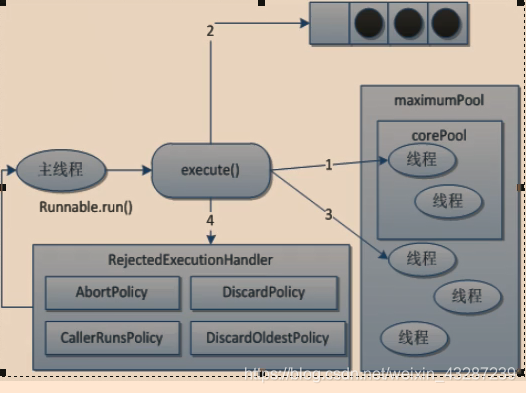
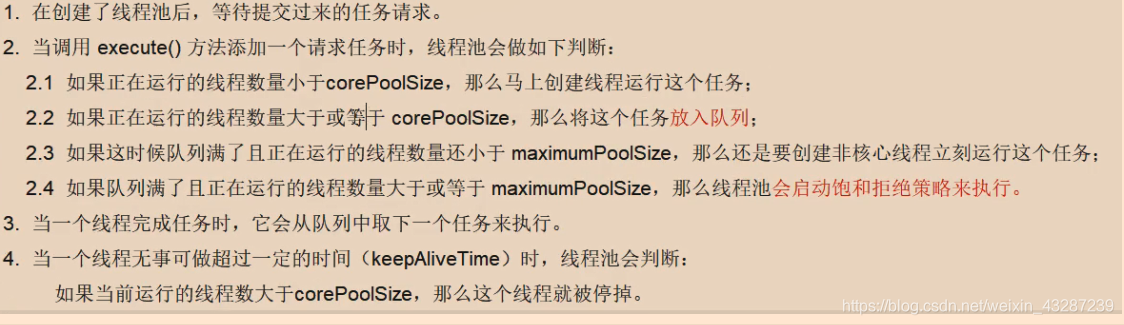
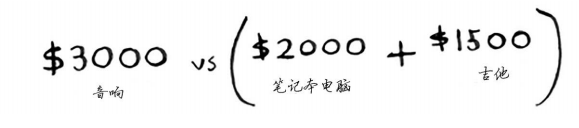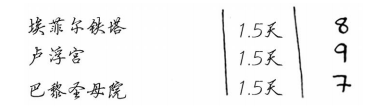wendaoit / fangwangye404 Goto Github PK
View Code? Open in Web Editor NEW备份我平时博客参考的网址,防止🛸🛸🛸
License: Boost Software License 1.0
备份我平时博客参考的网址,防止🛸🛸🛸
License: Boost Software License 1.0



在百度知道上发现了一个绝对很 nice 的回答
对 epoll 的解释很清晰到位,这里转载下
如侵立删
作者为(dsuwlzon )
原文如下 (本文为了方便阅读重新进行了排版)
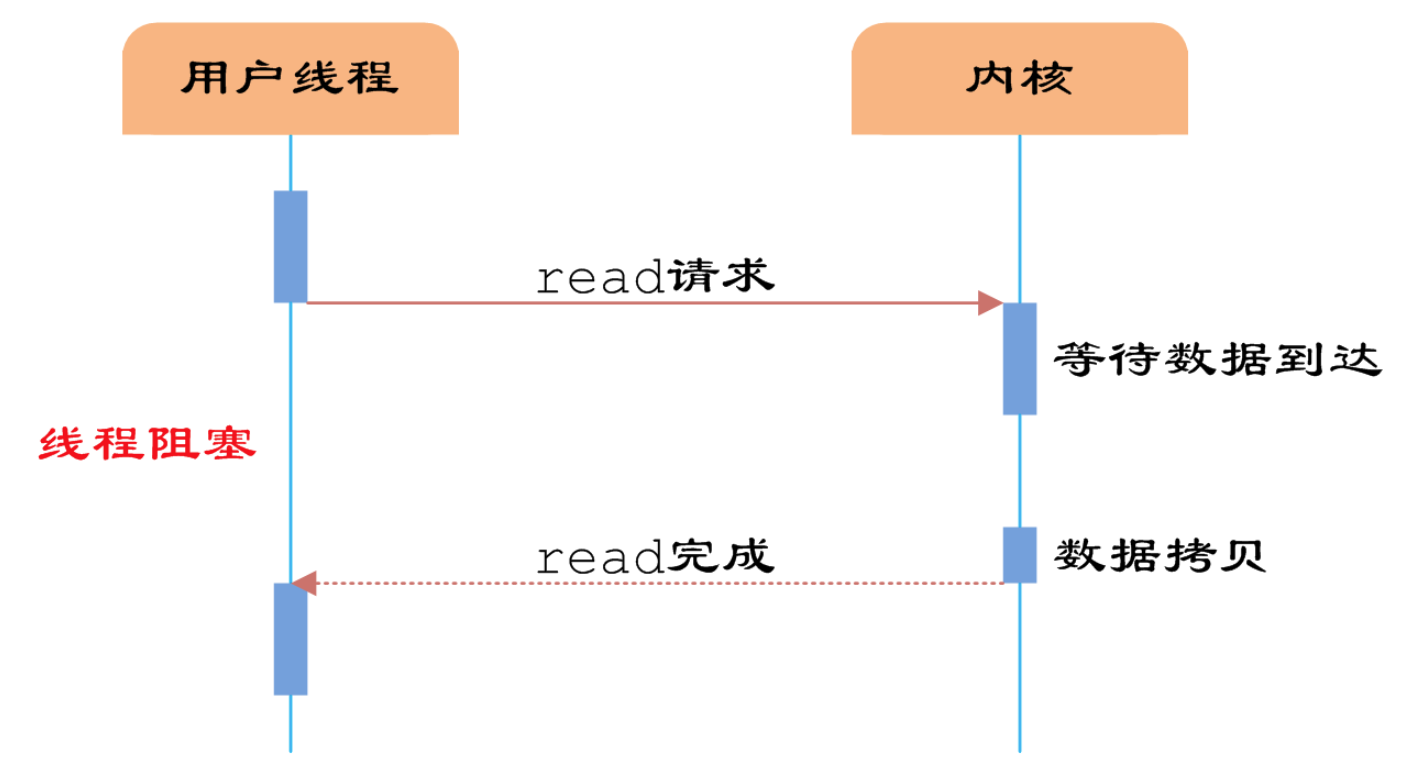
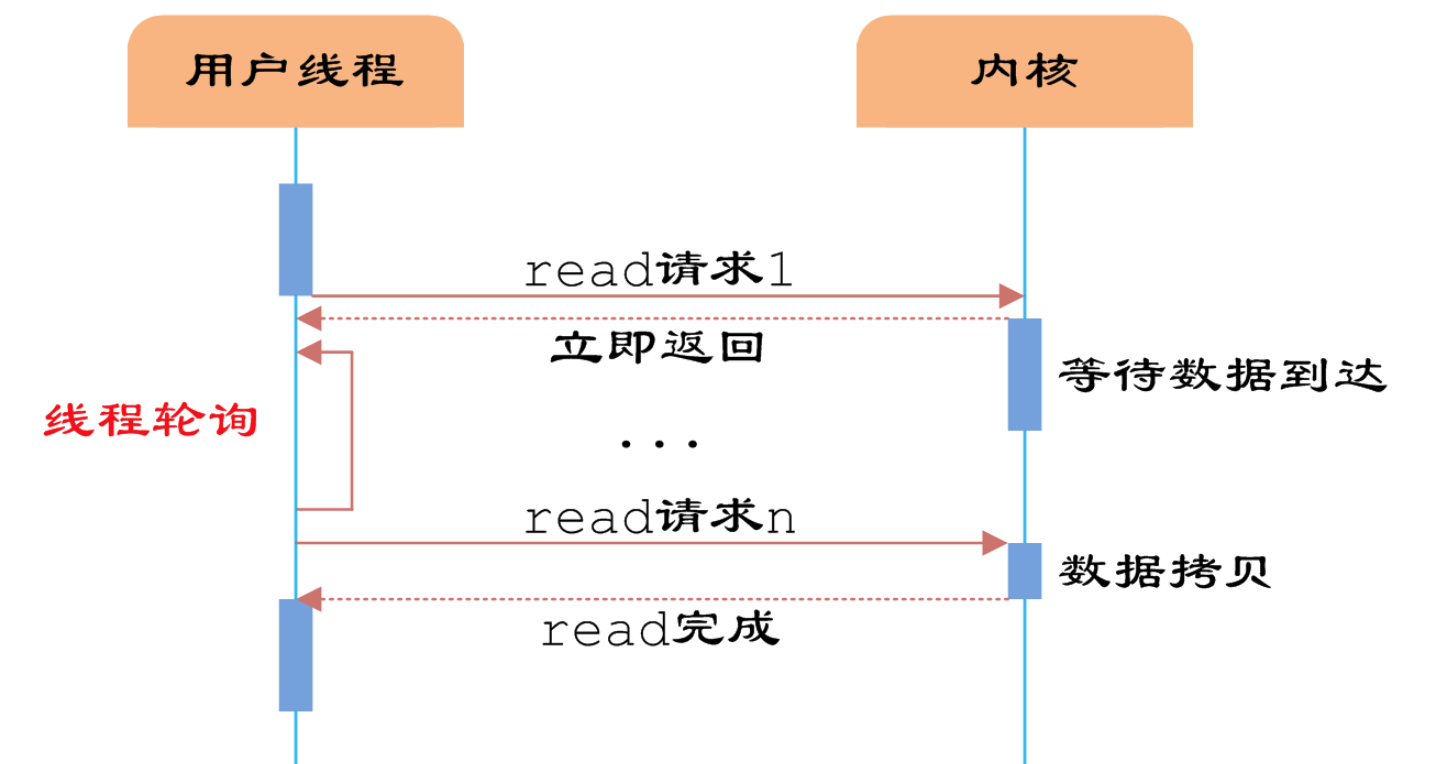
假设你在大学中读书,要等待一个朋友来访,而这个朋友只知道你在 A 号楼,但是不知道你具体住在哪里,于是你们约好了在 A 号楼门口见面.
如果你使用的阻塞 IO 模型来处理这个问题,那么你就只能一直守候在 A 号楼门口等待朋友的到来,在这段时间里你不能做别的事情,不难知道,这种方式的效率是低下的.
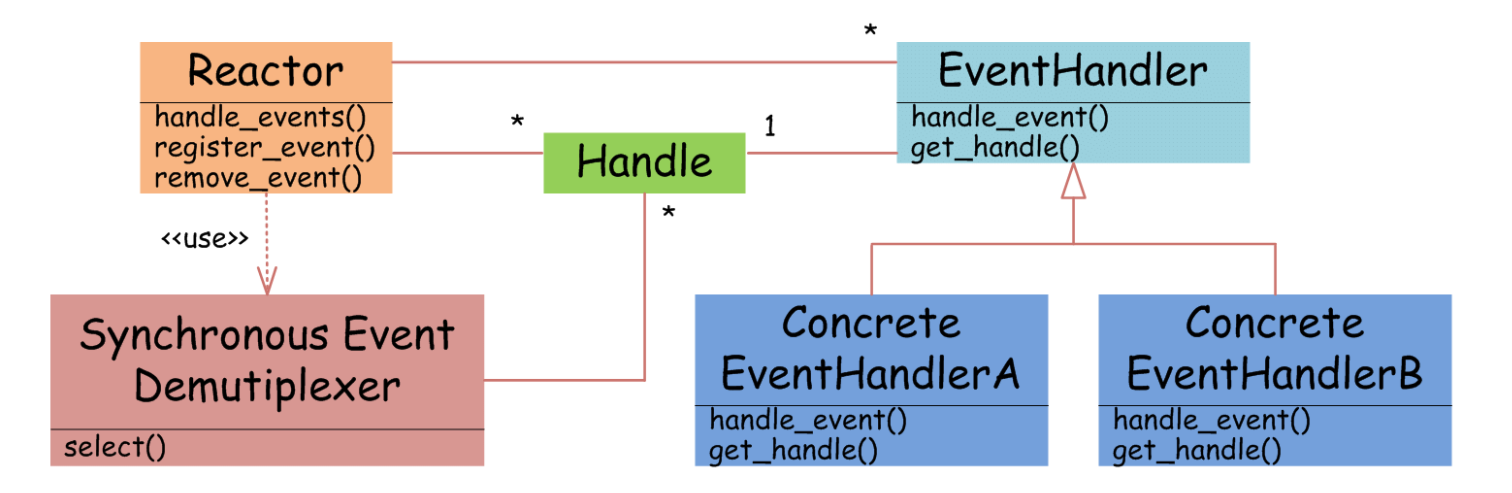
进一步解释 select 和 epoll 模型的差异.
select 版大妈做的是如下的事情:比如同学甲的朋友来了,select 版大妈比较笨,她带着朋友挨个房间进行查询谁是同学甲,你等的朋友来了,于是在实际的代码中,select 版大妈做的是以下的事情:
int n = select(&readset,NULL,NULL,100);
for (int i = 0; n > 0; ++i) {
if (FD_ISSET(fdarray[i], &readset)) {
do_something(fdarray[i]); --n;
}
}
epoll 版大妈就比较先进了,她记下了同学甲的信息,比如说他的房间号,那么等同学甲的朋友到来时,只需要告诉该朋友同学甲在哪个房间即可,不用自己亲自带着人满大楼的找人了。于是 epoll 版大妈做的事情可以用如下的代码表示:
n = epoll_wait(epfd,events,20,500);
for(i=0;i<n;++i) { do_something(events[n]);
}
在 epoll 中,关键的数据结构 epoll_event 定义如下:
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
}epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data;/* User data variable */
};
可以看到,epoll_data 是一个 union 结构体,它就是 epoll 版大妈用于保存同学信息的结构体,它可以保存很多类型的信息:
fd, 指针,等等。有了这个结构体,epoll 大妈可以不用吹灰之力就可以定位到同学甲.
别小看了这些效率的提高,在一个大规模并发的服务器中,轮询 IO 是最耗时间的操作之一。再回到那个例子中,如果每到来一个朋友楼管大妈都要全楼的查询同学,那么处理的效率必然就低下了,过不久楼底就有不少的人了.
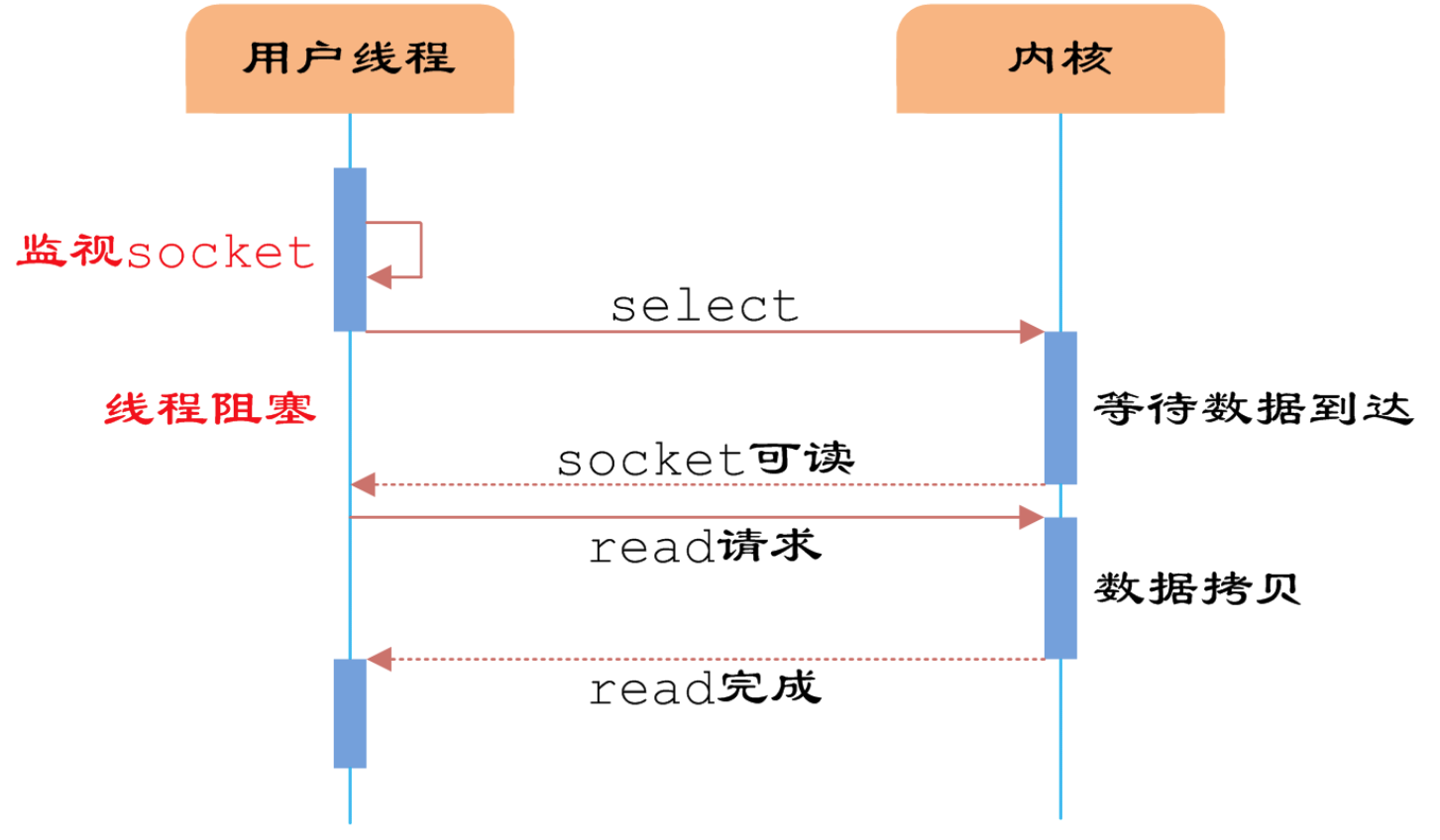
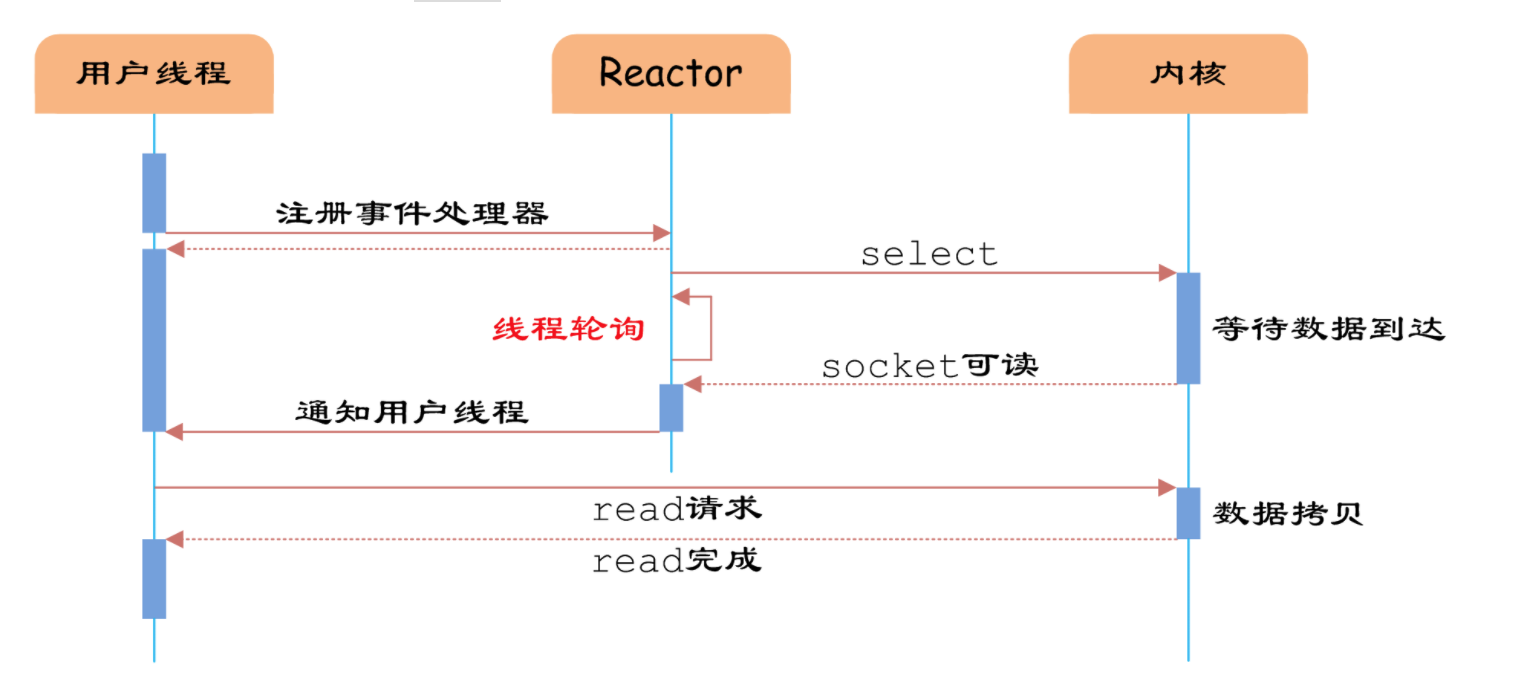
对比最早给出的阻塞 IO 的处理模型,可以看到采用了多路复用 IO 之后,程序可以自由的进行自己除了 IO 操作之外的工作,只有到 IO 状态发生变化的时候由多路复用 IO 进行通知,然后再采取相应的操作,而不用一直阻塞等待 IO 状态发生变化了.
从上面的分析也可以看出,epoll 比 select 的提高实际上是一个用空间换时间**的具体应用.
大家都明白 epoll 是一种 IO 多路复用技术,可以非常高效的处理数以百万计的 socket 句柄,比起以前的 select 和 poll 效率高大发了。
我们用起 epoll 来都感觉挺爽,确实快,那么,它到底为什么可以高速处理这么多并发连接呢?
先简单回顾下如何使用 C 库封装的 3 个 epoll 系统调用吧。
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
使用起来很清晰,首先要调用 epoll_create 建立一个 epoll 对象。参数 size 是内核保证能够正确处理的最大句柄数,多于这个最大数时内核可不保证效果。
epoll_ctl 可以操作上面建立的 epoll,例如,将刚建立的 socket 加入到 epoll 中让其监控,或者把 epoll 正在监控的某个 socket 句柄移出 epoll,不再监控它等等。
epoll_wait 在调用时,在给定的 timeout 时间内,当在监控的所有句柄中有事件发生时,就返回用户态的进程。
从上面的调用方式就可以看到 epoll 比 select/poll 的优越之处:
因为后者每次调用时都要传递你所要监控的所有 socket 给 select/poll 系统调用,这意味着需要将用户态的 socket 列表 copy 到内核态,如果以万计的句柄会导致每次都要 copy 几十几百 KB 的内存到内核态,非常低效。
而我们调用 epoll_wait 时就相当于以往调用 select/poll,但是这时却不用传递 socket 句柄给内核,因为内核已经在 epoll_ctl 中拿到了要监控的句柄列表。
所以,实际上在你调用 epoll_create 后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用 epoll_ctl 只是在往内核的数据结构里塞入新的 socket 句柄。
在内核里,一切皆文件。所以,epoll 向内核注册了一个文件系统,用于存储上述的被监控 socket。
当你调用 epoll_create 时,就会在这个虚拟的 epoll 文件系统里创建一个 file 结点。当然这个 file 不是普通文件,它只服务于 epoll。epoll 在被内核初始化时(操作系统启动),同时会开辟出 epoll 自己的内核高速 cache 区,用于安置每一个我们想监控的 socket,这些 socket 会以红黑树的形式保存在内核 cache 里,以支持快速的查找、插入、删除。
这个内核高速 cache 区,就是建立连续的物理内存页,然后在之上建立 slab 层,简单的说,就是物理上分配好你想要的 size 的内存对象,每次使用时都是使用空闲的已分配好的对象。
static int __init eventpoll_init(void) {
... ...
/* Allocates slab cache used to allocate "struct epitem" items */
epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),0,SLAB_HWCACHE_ALIGN| EPI_SLAB_DEBUG|SLAB_PANIC, NULL, NULL);
/* Allocates slab cache used to allocate "struct eppoll_entry" */
pwq_cache = kmem_cache_create("eventpoll_pwq", sizeof(struct eppoll_entry), 0, EPI_SLAB_DEBUG|SLAB_PANIC, NULL, NULL);
... ...
epoll 的高效就在于,当我们调用 epoll_ctl 往里塞入百万个句柄时,epoll_wait 仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。
这是由于我们在调用 epoll_create 时,内核除了帮我们在 epoll 文件系统里建了个 file 结点,在内核 cache 里建了个红黑树用于存储以后 epoll_ctl 传来的 socket 外,还会再建立一个 list 链表,用于存储准备就绪的事件,当 epoll_wait 调用时,仅仅观察这个 list 链表里有没有数据即可。有数据就返回,没有数据就 sleep,等到 timeout 时间到后即使链表没数据也返回。所以,epoll_wait 非常高效。
那么,这个准备就绪 list 链表是怎么维护的呢?当我们执行 epoll_ctl 时,除了把 socket 放到 epoll 文件系统里 file 对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪 list 链表里。
所以,当一个 socket 上有数据到了,内核在把网卡上的数据 copy 到内核中后就来把 socket 插入到准备就绪链表里了。
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核 cache,就帮我们解决了大并发下的 socket 处理问题。
执行 epoll_create 时,创建了红黑树和就绪链表,执行 epoll_ctl 时,如果增加 socket 句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行 epoll_wait 时立刻返回准备就绪链表里的数据即可。
最后看看 epoll 独有的两种模式 LT 和 ET。无论是 LT 和 ET 模式,都适用于以上所说的流程。
区别是,LT 模式下,只要一个句柄上的事件一次没有处理完,会在以后调用 epoll_wait 时次次返回这个句柄,而 ET 模式仅在第一次返回。
这件事怎么做到的呢?当一个 socket 句柄上有事件时,内核会把该句柄插入上面所说的准备就绪 list 链表,这时我们调用 epoll_wait,会把准备就绪的 socket 拷贝到用户态内存,然后清空准备就绪 list 链表,最后,epoll_wait 干了件事,就是检查这些 socket,如果不是 ET 模式(就是 LT 模式的句柄了),并且这些 socket 上确实有未处理的事件时,又把该句柄放回到刚刚清空的准备就绪链表了。
所以,非 ET 的句柄,只要它上面还有事件,epoll_wait 每次都会返回。而 ET 模式的句柄,除非有新中断到,即使 socket 上的事件没有处理完,也是不会次次从 epoll_wait 返回的。
Linux 提供了 select、poll、epoll 接口来实现 IO 复用,三者的原型如下所示,本文从参数、实现、性能等方面对三者进行对比。
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
select、poll、epoll_wait 参数及实现对比
本系列主要分五部分:
1.《WEB 请求处理一:浏览器请求发起处理》:分析用户在浏览器中输入 URL 地址,浏览器如何找到服务器地址的过程,并发起请求;
2.《WEB 请求处理二:Nginx 请求反向代理》:分析请求在达反向代理服务器内部处理过程;
3.《WEB 请求处理三:Servlet 容器请求处理》:分析请求在 Servlet 容器内部处理过程,并找到目标应用程序;
4.《WEB 请求处理四:WEB MVC 框架请求处理》:分析请求在应用程序内部,开源 MVC 框架的处理过程;
5.《WEB 请求处理五:浏览器请求响应处理》:分析请求在服务器端处理完成后,浏览器渲染响应页面过程;
为直观明了,先上一张图,红色部分为本章所述模块:
本章所述模块
我们先了解下 B/S 网络架构是什么?B/S 网络架构从前端到后端都得到了简化,都基于统一的应用层协议 HTTP 来交互数据,HTTP 协议采用无状态的短链接的通信方式,通常情况下,一次请求就完成了一次数据交互,通常也对应一个业务逻辑,然后这次通信连接就断开了。采用这种方式是为了能够同时服务更多的用户,因为当前互联网应用每天都会处理上亿的用户请求,不可能每个用户访问一次后就一直保持住这个连接。
当一个用户在浏览器里输入 www.google.com 这个 URL 时,将会发生如下操作:
- 首先,浏览器会请求 DNS 把这个域名解析成对应的 IP 地址;
- 然后,根据这个 IP 地址在互联网上找到对应的服务器,建立 Socket 连接,向这个服务器发起一个 HTTP Get 请求,由这个服务器决定返回默认的数据资源给访问的用户;
- 在服务器端实际上还有复杂的业务逻辑:服务器可能有多台,到底指定哪台服务器处理请求,这需要一个负载均衡设备来平均分配所有用户的请求;
- 还有请求的数据是存储在分布式缓存里还是一个静态文件中,或是在数据库里;
- 当数据返回浏览器时,浏览器解析数据发现还有一些静态资源(如:css,js 或者图片)时又会发起另外的 HTTP 请求,而这些请求可能会在 CDN 上,那么 CDN 服务器又会处理这个用户的请求;
以上具体流程,如图所示:
以上具体流程,如图所示
不管网络架构如何变化,但是始终有一些固定不变的原则需要遵守:
- 互联网上所有资源都要用一个 URL 来表示。URL 就是统一资源定位符;
- 必须基于 HTTP 协议与服务端交互;
- 数据展示必须在浏览器中进行;
B/S 网络架构的核心是 HTTP 协议,最重要的就是要熟悉 HTTP 协议中的 HTTP Header,HTTP Header 控制着互联网上成千上万的用户的数据传输。最关键的是,它控制着用户浏览器的渲染行为和服务器的执行逻辑。
常见的 HTTP 请求头:
常见的 HTTP 请求头
常见的 HTTP 响应头:
常见的 HTTP 响应头
常见的 HTTP 状态码:
常见的 HTTP 状态码
当我们使用 Ctrl+F5 组合键刷新一个页面时,首先是在浏览器端,会直接向目标 URL 发送请求,而不会使用浏览器缓存的数据;其次即使请求发送到服务端,也有可能访问到的是缓存的数据。所以在 HTTP 的请求头中会增加一些请求头,它告诉服务端我们要获取最新的数据而非缓存。最重要的是在请求 Head 中增加了两个请求项 Pragma:no-cache 和 Cache-Control:no-cache。
这个 HTTP Head 字段**用于指定所有缓存机制在整个请求 / 响应链中必须服从的指令,如果知道该页面是否为缓存,不仅可以控制浏览器,还可以控制和 HTTP 协议相关的缓存或代理服务器**。
Cache-Control/Pragma 字段的可选值:
Cache-Control/Pragma 字段的可选值
Cache-Control 请求字段被各个浏览器支持的较好,而且它的优先级也比较高,它和其他一些请求字段(如 Expires)同时出现时,Cache-Control 会覆盖其他字段。
Pragma 字段的作用和 Cache-Control 有点类似,它也是在 HTTP 头中包含一个特殊的指令,使相关的服务器来遵守,最常用的就是 Pragma:no-cache,它和 Cache-Control:no-cache 的作用是一样的。
Expires 通常的使用格式是 Expires:Sat,25 Feb 2012 12:22:17 GMT,后面跟着一个日期和时间,超过这个值后,缓存的内容将失效,也就是**浏览器在发出请求之前检查这个页面的这个字段,看该页面是否已经过期了,过期了将重新向服务器发起请求**。
Last-Modified 字段一般用于表示一个服务器上的字段的最后修改时间,资源可以是静态(静态内容自动加上 Last-Modified)或者动态的内容(如 Servlet 提供了一个 getLastModified 方法用于检查某个动态内容是否已经更新),通过这个最后修改时间可以判断当前请求的资源是否是最新的。
一般服务器端在响应头中返回一个 Last-Modified 字段,告诉浏览器这个页面的最后修改时间,如:Sat,25 Feb 2012 12:55:04 GMT,浏览器再次请求时在请求头中增加一个 If-Modified-Since:Sat,25 Feb 2012 12:55:04 GMT 字段,询问当前缓存的页面是否是最新的,如果是最新的就会返回 304 状态码,告诉浏览器是最新的,服务器也不会传输新的数据。
与 Last-Modified 字段有类似功能的还有一个 Etag 字段,这个字段的作用是让服务端给每个页面分配一个唯一编号,然后通过这个编号来区分当前这个页面是否是最新的。这种方式比使用 Last-Modified 更加灵活,但是在后端的 Web 服务器有多台时比较难处理,因为每个 Web 服务器都要记住网站的所有资源编号,否则浏览器返回这个编号就没有意义了。
对于正常的上网过程,系统其实是这样做的:
浏览器本身是一个客户端,当你输入 URL 的时候,
首先浏览器会去请求 DNS 服务器,通过 DNS 获取相应的域名对应的 IP,然后通过 IP 地址找到 IP 对应的服务器后,要求建立 TCP 连接,等浏览器发送完 HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回 HTTP Response(响应)包;客户端收到来自服务器的响应后开始渲染这个 Response 包里的主体(body),等收到全部的内容随后断开与该服务器之间的 TCP 连接。
Web 请求的工作原理
Web 请求的工作原理可以简单地归纳为:
- 浏览器通过 DNS 域名解析到服务器 IP;
- 客户机通过 TCP/IP 协议建立到服务器的 TCP 连接;
- 客户端向服务器发送 HTTP 协议请求包,请求服务器里的资源文档;
- 服务器向客户机发送 HTTP 协议应答包,如果请求的资源包含有动态语言的内容,那么服务器会调用动态语言的解释引擎负责处理 “动态内容”,并将处理得到的数据返回给客户端;
- 客户机与服务器断开。由客户端解释 HTML 文档,在客户端屏幕上渲染图形结果;
一个简单的 HTTP 事务就是这样实现的,看起来很复杂,原理其实是挺简单的。需要注意的是客户机与服务器之间的通信是非持久连接的,也就是当服务器发送了应答后就与客户机断开连接,等待下一次请求。
当用户在浏览器中输入域名,如:www.google.com,并按下回车后,DNS 解析过程大体如下:
DNS 解析过程
浏览器会首先搜索浏览器自身的 DNS 缓存(缓存时间比较短,大概只有 1 分钟,且只能容纳 1000 条缓存),看自身的缓存中是否有 www.google.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
浏览器缓存域名也是有限制的,不仅浏览器缓存大小有限制,而且缓存的时间也有限制,通常情况下为几分钟到几小时不等,域名被缓存的时间限制可以通过 TTL 属性来设置。这个缓存时间太长和太短都不好,如果缓存时间太长,一旦域名被解析到的 IP 有变化,会导致被客户端缓存的域名无法解析到变化后的 IP 地址,以致该域名不能正常解析,这段时间内有可能会有一部分用户无法访问网站。如果时间设置太短,会导致用户每次访问网站都要重新解析一次域名。
注:我们怎么查看 Chrome 自身的缓存?可以使用 chrome://net-internals/#dns 来进行查看
查看 Chrome 自身的 DNS 缓存
如果浏览器自身的缓存里面没有找到对应的条目,其实操作系统也会有一个域名解析的过程,那么 Chrome 会首先搜索操作系统自身的 DNS 缓存中是否有这个域名对应的 DNS 解析结果,如果找到且没有过期则停止搜索解析到此结束。
其次在 Linux 中可以通过 / etc/hosts 文件来设置,你可以将任何域名解析到任何能够访问的 IP 地址。如果你在这里指定了一个域名对应的 IP 地址,那么浏览器会首先使用这个 IP 地址。当解析到这个配置文件中的某个域名时,操作系统会在缓存中缓存这个解析结果,缓存的时间同样是受这个域名的失效时间和缓存的空间大小控制的。
如果在 hosts 文件中也没有找到对应的条目,浏览器就会发起一个 DNS 的系统调用,就会向本地配置的首选 DNS 服务器(LDNS 一般是电信运营商提供的,也可以使用像 Google 提供的 DNS 服务器)发起域名解析请求(通过的是 UDP 协议向 DNS 的 53 端口发起请求,这个请求是递归的请求,也就是运营商的 DNS 服务器必须得提供给我们该域名的 IP 地址)。
在我们的网络配置中都会有 “DNS 服务器地址” 这一项,这个地址就用于解决前面所说的如果两个过程无法解析时要怎么办,操作系统会把这个域名发送给这里设置的 LDNS,也就是本地区的域名服务器。这个 DNS 通常都提供给你本地互联网接入的一个 DNS 解析服务,例如你是在学校接入互联网,那么你的 DNS 服务器肯定在你的学校,如果你是在一个小区接入互联网的,那这个 DNS 就是提供给你接入互联网的应用提供商,即电信或者联通,也就是通常所说的 SPA,那么这个 DNS 通常也会在你所在城市的某个角落,通常不会很远。这个专门的域名解析服务器性能都会很好,它们一般都会缓存域名解析结果,当然缓存时间是受域名的失效时间控制的,一般缓存空间不是影响域名失效的主要因素。大约 80% 的域名解析都到这里就已经完成了,所以 LDNS 主要承担了域名的解析工作。
运营商的 DNS 服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。
运营商的 DNS 服务器
如果 LDNS 没有找到对应的条目,则由运营商的 DNS 代我们的浏览器发起迭代 DNS 解析请求。它首先是会找根域的 DNS 的 IP 地址(这个 DNS 服务器都内置 13 台根域的 DNS 的 IP 地址),找到根域的 DNS 地址,就会向其发起请求(请问 www.google.com 这个域名的 IP 地址是多少啊?)。
根域发现这是一个顶级域 com 域的一个域名,于是就告诉运营商的 DNS 我不知道这个域名的 IP 地址,但是我知道 com 域的 IP 地址,你去找它去。
于是运营商的 DNS 就得到了 com 域的 IP 地址,又向 com 域的 IP 地址发起了请求(请问 www.google.com 这个域名的 IP 地址是多少?),com 域这台服务器告诉运营商的 DNS 我不知道 www.google.com 这个域名的 IP 地址,但是我知道 google.com 这个域的 DNS 地址,你去找它去。
于是运营商的 DNS 又向 google.com 这个域名的 DNS 地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问 www.google.com 这个域名的 IP 地址是多少?),这个时候 google.com 域的 DNS 服务器一查,果真在我这里,于是就把找到的结果发送给运营商的 DNS 服务器,这个时候运营商的 DNS 服务器就拿到了 www.google.com 这个域名对应的 IP 地址。
通过上面的步骤,我们最后获取的是 IP 地址,也就是浏览器最后发起请求的时候是基于 IP 来和服务器做信息交互的。在实际的 DNS 解析过程中,可能还不止这 10 个步骤,如 Name Server 也可能有多级,或者有一个 GTM 来负载均衡控制,这都有可能会影响域名解析的过程。根据以上解析流程,DNS 解析整个过程,分为:递归查询过程和迭代查询过程。如图所示:
DNS 解析整个过程
所谓 递归查询过程 就是 “查询的递交者” 更替, 而 迭代查询过程 则是 “查询的递交者” 不变。
举个例子来说,你想知道某个一起上法律课的女孩的电话,并且你偷偷拍了她的照片,回到寝室告诉一个很仗义的哥们儿,这个哥们儿二话没说,拍着胸脯告诉你,甭急,我替你查 (
此处完成了一次递归查询,即,问询者的角色更替)。然后他拿着照片问了学院大四学长,学长告诉他,这姑娘是 xx 系的;然后这哥们儿马不停蹄又问了 xx 系的办公室主任助理同学,助理同学说是 xx 系 yy 班的,然后很仗义的哥们儿去 xx 系 yy 班的班长那里取到了该女孩儿电话。(此处完成若干次迭代查询,即,问询者角色不变,但反复更替问询对象) 最后,他把号码交到了你手里。完成整个查询过程。
在 Linux 系统中还可以**使用 dig 命名来查询 DNS 的解析过程,如下所示:dig +cmd +trace www.google.com**
使用 dig 命名来查询 DNS 的解析过程
上面清楚地显示了整个域名是如何发起和解析的,从根域名 (.) 到 gTLD Server(.com.)再到 Name Server (google.com.)的整个过程都显示出来了。还可以看出 DNS 的服务器有多个备份,可以从任何一台查询到解析结果。
我们知道 DNS 域名解析后会缓存解析结果,其中主要在两个地方缓存结果,一个是 Local DNS Server,另外一个是用户的本地机器。这两个缓存都是 TTL 值和本机缓存大小控制的,但是最大缓存时间是 TTL 值,基本上 Local DNS Server 的缓存时间就是 TTL 控制的,很难人工介入,但是我们的本机缓存可以通过如下方式清除。
在 Linux 下可以通过 /etc/init.d/nscd restart 来清除 DNS 缓存。如下:
在 Linux 下清除 DNS 缓存
JVM 缓存 DNS 解析结果:
在 Java 应用中 JVM 也会缓存 DNS 的解析结果,这个缓存是在 InetAddress 类中完成的,而且这个缓存时间还比较特殊,它有两种缓存策略:一种是正确解析结果缓存,另一种是失败的解析结果缓存。这两个缓存时间由两个配置项控制,配置项是在 % JAVA_ HOME%\lib\security\java.security 文件中配置的。两个配置项分别是 networkaddress.cache.ttl 和 networkaddress.cache.negative.ttl,它们的默认值分别是 - 1(永不失效)和 10(缓存 10 秒)。
要修改这两个值同样有几种方式,分别是:直接修改 java.security 文件中的默认值、在 Java 的启动参数中增加 - Dsun.net.inetaddr.ttl=xxx 来修改默认值、通过 InetAddress 类动态修改。
在这里还要特别强调一下,如果我们需要用 InetAddress 类解析域名时,一定要是单例模式,不然会有严重的性能问题,如果每次都创建 InetAddress 实例,每次都要进行一次完整的域名解析,非常耗时,这点要特别注意。
如将 item.taobao.com 指定到 115.238.23.241,将 switch.taobao.com 指定到 121.14.24.241。A 记录可以将多个域名解析到一个 IP 地址,但是不能将一个域名解析到多个 IP 地址。
如 taobao.com 域名的 A 记录 IP 地址是 115.238.25.245,如果 MX 记录设置为 115.238.25.246,是 [email protected] 的邮件路由,DNS 会将邮件发送到 115.238.25.246 所在的服务器,而正常通过 Web 请求的话仍然解析到 A 记录的 IP 地址。
如将 taobao.com 解析到 xulingbo.net,将 srcfan.com 也解析到 xulingbo.net,其中 xulingbo.net 分别是 taobao.com 和 srcfan.com 的别名。前面的跟踪域名解析中的 “www.taobao.com. 1542 IN CNAME www.gslb.taobao.com” 就是 CNAME 解析。
前面的 “google.com. 172800 IN NS ns4.google.com.” 就是 NS 解析。
如可以为 google.com 设置 TXT 记录为 “谷歌 | **” 这样的说明。
Linux 虚拟机测试,使用命令 wget www.linux178.com 来请求,发现直接使用 chrome 浏览器请求时,干扰请求比较多,所以就使用 wget 命令来请求,不过使用 wget 命令只能把 index.html 请求回来,并不会对 index.html 中包含的静态资源(js、css 等文件)进行请求。
抓包截图如下:
抓包截图
1 号包,这个是那台虚拟机在广播,要获取 192.168.100.254(也就是网关)的 MAC 地址,
因为局域网的通信靠的是 MAC 地址,它为什么需要跟网关进行通信是因为我们的 DNS 服务器 IP 是外围 IP,要出去必须要依靠网关帮我们出去才行。2 号包,这个是网关收到了虚拟机的广播之后,
回应给虚拟机的回应,告诉虚拟机自己的 MAC 地址,于是客户端找到了路由出口。3 号包,这个包是 wget 命令向系统配置的 DNS 服务器提出域名解析请求(准确的说应该是 wget 发起了一个 DNS 解析的系统调用),请求的域名 www.linux178.com,
期望得到的是 IP6 的地址(AAAA 代表的是 IPv6 地址)。4 号包,这个 DNS 服务器给系统的响应,很显然目前使用 IPv6 的还是极少数,所以得不到 AAAA 记录的。
5&6 号包,这个还是请求解析 IPv6 地址,但是 www.linux178.com.leo.com 这个主机名是不存在的,所以得到结果就是 no such name。
7 号包,这个才是请求的域名对应的 IPv4 地址(A 记录)。
8 号包,
DNS 服务器不管是从缓存里面,还是进行迭代查询最终得到了域名的 IP 地址,响应给了系统,系统再给了 wget 命令,wget 于是得到了 www.linux178.com 的 IP 地址,这里也可以**看出客户端和本地的 DNS 服务器是递归的查询(也就是服务器必须给客户端一个结果)这就可以开始下一步了**,进行 TCP 的三次握手。
拿到域名对应的 IP 地址之后,**User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的 WEB 程序(常用的有 httpd,nginx 等)80 端口发起 TCP 的连接请求。**这个连接请求(原始的 http 请求经过 TCP/IP4 层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的 TCP/IP 协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过 Netfilter 防火墙(属于内核的模块)的过滤,最终到达 WEB 程序,最终建立了 TCP/IP 的连接。
如下图所示:
03174517_saG0.png
- Client 首先发送一个连接试探,ACK=0 表示确认号无效,SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据,seq = x 表示 Client 自己的初始序号(seq = 0 就代表这是第 0 号包),这时候 Client 进入 syn_sent 状态,表示客户端等待服务器的回复。
- Server 监听到连接请求报文后,如同意建立连接,则向 Client 发送确认。TCP 报文首部中的 SYN 和 ACK 都置 1 ,ack = x + 1 表示期望收到对方下一个报文段的第一个数据字节序号是 x+1,同时表明 x 为止的所有数据都已正确收到(ack=1 其实是 ack=0+1, 也就是期望客户端的第 1 个包),seq = y 表示 Server 自己的初始序号(seq=0 就代表这是服务器这边发出的第 0 号包)。这时服务器进入 syn_rcvd,表示服务器已经收到 Client 的连接请求,等待 client 的确认。
- Client 收到确认后还需再次发送确认,同时携带要发送给 Server 的数据。ACK 置 1 表示确认号 ack= y + 1 有效(代表期望收到服务器的第 1 个包),Client 自己的序号 seq= x + 1(表示这就是我的第 1 个包,相对于第 0 个包来说的),一旦收到 Client 的确认之后,这个 TCP 连接就进入 Established 状态,就可以发起 http 请求了。
看抓包截图:
抓包截图
TCP 为什么需要 3 次握手?
