基于hadoop集群中所有节点使用一致性的配置文件考虑,构建支持RWM(ReadWriteMany)的PVC挂载到POD中用来存放hadoop的配置文件(配置文件在POD之间共享)
hadoop的主从节点均采用StatefulSet进行部署,保证稳定的网络环境,各POD启动后,根据网络环境动态修改配置文件内容
启动hadoop集群时,各个节点POD分别启动对应的启动进程,替代传统hadoop集群在namenode上运行start-all.sh脚本(该脚本依赖ssh),方便scale进行扩缩节点数量。
镜像的构建基于父镜像centos7.5,jdk版本为1.8,hadoop版本为2.9.2,镜像采用阿里云的yum源
k8s支持的Volume插件的存取模式需要支持ReadWriteMany,这里采用NFS
| Volume Plugin | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| HostPath | √ | - | - |
| NFS | √ | √ | √ |
- 创建PVC
使用NFS存放配置文件在POD间共享
- 启动脚本和配置文件
配置文件采用ConfigMap来存放,启动脚本bootstrap.sh
启动脚本bootstrap.sh可以通过NFS挂载在POD目录里,也可以直接构建在容器里,这里采用挂载方式
配置文件的内容在POD启动并执行bootstrap.sh脚本,首先覆盖原始配置文件,然后根据节点类型和网络地址修改配置文件内容
