()的方式进行实例化,构造器都会执行一遍。
原型上的方法和变量的声明,都是通过Toast.prototype.*的方式。
那么在原型上普通的写法如下:
Toast.prototype.hide = function(){/*code*/}
Toast.prototype.myValue = 1;但是,该写法不好的地方:就是每次都要写前半部分Toast.prorotype,略显累赘。
在代码压缩优化方面也不友好,无法做到最佳的压缩。
改进的方式如下:
Toast.prorotype = {
constructor: Toast,
hide: function(){/*code*/},
myValue: 1
}这里的优化,是把原型指向一个新的空对象{}。
带来的好处,就是可以用{key:value}的方式写原型上的方法和变量。
但是,这种方式会改变原型上构造器prototype.constructor的指向。
如果不重新显式声明constructor的指向,Toast.constructor.prototype.constructor的会隐式被指向Object。而正确的指向,应该是Toast。
虽然通过new实例化没有出现异常,但是在类继承方面,constructor的指向异常,会产生不正确的继承判断结果。这是我们不希望看到的。
所以,需要修正constructor。
原型上的方法和变量,是该类所有实例化对象共享的。也就是说,只有一份。
而构造器内的代码块,则是每个实例化对象单独占有。不管是否用this.**方式,还是私有变量的方式,都是独占的。
所以,在写一个类的时候,需要考虑该新增属性是共享的,还是独占的。以此,决定在构造器还是原型上进行声明。
类的实例化,一个强制要求的行为,就是需要使用new操作符。如果不使用new操作符,那么构造器内的this指向,将不是当前的实例化对象。
优化的方式,就是使用instanceof做一层防护。
function Toast(option){
if(!(this instanceof Toast)){
return new Toast(option);
}
this.prompt = '';
this.elem = null;
this.init(option);
}从上述代码可以看出,使用这个技巧,可以防止团队一些大头虾出现使用错误实例化方式,导致代码污染的问题。
这种忍者技巧很酷,但从另一方面考虑,还是希望使用者可以用正确的方式去�实例化类�。
所以,改成以下这种防护方式
function Toast(option){
if(!(this instanceof Toast)){
throw new Error('Toast instantiation error');
}
this.prompt = '';
this.elem = null;
this.init(option);
}这样,把锅甩回去,岂不是更妙👽
shell 是个好东西,建议学习下:)
本文将讲解如何用shell开发自动化脚本刷新CDN缓存。
为什么会做这个小脚本,根本原因还是懒...
公司的运维,很贴心开发了一个form表单的网页,专门给前端同学刷新CDN缓存。虽然可以满足要求,但是每次上一次项目,就得打开该网页,输入SecretKey和需要刷新的URL地址,很心累。
有痛点,那么就尝试解决它!
#!bin/bash
# 刷新cdn
urls="https://***.com/page1;\
https://***.com/page2;"
curl \
-X POST \
--data-urlencode "qq=00" \
--data-urlencode "ws=01" \
--data-urlencode "SecretKey=***" \
--data-urlencode "flushurl=${urls}" \
http://127.0.0.1/凡是在客户端可以跑的命令,都可以用shell集成,做自动化。
curl是一种命令行工具,作用是发出网络请求,然后得到和提取数据,显示在"标准输出"(stdout)上面。
主要了解两种方式:get和post。
curl example.com/a.html?data=xxxcurl -X POST --data "data=xxx" example.com/form.cgicurl -X POST--data-urlencode "date=April" example.com/form.cgi#!bin/bash
curl -X POST --data-urlencode "qq=00" --data-urlencode "ws=01" --data-urlencode "SecretKey=***" --data-urlencode "flushurl=https://***.com/page1;https://***.com/page2;" http://127.0.0.1/要实现的目的基本达到,但是代码不友好,修改不方便。
#!bin/bash
urls="https://***.com/page1;\
https://***.com/page2;"
curl \
-X POST \
--data-urlencode "qq=00" \
--data-urlencode "ws=01" \
--data-urlencode "SecretKey=***" \
--data-urlencode "flushurl=${urls}" \
http://127.0.0.1/Git Bash工具跑shell命令例子:bash cdn.sh
有前端同事,用commander+axios做了一个刷新CDN工具,但是,没我这个来得简单粗爆:)
shell就是这么好用~
robots.txt 文件由一条或多条规则组成。每条规则可禁止(或允许)特定抓取工具抓取相应网站中的指定文件路径。
通俗一点的说法就是:告诉爬虫,我这个网站,你哪些能�看,哪些不能看的一个协议。
搜索引擎(爬虫),访问一个网站,首先要查看当前网站根目录下的robots.txt,然后依据里面的规则,进行网站页面的爬取。
也就是说,robots.txt起到一个基调的作用,也可以说是爬虫爬取当前网站的一个行为准则。
那使用robots.txt的目的,就很明确了。
栗子如下:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.wangxiaokai.vip/sitemap.xml
解析:
名为“Googlebot”抓取工具的用户代理不应抓取 http://wangxiaokai.vip/nogooglebot/ 文件夹或任何子目录。
所有其他用户代理均可访问整个网站。(不指定这条规则也无妨,结果是一样的,因为完全访问权限是系统默认的前提。)
网站的站点地图文件位于 http://www.wangxiaokai.vip/sitemap.xml
必须位于它所应用到的网站主机的根目录下
网页抓取工具的名称不应抓取的目录或网页应抓取的目录或网页网站的站点地图的位置百度网盘的资源,到博文��编写时间为止,已经不能用常用的搜索技巧site:pan.baidu.com 搜索关键字的方式,在baidu.com|google.com|biying.com(国际版还可以勉强搜索到)去搜索对应的资源。
禁止的方式,很大程度上是依靠robots.txt,而不是请去喝茶😆。
以下是访问 http://pan.baidu.com/robots.txt 得到的规则:
可以看到,百度网盘封杀了所有资源文件入口。
最狠的是最后一句:
User-agent: *
Disallow: /
我只想说有资源真的可以为所欲为😂
为什么要做Cookie防篡改,一个重要原因是 Cookie中存储有判断当前登陆用户会话信息(Session)的会话票据-SessionID和一些用户信息。
当发起一个HTTP请求,HTTP请求头会带上Cookie,Cookie里面就包含有SessionID。
后端服务根据SessionID,去获取当前的会话信息。如果会话信息存在,则代表该请求的用户已经登陆。
服务器根据登陆用户的权限,返回请求的数据到浏览器端。
因为Cookie是存储在客户端,用户可以随意修改。所以,存在一定的安全隐患。
wall在浏览器端输入用户名密码,发起POST请求到后端服务器。后端服务器验证合法,返回Response,并Set-Cookie为sessionid=***;username=wall;。Set-Cookie,将其存入本地内存或硬盘中。sessionid=***;username=wall;,请求修改自己的头像信息。sessionid验证当前用户已登陆,根据username,查找数据库中的对应数据,修改头像信息。如果当前用户知道username的作用,修改username=pony。再次发起请求,则服务器接收到请求后,会去修改username为pony的数据。
这样,就暴露出数据被恶意篡改的风险。
服务器为每个Cookie项生成签名。如果用户篡改Cookie,则与签名无法对应上。以此,来判断数据是否被篡改。
原理如下:
secretsecret(wall)=34Yult8iusername=wall|34Yult8i。其中,内容和签名用|隔开。举个栗子:
比如服务器接收到请求中的Cookie项username=pony|34Yult8i,然后使用签名生成算法secret(pony)=666。
算法得到的签名666和请求中数据的签名不一致,则证明数据被篡改。
鉴于Cookie的安全性隐患,敏感数据都应避免存储在Cookie。
应该根据SessionID,将敏感数据存储在后端。取数据时,根据SessionID去后端服务器获取即可。
另外,对一些重要的Cookie项,应该生成对应的签名,来防止被恶意篡改。
尤达表达式是计算机编程中的一种风格,其中表达式的两个部分与条件语句中的典型顺序相反。
这种风格的命名,来源于星球大战的一个角色,绝地大师尤达(Yoda)。剧中,该角色喜欢以颠倒的语序说英语。比如“当九百岁你活到,看起来很好你将不”。
下面举个栗子:
// 正常的写法
if(number == 7){/* code */}
// 尤达表达式
if(7 == number){/* code */}特点就是:将表达式的常量部分放在条件语句的左侧。

评判一个东西的好坏,通常都需要比较。那就先看看尤达表达式有什么优缺点
例如以下判断,由于判断相等少写了一个=号,导致程序运行中发生意外的赋值操作
if (number = 7) { /* code */ }而使用尤达表达式,则可以在编译时捕捉到这个错误
if (7 = number) { /* code */ } // Uncaught ReferenceError: Invalid left-hand side in assignment例如Java中的equals比较
String myString = null;
if (myString.equals("hehe")) { /* code */ } // This causes a NullPointerException in Java尤达表达式的方式可以避开
String myString = null;
if ("hehe".equals(myString)) { /* code */ } 与常规的编程直线思维相悖,造成代码阅读和理解上的不顺畅,缺乏可读性。
尤达表达式的优点,其实可以通过其他方式去避免所犯的错误。例如第一个条件语句写成赋值语句,可以由代码检查工具检测出来。反而是可读性的缺陷,影响多人写作开发和维护。所以,要避免使用尤达表达式。
书写条件语句时,避免常量在前,变量在后去进行比较。应该按变量在前,常量在后的方式去书写。
本文讲述css-loader开启css模块功能之后,如何与引用的npm包中样式文件不产生冲突。
比如antd-mobilenpm包的引入。在不做特殊处理的前提下,样式文件将会被转译成css module。
{
test: /\.css$/,
use: [
'style-loader',
{
loader: 'css-loader',
options: {
modules: true,
localIdentName: '[hash:base64:6]'
}
},
'postcss-loader'
]
}以上代码片段,摘自webpack配置的module.rule。
可以看出wepack在编译过程中,遇到.css结尾的文件,都会交由postcss-loader、css-loader和style-loader依次处理。
因为css-loader开启了css模块功能,所以,所有经过处理的css文件,类名都将被改变。
使用
exclude和include进行区分
node_module文件夹内的文件,避免被当前rule处理{
test: /\.css$/,
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader',
options: {
modules: true,
localIdentName: '[hash:base64:6]'
}
},
{
loader: 'postcss-loader'
}
],
exclude:[path.resolve(__dirname, '..', 'node_modules')]
}如上所示,将node_module文件夹内的文件,用exclude排除在外,不用当前rule进行处理。
node_module内的css文件{
test: /\.css$/,
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader'
},
{
loader: 'postcss-loader'
}
],
include:[path.resolve(__dirname, '..', 'node_modules')]
}css module模式和普通模式混用普通模式css module模式这里统一用 global 关键词进行识别。
// css module
{
test: new RegExp(`^(?!.*\\.global).*\\.css`),
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader',
options: {
modules: true,
localIdentName: '[hash:base64:6]'
}
},
{
loader: 'postcss-loader'
}
],
exclude:[path.resolve(__dirname, '..', 'node_modules')]
}
// 普通模式
{
test: new RegExp(`^(.*\\.global).*\\.css`),
use: [
{
loader: 'style-loader'
},
{
loader: 'css-loader',
},
{
loader: 'postcss-loader'
}
],
exclude:[path.resolve(__dirname, '..', 'node_modules')]
}less在使用css module时,对url的解析存在冲突,可以用resolve-url-loader进行解决,直接上代码:
test: /\.less/,
use: [
{
loader: "style-loader"
},
{
loader: "css-loader",
options: {
sourceMap: true,
importLoaders: 2
}
},
{
loader: "postcss-loader",
options: {
sourceMap: true
}
},
{
loader: "resolve-url-loader",
options: {
sourceMap: true
}
},
{
loader: "less-loader",
options: {
sourceMap: true
}
}
]ping-url是我最近开源的一个小工具,这篇文章也是专门写它设计理念的科普文。
为什么会做这个ping-url开源工具呢?