举个例子:假设一个老外在故宫里面迷路了,看到了小明,于是就有下面的对话:
老外: Excuse me,Can you Speak English?
小明: yes 。
老外: OK,I want ...
在问路之前,老外先问小明是否会说英语,小明回答是的,这时老外才开始问路。
2 个计算机通信是靠协议(目前流行的 TCP/IP 协议)来实现,如果 2 个计算机使用的协议不一样,那是不能进行通信的,所以这个 3 次握手就相当于试探一下对方是否遵循 TCP/IP 协议,协商完成后就可以进行通信了,当然这样理解不是那么准确。
为什么 HTTP 协议要基于 TCP 来实现?
目前在 Internet 中所有的传输都是通过 TCP/IP 进行的,HTTP 协议作为 TCP/IP 模型中应用层的协议也不例外,TCP 是一个端到端的可靠的面向连接的协议,所以 HTTP 基于传输层 TCP 协议不用担心数据的传输的各种问题。
经过 TCP3 次握手之后,浏览器发起了 http 的请求(看第⑫包),使用的 http 的方法 GET 方法,请求的 URL 是 / , 协议是 HTTP/1.0:
03175340_4j8z.png
下面是第 12 号包的详细内容:
03175429_kHoP.png
以上的报文是 HTTP 请求报文。那么 HTTP 请求报文和响应报文会是什么格式呢?
起始行:如 GET / HTTP/1.0 (请求的方法 请求的 URL 请求所使用的协议)
头部信息:User-Agent Host 等成对出现的值
主体
不管是请求报文还是响应报文都会遵循以上的格式。那么起始行中的请求方法有哪些种呢?
GET: 完整请求一个资源 (常用)
HEAD: 仅请求响应首部
POST: 提交表单 (常用)
PUT: 上传
DELETE: 删除
OPTIONS: 返回请求的资源所支持的方法的方法
TRACE: 追求一个资源请求中间所经过的代理
那什么是 URL、URI、URN?
URI Uniform Resource Identifier 统一资源标识符,如:scheme://[username:password@] HOST:port/path/to/source
URL Uniform Resource Locator 统一资源定位符,如:http://www.magedu.com/downloads/nginx-1.5.tar.gz
URN Uniform Resource Name 统一资源名称
URL 和 URN 都属于 URI,为了方便就把 URL 和 URI 暂时都通指一个东西。
请求的协议有哪些种?有以下几种:
http/0.9: stateless
http/1.0: MIME, keep-alive (保持连接), 缓存
http/1.1: 更多的请求方法,更精细的缓存控制,持久连接 (persistent connection) 比较常用
下面是 Chrome 发起的 http 请求报文头部信息:
03181252_cIE1.png
Accept 就是告诉服务器端,接受那些 MIME 类型
Accept-Encoding 这个看起来是接受那些压缩方式的文件
Accept-Lanague 告诉服务器能够发送哪些语言
Connection 告诉服务器支持 keep-alive 特性,TCP 连接在发送后将仍然保持打开状态,于是,
浏览器可以继续通过相同的 TCP 连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。Cookie 每次请求时都会携带上 Cookie 以方便服务器端识别是否是同一个客户端
Host 用来标识请求服务器上的那个虚拟主机,比如 Nginx 里面可以定义很多个虚拟主机,那这里就是用来标识要访问那个虚拟主机。
User-Agent 用户代理,一般情况是浏览器,也有其他类型,如:wget curl 搜索引擎的蜘蛛等
条件请求头部:If-Modified-Since 是浏览器向服务器端询问某个资源文件如果自从什么时间修改过,那么重新发给我,这样就保证服务器端资源文件更新时,浏览器再次去请求,而不是使用缓存中的文件。
安全请求头部:Authorization: 客户端提供给服务器的认证信息;
什么是 MIME?
MIME(Multipurpose Internet Mail Extesions 多用途互联网邮件扩展)是一个互联网标准,它扩展了电子邮件标准,使其能够支持非 ASCII 字符、二进制格式附件等多种格式的邮件消息,这个标准被定义在 RFC 2045、RFC 2046、RFC 2047、RFC 2048、RFC 2049 等 RFC 中。 由 RFC 822 转变而来的 RFC 2822,规定电子邮件标准并不允许在邮件消息中使用 7 位 ASCII 字符集以外的字符。正因如此,一些非英语字符消息和二进制文件,图像,声音等非文字消息都不能在电子邮件中传输。
**MIME 规定了用于表示各种各样的数据类型的符号化方法。**此外,在万维网中使用的 HTTP 协议中也使用了 MIME 的框架,标准被扩展为互联网媒体类型。
MIME 遵循以下格式:major/minor 主类型 / 次类型 例如:
image/jpg
image/gif
text/html
video/quicktime
appliation/x-httpd-php
https://www.cnblogs.com/technologykai/articles/10682612.html
在日常使用 SpringMVC 进行开发的时候,有可能遇到前端各种类型的请求参数,这里做一次相对全面的总结。SpringMVC 中处理控制器参数的接口是 HandlerMethodArgumentResolver,此接口有众多子类,分别处理不同 (注解类型) 的参数,下面只列举几个子类:
实际上,一般在解析一个控制器的请求参数的时候,用到的是 HandlerMethodArgumentResolverComposite,里面装载了所有启用的 HandlerMethodArgumentResolver 子类。而 HandlerMethodArgumentResolver 子类在解析参数的时候使用到 HttpMessageConverter (实际上也是一个列表,进行遍历匹配解析) 子类进行匹配解析,常见的如 MappingJackson2HttpMessageConverter。而 HandlerMethodArgumentResolver 子类到底依赖什么 HttpMessageConverter 实例实际上是由请求头中的 ContentType (在 SpringMVC 中统一命名为 MediaType,见 org.springframework.http.MediaType) 决定的,因此我们在处理控制器的请求参数之前必须要明确外部请求的 ContentType 到底是什么。上面的逻辑可以直接看源码 AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters,思路是比较清晰的。在 @RequestMapping 注解中,produces 和 consumes 就是和请求或者响应的 ContentType 相关的:
另外提一点,SpringMVC 中默认使用 Jackson 作为 JSON 的工具包,如果不是完全理解透整套源码的运作,一般不是十分建议修改默认使用的 MappingJackson2HttpMessageConverter (例如有些人喜欢使用 FastJson,实现 HttpMessageConverter 引入 FastJson 做转换器)。
其实一般的表单或者 JSON 数据的请求都是相对简单的,一些复杂的处理主要包括 URL 路径参数、文件上传、数组或者列表类型数据等。另外,关于参数类型中存在日期类型属性 (例如 java.util.Date、java.sql.Date、java.time.LocalDate、java.time.LocalDateTime),解析的时候一般需要自定义实现的逻辑实现 String-> 日期类型的转换。其实道理很简单,日期相关的类型对于每个国家、每个时区甚至每个使用者来说认知都不一定相同。在演示一些例子主要用到下面的模特类:
@Data
public class User {
private String name;
private Integer age;
private List<Contact> contacts;
}
@Data
public class Contact {
private String name;
private String phone;
}
非对象类型单个参数接收:
这种是最常用的表单参数提交,ContentType 指定为 application/x-www-form-urlencoded,也就是会进行 URL 编码。
spmvc-p-1
对应的控制器如下:
@PostMapping(value = "/post")
public String post(@RequestParam(name = "name") String name,
@RequestParam(name = "age") Integer age) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
说实话,如果有毅力的话,所有的复杂参数的提交最终都可以转化为多个单参数接收,不过这样做会产生十分多冗余的代码,而且可维护性比较低。这种情况下,用到的参数处理器是 RequestParamMapMethodArgumentResolver。
对象类型参数接收:
我们接着写一个接口用于提交用户信息,用到的是上面提到的模特类,主要包括用户姓名、年龄和联系人信息列表,这个时候,我们目标的控制器最终编码如下:
@PostMapping(value = "/user")
public User saveUser(User user) {
log.info(user.toString());
return user;
}
我们还是指定 ContentType 为 application/x-www-form-urlencoded,接着我们需要构造请求参数:
spmvc-p-2
因为没有使用注解,最终的参数处理器为 ServletModelAttributeMethodProcessor,主要是把 HttpServletRequest 中的表单参数封装到 MutablePropertyValues 实例中,再通过参数类型实例化 (通过构造反射创建 User 实例),反射匹配属性进行值的填充。另外,请求复杂参数里面的列表属性请求参数看起来比较奇葩,实际上和在. properties 文件中添加最终映射到 Map 类型的参数的写法是一致的。那么,能不能把整个请求参数塞在一个字段中提交呢?
spmvc-p-3
直接这样做是不行的,因为实际提交的 form 表单,key 是 user,value 实际上是一个字符串,缺少一个 String->User 类型的转换器,实际上 RequestParamMethodArgumentResolver 依赖 WebConversionService 中 Converter 列表进行参数转换:
spmvc-p-4
解决办法还是有的,添加一个 org.springframework.core.convert.converter.Converter 实现即可:
@Component
public class StringUserConverter implements Converter<String, User> {
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public User convert(String source) {
try {
return MAPPER.readValue(source, User.class);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
上面这种做法属于曲线救国的做法,不推荐使用在生产环境,但是如果有些第三方接口的对接无法避免这种参数,可以选择这种实现方式。
一般来说,直接 POST 一个 JSON 字符串这种方式对于 SpringMVC 来说是比较友好的,只需要把 ContentType 设置为 application/json,提交一个原始的 JSON 字符串即可:
spmvc-p-5
后端控制器的代码也比较简单:
@PostMapping(value = "/user-2")
public User saveUser2(@RequestBody User user) {
log.info(user.toString());
return user;
}
因为使用了 @RequestBody 注解,最终使用到的参数处理器为 RequestResponseBodyMethodProcessor,实际上会用到 MappingJackson2HttpMessageConverter 进行参数类型的转换,底层依赖到 Jackson 相关的包。
URL 参数,或者叫请求路径参数是基于 URL 模板获取到的参数,例如 /user/{userId} 是一个 URL 模板 (URL 模板中的参数占位符是 {}),实际请求的 URL 为 /user/1,那么通过匹配实际请求的 URL 和 URL 模板就能提取到 userId 为 1。在 SpringMVC 中,URL 模板中的路径参数叫做 PathVariable,对应注解 @PathVariable,对应的参数处理器为 PathVariableMethodArgumentResolver。注意一点是,@PathVariable 的解析是按照 value (name) 属性进行匹配,和 URL 参数的顺序是无关的。举个简单的例子:
spmvc-p-6
后台的控制器如下:
@GetMapping(value = "/user/{name}/{age}")
public String findUser1(@PathVariable(value = "age") Integer age,
@PathVariable(value = "name") String name) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
这种用法被广泛使用于 Representational State Transfer (REST) 的软件架构风格,个人觉得这种风格是比较灵活和清晰的 (从 URL 和请求方法就能完全理解接口的意义和功能)。下面再介绍两种相对特殊的使用方式。
带条件的 URL 参数
其实路径参数支持正则表达式,例如我们在使用 /sex/{sex} 接口的时候,要求 sex 必须是 F (Female) 或者 M (Male),那么我们的 URL 模板可以定义为 /sex/{sex:M|F},代码如下:
@GetMapping(value = "/sex/{sex:M|F}")
public String findUser2(@PathVariable(value = "sex") String sex){
log.info(sex);
return sex;
}
只有 /sex/F 或者 /sex/M 的请求才会进入 findUser2 控制器方法,其他该路径前缀的请求都是非法的,会返回 404 状态码。这里仅仅是介绍了一个最简单的 URL 参数正则表达式的使用方式,更强大的用法可以自行摸索。
@MatrixVariable 的使用
MatrixVariable 也是 URL 参数的一种,对应注解 @MatrixVariable,不过它并不是 URL 中的一个值 (这里的值指定是两个 "/" 之间的部分),而是值的一部分,它通过 ";" 进行分隔,通过 "=" 进行 K-V 设置。说起来有点抽象,举个例子:假如我们需要打电话给一个名字为 doge,性别是男,分组是码畜的程序员,GET 请求的 URL 可以表示为:/call/doge;gender=male;group=programmer,我们设计的控制器方法如下:
@GetMapping(value = "/call/{name}")
public String find(@PathVariable(value = "name") String name,
@MatrixVariable(value = "gender") String gender,
@MatrixVariable(value = "group") String group) {
String content = String.format("name = %s,gender = %s,group = %s", name, gender, group);
log.info(content);
return content;
}
当然,如果你按照上面的例子写好代码,尝试请求一下该接口发现是报错的:400 Bad Request - Missing matrix variable 'gender' for method parameter of type String。这是因为 @MatrixVariable 注解的使用是不安全的,在 SpringMVC 中默认是关闭对其支持。要开启对 @MatrixVariable 的支持,需要设置 RequestMappingHandlerMapping#setRemoveSemicolonContent 方法为 false:
@Configuration
public class CustomMvcConfiguration implements InitializingBean {
@Autowired
private RequestMappingHandlerMapping requestMappingHandlerMapping;
@Override
public void afterPropertiesSet() throws Exception {
requestMappingHandlerMapping.setRemoveSemicolonContent(false);
}
}
除非有很特殊的需要,否则不建议使用 @MatrixVariable。
文件上传在使用 POSTMAN 模拟请求的时候需要选择 form-data,POST 方式进行提交:
spmvc-p-8
假设我们在 D 盘有一个图片文件叫 doge.jpg,现在要通过本地服务接口把文件上传,控制器的代码如下:
@PostMapping(value = "/file1")
public String file1(@RequestPart(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
控制台输出是:
name = file1,originName = doge.jpg,size = 68727
可能有点疑惑,参数是怎么来的,我们可以用 Fildder 抓个包看下:
spmvc-p-7
可知 MultipartFile 实例的主要属性分别来自 Content-Disposition、content-type 和 content-length,另外,InputStream 用于读取请求体的最后部分 (文件的字节序列)。参数处理器用到的是 RequestPartMethodArgumentResolver (记住一点,使用了 @RequestPart 和 MultipartFile 一定是使用此参数处理器)。在其他情况下,使用 @RequestParam 和 MultipartFile 或者仅仅使用 MultipartFile (参数的名字必须和 POST 表单中的 Content-Disposition 描述的 name 一致) 也可以接收上传的文件数据,主要是通过 RequestParamMethodArgumentResolver 进行解析处理的,它的功能比较强大,具体可以看其 supportsParameter 方法,这两种情况的控制器方法代码如下:
@PostMapping(value = "/file2")
public String file2(MultipartFile file1) {
String content = String.format("name = %s,originName = %s,size = %d",
file1.getName(), file1.getOriginalFilename(), file1.getSize());
log.info(content);
return content;
}
@PostMapping(value = "/file3")
public String file3(@RequestParam(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
其他参数主要包括请求头、Cookie、Model、Map 等相关参数,还有一些并不是很常用或者一些相对原生的属性值获取 (例如 HttpServletRequest、HttpServletResponse 等) 不做讨论。
请求头的值主要通过 @RequestHeader 注解的参数获取,参数处理器是 RequestHeaderMethodArgumentResolver,需要在注解中指定请求头的 Key。简单实用如下:
spmvc-p-9
控制器方法代码:
@PostMapping(value = "/header")
public String header(@RequestHeader(name = "Content-Type") String contentType) {
return contentType;
}
Cookie 的值主要通过 @CookieValue 注解的参数获取,参数处理器为 ServletCookieValueMethodArgumentResolver,需要在注解中指定 Cookie 的 Key。控制器方法代码如下:
@PostMapping(value = "/cookie")
public String cookie(@CookieValue(name = "JSESSIONID") String sessionId) {
return sessionId;
}
Model 类型参数的处理器是 ModelMethodProcessor,实际上处理此参数是直接返回 ModelAndViewContainer 实例中的 Model (ModelMap 类型),因为要桥接不同的接口和类的功能,因此回调的实例是 BindingAwareModelMap 类型,此类型继承自 ModelMap 同时实现了 Model 接口。举个例子:
@GetMapping(value = "/model")
public String model(Model model, ModelMap modelMap) {
log.info("{}", model == modelMap);
return "success";
}
注意调用此接口,控制台输出 Info 日志内容为:true。ModelMap 或者 Model 中添加的属性项会附加到 HttpRequestServlet 中带到页面中进行渲染。
@ModelAttribute 注解处理的参数处理器为 ModelAttributeMethodProcessor,@ModelAttribute 的功能源码的注释如下:
Annotation that binds a method parameter or method return value to a named model attribute, exposed to a web view.
简单来说,就是通过 key-value 形式绑定方法参数或者方法返回值到 Model (Map) 中,区别下面三种情况:
在一个控制器 (使用了 @controller) 中,如果存在一到多个使用了 @ModelAttribute 的方法,这些方法总是在进入控制器方法之前执行,并且执行顺序是由加载顺序决定的 (具体的顺序是带参数的优先,并且按照方法首字母升序排序),举个例子:
@Slf4j
@RestController
public class ModelAttributeController {
@ModelAttribute
public void before(Model model) {
log.info("before..........");
model.addAttribute("before", "beforeValue");
}
@ModelAttribute(value = "beforeArg")
public String beforeArg() {
log.info("beforeArg..........");
return "beforeArgValue";
}
@GetMapping(value = "/modelAttribute")
public String modelAttribute(Model model, @ModelAttribute(value = "beforeArg") String beforeArg) {
log.info("modelAttribute..........");
log.info("beforeArg..........{}", beforeArg);
log.info("{}", model);
return "success";
}
@ModelAttribute
public void after(Model model) {
log.info("after..........");
model.addAttribute("after", "afterValue");
}
@ModelAttribute(value = "afterArg")
public String afterArg() {
log.info("afterArg..........");
return "afterArgValue";
}
}
调用此接口,控制台输出日志如下:
after..........
before..........
afterArg..........
beforeArg..........
modelAttribute..........
beforeArg..........beforeArgValue
{after=afterValue, before=beforeValue, afterArg=afterArgValue, beforeArg=beforeArgValue}
可以印证排序规则和参数设置、获取。
Errors 其实是 BindingResult 的父接口,BindingResult 主要用于回调 JSR 参数校验异常的属性项,如果 JSR 校验异常,一般会抛出 MethodArgumentNotValidException 异常,并且会返回 400 (Bad Request),见全局异常处理器 DefaultHandlerExceptionResolver。Errors 类型的参数处理器为 ErrorsMethodArgumentResolver。举个例子:
@PostMapping(value = "/errors")
public String errors(@RequestBody @Validated ErrorsModel errors, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
for (ObjectError objectError : bindingResult.getAllErrors()) {
log.warn("name={},message={}", objectError.getObjectName(), objectError.getDefaultMessage());
}
}
return errors.toString();
}
@Data
@NoArgsConstructor
public class ErrorsModel {
@NotNull(message = "id must not be null!")
private Integer id;
@NotEmpty(message = "errors name must not be empty!")
private String name;
}
调用接口控制台 Warn 日志如下:
name=errors,message=errors name must not be empty!
一般情况下,不建议用这种方式处理 JSR 校验异常的属性项,因为会涉及到大量的重复的硬编码工作,建议直接继承 ResponseEntityExceptionHandler,覆盖对应的方法。
控制器方法的参数可以是 @value 注解修饰的参数,会从 Environment 中装配和转换属性值到对应的参数中 (也就是参数的来源并不是请求体),参数处理器为 ExpressionValueMethodArgumentResolver。举个例子:
@GetMapping(value = "/value")
public String value(@Value(value = "${spring.application.name}") String name) {
log.info("spring.application.name={}", name);
return name;
}
Map 类型参数的范围相对比较广,对应一系列的参数处理器,注意区别使用了上面提到的部分注解的 Map 类型和完全不使用注解的 Map 类型参数,两者的处理方式不相同。下面列举几个相对典型的 Map 类型参数处理例子。
不使用任何注解的 Map<String,Object> 参数
这种情况下参数实际上直接回调 ModelAndViewContainer 中的 ModelMap 实例,参数处理器为 MapMethodProcessor,往 Map 参数中添加的属性将会带到页面中。
使用 @RequestParam 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestParamMapMethodArgumentResolver,使用的请求方式需要指定 ContentType 为 x-www-form-urlencoded,不能使用 application/json 的方式:
spmvc-p-10
控制器代码为:
@PostMapping(value = "/map")
public String mapArgs(@RequestParam Map<String, Object> map) {
log.info("{}", map);
return map.toString();
}
使用 @RequestHeader 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestHeaderMapMethodArgumentResolver,作用是获取请求的所有请求头的 Key-Value。
使用 @PathVariable 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 PathVariableMapMethodArgumentResolver,作用是获取所有路径参数封装为 Key-Value 结构。
批量文件上传的时候,我们一般需要接收一个 MultipartFile 集合,可以有两种选择:
getFiles 方法获取 MultipartFile 列表。spmvc-p-11
控制器方法代码如下:
@PostMapping(value = "/parts")
public String partArgs(@RequestParam(name = "file") List<MultipartFile> parts) {
log.info("{}", parts);
return parts.toString();
}
日期处理个人认为是请求参数处理中最复杂的,因为一般日期处理的逻辑不是通用的,过多的定制化处理导致很难有一个统一的标准处理逻辑去处理和转换日期类型的参数。不过,这里介绍几个通用的方法,以应对各种奇葩的日期格式。下面介绍的例子中全部使用 Jdk8 中引入的日期时间 API,围绕 java.util.Date 为核心的日期时间 API 的使用方式类同。
这种是最原始但是最奏效的方式,统一以字符串形式接收,然后自行处理类型转换,下面给个小例子:
@PostMapping(value = "/date1")
public String date1(@RequestBody UserDto userDto) {
UserEntity userEntity = new UserEntity();
userEntity.setUserId(userDto.getUserId());
userEntity.setBirthdayTime(LocalDateTime.parse(userDto.getBirthdayTime(), FORMATTER));
userEntity.setGraduationTime(LocalDateTime.parse(userDto.getGraduationTime(), FORMATTER));
log.info(userEntity.toString());
return "success";
}
@Data
public class UserDto {
private String userId;
private String birthdayTime;
private String graduationTime;
}
@Data
public class UserEntity {
private String userId;
private LocalDateTime birthdayTime;
private LocalDateTime graduationTime;
}
spmvc-p-12
@DateTimeFormat 注解配合 @RequestBody 的参数使用的时候,会发现抛出 InvalidFormatException 异常,提示转换失败,这是因为在处理此注解的时候,只支持 form 提交 (ContentType 为 x-www-form-urlencoded),例子如下:
spmvc-p-13
@Data
public class UserDto2 {
private String userId;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime birthdayTime;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime graduationTime;
}
@PostMapping(value = "/date2")
public String date2(UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@PostMapping(value = "/date2")
public String date2(@RequestParam("name"="userId")String userId,
@RequestParam("name"="birthdayTime")LocalDateTime birthdayTime,
@RequestParam("name"="graduationTime")LocalDateTime graduationTime) {
return "success";
}
而 @jsonformat 注解可使用在 form 或者 Json 请求参数的场景,因此更推荐使用 @jsonformat 注解,不过注意需要指定时区 (timezone 属性,例如在**是东八区 "GMT+8"),否则有可能导致出现 "时差",举个例子:
@PostMapping(value = "/date2")
public String date2(@RequestBody UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@Data
public class UserDto2 {
private String userId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime birthdayTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime graduationTime;
}
因为 SpringMVC 默认使用 Jackson 处理 @RequestBody 的参数转换,因此可以通过定制序列化器和反序列化器来实现日期类型的转换,这样我们就可以使用 application/json 的形式提交请求参数。这里的例子是转换请求 Json 参数中的字符串为 LocalDateTime 类型,属于 Json 反序列化,因此需要定制反序列化器:
@PostMapping(value = "/date3")
public String date3(@RequestBody UserDto3 userDto3) {
log.info(userDto3.toString());
return "success";
}
@Data
public class UserDto3 {
private String userId;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime birthdayTime;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime graduationTime;
}
public class CustomLocalDateTimeDeserializer extends LocalDateTimeDeserializer {
public CustomLocalDateTimeDeserializer() {
super(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
}
前面三种方式都存在硬编码等问题,其实最佳实践是直接修改 MappingJackson2HttpMessageConverter 中的 ObjectMapper 对于日期类型处理默认的序列化器和反序列化器,这样就能全局生效,不需要再使用其他注解或者定制序列化方案 (当然,有些时候需要特殊处理定制),或者说,在需要特殊处理的场景才使用其他注解或者定制序列化方案。使用钩子接口 Jackson2ObjectMapperBuilderCustomizer 可以实现 ObjectMapper 的属性定制:
@Bean
public Jackson2ObjectMapperBuilderCustomizer jackson2ObjectMapperBuilderCustomizer(){
return customizer->{
customizer.serializerByType(LocalDateTime.class,new LocalDateTimeSerializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
customizer.deserializerByType(LocalDateTime.class,new LocalDateTimeDeserializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
};
}
这样就能定制化 MappingJackson2HttpMessageConverter 中持有的 ObjectMapper,上面的 LocalDateTime 序列化和反序列化器对全局生效。
前面基本介绍完了主流的请求参数处理,其实 SpringMVC 中还会按照 URL 的模式进行匹配,使用的是 Ant 路径风格,处理工具类为 org.springframework.util.AntPathMatcher,从此类的注释来看,匹配规则主要包括下面四点:
? 匹配 1 个字符。* 匹配 0 个或者多个字符。** 匹配路径中 0 个或者多个目录。{spring:[a-z]+} 将正则表达式 [a-z]+ 匹配到的值,赋值给名为 spring 的路径变量。举些例子:
? 形式的 URL:
@GetMapping(value = "/pattern?")
public String pattern() {
return "success";
}
/pattern 404 Not Found
/patternd 200 OK
/patterndd 404 Not Found
/pattern/ 404 Not Found
/patternd/s 404 Not Found
* 形式的 URL:
@GetMapping(value = "/pattern*")
public String pattern() {
return "success";
}
/pattern 200 OK
/pattern/ 200 OK
/patternd 200 OK
/pattern/a 404 Not Found
** 形式的 URL:
@GetMapping(value = "/pattern/**/p")
public String pattern() {
return "success";
}
/pattern/p 200 OK
/pattern/x/p 200 OK
/pattern/x/y/p 200 OK
{spring:[a-z]+} 形式的 URL:
@GetMapping(value = "/pattern/{key:[a-c]+}")
public String pattern(@PathVariable(name = "key") String key) {
return "success";
}
/pattern/a 200 OK
/pattern/ab 200 OK
/pattern/abc 200 OK
/pattern 404 Not Found
/pattern/abcd 404 Not Found
上面的四种 URL 模式可以组合使用,千变万化。
URL 匹配还遵循精确匹配原则,也就是存在两个模式对同一个 URL 都能够匹配成功,则选取最精确的 URL 匹配,进入对应的控制器方法,举个例子:
@GetMapping(value = "/pattern/**/p")
public String pattern1() {
return "success";
}
@GetMapping(value = "/pattern/p")
public String pattern2() {
return "success";
}
上面两个控制器,如果请求 URL 为 /pattern/p,最终进入的方法为 pattern2。
最后,org.springframework.util.AntPathMatcher 作为一个工具类,可以单独使用,不仅仅可以用于匹配 URL,也可以用于匹配系统文件路径,不过需要使用其带参数构造改变内部的 pathSeparator 变量,例如:
AntPathMatcher antPathMatcher = new AntPathMatcher(File.separator);
笔者在前一段时间曾经花大量时间梳理和分析过 Spring、SpringMVC 的源码,但是后面一段很长的时间需要进行业务开发,对架构方面的东西有点生疏了,毕竟东西不用就会生疏,这个是常理。这篇文章基于一些 SpringMVC 的源码经验总结了请求参数的处理相关的一些知识,希望帮到自己和大家。
参考资料:
1. 在静态方法中是不能使用 this 预定义对象引用的 , 即使其后边所操作的也是静态成员也不行.
因为 this 代表的是调用这个函数的对象的引用 , 而静态方法是属于类的 , 不属于对象 , 静态方法成功加载后 , 对象还不一定存在
2. 在问题之前先讲 super 的用法:
1.super 的用法跟 this 类似,this 代表对本类对象的引用,指向本类已经创建的对象;而 super 代表对父类对象的引用,指向父类对象;
2. 静态优先于对象存在;
3. 由上面的 1. 和 2. 知:
因为静态优先于对象存在,所以方法被静态修饰之后方法先存在,而方法里面要用到 super 指向的父类对象,但是所需的父类引用对象晚于该方法出现,也就是 super 所指向的对象没有,当然就会出错。
综上,静态方法中不可以出现 super 关键字。
3. 首先你要明白对象和类的区别。
this 和 super 是属于对象范畴的东西,而静态方法是属于类范畴的东西
所有的成员方法 , 都有一个默认的的参数 this(即使是无参的方法), 只要是成员方法 , 编译器就会给你加上 this 这个参数如:
Class A 中
void method1(){} 实际上是这样的 --------> void method1(A this)
void method2(int x){} 实际上是这样的 --------> void method2(A this, intx) 而静态方法与对象无关 , 根本不能把对象的引用传到方法中 , 所以不能用 this
4. 在一个类中定义一个方法为 static,则为静态方法,那就是说,无需本类的对象即可调用此方法,调用一个静态方法就是 “类名. 方法名” 既然 "无需本类的对象即可调用静态方法",而 this 和 super 关键字都是用于本类对象的-----调用静态方法无需本类的对象这句话很清楚表明:静态方法中不能用 this 和 super 关键字
5. 静态方法是存放在内存中的数据段里,this 和 super 调用的是堆空间里的应用对象不能调用数据段区域里的数据,因此静态方法中不能用 this 和 super 关键字
6. 静态方法和静态类不属于单个对象,而是类的所有对象共享使用
而 this 代表当前对象
7. 东西只属于类,不属于任何对象,所以不能用 THIS 和 SUPER。
https://blog.csdn.net/u010479322/article/details/51730275
众所周知,因为疫情的原因,很多高校和公司都要求员工每日在微信上进行打卡,来汇报自己的当前身体状态和所处地区。但绝大多数情况下,每天打卡的信息其实是不会变的,我们要做的就是进入公众号——自动登录点进打卡页面——完成打卡,这样重复的操作。
这样的操作在手机上需要花费的时间应该不足一分钟,但依旧每天都会有懒得或者忘了进行操作的人。所以就想到能不能用 python 写一个脚本,在 PC 端进行自动打卡呢?