节点类型通过环境变量配置,包括:NN(NameNode)、DN(DataNode)、RM(ResourceManager)、NM(NodeManager)。bootstrap.sh将根据不同的节点类型启动不同的进程,这里hdfs跟yarn在一起部署
- 创建NameNode
挂载共享目录hadoop-config-nfs-pvc
使用statefulset进行部署,statefulset使用haedless-service确保POD基本稳定的网络ID
通过环境变量设置NODE_TYPE,这里NameNode跟ResourceManager运行在同一个容器中
这里的数据存储采用volumeClaimTemplates。可改进空间:能采用DaemonSet部署,网络状态固定,可以在对应的节点挂载磁盘,使用HostPath来映射存储,更符合hadoop的分布式
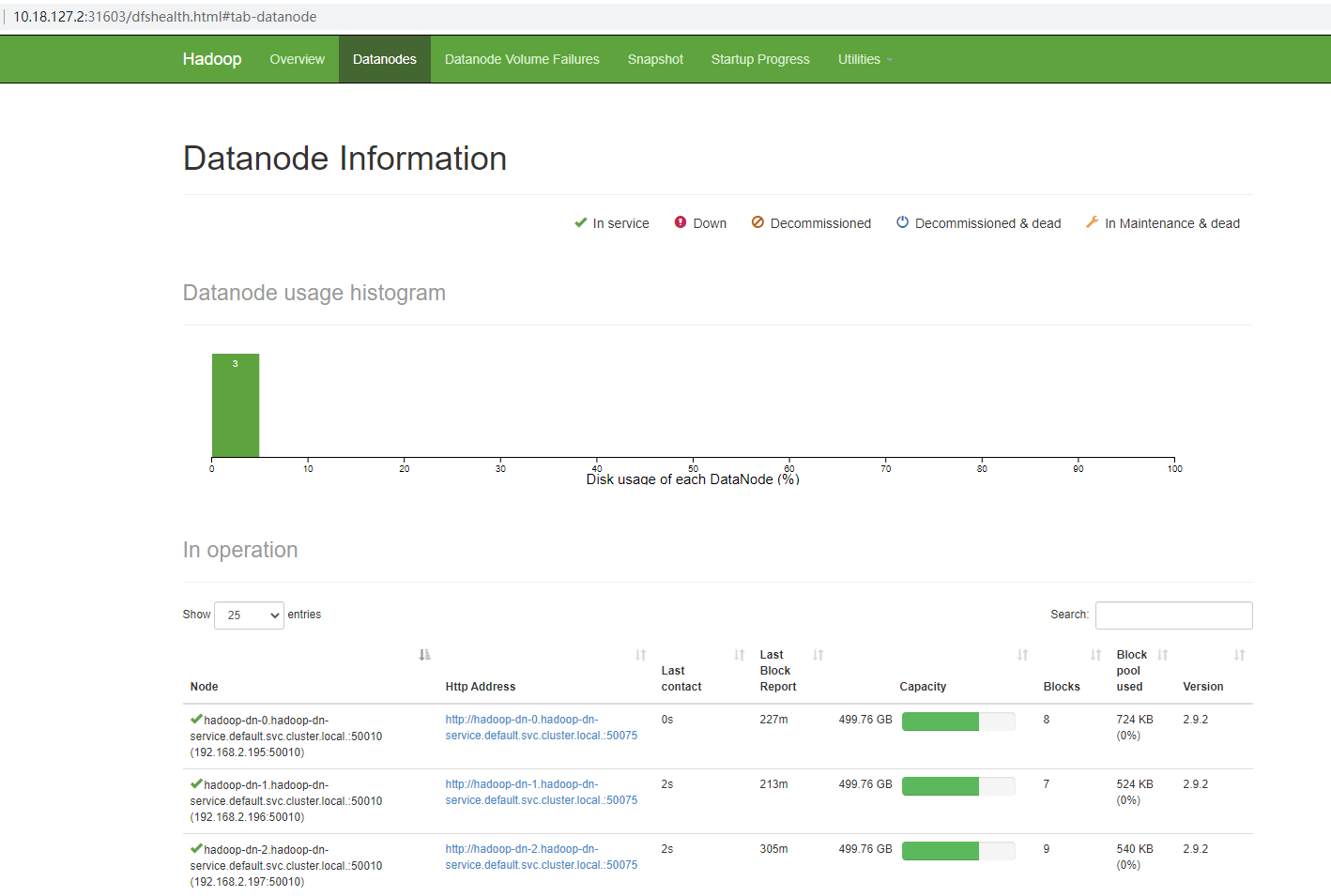
- 创建DataNode
挂载共享目录hadoop-config-nfs-pvc
NODE_TYPE设置为DN,NM,表示DataNode和NodeManager运行在同一个容器中
设置replicas为3,hadoop集群启动后会有三个数据节点
- 创建Web UI Service
这里采用NodePort暴露hdfs和yarn的web访问服务
kubectl get svc
kubectl get sts
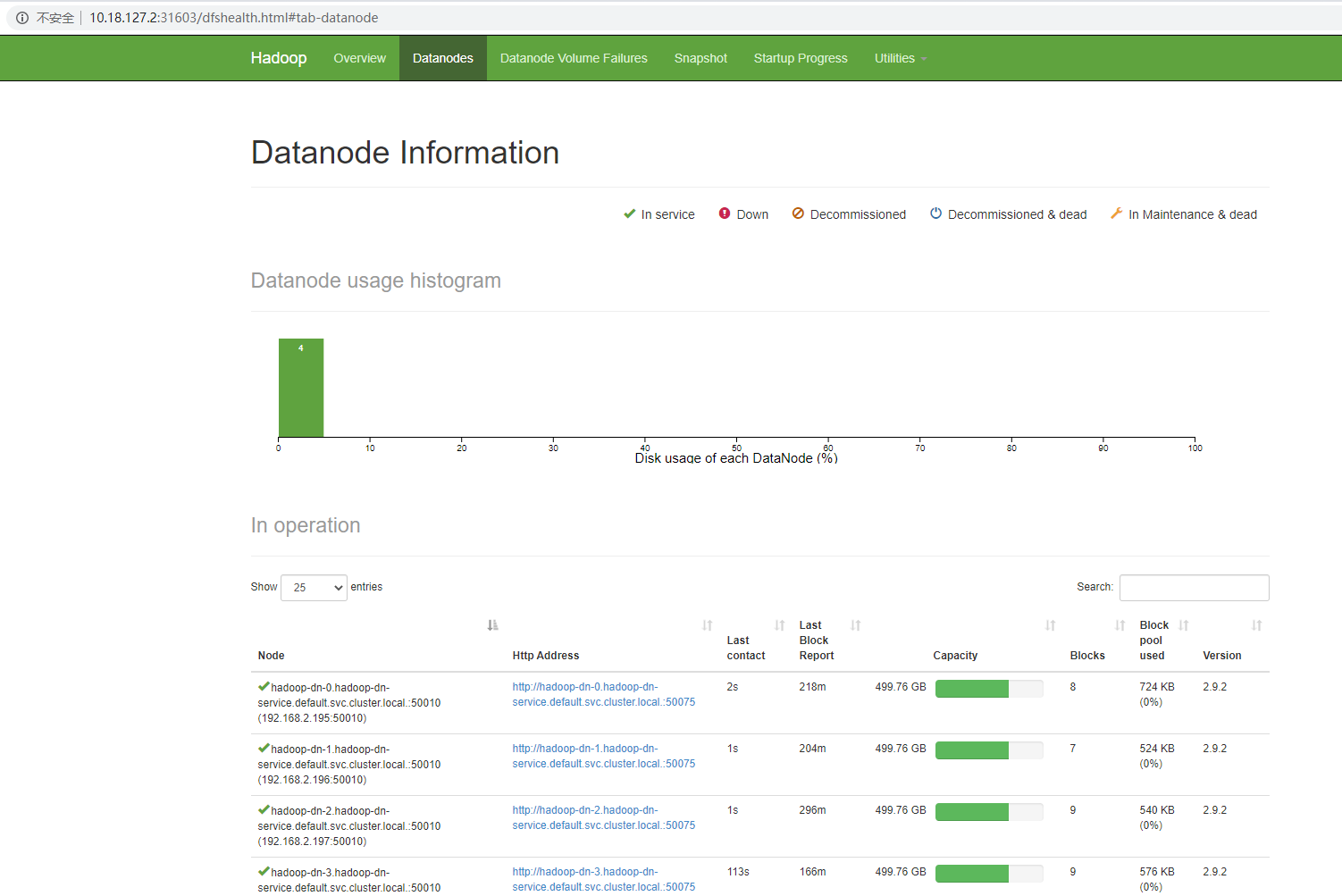
kubectl scale sts hadoop-dn --replicas=4
kubectl get sts效果