起因是:本小哥在某天接到一个特殊的需求,要用前端的方式判断任意一个url,是否可以正常访问。
这么简短的需求,通常背后都有个大坑:alien:
先捊下思路,要实现这个功能,必须具备以下2点:
有了思路,就开始撸起袖子加油干!
由于浏览器的安全机制——同源策略的存在,要实现任意这个要求确实有点难。
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
所以,为了实现任意url可以正常访问,第一个要解决的问题就是:跨域。
前端老鸟很快就会联想到JSONP。其原理其实是利用script可跨源访问的特性。
依据这个,可以做个拓展,找出所有可跨源访问的html标签:
<script><img><link><video><audio><audio><iframe>从可跨源访问的html标签中,筛选出能支持onerror和onload事件标签,则可以依靠标签很好地完成功能的开发。
这里说明下:
onerror事件的作用
如果跨源标签请求的资源,和本身能解析的文件格式不一样,就会报error事件。
而要检测的url,通常都是html。
所以onerror事件可以用于监听发起请求,到接收到反馈error所花费的时间。这样,就可以直接算出网络访问的延时。
但是,很遗憾,准确率并不是100%。
因为有一种情况是:url本身就是死链。
用死链发起http请求后,会得到failed的状态。这种情况下onerror也是会触发的。
为什么需要onload事件?
onload事件的触发时机是资源已下载完成。
只要触发这个事件,则证明url不是死链。
这样,就可以帮onerror排除意外情况,让准确率达到100%!
基于以上两点硬性要求,对标签进行过滤后如下:
<script><img><link>其中<iframe>的硬伤是:只要服务器设置X-Frame-Options消息头,就直接废了。所以也被排除掉。
X-Frame-Options是一个HTTP标头(header),用来告诉浏览器这个网页是否可以放在iFrame内。
<script>虽然可以满足需求,但是有一个很致命的问题:存在被XSS攻击的可能。
如果url对应的资源是可自执行的js函数,则完全有可能被利用干坏事。
<img>标签因为只能触发onerror,所以也被排除。
最后只有<link>标签可以使用。
由于解析方式是CSS,所以不存在攻击的可能性。
以下是实现代码:
function getStatus(url: string){
return new Promise((resolve, reject) => {
let link = document.createElement('link');
link.rel="stylesheet";
link.type="text/css"
link.href = url;
link.onload = function(){
resolve(true);
}
link.onerror = function(){
resolve(false);
}
document.body.appendChild(link);
})
}<link>节点,并加入资源地址urlonload、onerrorbody中,发起请求需要注意的是,一定要声明rel和type,否则是触发不了绑定的事件的。
由于CSS的跨域需要一个设置正确的Content-Type 消息头,所以还是存在很小概率的风险。
因此,计算网络延时这块,ping-url还是用最保守的<img>。
function getLoadTime(url: string){
return new Promise(resolve => {
let img = document.createElement('img');
img.style.display = "none";
img.src=`${url}/?v=${Math.random()}`;
const timeStart = new Date();
img.onerror = function(){
const timeEnd = new Date();
resolve(timeEnd.getTime() - timeStart.getTime());
}
img.onload = function(){
const timeEnd = new Date();
resolve(timeEnd.getTime() - timeStart.getTime());
}
document.body.appendChild(img);
});
}<img>节点,加入资源请求url,并将样式设置为display:none,避免对页面产生影响timeStartonerror、onloadbody中,发起请求这里有个小细节,url后要加上随机数v=***。这样可以避免缓存的情况。
虽然这只是个小项目,但是挺实用的。所以利用空闲时间,将其封装成npm包,发布到npmjs.com上。
源码也同步到GitHub上,可以点击访问ping-url。
如果对你有帮助的话,可以打赏个Star:star2:。
有个小遗憾:ping-url的测试覆盖率达不到100%,原因是:
async、await__awaiter、__generator方法,测试用例无法覆盖所有路径有类似经验的码友,帮忙看下怎么解决,不盛感激!
[1] 华佗诊断分析系统
[2] 详解script标签
[3] 不要再问我跨域的问题了
[4] <link>:外部资源链接元素
[5] 跨源网络访问
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
基于堆栈的特性,可以用数组做线性表进行存储。
初始化Stack类的结构如下:
function Stack(){
this.space = [];
}
Stack.prototype = {
constructor: Stack,
/* 接口code */
};接下来,就是在原型上,对入栈、出栈、清空栈、读取栈顶、读取整个栈数据这几个接口的实现。
Stack类默认以数组头部做栈底,尾部做栈顶。
push入栈可以利用js数组的push方法,在数组尾部压入数据。
Stack.prototype = {
push: function(value){
return this.space.push(value);
}
}pop出栈同样是利用js数组的pop方法,在数组尾部推出数据。
Stack.prototype = {
pop: function(){
return this.space.pop();
}
}clear清空栈相对简单,将存储数据的数组重置为空数组即可。
Stack.prototype = {
clear: function(){
this.space = [];
}
}readTop读取栈顶数据,采用数组下标的方式进行获取。带来的一个好处就是:下标超出数组有效范围时,返回值为undefined。
Stack.prototype = {
readTop: function(){
return this.space[this.space.length - 1];
}
}read读取整个栈数据,直接返回当前数组即可。
Stack.prototype = {
read: function(){
return this.space;
}
}最后,将所有功能聚合后,如下所示,一个堆栈的数据结构就搞定了。
function Stack(){
this.space = [];
}
Stack.prototype = {
constructor: Stack,
push: function(value){
return this.space.push(value);
},
pop: function(){
return this.space.pop();
},
clear: function(){
this.space = [];
},
readTop: function(){
return this.space[this.space.length - 1];
},
read: function(){
return this.space;
}
};学数据结构和算法是为了更好、更高效率地解决工程问题。
这里学以致用,提供了几个真实的案例,来体会下数据结构和算法的魅力:)
reverse的实现当前案例,将用堆栈来实现数组的反转功能。
function reverse(arr){
var ArrStack = new Stack();
for(var i = arr.length - 1; i >= 0; i--){
ArrStack.push(arr[i]);
}
return ArrStack.read();
}如代码所示,可分为以下几个步骤:
read接口,输出数据好像很简单,不用担心,复杂的在后面:)
数值转换进制的问题,是堆栈的小试牛刀。
讲解转换方法前,先来看一个小例子:
将十进制的13转换成二进制
2 | 13 1
 ̄ ̄ ̄
2 | 6 0
 ̄ ̄ ̄
2 | 3 1
 ̄ ̄ ̄ ̄
1 1如上所示:13的二进制码为1101。
将手工换算,变成堆栈存储,只需将对2取余的结果依次压入堆栈保存,最后反转输出即可。
function binary(number){
var tmp = number;
var ArrStack = new Stack();
if(number === 0){
return 0;
}
while(tmp){
ArrStack.push(tmp % 2);
tmp = parseInt(tmp / 2, 10);
}
return reverse(ArrStack.read()).join('');
}
binary(14); // 输出=> "1110"
binary(1024); // 输出=> "10000000000"这个案例,其实可以理解为简化版的eval方法。
案例内容是对1+7*(4-2)的求值。
进入主题前,有必要先了解以下的数学理论:
- 中缀表示法(或中缀记法)是一个通用的算术或逻辑公式表示方法, 操作符是以中缀形式处于操作数的中间(例:3 + 4)。
- 逆波兰表示法(Reverse Polish notation,RPN,或逆波兰记法),是一种是由波兰数学家扬·武卡谢维奇1920年引入的数学表达式方式,在逆波兰记法中,所有操作符置于操作数的后面,因此也被称为后缀表示法。逆波兰记法不需要括号来标识操作符的优先级。
常规中缀记法的“3 - 4 + 5”在逆波兰记法中写作“3 4 - 5 +”- 调度场算法(Shunting Yard Algorithm)是一个用于将中缀表达式转换为后缀表达式的经典算法,由艾兹格·迪杰斯特拉引入,因其操作类似于火车编组场而得名。
提前说明,这只是简单版实现。所以规定有两个:
- 数字要求为整数
- 不允许表达式中出现多余的空格
实现代码如下:
function calculate(exp){
var valueStack = new Stack(); // 数值栈
var operatorStack = new Stack(); // 操作符栈
var expArr = exp.split(''); // 切割字符串表达式
var FIRST_OPERATOR = ['+', '-']; // 加减运算符
var SECOND_OPERATOR = ['*', '/']; // 乘除运算符
var SPECIAL_OPERATOR = ['(', ')']; // 括号
var tmp; // 临时存储当前处理的字符
var tmpOperator; // 临时存储当前的运算符
// 遍历表达式
for(var i = 0, len = expArr.length; i < len; i++){
tmp = expArr[i];
switch(tmp){
case '(':
operatorStack.push(tmp);
break;
case ')':
// 遇到右括号,先出栈括号内数据
while( (tmpOperator = operatorStack.pop()) !== '(' &&
typeof tmpOperator !== 'undefined' ){
valueStack.push(calculator(tmpOperator, valueStack.pop(), valueStack.pop()));
}
break;
case '+':
case '-':
while( typeof operatorStack.readTop() !== 'undefined' &&
SPECIAL_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
(SECOND_OPERATOR.indexOf(operatorStack.readTop()) !== -1 || tmp != operatorStack.readTop()) ){
// 栈顶为乘除或相同优先级运算,先出栈