(本操作仅提供思路参考,大家还是要重视防疫打卡操作)
以下所有操作均以某高校页面为例
目录
2. 代码实现(Cookie + 纯 requests 版本)
3. 代码实现(账号密码 + Selenium+Requests 版本)
由于微信的普及,所以基本各高校和公司每日打卡都是在微信端进行,所以我们需要通过微信找到我们的登录页。
公众号进入打卡页面标题
标题选择复制链接地址
我们最终希望用Requests模拟发包登录,而平时都是直接用微信进行自动登录。显然在只用脚本的情况下没办法实现微信自动登录跳转,所以我们需要先找到能输入账号密码的页面。(此时没有用 Cookie 是因为实验之后发现,Cookie 有效期不到 2 小时,没办法支撑每日用同一个 Cookie 登录打卡)
此时,我们通过 PC 微信找到该链接:http://****app.i****.info/NYDXY/#/,但是如果直接用浏览器打开该链接,会跳转” 请用微信客户端打开链接 “的页面。
标题直接用浏览器打开出错
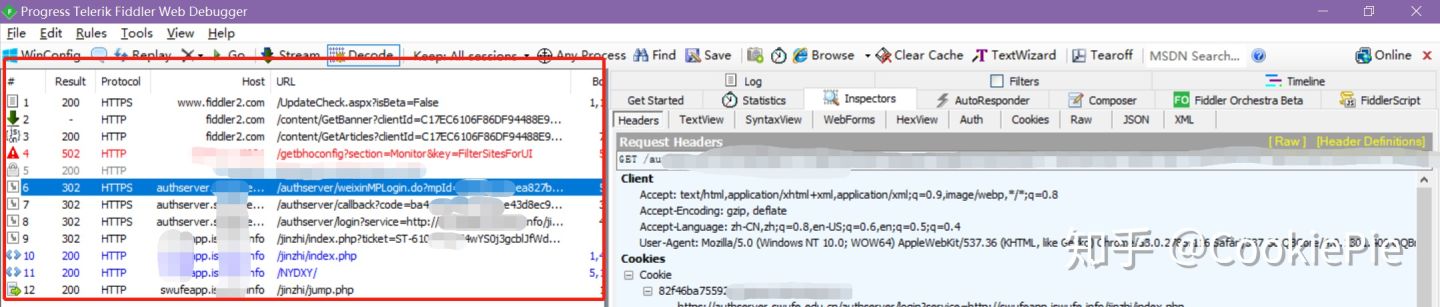
因此,需要想办法绕过该限制,思路有两个:1. 通过 Fiddler 等抓包软件,找找有没有其他登录页面。2. 模拟微信浏览器的请求头和 Cookie 进入。但是正如前文所说,经过尝试思路 2,确实能够完成全流程,但该页面 Cookie 有效期很短,没办法每日均进行自动打卡,因此我们选择尝试思路 1,还是通过账号密码登录。
沿着思路 1,我们打开 Fiddler,启动抓包。然后回到 PC 微信,和刚才同样的操作进入打卡页面自动登录,再回到 Fiddler,发现刚才进入打卡页面的所有操作已经被记录在软件里了。接下来就是通过 url 和请求头等信息,来判断是否存在其他的登录页面。
红框所示为抓包所得
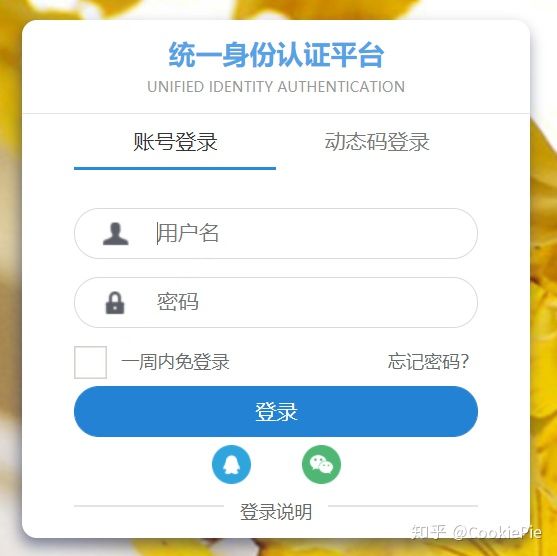
经过分析和尝试,前两个链接都会提示 400 或其他错误,但尝试到第三个链接时,会跳转到学校的统一登陆页面,同时还在下方发现微信快捷登录图表。通过该页面输入账号密码后,浏览器自动跳转到了我们所需的打卡页面了。此时,我们实现了 PC 端模拟登录微信打卡页面。
统一登录页面
浏览器成功登入打卡页面
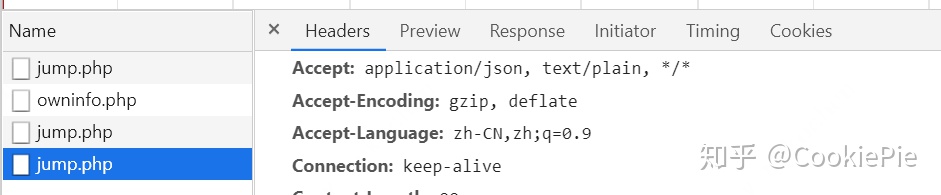
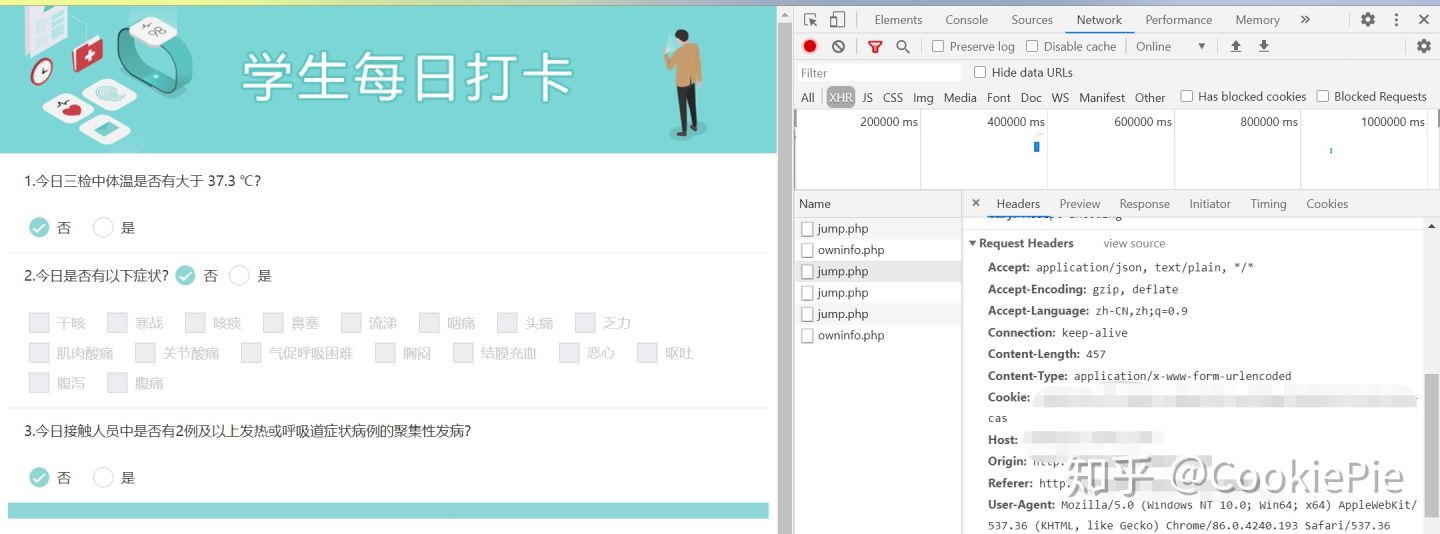
第二步,我们需要看我们打卡到底在浏览器端是如何完成的。在手动进行打卡操作之后,经过浏览器的 F12,看到有四个 php 提供了 post 操作,而通常我们的表单数据都是由 post 方法完成的。排除掉之前就存在的第一二个 php,所以我们强烈怀疑就是通过这剩余两个 php 完成的打卡操作。
怀疑的 jump.php
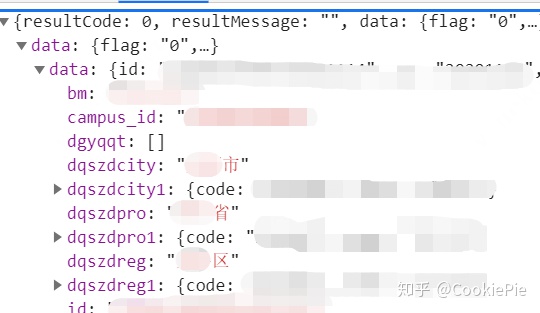
具体来看发现,最后一个 jump.php 实际上返回的是个人基本信息,以供自动填充用的,提交的表单也与打卡无关。
最后的 jump.php 返回的结果
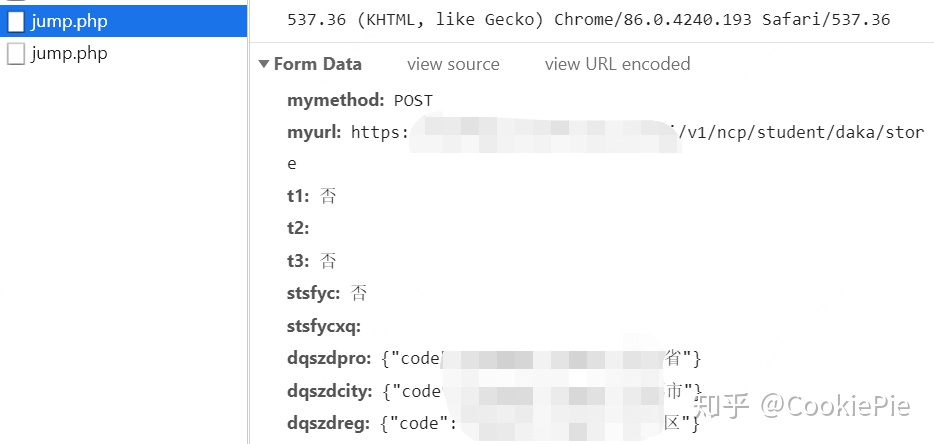
但到了倒数第二个 jump.php,通过其提交的 Form 数据,我们发现就是通过这个 php 我们完成了打卡操作。因此得知,我们的最终目标,就是通过该 php 来完成我们的自动打卡。至此,我们的代码前分析全部完成,接下来进入代码环节。
倒数第二个 php 提交的表单
( 此版本使用 requests 包进行 python 代码实现)
因为我们已经通过浏览器进行过登录,获得了 Cookie,所以我们先尝试通过 Cookie 进行直接打卡。先通过浏览器 F12 获得 Cookie 和其余请求头,然后根据需要放在 Python 文件中。(这里的请求头大家可以选择需要的来放,一般加上Cookie 和 User-Agent即可,如果失败还可以尝试将 User-Agent 换为 Android 或 ios 的模拟请求)
右侧为请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36','Cookie': '浏览器上找到的Cookie'```
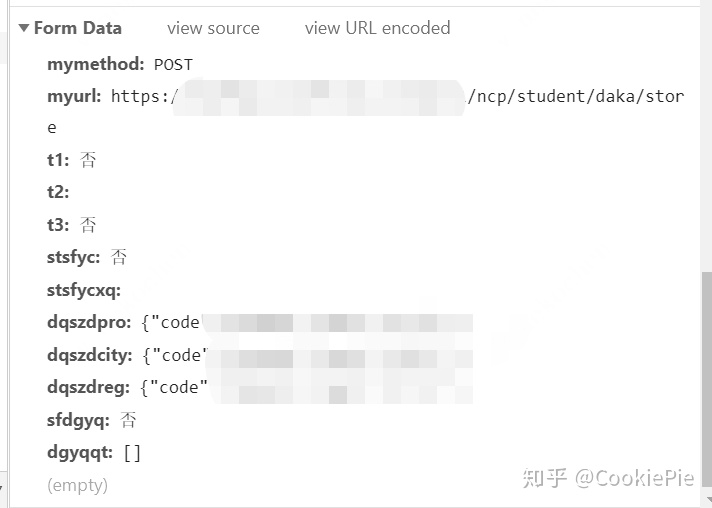
然后再根据From Data的数据,按照字典格式一一放进Python文件中去。
From Data数据
Python文件格式
最后再尝试post即可。发现最后返回值和浏览器返回值相同,打卡成功。
```null
url = 'http://****app.i****.info/jinzhi/jump.php'response = s.post(url=url, headers=headers, data=data)response.encoding = 'utf-8'```
Python返回值

浏览器返回值
3.代码实现(账号密码+Selenium+Requests版本)
--------------------------------
前文已经实现在知道Cookie的前提下,可以直接通过固定php页面进行表单上传打卡。但是由于Cookie有效期极短,所以我们明显需要有一个每次打卡前自动获取Cookie的方法。
回到一开始的Login页面,同样我们通过F12抓包,看每次登录时提交的表单具体值有些什么。在用户名和密码,我们尝试性的输入123456之后点击提交,会发现在login文件下会POST一个表单,里面所包含的就是每次登录要传给服务器的信息了。
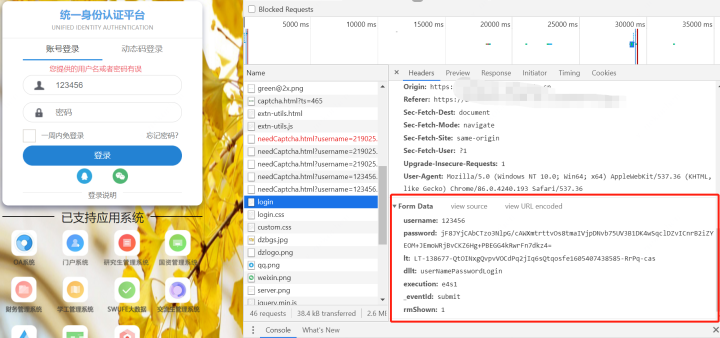
登录信息
但是从表单我们看到,除了我们填写的账号密码,还有包括lt,execution等信息。经过查找,我们发现这些信息是在加载网页时就自动生成的,所以我们可以通过request.session()的方法进入页面后,再通过正则表达式将所需信息找出来,和账号密码一起形成表单。

页面隐藏的元素
但是我们还可以看到,password明显是经过加密处理后的信息,所以我们不能直接明文提交密码,要想办法将密码进行处理。而这个加密后的密码,是我们点击提交后网页自动将我们的明文密码进行的加密,所以大概率就是一个js的处理,因此需要找到网页上加密的js文件。查找login页面和js之后,最终找到是encrypt.js这个文件完成了明文密码的加密。
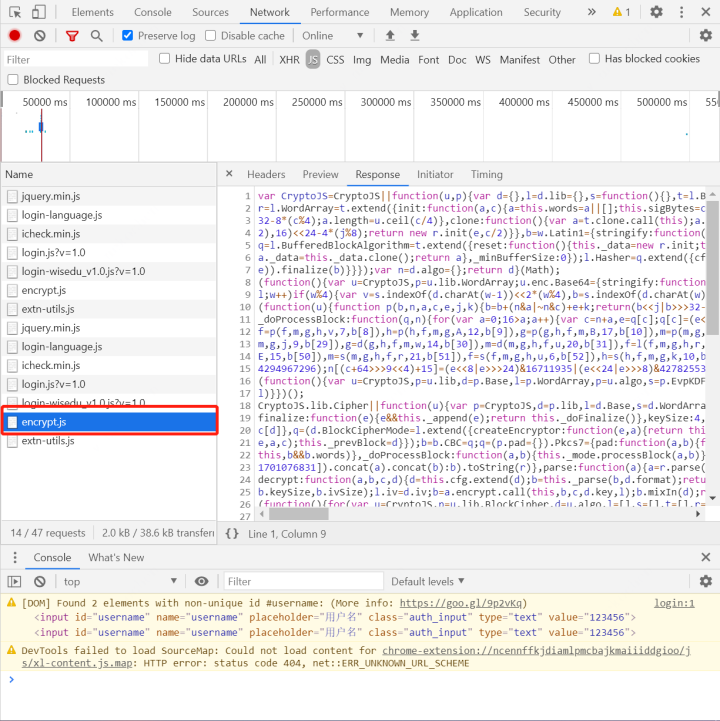
加密js
按逻辑来说,我们此时就可以查找传递该js所需参数,得到加密后的密码,连同其他信息一起post给login就可以完成我们的登录和cookie获取了。但是这个js真是又长又混淆,以现在的水平暂时不能找到其所需参数。所以换了个思路,通过Selenium来模拟登录,直接获取Cookie。
(这里如果可以看懂这个js加密的话,是完全可以不依靠Selenium获取Cookie的,大家有兴趣可以尝试一下)
Selenium就比较简单了,通过分析登录页面,找到需要Input的地方,获取Xpath,再通过Selenium填写,并获取Cookie就可以了。
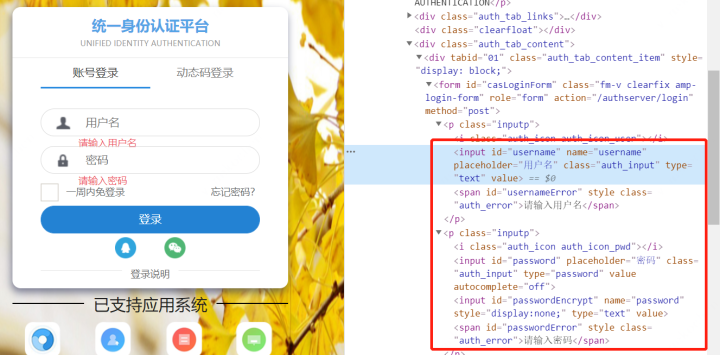
通过F12得到元素的Xpath
```null
def get_cookie(url_, user_): driver = webdriver.Chrome() driver.find_element_by_xpath('//*[@id="username"]').send_keys(user_['name']) driver.find_element_by_xpath('//*[@id="password"]').send_keys(user_['password']) driver.find_element_by_xpath('//*[@id="casLoginForm"]/p[4]/button').click() cookie_ = driver.get_cookies()[0] return cookie_['name']+'='+cookie_['value']```
获取cookie后,和之前操作相同,提交表单即可,完整代码如下。
```null
from selenium import webdriverdef get_cookie(url_, user_): driver = webdriver.Chrome() driver.find_element_by_xpath('//*[@id="username"]').send_keys(user_['name']) driver.find_element_by_xpath('//*[@id="password"]').send_keys(user_['password']) driver.find_element_by_xpath('//*[@id="casLoginForm"]/p[4]/button').click() cookie_ = driver.get_cookies()[0]return cookie_['name']+'='+cookie_['value']user = {'name': '', 'password': ''}cookie = get_cookie('https://authserver.*****.edu.cn/authserver/login?service=http://*****app.i*****.info/jinzhi/index.php', user)'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36','myurl': 'https://*****api.*****.edu.cn/api/v1/ncp/student/daka/update','dqszdpro': '{"code":""}','dqszdcity': '{"code":""}','dqszdreg': '{"code":""}',url = 'http://*****app.i*****.info/jinzhi/jump.php'response = s.post(url=url, headers=headers, data=data)```
4.总结
----
其实在类似需求中,代码部分相对而言占比更少,重要的地方在于找到提交的表单数据和页面链接,和能否完成加密解密。本文由于js加密的限制,只能通过Selenium来获取Cookie进而实现表单提交。在之后的版本中,希望能够通过分析js文件,完成参数传递加密,最终只用Requests包完成打卡操作。
与本文类似的应用场景还有很多,都可以用相同的思路去解决,本文作为供大家选择的参考,如果各位读者有更好的思路欢迎多多交流。
[https://blog.csdn.net/CookiePie/article/details/109698484](https://blog.csdn.net/CookiePie/article/details/109698484)
0.2932018.08.07 01:21:20 字数 4,800 阅读 1,372
在日常使用 SpringMVC 进行开发的时候,有可能遇到前端各种类型的请求参数,这里做一次相对全面的总结。SpringMVC 中处理控制器参数的接口是 HandlerMethodArgumentResolver,此接口有众多子类,分别处理不同 (注解类型) 的参数,下面只列举几个子类:
实际上,一般在解析一个控制器的请求参数的时候,用到的是 HandlerMethodArgumentResolverComposite,里面装载了所有启用的 HandlerMethodArgumentResolver 子类。而 HandlerMethodArgumentResolver 子类在解析参数的时候使用到 HttpMessageConverter (实际上也是一个列表,进行遍历匹配解析) 子类进行匹配解析,常见的如 MappingJackson2HttpMessageConverter。而 HandlerMethodArgumentResolver 子类到底依赖什么 HttpMessageConverter 实例实际上是由请求头中的 ContentType (在 SpringMVC 中统一命名为 MediaType,见 org.springframework.http.MediaType) 决定的,因此我们在处理控制器的请求参数之前必须要明确外部请求的 ContentType 到底是什么。上面的逻辑可以直接看源码 AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters,思路是比较清晰的。在 @RequestMapping 注解中,produces 和 consumes 就是和请求或者响应的 ContentType 相关的:
另外提一点,SpringMVC 中默认使用 Jackson 作为 JSON 的工具包,如果不是完全理解透整套源码的运作,一般不是十分建议修改默认使用的 MappingJackson2HttpMessageConverter (例如有些人喜欢使用 FastJson,实现 HttpMessageConverter 引入 FastJson 做转换器)。
其实一般的表单或者 JSON 数据的请求都是相对简单的,一些复杂的处理主要包括 URL 路径参数、文件上传、数组或者列表类型数据等。另外,关于参数类型中存在日期类型属性 (例如 java.util.Date、java.sql.Date、java.time.LocalDate、java.time.LocalDateTime),解析的时候一般需要自定义实现的逻辑实现 String-> 日期类型的转换。其实道理很简单,日期相关的类型对于每个国家、每个时区甚至每个使用者来说认知都不一定相同。在演示一些例子主要用到下面的模特类:
@Data
public class User {
private String name;
private Integer age;
private List<Contact> contacts;
}
@Data
public class Contact {
private String name;
private String phone;
}
非对象类型单个参数接收:
这种是最常用的表单参数提交,ContentType 指定为 application/x-www-form-urlencoded,也就是会进行 URL 编码。
spmvc-p-1
对应的控制器如下:
@PostMapping(value = "/post")
public String post(@RequestParam(name = "name") String name,
@RequestParam(name = "age") Integer age) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
说实话,如果有毅力的话,所有的复杂参数的提交最终都可以转化为多个单参数接收,不过这样做会产生十分多冗余的代码,而且可维护性比较低。这种情况下,用到的参数处理器是 RequestParamMapMethodArgumentResolver。
对象类型参数接收:
我们接着写一个接口用于提交用户信息,用到的是上面提到的模特类,主要包括用户姓名、年龄和联系人信息列表,这个时候,我们目标的控制器最终编码如下:
@PostMapping(value = "/user")
public User saveUser(User user) {
log.info(user.toString());
return user;
}
我们还是指定 ContentType 为 application/x-www-form-urlencoded,接着我们需要构造请求参数:
spmvc-p-2
因为没有使用注解,最终的参数处理器为 ServletModelAttributeMethodProcessor,主要是把 HttpServletRequest 中的表单参数封装到 MutablePropertyValues 实例中,再通过参数类型实例化 (通过构造反射创建 User 实例),反射匹配属性进行值的填充。另外,请求复杂参数里面的列表属性请求参数看起来比较奇葩,实际上和在. properties 文件中添加最终映射到 Map 类型的参数的写法是一致的。那么,能不能把整个请求参数塞在一个字段中提交呢?
spmvc-p-3
直接这样做是不行的,因为实际提交的 form 表单,key 是 user,value 实际上是一个字符串,缺少一个 String->User 类型的转换器,实际上 RequestParamMethodArgumentResolver 依赖 WebConversionService 中 Converter 列表进行参数转换:
spmvc-p-4
解决办法还是有的,添加一个 org.springframework.core.convert.converter.Converter 实现即可:
@Component
public class StringUserConverter implements Converter<String, User> {
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public User convert(String source) {
try {
return MAPPER.readValue(source, User.class);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
上面这种做法属于曲线救国的做法,不推荐使用在生产环境,但是如果有些第三方接口的对接无法避免这种参数,可以选择这种实现方式。
一般来说,直接 POST 一个 JSON 字符串这种方式对于 SpringMVC 来说是比较友好的,只需要把 ContentType 设置为 application/json,提交一个原始的 JSON 字符串即可:
spmvc-p-5
后端控制器的代码也比较简单:
@PostMapping(value = "/user-2")
public User saveUser2(@RequestBody User user) {
log.info(user.toString());
return user;
}
因为使用了 @RequestBody 注解,最终使用到的参数处理器为 RequestResponseBodyMethodProcessor,实际上会用到 MappingJackson2HttpMessageConverter 进行参数类型的转换,底层依赖到 Jackson 相关的包。
URL 参数,或者叫请求路径参数是基于 URL 模板获取到的参数,例如 /user/{userId} 是一个 URL 模板 (URL 模板中的参数占位符是 {}),实际请求的 URL 为 /user/1,那么通过匹配实际请求的 URL 和 URL 模板就能提取到 userId 为 1。在 SpringMVC 中,URL 模板中的路径参数叫做 PathVariable,对应注解 @PathVariable,对应的参数处理器为 PathVariableMethodArgumentResolver。注意一点是,@PathVariable 的解析是按照 value (name) 属性进行匹配,和 URL 参数的顺序是无关的。举个简单的例子:
spmvc-p-6
后台的控制器如下:
@GetMapping(value = "/user/{name}/{age}")
public String findUser1(@PathVariable(value = "age") Integer age,
@PathVariable(value = "name") String name) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
这种用法被广泛使用于 Representational State Transfer (REST) 的软件架构风格,个人觉得这种风格是比较灵活和清晰的 (从 URL 和请求方法就能完全理解接口的意义和功能)。下面再介绍两种相对特殊的使用方式。
带条件的 URL 参数
其实路径参数支持正则表达式,例如我们在使用 /sex/{sex} 接口的时候,要求 sex 必须是 F (Female) 或者 M (Male),那么我们的 URL 模板可以定义为 /sex/{sex:M|F},代码如下:
@GetMapping(value = "/sex/{sex:M|F}")
public String findUser2(@PathVariable(value = "sex") String sex){
log.info(sex);
return sex;
}
只有 /sex/F 或者 /sex/M 的请求才会进入 findUser2 控制器方法,其他该路径前缀的请求都是非法的,会返回 404 状态码。这里仅仅是介绍了一个最简单的 URL 参数正则表达式的使用方式,更强大的用法可以自行摸索。
@MatrixVariable 的使用
MatrixVariable 也是 URL 参数的一种,对应注解 @MatrixVariable,不过它并不是 URL 中的一个值 (这里的值指定是两个 "/" 之间的部分),而是值的一部分,它通过 ";" 进行分隔,通过 "=" 进行 K-V 设置。说起来有点抽象,举个例子:假如我们需要打电话给一个名字为 doge,性别是男,分组是码畜的程序员,GET 请求的 URL 可以表示为:/call/doge;gender=male;group=programmer,我们设计的控制器方法如下:
@GetMapping(value = "/call/{name}")
public String find(@PathVariable(value = "name") String name,
@MatrixVariable(value = "gender") String gender,
@MatrixVariable(value = "group") String group) {
String content = String.format("name = %s,gender = %s,group = %s", name, gender, group);
log.info(content);
return content;
}
当然,如果你按照上面的例子写好代码,尝试请求一下该接口发现是报错的:400 Bad Request - Missing matrix variable 'gender' for method parameter of type String。这是因为 @MatrixVariable 注解的使用是不安全的,在 SpringMVC 中默认是关闭对其支持。要开启对 @MatrixVariable 的支持,需要设置 RequestMappingHandlerMapping#setRemoveSemicolonContent 方法为 false:
@Configuration
public class CustomMvcConfiguration implements InitializingBean {
@Autowired
private RequestMappingHandlerMapping requestMappingHandlerMapping;
@Override
public void afterPropertiesSet() throws Exception {
requestMappingHandlerMapping.setRemoveSemicolonContent(false);
}
}
除非有很特殊的需要,否则不建议使用 @MatrixVariable。
文件上传在使用 POSTMAN 模拟请求的时候需要选择 form-data,POST 方式进行提交:
spmvc-p-8
假设我们在 D 盘有一个图片文件叫 doge.jpg,现在要通过本地服务接口把文件上传,控制器的代码如下:
@PostMapping(value = "/file1")
public String file1(@RequestPart(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
控制台输出是:
name = file1,originName = doge.jpg,size = 68727
可能有点疑惑,参数是怎么来的,我们可以用 Fildder 抓个包看下:
spmvc-p-7
可知 MultipartFile 实例的主要属性分别来自 Content-Disposition、content-type 和 content-length,另外,InputStream 用于读取请求体的最后部分 (文件的字节序列)。参数处理器用到的是 RequestPartMethodArgumentResolver (记住一点,使用了 @RequestPart 和 MultipartFile 一定是使用此参数处理器)。在其他情况下,使用 @RequestParam 和 MultipartFile 或者仅仅使用 MultipartFile (参数的名字必须和 POST 表单中的 Content-Disposition 描述的 name 一致) 也可以接收上传的文件数据,主要是通过 RequestParamMethodArgumentResolver 进行解析处理的,它的功能比较强大,具体可以看其 supportsParameter 方法,这两种情况的控制器方法代码如下:
@PostMapping(value = "/file2")
public String file2(MultipartFile file1) {
String content = String.format("name = %s,originName = %s,size = %d",
file1.getName(), file1.getOriginalFilename(), file1.getSize());
log.info(content);
return content;
}
@PostMapping(value = "/file3")
public String file3(@RequestParam(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
其他参数主要包括请求头、Cookie、Model、Map 等相关参数,还有一些并不是很常用或者一些相对原生的属性值获取 (例如 HttpServletRequest、HttpServletResponse 等) 不做讨论。
请求头的值主要通过 @RequestHeader 注解的参数获取,参数处理器是 RequestHeaderMethodArgumentResolver,需要在注解中指定请求头的 Key。简单实用如下:
spmvc-p-9
控制器方法代码:
@PostMapping(value = "/header")
public String header(@RequestHeader(name = "Content-Type") String contentType) {
return contentType;
}
Cookie 的值主要通过 @CookieValue 注解的参数获取,参数处理器为 ServletCookieValueMethodArgumentResolver,需要在注解中指定 Cookie 的 Key。控制器方法代码如下:
@PostMapping(value = "/cookie")
public String cookie(@CookieValue(name = "JSESSIONID") String sessionId) {
return sessionId;
}
Model 类型参数的处理器是 ModelMethodProcessor,实际上处理此参数是直接返回 ModelAndViewContainer 实例中的 Model (ModelMap 类型),因为要桥接不同的接口和类的功能,因此回调的实例是 BindingAwareModelMap 类型,此类型继承自 ModelMap 同时实现了 Model 接口。举个例子:
@GetMapping(value = "/model")
public String model(Model model, ModelMap modelMap) {
log.info("{}", model == modelMap);
return "success";
}
注意调用此接口,控制台输出 Info 日志内容为:true。ModelMap 或者 Model 中添加的属性项会附加到 HttpRequestServlet 中带到页面中进行渲染。
@ModelAttribute 注解处理的参数处理器为 ModelAttributeMethodProcessor,@ModelAttribute 的功能源码的注释如下:
Annotation that binds a method parameter or method return value to a named model attribute, exposed to a web view.
简单来说,就是通过 key-value 形式绑定方法参数或者方法返回值到 Model (Map) 中,区别下面三种情况:
在一个控制器 (使用了 @controller) 中,如果存在一到多个使用了 @ModelAttribute 的方法,这些方法总是在进入控制器方法之前执行,并且执行顺序是由加载顺序决定的 (具体的顺序是带参数的优先,并且按照方法首字母升序排序),举个例子:
@Slf4j
@RestController
public class ModelAttributeController {
@ModelAttribute
public void before(Model model) {
log.info("before..........");
model.addAttribute("before", "beforeValue");
}
@ModelAttribute(value = "beforeArg")
public String beforeArg() {
log.info("beforeArg..........");
return "beforeArgValue";
}
@GetMapping(value = "/modelAttribute")
public String modelAttribute(Model model, @ModelAttribute(value = "beforeArg") String beforeArg) {
log.info("modelAttribute..........");
log.info("beforeArg..........{}", beforeArg);
log.info("{}", model);
return "success";
}
@ModelAttribute
public void after(Model model) {
log.info("after..........");
model.addAttribute("after", "afterValue");
}
@ModelAttribute(value = "afterArg")
public String afterArg() {
log.info("afterArg..........");
return "afterArgValue";
}
}
调用此接口,控制台输出日志如下:
after..........
before..........
afterArg..........
beforeArg..........
modelAttribute..........
beforeArg..........beforeArgValue
{after=afterValue, before=beforeValue, afterArg=afterArgValue, beforeArg=beforeArgValue}
可以印证排序规则和参数设置、获取。
Errors 其实是 BindingResult 的父接口,BindingResult 主要用于回调 JSR 参数校验异常的属性项,如果 JSR 校验异常,一般会抛出 MethodArgumentNotValidException 异常,并且会返回 400 (Bad Request),见全局异常处理器 DefaultHandlerExceptionResolver。Errors 类型的参数处理器为 ErrorsMethodArgumentResolver。举个例子:
@PostMapping(value = "/errors")
public String errors(@RequestBody @Validated ErrorsModel errors, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
for (ObjectError objectError : bindingResult.getAllErrors()) {
log.warn("name={},message={}", objectError.getObjectName(), objectError.getDefaultMessage());
}
}
return errors.toString();
}
@Data
@NoArgsConstructor
public class ErrorsModel {
@NotNull(message = "id must not be null!")
private Integer id;
@NotEmpty(message = "errors name must not be empty!")
private String name;
}
调用接口控制台 Warn 日志如下:
name=errors,message=errors name must not be empty!
一般情况下,不建议用这种方式处理 JSR 校验异常的属性项,因为会涉及到大量的重复的硬编码工作,建议直接继承 ResponseEntityExceptionHandler,覆盖对应的方法。
控制器方法的参数可以是 @value 注解修饰的参数,会从 Environment 中装配和转换属性值到对应的参数中 (也就是参数的来源并不是请求体),参数处理器为 ExpressionValueMethodArgumentResolver。举个例子:
@GetMapping(value = "/value")
public String value(@Value(value = "${spring.application.name}") String name) {
log.info("spring.application.name={}", name);
return name;
}
Map 类型参数的范围相对比较广,对应一系列的参数处理器,注意区别使用了上面提到的部分注解的 Map 类型和完全不使用注解的 Map 类型参数,两者的处理方式不相同。下面列举几个相对典型的 Map 类型参数处理例子。
不使用任何注解的 Map<String,Object> 参数
这种情况下参数实际上直接回调 ModelAndViewContainer 中的 ModelMap 实例,参数处理器为 MapMethodProcessor,往 Map 参数中添加的属性将会带到页面中。
使用 @RequestParam 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestParamMapMethodArgumentResolver,使用的请求方式需要指定 ContentType 为 x-www-form-urlencoded,不能使用 application/json 的方式:
spmvc-p-10
控制器代码为:
@PostMapping(value = "/map")
public String mapArgs(@RequestParam Map<String, Object> map) {
log.info("{}", map);
return map.toString();
}
使用 @RequestHeader 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestHeaderMapMethodArgumentResolver,作用是获取请求的所有请求头的 Key-Value。
使用 @PathVariable 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 PathVariableMapMethodArgumentResolver,作用是获取所有路径参数封装为 Key-Value 结构。
批量文件上传的时候,我们一般需要接收一个 MultipartFile 集合,可以有两种选择:
getFiles 方法获取 MultipartFile 列表。spmvc-p-11
控制器方法代码如下:
@PostMapping(value = "/parts")
public String partArgs(@RequestParam(name = "file") List<MultipartFile> parts) {
log.info("{}", parts);
return parts.toString();
}
日期处理个人认为是请求参数处理中最复杂的,因为一般日期处理的逻辑不是通用的,过多的定制化处理导致很难有一个统一的标准处理逻辑去处理和转换日期类型的参数。不过,这里介绍几个通用的方法,以应对各种奇葩的日期格式。下面介绍的例子中全部使用 Jdk8 中引入的日期时间 API,围绕 java.util.Date 为核心的日期时间 API 的使用方式类同。
这种是最原始但是最奏效的方式,统一以字符串形式接收,然后自行处理类型转换,下面给个小例子:
@PostMapping(value = "/date1")
public String date1(@RequestBody UserDto userDto) {
UserEntity userEntity = new UserEntity();
userEntity.setUserId(userDto.getUserId());
userEntity.setBirthdayTime(LocalDateTime.parse(userDto.getBirthdayTime(), FORMATTER));
userEntity.setGraduationTime(LocalDateTime.parse(userDto.getGraduationTime(), FORMATTER));
log.info(userEntity.toString());
return "success";
}
@Data
public class UserDto {
private String userId;
private String birthdayTime;
private String graduationTime;
}
@Data
public class UserEntity {
private String userId;
private LocalDateTime birthdayTime;
private LocalDateTime graduationTime;
}
spmvc-p-12
@DateTimeFormat 注解配合 @RequestBody 的参数使用的时候,会发现抛出 InvalidFormatException 异常,提示转换失败,这是因为在处理此注解的时候,只支持 form 提交 (ContentType 为 x-www-form-urlencoded),例子如下:
spmvc-p-13
@Data
public class UserDto2 {
private String userId;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime birthdayTime;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime graduationTime;
}
@PostMapping(value = "/date2")
public String date2(UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@PostMapping(value = "/date2")
public String date2(@RequestParam("name"="userId")String userId,
@RequestParam("name"="birthdayTime")LocalDateTime birthdayTime,
@RequestParam("name"="graduationTime")LocalDateTime graduationTime) {
return "success";
}
而 @jsonformat 注解可使用在 form 或者 Json 请求参数的场景,因此更推荐使用 @jsonformat 注解,不过注意需要指定时区 (timezone 属性,例如在**是东八区 "GMT+8"),否则有可能导致出现 "时差",举个例子:
@PostMapping(value = "/date2")
public String date2(@RequestBody UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@Data
public class UserDto2 {
private String userId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime birthdayTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime graduationTime;
}
因为 SpringMVC 默认使用 Jackson 处理 @RequestBody 的参数转换,因此可以通过定制序列化器和反序列化器来实现日期类型的转换,这样我们就可以使用 application/json 的形式提交请求参数。这里的例子是转换请求 Json 参数中的字符串为 LocalDateTime 类型,属于 Json 反序列化,因此需要定制反序列化器:
@PostMapping(value = "/date3")
public String date3(@RequestBody UserDto3 userDto3) {
log.info(userDto3.toString());
return "success";
}
@Data
public class UserDto3 {
private String userId;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime birthdayTime;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime graduationTime;
}
public class CustomLocalDateTimeDeserializer extends LocalDateTimeDeserializer {
public CustomLocalDateTimeDeserializer() {
super(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
}
前面三种方式都存在硬编码等问题,其实最佳实践是直接修改 MappingJackson2HttpMessageConverter 中的 ObjectMapper 对于日期类型处理默认的序列化器和反序列化器,这样就能全局生效,不需要再使用其他注解或者定制序列化方案 (当然,有些时候需要特殊处理定制),或者说,在需要特殊处理的场景才使用其他注解或者定制序列化方案。使用钩子接口 Jackson2ObjectMapperBuilderCustomizer 可以实现 ObjectMapper 的属性定制:
@Bean
public Jackson2ObjectMapperBuilderCustomizer jackson2ObjectMapperBuilderCustomizer(){
return customizer->{
customizer.serializerByType(LocalDateTime.class,new LocalDateTimeSerializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
customizer.deserializerByType(LocalDateTime.class,new LocalDateTimeDeserializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
};
}
这样就能定制化 MappingJackson2HttpMessageConverter 中持有的 ObjectMapper,上面的 LocalDateTime 序列化和反序列化器对全局生效。
前面基本介绍完了主流的请求参数处理,其实 SpringMVC 中还会按照 URL 的模式进行匹配,使用的是 Ant 路径风格,处理工具类为 org.springframework.util.AntPathMatcher,从此类的注释来看,匹配规则主要包括下面四点:
? 匹配 1 个字符。* 匹配 0 个或者多个字符。** 匹配路径中 0 个或者多个目录。{spring:[a-z]+} 将正则表达式 [a-z]+ 匹配到的值,赋值给名为 spring 的路径变量。举些例子:
? 形式的 URL:
@GetMapping(value = "/pattern?")
public String pattern() {
return "success";
}
/pattern 404 Not Found
/patternd 200 OK
/patterndd 404 Not Found
/pattern/ 404 Not Found
/patternd/s 404 Not Found
* 形式的 URL:
@GetMapping(value = "/pattern*")
public String pattern() {
return "success";
}
/pattern 200 OK
/pattern/ 200 OK
/patternd 200 OK
/pattern/a 404 Not Found
** 形式的 URL:
@GetMapping(value = "/pattern/**/p")
public String pattern() {
return "success";
}
/pattern/p 200 OK
/pattern/x/p 200 OK
/pattern/x/y/p 200 OK
{spring:[a-z]+} 形式的 URL:
@GetMapping(value = "/pattern/{key:[a-c]+}")
public String pattern(@PathVariable(name = "key") String key) {
return "success";
}
/pattern/a 200 OK
/pattern/ab 200 OK
/pattern/abc 200 OK
/pattern 404 Not Found
/pattern/abcd 404 Not Found
上面的四种 URL 模式可以组合使用,千变万化。
URL 匹配还遵循精确匹配原则,也就是存在两个模式对同一个 URL 都能够匹配成功,则选取最精确的 URL 匹配,进入对应的控制器方法,举个例子:
@GetMapping(value = "/pattern/**/p")
public String pattern1() {
return "success";
}
@GetMapping(value = "/pattern/p")
public String pattern2() {
return "success";
}
上面两个控制器,如果请求 URL 为 /pattern/p,最终进入的方法为 pattern2。
最后,org.springframework.util.AntPathMatcher 作为一个工具类,可以单独使用,不仅仅可以用于匹配 URL,也可以用于匹配系统文件路径,不过需要使用其带参数构造改变内部的 pathSeparator 变量,例如:
AntPathMatcher antPathMatcher = new AntPathMatcher(File.separator);
笔者在前一段时间曾经花大量时间梳理和分析过 Spring、SpringMVC 的源码,但是后面一段很长的时间需要进行业务开发,对架构方面的东西有点生疏了,毕竟东西不用就会生疏,这个是常理。这篇文章基于一些 SpringMVC 的源码经验总结了请求参数的处理相关的一些知识,希望帮到自己和大家。
参考资料:
(本文完)
更多精彩内容,就在简书 APP
"如果觉得我的文章对您有用,请随意打赏。你的支持和鼓励是我前进动力的一部分"
还没有人赞赏,支持一下
总资产 10 共写了 5.2W 字获得 223 个赞共 178 个粉丝
Spring Web MVC Spring Web MVC 是包含在 Spring 框架中的 Web 框架,建立于...
Spring Cloud 为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智...
首先, Promise 并不是发源于 javascript, 它最早被提出于 E 语言中. 那到底什么是 Promise, 它是抽...
最近看大陆鬼片类电影很难看到真正的 “鬼片”,结尾大多是主角因为有精神分裂症、被害妄想症等产生的“鬼” 的幻觉。整部剧...
林原雪狐阅读 895 评论 0 赞 0
https://www.jianshu.com/p/5f6abd08ee08
本文属于《算法图解》系列。学习动态规划,这是一种解决棘手问题的方法,它将问题分成小问题,并先着手解决这些小问题。
背包问题,在可装物品有限的前提下,尽量装价值最大的物品,如果物品数量足够大,简单的暴力穷举法是不可行的 O(2ⁿ), 前一章介绍了《贪婪算法》就是解决如何找到近似解,这接近最优解,但可能不是最优解。如何找到最优解呢?就是动态规划算法。动态规划先解决子问题,再逐步解决大问题。
每个动态规划算法都从一个网格开始,背包问题的网格如下。
网格的各行为商品,各列为不同容量(1~4 磅)的背包。所有这些列你都需要,因为它们将帮助你计算子背包的价值。网格最初是空的。你将填充其中的每个单元格,网格填满后,就找到了问题的答案。
1 吉他行
这是第一行,只有吉他可供你选择。第一个单元格表示背包的容量为 1 磅。吉他的重量也是 1 磅,这意味着它能装入背包!因此这个单元格包含吉他,价值为 1500 美元。来看下一个单元格。这个单元格表示背包的容量为 2 磅,完全能够装下吉他!以此类推。
你知道这不是最终的解。随着算法往下执行,你将逐步修改最大价值。
2 音响行
可选的有吉他和音响。在每一行, 可选的商品都为当前行的商品以及之前各行的商品。
背包的容量为 1 磅,能装下音响吗?音响太重了,装不下!由于容量 1 磅的背包装不下音响, 因此最大价值依然是 1500 美元。接下来的两个单元格的情况与此相同,背包容量为 4 磅呢?终于能够装下音响了!
3 笔记本电脑行
下面以同样的方式处理笔记本电脑。笔记本电脑重 3 磅,没法将其装入容量为 1 磅或 2 磅的背 包,因此前两个单元格的最大价值还是 1500 美元。对于容量为 3 磅的背包,可选笔记本电脑而不是吉他,这样新的最大价值将为 2000 美元!
对于容量为 4 磅的背包,情况很有趣。这是非常重要的部分。当前的最大价值为 3000 美元,选择笔记本电脑 2000 美元,还有 1 磅空间没用使用。根据之前计算的最大价值可知,在 1 磅的容量中可装入吉他,价值 1500 美元。因此,你需要做如下比较。
为何计算小背包可装入的商品的最大价值呢?因为余下了空间时,你可根据这些子问题的答案来确定余下的空间可装入哪些商品。笔记本电脑和吉他的总价值为 3500 美元,最终的网格类似于下面这样。
你可能认为,计算最后一个单元格的价值时,我使用了不同的公式。那是因为填充之前的单元格时,我故意避开了一些复杂的因素。其实,计算每个单元格的价值时,使用的公式都相同。 这个公式如下。
你可以使用这个公式来计算每个单元格的价值,最终的网格将与前一个网格相同。现在你明 白了为何要求解子问题吧?你可以合并两个子问题的解来得到更大问题的解。
假设你还选择一件商品:iPhone
此时需要重新执行前面所做的计算吗?不需要。别忘了,动态规划 逐步计算最大价值。
沿着一列往下走时,最大价值有可能降低吗?
答案:不可能。每次迭代时,你都存储当前的最大价值。最大价值不可能比以前低!
练习:假设你还可以选择 ——MP3 播放器,它重 1 磅,价值 1000 美元。你会选择吗?
不会。
假设你按如下顺序填充各行:音响、笔记本电脑、吉他。网格将会是什么样的?请自己动手填充这个网格,再接着往下读。
答案没有变化。也就是说,各行的排列顺序无关紧要。
自己动手试试吧!
这里推荐一个网站:http://karaffeltut.com/NEWKaraffeltutCom/Knapsack/knapsack.html
需要重新调整网格,计算的单位更新如(0.5)。可以自己动手验证下。
如果想这种情况下。只装商品的一部分。如何使用动态规划来处 理这种情形呢?
答案是没法处理。使用动态规划时,要么考虑拿走整件商品,要么考虑不拿,而没法判断该不该拿走商品的一部分。
但使用贪婪算法可轻松地处理这种情况!首先,尽可能多地拿价值最高的商品;如果拿光了, 再尽可能多地拿价值次高的商品,以此类推。
假设你要去伦敦度假,假期两天,但你想去游览的地方很多。你没法前往每个地方游览,因此你列个单子。
这也是一个背包问题!但约束条件不是背包的容量,而是有限的时间;不是决定该装入哪些 商品,而是决定该去游览哪些名胜。请根据这个清单绘制动态规划网格。
当我在纸上画这个网格,逐个元素去填值计算的时候,边上的土豪 QA 妹子,应该不应这么纠结,多待两天都逛完了。可见钱能解决 90% 的问题。
假设你还想去巴黎,因此在前述清单中又添加了几项。
去这些地方游览需要很长时间,因为你先得从伦敦前往巴黎,这需要半天时间。如果这 3 个地方都去玩,是不是要 4.5 天呢?
不是的,因为不是去每个地方都得先从伦敦到巴黎。到达巴黎后,每个地方都只需 1 天时间。
因此玩这 3 个地方需要的总时间为 3.5 天(半天从伦敦到巴黎,每个地方 1 天),而不是 4.5 天。
将埃菲尔铁塔加入 “背包” 后,卢浮宫将更 “便宜”:只要 1 天时间,而不是 1.5 天。如何使 用动态规划对这种情况建模呢?
没办法建模。动态规划功能强大,它能够解决子问题并使用这些答案来解决大问题。但仅当 每个子问题都是离散的,即不依赖于其他子问题时,动态规划才管用。
但根据动态规划算法的设计,最多只需合并两个子背包,即根本不会涉及两个以上的子背包。不过这些子背包可能又包含子背包。
完全可能,假设你选了一个 3.5 磅的钻石。
练习:
假设你要去野营。你有一个容量为 6 磅的背包,需要决定该携带下面的哪些东西。其中每样东西都有相应的价值,价值越大意味着越重要:
我推导的结果:水 + 食物 + 相机 = 25
最后附上一版本 Java 解决背包问题。
public class FindMaxTest {static String[] names= {"","sound","laptop","guita","phone"};static int[] w = {0,4, 3, 1,1 };static int[] v = {0,3000,2000,1500,2000}; static int[][] b = new int[5][5];public static void main(String[] args) {for (int i = 1; i <= 4; i++) {for (int j = 1; j <= 4; j++) {int value1 = v[i] + b[i - 1][j - w[i]] ; int value2 = b[i - 1][j]; b[i][j] = Math.max(value1, value2); System.out.println("value:"+b[4][4]);public static void findMax(int i,int j){ System.out.println("not choose :"+names[i]+",value="+v[i]);else if( b[i][j]==(v[i] + b[i - 1][j - w[i]]) ){ System.out.println("choose :"+names[i]+",value="+v[i]);```
运行结果:
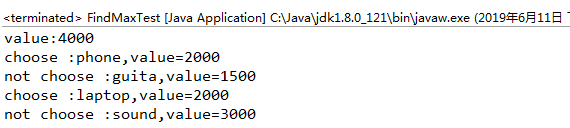
背包问题已经解决,利用动态规划解决此问题的效率即是填写此张表的效率,所以动态规划的时间效率为 O (number\*capacity)=O (n\*c),由于用到二维数组存储子问题的解,所以动态规划的空间效率为 O (n\*c)。
注意下一些代码细节,例子画的网格图是为了便于理解,实际 demo Java 取的数组是从 0 开始的。所以数组的比图上的网格多加了一行,一列的 0 的数组,无实际意义,纯粹为了填空格使用。还有网上有优化算法,二维数组转一维数组,只为了求值优化,但是不能找到最优组合选择的元素。感兴趣的可以试验下。
[https://blog.csdn.net/bohu83/article/details/91453227](https://blog.csdn.net/bohu83/article/details/91453227)
0.1892019.03.06 00:07:12 字数 2,917 阅读 11,150
代理模式:代理模式又叫委托模式,是为某个对象提供一个代理对象,并且由代理对象控制对原对象的访问。代理模式通俗来讲就是我们生活中常见的中介。
代理模式可以提供非常好的访问控制,应用比较广泛。
举个例子来说明:假如说我现在想买一辆二手车,虽然我可以自己去找车源,做质量检测等一系列的车辆过户流程,但是这确实太浪费我得时间和精力了。我只是想买一辆车而已为什么我还要额外做这么多事呢?于是我就通过中介公司来买车,他们来给我找车源,帮我办理车辆过户流程,我只是负责选择自己喜欢的车,然后付钱就可以了。
代理模式的通用类图:
代理模式的通用类图
一个代理类可以代理多个被委托者或被代理者,因此一个代理类具体代理哪个具体主题角色,是由场景类决定的。最简单的情况是一个主题类和一个代理类。通常情况下,一个接口只需要一个代理类,具体代理哪个实现类有高层模块决定。
代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后对返回结果的处理等。代理类本身并不真正实现服务,而是通过调用委托类的相关方法,来提供特定的服务。真正的业务功能还是由委托类来实现,但是可以在业务功能执行的前后加入一些公共的服务。例如我们想给项目加入缓存、日志这些功能,我们就可以使用代理类来完成,而没必要打开已经封装好的委托类。
为了保持行为的一致性,代理类和委托类通常会实现相同的接口,所以在访问者看来两者没有丝毫的区别。通过代理类这中间一层,能有效控制对委托类对象的直接访问,也可以很好地隐藏和保护委托类对象,同时也为实施不同控制策略预留了空间,从而在设计上获得了更大的灵活性。
更通俗的说,代理解决的问题是:当两个类需要通信时,引入第三方代理类,将两个类的关系解耦,让我们只了解代理类即可,而且代理的出现还可以让我们完成与另一个类之间的关系的统一管理。但是切记,代理类和委托类要实现相同的接口,因为代理真正调用的还是委托类的方法。
代理模式有多种不同的实现方式。如果按照代理创建的时期来进行分类:静态代理、动态代理。
抽象主题类
public interface Subject {
public void request();
}
具体主题类
public class ConcreteSubject implements Subject {
@Override
public void request() {
}
}
代理类
public class Proxy implements Subject {
private Subject subject = null;
public Proxy() {
this.subject = new Proxy();
}
public Proxy(Subject subject) {
this.subject = subject;
}
public Proxy(Object... objects) {
}
@Override
public void request() {
this.before();
this.subject.request();
this.after();
}
private void before() {
}
private void after() {
}
}
客户端类
public class Client {
public static void main(String[] args) {
Subject subject = new ConcreteSubject();
Proxy proxy = new Proxy(subject);
proxy.request();
}
}
静态代理优缺点
Subject subject = new ConcreteSubject(); Proxy proxy = new Proxy(subject); 可以应用工厂方法将它隐藏。从静态代理会发现 —— 每个代理类只能为一个接口服务,这样程序开发中必然会产生许多的代理类。所以我们想办法通过一个代理类完成全部的代理功能,那么我们就需要用动态代理.
在上面 4.1 的示例中,一个代理只能代理一种类型,而且是在编译器就已经确定被代理的对象。而动态代理是在运行时,通过反射机制实现动态代理,并且能够代理各种类型的对象。
在 Java 中要想实现动态代理机制,需要 java.lang.reflect.InvocationHandler 接口和 java.lang.reflect.Proxy 类的支持。
java.lang.reflect.InvocationHandler 接口的定义
package java.lang.reflect;
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}
参数解释:
java.lang.reflect.Proxy 类的定义
public class Proxy implements java.io.Serializable {
private static final long serialVersionUID = -2222568056686623797L;
private static final Class<?>[] constructorParams =
{ InvocationHandler.class };
private static final WeakCache<ClassLoader, Class<?>[], Class<?>>
proxyClassCache = new WeakCache<>(new KeyFactory(), new ProxyClassFactory());
protected InvocationHandler h;
private Proxy() {
}
protected Proxy(InvocationHandler h) {
Objects.requireNonNull(h);
this.h = h;
}
@CallerSensitive
public static Class<?> getProxyClass(ClassLoader loader,
Class<?>... interfaces)
throws IllegalArgumentException
{
final Class<?>[] intfs = interfaces.clone();
final SecurityManager sm = System.getSecurityManager();
if (sm != null) {
checkProxyAccess(Reflection.getCallerClass(), loader, intfs);
}
return getProxyClass0(loader, intfs);
}
private static void checkProxyAccess(Class<?> caller,
ClassLoader loader,
Class<?>... interfaces)
{
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
ClassLoader ccl = caller.getClassLoader();
if (VM.isSystemDomainLoader(loader) && !VM.isSystemDomainLoader(ccl)) {
sm.checkPermission(SecurityConstants.GET_CLASSLOADER_PERMISSION);
}
ReflectUtil.checkProxyPackageAccess(ccl, interfaces);
}
}
private static Class<?> getProxyClass0(ClassLoader loader,
Class<?>... interfaces) {
if (interfaces.length > 65535) {
throw new IllegalArgumentException("interface limit exceeded");
}
return proxyClassCache.get(loader, interfaces);
}
private static final Object key0 = new Object();
private static final class Key1 extends WeakReference<Class<?>> {
private final int hash;
Key1(Class<?> intf) {
super(intf);
this.hash = intf.hashCode();
}
@Override
public int hashCode() {
return hash;
}
@Override
public boolean equals(Object obj) {
Class<?> intf;
return this == obj ||
obj != null &&
obj.getClass() == Key1.class &&
(intf = get()) != null &&
intf == ((Key1) obj).get();
}
}
private static final class Key2 extends WeakReference<Class<?>> {
private final int hash;
private final WeakReference<Class<?>> ref2;
Key2(Class<?> intf1, Class<?> intf2) {
super(intf1);
hash = 31 * intf1.hashCode() + intf2.hashCode();
ref2 = new WeakReference<Class<?>>(intf2);
}
@Override
public int hashCode() {
return hash;
}
@Override
public boolean equals(Object obj) {
Class<?> intf1, intf2;
return this == obj ||
obj != null &&
obj.getClass() == Key2.class &&
(intf1 = get()) != null &&
intf1 == ((Key2) obj).get() &&
(intf2 = ref2.get()) != null &&
intf2 == ((Key2) obj).ref2.get();
}
}
private static final class KeyX {
private final int hash;
private final WeakReference<Class<?>>[] refs;
@SuppressWarnings("unchecked")
KeyX(Class<?>[] interfaces) {
hash = Arrays.hashCode(interfaces);
refs = (WeakReference<Class<?>>[])new WeakReference<?>[interfaces.length];
for (int i = 0; i < interfaces.length; i++) {
refs[i] = new WeakReference<>(interfaces[i]);
}
}
@Override
public int hashCode() {
return hash;
}
@Override
public boolean equals(Object obj) {
return this == obj ||
obj != null &&
obj.getClass() == KeyX.class &&
equals(refs, ((KeyX) obj).refs);
}
private static boolean equals(WeakReference<Class<?>>[] refs1,
WeakReference<Class<?>>[] refs2) {
if (refs1.length != refs2.length) {
return false;
}
for (int i = 0; i < refs1.length; i++) {
Class<?> intf = refs1[i].get();
if (intf == null || intf != refs2[i].get()) {
return false;
}
}
return true;
}
}
private static final class KeyFactory
implements BiFunction<ClassLoader, Class<?>[], Object>
{
@Override
public Object apply(ClassLoader classLoader, Class<?>[] interfaces) {
switch (interfaces.length) {
case 1: return new Key1(interfaces[0]);
case 2: return new Key2(interfaces[0], interfaces[1]);
case 0: return key0;
default: return new KeyX(interfaces);
}
}
}
private static final class ProxyClassFactory
implements BiFunction<ClassLoader, Class<?>[], Class<?>>
{
private static final String proxyClassNamePrefix = "$Proxy";
private static final AtomicLong nextUniqueNumber = new AtomicLong();
@Override
public Class<?> apply(ClassLoader loader, Class<?>[] interfaces) {
Map<Class<?>, Boolean> interfaceSet = new IdentityHashMap<>(interfaces.length);
for (Class<?> intf : interfaces) {
Class<?> interfaceClass = null;
try {
interfaceClass = Class.forName(intf.getName(), false, loader);
} catch (ClassNotFoundException e) {
}
if (interfaceClass != intf) {
throw new IllegalArgumentException(
intf + " is not visible from class loader");
}
if (!interfaceClass.isInterface()) {
throw new IllegalArgumentException(
interfaceClass.getName() + " is not an interface");
}
if (interfaceSet.put(interfaceClass, Boolean.TRUE) != null) {
throw new IllegalArgumentException(
"repeated interface: " + interfaceClass.getName());
}
}
String proxyPkg = null;
int accessFlags = Modifier.PUBLIC | Modifier.FINAL;
for (Class<?> intf : interfaces) {
int flags = intf.getModifiers();
if (!Modifier.isPublic(flags)) {
accessFlags = Modifier.FINAL;
String name = intf.getName();
int n = name.lastIndexOf('.');
String pkg = ((n == -1) ? "" : name.substring(0, n + 1));
if (proxyPkg == null) {
proxyPkg = pkg;
} else if (!pkg.equals(proxyPkg)) {
throw new IllegalArgumentException(
"non-public interfaces from different packages");
}
}
}
if (proxyPkg == null) {
proxyPkg = ReflectUtil.PROXY_PACKAGE + ".";
}
long num = nextUniqueNumber.getAndIncrement();
String proxyName = proxyPkg + proxyClassNamePrefix + num;
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(
proxyName, interfaces, accessFlags);
try {
return defineClass0(loader, proxyName,
proxyClassFile, 0, proxyClassFile.length);
} catch (ClassFormatError e) {
throw new IllegalArgumentException(e.toString());
}
}
}
@CallerSensitive
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
{
Objects.requireNonNull(h);
final Class<?>[] intfs = interfaces.clone();
final SecurityManager sm = System.getSecurityManager();
if (sm != null) {
checkProxyAccess(Reflection.getCallerClass(), loader, intfs);
}
Class<?> cl = getProxyClass0(loader, intfs);
try {
if (sm != null) {
checkNewProxyPermission(Reflection.getCallerClass(), cl);
}
final Constructor<?> cons = cl.getConstructor(constructorParams);
final InvocationHandler ih = h;
if (!Modifier.isPublic(cl.getModifiers())) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
cons.setAccessible(true);
return null;
}
});
}
return cons.newInstance(new Object[]{h});
} catch (IllegalAccessException|InstantiationException e) {
throw new InternalError(e.toString(), e);
} catch (InvocationTargetException e) {
Throwable t = e.getCause();
if (t instanceof RuntimeException) {
throw (RuntimeException) t;
} else {
throw new InternalError(t.toString(), t);
}
} catch (NoSuchMethodException e) {
throw new InternalError(e.toString(), e);
}
}
private static void checkNewProxyPermission(Class<?> caller, Class<?> proxyClass) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
if (ReflectUtil.isNonPublicProxyClass(proxyClass)) {
ClassLoader ccl = caller.getClassLoader();
ClassLoader pcl = proxyClass.getClassLoader();
int n = proxyClass.getName().lastIndexOf('.');
String pkg = (n == -1) ? "" : proxyClass.getName().substring(0, n);
n = caller.getName().lastIndexOf('.');
String callerPkg = (n == -1) ? "" : caller.getName().substring(0, n);
if (pcl != ccl || !pkg.equals(callerPkg)) {
sm.checkPermission(new ReflectPermission("newProxyInPackage." + pkg));
}
}
}
}
public static boolean isProxyClass(Class<?> cl) {
return Proxy.class.isAssignableFrom(cl) && proxyClassCache.containsValue(cl);
}
@CallerSensitive
public static InvocationHandler getInvocationHandler(Object proxy)
throws IllegalArgumentException
{
if (!isProxyClass(proxy.getClass())) {
throw new IllegalArgumentException("not a proxy instance");
}
final Proxy p = (Proxy) proxy;
final InvocationHandler ih = p.h;
if (System.getSecurityManager() != null) {
Class<?> ihClass = ih.getClass();
Class<?> caller = Reflection.getCallerClass();
if (ReflectUtil.needsPackageAccessCheck(caller.getClassLoader(),
ihClass.getClassLoader()))
{
ReflectUtil.checkPackageAccess(ihClass);
}
}
return ih;
}
private static native Class<?> defineClass0(ClassLoader loader, String name,
byte[] b, int off, int len);
}
其中,最重要的方法是
@CallerSensitive
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
参数说明:
抽象主题类
public interface Subject {
public void request();
}
具体主题类
public class ConcreteSubject implements Subject {
@Override
public void request() {
}
}
动态创建代理对象的类
动态代理类只能代理接口(不支持抽象类),代理类都需要实现 InvocationHandler 类,实现 invoke 方法。invoke 方法就是调用被代理接口的所有方法时需要调用的,返回的值是被代理接口的一个实现类。
package com.jerry.microservice.cloud.service.proxy.dynamic;
import lombok.extern.slf4j.Slf4j;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
@slf4j
public class ProxyHandler implements InvocationHandler {
private Object target;
public Object newProxyInstance(Object target) {
this.target = target;
Object result = Proxy.newProxyInstance(target.getClass().getClassLoader(),
target.getClass().getInterfaces(), this);
return result;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object ret = null;
try {
ret = method.invoke(target, args);
} catch (Exception e) {
log.error("调用{}.{}发生异常", target.getClass().getName(), method.getName(), e);
throw e;
}
return ret;
}
}
被代理对象 target 通过参数传递进来,我们通过 target.getClass().getClassLoader() 获取 ClassLoader 对象,然后通过 target.getClass().getInterfaces() 获取它实现的所有接口,然后将 target 包装到实现了 InvocationHandler 接口的 ProxyHandler 实现对象中。通过 newProxyInstance 函数我们就获得了一个动态代理对象。
客户端类
@slf4j
public class Client {
public static void main(String[] args) {
log.info("开始");
ProxyHandler handler = new ProxyHandler();
Subject subject = (Subject) handler.newProxyInstance(new ConcreteSubject());
subject.request();
log.info("结束");
}
}
可以看到,我们可以通过 ProxyHandler 代理不同类型的对象,如果我们把对外的接口都通过动态代理来实现,那么所有的函数调用最终都会经过 invoke 函数的转发,因此我们就可以在这里做一些自己想做的操作,比如日志系统、事务、拦截器、权限控制等。
当前非常流行的面向切面的编程 (Aspect Oriented Programming, AOP),其核心就是动态代理机制。
备注:
要实现动态代理的首要条件:被代理类必须实现一个接口,才能被代理。
(现在还有 CGLIB 可以实现不用实现接口也可以实现动态代理。后续研究)
InvocationHandler.invoke)。这样,在接口方法数量比较多的时候,我们可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。而且动态代理的应用使我们的类职责更加单一,复用性更强。代理模式使用广泛,尤其是动态代理在大型开发框架中,应用较多并且高效。特别是使用 AOP,实现代理模式就更方便了,比如使用 Spring AOP 和 AspectJ 这样的工具。
在使用 AOP 框架时,需要关注几个名词:
更多精彩内容,就在简书 APP
"各位如果内容你觉得内容有帮助,请不吝给作者晚上添加一只鸡腿。"
还没有人赞赏,支持一下
总资产 5 共写了 5.7W 字获得 50 个赞共 19 个粉丝
设计模式是语言的表达方式,它能让语言轻便而富有内涵、易读却功能强大。代理模式在 Java 中十分常见,有为扩展某些类的...
原文连接 简介 Java 编程的目标是实现现实不能完成的,优化现实能够完成的,是一种虚拟技术。生活中的方方面面都可以...
代理模式的定义:代理模式给某一个对象提供一个代理对象,并由代理对象控制对 原对象 的引用。 通俗的来讲代理...
代码之尖阅读 448 评论 0 赞 49
声明:原创作品,转载请注明出处 https://www.jianshu.com/p/e4c1e6b734ad 今天来...
蛇发女妖阅读 1,224 评论 3 赞 7
引子 今天在学 netty 相关的内容的时候,知道了 netty 是 RPC(远程过程调用)的一种实现,就想深入了解一下 RP...
云师兄阅读 97 评论 0 赞 0
https://www.jianshu.com/p/9cdcf4e5c27d
本文包含了多线程基础、synchronized、ThreadLocal、ReentrantLock、volatile 、线程池、AQS 和原子类的多线程常见面试题。
共 50 道,接近 2w 字,收藏点赞再看吧~
本文目录:
我总结的 500 道大厂高频面试题 pdf,百度云链接 (复制到浏览器打开):https://pan.baidu.com/s/1k5FghNZCjD9pPIlvUQTQwQ
提取码:6666
线程具有许多传统进程所具有的特征,故又称为轻型进程 (Light—Weight Process) 或进程元;而把传统的进程称为重型进程 (Heavy—Weight Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口。顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
1)采用实现 Runnable. Callable 接口的方式创建多线程。
优势是:
线程类只是实现了 Runnable 接口或 Callable 接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个 target 对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将 CPU. 代码和数据分开,形成清晰的模型,较好地体现了面向对象的**。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用 Thread.currentThread () 方法。
2)使用继承 Thread 类的方式创建多线程
优势是:
编写简单,如果需要访问当前线程,则无需使用 Thread.currentThread () 方法,直接使用 this 即可获得当前线程。
劣势是:
线程类已经继承了 Thread 类,所以不能再继承其他父类。
3)Runnable 和 Callable 的区别
从计算机底层来说:
线程的生命周期及五种基本状态:
Java 线程具有五中基本状态
1)新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread ();
2)就绪状态(Runnable):当调用线程对象的 start () 方法(t.start ();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待 CPU 调度执行,并不是说执行了 t.start () 此线程立即就会执行;
3)运行状态(Running):当 CPU 开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
4)阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对 CPU 的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被 CPU 调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
等待阻塞:运行状态中的线程执行 wait () 方法,使本线程进入到等待阻塞状态;
同步阻塞 — 线程在获取 synchronized 同步锁失败 (因为锁被其它线程所占用),它会进入同步阻塞状态;
其他阻塞 — 通过调用线程的 sleep () 或 join () 或发出了 I/O 请求时,线程会进入到阻塞状态。当 sleep () 状态超时. join () 等待线程终止或者超时。或者 I/O 处理完毕时,线程重新转入就绪状态。
5)死亡状态(Dead):线程执行完了或者因异常退出了 run () 方法,该线程结束生命周期。

只要破坏产生死锁的四个条件中的其中一个就可以了
Yield 方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃 CPU 占用而不能保证使其它线程一定能占用 CPU,执行 yield () 的线程有可能在进入到暂停状态后马上又被执行。
volatile 的两层语义:
volatile 的原理:
获取 JIT(即时 Java 编译器,把字节码解释为机器语言发送给处理器)的汇编代码,发现 volatile 多加了 lock addl 指令,这个操作相当于一个内存屏障,使得 lock 指令后的指令不能重排序到内存屏障前的位置。这也是为什么 JDK1.5 以后可以使用双锁检测实现单例模式。
lock 前缀的另一层意义是使得本线程工作内存中的 volatile 变量值立即写入到主内存中,并且使得其他线程共享的该 volatile 变量无效化,这样其他线程必须重新从主内存中读取变量值。
具体原理见这篇文章:https://www.javazhiyin.com/61019.html
Thread 类本质上是实现 Runnable 接口的一个实例,代表一个线程的实例。创建线程实例一般有两种方法:
run () 方在调用 start () 方法后被执行,而且一旦线程启动后 start () 方法后就会立即返回,而不是等到 run () 方法执行完毕后再返回。
在新建类时实现 Runnable 接口,然后在 Thread 类的构造函数中传入 MyRunnable 的实例对象,最后执行 start () 方法即可;
当线程因为某种原因放弃 CPU 使用权后,即让出了 CPU 时间片,暂时就会停止运行,知道线程进入可运行状态(Runnable),才有机会再次获得 CPU 时间片转入 RUNNING 状态。一般来讲,阻塞的情况可以分为如下三种:
RUNNING 状态的线程执行 Object.wait () 方法后,JVM 会将线程放入等待序列(waitting queue);
RUNNING 状态的线程在获取对象的同步锁时,若该 同步锁被其他线程占用,则 JVM 将该线程放入锁池(lock pool)中;
RUNNING 状态的线程执行 Thread.sleep (long ms) 或 Thread.join () 方法,或发出 I/O 请求时,JVM 会将该线程置为阻塞状态。当 sleep () 状态超时,join () 等待线程终止或超时。或者 I/O 处理完毕时,线程重新转入可运行状态(RUNNABLE);
run () 或者 call () 方法执行完成后,线程正常结束;
线程抛出一个未捕获的 Exception 或 Error,导致线程异常结束;
直接调用线程的 stop () 方法来结束该线程,但是一般不推荐使用该种方式,因为该方法通常容易导致死锁;
JVM 执行 start 方 *** 另起一条线程执行 thread 的 run 方法,这才起到多线程的效果~
如果直接调用 Thread 的 run () 方法,其方法还是运行在主线程中,没有起到多线程效果。
守护线程是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。在 Java 中垃圾回收线程就是特殊的守护线程。
Fork/Join 框架是 Java7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join 框架需要理解两个点,「分而治之」和「工作窃取算法」。
「分而治之」
以上 Fork/Join 框架的定义,就是分而治之**的体现啦
「工作窃取算法」
把大任务拆分成小任务,放到不同队列执行,交由不同的线程分别执行时。有的线程优先把自己负责的任务执行完了,其他线程还在慢慢悠悠处理自己的任务,这时候为了充分提高效率,就需要工作 *** 算法啦~
工作 * 算法就是,「某个线程从其他队列中窃取任务进行执行的过程」。一般就是指做得快的线程(* 线程)抢慢的线程的任务来做,同时为了减少锁竞争,通常使用双端队列,即快线程和慢线程各在一端。
CAS 并发原语体现在 Java 语言中的 sum.misc.Unsafe 类中的各个方法。调用 Unsafe 类中的 CAS 方法, JVM 会帮助我们实现出 CAS 汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于 CAS 是一种系统原语,原语属于操作系统用于范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,CAS 是一条 CPU 的原子指令,不会造成数据不一致问题。
1. ABA 问题
并发环境下,假设初始条件是 A,去修改数据时,发现是 A 就会执行修改。但是看到的虽然是 A,中间可能发生了 A 变 B,B 又变回 A 的情况。此时 A 已经非彼 A,数据即使成功修改,也可能有问题。
可以通过 AtomicStampedReference 解决 ABA 问题,它,一个带有标记的原子引用类,通过控制变量值的版本来保证 CAS 的正确性。
2. 循环时间长开销
自旋 CAS,如果一直循环执行,一直不成功,会给 CPU 带来非常大的执行开销。
很多时候,CAS **体现,是有个自旋次数的,就是为了避开这个耗时问题~
3. 只能保证一个变量的原子操作。
CAS 保证的是对一个变量执行操作的原子性,如果对多个变量操作时,CAS 目前无法直接保证操作的原子性的。
可以通过这两个方式解决这个问题:
volatile 解决的是内存可见性问题,会使得所有对 volatile 变量的读写都直接写入主存,即 保证了变量的可见性。
synchronized 解决的事执行控制的问题,它会阻止其他线程获取当前对象的监控锁,这样一来就让当前对象中被 synchronized 关键字保护的代码块无法被其他线程访问,也就是无法并发执行。而且,synchronized 还会创建一个 内存屏障,内存屏障指令保证了所有 CPU 操作结果都会直接刷到主存中,从而 保证操作的内存可见性,同时也使得这个锁的线程的所有操作都 happens-before 于随后获得这个锁的线程的操作。
两者的区别主要有如下:
1. 两者都是可重入锁
可重入锁:重入锁,也叫做递归锁,可重入锁指的是在一个线程中可以多次获取同一把锁,比如: 一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法,而无需重新获得锁, 两者都是同一个线程每进入一次,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
3.ReentrantLock 比 synchronized 增加了一些高级功能
相比 synchronized,ReentrantLock 增加了一些高级功能。主要来说主要有三点:①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)
4. 使用选择
特别注意:
①如果一个线程 A 调用一个实例对象的非静态 synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁
②尽量不要使用 synchronized (String s) , 因为 JVM 中,字符串常量池具有缓冲功能
synchronized 同步代码块的实现是通过 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor (monitor 对象存在于每个 Java 对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么 Java 中任意对象可以作为锁的原因) 的持有权。
其内部包含一个计数器,当计数器为 0 则可以成功获取,获取后将锁计数器设为 1 也就是加 1。相应的在执行 monitorexit 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
synchronized 锁升级原理:在锁对象的对象头里面有一个 threadid 字段,在第一次访问的时候 threadid 为空,jvm 让其持有偏向锁,并将 threadid 设置为其线程 id,再次进入的时候会先判断 threadid 是否与其线程 id 一致,如果一致则可以直接使用此对象,如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁,执行一定次数之后,如果还没有正常获取到要使用的对象,此时就会把锁从轻量级升级为重量级锁,此过程就构成了 synchronized 锁的升级。
锁的升级的目的:锁升级是为了减低了锁带来的性能消耗。在 Java 6 之后优化 synchronized 的实现方式,使用了偏向锁升级为轻量级锁再升级到重量级锁的方式,从而减低了锁带来的性能消耗。
synchronized 的非公平其实在源码中应该有不少地方,因为设计者就没按公平锁来设计,核心有以下几个点:
1)当持有锁的线程释放锁时,该线程会执行以下两个重要操作:
在 1 和 2 之间,如果有其他线程刚好在尝试获取锁(例如自旋),则可以马上获取到锁。
2)当线程尝试获取锁失败,进入阻塞时,放入链表的顺序,和最终被唤醒的顺序是不一致的,也就是说你先进入链表,不代表你就会先被唤醒。
从最近几个 jdk 版本中可以看出,Java 的开发团队一直在对 synchronized 优化,其中最大的一次优化就是在 jdk6 的时候,新增了两个锁状态,通过锁消除、锁粗化、自旋锁等方法使用各种场景,给 synchronized 性能带来了很大的提升。
上面讲到锁有四种状态,并且会因实际情况进行膨胀升级,其膨胀方向是:无锁 ——> 偏向锁 ——> 轻量级锁 ——> 重量级锁,并且膨胀方向不可逆。
一句话总结它的作用:减少统一线程获取锁的代价。在大多数情况下,锁不存在多线程竞争,总是由同一线程多次获得,那么此时就是偏向锁。
核心**:
如果一个线程获得了锁,那么锁就进入偏向模式,此时 Mark Word 的结构也就变为偏向锁结构,当该线程再次请求锁时,无需再做任何同步操作,即获取锁的过程只需要检查 **Mark Word ** 的锁标记位为偏向锁以及当前线程 ID 等于 ** Mark Word**** 的 ThreadID 即可**,这样就省去了大量有关锁申请的操作。
轻量级锁是由偏向锁升级而来,当存在第二个线程申请同一个锁对象时,偏向锁就会立即升级为轻量级锁。注意这里的第二个线程只是申请锁,不存在两个线程同时竞争锁,可以是一前一后地交替执行同步块。
重量级锁是由轻量级锁升级而来,当同一时间有多个线程竞争锁时,锁就会被升级成重量级锁,此时其申请锁带来的开销也就变大。
重量级锁一般使用场景会在追求吞吐量,同步块或者同步方法执行时间较长的场景。
消除锁是虚拟机另外一种锁的优化,这种优化更彻底,在 JIT 编译时,对运行上下文进行扫描,去除不可能存在竞争的锁。比如下面代码的 method1 和 method2 的执行效率是一样的,因为 object 锁是私有变量,不存在所得竞争关系。
锁粗化是虚拟机对另一种极端情况的优化处理,通过扩大锁的范围,避免反复加锁和释放锁。比如下面 method3 经过锁粗化优化之后就和 method4 执行效率一样了。
轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
自旋锁:许多情况下,共享数据的锁定状态持续时间较短,切换线程不值得,通过让线程执行循环等待锁的释放,不让出 CPU。如果得到锁,就顺利进入临界区。如果还不能获得锁,那就会将线程在操作系统层面挂起,这就是自旋锁的优化方式。但是它也存在缺点:如果锁被其他线程长时间占用,一直不释放 CPU,会带来许多的性能开销。
自适应自旋锁:这种相当于是对上面自旋锁优化方式的进一步优化,它的自旋的次数不再固定,其自旋的次数由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定,这就解决了自旋锁带来的缺点。
为什么要引入偏向锁和轻量级锁?为什么重量级锁开销大?