valueStack.push(calculator(operatorStack.pop(), valueStack.pop(), valueStack.pop()));
}
operatorStack.push(tmp);
break;
case '*':
case '/':
while( typeof operatorStack.readTop() != 'undefined' &&
FIRST_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
SPECIAL_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
tmp != operatorStack.readTop()){
// 栈顶为相同优先级运算,先出栈
valueStack.push(calculator(operatorStack.pop(), valueStack.pop(), valueStack.pop()));
}
operatorStack.push(tmp);
break;
default:
valueStack.push(tmp);
}
}
// 处理栈内数据
while( typeof (tmpOperator = operatorStack.pop()) !== 'undefined' ){
valueStack.push(calculator(tmpOperator, valueStack.pop(), valueStack.pop()));
}
return valueStack.pop(); // 将计算结果推出
/*
@param operator 操作符
@param initiativeNum 主动值
@param passivityNum 被动值
*/
function calculator(operator, passivityNum, initiativeNum){
var result = 0;
initiativeNum = typeof initiativeNum === 'undefined' ? 0 : parseInt(initiativeNum, 10);
passivityNum = typeof passivityNum === 'undefined' ? 0 : parseInt(passivityNum, 10);
switch(operator){
case '+':
result = initiativeNum + passivityNum;
console.log(`${initiativeNum} + ${passivityNum} = ${result}`);
break;
case '-':
result = initiativeNum - passivityNum;
console.log(`${initiativeNum} - ${passivityNum} = ${result}`);
break;
case '*':
result = initiativeNum * passivityNum;
console.log(`${initiativeNum} * ${passivityNum} = ${result}`);
break;
case '/':
result = initiativeNum / passivityNum;
console.log(`${initiativeNum} / ${passivityNum} = ${result}`);
break;
default:;
}
return result;
}
}实现思路:
调度场算法,对中缀表达式进行读取,对结果进行合理运算。operatorStack.readTop() !== 'undefined'进行判定。有些书采用#做结束标志,个人觉得有点累赘。split进行拆分,然后进行遍历读取,压入堆栈。有提前要计算结果的,进行对应的出栈处理。calculator。由于乘除运算符前后的数字,在运算上有区别,所以不能随意调换位置。逆波兰表示法,是一种对计算机友好的表示法,不需要使用括号。
下面案例,是对上一个案例的变通,也是用调度场算法,将中缀表达式转换为后缀表达式。
function rpn(exp){
var valueStack = new Stack(); // 数值栈
var operatorStack = new Stack(); // 操作符栈
var expArr = exp.split('');
var FIRST_OPERATOR = ['+', '-'];
var SECOND_OPERATOR = ['*', '/'];
var SPECIAL_OPERATOR = ['(', ')'];
var tmp;
var tmpOperator;
for(var i = 0, len = expArr.length; i < len; i++){
tmp = expArr[i];
switch(tmp){
case '(':
operatorStack.push(tmp);
break;
case ')':
// 遇到右括号,先出栈括号内数据
while( (tmpOperator = operatorStack.pop()) !== '(' &&
typeof tmpOperator !== 'undefined' ){
valueStack.push(translate(tmpOperator, valueStack.pop(), valueStack.pop()));
}
break;
case '+':
case '-':
while( typeof operatorStack.readTop() !== 'undefined' &&
SPECIAL_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
(SECOND_OPERATOR.indexOf(operatorStack.readTop()) !== -1 || tmp != operatorStack.readTop()) ){
// 栈顶为乘除或相同优先级运算,先出栈
valueStack.push(translate(operatorStack.pop(), valueStack.pop(), valueStack.pop()));
}
operatorStack.push(tmp);
break;
case '*':
case '/':
while( typeof operatorStack.readTop() != 'undefined' &&
FIRST_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
SPECIAL_OPERATOR.indexOf(operatorStack.readTop()) === -1 &&
tmp != operatorStack.readTop()){
// 栈顶为相同优先级运算,先出栈
valueStack.push(translate(operatorStack.pop(), valueStack.pop(), valueStack.pop()));
}
operatorStack.push(tmp);
break;
default:
valueStack.push(tmp);
}
}
while( typeof (tmpOperator = operatorStack.pop()) !== 'undefined' ){
valueStack.push(translate(tmpOperator, valueStack.pop(), valueStack.pop()));
}
return valueStack.pop(); // 将计算结果推出
/*
@param operator 操作符
@param initiativeNum 主动值
@param passivityNum 被动值
*/
function translate(operator, passivityNum, initiativeNum){
var result = '';
switch(operator){
case '+':
result = `${initiativeNum} ${passivityNum} +`;
console.log(`${initiativeNum} + ${passivityNum} = ${result}`);
break;
case '-':
result = `${initiativeNum} ${passivityNum} -`;
console.log(`${initiativeNum} - ${passivityNum} = ${result}`);
break;
case '*':
result = `${initiativeNum} ${passivityNum} *`;
console.log(`${initiativeNum} * ${passivityNum} = ${result}`);
break;
case '/':
result = `${initiativeNum} ${passivityNum} /`;
console.log(`${initiativeNum} / ${passivityNum} = ${result}`);
break;
default:;
}
return result;
}
}
rpn('1+7*(4-2)'); // 输出=> "1 7 4 2 - * +"汉诺塔(港台:河内塔)是根据一个传说形成的数学问题:
有三根杆子A,B,C。A杆上有 N 个 (N>1) 穿孔圆盘,盘的尺寸由下到上依次变小。要求按下列规则将所有圆盘移至 C 杆:
- 每次只能移动一个圆盘;
- 大盘不能叠在小盘上面。
堆栈的经典算法应用,首推就是汉诺塔。
理解该算法,要注意以下几点:
以下是代码实现:
var ATower = new Stack(); // A塔
var BTower = new Stack(); // B塔
var CTower = new Stack(); // C塔 (目标塔)
var TIER = 4; // 层数
for(var i = TIER; i > 0; i--){
ATower.push(i);
}
function Hanoi(n, from, to, buffer){
if(n > 0){
Hanoi(n - 1, from, buffer, to); // 所有不符合要求的盘(n-1),从A塔统一移到B塔缓存
to.push(from.pop()); // 将符合的盘(n)移动到C塔
Hanoi(n - 1, buffer, to, from); // 把B塔缓存的盘全部移动到C塔
}
}
Hanoi(ATower.read().length, ATower, CTower, BTower);汉诺塔的重点,还是靠递归去实现。把一个大问题,通过递归,不断分拆为更小的问题。然后,集中精力解决小问题即可。
不知不觉,写得有点多ORZ。
后面章节的参考链接,还是推荐看看。也许配合本文,你会有更深的理解。
移动端开发,经常会遇到的问题,就是文字居中。一般都只能往css方向去fix这个问题。
自己以前也用过position:relative;top:-*px的方式去解决。🌚
后来才发现,原来不是css的问题,是浏览器在渲染象形文字时,就已经错误了。
本文参考自知乎回答,用来总结如何填上这个坑~
先总结下,前端开发中,常用的文字居中技巧。
height:20px;
line-height:20px;<p class="text-wrap">
<span class="text">文字居中</span>
</p>.text-wrap{
display:table;
}
.text{
display:table-cell;
vertical-align:middle;
}<p class="text-wrap">
<span class="text">文字居中</span>
</p>.text-wrap{
position:relative;
height:20px; /* 必须设置一个高度,一般取文字高度 。因为内容abs定位后,高度为0*/
}
.text{
position:absolute;
top:50%;
left:50%;
transform:translate(-50%, -50%);
}<p class="text-wrap">
<span class="text">文字居中</span>
</p>.text-wrap{
display:flex;
justify-content:center; /* 左右居中 */
align-items:center; /* 上下居中 */
}因为文字在content-area内部渲染的时候就已经偏移。css的居中方案都是用来控制整个content-area的居中而已,对content-area内部不会产生实质性的影响。
导致这个问题的本质原因可能是Android在排版计算的时候参考了primyfont字体的相关属性(即HHead Ascent、HHead Descent等)。
primyfont字体的确定,是依据font-family里哪个字体在fonts.xml里第一个匹配上。
原生Android下中文字体是没有family name的,导致匹配上的字体始终不是中文字体。所以渲染的时候出现偏差。
那么,解决这个问题就要在font-family里显式申明中文,或者通过什么方法保证所有字符都fallback到中文字体。
1.针对Android 7.0+设备:上设置 lang 属性:,同时font-family不指定英文。
比较常用的是设置font-family: sans-serif 。
这个方法是利用了浏览器的字体fallback机制,让英文也使用中文字体来展示。blink早期的内核在fallback机制上存在问题,Android 7.0+才能ok,早期的内核下会导致英文fallback到Noto Sans Myanmar,这个字体非常丑。
2.针对MIUI 8.0+设备:设置font-family: miui。
这个方案就是显式申明中文的方案,MIUI在8.0+上内置了小米兰亭,同时在fonts.xml里给这个字体指定了family name:miui,所以我们可以直接设置。
另外,腾讯的IMWeb团队也给出了解决方案,但亲测,治标不治本。还是上述方案较为完美地解决。
[1] Android浏览器下line-height垂直居中为什么会偏离 -- 周祺回答
[2] Android 浏览器文本垂直居中问题 -- IMWeb解决方案
柯里化,可以理解为提前接收部分参数,延迟执行,不立即输出结果,而是返回一个接受剩余参数的函数。因为这样的特性,也被称为部分计算函数。柯里化,是一个逐步接收参数的过程。在接下来的剖析中,你会深刻体会到这一点。
反柯里化,是一个泛型化的过程。它使得被反柯里化的函数,可以接收更多参数。目的是创建一个更普适性的函数,可以被不同的对象使用。有鸠占鹊巢的效果。
实现 add(1)(2, 3)(4)() = 10 的效果
依题意,有两个关键点要注意:
- 传入参数时,代码不执行输出结果,而是先记忆起来
- 当传入空的参数时,代表可以进行真正的运算
完整代码如下:
function currying(fn){
var allArgs = [];
return function next(){
var args = [].slice.call(arguments);
if(args.length > 0){
allArgs = allArgs.concat(args);
return next;
}else{
return fn.apply(null, allArgs);
}
}
}
var add = currying(function(){
var sum = 0;
for(var i = 0; i < arguments.length; i++){
sum += arguments[i];
}
return sum;
});由于是延迟计算结果,所以要对参数进行记忆。
这里的实现方式是采用闭包。
function currying(fn){
var allArgs = [];
return function next(){
var args = [].slice.call(arguments);
if(args.length > 0){
allArgs = allArgs.concat(args);
return next;
}
}
}当执行var add = currying(...)时,add变量已经指向了next方法。此时,allArgs在next方法内部有引用到,所以不能被GC回收。也就是说,allArgs在该赋值语句执行后,一直存在,形成了闭包。
依靠这个特性,只要把接收的参数,不断放入allArgs变量进行存储即可。
所以,当arguments.length > 0时,就可以将接收的新参数,放到allArgs中。
最后返回next函数指针,形成链式调用。
题意是,空参数时,输出结果。所以,只要判断arguments.length == 0即可执行。
另外,由于计算结果的方法,是作为参数传入currying函数,所以要利用apply进行执行。
综合上述思考,就可以得到以下完整的柯里化函数。
function currying(fn){
var allArgs = []; // 用来接收参数
return function next(){
var args = [].slice.call(arguments);
// 判断是否执行计算
if(args.length > 0){
allArgs = allArgs.concat(args); // 收集传入的参数,进行缓存
return next;
}else{
return fn.apply(null, allArgs); // 符合执行条件,执行计算
}
}
}柯里化,在这个例子中可以看出很明显的行为规范:
实现 add(1)(2, 3)(4)(5) = 15 的效果。
很多人这里就犯嘀咕了:我怎么知道执行的时机?
其实,这里有个忍者技艺:valueOf和toString。
js在获取当前变量值的时候,会根据语境,隐式调用valueOf和toString方法进行获取需要的值。
那么,实现起来就很简单了。
function currying(fn){
var allArgs = [];
function next(){
var args = [].slice.call(arguments);
allArgs = allArgs.concat(args);
return next;
}
// 字符类型
next.toString = function(){
return fn.apply(null, allArgs);
};
// 数值类型
next.valueOf = function(){
return fn.apply(null, allArgs);
}
return next;
}
var add = currying(function(){
var sum = 0;
for(var i = 0; i < arguments.length; i++){
sum += arguments[i];
}
return sum;
});有以下轻提示类。现在想要单独使用其show方法,输出新对象obj中的内容。
// 轻提示
function Toast(option){
this.prompt = '';
}
Toast.prototype = {
constructor: Toast,
// 输出提示
show: function(){
console.log(this.prompt);
}
};
// 新对象
var obj = {
prompt: '新对象'
};用反柯里化的方式,可以这么做
function unCurrying(fn){
return function(){
var args = [].slice.call(arguments);
var that = args.shift();
return fn.apply(that, args);
}
}
var objShow = unCurrying(Toast.prototype.show);
objShow(obj); // 输出"新对象"在上面的例子中,Toast.prototype.show方法,本来是Toast类的私有方法。跟新对象obj没有半毛钱关系。
经过反柯里化后,却可以为obj对象所用。
为什么能被obj所用,是因为内部将Toast.prototype.show的上下文重新定义为obj。也就是用apply改变了this指向。
而实现这一步骤的过程,就需要增加反柯里化后的objShow方法参数。
Function.prototype.unCurrying = function(){
var self = this;
return function(){
return Function.prototype.call.apply(self, arguments);
}
}
// 使用
var objShow = Toast.prototype.show.unCurrying();
objShow(obj);这里的难点,在于理解Function.prototype.call.apply(self, arguments);。
可以分拆为两步:
1) Function.prototype.call.apply(...)的解析
可以看成是callFunction.apply(...)。这样,就清晰很多。
callFunction的this指针,被apply修改为self。
然后执行callFunction -> callFunction(arguments)
2) callFunction(arguments)的解析
call方法,第一个参数,是用来指定this的。所以callFunction(arguments) -> callFunction(arguments[0], arguments[1-n])。
由此可以得出,反柯里化后,第一个参数,是用来指定this指向的。
3)为什么要用apply(self, arguments)
如果使用apply(null, arguments),因为null对象没有call方法,会报错。
var fn = function(){};
var val = 1;
if(Object.prototype.toString.call(fn) == '[object Function]'){
console.log(`${fn} is function.`);
}
if(Object.prototype.toString.call(val) == '[object Number]'){
console.log(`${val} is number.`);
}上述代码,用反柯里化,可以这么写:
var fn = function(){};
var val = 1;
var toString = Object.prototype.toString.unCurrying();
if(toString(fn) == '[object Function]'){
console.log(`${fn} is function.`);
}
if(toString(val) == '[object Number]'){
console.log(`${val} is number.`);
}function nodeListen(node, eventName){
return function(fn){
node.addEventListener(eventName, function(){
fn.apply(this, Array.prototype.slice.call(arguments));
}, false);
}
}
var bodyClickListen = nodeListen(document.body, 'click');
bodyClickListen(function(){
console.log('first listen');
});
bodyClickListen(function(){
console.log('second listen');
});使用柯里化,优化监听DOM节点事件。addEventListener三个参数不用每次都写。
其实,反柯里化和泛型方法一样,只是理念上有一些不同而已。理解这种思维即可。
本文适用于使用Git做VCS(版本控制系统)的场景。
用过Git的程序猿,都喜欢其分布式架构带来的commit快感。不用像使用SVN这种集中式版本管理系统,每一次提交代码,都要为代码冲突捏一把冷汗。
频繁commit的背后,带来的结果是一长串密密麻麻的提交记录。
一旦项目出现问题,需要检查某个节点的代码问题,就会有点头疼。
虽然有commit message,但还是有存在查找困难和描述不清的问题。
本文的侧重点,就是通过Git的打标签功能git tag来解决这个问题,并用SemVer(语义化版本控制规范)规范标签的命名。
打标签的作用,就是给项目的开发节点,加上语义化的名字,也即功能版本的别名。
打上标签名的同时,写上附带信息,可以方便项目日后维护过程中的回溯和复查。
另外,也可以通过标签记录,大致了解当前项目的向下兼容性、API的修改和迭代情况。
一般推荐打带附注信息的标签,这样可以最大限度的查看标签版本的修改情况。
// 命令格式
git tag -a 标签名 -m "附注信息"
// 示例
git tag -a v0.1.0 -m "完成了文章a和文章b的撰写,耗费时间2h,感觉棒棒的!"
一份文集等待出版,有
a、b、c、d四篇。
现在通过Git管理进度。
commit操作,添加a.txt和b.txt后,将代码修改push到远程仓库。仓库图表如下:
master -> * 添加b.txt
|
* 添加a.txt
|
* 初始化
// 打标签
git tag -a v0.1.0 -m "完成了文章a和文章b的撰写,耗费时间2h,感觉棒棒的!"