重量级锁底层依赖于系统的同步函数来实现,在 linux 中使用 pthread_mutex_t(互斥锁)来实现。
这些底层的同步函数操作会涉及到:操作系统用户态和内核态的切换、进程的上下文切换,而这些操作都是比较耗时的,因此重量级锁操作的开销比较大。
而在很多情况下,可能获取锁时只有一个线程,或者是多个线程交替获取锁,在这种情况下,使用重量级锁就不划算了,因此引入了偏向锁和轻量级锁来降低没有并发竞争时的锁开销。
可以的。
具体的触发时机:在全局安全点(safepoint)中,执行清理任务的时候会触发尝试降级锁。
当锁降级时,主要进行了以下操作:
1)恢复锁对象的 markword 对象头;
2)重置 ObjectMonitor,然后将该 ObjectMonitor 放入全局空闲列表,等待后续使用。
ThreadLocal,即线程本地变量。如果你创建了一个 ThreadLocal 变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
ThreadLocal 的应用场景有
ThreadLocal 内存结构图:
由结构图是可以看出:
先看看一下的 TreadLocal 的引用示意图哈,
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,如下
:
弱引用:只要垃圾回收机制一运行,不管 JVM 的内存空间是否充足,都会回收该对象占用的内存。
弱引用比较容易被回收。因此,如果 ThreadLocal(ThreadLocalMap 的 Key)被垃圾回收器回收了,但是因为 ThreadLocalMap 生命周期和 Thread 是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap 的 key 没了,value 还在,这就会**「造成了内存泄漏问题」**。
如何**「解决内存泄漏问题」**?使用完 ThreadLocal 后,及时调用 remove () 方法释放内存空间。
ReetrantLock 是一个可重入的独占锁,主要有两个特性,一个是支持公平锁和非公平锁,一个是可重入。 ReetrantLock 实现依赖于 AQS (AbstractQueuedSynchronizer)。
ReetrantLock 主要依靠 AQS 维护一个阻塞队列,多个线程对加锁时,失败则会进入阻塞队列。等待唤醒,重新尝试加锁。
首先 ReentrantLock 某些时候有局限,如果使用 ReentrantLock,可能本身是为了防止线程 A 在写数据、线程 B 在读数据造成的数据不一致,但这样,如果线程 C 在读数据、线程 D 也在读数据,读数据是不会改变数据的,没有必要加锁,但是还是加锁了,降低了程序的性能。
因为这个,才诞生了读写锁 ReadWriteLock。ReadWriteLock 是一个读写锁接口,ReentrantReadWriteLock 是 ReadWriteLock 接口的一个具体实现,实现了读写的分离,读锁是共享的,写锁是独占的,读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,提升了读写的性能
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
使用线程池的好处:
corePoolSize : 核心线程大小。线程池一直运行,核心线程就不会停止。
maximumPoolSize :线程池最大线程数量。非核心线程数量 = maximumPoolSize-corePoolSize
keepAliveTime :非核心线程的心跳时间。如果非核心线程在 keepAliveTime 内没有运行任务,非核心线程会消亡。
workQueue :阻塞队列。ArrayBlockingQueue,LinkedBlockingQueue 等,用来存放线程任务。
defaultHandler :饱和策略。ThreadPoolExecutor 类中一共有 4 种饱和策略。通过实现 RejectedExecutionHandler 接口。
ThreadFactory :线程工厂。新建线程工厂。
1、newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
这种类型的线程池特点是:
工作线程的创建数量几乎没有限制 (其实也有限制的,数目为 Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间 (默认为 1 分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
在使用 CachedThreadPool 时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统 OOM。
2、newFixedThreadPool
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。
FixedThreadPool 是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
3、newSingleThreadExecutor
创建一个单线程化的 Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序 (FIFO, LIFO, 优先级) 执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
4、newScheduleThreadPool
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
表格左侧是线程池,右侧为它们对应的阻塞队列,可以看到 5 种线程池对应了 3 种阻塞队列
LinkedBlockingQueue 对于 FixedThreadPool 和 SingleThreadExector 而言,它们使用的阻塞队列是容量为 Integer.MAX_VALUE 的 LinkedBlockingQueue,可以认为是无界队列。由于 FixedThreadPool 线程池的线程数是固定的,所以没有办法增加特别多的线程来处理任务,这时就需要 LinkedBlockingQueue 这样一个没有容量限制的阻塞队列来存放任务。
这里需要注意,由于线程池的任务队列永远不会放满,所以线程池只会创建核心线程数量的线程,所以此时的最大线程数对线程池来说没有意义,因为并不会触发生成多于核心线程数的线程。
SynchronousQueue 第二种阻塞队列是 SynchronousQueue,对应的线程池是 CachedThreadPool。线程池 CachedThreadPool 的最大线程数是 Integer 的最大值,可以理解为线程数是可以无限扩展的。CachedThreadPool 和上一种线程池 FixedThreadPool 的情况恰恰相反,FixedThreadPool 的情况是阻塞队列的容量是无限的,而这里 CachedThreadPool 是线程数可以无限扩展,所以 CachedThreadPool 线程池并不需要一个任务队列来存储任务,因为一旦有任务被提交就直接转发给线程或者创建新线程来执行,而不需要另外保存它们。 我们自己创建使用 SynchronousQueue 的线程池时,如果不希望任务被拒绝,那么就需要注意设置最大线程数要尽可能大一些,以免发生任务数大于最大线程数时,没办法把任务放到队列中也没有足够线程来执行任务的情况。
DelayedWorkQueue 第三种阻塞队列是 DelayedWorkQueue,它对应的线程池分别是 ScheduledThreadPool 和 SingleThreadScheduledExecutor,这两种线程池的最大特点就是可以延迟执行任务,比如说一定时间后执行任务或是每隔一定的时间执行一次任务。
DelayedWorkQueue 的特点是内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是 “堆” 的数据结构。之所以线程池 ScheduledThreadPool 和 SingleThreadScheduledExecutor 选择 DelayedWorkQueue,是因为它们本身正是基于时间执行任务的,而延迟队列正好可以把任务按时间进行排序,方便任务的执行。
源码中 ThreadPoolExecutor 中有个内置对象 Worker,每个 worker 都是一个线程,worker 线程数量和参数有关,每个 worker 会 while 死循环从阻塞队列中取数据,通过置换 worker 中 Runnable 对象,运行其 run 方法起到线程置换的效果,这样做的好处是避免多线程频繁线程切换,提高程序运行性能。
自定义线程池就需要我们自己配置最大线程数 maximumPoolSize ,为了高效的并发运行,这时需要看我们的业务是 IO 密集型还是 CPU 密集型。
CPU 密集型 CPU 密集的意思是该任务需要最大的运算,而没有阻塞,CPU 一直全速运行。CPU 密集任务只有在真正的多核 CPU 上才能得到加速 (通过多线程)。而在单核 CPU 上,无论你开几个模拟的多线程该任务都不可能得到加速,因为 CPU 总的运算能力就那么多。
IO 密集型 IO 密集型,即该任务需要大量的 IO,即大量的阻塞。在单线程上运行 IO 密集型的任务会导致大量的 CPU 运算能力浪费在等待。所以在 IO 密集型任务中使用多线程可以大大的加速程序运行,即使在单核 CPU 上这种加速主要就是利用了被浪费掉的阻塞时间。
IO 密集型时,大部分线程都阻塞,故需要多配制线程数。公式为:
当以上都不适用时,选用动态化线程池,看美团技术团队的实践:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
Executors 工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
Executor 接口对象能执行我们的线程任务。ExecutorService 接口继承了 Executor 接口并进行了扩展,提供了更多的方法我们能获得任务执行的状态并且可以获取任务的返回值。
使用 ThreadPoolExecutor 可以创建自定义线程池。Future 表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并可以使用 get () 方法获取计算的结果。
AQS 同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:
AQS 定义两种资源共享方式
Exclusive
(独占):只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁:
Share(共享):多个线程可同时执行,如 Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队 / 唤醒出队等),AQS 已经在顶层实现好了。
Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
所以,所谓原子类说简单点就是具有原子 / 原子操作特征的类。
并发包 java.util.concurrent 的原子类都存放在 java.util.concurrent.atomic 下:
基本类型 使用原子的方式更新基本类型:
数组类型 使用原子的方式更新数组里的某个元素:
引用类型 使用原子的方式更新引用类型:
AtomicInteger 类主要利用 CAS 和 volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
AtomicInteger 类的部分源码:
https://www.nowcoder.com/discuss/753354?channel=666&source_id=feed_index_nctrack
一、后台进程管理命令
fg、bg、jobs、&、ctrl + z、ctrl + c、ctrl + \、ctrl + d
1、 &
加在一个命令的最后,可以把这个命令放到后台执行,如 gftp &,
2、ctrl + z
可以将一个正在前台执行的命令放到后台,并且处于暂停状态,不可执行
3、jobs
查看当前有多少在后台运行的命令
jobs -l 选项可显示所有任务的 PID,jobs 的状态可以是 running, stopped, Terminated, 但是如果任务被终止了(kill),shell 从当前的 shell 环境已知的列表中删除任务的进程标识;也就是说,jobs 命令显示的是当前 shell 环境中所起的后台正在运行或者被挂起的任务信息;
4、fg
将后台中的命令调至前台继续运行
如果后台中有多个命令,可以用 fg % jobnumber 将选中的命令调出,% jobnumber 是通过 jobs 命令查到的后台正在执行的命令的序号 (不是 pid)
5、bg
将一个在后台暂停的命令,变成继续执行 (在后台执行)
如果后台中有多个命令,可以用 bg % jobnumber 将选中的命令调出,% jobnumber 是通过 jobs 命令查到的后台正在执行的命令的序号 (不是 pid)
将任务转移到后台运行:
先 ctrl + z;再 bg,这样进程就被移到后台运行,终端还能继续接受命令。
概念:当前任务
如果后台的任务号有 2 个,[1],[2];如果当第一个后台任务顺利执行完毕,第二个后台任务还在执行中时,当前任务便会自动变成后台任务号码 “[2]” 的后台任务。所以可以得出一点,即当前任务是会变动的。当用户输入 “fg”、“bg” 和 “stop” 等命令时,如果不加任何引号,则所变动的均是当前任务
二、进程的终止
后台进程的终止:
方法一:
通过 jobs 命令查看 job 号(假设为 num),然后执行 kill % num
方法二:
通过 ps 命令查看 job 的进程号(PID,假设为 pid),然后执行 kill pid
前台进程的终止:
ctrl+c
三、进程的挂起(暂停的意思吧)
后台进程的挂起:
在 solaris 中通过 stop 命令执行,通过 jobs 命令查看 job 号 (假设为 num),然后执行 stop % num;
在 redhat 中,不存在 stop 命令,可通过执行命令 kill -stop PID,将进程挂起;
当要重新执行当前被挂起的任务时,通过 bg % num 即可将挂起的 job 的状态由 stopped 改为 running,仍在后台执行;当需要改为在前台执行时,执行命令 fg % num 即可;
前台进程的挂起:
ctrl+Z;
四、kill 的其他作用
kill 除了可以终止进程,还能给进程发送其它信号,使用 kill -l 可以察看 kill 支持的信号。
SIGTERM 是不带参数时 kill 发送的信号,意思是要进程终止运行,但执行与否还得看进程是否支持。如果进程还没有终止,可以使用 kill -SIGKILL pid,这是由内核来终止进程,进程不能监听这个信号。
五、ctrl+z(挂起)、ctrl+c(中断)、ctrl+\(退出)和 ctrl+d(EOF)的区别
1、四种操作的表现
ctrl+c 强行中断当前程序的执行。
ctrl+z 将任务中断,但是此任务并没有结束,他仍然在进程中,只是放到后台并维持挂起的状态。如需其在后台继续运行,需用 “bg 进程号” 使其继续运行;再用 "fg 进程号" 可将后台进程前台化。
ctrl+\ 表示退出。
ctrl+d 表示结束当前输入(即用户不再给当前程序发出指令),那么 Linux 通常将结束当前程序。
2、ctrl+c,ctrl+d,ctrl+z 在 linux 中意义。
linux 下:
ctrl-c 发送 SIGINT 信号给前台进程组中的所有进程。常用于终止正在运行的程序。
ctrl-z 发送 SIGTSTP 信号给前台进程组中的所有进程,常用于挂起一个进程。
ctrl-d 不是发送信号,而是表示一个特殊的二进制值,表示 EOF。
ctrl-\ 发送 SIGQUIT 信号给前台进程组中的所有进程,终止前台进程并生成 core 文件。
Key Function
Ctrl-c Kill foreground process
Ctrl-z Suspend foreground process
Ctrl-d Terminate input, or exit shell
Ctrl-s Suspend output
Ctrl-q Resume output
Ctrl-o Discard output
Ctrl-l Clear screen
https://www.cnblogs.com/jiangzhaowei/p/8971265.html
锁作为并发共享数据,保证一致性的工具,在 JAVA 平台有多种实现 (如 synchronized 和 ReentrantLock 等) 。
上面是很多锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计,下面总结的内容是对每个锁的名词进行一定的解释。
公平锁 / 非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于 Java ReentrantLock 而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于 synchronized 而言,也是一种非公平锁。由于其并不像 ReentrantLock 是通过 AQS 的来实现线程调度,所以并没有任何办法使其变成公平锁。
可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。对于 Java ReentrantLock 而言,其名字是 Re entrant Lock 即是重新进入锁。对于 synchronized 而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。
synchronized void setA() throws Exception{
Thread.sleep(1000);
setB();
}
synchronized void setB() throws Exception{
Thread.sleep(1000);
}```
上面的代码就是一个可重入锁的一个特点,如果不是可重入锁的话,setB 可能不会被当前线程执行,可能造成死锁。
**独享锁 / 共享锁**
独享锁是指该锁一次只能被一个线程所持有;共享锁是指该锁可被多个线程所持有。
对于 Java ReentrantLock 而言,其是独享锁。但是对于 Lock 的另一个实现类 ReadWriteLock,其读锁是共享锁,其写锁是独享锁。读锁的共享锁可保证并发读是非常高效的,读写、写读 、写写的过程是互斥的。独享锁与共享锁也是通过 AQS 来实现的,通过实现不同的方法,来实现独享或者共享。对于 synchronized 而言,当然是独享锁。
**互斥锁 / 读写锁**
上面说到的独享锁 / 共享锁就是一种广义的说法,互斥锁 / 读写锁就是具体的实现。互斥锁在 Java 中的具体实现就是 ReentrantLock;读写锁在 Java 中的具体实现就是 ReadWriteLock。
**乐观锁 / 悲观锁**
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。比如 Java 里面的同步原语 synchronized 关键字的实现就是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,在 Java 中 java.util.concurrent.atomic 包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS (Compare and Swap 比较并交换) 实现的。
**分段锁**
分段锁其实是一种锁的设计,并不是具体的一种锁,对于 ConcurrentHashMap 而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作,ConcurrentHashMap 中的分段锁称为 Segment,它即类似于 HashMap(JDK7 与 JDK8 中 HashMap 的实现)的结构,即内部拥有一个 Entry 数组,数组中的每个元素又是一个链表;同时又是一个 ReentrantLock(Segment 继承了 ReentrantLock)。当需要 put 元素的时候,并不是对整个 HashMap 进行加锁,而是先通过 hashcode 来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程 put 的时候,只要不是放在一个分段中,就实现了真正的并行的插入。但是,在统计 size 的时候,可就是获取 HashMap 全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
**偏向锁 / 轻量级锁 / 重量级锁**
这三种锁是指锁的状态,并且是针对 synchronized。在 Java 5 通过引入锁升级的机制来实现高效 synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
**自旋锁**
在 Java 中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗 CPU。
1\. 预备知识
--------
### 1.AQS
AbstractQueuedSynchronized 抽象的队列式的同步器,AQS 定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的 ReentrantLock/Semaphore/CountDownLatch…

AQS 维护了一个 volatile int state(代表共享资源)和一个 FIFO 线程等待队列(多线程争用资源被阻塞时会进入此队列)。state 的访问方式有三种:
```null
getState()
setState()
compareAndSetState()```
AQS 定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如 ReentrantLock)和 Share(共享,多个线程可同时执行,如 Semaphore/CountDownLatch)。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队 / 唤醒出队等),AQS 已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法:
```null
isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。```
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock () 时,会调用 tryAcquire () 独占该锁并将 state+1。此后,其他线程再 tryAcquire () 时就会失败,直到 A 线程 unlock () 到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown () 一次,state 会 CAS 减 1。等到所有子线程都执行完后 (即 state=0),会 unpark () 主调用线程,然后主调用线程就会从 await () 函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现 tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared 中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如 ReentrantReadWriteLock。
### 2.CAS
CAS (Compare and Swap 比较并交换) 是乐观锁技术,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
CAS 操作中包含三个操作数 —— 需要读写的内存位置 (V)、进行比较的预期原值 (A) 和拟写入的新值 (B)。如果内存位置 V 的值与预期原值 A 相匹配,那么处理器会自动将该位置值更新为新值 B,否则处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值)。CAS 有效地说明了 “ 我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可”。这其实和乐观锁的冲突检查 + 数据更新的原理是一样的。
JAVA 对 CAS 的支持:
在 JDK1.5 中新增 java.util.concurrent 包就是建立在 CAS 之上的。相对于对于 synchronized 这种阻塞算法,CAS 是非阻塞算法的一种常见实现。所以 java.util.concurrent 在性能上有了很大的提升。
以 java.util.concurrent 包中的 AtomicInteger 为例,看一下在不使用锁的情况下是如何保证线程安全的。主要理解 getAndIncrement 方法,该方法的作用相当于 ++i 操作。
```null
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
public final int get() {
return value;
}
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}```
2\. 实战
------
### 1.synchronized
synchronized 可重入锁验证
```null
public class Test implements Runnable{
public synchronized void get(){
System.out.println("2 enter thread name-->" + Thread.currentThread().getName());
System.out.println("3 get thread name-->" + Thread.currentThread().getName());
set();
System.out.println("5 leave run thread name-->" + Thread.currentThread().getName());
}
public synchronized void set(){
System.out.println("4 set thread name-->" + Thread.currentThread().getName());
}
@Override
public void run() {
System.out.println("1 run thread name-->" + Thread.currentThread().getName());
get();
}
public static void main(String[] args){
Test test = new Test();
for(int i = 0; i < 10; i++){
new Thread(test, "thread-" + i).start();
}
}
}
运行结果
1 run thread name
1 run thread name
1 run thread name
1 run thread name
2 enter thread name
3 get thread name
1 run thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
1 run thread name
4 set thread name
1 run thread name
1 run thread name
5 leave run thread name
1 run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
get () 方法中顺利进入了 set () 方法,说明 synchronized 的确是可重入锁。分析打印 Log,thread-0 先进入 get 方法体,这个时候 thread-3、thread-2、thread-1 等待进入,但当 thread-0 离开时,thread-4 却先进入了方法体,没有按照 thread-3、thread-2、thread-1 的顺序进入 get 方法体,说明 sychronized 的确是非公平锁。而且在一个线程进入 get 方法体后,其他线程只能等待,无法同时进入,验证了 synchronized 是独占锁。
ReentrantLock 既可以构造公平锁又可以构造非公平锁,默认为非公平锁,将上面的代码改为用 ReentrantLock 实现,再次运行。
import java.util.concurrent.locks.ReentrantLock;
public class Test implements Runnable{
private ReentrantLock reentrantLock = new ReentrantLock();
public void get(){
System.out.println("2 enter thread name-->" + Thread.currentThread().getName());
reentrantLock.lock();
System.out.println("3 get thread name-->" + Thread.currentThread().getName());
set();
reentrantLock.unlock();
System.out.println("5 leave run thread name-->" + Thread.currentThread().getName());
}
public void set(){
reentrantLock.lock();
System.out.println("4 set thread name-->" + Thread.currentThread().getName());
reentrantLock.unlock();
}
@Override
public void run() {
System.out.println("1 run thread name-->" + Thread.currentThread().getName());
get();
}
public static void main(String[] args){
Test test = new Test();
for(int i = 0; i < 10; i++){
new Thread(test, "thread-" + i).start();
}
}
}
运行结果
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
1 run thread name
2 enter thread name
1 run thread name
2 enter thread name
1 run thread name
2 enter thread name
5 leave run thread name
3 get thread name
4 set thread name
5 leave run thread name
3 get thread name
4 set thread name
5 leave run thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
5 leave run thread name```
的确如其名,可重入锁,当然默认的确是非公平锁。thread-0 持有锁期间,thread-1、thread-2、thread-3 等待拥有锁,当 thread-0 释放锁时 thread-2 先获取到锁,并非按照先后顺序获取锁的。
将其构造为公平锁,看看运行结果是否符合预期。查看源码构造公平锁很简单,只要在构造器传入 boolean 值 true 即可。
```null
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}```
修改上面例程的代码构造方法为:
```null
ReentrantLock reentrantLock = new ReentrantLock(true);```
如果使用了 IntelliJ IDEA IDE 可以看到在 true 前面还有个 fair 提示。
```null
import java.util.concurrent.locks.ReentrantLock;
public class Test implements Runnable{
private ReentrantLock reentrantLock = new ReentrantLock(true);
public void get(){
System.out.println("2 enter thread name-->" + Thread.currentThread().getName());
reentrantLock.lock();
System.out.println("3 get thread name-->" + Thread.currentThread().getName());
set();
reentrantLock.unlock();
System.out.println("5 leave run thread name-->" + Thread.currentThread().getName());
}
public void set(){
reentrantLock.lock();
System.out.println("4 set thread name-->" + Thread.currentThread().getName());
reentrantLock.unlock();
}
@Override
public void run() {
System.out.println("1 run thread name-->" + Thread.currentThread().getName());
get();
}
public static void main(String[] args){
Test test = new Test();
for(int i = 0; i < 10; i++){
new Thread(test, "thread-" + i).start();
}
}
}
运行结果
1 run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
1 run thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
2 enter thread name
1 run thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
1 run thread name
2 enter thread name
1 run thread name
5 leave run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
3 get thread name
4 set thread name
5 leave run thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
1 run thread name
2 enter thread name
4 set thread name
3 get thread name
4 set thread name
5 leave run thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
1 run thread name
2 enter thread name
3 get thread name
4 set thread name
5 leave run thread name
公平锁在多个线程想要同时获取锁的时候,会发现再排队,按照先来后到的顺序进行。
读写锁的性能都会比排它锁要好,因为大多数场景读是多于写的。在读多于写的情况下,读写锁能够提供比排它锁更好的并发性和吞吐量。Java 并发包提供读写锁的实现是 ReentrantReadWriteLock。
| 特性 | 说明 |
|---|---|
| 公平性选择 | 支持非公平 (默认) 和公平的锁获取方式,吞吐量还是非公平优于公平 |
| 重进入 | 该锁支持重进入,以读写线程为例:读线程在获取了读锁之后,能够再次获取读锁。而写线程在获取了写锁之后能够再次获取写锁,同时也可以获取读锁 |
| 锁降级 | 遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级成为读锁 |
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class Test {
public static void main(String[] args){
for(int i = 0; i < 10; i++){
new Thread(new Runnable() {
@Override
public void run() {
Cache.put("key", new String(Thread.currentThread().getName() + " joke"));
}
}, "threadW-"+ i).start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Cache.get("key"));
}
}, "threadR-"+ i).start();
new Thread(new Runnable() {
@Override
public void run() {
Cache.clear();
}
}, "threadC-"+ i).start();
}
}
}
class Cache {
static Map<String, Object> map = new HashMap<String, Object>();
static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
static Lock r = rwl.readLock();
static Lock w = rwl.writeLock();
public static final Object get(String key) {
r.lock();
try {
System.out.println("get " + Thread.currentThread().getName());
return map.get(key);
} finally {
r.unlock();
}
}
public static final Object put(String key, Object value) {
w.lock();
try {
System.out.println("put " + Thread.currentThread().getName());
return map.put(key, value);
} finally {
w.unlock();
}
}
public static final void clear() {
w.lock();
try {
System.out.println("clear " + Thread.currentThread().getName());
map.clear();
} finally {
w.unlock();
}
}
}
运行结果
clear threadC-0
get threadR-2
null
put threadW-2
get threadR-0
threadW-2 joke
get threadR-3
threadW-2 joke
clear threadC-1
put threadW-3
clear threadC-3
clear threadC-2
get threadR-1
null
put threadW-1
put threadW-0
put threadW-4
get threadR-4
threadW-4 joke
clear threadC-4
get threadR-5
null
put threadW-5
put threadW-6
get threadR-6
threadW-6 joke
get threadR-7
threadW-6 joke
put threadW-7
clear threadC-6
put threadW-8
get threadR-8
threadW-8 joke
clear threadC-8
get threadR-9
null
clear threadC-5
clear threadC-9
clear threadC-7
put threadW-9
可看到普通 HashMap 在多线程中数据可见性正常。
1.http://ifeve.com/java-art-reentrantlock/
https://blog.csdn.net/tyyj90/article/details/78236053
本文主要介绍 JUC 多线程以及高并发
本文较长,可收藏,勿吃尘
如有需要,可以参考
如有帮助,不忘 点赞 ❥
volatile 是 Java 虚拟机提供的轻量级的同步机制
JMM 模型的线程工作:
各个线程对主内存**享变量 X 的操作都是各个线程各自拷贝到自己的工作内存操作后再协会主内存中。存在的问题:
如果一个线程 A 修改了共享变量 X 的值还未写回主内存,这是另外一个线程 B 又对内存中的一个共享变量 X 进行操作,但是此时线程 A 工作内存中的共享变量对线程 B 来说事并不可见的。这种工作内存与主内存延迟的现象就会造成了可见性的问题。解决(volatile):
当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看到修改的值
public class Volatile{
public static void main(Stirng[] args){
testVolatile();
}
public static void testVolatile(){
Test test = new Test();
new Thread(() -> { System.out.println(Thread.currentThread().getName() + "\t first thread");
try {
TimeUnit.SECONDS.sleep(3);
test.changeNum();
System.out.println(Thread.currentThread().getName() + "\t current value:" + test.n);
} catch (Exception e) {
e.printStackTrace();
}
}, "threadAAA").start();
while (test.n == 0) {
}
System.out.println(Thread.currentThread().getName() + "\t now value:" + test.n);
}
}
class Test{
volatile int n = 0;
public void changeNum(){
this.n = 1;
}
}
原子性:
不可分割、完整性,即某个线程正在做某个具体业务时,中间不可以被加塞或者被分割,需要整体完整,要么同时成功,要么同时失败解决方法:
- 加入 synchronized
- 使用 JUC 下的 AtomicInteger
public class Volatile {
public static void main(String[] args) {
atomicByVolatile();
}
public static void atomicByVolatile(){
Test test= new Test();
for(int i = 1; i <= 20; i++){
new Thread(() ->{
for(int j = 1; j <= 1000; j++){
test.addSelf();
test.atomicAddSelf();
}
},"Thread "+i).start();
}
while (Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+"\t finally num value is "+test.n);
System.out.println(Thread.currentThread().getName()+"\t finally atomicnum value is "+test.atomicInteger);
}
}
class Test {
volatile int n = 0;
public void addSelf(){
n++;
}
AtomicInteger atomicInteger = new AtomicInteger();
public void atomicAddSelf(){
atomicInteger.getAndIncrement();
}
}
指令重排:
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。指令重排过程:
源代码 -> 编辑器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行的指令内存屏障作用:
- 保证特定操作的执行顺序
- 保证某些变量的内存可见性(利用该特性实现 volatile 的内存可见性)
硬件功能,通过它实现了原子操作,再次强调,由于 CAS 是一种系统源语,源语属于操作系统用于范畴,是由若干个指令组成,用于完成某个功能的一个过程,并且源语的执行必须是连续的,在执行过程中不允许中断,也即是说 CAS 是一条原子指令,不会造成所谓的数据不一致的问题public class CASDemo{
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger();
System.out.println(atomicInteger.compareAndSet(0,5));
System.out.println(atomicInteger.compareAndSet(0,2));
System.out.println(atomicInteger);
}
} public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
} public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}public class ABADemo {
public static void main(String[] args) {
User u1 = new User("u1",18);
User u2 = new User("u2",19);
AtomicReference<User> atomicReference = new AtomicReference(u1);
System.out.println(atomicReference.compareAndSet(u1,u2)+"\t"+atomicReference.get().getName());
System.out.println(atomicReference.compareAndSet(u1,u2)+"\t"+atomicReference.get().getName());
}
}
class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}AtomicStampedReference) public static void main(String[] args) {
System.out.println("====存在ABA问题");
new Thread(() -> {
atomicReference.compareAndSet(100, 101);
atomicReference.compareAndSet(101, 100);
}, "线程A").start();
new Thread(() -> {
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
System.out.println(atomicReference.compareAndSet(100, 102) + "\t" + atomicReference.get());
}, "线程2").start();
System.out.println("====通过时间戳原子引用解决ABA问题====");
new Thread(()->{
int stamp1 = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName()+"===第一次版本号:"+stamp1+"===值:"+atomicStampedReference.getReference());
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
atomicStampedReference.compareAndSet(100,101,stamp1,stamp1+1);
int stamp2 = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName()+"===第二次版本号:"+stamp2+"===值:"+atomicStampedReference.getReference());
atomicStampedReference.compareAndSet(101,100,stamp2,stamp2+1);
int stamp3 = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName()+"===第三次版本号:"+stamp3+"===值:"+atomicStampedReference.getReference());
},"线程3").start();
new Thread(()->{
int stamp4 = atomicStampedReference.getStamp();
System.out.println(Thread.currentThread().getName()+"===第一次版本号:"+stamp4+"===值:"+atomicStampedReference.getReference());
try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}
boolean result = atomicStampedReference.compareAndSet(100, 101, stamp4, stamp4 + 1);
System.out.println(Thread.currentThread().getName()+"===是否修改成功:"+result+"===当前版本:"+atomicStampedReference.getStamp());
System.out.println("===当前最新值:"+atomicStampedReference.getReference());
},"线程4").start();
}出现 java.util.ConcurrentModificationException 异常
并发争抢修改导致
public static void main(String[] args) {
List<String> stringList = new ArrayList<>();
for (int i = 0; i < 30; i++) {
new Thread(()->{
stringList.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(stringList);
},"线程"+i).start();
}
}new CopyOnWriteArrayList<>();new CopyOnWriteArraySet<>();ConcurrentHashMap();公平锁: 是指多个线程按照申请锁的顺序来获取锁,类似于排队,FIFO 规则
非公平锁: 是指在多线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获到锁,在高并发的情况下,有可能造成优先级反转或者饥饿现象。
并发包 ReentrantLock 的创建可以指定函数的 boolean 类型来得到公平锁或者非公平锁,默认是非公平锁
公平锁: 就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照 FIFO 的规则从队列中抽取到自己。
非公平锁: 非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁的那种方式。
就 Java ReentrantLock 而言,通过构造函数指定该锁是否是公平锁, 默认 非公平锁 ,非公平锁的优点在于吞吐量比公平锁大,就 synchronized 而言,它是一种非公平锁。
递归锁,指定是同一个线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。也就是说, 线程可以进入任何一个它已经拥有的锁所同步着的代码块ReentrantLock/syschronized 就是一个典型的可重入锁
public class ReenterLockDemo {
public static void main(String[] args) {
Rld rld = new Rld();
Thread thread1 = new Thread(rld,"t1");
Thread thread2 = new Thread(rld,"t2");
thread1.start();
thread2.start();
}
}
class Rld implements Runnable {
private Lock lock = new ReentrantLock();
@Override
public void run() {
get();
}
private void get() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t====get方法");
set();
} finally {
lock.unlock();
}
}
private void set() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t====set方法");
} finally {
lock.unlock();
}
}
}
public class ReenterLockDemo {
public synchronized static void sendMsg(){
System.out.println(Thread.currentThread().getName()+"\t"+"发送短信");
sendEmail();
}
public synchronized static void sendEmail(){
System.out.println(Thread.currentThread().getName()+"\t"+"发送邮件");
}
public static void main(String[] args) {
new Thread(()->{
sendMsg();
},"t1").start();
new Thread(()->{
sendMsg();
},"t2").start();
}
}
上面的 CAS 问题中的 unsafe 用到的就是自旋锁。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
public class SpinLockDemo {
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(() -> {
spinLockDemo.mylock();
try {
TimeUnit.SECONDS.sleep(3);
}catch (Exception e){
e.printStackTrace();
}
spinLockDemo.myUnlock();
}, "Thread 1").start();
try {
TimeUnit.SECONDS.sleep(1);
}catch (Exception e){
e.printStackTrace();
}
new Thread(() -> {
spinLockDemo.mylock();
spinLockDemo.myUnlock();
}, "Thread 2").start();
}
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void mylock() {
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "\t come in");
while (!atomicReference.compareAndSet(null, thread)) {
System.out.println(Thread.currentThread().getName()+"wait...");
}
}
public void myUnlock() {
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread, null);
System.out.println(Thread.currentThread().getName()+"\t invoked myunlock()");
}
}
对 ReentrantReadWriteLock 而言,其读锁是共享锁,其写锁是独占锁。读锁的共享锁可以保证并发度是非常高效的。读写,写读,写写的过程是互斥的。
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache cache = new MyCache();
for (int i = 0; i < 5; i++) {
final int temp = i;
new Thread(() -> {
cache.put(temp + "", temp + "");
}).start();
}
for (int i = 0; i < 5; i++) {
final int temp = i;
new Thread(() -> {
cache.get(temp + "");
}).start();
}
}
}
class MyCache {
private volatile Map<String, Object> map = new HashMap<>();
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();
ReentrantReadWriteLock.ReadLock readLock = lock.readLock();
public void put(String key, Object value) {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " 正在写入...");
try { TimeUnit.MICROSECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + " 写入完成");
} finally {
writeLock.unlock();
}
}
public void get(String key) {
try {
readLock.lock();
System.out.println(Thread.currentThread().getName() + " 正在读...");
try {TimeUnit.MICROSECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
Object res = map.get(key);
System.out.println(Thread.currentThread().getName() + " 读取完成 :" + res);
} finally {
readLock.unlock();
}
}
}
public class CountDownLanchDemo {
public static void main(String[] args) {
for (int i = 0; i < 6; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 离开了教室...");
}, i+"号学生").start();
}
System.out.println("========班长锁门========");
}
}
public static void main(String[] args) {
try {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
new Thread(() -> {
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName() + " 离开了教室...");
}, i + "号学生").start();
}
countDownLatch.await();
System.out.println("========班长锁门========");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
CyclicBarrier cyclicBarrie = new CyclicBarrier(6, () -> {
System.out.println("班长锁门离开教室...");
});
for (int i = 0; i < 6; i++) {
final int temp = i;
new Thread(() -> {
System.out.println("离开教室...");
try {
cyclicBarrie.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}, temp + "号学生").start();
}
}
CountDownLatch 和 CyclicBarrier 其实是相反的操作,一个是相减到 0 开始执行,一个是相加到指定值开始执行
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for (int i = 1; i <= 6; i++) {
new Thread(()->{
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"\t 抢到车位");
try { TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}
System.out.println(Thread.currentThread().getName()+"\t 停车2秒后,离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
},i + "号车辆").start();
}
}
概念:阻塞队列,拆分为 “阻塞” 和 “队列”,所谓阻塞,在多线程领域,某些情况下会刮起线程(即线程阻塞),一旦条件满足,被挂起的线程优先被自动唤醒。
Tread 1 往阻塞队列中添加元素,Thread 2 往阻塞队列中移除元素
吞吐量:SynchronusQueue > LinkedBlockingQueue > ArrayBlockingQueue
我们不需要关心什么时候胡需要阻塞线程,什么时候需要唤醒线程,因为 BlockingQueure 都一手给你办好了。在 concurrent 包,发布以前,在多线程环境下,我们必须自己去控制这些细节,尤其还要兼顾效率和线程安全, 而这会给我们的程序带来不小的复杂度
| 方法类型 | 抛异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入方法 | add(o) | offer(o) | put(o) | offer(o, timeout, timeunit) |
| 移除方法 | remove(o) | poll() | take() | poll(timeout, timeunit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
public class ShareData {
private int stock = 0;
private Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
private void produce() throws InterruptedException {
lock.lock();
try {
while (stock > 0) {
condition.await();
}
stock++;
System.out.println(Thread.currentThread().getName()+"\t生产者生产完毕,此时库存:"+stock+"通知消费者消费");
condition.signalAll();
} finally {
lock.unlock();
}
}
private void consume() throws InterruptedException {
lock.lock();
try {
while (stock <1 ) {
condition.await();
}
stock--;
System.out.println(Thread.currentThread().getName()+"\t消费者消费完毕,此时库存:"+stock+"通知生产者生产");
condition.signalAll();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ShareData shareData = new ShareData();
new Thread(()->{
for (int i = 1; i < 5; i++) {
try {
shareData.produce();
} catch (InterruptedException e) {}
}
},"线程A").start();
new Thread(()->{
for (int i = 1; i < 5; i++) {
try {
shareData.consume();
} catch (InterruptedException e) {}
}
},"线程B").start();
}
}
public class BlockingQueueDemo {
private volatile boolean flag = true;
private AtomicInteger atomicInteger = new AtomicInteger();
private BlockingQueue<String> blockingQueue;
public BlockingQueueDemo(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
System.out.println(blockingQueue.getClass().getName());
}
public void produce() throws InterruptedException {
String data;
boolean returnValue;
while (flag) {
data = atomicInteger.incrementAndGet() + "";
returnValue = blockingQueue.offer(data, 2, TimeUnit.SECONDS);
if (returnValue) {
System.out.println(Thread.currentThread().getName() + "\t 插入队列的数据为:" + data + "成功");
} else {
System.out.println(Thread.currentThread().getName() + "\t 插入队列的数据为:" + data + "失败");
}
TimeUnit.SECONDS.sleep(1);
}
System.out.println(Thread.currentThread().getName()+"\t 停止标识 flag为:\t"+flag);
}
public void consume() throws InterruptedException {
String result;
while (flag) {
result = blockingQueue.poll(2,TimeUnit.SECONDS);
if (null == result || "".equalsIgnoreCase(result)) {
flag = false;
System.out.println(Thread.currentThread().getName()+"\t 没有取到数据");
return;
}
System.out.println(Thread.currentThread().getName()+"\t 消费者取到数据:"+result);
}
}
public void stop() {
flag = false;
}
}
class TestDemo{
public static void main(String[] args) {
BlockingQueueDemo blockingQueueDemo = new BlockingQueueDemo(new ArrayBlockingQueue<>(10));
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t 生产线程启动");
try {
blockingQueueDemo.produce();
} catch (InterruptedException e){}
},"生产者线程").start();
new Thread(()->{
System.out.println(Thread.currentThread().getName()+"\t 消费线程启动");
try {
blockingQueueDemo.consume();
} catch (InterruptedException e) {}
},"消费者线程").start();
try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}
System.out.println();
System.out.println();
System.out.println("停止工作");
blockingQueueDemo.stop();
}
}
概念:线程池做的工作主要是控制运行的线程的数量,处理过程中将任务加入队列,然后在线程创建后启动这些任务,如果线程超过了最大数量,超出的线程将排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
特点:
- 线程复用
- 控制最大并发数
- 管理线程
优点:
- 降低资源消耗,通过重复利用自己创建的线程减低线程创建和销毁造成的消耗。
- 提高响应速度,当任务到达时,任务可不需要等到线程创建就能立即执行。
- 提高线程的可管理性,线程是稀缺西苑,如果无限制的创建,不仅会消耗系统资源,还会降低体统的稳定性,使用线程可以进行统一分配,调优和监控。
class ThreadDemo extends Thread{
@Override
public void run() {
System.out.println("ThreadDemo 运行中...");
}
public static void main(String[] args) {
ThreadDemo threadDemo = new ThreadDemo();
threadDemo.start();
}
}class RunnableDemo{
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("RunnableDemo 运行中...");
}
}).start();
}
}public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
return 1;
}
});
new Thread(futureTask).start();
System.out.println(futureTask.get());
}Java 中的线程池使用过 Excutor 框架实现的,该框架中用到了 Executor,Executors,ExecutorService,ThreadPoolExecutor 这几个类。
特点:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<Runnable>());
}特点:
public static ExecutorService newSingleThreadExecutor() {
return new ThreadPoolExecutor(1, 1, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<Runnable>());
}特点:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60,
TimeUnit.SECONDS, new SynchronousQueue<>());
}| 参数 | 作用 |
|---|---|
| corePoolSize | 线程池中常驻核心线程数 |
| maximumPoolSize | 线程池能够容纳同时执行的最大线程数,需大于 1 |
| keepAliveTime | 多余空闲线程的存活时间,当空间时间达到 keepAliveTime 值时,多余的线程会被销毁直到只剩下 corePoolSize 个线程为止 |
| TimeUnit: keepAliveTime | 时间单位 |
| workQueue | 阻塞任务队列 |
| threadFactory | 表示生成线程池中工作线程的线程工厂,用户创建新线程,一般用默认即可 |
| RejectedExecutionHandler | 拒绝策略,表示当线程队列满了并且工作线程大于线程池的最大显示数(maximumPoolSize)时如何来拒绝 |
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> blockingQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize < 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0) {
throw new IllegalArgumentException("不合法配置");
}
if (blockingQueue == null ||
threadFactory == null ||
handler == null) {
throw new NullPointerException();
}
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.keepAliveTime = keepAliveTime;
this.unit = unit;
this.blocking = blockingQueue;
this.threadFactory = threadFactory;
this.handler = handler;
}例子:
(银行)一家银行总共有六个窗口(maximumPoolSize),周末开了三个窗口提供业务办理(corePoolSize),上班期间来了 3 个人办理业务,三个窗口能够应付的过来,这个时候又来了 1 个,三个窗口便忙不过来了,,只好让新来的客户去等待区(workQueue)等待,接下来如果还有来客户的话便让客户去等待区(workQueue)等待。但是如果等待区也坐满了。业务经理(threadFactory)便通知剩下的窗口开启来进行业务办理,但是如果六个窗口都占满了,而且等待区也坐不下了。这个时候银行便要考虑采用什么方式(RejectedExecutionHandler)来拒绝客户。时间慢慢的过去了,办理业务的客户也差不多走了,只剩下 3 个客户在办理。这个时候空闲了 3 个新增的窗口,他们便开始等待(keepAliveTime)一定时间,如果时间到了还没有客户来办理业务的话,这 3 个新增窗口便可以关闭,回去休息。但是原来的三个窗口(corePoolSize)还得继续开着。
等待队列已经排满,再也塞不下新的任务,而且也达到了 maximumPoolSize 数量,无法继续为新任务服务,这个时候我们便要采取拒绝策略机制合理的处理这个问题。
以下内置拒绝策略均实现了 RejectExecutionHandler 接口
直接抛出 RejectedException 异常来阻止系统正常运行。
“调用者运行” 一种调节机制,该策略既不会抛弃任务,也不会抛出异常。线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交(如果再次失败,则重复此过程)。
直接丢弃任务,不予任何处理也不抛出异常,如果允许任务丢失,这是最好的拒绝策略。
阿里巴巴 java 开发手册
【强制】线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者 “过度切换” 的问题。
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
自定义例子:
private static void threadPoolInit() {
ExecutorService threadPool = Executors.newCachedThreadPool();
try {
for (int i = 1; i <= 20; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"\t 来办理业务");
});
try {TimeUnit.MICROSECONDS.sleep(200);} catch (InterruptedException e) {e.printStackTrace();}
}
} catch (Exception e) {
e.printStackTrace();
}finally {
threadPool.shutdown();
}
}
public static void main(String[] args) {
ExecutorService customizeThreadPool = new ThreadPoolExecutor(
2, 5, 1L, TimeUnit.SECONDS,
new LinkedBlockingDeque<Runnable>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()
);
try {
for (int i = 1; i <= 20; i++) {
customizeThreadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t 来办理业务");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
customizeThreadPool.shutdown();
}
}Runtime.getRuntime().availableProcessors()死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,如果无外力的干涉那么它们将无法推进下去,如果系统的资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则会因争夺有限的资源而陷入死锁。
例子:
public class DeadLockDemo {
public static void main(String[] args) {
String lockA = "A锁";
String lockB = "B锁";
ExecutorService threadPool = new ThreadPoolExecutor(
2,2,1L,TimeUnit.SECONDS,
new LinkedBlockingDeque<>(2),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()
);
threadPool.execute(()->{
new HoldThread(lockA,lockB).run();
});
threadPool.execute(()->{
new HoldThread(lockB,lockA).run();
});
}
}
class HoldThread implements Runnable{
private String lockA;
private String lockB;
public HoldThread(String lockA,String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA) {
System.out.println(Thread.currentThread().getName()+"\t 自己持有:"+lockA+"\t 尝试获取:"+lockB);
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
synchronized (lockB) {
System.out.println(Thread.currentThread().getName()+"\t 自己持有:"+lockB+"\t 尝试获取:"+lockA);
}
}
}
}打印结果
陷入死锁状态:
本文较长,能看到这里的都是好样的,成长之路学无止境
今天的你多努力一点,明天的你就能少说一句求人的话!