// push 标签到远程仓库
git push origin v0.1.0
仓库图表如下:
master v0.1.0 -> * 添加b.txt
|
* 添加a.txt
|
* 初始化
commit操作,添加c.txt和d.txt后,将代码修改push到远程仓库。仓库图表如下:
master -> * 添加d.txt
|
* 添加c.txt
|
v0.1.0 -> * 添加b.txt
|
* 添加a.txt
|
* 初始化
// 打标签
git tag -a v1.0.0 -m "文集完成,共4篇文章,等出版�。"
// push 标签到远程仓库
git push origin v1.0.0
仓库图表如下:
master v1.0.0 -> * 添加d.txt
|
* 添加c.txt
|
v0.1.0 -> * 添加b.txt
|
* 添加a.txt
|
* 初始化
v0.1.0版本的情况// 输出v0.1.0的详情
git show v0.1.0
// 输出结果
tag v0.1.0
Tagger: wall <[email protected]>
Date: Wed May 23 15:57:13 2018 +0800
完成了文章a和文章b的撰写,耗费时间2h,感觉棒棒的!
commit 7107eb8b3f870cd864e3eb5b14f26184d73dd1e6 (tag: v0.1.0)
Author: wall <[email protected]>
Date: Wed May 23 15:27:10 2018 +0800
添加b.txt
diff --git a/src/b.txt b/src/b.txt
new file mode 100644
index 0000000..f9ee20e
--- /dev/null
+++ b/src/b.txt
这里,可以清晰地看到当时打标签的内容和附注信息。
还有另外一个方便的点,就是不需要用hash字符串表示的版本号去查看更改。
以下是用版本号查询的结果:
// 用版本号查看
git show 7107eb8b3f870cd864e3eb5b14f26184d73dd1e6
// 输出结果
commit 7107eb8b3f870cd864e3eb5b14f26184d73dd1e6 (tag: v0.1.0)
Author: wall <[email protected]>
Date: Wed May 23 15:27:10 2018 +0800
添加b.txt
diff --git a/src/b.txt b/src/b.txt
new file mode 100644
index 0000000..f9ee20e
--- /dev/null
+++ b/src/b.txt
@@ -0,0 +1 @@
+This is B.
\ No newline at end of file
像上文的栗子,可以看出使用了v0.1.0和v1.0.0打标签。
其实,这里是遵循了一套语义化版本控制规范(Semantic Versioning)。
规范的概要如下:
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
- 主版本号:当你做了不兼容的 API 修改,
- 次版本号:当你做了向下兼容的功能性新增,
- 修订号:当你做了向下兼容的问题修正。
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
为什么要有这套规范,就是为了避免软件管理的领域里存在的,称为“依赖地狱”的死亡之谷。
规范详情,可以在下面的参考链接获取。
[1] 语义化版本2.0
利用markdown+Hexo写文章,整体体验已经很棒。在写作过程中,节省了我不少时间。
但是,美中不足的,就是发布的时候,需要手动输入命令,build好文件,再用scp部署到服务器上。
本文,用于记录解决这个痛点的过程。采取的解决方案就是持续集成。
以下是我用于部署个人站点的服务器概况:
服务器 - 阿里云ECS
系统 - CentOS 7
Git仓库管理工具 - Gitlab(9.0.0)
CPU - 1核
内存 - 2 GB (乞丐版💔)
正常情况下,注册GitLab-Runner的服务器和部署生产文件的服务器是分开的。
因为穷🌚,我只有一台服务器,所以两者都部署到一起,大家就别太纠结这个点了。
持续集成(Continuous integration),简称 CI,是指开发代码频繁地合并进主干,始终保持可发布状态的这个过程。其中包含持续构建和持续发布。
GitLab 8.0以上的版本就有提供持续集成服务。只要在项目中添加一个.gitlab-ci.yml文件,然后再添加一个Runner,即可进行持续集成。
我对自动发布博客的总体实现思路:
添加Runner用于监听git push操作,然后用.gitlab-ci.yml指导步骤的执行,最后用shell脚本copy目标文件到指定目录下。
前提:请自行Google
gitlab-ci-multi-runner安装教程。
URL和token浏览器打开一个GitLab项目,到 Settings-CI/CD Pipelines 下,可以看到一个 Specific Runners块,主要有以下内容:
How to setup a specific Runner for a new project
1.Install a Runner compatible with GitLab CI (checkout the GitLab Runner section for information on how to install it).
2.Specify the following URL during the Runner setup:
http://gitlab.***.com/ci3.Use the following registration token during setup: TB8nknzg1woVb4pCx666
Start the Runner!
其中第2项的URL和第3项的token,是注册Runner所必需的。
Runner凭借token注册监听对应的URL。
GitLab-Runner这里,我用SecureCRT连接上服务器,进行以下操作:
// 1.运行命令
sudo gitlab-ci-multi-runner register
// 2.根据提示输入`URL`
Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/):
http://gitlab.***.com/ci
// 3.根据提示输入`token`
Please enter the gitlab-ci token for this runner:
TB8nknzg1woVb4pCx666
// 4.然后输入runner的描述
Please enter the gitlab-ci description for this runner:
wall-runner
// 5.输入标签,可以多个,用逗号隔开即可
Please enter the gitlab-ci tags for this runner (comma separated):
test
// 6.是否运行无此标签的构建
Whether to run untagged builds [true/false]:
true
// 7.将Runer锁定到当前项目
Whether to lock the Runner to current project [true/false]:
true
// 8.选择Runner的类型
Please enter the executor: ssh, docker+machine, kubernetes, docker, docker-ssh, parallels, shell, virtualbox, docker-ssh+machine:
shell
这样,一个GitLab-Runner就创建成功。刷新浏览器页面,在Settings-CI/CD Pipelines 下可以看到runner已经绑定成功。
.gitlab-ci.yml在要添加持续集成功能的项目的根目录下,创建.gitlab-ci.yml文件,编写构建步骤。
在编写之前,先大致了解下写法:
# 定义stages
stages:
- install
- deploy
# 定义需要缓存的文件
cache:
paths:
- node_modules/
# 定义任务
job1:
stage: install
script:
- cnpm install
only:
- master
# 定义任务
job2:
stage: deploy
script:
- bash pub.sh
only:
- masterstages关键字定义Pipeline中的各个构建阶段的先后顺序cache关键字定义每个构建阶段,不需要清除的文件job1和job2。也有真正的stage名,用于stages中标识先后的顺序script用于定义当前构建阶段需要执行的命令only用于指定哪个Git分支的push操作才能触发自动构建以下是我在blog项目应用的.gitlab-ci.yml
# 持续集成
stages:
- install
- build
- minify
- deploy
cache:
paths:
- node_modules/
- public/
- db.json
# 安装依赖
install_npm:
stage: install
script:
## - cnpm install [email protected] -g ## 同一台服务器,不用多次安装
- cnpm install
only:
- master
# 编译,生成静态文件
build_public:
stage: build
script:
- npm run build
only:
- master
# 压缩文件
mini_file:
stage: minify
script:
- npm run minify
only:
- master
# 部署
deploy:
stage: deploy
script:
- bash pub.sh
only:
- master
前言中,有提到一个痛点就是scp部署文件。因为网速的原因,每次跑scp命令都要等好几分钟,电脑也不能关机。得等到传输完成,才可以。
升级为持续集成后,就不需要在本地跑命令了,都统一在服务器上跑。
而能代替文件传输这个步骤的,就是写一个Shell脚本,让服务器自动copy文件到对应的目录下。
以下是我应用的Shell脚本pub.sh
#!bin/bash
cp -f -r -v ./public/* /mnt/blog/作用就是将public文件夹下所有文件copy到/mnt/blog/下。
因为我是同一台服务器上跑命令,所以当前Runner进程必须对相关文件夹有写入和读取权限。
所以,我把几个文件夹的读写权限赋予Runner进程。
使用chown命令,对文件夹对拥有者权限进行更改:
chown wall-runner 文件路径
如果Runner服务器和生产环境服务器是相互独立的,则可以使用ssh的方式去连接。配置好密钥和绕过指纹检查即可。
经过上述的配置,每次push代码到master分支。Runner监听到操作后,就会启动自动构建,完成部署。
这样,我发表新文章,只需要负责把markdown写好,push代码到GitLab。其他的工作,服务器会自动帮我做好。
写好文章,我也可以愉快地关机休息,不用去打理其他的事,感觉真棒!
而且,每次构建记录都有保存在GitLab上。可以在Pipelines中查看每次构建的结果。
还可以在README.md加入构建状态图标:
有需要的,就买个服务器折腾下,挺好玩的🌚
附上阿里云服务器的优惠券
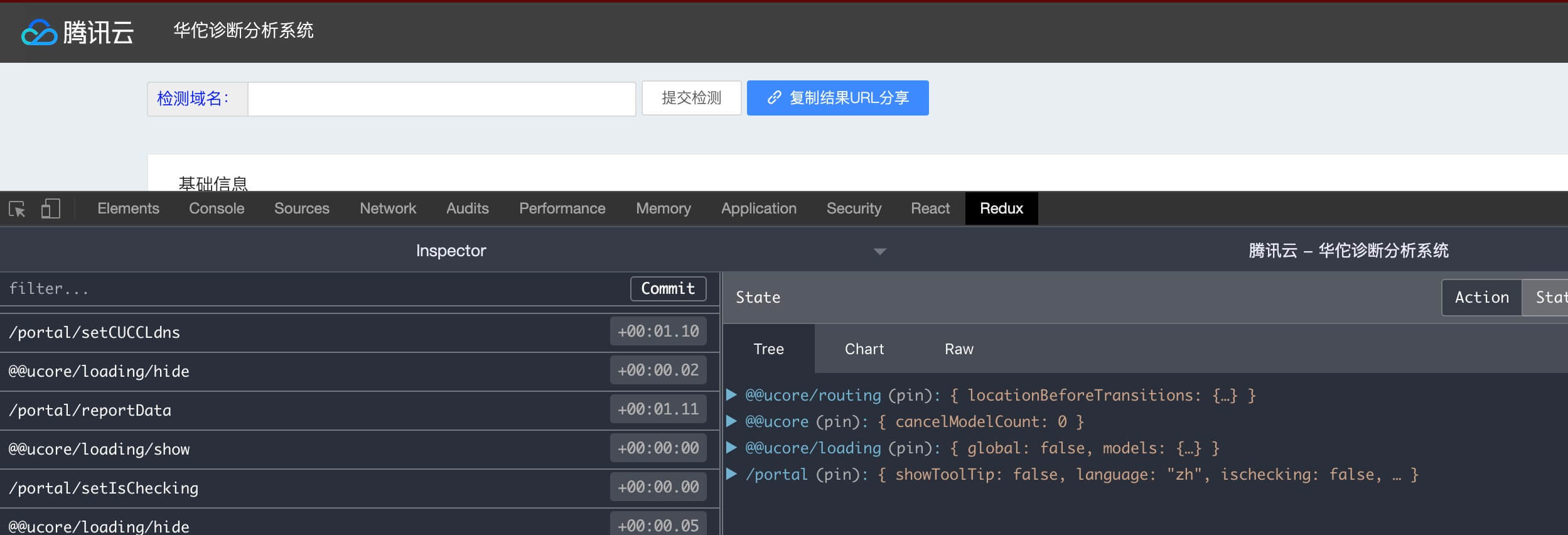
React Developer Tools、Redux DevTools 可以给开发人员在研发阶段调试程序带来极大的方便。
但是,很多人忽略了一点:上了生产环境后,把一些代码细节轻易让外部人员获取,并不是好事。
解决方案就是:生产环境下,将DevTools禁止使用。
以下是实现的代码
// 项目入口文件index.tsx
import {
disableReactDevTools
} from '@utils/js/other';
if(process.env.NODE_ENV == 'production'){
disableReactDevTools();
}// @utils/js/other.ts
export const disableReactDevTools = (): void => {
const noop = (): void => undefined;
const DEV_TOOLS = (window as any).__REACT_DEVTOOLS_GLOBAL_HOOK__;
if (typeof DEV_TOOLS === 'object') {
for (const [key, value] of (<any>Object).entries(DEV_TOOLS)) {
DEV_TOOLS[key] = typeof value === 'function' ? noop : null;
}
}
};禁止思路如下:
window.__REACT_DEVTOOLS_GLOBAL_HOOK__.inject = function () {}这样可以阻止devtools访问React上下文
window.__REACT_DEVTOOLS_GLOBAL_HOOK__下挂载的方法,将其重置为空函数。windwo.__REACT_DEVTOOLS_GLOBAL_HOOK__的,所以要进行安全防护。综合以上3点,就可以得出disableReactDevTools方法。
另外,只在生产环境禁止,则需要读取process.env.NODE_ENV的值,进行判断。符合要求,则执行disableReactDevTools方法。
Redux DevTools的作者做得比较全面,已经给出了标准的解决方案。
具体实现步骤如下:
'process.env.NODE_ENV': JSON.stringify('production')redux-devtools-extension/developmentOnly引入方法以下是我的项目代码片断:
import {
composeWithDevTools
} from 'redux-devtools-extension/developmentOnly';
// other code...
const store = createStore(
rootReducer,
composeWithDevTools(middlewareEnhancer)
);
// other code...如图所示,nginx缓存,可以在一定程度上,减少源服务器的处理请求压力。
因为静态文件(比如css,js, 图片)中,很多都是不经常更新的。nginx使用proxy_cache将用户的请求缓存到本地一个目录。下一个相同请求可以直接调取缓存文件,就不用去请求服务器了。
毕竟,IO密集型服务的处理是nginx的强项。
先上个栗子:
http{
proxy_connect_timeout 10;
proxy_read_timeout 180;
proxy_send_timeout 5;
proxy_buffer_size 16k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 96k;
proxy_temp_file_write_size 96k;
proxy_temp_path /tmp/temp_dir;
proxy_cache_path /tmp/cache levels=1:2 keys_zone=cache_one:100m inactive=1d max_size=10g;
server {
listen 80 default_server;
server_name localhost;
root /mnt/blog/;
location / {
}
#要缓存文件的后缀,可以在以下设置。
location ~ .*\.(gif|jpg|png|css|js)(.*) {
proxy_pass http://ip地址:90;
proxy_redirect off;
proxy_set_header Host $host;
proxy_cache cache_one;
proxy_cache_valid 200 302 24h;
proxy_cache_valid 301 30d;
proxy_cache_valid any 5m;
expires 90d;
add_header wall "hey!guys!give me a star.";
}
}
# 无nginx缓存的blog端口
server {
listen 90;
server_name localhost;
root /mnt/blog/;
location / {
}
}
}
因为我是在一台服务器上做试验,�所以用了两个端口80和90进行模拟两台服务器之间的交互。
80端口对接的是普通的域名(http://wangxiaokai.vip)访问。
90端口负责处理80端口代理过来的资源访问。
相当于90端口是源服务器,80端口是nginx�反向缓存代理服务器。
接下来讲一下配置项:
proxy_connect_timeout 10;
proxy_read_timeout 180;
proxy_send_timeout 5;
proxy_buffer_size 16k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 96k;
proxy_temp_file_write_size 96k;
proxy_temp_path /tmp/temp_dir;
proxy_cache_path /tmp/cache levels=1:2 keys_zone=cache_one:100m inactive=1d max_size=10g;
服务器连接的超时时间连接成功后,等候后端服务器响应时间后端服务器数据回传时间缓冲区的大小每个连接设置缓冲区的数量为number,每块缓冲区的大小为size开启缓冲响应的功能以后,在没有读到全部响应的情况下,写缓冲到达一定大小时,nginx一定会向客户端发送响应,直到缓冲小于此值。设置nginx每次写数据到临时文件的size(大小)限制从后端服务器接收的临时文件的存放路径设置缓存的路径和其他参数。被缓存的数据如果在inactive参数(当前�为1天)指定的时间内未被访问,就会被从缓存中移除 server {
listen 80 default_server;
server_name localhost;
root /mnt/blog/;
location / {
}
#要缓存文件的后缀,可以在以下设置。
location ~ .*\.(gif|jpg|png|css|js)(.*) {
proxy_pass http://ip地址:90;
proxy_redirect off;
proxy_set_header Host $host;
proxy_cache cache_one;
proxy_cache_valid 200 302 24h;
proxy_cache_valid 301 30d;
proxy_cache_valid any 5m;
expires 90d;
add_header wall "hey!guys!give me a star.";
}
}
�nginx缓存里拿不到资源,向该地址转发请求,拿到新的资源,并进行缓存设置后端服务器“Location”响应头和“Refresh”响应头的替换文本允许重新定义或者添加发往后端服务器的请求头指定用于页面缓存的共享内存,对应http层设置的keys_zone为不同的响应状态码设置不同的缓存时间缓存时间这里我设置了图片、css、js静态资源进行缓存。
当用户输入http://wangxiaokai.vip域名时,解析得到ip:port的访问地址。port默认为80�。所以页面请求会被当前server截取到,进行请求处理。
当解析到上述文件名结尾的静态资源,会到缓存区获取静态资源。
如果获取到对应资源,则直接返回数据。
如果获取不到,则将请求转发给proxy_pass指向的地址进行处理。
server {
listen 90;
server_name localhost;
root /mnt/blog/;
location / {
}
}
这里直接处理90端口接受到的请求,到服务器本地目录/mnt/blog下抓取资源�进行响应。
细心的读者应该发现,我在第二段栗子里,留了个彩蛋 add_header wall "hey!guys!give me a star."。
add_header是用于在报头设置自定义的信息。
所以,如果缓存有效的话,那么静态资源返回的报头,一定会带上这个信息。
访问http://wangxiaokai.vip结果如下:
[1] nginx文档
[2] nginx反向缓存代理详解
[3] Nginx缓存服务器静态文件
我的GitHub仓库
Give me a star,if it's work out for you.Thank you.
lodash受欢迎的一个原因,是其优异的计算性能。而其性能能有这么突出的表现,很大部分就来源于其使用的算法——惰性求值。
本文将讲述lodash源码中,惰性求值的原理和实现。
惰性求值(Lazy Evaluation),又译为惰性计算、懒惰求值,也称为传需求调用(call-by-need),是计算机编程中的一个概念,它的目的是要最小化计算机要做的工作。
惰性求值中的参数直到需要时才会进行计算。这种程序实际上是从末尾开始反向执行的。它会判断自己需要返回什么,并继续向后执行来确定要这样做需要哪些值。
以下是How to Speed Up Lo-Dash ×100? Introducing Lazy Evaluation.(如何提升Lo-Dash百倍算力?惰性计算的简介)文中的示例,形象地展示惰性求值。
function priceLt(x) {
return function(item) { return item.price < x; };
}
var gems = [
{ name: 'Sunstone', price: 4 },
{ name: 'Amethyst', price: 15 },
{ name: 'Prehnite', price: 20},
{ name: 'Sugilite', price: 7 },
{ name: 'Diopside', price: 3 },
{ name: 'Feldspar', price: 13 },
{ name: 'Dioptase', price: 2 },
{ name: 'Sapphire', price: 20 }
];
var chosen = _(gems).filter(priceLt(10)).take(3).value();程序的目的,是对数据集gems进行筛选,选出3个price小于10的数据。
如果抛开lodash这个工具库,让你用普通的方式实现var chosen = _(gems).filter(priceLt(10)).take(3);那么,可以用以下方式:
_(gems)拿到数据集,缓存起来。
再执行filter方法,遍历gems数组(长度为10),取出符合条件的数据:
[
{ name: 'Sunstone', price: 4 },
{ name: 'Sugilite', price: 7 },
{ name: 'Diopside', price: 3 },
{ name: 'Dioptase', price: 2 }
]然后,执行take方法,提取前3个数据。
[
{ name: 'Sunstone', price: 4 },
{ name: 'Sugilite', price: 7 },
{ name: 'Diopside', price: 3 }
]总共遍历的次数为:10+3。
执行的示例图如下:
普通的做法存在一个问题:每个方法各做各的事,没有协调起来浪费了很多资源。
如果能先把要做的事,用小本本记下来😎,然后等到真正要出数据时,再用最少的次数达到目的,岂不是更好。
惰性计算就是这么做的。
以下是实现的思路:
_(gems)拿到数据集,缓存起来filter方法,先记下来take方法,先记下来value方法,说明时机到了filter方法里的判断方法priceLt对数据进行逐个裁决[
{ name: 'Sunstone', price: 4 }, => priceLt裁决 => 符合要求,通过 => 拿到1个
{ name: 'Amethyst', price: 15 }, => priceLt裁决 => 不符合要求
{ name: 'Prehnite', price: 20}, => priceLt裁决 => 不符合要求
{ name: 'Sugilite', price: 7 }, => priceLt裁决 => 符合要求,通过 => 拿到2个
{ name: 'Diopside', price: 3 }, => priceLt裁决 => 符合要求,通过 => 拿到3个 => 够了,收工!