https://blog.csdn.net/weixin_43287239/article/details/104778572
转自 https://www.cnblogs.com/xuanbiyijue/p/7980010.html
一.写在前面
对于前端开发而言,微信小程序因为其简单快速、开发成本低、用户流量巨大等特点,也就成了前端开发工程师必会的一个技能。
可以在微信小程序搜索 “悬笔 e 绝”,或者用微信扫描下面的二维码哦
(1)欢迎页:这个 logo 是当年念大学给社团做的 logo,苦学了整整一周的 PS 啊。。。
(2)首页:轮播头图,天气,豆瓣电影正在热映
(3)全国城市切换页
(4)天气详情页
(5)地图周边服务
(6)豆瓣电影
(7)热点新闻
(8)更多页面
(1)有人开玩笑说,会 vue 小程序根本都不用学:
微信小程序虽然是腾讯自己搞的,但是核心的**跟 vue 等框架是一样一样的哦~
(2)善于搜集精美的小组件: “我们不生产代码,我们只是代码的搬运工”,善于找到想要的组件并把他们巧妙优雅的组装成一个大项目,也算是程序员一项基本技能了。
具体怎么找到想要的小程序 demo,篇末会给大家推荐小程序的资源,有很多大神的项目哦
撸起袖子开干了
一。注册小程序账号,下载 IDE
官网注册 https://mp.weixin.qq.com/,并下载 IDE。
官方文档一向都是最好的学习资料。
注意:
(1)注册账号之后会有一个 appid,新建项目的时候需要填上,不然很多功能是用不了的,比如不能预览,不能上传代码等等。
(2)如果你注册过微信公众号的话,一定要注意,微信公众号和小程序是两个账号,二者的 appid 也是不同,小程序开发必须使用小程序的 appid 哦。
二。小程序框架介绍和运行机制
2.app.js
整个项目的启动文件,如注释写的 onlaunch 方法有三大功能,浏览器缓存进行存和取数据;用登陆成功的回调;获取用户信息。
globalData 是定义整个项目的全局变量或者常量哦。
3.app.json
整个项目的配置文件,比如注册页面,配置 tab 页,设置整个项目的样式,页面标题等等;
!注意:小程序启动默认的第一个页面,就是 app.json 的 pages 中的第一个页面哦。
4.pages
小程序的页面组件,有几个页面就会有几个子文件夹。比如快速启动模板,就有两个页面,index 和 logs
可以看到有三个文件,其实和我们 web 开发的文件是一一对应的。
index.wxml 对应 index.html;
index.wxss 对应 index.css;
index.js 就是 js 文件哦。
一般我们还会给每个页面组件添加一个. json 文件,作为该页面组件的配置文件,设置页面标题等功能
(1)var app = getApp();
引入整个项目的 app.js 文件,用来取期中的公共变量等信息。
如果要使用 util.js 工具库中的某个方法,在 util.js 中 module.exports 导出,然后在需要的页面中 require 即可得到哦。
(2)比如,我们要获取豆瓣电影的时候,我们需要调用豆瓣的 api;我们先在 app.js 中的 gloabData 中定义 doubanBase
然后在 index.js 中使用 app.globaData.doubanBase 即可取到这个值。
当然这些常量你也可以在页面需要的时候,再用写死的值,但是为了整个项目的维护,还是建议把这种公用参数统一写在配置文件中哦。
(3)接下来在整个 page ({}) 中,第一个 data,就是本页面组件的内部数据,会渲染到该页面的 wxml 文件中,类似于 vue、react 哦~
通过 setData 修改 data 数据,驱动页面渲染
(4)一些生命周期函数
比如 onload (), onready (), onshow (), onhide () 等等,监听页面加载、页面初次渲染、页面显示、页面隐藏等等
更多的可以查官网 API 哦。其中用的最多的就是 onload () 方法,和 onShareAppMessage () 方法(设置页面分享的信息)
7 .wxml 模板的使用。
比如本项目电影页面,就是以最小的星级评价组件 wxml 当做模板,star 到 movie 到 movie-list,一级一级的嵌套使用。
star-template.wxml 页面写好 name 属性;然后 import 引入的时候通过 name 获得即可
view,text,icon,swiper,block,scroll-view 等等,这些标签直接查官网文档即可
三。小程序框架、各个页面以及发布上线的注意点
1. 整个框架中的一些注意点
(1)整个 wxml 页面,最底层的标签是 哦。
(2) 每个页面顶部导航栏的颜色,title 在本页面的 json 中配置,如果没有配置的话,取 app.json 中的总配置哦。
(3)json 中不能写注释哦,不然会报错的。
(4)路由相关
1)使用 wx.SwitchTab 跳转 tab 页的话,在 app.json 中除了注册 pages 页面,还需要在 tabBar 中注册 tab 页,才能生效哦。
注意:tab 最多 5 个,也就是我们说的头部或者底部最多 5 个菜单。其他的页面只能通过其他路由方法打开哦。
2)navigateTo 是跳到某个非 tab 页,比如欢迎页,电影详情页,城市选择页;在 app.json 中注册后,不能在 tabBar 里注册哦,不然同样也是不能跳转的哦。
3)reLaunch 跳转,新开的页面左上角是没有退回按钮的,本项目只用了一次,切换城市的时候哦。
(5)页面之间传递参数
参数写在跳转的 url 之中,然后另一个页面在 onload 方法中的传参 option 接收到。如下传递和获取 id
(6)data - 开头的自定义属性的使用
比如 wxml 中我们怎么写
点击的事件对象可以这么取,var postId = event.currentTarget.dataset.postid;
注意: 大写会转换成小写,带_符号会转成驼峰形式
(7)事件对象 event,event.target 和 event.currentTarget 的区别:
target 指的是当前点击的组件 和 currentTarget 指的是事件捕获的组件。
比如,轮播图组件,点击事件应该要绑定到 swiper 上,这样才能监控任意一张图片是否被点击,
这时 target 这里指的是 image(因为点击的是图片),而 currentTarget 指的是 swiper(因为绑定点击事件在 swiper 上)
(8)使用免费的网络接口:
本项目中用到了 和风天气 api,腾讯地图 api,百度地图 api,豆瓣电影 api,聚合头条新闻 api 等,具体用法可以看各自官网的接口文档哦,很详细的
注意:免费接口是有访问限制的,所以如果用别人的组件用了这种接口的话,最好还是自己注册一个新的 key 替换上哦
附上一个免费接口大全:
https://github.com/jokermonn/-Api
!!另外还要注意,要把这些接口的域名配置到小程序的合法域名中,不然也是访问不了的
(8)wxss 有一个坑:无法读取本地资源,比如背景图片用本地就会报错哦。
把本地图片弄成网络图片的几种方式: 上传到个人网站;QQ 空间相册等等也是可以的哦
2. 切换城市页面:
(1)首页使用 navigateTo 跳转到切换城市页,由于首页并没有关闭,导致切换了城市返回来,天气信息还是旧的。
正确的处理逻辑如下:
1)使用 reLaunch 跳转到切换城市页面,实质是关闭所有页面打开新的页面哦。
2)切换城市页面,更新公共变量中城市信息为手动切换的城区,再 switchTab 回到首页,触发首页重新加载。
3)首页获取城市信息的时候加一个判断,全局没有才取定位的,全局有(比如刚才设置了)就用全局的哦。
(2)城市列表的滚动和回到顶部
基于 scroll-view 组件的 scroll-top 属性,初始就是 0,滚动就会增加的;点击回到顶部给它置为 0 即可回到顶部
3. 天气页
(1)初始化页面,天气显示的逻辑
首先调用小程序的 wx.getLocation 方法获得当前的经纬度,然后调用腾讯地图获得当前的城市名称和区县名称,并存到公共变量中,
再调用查询天气和空气质量的方法哦。
(2)容错处理
城市的名称长短不一,有点名字特别长,比如巴彦淖尔市这种,需要动态的获取完整的城市名称;
有些偏僻的城市暂时没有天气信息,我们需要对返回的结果进行判断,没有信息的需要给用户一个良好的提示信息。
4. 周边 - 地图服务页面
(1)调用百度地图的各种服务,查询酒店,美食,生活服务三种信息,更多信息可以看百度地图的文档
(2)点击时给被点中的图标加个边框,数据驱动视图,所以使用一个长度为 3 的数组保存三个图标当前是否被点中的状态
然后 wxml 再根据数据来动态添加 class,增加边框样式
5. 豆瓣电影页
(1)电影详情页的预览图片,用小程序本身的 previewImage 实现。
(2)详情页使用 onReachBottom () 方法,监控用户上拉触底事件,然后发送请求继续获得数据,实现懒加载的效果
(3)用户体验方面的优化,js 中将整数评分比如 7 分统一改为 7.0 分,然后 wxml 模板再判断分数是否为 0 显示 “暂无评分”
(4)搜索之后清空搜索框
因为小程序中不能使用 getelementbyId 这种方式获得元素,只能用数据来控制了
在 data 中加一个属性 searchText 来保存搜索框的内容并和 input 的 value 属性绑定,搜索完成或者点击 X 时,searchText 变量清空即可实现清空输入框的效果哦。
6. 新闻页面
(1)聚合头条新闻的免费接口,只返回了新闻的基本信息,新闻的主体内容是没有的哦。
我找了好多新闻类的接口,好像都是没有新闻主体内容的。如果谁知道更好的接口欢迎留言告诉我哈~
(2)当然,也可以自己去爬新闻网站的数据哦
7. 更多页面
(1)小程序目前开放外链的功能只是给公司组织的小程序开放了,个人开发还是不能使用外链的哦。
(2)彩蛋页面,获得用户信息
通过 wx.setStorageSync ('userInfos', userInfos); 可以获得登陆小程序的用户的个人信息,可以发送给后台存到数据库中,方便对用户进行分析
我这里只是存储到浏览器缓存中哦,最大应该是 10M 缓存;如果用户把这个小程序从小程序列表中删除掉,就会清空这个缓存。
8. 发布注意
(1) 新版本小程序发布的限制为 2M,一般都是图片最占空间,所以尽量使用网络图片
具体怎么把本地图片变成网络图片,上面有讲哦。
(2)在开发者工具上预览测试没问题,点击上传;网页版小程序个的人中心的左侧 “开发管理” 菜单,第三块 -- 开发版本就有了内容。
(3)点击提交,填写小程序相关信息,就可以提交审核了哦。
注意:分类最好填写准确,这样才能更快的通过审核哦。我这个小程序一天半时间过审上线的
至此,我就把两天开发内碰到的坑和注意点都过了一遍,据说还有更多的坑,等之后更深入的开发再继续研究咯。
四。写在最后
(1)知乎一篇小程序的资料:
https://www.zhihu.com/question/50907897
(2)小程序社区
http://www.wxapp-union.com/portal.php
(3)极乐小程序商店
大家好,我是 bigsai,好久不见,甚是想念 (天天想念)!
很久前就有小伙伴被动态规划所折磨,确实,很多题动态规划确实太难看出了了,甚至有的题看了题解理解起来都费劲半天。
动态规划的范围虽然确实是很广很难,但是从整个动态规划出现的频率来看,这几种基础的动态规划理解容易,学习起来压力不大,并且出现频率非常高。
这几个常见的动态规划有:连续子数组最大和,子数组的最大乘积,最长递增子序列 (LIS),最长公共子序列 (LCS),最长公共子串,最长公共子串,不同子序列。
首先很多人问,何为动态规划?动态规划(Dynamic Programming,DP)是运筹学的一个分支,是求解决策过程最优化的过程。通俗一点动态规划就是从下往上 (从前向后) 阶梯型求解数值。
那么动态规划和递归有什么区别和联系?
总的来说动态规划从前向后,递归从后向前,两者策略不同,并且一般动态规划效率高于递归。
不过都要考虑初始状态,上下层数据之间的联系。很多时候用动态规划能解决的问题,用递归也能解决不过很多时候效率不高可能会用到记忆化搜索。
不太明白?
就拿求解斐波那契额数列来说,如果直接用递归不优化,那么复杂度太多会进行很多重复的计算。
但是利用记忆化你可以理解为一层缓存,将求过的值存下来下次再遇到就直接使用就可以了。
实现记忆化搜索求斐波那契代码为:
static long F(int n,long record[]){ if(n==1||n==2) {return 1;} if(record[n]>0) return record[n]; else record[n]=F(n-1,record)+F(n-2,record); return record[n];}public static void main(String[] args) { int n=6; long[] record = new long[n+1]; System.out.println(F(n,record));}
而动态规划的方式你可以从前往后逻辑处理,从第三个开始每个 dp 都是前两个 dp 之和。
public int fib(int n) { int dp[]=new int[n+1]; dp[0]=0; dp[1]=1; for(int i=2;i<n+1;i++){ dp[i]=dp[i-1]+dp[i-2]; } return dp[n]; }
当然动态规划也能有很多空间优化,有些只用一次的值,你可以用一些变量去替代。有些二维数组很大也可以用一维数组交替替代。当然动态规划专题很大,有很多比如树形 dp、状压 dp、背包问题等等经常出现在竞赛中,能力有限这里就将一些出现笔试高频的动态规划!
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6。
dp 的方法就是 O (n) 的方法。如果 dp [i] 表示以第 i 个结尾的最大序列和,而这个 dp 的状态方程为:
dp[0]=a[0]dp[i]=max(dp[i-1]+a[i],a[i])
也不难解释,如果以前一个为截至的最大子序列和大于 0,那么就连接本个元素,否则本个元素就自立门户。
实现代码为:
public int maxSubArray(int[] nums) { int dp[]=new int[nums.length]; int max=nums[0]; dp[0]=nums[0]; for(int i=1;i<nums.length;i++) { dp[i]=Math.max(dp[i-1]+nums[i],nums[i]); if(dp[i]>max) max=dp[i]; } return max;}
ps: 有小伙伴问那求可以不连续的数组最大和呢?你好好想想枚举一下正的收入囊中,那个问题没意义的。
给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
示例 :
输入: [2,3,-2,4]
输出: 6
解释:子数组 [2,3] 有最大乘积 6。
连续子数组的最大乘积,这也是一道经典的动态规划问题,但是和普通动态规划又有点小不同。
如果数据中都是非负数,对于连续数组的最大乘积,那样处理起来和前面连续子数组最大和处理起来有些相似,要么和前面的叠乘,要么自立门户。
dp[0]=nums[0]dp[i]=max(dp[i-1]*a[i],a[i])
但是这里面的数据会出现负数,乘以一个负数它可能从最大变成最小,并且还有负负得正就又可能变成最大了。
这时候该怎么考虑呢?
容易,我们开两个 dp,一个 dpmax[] 记录乘积的最大值,一个 dpmin[] 记录乘积的最小值。然后每次都更新 dpmax 和 dpmin 不管当前值是正数还是负数。这样通过这两个数组就可以记录乘积的绝对值最大。
动态方程也很容易
dpmax[i]=max(dpmax[i-1]*nums[i],dpmin[i-1]*nums[i],nums[i])dpmin[i]=min(dpmax[i-1]*nums[i],dpmin[i-1]*nums[i],nums[i])
看一个过程就能理解明白,dpmin 就是起到中间过度的作用,记录一些可能的负极值以防备用。结果还是 dpmax 中的值。
最长递增子序列,也称为 LIS, 是出现非常高频的动态规划算法之一。这里对应力扣 300
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
输入:nums = [0,1,0,3,2,3]
输出:4
解释:最长递增子序列是 [0,1,2,3],因此长度为 4 。
对于最长递增子序列,如果不考虑动态规划的方法,使用暴力枚举其实还是比较麻烦的,因为你不知道遇到比前面元素大的是否要递增。
比如 1 10 3 11 4 5,这个序列不能选取 1 10 11 而 1 3 4 5 才是最大的,所以暴力枚举所有情况的时间复杂度还是非常高的。
如果我们采取动态规划的方法,创建的 dp[] 数组,dp [i] 表示以 nums[i] 结尾的最长递增子序列,而 dp [i] 的求解方式就是枚举 i 号前面的元素和对应结尾的最长子序列,找到一个元素值小于 nums[i] 并且递增序列最长,这样的时间复杂度为 O (n2)。
状态转移方程为:
dp[i]=max(dp[j])+1, 其中0≤j<i且num[j]<num[i]
具体流程为:
实现代码为:
class Solution { public int lengthOfLIS(int[] nums) { int dp[]=new int[nums.length]; int maxLen=1; dp[0]=1; for(int i=1;i<nums.length;i++){ int max=0;//统计前面 末尾数字比自己小 最长递增子串 for(int j=0;j<i;j++){//枚举 //结尾数字小于当前数字 并且长度大于记录的最长 if(nums[j]<nums[i]&&dp[j]>max){ max=dp[j]; } } dp[i]=max+1;//前面最长 加上自己 if(maxLen<dp[i]) maxLen=dp[i]; } return maxLen; }}
不过这道题还有一个优化,可以优化成 O (nlogn) 的时间复杂度。
我们用 dp 记录以 nums[i] 结尾的最长子序列长度,纵观全局,我们希望在长度一致的情况下末尾的值能够尽量的小!
例如 2,3,9,5 …… 在前面最长的长度为 3 我们愿意抛弃 2,3,9 而全部使用 2,3,5 。也就是对于一个值,我们希望这个值能更新以它为结尾的最长的序列的末尾值。
如果这个值更新不了最长的序列,那就尝试更新第二长的末尾值以防待用。例如 2,3,9,5,4,5 这个序列 2,3,5 更新 2,3,9; 然后 2,3,4 更新 2,3,5 为最长的 2,3,4,5 做铺垫。
而这个思路的核心就是维护一个 lenth[] 数组,length [i] 表示长度为 i 的子序列末尾最小值,因为我们每次顺序增加一个长度说明这个值比前面的都大 (做了充分比较),所以这个数组也是个递增的,递增,那么在锁定位置更新最大长度序列尾值的时候可以使用二分法优化。
实现代码为:
class Solution { public int lengthOfLIS(int[] nums) { int length[]=new int[nums.length]; int len=1; length[0]=nums[0]; for(int i=1;i<nums.length;i++){ int left=0,right=len; while (left<right){ int mid=left+(right-left)/2; if(length[mid]<nums[i]){ left=mid+1; }else { right=mid; } } length[left]=nums[i]; if(right==len) len++; } return len; }}
最长公共子序列也成为 LCS. 出现频率非常高!
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
拿 b c d d e 和 a c e e d e 举例,其的公共子串为 c d e。如果使用暴力,复杂度太高会直接超时,就需要使用动态规划。两个字符串匹配,我们设立二维 dp[][] 数组,dp[i][j] 表示 text1 串第 i 个结尾,text2 串第 j 个结尾的最长公共子串的长度。
这里核心就是要搞懂状态转移,分析 dp[i][j] 的转换情况,当到达 i,j 时候:
如果 text1[i]==text2[j], 因为两个元素都在最末尾的位置,所以一定可以匹配成功,换句话说,这个位置的邻居 dp 值不可能大于他(最多相等)。所以这个时候就是 dp[i][j]\=dp[i-1][j-1] +1;
如果 text1[i]!=text2[j],就有两种可能性,我们知道的邻居有 dp[i-1][j],dp[i][j-1],很多人还会想到 dp[i-1][j-1] 这个一定比前两个小于等于,因为就是前面两个子范围嘛!所以这时就相当于末尾匹配不成,就要看看邻居能匹配的最大值啦,此时 dp[i][j]\=max(dp[i][j-1],dp[i-1][j])。
所以整个状态转移方程为:
dp[i][j] = dp[i-1][j-1] + 1 //text1[i]==text2[j]时dp[i][j] = max(dp[i][j-1],dp[i-1][j]) //text1[i]!=text2[j]时
实现代码为:
class Solution { public int longestCommonSubsequence(String text1, String text2) { char ch1[]=text1.toCharArray(); char ch2[]=text2.toCharArray(); int dp[][]=new int[ch1.length+1][ch2.length+1]; for(int i=0;i<ch1.length;i++) { for(int j=0;j<ch2.length;j++) { if(ch1[i]==ch2[j]) { dp[i+1][j+1]=dp[i][j]+1; } else dp[i+1][j+1]=Math.max(dp[i][j+1],dp[i+1][j]); } } return dp[ch1.length][ch2.length]; }}
给定两个字符串 str1 和 str2, 输出两个字符串的最长公共子串。
例如 abceef 和 a2b2cee3f 的最长公共子串就是 cee。公共子串是两个串中最长连续的相同部分。
如何分析呢?和上面最长公共子序列的分析方式相似,要进行动态规划匹配,并且逻辑上处理更简单,只要当前 i,j 不匹配那么 dp 值就为 0,如果可以匹配那么就变成 dp[i-1][j-1] + 1
核心的状态转移方程为:
dp[i][j] = dp[i-1][j-1] + 1 //text1[i]==text2[j]时dp[i][j] = 0 //text1[i]!=text2[j]时
这里代码和上面很相似就不写啦,但是有个问题有的会让你输出最长字符串之类,你要记得用一些变量存储值。
不同子序列也会出现,并且有些难度,前面这篇不同子序列问题分析讲的大家可以看看。
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
示例 :
输入:s = "rabbbit", t = "rabbit"输出:3解释:如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。(上箭头符号 ^ 表示选取的字母)rabbbit^^^^ ^^rabbbit^^ ^^^^rabbbit^^^ ^^^
分析:
这个问题其实就是上面有几个 pat 的变形拓展,其基本**其实是一致的,上面那题问的是有几个 pat,固定、且很短。但这里面 t 串的长度不固定,所以处理上就要使用数组来处理而不能直接 if else。
这题的思路肯定也是动态规划 dp 了,dp[j] 的意思就是 t 串中 [0,j-1] 长字符在 s 中能够匹配的数量 (当然这个值从前往后是动态变化的),数组大小为 dp[t.length+1]。在遍历 s 串的每一个元素都要和 t 串中所有元素进行对比看看是否相等,如果 s 串枚举到的这个串和 t 串中的第 j 个相等。那么 dp[j+1]+=dp[j]。你可能会问为啥是 dp[j+1], 因为第一个元素匹配到需要将数量 + 1,而这里为了避免这样的判断我们将 dp[0]=1, 这样 t 串的每个元素都能正常的操作。
但是有一点需要注意的就是在遍历 s 串中第 i 个字母的时候,遍历 t 串比较不能从左向右而必须从右向左。因为在遍历 s 串的第 i 个字符在枚举 dp 数组时候要求此刻数据是相对静止的叠加 (即同一层次不能产生影响),而从左往右进行遇到相同字符会对后面的值产生影响。区别的话可以参考下图这个例子:
实现的代码为:
class Solution { public int numDistinct(String s, String t) { char s1[]=s.toCharArray(); char t1[]=t.toCharArray(); int dp[]=new int[t1.length+1]; dp[0]=1;//用来叠加 for(int i=0;i<s1.length;i++) { for(int j=t1.length-1;j>=0;j--) { if(t1[j]==s1[i]) { dp[j+1]+=dp[j]; } } } return dp[t1.length]; }}
至此,简单的动态规划算是分享完了。
大部分简单动态规划还是有套路的,你看到一些数组问题、字符串问题很有可能就暗藏动态规划。动态规划的套路跟递归有点点相似,主要是找到状态转移方程,有时候考虑问题不能一步想的太多 (想太多可能就把自己绕进去了),而动态规划就是要大家对数值上下转换计算需要了解其中关系。
对于复杂 dp 问题或者很多套一层壳确实很难看出来,但是掌握上面的常见 dp 问题和背包问题,就可以解决大部分动态规划问题啦 (毕竟咱们不是搞竞赛遇到的还是偏简单或者中等难度的)。
推荐阅读:
最近,大赛把他的原创文章整理成一本数据结构与算法 pdf,一共 218 页会定期更新维护,关注他的公众号【bigsai】回复【666】即可领取,可以点击下面名片关注。
原创不易,求个点赞和在看!!