{ name: 'Feldspar', price: 13 },
{ name: 'Dioptase', price: 2 },
{ name: 'Sapphire', price: 20 }
]如上所示,一共只执行了5次,就把结果拿到。
执行的示例图如下:
从上面的例子可以得到惰性计算的特点:
value方法,通知真正开始计算依据上述的特点,我将lodash的惰性求值实现进行抽离为以下几个部分:
实现_(gems)。我这里为了语义明确,采用lazy(gems)代替。
var MAX_ARRAY_LENGTH = 4294967295; // 最大的数组长度
// 缓存数据结构体
function LazyWrapper(value){
this.__wrapped__ = value;
this.__iteratees__ = [];
this.__takeCount__ = MAX_ARRAY_LENGTH;
}
// 惰性求值的入口
function lazy(value){
return new LazyWrapper(value);
}this.__wrapped__ 缓存数据this.__iteratees__ 缓存数据管道中进行“裁决”的方法this.__takeCount__ 记录需要拿的符合要求的数据集个数这样,一个基本的结构就完成了。
filter方法var LAZY_FILTER_FLAG = 1; // filter方法的标记
// 根据 筛选方法iteratee 筛选数据
function filter(iteratee){
this.__iteratees__.push({
'iteratee': iteratee,
'type': LAZY_FILTER_FLAG
});
return this;
}
// 绑定方法到原型链上
LazyWrapper.prototype.filter = filter;filter方法,将裁决方法iteratee缓存起来。这里有一个重要的点,就是需要记录iteratee的类型type。
因为在lodash中,还有map等筛选数据的方法,也是会传入一个裁决方法iteratee。由于filter方法和map方法筛选方式不同,所以要用type进行标记。
这里还有一个技巧:
(function(){
// 私有方法
function filter(iteratee){
/* code */
}
// 绑定方法到原型链上
LazyWrapper.prototype.filter = filter;
})();原型上的方法,先用普通的函数声明,然后再绑定到原型上。如果工具内部需要使用filter,则使用声明好的私有方法。
这样的好处是,外部如果改变LazyWrapper.prototype.filter,对工具内部,是没有任何影响的。
take方法// 截取n个数据
function take(n){
this.__takeCount__ = n;
return this;
};
LazyWrapper.prototype.take = take;value方法// 惰性求值
function lazyValue(){
var array = this.__wrapped__;
var length = array.length;
var resIndex = 0;
var takeCount = this.__takeCount__;
var iteratees = this.__iteratees__;
var iterLength = iteratees.length;
var index = -1;
var dir = 1;
var result = [];
// 标签语句
outer:
while(length-- && resIndex < takeCount){
// 外层循环待处理的数组
index += dir;
var iterIndex = -1;
var value = array[index];
while(++iterIndex < iterLength){
// 内层循环处理链上的方法
var data = iteratees[iterIndex];
var iteratee = data.iteratee;
var type = data.type;
var computed = iteratee(value);
// 处理数据不符合要求的情况
if(!computed){
if(type == LAZY_FILTER_FLAG){
continue outer;
}else{
break outer;
}
}
}
// 经过内层循环,符合要求的数据
result[resIndex++] = value;
}
return result;
}
LazyWrapper.prototype.value = lazyValue;这里的一个重点就是:标签语句
outer:
while(length-- && resIndex < takeCount){
// 外层循环待处理的数组
index += dir;
var iterIndex = -1;
var value = array[index];
while(++iterIndex < iterLength){
// 内层循环处理链上的方法
var data = iteratees[iterIndex];
var iteratee = data.iteratee;
var type = data.type;
var computed = iteratee(value);
// 处理数据不符合要求的情况
if(!computed){
if(type == LAZY_FILTER_FLAG){
continue outer;
}else{
break outer;
}
}
}
// 经过内层循环,符合要求的数据
result[resIndex++] = value;
}当前方法的数据管道实现,其实就是内层的while循环。通过取出缓存在iteratees中的裁决方法取出,对当前数据value进行裁决。
如果裁决结果是不符合,也即为false。那么这个时候,就没必要用后续的裁决方法进行判断了。而是应该跳出当前循环。
而如果用break跳出内层循环后,外层循环中的result[resIndex++] = value;还是会被执行,这是我们不希望看到的。
应该一次性跳出内外两层循环,并且继续外层循环,才是正确的。
标签语句,刚好可以满足这个要求。
var testArr = [1, 19, 30, 2, 12, 5, 28, 4];
lazy(testArr)
.filter(function(x){
console.log('check x='+x);
return x < 10
})
.take(2)
.value();
// 输出如下:
check x=1
check x=19
check x=30
check x=2
// 得到结果: [1, 2]整个惰性求值的实现,重点还是在数据管道这块。以及,标签语句在这里的妙用。其实实现的方式,不只当前这种。但是,要点还是前面讲到的三个。掌握精髓,变通就很容易了。
惰性求值,是我在阅读lodash源码中,发现的最大闪光点。
当初对惰性求值不甚理解,想看下javascript的实现,但网上也只找到上文提到的一篇文献。
那剩下的选择,就是对lodash进行剖离分析。也因为这,才有本文的诞生。
希望这篇文章能对你有所帮助。如果可以的话,给个star :)
最后,附上本文实现的简易版lazy.js完整源码:
https://github.com/wall-wxk/blogDemo/blob/master/lodash/lazy.js
本文讲述怎么实现动态加载组件,并借此阐述适配器模式。
import Center from 'page/center';
import Data from 'page/data';
function App(){
return (
<Router>
<Switch>
<Route exact path="/" render={() => (<Redirect to="/center" />)} />
<Route path="/data" component={Data} />
<Route path="/center" component={Center} />
<Route render={() => <h1 style={{ textAlign: 'center', marginTop: '160px', color:'rgba(255, 255, 255, 0.7)' }}>页面不见了</h1>} />
</Switch>
</Router>
);
}以上是最常见的React router。在简单的单页应用中,这样写是ok的。因为打包后的单一js文件bundle.js也不过200k左右,gzip之后,对加载性能并没有太大的影响。
但是,当产品经历多次迭代后,追加的页面导致bundle.js的体积不断变大。这时候,优化就变得很有必要。
优化使用到的一个重要理念就是——按需加载。
可以结合例子进行理解为:只加载当前页面需要用到的组件。
比如当前访问的是/center页,那么只需要加载Center组件即可。不需要加载Data组件。
业界目前实现的方案有以下几种:
getComponent方法(router4已不支持)而这些方案共通的点,就是利用webpack的code splitting功能(webpack1使用require.ensure,webpack2/webpack3使用import),将代码进行分割。
接下来,将介绍如何用自定义高阶组件实现按需加载。
webpack将
import()看做一个分割点并将其请求的module打包为一个独立的chunk。import()以模块名称作为参数名并且返回一个Promise对象。
因为import()返回的是Promise对象,所以不能直接给<Router/>使用。
适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
当前场景,需要解决的是,使用import()异步加载组件后,如何将加载的组件交给React进行更新。
方法也很容易,就是利用state。当异步加载好组件后,调用setState方法,就可以通知到。
那么,依照这个思路,新建个高阶组件,运用适配器模式,来对import()进行封装。
import React from 'react';
export const asyncComponent = loadComponent => (
class AsyncComponent extends React.Component {
constructor(...args){
super(...args);
this.state = {
Component: null,
};
this.hasLoadedComponent = this.hasLoadedComponent.bind(this);
}
componentWillMount() {
if(this.hasLoadedComponent()){
return;
}
loadComponent()
.then(module => module.default ? module.default : module)
.then(Component => {
this.setState({
Component
});
})
.catch(error => {
/*eslint-disable*/
console.error('cannot load Component in <AsyncComponent>');
/*eslint-enable*/
throw error;
})
}
hasLoadedComponent() {
return this.state.Component !== null;
}
render(){
const {
Component
} = this.state;
return (Component) ? <Component {...this.props} /> : null;
}
}
);// 使用方式
const Center = asyncComponent(()=>import(/* webpackChunkName: 'pageCenter' */'page/center'));如例子所示,新建一个asyncComponent方法,用于接收import()返回的Promise对象。
当componentWillMount时(服务端渲染也有该生命周期方法),执行import(),并将异步加载的组件,set入state,触发组件重新渲染。
this.state = {
Component: null,
};这里的null,主要用于判断异步组件是否已经加载。
module.default ? module.default : module这里是为了兼容具名和default两种export写法。
return (Component) ? <Component {...this.props} /> : null;这里的null,其实可以用<LoadingComponent />代替。作用是:当异步组件还没加载好时,起到占位的作用。
this.props是通过AsyncComponent组件透传给异步组件的。
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash].js'),
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
}在输出项中,增加chunkFilename即可。
自定义高阶组件的好处,是可以按最少的改动,来优化已有的旧项目。
像上面的例子,只需要改变import组件的方式即可。花最少的代价,就可以得到页面性能的提升。
其实,react-loadable也是按这种思路去实现的,只不过增加了很多附属的功能点而已。
传统的前端项目初始流程一般是这样:
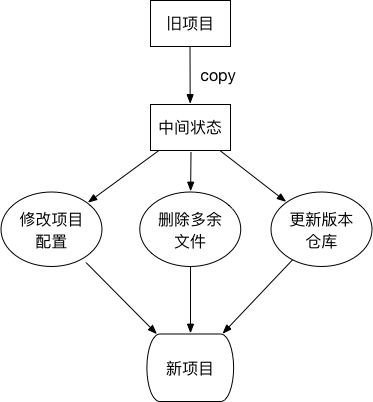
可以看出,传统的初始化步骤,花费的时间并不少。而且,人工操作的情况下,总有改漏的情况出现。这个缺点有时很致命。
甚至有马大哈,没有更新项目仓库地址,导致提交代码到旧仓库,这就很尴尬了。。。
基于这些情况,编写命令行工具(CLI)的目的就很明确:
以下是新的流程示意图:
以下是自动化流程图:
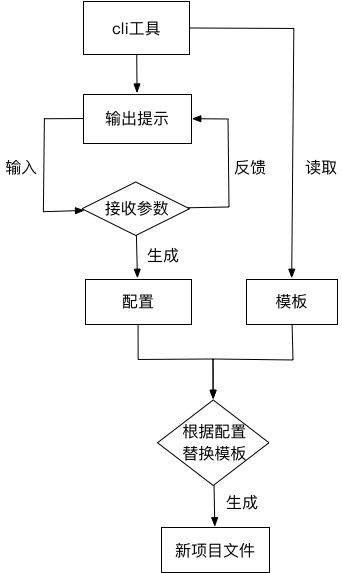
从流程图可以得出两个重要的信息:
命令行工具的角色,是负责将两个信息进行融合,提供一个交互平台给用户。
配置信息的获得,需要靠和用户进行交互。由于程序员一般是用终端输入命令进行项目操作。所以,这里选择了两个工具进行支撑。
借鉴Ruby commander理念实现的命令行执行补全解决方案
commander可以接收命令行传入的参数
例子:
npg-cli --help
♫ ♫♬♪♫ npm-package-cli ♫ ♫♬♪♫
Usage: npg-cli [options]
Options:
-V, --version output the version number
-h, --help output usage information
run testcli and edit the setting.常用交互式命令行用户界面的集合。
inquirer用询问式的语句,与用户进行交互,接收参数
例子:
npg-cli
♫ ♫♬♪♫ npm-package-cli ♫ ♫♬♪♫
Follow the prompts to complete the project configuration.