https://mp.weixin.qq.com/s/QwkZYEFTWZJtngQMarCxKg
0×01 前言
信息搜集分为主动信息搜集和被动信息搜集,主动信息搜集是与目标主机进行直接交互,从而拿到我们的目标信息,而被动信息搜集恰恰与主动信息搜集相反,不与目标主机进行直接交互,通过搜索引擎或者社交等方式间接的获取目标主机的信息。当我们拿到一个目标进行渗透测试的时候,我们关注目标主机的 whois 信息,子域名,目标 IP,旁站 C 段查询,邮箱搜集,CMS 类型,敏感目录,端口信息,服务器与中间件信息。针对上边的信息,网上有很多工具,但是,我们可以自己写一个工具得到所有的信息,方便渗透测试。
0×02 whois 信息
whois 信息可以获取关键注册人的信息,包括注册公司、注册邮箱、管理员邮箱、管理员联系手机等,对后期社工很有用。同时该工具还可以查询同一注册人注册的其他的域名,域名对应的 NS 记录、MX 记录,自动识别国内常见的托管商(万网、新网等)。常用的工具有:chinaz,kali 下的 whois 命令。
0×03 子域名
在渗透测试的时候,往往主站的防御会很强,常常无从下手,那么子站就是一个重要的突破口,因此子域名是渗透测试的主要关注对象,子域名搜集的越完整,那么挖到的漏洞就可能更多,甚至漏洞的级别也会更高。常用的工具有:搜索引擎(google,baidu,bing),DNS 区域传送漏洞,子域名挖掘机 Layer,subDomainsBrute,phpinfo.me, 定制字典暴力破解。
0×04 目标 IP
现在大部分网站都加了 CDN,CDN 的虚假 IP 干扰了我们的渗透测试,如何绕过 CDN 查找到目标的真实 IP,对我们来说非常重要。首先,我们需要判断下是否存在 CDN, 方法很简单,只要在不同地区进行 ping 检测就可以知道。不同地区 ping 同一个网址,得到不同的 IP 地址,那么该网站开启了 CDN 加速,相反如果得到的是同一个 IP 地址,那么极大可能不存在 cdn,但是不绝对。常用的工具有多个地点 ping 服务器 - 网站测速 - 站长工具。其次,绕过 CDN 获取真实 IP 的方法互联网上有很多,我常用的有二级域名法,目标长得一般不会把所有的二级域名放在 cdn 上,伤钱呐,确定了没有使用 CDN 的二级域名后,本地将目标域名绑定到同 ip,能访问就说明目标站与二级域名在同一服务器叶可能在同 C 段,扫描 C 段所有开 80 端口的 ip,挨个尝试。nslookup 法,大部分 CDN 提供商只针对国内市场,而对国外市场几乎是不做 CDN,所以有很大的几率直接解析到真实 IP,不过需要国外的冷门的 DNS,如下:
209.244.0.3
64.6.64.6
8.8.8.8
9.9.9.9
8.26.56.26
199.85.126.10
208.67.222.222
195.46.39.39
69.195.152.204
208.76.50.50
216.146.35.35
37.235.1.174
198.101.242.72
77.88.8.8
91.239.100.100
74.82.42.42
109.69.8.51
156.154.70.1
1.1.1.1
45.77.165.194
0×05 旁站 C 段查询
旁站是和目标网站在同一台服务器上的其它的网站;如果从目标站本身找不到好的入手点,这时候,如果想快速拿下目标的话,一般都会先找个目标站点所在服务器上其他的比较好搞的站下手,然后再想办法跨到真正目标的站点目录中。C 段是和目标机器 ip 处在同一个 C 段的其它机器;通过目标所在 C 段的其他任一台机器,想办法跨到我们的目标机器上。常用的工具有 webscancc,Nmap,Zenmap。
0×06 邮箱收集
首先确定目标的邮件服务器所在的真实位置,看看邮件服务器自身有没有什么错误配置,比如,没有禁用 VREY 或者 EXPN 命令导致用户信息泄露。然后从 whois 中获取域名的注册人、管理员邮箱,利用搜索引擎或者社工库查看有木有泄露的密码,然后尝试泄露的密码进行登录,最后从目标站点上搜集邮箱,例如网站上的联系我们,我们发发邮件钓鱼什么的。常用的工具有 kali 下的 theharester。
0×07 CMS 类型
对目标渗透测试过程中,目标 CMS 是十分重要的信息,有了目标的 CMS,就可以利用相关的 bug 进行测试,进行代码审计。CMS 识别方式有网站特有文件,例如 /templets/default/style/dedecms.css — dedecms;网站独有文件的 md5,例如 favicon.ico,但是该文件可以被修改导致不准确;网站命名规则;返回头的关键字;网页关键字;URL 特征;Meta 特征;Script 特征;robots.txt;网站路径特征;网站静态资源;爬取网站目录信息;常用的工具有 云悉,工具 1,BugScaner。
0×08 敏感目录 / 文件
用扫描器扫描目录,这时候你需要一本强大的字典,重在平时积累。字典越强扫描处的结果可能越多,这一步主要扫出网站的管理员入口,一些敏感文件(.mdb,.excel,.word,.zip,.rar), 查看是否存在源代码泄露。常见有. git 文件泄露,.svn 文件泄露,.DB_store 文件泄露,WEB-INF/web.xml 泄露。目录扫描有两种方式,使用目录字典进行暴力才接存在该目录或文件返回 200 或者 403;使用爬虫爬行主页上的所有链接,对每个链接进行再次爬行,收集这个域名下的所有链接,然后总结出需要的信息。常用的工具有:御剑,kali 下的 dirb,DirBrute。
0×09 端口信息
服务和安全是相对应的,每开启一个端口,那么攻击面就大了一点,开启的端口越多,也就意味着服务器面临的威胁越大。开始扫描之前不妨使用 telnet 先简单探测下某些端口是否开放,避免使用扫描器而被封 IP,扫描全端口一般使用 Nmap,masscan 进行扫描探测,尽可能多的搜集开启的端口好已经对应的服务版本,得到确切的服务版本后可以搜索有没有对应版本的漏洞。常见的端口信息及渗透方法。
端口号 端口服务 / 协议简要说明 关于端口可能的一些渗透用途 tcp 20,21 ftp 默认的数据和命令传输端口 [可明文亦可加密传输] 允许匿名的上传下载,爆破,嗅探,win 提权,远程执行 (proftpd 1.3.5), 各类后门 (proftpd,vsftp 2.3.4)
tcp 22ssh [数据 ssl 加密传输] 可根据已搜集到的信息尝试爆破,v1 版本可中间人,ssh 隧道及内网代理转发,文件传输,等等… 常用于 linux 远程管理…
tcp 23telnet [明文传输] 爆破,嗅探,一般常用于路由,交换登陆,可尝试弱口令,也许会有意想不到的收获
tcp 25smtp [简单邮件传输协议,多数 linux 发行版可能会默认开启此服务] 邮件伪造,vrfy/expn 查询邮件用户信息,可使用 smtp-user-enum 工具来自动跑
tcp/udp 53dns [域名解析] 允许区域传送,dns 劫持,缓存投毒,欺骗以及各种基于 dns 隧道的远控
tcp/udp 69tftp [简单文件传输协议,无认证] 尝试下载目标及其的各类重要配置文件
tcp 80-89,443,8440-8450,8080-8089web [各种常用的 web 服务端口] 各种常用 web 服务端口,可尝试经典的 top n,vpn,owa,webmail, 目标 oa, 各类 java 控制台,各类服务器 web 管理面板,各类 web 中间件漏洞利用,各类 web 框架漏洞利用等等……
tcp 110 [邮局协议,可明文可密文] 可尝试爆破,嗅探
tcp 137,139,445samba [smb 实现 windows 和 linux 间文件共享,明文] 可尝试爆破以及 smb 自身的各种远程执行类漏洞利用,如,ms08-067,ms17-010, 嗅探等……
tcp 143imap [可明文可密文] 可尝试爆破
udp 161snmp [明文] 爆破默认团队字符串,搜集目标内网信息
tcp 389ldap [轻量级目录访问协议] ldap 注入,允许匿名访问,弱口令
tcp 512,513,514linux rexec 可爆破,rlogin 登陆
tcp 873rsync 备份服务匿名访问,文件上传
tcp 1194openvpn 想办法钓 vpn 账号,进内网
tcp 1352Lotus domino 邮件服务弱口令,信息泄漏,爆破
tcp 1433mssql 数据库注入,提权,sa 弱口令,爆破
tcp 1521oracle 数据库 tns 爆破,注入,弹 shell…
tcp 1500ispmanager 主机控制面板弱口令
tcp 1025,111,2049nfs 权限配置不当
tcp 1723pptp 爆破,想办法钓 vpn 账号,进内网
tcp 2082,2083cpanel 主机管理面板登录弱口令
tcp 2181zookeeper 未授权访问
tcp 2601,2604zebra 路由默认密码 zerbra
tcp 3128squid 代理服务弱口令
tcp 3312,3311kangle 主机管理登录弱口令
tcp 3306mysql 数据库注入,提权,爆破
tcp 3389windows rdp 远程桌面 shift 后门 [需要 03 以下的系统], 爆破,ms12-020 [蓝屏 exp]
tcp 4848glassfish 控制台弱口令
tcp 4899radmin 远程桌面管理工具,现在已经非常非常少了抓密码拓展机器
tcp 5000sybase/DB2 数据库爆破,注入
tcp 5432postgresql 数据库爆破,注入,弱口令
tcp 5632pcanywhere 远程桌面管理工具抓密码,代码执行,已经快退出历史舞台了
tcp 5900,5901,5902vnc 远程桌面管理工具弱口令爆破,如果信息搜集不到位,成功几率很小
tcp 5984CouchDB 未授权导致的任意指令执行
tcp 6379redis 未授权可尝试未授权访问,弱口令爆破
tcp 7001,7002weblogic 控制台 java 反序列化,弱口令
tcp 7778kloxo 主机面板登录
tcp 8000Ajenti 主机控制面板弱口令
tcp 8443plesk 主机控制面板弱口令
tcp 8069zabbix 远程执行,sql 注入
tcp 8080-8089Jenkins,jboss 反序列化,控制台弱口令
tcp 9080-9081,9090websphere 控制台 java 反序列化 / 弱口令
tcp 9200,9300elasticsearch 远程执行
tcp 10000webmin linux 主机 web 控制面板入口弱口令
tcp 11211memcached 未授权访问
tcp 27017,27018mongodb 爆破,未授权访问
tcp 3690svn 服务 svn 泄露,未授权访问
tcp 50000SAP Management Console 远程执行
tcp 50070,50030hadoop 默认端口未授权访问
0×10 服务器与中间件信息
通过 Nmap、Zmap 等端口和指纹识别功能搜集,也可以使用 nc 和 telnet 获取 Banner 信息进行识别,常用工具有 whatweb
0×11 其他
探测目标是否存在 WAF,WAF 识别一般是基于 headers 头信息,例如,Mod_Security 是为 Apache 设计的开源 Web 防护模块,一个恶意的请求 Mod_Security 会在响应头返回 “406 Not acceptable” 的信息。waf00f 是 kali 下的识别 WAF 的老工具,whatwaf 不仅可以识别 WAF 类型还会给出一些 bypass 方法;另外从乌云镜像站、CNVD 搜集网站历史漏洞对渗透测试也是有很大帮助的。
0×12 自己写的小脚本
基于以上内容写个一个蹩脚的脚本,大佬勿喷。
0×13 总结
信息搜集在渗透测试中的作用不言而喻,脚本基于以上文章的内容的编写,笔者还会继续完善,若读者有什么建议可以留言。菜鸡一定虚心接受。最后,信息搜集很重要,信息搜集很重要,信息搜集很重要。
https://zhuanlan.zhihu.com/p/41329579
JavaKeeper
2020-10-30 1517 浏览量
简介: 1. 三个线程分别打印 A,B,C,要求这三个线程一起运行,打印 n 次,输出形如 “ABCABCABC....” 的字符串 2. 两个线程交替打印 0~100 的奇偶数 3. 通过 N 个线程顺序循环打印从 0 至 100 4. 多线程按顺序调用,A->B->C,AA 打印 5 次,BB 打印 10 次,CC 打印 15 次,重复 10 次 5. 用两个线程,一个输出字母,一个输出数字,交替输出 1A2B3C4D...26Z
大家在换工作面试中,除了一些常规算法题,还会遇到各种需要手写的题目,所以打算总结出来,给大家个参考。
第一篇打算总结下阿里最喜欢问的多个线程顺序打印问题,我遇到的是机试,直接写出运行。同类型的题目有很多,比如
其实这类题目考察的都是线程间的通信问题,基于这类题目,做一个整理,方便日后手撕面试官,文明的打工人,手撕面试题。
我们以第一题为例:三个线程分别打印 A,B,C,要求这三个线程一起运行,打印 n 次,输出形如 “ABCABCABC....” 的字符串。
思路:使用一个取模的判断逻辑 C%M ==N,题为 3 个线程,所以可以按取模结果编号:0、1、2,他们与 3 取模结果仍为本身,则执行打印逻辑。
public class PrintABCUsingLock {
private int times; // 控制打印次数
private int state; // 当前状态值:保证三个线程之间交替打印
private Lock lock = new ReentrantLock();
public PrintABCUsingLock(int times) {
this.times = times;
}
private void printLetter(String name, int targetNum) {
for (int i = 0; i < times; ) {
lock.lock();
if (state % 3 == targetNum) {
state++;
i++;
System.out.print(name);
}
lock.unlock();
}
}
public static void main(String[] args) {
PrintABCUsingLock loopThread = new PrintABCUsingLock(1);
new Thread(() -> {
loopThread.printLetter("B", 1);
}, "B").start();
new Thread(() -> {
loopThread.printLetter("A", 0);
}, "A").start();
new Thread(() -> {
loopThread.printLetter("C", 2);
}, "C").start();
}
}```
main 方法启动后,3 个线程会抢锁,但是 state 的初始值为 0,所以第一次执行 if 语句的内容只能是 **线程 A**,然后还在 for 循环之内,此时 `state = 1`,只有 **线程 B** 才满足 `1% 3 == 1`,所以第二个执行的是 B,同理只有 **线程 C** 才满足 `2% 3 == 2`,所以第三个执行的是 C,执行完 ABC 之后,才去执行第二次 for 循环,所以要把 i++ 写在 for 循环里边,不能写成 `for (int i = 0; i < times;i++)` 这样。
使用 wait/notify
--------------
其实遇到这类型题目,好多同学可能会先想到的就是 join (),或者 wati/notify 这样的思路。算是比较传统且万能的解决方案。也有些面试官会要求不能使用这种方式。
思路:还是以第一题为例,我们用对象监视器来实现,通过 `wait` 和 `notify()` 方法来实现等待、通知的逻辑,A 执行后,唤醒 B,B 执行后唤醒 C,C 执行后再唤醒 A,这样循环的等待、唤醒来达到目的。
```null
public class PrintABCUsingWaitNotify {
private int state;
private int times;
private static final Object LOCK = new Object();
public PrintABCUsingWaitNotify(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingWaitNotify printABC = new PrintABCUsingWaitNotify(10);
new Thread(() -> {
printABC.printLetter("A", 0);
}, "A").start();
new Thread(() -> {
printABC.printLetter("B", 1);
}, "B").start();
new Thread(() -> {
printABC.printLetter("C", 2);
}, "C").start();
}
private void printLetter(String name, int targetState) {
for (int i = 0; i < times; i++) {
synchronized (LOCK) {
while (state % 3 != targetState) {
try {
LOCK.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
state++;
System.out.print(name);
LOCK.notifyAll();
}
}
}
}```
同样的思路,来解决下第 2 题:两个线程交替打印奇数和偶数
使用对象监视器实现,两个线程 A、B 竞争同一把锁,只要其中一个线程获取锁成功,就打印 ++i,并通知另一线程从等待集合中释放,然后自身线程加入等待集合并释放锁即可。

```null
public class OddEvenPrinter {
private Object monitor = new Object();
private final int limit;
private volatile int count;
OddEvenPrinter(int initCount, int times) {
this.count = initCount;
this.limit = times;
}
public static void main(String[] args) {
OddEvenPrinter printer = new OddEvenPrinter(0, 10);
new Thread(printer::print, "odd").start();
new Thread(printer::print, "even").start();
}
private void print() {
synchronized (monitor) {
while (count < limit) {
try {
System.out.println(String.format("线程[%s]打印数字:%d", Thread.currentThread().getName(), ++count));
monitor.notifyAll();
monitor.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//防止有子线程被阻塞未被唤醒,导致主线程不退出
monitor.notifyAll();
}
}
}```
同样的思路,来解决下第 5 题:用两个线程,一个输出字母,一个输出数字,交替输出 1A2B3C4D...26Z
```null
public class NumAndLetterPrinter {
private static char c = 'A';
private static int i = 0;
static final Object lock = new Object();
public static void main(String[] args) {
new Thread(() -> printer(), "numThread").start();
new Thread(() -> printer(), "letterThread").start();
}
private static void printer() {
synchronized (lock) {
for (int i = 0; i < 26; i++) {
if (Thread.currentThread().getName() == "numThread") {
//打印数字1-26
System.out.print((i + 1));
// 唤醒其他在等待的线程
lock.notifyAll();
try {
// 让当前线程释放锁资源,进入wait状态
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else if (Thread.currentThread().getName() == "letterThread") {
// 打印字母A-Z
System.out.print((char) ('A' + i));
// 唤醒其他在等待的线程
lock.notifyAll();
try {
// 让当前线程释放锁资源,进入wait状态
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
lock.notifyAll();
}
}
}```
使用 Lock/Condition
-----------------
还是以第一题为例,使用 Condition 来实现,其实和 wait/notify 的思路一样。
> Condition 中的 `await()` 方法相当于 Object 的 `wait()` 方法,Condition 中的 `signal()` 方法相当于 Object 的 `notify()` 方法,Condition 中的 `signalAll()` 相当于 Object 的 `notifyAll()` 方法。
>
> 不同的是,Object 中的 `wait(),notify(),notifyAll()` 方法是和 `"同步锁"`(synchronized 关键字) 捆绑使用的;而 Condition 是需要与 `"互斥锁"/"共享锁"` 捆绑使用的。
```null
public class PrintABCUsingLockCondition {
private int times;
private int state;
private static Lock lock = new ReentrantLock();
private static Condition c1 = lock.newCondition();
private static Condition c2 = lock.newCondition();
private static Condition c3 = lock.newCondition();
public PrintABCUsingLockCondition(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingLockCondition print = new PrintABCUsingLockCondition(10);
new Thread(() -> {
print.printLetter("A", 0, c1, c2);
}, "A").start();
new Thread(() -> {
print.printLetter("B", 1, c2, c3);
}, "B").start();
new Thread(() -> {
print.printLetter("C", 2, c3, c1);
}, "C").start();
}
private void printLetter(String name, int targetState, Condition current, Condition next) {
for (int i = 0; i < times; ) {
lock.lock();
try {
while (state % 3 != targetState) {
current.await();
}
state++;
i++;
System.out.print(name);
next.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}```
使用 Lock 锁的多个 Condition 可以实现精准唤醒,所以碰到那种多个线程交替打印不同次数的题就比较容易想到,比如解决第四题:多线程按顺序调用,A->B->C,AA 打印 5 次,BB 打印 10 次,CC 打印 15 次,重复 10 次
代码就不贴了,思路相同。
> 以上几种方式,其实都会存在一个锁的抢夺过程,如果抢锁的的线程数量足够大,就会出现很多线程抢到了锁但不该自己执行,然后就又解锁或 wait () 这种操作,这样其实是有些浪费资源的。
使用 Semaphore
------------
> 在信号量上我们定义两种操作: 信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
>
> 1. acquire(获取) 当一个线程调用 acquire 操作时,它要么通过成功获取信号量(信号量减 1),要么一直等下去,直到有线程释放信号量,或超时。
> 2. release(释放)实际上会将信号量的值加 1,然后唤醒等待的线程。
先看下如何解决第一题:三个线程循环打印 A,B,C
```null
public class PrintABCUsingSemaphore {
private int times;
private static Semaphore semaphoreA = new Semaphore(1); // 只有A 初始信号量为1,第一次获取到的只能是A
private static Semaphore semaphoreB = new Semaphore(0);
private static Semaphore semaphoreC = new Semaphore(0);
public PrintABCUsingSemaphore(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingSemaphore printer = new PrintABCUsingSemaphore(1);
new Thread(() -> {
printer.print("A", semaphoreA, semaphoreB);
}, "A").start();
new Thread(() -> {
printer.print("B", semaphoreB, semaphoreC);
}, "B").start();
new Thread(() -> {
printer.print("C", semaphoreC, semaphoreA);
}, "C").start();
}
private void print(String name, Semaphore current, Semaphore next) {
for (int i = 0; i < times; i++) {
try {
System.out.println("111" + Thread.currentThread().getName());
current.acquire(); // A获取信号执行,A信号量减1,当A为0时将无法继续获得该信号量
System.out.print(name);
next.release(); // B释放信号,B信号量加1(初始为0),此时可以获取B信号量
System.out.println("222" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}```
如果题目中是多个线程循环打印的话,一般使用信号量解决是效率较高的方案,上一个线程持有下一个线程的信号量,通过一个信号量数组将全部关联起来,这种方式不会存在浪费资源的情况。
接着用信号量的方式解决下第三题:通过 N 个线程顺序循环打印从 0 至 100
```null
public class LoopPrinter {
private final static int THREAD_COUNT = 3;
static int result = 0;
static int maxNum = 10;
public static void main(String[] args) throws InterruptedException {
final Semaphore[] semaphores = new Semaphore[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
//非公平信号量,每个信号量初始计数都为1
semaphores[i] = new Semaphore(1);
if (i != THREAD_COUNT - 1) {
System.out.println(i+"==="+semaphores[i].getQueueLength());
//获取一个许可前线程将一直阻塞, for 循环之后只有 syncObjects[2] 没有被阻塞
semaphores[i].acquire();
}
}
for (int i = 0; i < THREAD_COUNT; i++) {
// 初次执行,上一个信号量是 syncObjects[2]
final Semaphore lastSemphore = i == 0 ? semaphores[THREAD_COUNT - 1] : semaphores[i - 1];
final Semaphore currentSemphore = semaphores[i];
final int index = i;
new Thread(() -> {
try {
while (true) {
// 初次执行,让第一个 for 循环没有阻塞的 syncObjects[2] 先获得令牌阻塞了
lastSemphore.acquire();
System.out.println("thread" + index + ": " + result++);
if (result > maxNum) {
System.exit(0);
}
// 释放当前的信号量,syncObjects[0] 信号量此时为 1,下次 for 循环中上一个信号量即为syncObjects[0]
currentSemphore.release();
}
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
}
}```
使用 LockSupport
--------------
LockSupport 是 JDK 底层的基于 `sun.misc.Unsafe` 来实现的类,用来创建锁和其他同步工具类的基本线程阻塞原语。它的静态方法 `unpark()` 和 `park()` 可以分别实现阻塞当前线程和唤醒指定线程的效果,所以用它解决这样的问题会更容易一些。
(在 AQS 中,就是通过调用 `LockSupport.park( )` 和 `LockSupport.unpark()` 来实现线程的阻塞和唤醒的。)
```null
public class PrintABCUsingLockSupport {
private static Thread threadA, threadB, threadC;
public static void main(String[] args) {
threadA = new Thread(() -> {
for (int i = 0; i < 10; i++) {
// 打印当前线程名称
System.out.print(Thread.currentThread().getName());
// 唤醒下一个线程
LockSupport.unpark(threadB);
// 当前线程阻塞
LockSupport.park();
}
}, "A");
threadB = new Thread(() -> {
for (int i = 0; i < 10; i++) {
// 先阻塞等待被唤醒
LockSupport.park();
System.out.print(Thread.currentThread().getName());
// 唤醒下一个线程
LockSupport.unpark(threadC);
}
}, "B");
threadC = new Thread(() -> {
for (int i = 0; i < 10; i++) {
// 先阻塞等待被唤醒
LockSupport.park();
System.out.print(Thread.currentThread().getName());
// 唤醒下一个线程
LockSupport.unpark(threadA);
}
}, "C");
threadA.start();
threadB.start();
threadC.start();
}
}```
理解了思路,解决其他问题就容易太多了。
比如,我们再解决下第五题:用两个线程,一个输出字母,一个输出数字,交替输出 1A2B3C4D...26Z
```null
public class NumAndLetterPrinter {
private static Thread numThread, letterThread;
public static void main(String[] args) {
letterThread = new Thread(() -> {
for (int i = 0; i < 26; i++) {
System.out.print((char) ('A' + i));
LockSupport.unpark(numThread);
LockSupport.park();
}
}, "letterThread");
numThread = new Thread(() -> {
for (int i = 1; i <= 26; i++) {
System.out.print(i);
LockSupport.park();
LockSupport.unpark(letterThread);
}
}, "numThread");
numThread.start();
letterThread.start();
}
}```
写在最后
----
好了,以上就是常用的五种实现方案,多练习几次,手撕没问题。
当然,这类问题,解决方式不止是我列出的这些,还会有 join、CountDownLatch、也有放在队列里解决的,思路有很多,面试官想考察的其实只是对多线程的编程功底,其实自己练习的时候,是个很好的巩固理解 JUC 的过程。
> 以梦为马,越骑越傻。诗和远方,越走越慌。不忘初心是对的,但切记要出发,加油吧,程序员。
>
> 在路上的你,可以微信搜「 **JavaKeeper** 」一起前行,无套路领取 500+ 本电子书和 30+ 视频教学和源码,本文 **GitHub** [github.com/JavaKeeper](https://github.com/Jstarfish/JavaKeeper) 已经收录,服务端开发、面试必备技能兵器谱,有你想要的。
[https://developer.aliyun.com/article/776793](https://developer.aliyun.com/article/776793)
关键词: WIFI,二维码
前段时间去朋友家做客在连他家 WIFI 这件小事情上遇到了大问题。他家新装的 WIFI 刚过一个星期密码就被他给忘了,更绝望的是路由器的管理密码也不记得了,最后只好重置路由器重新设置 WIFI。
现在生活离不开网络,虽然 4G/5G 网网速足够快,流量也多,但总有网络不好的时候(比如春节回到老家),另一方面流量虽多但它不便宜,用流量看剧、刷抖音长时间下来也吃不消。回家或者去朋友亲戚家能有 WIFI 提供高速网络服务才能美滋滋。
日常使用网络的时候或多或少会遇到我上面遇到的问题。毕竟 WIFI 就是要安安静静地在角落里工作,谁会花心思去管它,而且密码一旦设定后很长一段时间都不会管它,这个时间短则数月,长则数年。经历长时间的遗忘后,突然让我们回想当时设下了什么奇奇怪怪的密码,确是有点难为人了。
那就写下来吧,拿来一张便条,写上 WIFI 密码,贴在冰箱上,方便自己随时查看密码,也方便访客连接 WIFI。商店大概率会选择把密码贴墙上(doge)。
现在有更方便的方法啦,不用手动进入系统设置 -- 选择 WIFI-- 输入密码了,直接打开相机扫码就能快速连接 WI-FI,入网更快、更直观!
扫码快速链接 WI-FI
打开手机相机(注意:不是微信扫一扫)尝试扫码上面的二维码,是不是提示连接名为 “肆不肆傻” 的 WI-FI 了?这只是一个测试说明例子,尝试连接并不能真的连上该 WI-FI,但如果将二维码换成你当前环境能访问的 WIFI 信息,连上 WI-FI 就只在一瞬之间。
其实 Andriod 手机高版本系统中,手动连接 WIFI 后打开 WI-FI 详情页就能看到二维码显示,但这种适合面对面扫码的应用场景,不适合分享。有没有其他方法能够生成 WIFI 二维码呢?
这里提供两个还不错的能在线生成 WIFI 二维码的网站。
WiFi Card
My WiFi Sign
这两个 WIFI 二维码生成网站都提供二维码打印功能。当然我们还可以通过其他方式生成 WIFI 二维码并自己在 PPT 或其他软件中利用二维码制作二维码卡片,见后文。
二维码不过是信息的一种特别呈现方式,比如网站二维码不过是将网站地址用二维码的形式呈现出来。那么 WIFI 二维码包含的是什么信息呢?
微信扫一扫或者其他应用内扫一扫是不支持扫码连 WIFI 的,这超出了他们的权限和功能范围,也正因此我们可以借助他们来一窥 WIFI 二维码的究竟。
打开微信扫一扫,扫描上文二维码,看到了吗?微信直接显示了二维码的明文信息:
WIFI:T:WPA;S:肆不肆傻;P:nodefinitelynot;;
它代表什么意义呢?
说明:
知道了 WIFI 二维码编码的具体内容和格式,动手为自己的 WI-FI 设计一个独特的 WIFI 卡片就是小菜一碟了。
首先我们要为 WIFI 生成二维码,可以使用上文说的两个网站,将生成的二维码图片截图或保存到本地;也可以通过其他的二维码生成网站,(不一定是能给专门生成 WIFI 二维码的)比如[草料二维码生成器](草料二维码生成器)。
使用草料等非专用二维码生成器的时候,将二维码编辑的内容设置成 `WIFI:T:WPA;S: 名称; P: 密码;;` 即可,其中名称替换成你的 WIFI 名称,密码替换成你的 WIFI 密码。这样就能从配置明文生成一种 WIFI 二维码。
有了 WIFI 二维码如何设计自己的 WIFI 卡片就是仁者见仁的事情,这里就不多说了。多一嘴,如果嫌各种设计软件用起来麻烦,PPT 是你的不二选择。
不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言。由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元 —— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解。我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语。这个翻译的过程就是编码。所以可以想象只要不是说英语的国家要能够使用计算机就必须要经过编码。这看起来有些霸道,但是这就是现状,这也和我们国家现在在大力推广汉语一样,希望其它国家都会说汉语,以后其它的语言都翻译成汉语,我们可以把计算机中存储信息的最小单位改成汉字,这样我们就不存在编码问题了。
所以总的来说,编码的原因可以总结为:
计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个
(8 位可能是 0 或者 1,有 2 * 2 * 2 *2 * 2 * 2 * 2 * 2 = 256 种可能)
, 人类要表示的符号太多,无法用一个字节来完全表示。
要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码 。
如何 “翻译”
明白了各种语言需要交流,经过翻译是必要的,那又如何来翻译呢?计算中提拱了多种翻译方式,常见有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 等。它们都可以被看作为字典,它们规定了转化的规则,按照这个规则就可以让计算机正确的表示我们的字符。目前的编码格式很多,例如 GB2312、GBK、UTF-8、UTF-16 这几种格式都可以表示一个汉字,那我们到底选择哪种编码格式来存储汉字呢?这就要考虑到其它因素了,是存储空间重要还是编码的效率重要。根据这些因素来正确选择编码格式,下面简要介绍一下这几种编码格式。
((American Standard Code for Information Interchange): 美国信息交换标准代码)
用一个字节的低 7 位表示,总共有 128 个,031 是控制字符如换行回车删除等;32126 是打印字符,可以通过键盘输入并且能够显示出来。
标准的 ASCII 码用一个字节中的 7 为二进制码来表示一个字符,这个编码的字符就是 ASCII 码值,从 0000000 到 1111111 公有 128 个编码,可用来表示 128 个字符!” “随着计算机的发展和深入,7 位的字符有时已不够用,为此国际标准化组织又制定了 ISO2022 标准,它在保持 ISO646 兼容的基础上,规定了扩充 ASCII 字符集为 8 位代码,可表示 256 个字符
https://blog.csdn.net/ericliutyy/article/details/5657601
可描述任何文字信息,中文需要转码
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符
传递字符信息时造成传输的数据较大
ISO 试图想创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典来相互翻译。可想而知这个字典是多么的复杂,关于 Unicode 的详细规范可以参考相应文档。
Unicode Transformation Format 是一种 UNICODE 的长度可变编码,常见 UTF-8
还有 UTF-8/16/32
实际项目中,往往都以 UTF-8 编码为主,写代码时建议将文件编码统一设置为 UTF-8
1) ANSI 的出现
他们决定用 8 个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到 8 个开关状态是好的,于是他们把这称为” 字节 “。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为” 计算机 “。
开始计算机只在美国用。八位的字节一共可以组合出 256 (2 的 8 次方) 种不同的状态。 他们把其中的编号从 0 开始的 32 种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作:遇上 0×10, 终端就换行;遇上 0×07, 终端就向人们嘟嘟叫;遇上 0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些 0×20 以下的字节状态称为” 控制码”。他们又把所有的空 格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第 127 号
一直编到了第 127 号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉
很好,于是大家都把这个方案叫做 ANSI 的”Ascii” 编码
2) GB2312/GBK
**人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示 6000 多个常用汉字。
汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。
**是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。
3) UNICODE/UTF-8/UTF-16/UTF-32
每个国家都像**一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。
UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8 个位和 16 个位。于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是**人,用 GBK 等编码也可以。
Unicode 是「字符集」
UTF-8 是「编码规则」
字符集:为全世界每一个字符分配一个唯一的 id(学名码位,码点,Code Point)
编码规则:将码位转换为字节序列的规则(编码 / 解码 可以理解为 加密 / 解密 的过程)
| 英文 | 中文 | 备注 | |
|---|---|---|---|
| ASCII | 1 | - | 用一个字节的低 7 位,共 128 个 |
| ISO-8859-1 | 1 | - | 一个字节的 8 位都使用,共 256 个 |
| GB2312 | 1 | 2 | 只表示简体中文,兼容 ASCII |
| GBK | 1 | 2 | 表示简体中文和繁体中文,兼容 GB2312,兼容 ASCII |
| GB18030 | 1 | 2 | 对 GBK 的扩展,表示多个民族语言,兼容 GBK/GB2312/ASCII |
| UTF-8 | 1 | 3 | 可变宽度编码。有 1/2/3/4 种可能。正常英文 1,中文 3 |
| UTF-16 | 4 | 4 | 可变宽度编码。英文,中文占 2 个或 4 个字节,正常情况占 4 个 |
| UTF-32 | 4 | 4 | 固定宽度编码,所有代码点占用四个字节。巨大的内存消耗,但是操作起来很快。 |
最准确方法:
"需要判断字符串".getBytes("编码格式").length单个英文字母:
字节数:2; 编码:UTF-16BE //tbd 不清楚含义
字节数:2; 编码:UTF-16LE
单个中文汉字:
字节数:2; 编码:UTF-16BE
字节数:2; 编码:UTF-16LE
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println("A".getBytes(StandardCharsets.US_ASCII).length+" "+"嗨".getBytes("ASCII").length);
System.out.println("A".getBytes("ISO8859-1").length+" "+"嗨".getBytes("ISO8859-1").length);
System.out.println("A".getBytes("GB2312").length+" "+"嗨".getBytes("GB2312").length);
System.out.println("A".getBytes("GBK").length+" "+"嗨".getBytes("GBK").length);
System.out.println("A".getBytes("GB18030").length+" "+"嗨".getBytes("GB18030").length);
System.out.println("A".getBytes("UTF-8").length+" "+"嗨".getBytes("UTF-8").length);
System.out.println("A".getBytes("UTF-16").length+" "+"嗨".getBytes("UTF-16").length);
System.out.println("A".getBytes("UTF-32").length+" "+"嗨".getBytes("UTF-32").length);
}public class Test {
public static void main(String[] args) {
System.getProperties().list(System.out);
}
}中有 file.encoding=UTF-8
getProperties 返回一个 Properties 对象
getProperties 取得当前系统属性
list 列出
list () 参数,输出到参数代表的流中
参照:
https://www.zhihu.com/question/23374078
https://blog.csdn.net/m0\_37732829/article/details/80774400
https://blog.csdn.net/yuxiangaaaaa/article/details/78060661
https://blog.csdn.net/cuiyaoqiang/article/details/52056175
https://blog.csdn.net/weixin_41838721/article/details/109234392
阅读本文大概需要 19 分钟。
来自:http://juejin.im/post/5e527c58e51d4526c654bf41
先亮出这篇文章的思维导图
TCP 作为传输层的协议,是一个软件工程师素养的体现,也是面试中经常被问到的知识点。在此,我将 TCP 核心的一些问题梳理了一下,希望能帮到各位。
首先概括一下基本的区别:TCP 是一个面向连接的、可靠的、基于字节流的传输层协议。 而 UDP 是一个面向无连接的传输层协议。 (就这么简单,其它 TCP 的特性也就没有了)。具体来分析,和 UDP 相比, TCP 有三大核心特性:
TCP 会精准记录哪些数据发送了,哪些数据被对方接收了,哪些没有被接收到,而且保证数据包按序到达,不允许半点差错。这是 有状态。当意识到丢包了或者网络环境不佳,TCP 会根据具体情况调整自己的行为,控制自己的发送速度或者重发。这是 可控制。相应的,UDP 就是 无状态 , 不可控的。
以谈恋爱为例,两个人能够在一起最重要的事情是首先确认各自 爱和 被爱的能力。接下来我们以此来模拟三次握手的过程。第一次:男: 我爱你。 女方收到。由此证明男方拥有 爱的能力。第二次:女: 我收到了你的爱,我也爱你。 男方收到。OK,现在的情况说明,女方拥有 爱和 被爱的能力。第三次:男: 我收到了你的爱。 女方收到。现在能够保证男方具备 被爱的能力。由此完整地确认了双方 爱和 被爱的能力,两人开始一段甜蜜的爱情。
当然刚刚那段属于扯淡,不代表本人价值观,目的是让大家理解整个握手过程的意义,因为两个过程非常相似。对应到 TCP 的三次握手,也是需要确认双方的两样能力: 发送的能力和 接收的能力。于是便会有下面的三次握手的过程:
从最开始双方都处于 CLOSED 状态。然后服务端开始监听某个端口,进入了 LISTEN 状态。然后客户端主动发起连接,发送 SYN , 自己变成了 SYN-SENT 状态。服务端接收到,返回 SYN 和 ACK(对应客户端发来的 SYN),自己变成了 SYN-REVD。之后客户端再发送 ACK 给服务端,自己变成了 ESTABLISHED 状态;服务端收到 ACK 之后,也变成了 ESTABLISHED 状态。另外需要提醒你注意的是,从图中可以看出,SYN 是需要消耗一个序列号的,下次发送对应的 ACK 序列号要加 1,为什么呢?只需要记住一个规则:
凡是需要对端确认的,一定消耗 TCP 报文的序列号。
SYN 需要对端的确认, 而 ACK 并不需要,因此 SYN 消耗一个序列号而 ACK 不需要。
根本原因:无法确认客户端的接收能力。分析如下:如果是两次,你现在发了 SYN 报文想握手,但是这个包 滞留在了当前的网络中迟迟没有到达,TCP 以为这是丢了包,于是重传,两次握手建立好了连接。看似没有问题,但是连接关闭后,如果这个 滞留在网路中的包到达了服务端呢?这时候由于是两次握手,服务端只要接收到然后发送相应的数据包,就默认 建立连接,但是现在客户端已经断开了。看到问题的吧,这就带来了连接资源的浪费。
三次握手的目的是确认双方 发送和 接收的能力,那四次握手可以嘛?当然可以,100 次都可以。但为了解决问题,三次就足够了,再多用处就不大了。
第三次握手的时候,可以携带。前两次握手不能携带数据。如果前两次握手能够携带数据,那么一旦有人想攻击服务器,那么他只需要在第一次握手中的 SYN 报文中放大量数据,那么服务器势必会消耗更多的 时间和 内存空间去处理这些数据,增大了服务器被攻击的风险。第三次握手的时候,客户端已经处于 ESTABLISHED 状态,并且已经能够确认服务器的接收、发送能力正常,这个时候相对安全了,可以携带数据。
如果双方同时发 SYN 报文,状态变化会是怎样的呢?这是一个可能会发生的情况。状态变迁如下:
在发送方给接收方发 SYN 报文的同时,接收方也给发送方发 SYN 报文,两个人刚上了!发完 SYN,两者的状态都变为 SYN-SENT。在各自收到对方的 SYN 后,两者状态都变为 SYN-REVD。接着会回复对应的 ACK + SYN,这个报文在对方接收之后,两者状态一起变为 ESTABLISHED。这就是同时打开情况下的状态变迁。
刚开始双方处于 ESTABLISHED 状态。客户端要断开了,向服务器发送 FIN 报文,在 TCP 报文中的位置如下图:
发送后客户端变成了 FIN-WAIT-1 状态。注意,这时候客户端同时也变成了 half-close(半关闭) 状态,即无法向服务端发送报文,只能接收。服务端接收后向客户端确认,变成了 CLOSED-WAIT 状态。客户端接收到了服务端的确认,变成了 FIN-WAIT2 状态。
随后,服务端向客户端发送 FIN,自己进入 LAST-ACK 状态,客户端收到服务端发来的 FIN 后,自己变成了 TIME-WAIT 状态,然后发送 ACK 给服务端。注意了,这个时候,客户端需要等待足够长的时间,具体来说,是 2 个 MSL( Maximum Segment Lifetime,报文最大生存时间), 在这段时间内如果客户端没有收到服务端的重发请求,那么表示 ACK 成功到达,挥手结束,否则客户端重发 ACK。
如果不等待会怎样?如果不等待,客户端直接跑路,当服务端还有很多数据包要给客户端发,且还在路上的时候,若客户端的端口此时刚好被新的应用占用,那么就接收到了无用数据包,造成数据包混乱。所以,最保险的做法是等服务器发来的数据包都死翘翘再启动新的应用。那,照这样说一个 MSL 不就不够了吗,为什么要等待 2 MSL?