? project name test
? version 1.0.0
? description前端的JavaScript 模板引擎,比如ejs,jade等。可以根据传入的参数,对模板标签进行替换,最终生成html。
如果把所有项目文件,不管文件后缀名,都看成是ejs模板,则可以在文件内容中使用ejs语法。
再根据配置信息进行替换,最终生成新文件。
其实,业界依据这个想法,已经有成熟的工具产生。
mem-fs是对文件进行读取,存入内存中。
mem-fs-editor是对内存中的文件信息,使用ejs语法进行编译。最后调用commit方法输出最终文件。
提示信息,除了console.log,还可以使用色彩更丰富的chalk。
这样,可以输出更直观、友好的提示。
文件操作,有业界成熟的shelljs。
利用shelljs,可以在项目中简化以下步骤:
shelljs.copySync同步方式生成。shelljs.mkdir进行创建以下按我做的开源项目——npm-package-cli的创作过程进行分拆、讲解。
新建项目文件夹npm-package-cli,并在该文件夹下运行npm init,生成package.json。
项目结构如下:
npm-package-cli
|-- package.json
这里要生成的全局指令是npg-cli。
新建文件夹bin,并在文件夹下新建名称为cli的shell脚本文件(注意:不能有后缀名)。
clishell脚本文件内容如下:
#!/usr/bin/env node
console.log('hello world');其中,#!/usr/bin/env node是告诉编译器,以node的方式,运行代码。
并在package.json加入以下内容:
"bin": {
"npg-cli": "bin/cli"
}
此时,项目结构如下:
npm-package-cli
|-- bin
|-- cli
|-- package.json
链接指令有两种方式:
npm linknpm install -g两种方式,都需要在npm-package-cli文件夹下运行,才能生效。
作用是把npg-cli指令,指向全局的bin文件下,实现软链。
在任意文件夹下运行命令:
npg-cli
# 输出
hello world到这里,一个基本的指令就算完成了,接下来是指令的工作内容细化。
Creation的作用是整合所有操作,并提供接口给指令文件cli。
Creation的结构如下:
class Creation{
constructor(){
// code
}
do(){
// code
}
// other function
}其中do方法暴露给脚本文件cli调用。
Creation类放在src/index.js中。
此时,项目结构如下:
npm-package-cli
|-- bin
|-- cli
|-- src
|-- index.js
|-- package.json
cli文件#!/usr/bin/env node
const Creator = require('../src/index.js');
const project = new Creator();
project.do();
这样,只要实现好do方法,就可以完成npg-cli指令的运行了。
实现npg-cli --help,需要借助上文提到的工具commander。
新建src/command.js文件,文件内容如下:
const commander = require('commander');
const chalk = require('chalk');
const packageJson = require('../package.json');
const log = console.log;
function initCommand(){
commander.version(packageJson.version)
.on('--help', ()=>{
log(chalk.green(' run testcli and edit the setting.'));
})
.parse(process.argv);
}
module.exports = initCommand;此时,项目结构如下:
npm-package-cli
|-- bin
|-- cli
|-- src
|-- command.js
|-- index.js
|-- package.json
然后在Creation.do方法内执行initCommand()即可生效。
// src/index.js Creation
const initCommand = require('./command');
class Creation{
// other code
do(){
initCommand();
}
}此时,运行npg-cli --help指令,就可以看到:
Usage: npg-cli [options]
Options:
-V, --version output the version number
-h, --help output usage information
run testcli and edit the setting.要获取用户输入的信息,需要借助工具inquirer。
新建src/setting.js文件,文件内容如下:
const inquirer = require('inquirer');
const fse = require('fs-extra');
function initSetting(){
let prompt = [
{
type: 'input',
name: 'projectName',
message: 'project name',
validate(input){
if(!input){
return 'project name is required.'
}
if(fse.existsSync(input)){
return 'project name of folder is exist.'
}
return true;
}
},
// other prompt
];
return inquirer.prompt(prompt);
}
module.exports = initSetting;此时,项目结构如下:
npm-package-cli
|-- bin
|-- cli
|-- src
|-- command.js
|-- index.js
|-- setting.js
|-- package.json
然后在Creation.do方法内执行initSetting()即可生效。
// src/index.js Creation
const initCommand = require('./command');
const initSetting = require('./setting');
class Creation{
// other code
do(){
initCommand();
initSetting().then(setting => {
// 用户输入完成后,会得到全部输入信息的json数据 setting
});
}
}这里,inquirer.prompt方法装载好要收集的问题后,返回的是Promise对象。收集完成之后,要在then方法内拿到配置信息,以便进行下一步模板替换的操作。
模板文件替换,要用到工具mem-fs和mem-fs-editor。
文件操作,要用到工具shelljs。
新建src/output.js文件,文件内容如下(删除了部分代码,以下只是示例,完整项目看最后分享链接):
const chalk = require('chalk');
const fse = require('fs-extra');
const path = require('path');
const log = console.log;
function output(creation){
return new Promise((resolve, reject)=>{
// 拿到配置信息
const setting = creation._setting;
const {
projectName
} = setting;
// 获取当前命令行执行环境所在文件夹
const cwd = process.cwd();
// 初始化文件夹path
const projectPath = path.join(cwd, projectName);
const projectResolve = getProjectResolve(projectPath);
// 新建项目文件夹
fse.mkdirSync(projectPath);
// copy文件夹
creation.copy('src', projectResolve('src'));
// 根据配置信息,替换文件内容
creation.copyTpl('package.json', projectResolve('package.json'), setting);
// 将内存中的文件,输出到硬盘上
creation._mfs.commit(() => {
resolve();
});
});
}
module.exports = output;output方法的作用:
mem-fs-editor的copyTpl方法)这里最重要的一步,是调用mem-fs-editor的方法后,要执行mem-fs-editor的commit方法,输出内存中的文件到硬盘上。
在Creation.do方法中,调用output方法即可输出新项目文件。
打开src/index.js文件,文件内容增加如下方法:
// src/index.js Creation
const initCommand = require('./command');
const initSetting = require('./setting');
const output = require('./output');
class Creation{
// other code
do(){
initCommand();
initSetting().then(setting => {
// 用户输入完成后,会得到全部输入信息的json数据 setting
this._setting = Object.assign({}, this._setting, setting);
// 输出文件
output(this).then(res => {
// 项目输出完成
});
});
}
}自动初始化一个项目的流程不外乎以下三点:
命令行工具,是对这三点的有效整合,串连成一个规范的流程。
命令行工具中,使用的第三方工具包,都需要用--save的方式安装。
体现在package.json的表现是dependencies字段:
"dependencies": {
"chalk": "^2.4.2",
"commander": "^3.0.0",
"fs-extra": "^8.1.0",
"inquirer": "^6.5.0",
"mem-fs": "^1.1.3",
"mem-fs-editor": "^6.0.0",
"shelljs": "^0.8.3"
},这样,其他用户在安装你发布的CLI工具时,才会自动安装这些依赖。
.gitignore文件npm官方是默认去除.gitignore文件的,不管你用任何方式声明.gitignore文件需要publish。
解决方式是:将.gitignore改名称,比如改为gitignore。当使用CLI工具时,再将文件名改回来。
例子:
creation.copy('gitignore', projectResolve('.gitignore'));我创作的npm-package-cli,是专门用于生成个人npm package项目的CLI工具。
生成的项目,囊括以下功能点:
coverageCHANGELOG.mdCLI工具安装方式:
npm install -g npm-package-cli开源仓库地址:https://github.com/wall-wxk/npm-package-cli
如果对你有所帮助,麻烦给个Star,你的肯定是我前进的动力~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.