这就是等待 2MSL 的意义。
因为服务端在接收到 FIN, 往往不会立即返回 FIN, 必须等到服务端所有的报文都发送完毕了,才能发 FIN。因此先发一个 ACK 表示已经收到客户端的 FIN,延迟一段时间才发 FIN。这就造成了四次挥手。
如果是三次挥手会有什么问题?等于说服务端将 ACK 和 FIN 的发送合并为一次挥手,这个时候长时间的延迟可能会导致客户端误以为 FIN 没有到达客户端,从而让客户端不断的重发 FIN。
如果客户端和服务端同时发送 FIN ,状态会如何变化?如图所示:
三次握手前,服务端的状态从 CLOSED 变为 LISTEN, 同时在内部创建了两个队列: 半连接队列和 全连接队列,即 SYN 队列和 ACCEPT 队列。
当客户端发送 SYN 到服务端,服务端收到以后回复 ACK 和 SYN,状态由 LISTEN 变为 SYN_RCVD,此时这个连接就被推入了 SYN 队列,也就是 半连接队列。
当客户端返回 ACK, 服务端接收后,三次握手完成。这个时候连接等待被具体的应用取走,在被取走之前,它会被推入另外一个 TCP 维护的队列,也就是 全连接队列 (Accept Queue)。
SYN Flood 属于典型的 DoS/DDoS 攻击。其攻击的原理很简单,就是用客户端在短时间内伪造大量不存在的 IP 地址,并向服务端疯狂发送 SYN。对于服务端而言,会产生两个危险的后果:
SYN 包并返回对应 ACK, 势必有大量连接处于 SYN_RCVD 状态,从而占满整个半连接队列,无法处理正常的请求。ACK,会导致服务端不断重发数据,直到耗尽服务端的资源。SYN 后不立即分配连接资源,而是根据这个 SYN 计算出一个 Cookie,连同第二次握手回复给客户端,在客户端回复 ACK 的时候带上这个 Cookie 值,服务端验证 Cookie 合法之后才分配连接资源。报文头部结构如下 (单位为字节):
请大家牢记这张图!
如何标识唯一标识一个连接?答案是 TCP 连接的 四元组 —— 源 IP、源端口、目标 IP 和目标端口。那 TCP 报文怎么没有源 IP 和目标 IP 呢?这是因为在 IP 层就已经处理了 IP 。TCP 只需要记录两者的端口即可。
即 Sequence number, 指的是本报文段第一个字节的序列号。从图中可以看出,序列号是一个长为 4 个字节,也就是 32 位的无符号整数,表示范围为 0 ~ 2^32 - 1。如果到达最大值了后就循环到 0。序列号在 TCP 通信的过程中有两个作用:
即 Initial Sequence Number(初始序列号), 在三次握手的过程当中,双方会用过 SYN 报文来交换彼此的 ISN。ISN 并不是一个固定的值,而是每 4 ms 加一,溢出则回到 0,这个算法使得猜测 ISN 变得很困难。那为什么要这么做?如果 ISN 被攻击者预测到,要知道源 IP 和源端口号都是很容易伪造的,当攻击者猜测 ISN 之后,直接伪造一个 RST 后,就可以强制连接关闭的,这是非常危险的。而动态增长的 ISN 大大提高了猜测 ISN 的难度。
即 ACK(Acknowledgment number)。用来告知对方下一个期望接收的序列号, 小于 ACK 的所有字节已经全部收到。
常见的标记位有 SYN, ACK, FIN, RST, PSH。SYN 和 ACK 已经在上文说过,后三个解释如下: FIN:即 Finish,表示发送方准备断开连接。RST:即 Reset,用来强制断开连接。PSH:即 Push, 告知对方这些数据包收到后应该马上交给上层的应用,不能缓存。
占用两个字节,也就是 16 位,但实际上是不够用的。因此 TCP 引入了窗口缩放的选项,作为窗口缩放的比例因子,这个比例因子的范围在 0 ~ 14,比例因子可以将窗口的值扩大为原来的 2 ^ n 次方。
占用两个字节,防止传输过程中数据包有损坏,如果遇到校验和有差错的报文,TCP 直接丢弃之,等待重传。
可选项的格式如下:
常用的可选项有以下几个:
第一节讲了 TCP 三次握手,可能有人会说,每次都三次握手好麻烦呀!能不能优化一点?可以啊。今天来说说这个优化后的 TCP 握手流程,也就是 TCP 快速打开 (TCP Fast Open, 即 TFO) 的原理。优化的过程是这样的,还记得我们说 SYN Flood 攻击时提到的 SYN Cookie 吗?这个 Cookie 可不是浏览器的 Cookie, 用它同样可以实现 TFO。
首先客户端发送 SYN 给服务端,服务端接收到。注意哦!现在服务端不是立刻回复 SYN + ACK,而是通过计算得到一个 SYN Cookie, 将这个 Cookie 放到 TCP 报文的 Fast Open 选项中,然后才给客户端返回。客户端拿到这个 Cookie 的值缓存下来。后面正常完成三次握手。首轮三次握手就是这样的流程。而后面的三次握手就不一样啦!
在后面的三次握手中,客户端会将之前缓存的 Cookie、 SYN 和 HTTP 请求 (是的,你没看错) 发送给服务端,服务端验证了 Cookie 的合法性,如果不合法直接丢弃;如果是合法的,那么就正常返回 SYN + ACK。
重点来了,现在服务端能向客户端发 HTTP 响应了!这是最显著的改变,三次握手还没建立,仅仅验证了 Cookie 的合法性,就可以返回 HTTP 响应了。当然,客户端的 ACK 还得正常传过来,不然怎么叫三次握手嘛。
流程如下:
注意:客户端最后握手的 ACK 不一定要等到服务端的 HTTP 响应到达才发送,两个过程没有任何关系。
TFO 的优势并不在与首轮三次握手,而在于后面的握手,在拿到客户端的 Cookie 并验证通过以后,可以直接返回 HTTP 响应,充分利用了 1 个 RTT(Round-Trip Time,往返时延) 的时间 提前进行数据传输,积累起来还是一个比较大的优势。
timestamp 是 TCP 报文首部的一个可选项,一共占 10 个字节,格式如下:
kind(1 字节) + length(1 字节) + info(8 个字节)
其中 kind = 8, length = 10, info 有两部分构成: timestamp 和 timestamp echo,各占 4 个字节。那么这些字段都是干嘛的呢?它们用来解决那些问题?接下来我们就来一一梳理,TCP 的时间戳主要解决两大问题:
在没有时间戳的时候,计算 RTT 会遇到的问题如下图所示:
如果以第一次发包为开始时间的话,就会出现左图的问题,RTT 明显偏大,开始时间应该采用第二次的;如果以第二次发包为开始时间的话,就会导致右图的问题,RTT 明显偏小,开始时间应该采用第一次发包的。实际上无论开始时间以第一次发包还是第二次发包为准,都是不准确的。那这个时候引入时间戳就很好的解决了这个问题。比如现在 a 向 b 发送一个报文 s1,b 向 a 回复一个含 ACK 的报文 s2 那么:
timestamp 中存放的内容就是 a 主机发送时的内核时刻 ta1。timestamp 中存放的是 b 主机的时刻 tb, timestamp echo 字段为从 s1 报文中解析出来的 ta1。ta1, 也就是 s2 对应的报文最初的发送时刻。然后直接采用 ta2 - ta1 就得到了 RTT 的值。现在我们来模拟一下这个问题。序列号的范围其实是在 0 ~ 2 ^ 32 - 1, 为了方便演示,我们缩小一下这个区间,假设范围是 0 ~ 4,那么到达 4 的时候会回到 0。第几次发包发送字节对应序列号状态。
假设在第 6 次的时候,之前还滞留在网路中的包回来了,那么就有两个序列号为 1 ~ 2 的数据包了,怎么区分谁是谁呢?这个时候就产生了序列号回绕的问题。那么用 timestamp 就能很好地解决这个问题,因为每次发包的时候都是将发包机器当时的内核时间记录在报文中,那么两次发包序列号即使相同,时间戳也不可能相同,这样就能够区分开两个数据包了。
TCP 具有超时重传机制,即间隔一段时间没有等到数据包的回复时,重传这个数据包。那么这个重传间隔是如何来计算的呢?今天我们就来讨论一下这个问题。这个重传间隔也叫做 超时重传时间 (Retransmission TimeOut, 简称 RTO),它的计算跟上一节提到的 RTT 密切相关。这里我们将介绍两种主要的方法,一个是经典方法,一个是标准方法。
经典方法引入了一个新的概念 ——SRTT (Smoothed round trip time,即平滑往返时间),没产生一次新的 RTT. 就根据一定的算法对 SRTT 进行更新,具体而言,计算方式如下 (SRTT 初始值为 0):
SRTT = (α * SRTT) + ((1 - α) * RTT)
其中,α 是 平滑因子,建议值是 0.8,范围是 0.8 ~ 0.9。拿到 SRTT,我们就可以计算 RTO 的值了:
RTO = min(ubound, max(lbound, β * SRTT))
β 是加权因子,一般为 1.3 ~ 2.0, lbound 是下界, ubound 是上界。其实这个算法过程还是很简单的,但是也存在一定的局限,就是在 RTT 稳定的地方表现还可以,而在 RTT 变化较大的地方就不行了,因为平滑因子 α 的范围是 0.8 ~ 0.9, RTT 对于 RTO 的影响太小。
为了解决经典方法对于 RTT 变化不敏感的问题,后面又引出了标准方法,也叫 Jacobson / Karels 算法。一共有三步。第一步: 计算 SRTT,公式如下:
SRTT = (1 - α) * SRTT + α * RTT
注意这个时候的 α 跟经典方法中的 α 取值不一样了,建议值是 1/8,也就是 0.125。第二步: 计算 RTTVAR(round-trip time variation) 这个中间变量。
RTTVAR = (1 - β) * RTTVAR + β * (|RTT - SRTT|)
β 建议值为 0.25。这个值是这个算法中出彩的地方,也就是说,它记录了最新的 RTT 与当前 SRTT 之间的差值,给我们在后续感知到 RTT 的变化提供了抓手。第三步: 计算最终的 RTO:
RTO = µ * SRTT + ∂ * RTTVAR
µ 建议值取 1, ∂建议值取 4。这个公式在 SRTT 的基础上加上了最新 RTT 与它的偏移,从而很好的感知了 RTT 的变化,这种算法下,RTO 与 RTT 变化的差值关系更加密切。
对于发送端和接收端而言,TCP 需要把发送的数据放到 发送缓存区 , 将接收的数据放到 接收缓存区。而流量控制索要做的事情,就是在通过接收缓存区的大小,控制发送端的发送。如果对方的接收缓存区满了,就不能再继续发送了。要具体理解流量控制,首先需要了解 滑动窗口的概念。
TCP 滑动窗口分为两种: 发送窗口和 接收窗口。
发送端的滑动窗口结构如下:
其中包含四大部分:
其中有一些重要的概念,我标注在图中:
发送窗口就是图中被框住的范围。SND 即 send, WND 即 window, UNA 即 unacknowledged, 表示未被确认,NXT 即 next, 表示下一个发送的位置。
接收端的窗口结构如下:
REV 即 receive,NXT 表示下一个接收的位置,WND 表示接收窗口大小。
这里我们不用太复杂的例子,以一个最简单的来回来模拟一下流量控制的过程,方便大家理解。首先双方三次握手,初始化各自的窗口大小,均为 200 个字节。假如当前发送端给接收端发送 100 个字节,那么此时对于发送端而言,SND.NXT 当然要右移 100 个字节,也就是说当前的 可用窗口减少了 100 个字节,这很好理解。
现在这 100 个到达了接收端,被放到接收端的缓冲队列中。不过此时由于大量负载的原因,接收端处理不了这么多字节,只能处理 40 个字节,剩下的 60 个字节被留在了缓冲队列中
。注意了,此时接收端的情况是处理能力不够用啦,你发送端给我少发点,所以此时接收端的接收窗口应该缩小,具体来说,缩小 60 个字节,由 200 个字节变成了 140 字节,因为缓冲队列还有 60 个字节没被应用拿走。因此,接收端会在 ACK 的报文首部带上缩小后的滑动窗口 140 字节,发送端对应地调整发送窗口的大小为 140 个字节。
此时对于发送端而言,已经发送且确认的部分增加 40 字节,也就是 SND.UNA 右移 40 个字节,同时 发送窗口缩小为 140 个字节。这也就是 流量控制的过程。尽管回合再多,整个控制的过程和原理是一样的。
上一节所说的 流量控制发生在发送端跟接收端之间,并没有考虑到整个网络环境的影响,如果说当前网络特别差,特别容易丢包,那么发送端就应该注意一些了。而这,也正是 拥塞控制需要处理的问题。对于拥塞控制来说,TCP 每条连接都需要维护两个核心状态:
涉及到的算法有这几个:
接下来,我们就来一一拆解这些状态和算法。首先,从拥塞窗口说起。
拥塞窗口(Congestion Window,cwnd)是指目前自己还能传输的数据量大小。那么之前介绍了接收窗口的概念,两者有什么区别呢?
接收端给的限制发送端的限制限制谁呢?限制的是 发送窗口的大小。有了这两个窗口,如何来计算 发送窗口?
取两者的较小值。而拥塞控制,就是来控制 cwnd 的变化。
刚开始进入传输数据的时候,你是不知道现在的网路到底是稳定还是拥堵的,如果做的太激进,发包太急,那么疯狂丢包,造成雪崩式的网络灾难。因此,拥塞控制首先就是要采用一种保守的算法来慢慢地适应整个网路,这种算法叫 慢启动。运作过程如下:
难道就这么无止境地翻倍下去?当然不可能。它的阈值叫做 慢启动阈值,当 cwnd 到达这个阈值之后,好比踩了下刹车,别涨了那么快了,老铁,先 hold 住!在到达阈值后,如何来控制 cwnd 的大小呢?这就是拥塞避免做的事情了。
原来每收到一个 ACK,cwnd 加 1,现在到达阈值了,cwnd 只能加这么一点: 1 / cwnd。那你仔细算算,一轮 RTT 下来,收到 cwnd 个 ACK, 那最后拥塞窗口的大小 cwnd 总共才增加 1。也就是说,以前一个 RTT 下来, cwnd 翻倍,现在 cwnd 只是增加 1 而已。当然, 慢启动和 拥塞避免是一起作用的,是一体的。
在 TCP 传输的过程中,如果发生了丢包,即接收端发现数据段不是按序到达的时候,接收端的处理是重复发送之前的 ACK。比如第 5 个包丢了,即使第 6、7 个包到达的接收端,接收端也一律返回第 4 个包的 ACK。
当发送端收到 3 个重复的 ACK 时,意识到丢包了,于是马上进行重传,不用等到一个 RTO 的时间到了才重传。这就是 快速重传,它解决的是 是否需要重传的问题。
那你可能会问了,既然要重传,那么只重传第 5 个包还是第 5、6、7 个包都重传呢?当然第 6、7 个都已经到达了,TCP 的设计者也不傻,已经传过去干嘛还要传?干脆记录一下哪些包到了,哪些没到,针对性地重传。
在收到发送端的报文后,接收端回复一个 ACK 报文,那么在这个报文首部的可选项中,就可以加上 SACK 这个属性,通过 left edge 和 right edge 告知发送端已经收到了哪些区间的数据报。因此,即使第 5 个包丢包了,当收到第 6、7 个包之后,接收端依然会告诉发送端,这两个包到了。
剩下第 5 个包没到,就重传这个包。这个过程也叫做 选择性重传 (SACK,Selective Acknowledgment),它解决的是 如何重传的问题。
当然,发送端收到三次重复 ACK 之后,发现丢包,觉得现在的网络已经有些拥塞了,自己会进入 快速恢复阶段。在这个阶段,发送端如下改变:
以上就是 TCP 拥塞控制的经典算法: 慢启动、 拥塞避免、 快速重传和快速恢复。
试想一个场景,发送端不停地给接收端发很小的包,一次只发 1 个字节,那么发 1 千个字节需要发 1000 次。这种频繁的发送是存在问题的,不光是传输的时延消耗,发送和确认本身也是需要耗时的,频繁的发送接收带来了巨大的时延。而避免小包的频繁发送,这就是 Nagle 算法要做的事情。具体来说,Nagle 算法的规则如下:
当第一次发送数据时不用等待,就算是 1byte 的小包也立即发送
后面发送满足下面条件之一就可以发了:
数据包大小达到最大段大小 (Max Segment Size, 即 MSS)
之前所有包的 ACK 都已接收到
试想这样一个场景,当我收到了发送端的一个包,然后在极短的时间内又接收到了第二个包,那我是一个个地回复,还是稍微等一下,把两个包的 ACK 合并后一起回复呢?延迟确认 (delayed ack) 所做的事情,就是后者,稍稍延迟,然后合并 ACK,最后才回复给发送端。TCP 要求这个延迟的时延必须小于 500ms,一般操作系统实现都不会超过 200ms。不过需要主要的是,有一些场景是不能延迟确认的,收到了就要马上回复:
tcp_in_quickack_mode 设置)前者意味着延迟发,后者意味着延迟接收,会造成更大的延迟,产生性能问题。
大家都听说过 http 的 keep-alive, 不过 TCP 层面也是有 keep-alive 机制,而且跟应用层不太一样。试想一个场景,当有一方因为网络故障或者宕机导致连接失效,由于 TCP 并不是一个轮询的协议,在下一个数据包到达之前,对端对连接失效的情况是一无所知的。这个时候就出现了 keep-alive, 它的作用就是探测对端的连接有没有失效。在 Linux 下,可以这样查看相关的配置:
sudo sysctl -a | grep keepalive
// 每隔 7200 s 检测一次
net.ipv4.tcp_keepalive_time = 7200
// 一次最多重传 9 个包
net.ipv4.tcp_keepalive_probes = 9
// 每个包的间隔重传间隔 75 s
net.ipv4.tcp_keepalive_intvl = 75
不过,现状是大部分的应用并没有默认开启 TCP 的 keep-alive 选项,为什么?站在应用的角度:
因此是一个比较尴尬的设计。
https://zhuanlan.zhihu.com/p/266505297
来源:微信公众号【编程新说】
曾经的 VIP 服务 在网络的初期,网民很少,服务器完全无压力,那时的技术也没有现在先进,通常用一个线程来全程跟踪处理一个请求。因为这样最简单。 其实代码实现大家都知道,就是服务器上有个 ServerSocket 在某个端口监听,接收到客户端的连接后,会创建一个 Socket,并把它交给一个线程进行后续处理。 线程主要从 Socket 读取客户端传过来的数据,然后进行业务处理,并把结果再写入 Socket 传回客户端。 由于网络的原因,Socket 创建后并不一定能立刻从它上面读取数据,可能需要等一段时间,此时线程也必须一直阻塞着。在向 Socket 写入数据时,也可能会使线程阻塞。 这里准备了一个示例,主要逻辑如下: 客户端:创建 20 个 Socket 并连接到服务器上,再创建 20 个线程,每个线程负责一个 Socket。 服务器端:接收到这 20 个连接,创建 20 个 Socket,接着创建 20 个线程,每个线程负责一个 Socket。 为了模拟服务器端的 Socket 在创建后不能立马读取数据,让客户端的 20 个线程分别休眠 5-10 之间的一个随机秒数。 客户端的 20 个线程会在第 5 秒到第 10 秒这段时间内陆陆续续的向服务器端发送数据,服务器端的 20 个线程也会陆陆续续接收到数据。
public class BioServer {
static AtomicInteger counter \= new AtomicInteger(0); static SimpleDateFormat sdf \= new SimpleDateFormat("HH:mm:ss"); public static void main(String\[\] args) { try { ServerSocket ss \= new ServerSocket(); ss.bind(new InetSocketAddress("localhost", 8080)); while (true) { Socket s \= ss.accept(); processWithNewThread(s); } } catch (Exception e) { e.printStackTrace(); } } static void processWithNewThread(Socket s) { Runnable run \= () \-\> { InetSocketAddress rsa \= (InetSocketAddress)s.getRemoteSocketAddress(); System.out.println(time() + "->" + rsa.getHostName() + ":" + rsa.getPort() + "->" + Thread.currentThread().getId() + ":" + counter.incrementAndGet()); try { String result \= readBytes(s.getInputStream()); System.out.println(time() + "->" + result + "->" + Thread.currentThread().getId() + ":" + counter.getAndDecrement()); s.close(); } catch (Exception e) { e.printStackTrace(); } }; new Thread(run).start(); } static String readBytes(InputStream is) throws Exception { long start \= 0; int total \= 0; int count \= 0; byte\[\] bytes \= new byte\[1024\];
static String time() { return sdf.format(new Date()); }}
public class Client {
public static void main(String\[\] args) { try { for (int i \= 0; i < 20; i++) { Socket s \= new Socket(); s.connect(new InetSocketAddress("localhost", 8080)); processWithNewThread(s, i); } } catch (IOException e) { e.printStackTrace(); } }
static void processWithNewThread(Socket s, int i) { Runnable run \= () \-\> { try {
执行结果如下:
时间\-\>IP:Port\-\>线程Id:当前线程数15:11:52\-\>127.0.0.1:55201\-\>10:115:11:52\-\>127.0.0.1:55203\-\>12:215:11:52\-\>127.0.0.1:55204\-\>13:315:11:52\-\>127.0.0.1:55207\-\>16:415:11:52\-\>127.0.0.1:55208\-\>17:515:11:52\-\>127.0.0.1:55202\-\>11:615:11:52\-\>127.0.0.1:55205\-\>14:715:11:52\-\>127.0.0.1:55206\-\>15:815:11:52\-\>127.0.0.1:55209\-\>18:915:11:52\-\>127.0.0.1:55210\-\>19:1015:11:52\-\>127.0.0.1:55213\-\>22:1115:11:52\-\>127.0.0.1:55214\-\>23:1215:11:52\-\>127.0.0.1:55217\-\>26:1315:11:52\-\>127.0.0.1:55211\-\>20:1415:11:52\-\>127.0.0.1:55218\-\>27:1515:11:52\-\>127.0.0.1:55212\-\>21:1615:11:52\-\>127.0.0.1:55215\-\>24:1715:11:52\-\>127.0.0.1:55216\-\>25:1815:11:52\-\>127.0.0.1:55219\-\>28:1915:11:52\-\>127.0.0.1:55220\-\>29:20
时间\-\>等待数据的时间,读取数据的时间,总共读取的字节数\-\>线程Id:当前线程数15:11:58\-\>wait\=5012ms,read\=1022ms,total\=1048576bs\-\>17:2015:11:58\-\>wait\=5021ms,read\=1022ms,total\=1048576bs\-\>13:1915:11:58\-\>wait\=5034ms,read\=1008ms,total\=1048576bs\-\>11:1815:11:58\-\>wait\=5046ms,read\=1003ms,total\=1048576bs\-\>12:1715:11:58\-\>wait\=5038ms,read\=1005ms,total\=1048576bs\-\>23:1615:11:58\-\>wait\=5037ms,read\=1010ms,total\=1048576bs\-\>22:1515:11:59\-\>wait\=6001ms,read\=1017ms,total\=1048576bs\-\>15:1415:11:59\-\>wait\=6016ms,read\=1013ms,total\=1048576bs\-\>27:1315:11:59\-\>wait\=6011ms,read\=1018ms,total\=1048576bs\-\>24:1215:12:00\-\>wait\=7005ms,read\=1008ms,total\=1048576bs\-\>20:1115:12:00\-\>wait\=6999ms,read\=1020ms,total\=1048576bs\-\>14:1015:12:00\-\>wait\=7019ms,read\=1007ms,total\=1048576bs\-\>26:915:12:00\-\>wait\=7012ms,read\=1015ms,total\=1048576bs\-\>21:815:12:00\-\>wait\=7023ms,read\=1008ms,total\=1048576bs\-\>25:715:12:01\-\>wait\=7999ms,read\=1011ms,total\=1048576bs\-\>18:615:12:02\-\>wait\=9026ms,read\=1014ms,total\=1048576bs\-\>10:515:12:02\-\>wait\=9005ms,read\=1031ms,total\=1048576bs\-\>19:415:12:03\-\>wait\=10007ms,read\=1011ms,total\=1048576bs\-\>16:315:12:03\-\>wait\=10006ms,read\=1017ms,total\=1048576bs\-\>29:215:12:03\-\>wait\=10010ms,read\=1022ms,total\=1048576bs\-\>28:1
可以看到服务器端确实为每个连接创建一个线程,共创建了 20 个线程。 客户端进入休眠约 5-10 秒,模拟连接上数据不就绪,服务器端线程在等待,等待时间约 5-10 秒。 客户端陆续结束休眠,往连接上写入 1M 数据,服务器端开始读取数据,整个读取过程约 1 秒。 可以看到,服务器端的工作线程会把时间花在 “等待数据” 和 “读取数据” 这两个过程上。 这有两个不好的地方: 一是有很多客户端同时发起请求的话,服务器端要创建很多的线程,可能会因为超过了上限而造成崩溃。 二是每个线程的大部分时光中都是在阻塞着,无事可干,造成极大的资源浪费。 开头已经说了那个年代网民很少,所以,不可能会有大量请求同时过来。至于资源浪费就浪费吧,反正闲着也是闲着。 来个简单的小例子: 饭店共有 10 张桌子,且配备了 10 位服务员。只要有客人来了,大堂经理就把客人带到一张桌子,并安排一位服务员全程陪同。 即使客人暂时不需要服务,服务员也一直在旁边站着。可能觉着是一种浪费,其实非也,这就是尊贵的 VIP 服务。 其实,VIP 映射的是一对一的模型,主要体现在 “专用” 上或 “私有” 上。
真正的多路复用技术 多路复用技术原本指的是,在通信方面,多种信号或数据(从宏观上看)交织在一起,使用同一条传输通道进行传输。 这样做的目的,一方面可以充分利用通道的传输能力,另一方面自然是省时省力省钱啦。 其实这个概念非常的 “生活化”,随手就可以举个例子: 一条小水渠里水在流,在一端往里倒入大量乒乓球,在另一端用网进行过滤,把乒乓球和水流分开。 这就是一个比较 “土” 的多路复用,首先在发射端把多种信号或数据进行 “混合”,接着是在通道上进行传输,最后在接收端 “分离” 出自己需要的信号或数据。 相信大家都看出来了,这里的重点其实就是处理好 “混合” 和 “分离”,对于不同的信号或数据,有不同的处理方法。 比如以前的有线电视是模拟信号,即电磁波。一家一般只有一根信号线,但可以同时接多个电视,每个电视任意换台,互不影响。 这是由于不同频率的波可以混合和分离。(当然,可能不是十分准确,明白意思就行了。) 再比如城市的高铁站一般都有数个站台供高铁(同时)停靠,但城市间的高铁轨道单方向只有一条,如何保证那么多趟高铁安全运行呢? 很明显是分时使用,每趟高铁都有自己的时刻。多趟高铁按不同的时刻出站相当于混合,按不同的时刻进站相当于分离。 总结一下,多路指的是多种不同的信号或数据或其它事物,复用指的是共用同一个物理链路或通道或载体。 可见,多路复用技术是一种一对多的模型,“多” 的这一方复用了 “一” 的这一方。
其实,一对多的模型主要体现在 “公用” 上或 “共享” 上。
您先看着,我一会再过来 一对一服务是典型的有钱任性,虽然响应及时、服务周到,但不是每个人都能享受的,毕竟还是 “屌丝” 多嘛,那就来个共享服务吧。 所以实际当中更多的情况是,客人坐下后,会给他一个菜单,让他先看着,反正也不可能立马点餐,服务员就去忙别的了。 可能不时的会有服务员从客人身旁经过,发现客人还没有点餐,就会主动去询问现在需要点餐吗? 如果需要,服务员就给你写菜单,如果不需要,服务员就继续往前走了。 这种情况饭店整体运行的也很好,但是服务员人数少多了。现在服务 10 桌客人,4 个服务员绰绰有余。(这节省的可都是纯利润呀。) 因为 10 桌客人同时需要服务的情况几乎是不会发生的,绝大部分情况都是错开的。如果真有的话,那就等会好了,又不是 120/119,人命关天的。 回到代码里,情况与之非常相似,完全可以采用相同的理论去处理。 连接建立后,找个地方把它放到那里,可以暂时先不管它,反正此时也没有数据可读。 但是数据早晚会到来的,所以,要不时的去询问每个连接有数据没有,有的话就读取数据,没有的话就继续不管它。 其实这个模式在 Java 里早就有了,就是 Java NIO,这里的大写字母 “N” 是单词 “New”,即 “新” 的意思,主要是为了和上面的 “一对一” 进行区分。 先铺垫一下吧 现在需要把 Socket 交互的过程再稍微细化一些。客户端先请求连接,connect,服务器端然后接受连接,accept,然后客户端再向连接写入数据,write,接着服务器端从连接上读出数据,read。 和打电话的场景一样,主叫拨号,connect,被叫接听,accept,主叫说话,speak,被叫聆听,listen。主叫给被叫打电话,说明主叫找被叫有事,所以被叫关注的是接通电话,听对方说。 客户端主动向服务器端发起请求,说明客户端找服务器端有事,所以服务器端关注的是接受请求,读取对方传来的数据。这里把接受请求,读取数据称为服务器端感兴趣的操作。 在 Java NIO 中,接受请求的操作,用 OP_ACCEPT 表示,读取数据的操作,用 OP_READ 表示。 我决定先过一遍饭店的场景,让首次接触 Java NIO 的同学不那么迷茫。就是把常规的场景进行了定向整理,稍微有点刻意,明白意思就行了。 1、专门设立一个 “跑腿” 服务员,工作职责单一,就是问问客人是否需要服务。 2、站在门口接待客人,本来是大堂经理的工作,但是他不愿意在门口盯着,于是就委托给跑腿服务员,你帮我盯着,有人来了告诉我。 于是跑腿服务员就有了一个任务,替大堂经理盯梢。终于来客人了,跑腿服务员赶紧告诉了大堂经理。 3、大堂经理把客人带到座位上,对跑腿服务员说,客人接下来肯定是要点餐的,但是现在在看菜单,不知道什么时候能看好,所以你不时的过来问问,看需不需要点餐,需要的话就再喊来一个 “点餐” 服务员给客人写菜单。 _于是跑腿服务员就又多了一个任务,就是盯着这桌客人,不时来问问,如果需要服务的话,就叫点餐服务员过来服务。_ 4、跑腿服务员在某次询问中,客人终于决定点餐了,跑题服务员赶紧找来一个点餐服务员为客人写菜单。 5、就这样,跑腿服务员既要盯着门外新过来的客人,也要盯着门内已经就坐的客人。新客人来了,通知大堂经理去接待。就坐的客人决定点餐了,通知点餐服务员去写菜单。 事情就这样一直循环的持续下去,一切,都挺好。角色明确,职责单一,配合很好。 大堂经理和点餐服务员是需求的提供者或实现者,跑腿服务员是需求的发现者,并识别出需求的种类,需要接待的交给大堂经理,需要点餐的交给点餐服务员。
哈哈,Java NIO 来啦
代码的写法非常的固定,可以配合着后面的解说来看,这样就好理解了,如下:
public class NioServer {
static int clientCount \= 0; static AtomicInteger counter \= new AtomicInteger(0); static SimpleDateFormat sdf \= new SimpleDateFormat("HH:mm:ss"); public static void main(String\[\] args) { try { Selector selector \= Selector.open(); ServerSocketChannel ssc \= ServerSocketChannel.open(); ssc.configureBlocking(false); ssc.register(selector, SelectionKey.OP\_ACCEPT); ssc.bind(new InetSocketAddress("localhost", 8080)); while (true) { selector.select(); Set<SelectionKey\> keys \= selector.selectedKeys(); Iterator<SelectionKey\> iterator \= keys.iterator(); while (iterator.hasNext()) { SelectionKey key \= iterator.next(); iterator.remove(); if (key.isAcceptable()) { ServerSocketChannel ssc1 \= (ServerSocketChannel)key.channel(); SocketChannel sc \= null; while ((sc \= ssc1.accept()) != null) { sc.configureBlocking(false); sc.register(selector, SelectionKey.OP\_READ); InetSocketAddress rsa \= (InetSocketAddress)sc.socket().getRemoteSocketAddress(); System.out.println(time() + "->" + rsa.getHostName() + ":" + rsa.getPort() + "->" + Thread.currentThread().getId() + ":" + (++clientCount)); } } else if (key.isReadable()) {
static void processWithNewThread(SocketChannel sc, SelectionKey key) { Runnable run \= () \-\> { counter.incrementAndGet(); try { String result \= readBytes(sc);
它的大致处理过程如下: 1、定义一个选择器,Selector。 相当于设立一个跑腿服务员。 2、定义一个服务器端套接字通道,ServerSocketChannel,并配置为非阻塞的。 相等于聘请了一位大堂经理。 3、将套接字通道注册到选择器上,并把感兴趣的操作设置为 OP_ACCEPT。 相当于大堂经理给跑腿服务员说,帮我盯着门外,有客人来了告诉我。 4、进入死循环,选择器不时的进行选择。 相当于跑腿服务员一遍又一遍的去询问、去转悠。 5、选择器终于选择出了通道,发现通道是需要 Acceptable 的。 相当于跑腿服务员终于发现门外来客人了,客人是需要接待的。 6、于是服务器端套接字接受了这个通道,开始处理。 相当于跑腿服务员把大堂经理叫来了,大堂经理开始着手接待。 7、把新接受的通道配置为非阻塞的,并把它也注册到了选择器上,该通道感兴趣的操作为 OP_READ。 相当于大堂经理把客人带到座位上,给了客人菜单,并又把客人委托给跑腿服务员,说客人接下来肯定是要点餐的,你不时的来问问。 8、选择器继续不时的进行选择着。 相当于跑腿服务员继续不时的询问着、转悠着。 9、选择器终于又选择出了通道,这次发现通道是需要 Readable 的。 相当于跑腿服务员终于发现了一桌客人有了需求,是需要点餐的。 10、把这个通道交给了一个新的工作线程去处理。 相当于跑腿服务员叫来了点餐服务员,点餐服务员开始为客人写菜单。 11、这个工作线程处理完后,就被回收了,可以再去处理其它通道。 相当于点餐服务员写好菜单后,就走了,可以再去为其他客人写菜单。 12、选择器继续着重复的选择工作,不知道什么时候是个头。 _相当于跑腿服务员继续着重复的询问、转悠,不知道未来在何方_。
相信你已经看出来了,大堂经理相当于服务器端套接字,跑腿服务员相当于选择器,点餐服务员相当于 Worker 线程。 启动服务器端代码,使用同一个客户端代码,按相同的套路发 20 个请求,结果如下:
时间\-\>IP:Port\-\>主线程Id:当前连接数16:34:39\-\>127.0.0.1:56105\-\>1:116:34:39\-\>127.0.0.1:56106\-\>1:216:34:39\-\>127.0.0.1:56107\-\>1:316:34:39\-\>127.0.0.1:56108\-\>1:416:34:39\-\>127.0.0.1:56109\-\>1:516:34:39\-\>127.0.0.1:56110\-\>1:616:34:39\-\>127.0.0.1:56111\-\>1:716:34:39\-\>127.0.0.1:56112\-\>1:816:34:39\-\>127.0.0.1:56113\-\>1:916:34:39\-\>127.0.0.1:56114\-\>1:1016:34:39\-\>127.0.0.1:56115\-\>1:1116:34:39\-\>127.0.0.1:56116\-\>1:1216:34:39\-\>127.0.0.1:56117\-\>1:1316:34:39\-\>127.0.0.1:56118\-\>1:1416:34:39\-\>127.0.0.1:56119\-\>1:1516:34:39\-\>127.0.0.1:56120\-\>1:1616:34:39\-\>127.0.0.1:56121\-\>1:1716:34:39\-\>127.0.0.1:56122\-\>1:1816:34:39\-\>127.0.0.1:56123\-\>1:1916:34:39\-\>127.0.0.1:56124\-\>1:20
时间\-\>等待数据的时间,读取数据的时间,总共读取的字节数\-\>线程Id:当前线程数16:34:45\-\>wait\=1ms,read\=1018ms,total\=1048576bs\-\>11:516:34:45\-\>wait\=0ms,read\=1054ms,total\=1048576bs\-\>10:516:34:45\-\>wait\=0ms,read\=1072ms,total\=1048576bs\-\>13:616:34:45\-\>wait\=0ms,read\=1061ms,total\=1048576bs\-\>14:516:34:45\-\>wait\=0ms,read\=1140ms,total\=1048576bs\-\>12:416:34:46\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>15:516:34:46\-\>wait\=0ms,read\=1062ms,total\=1048576bs\-\>17:616:34:46\-\>wait\=0ms,read\=1059ms,total\=1048576bs\-\>16:516:34:47\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>19:416:34:47\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>20:416:34:47\-\>wait\=0ms,read\=1015ms,total\=1048576bs\-\>18:316:34:47\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>21:216:34:48\-\>wait\=0ms,read\=1032ms,total\=1048576bs\-\>22:416:34:49\-\>wait\=0ms,read\=1002ms,total\=1048576bs\-\>23:316:34:49\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>25:216:34:49\-\>wait\=0ms,read\=1028ms,total\=1048576bs\-\>24:416:34:50\-\>wait\=0ms,read\=1008ms,total\=1048576bs\-\>28:416:34:50\-\>wait\=0ms,read\=1033ms,total\=1048576bs\-\>27:316:34:50\-\>wait\=1ms,read\=1002ms,total\=1048576bs\-\>29:216:34:50\-\>wait\=0ms,read\=1001ms,total\=1048576bs\-\>26:2
服务器端接受 20 个连接,创建 20 个通道,并把它们注册到选择器上,此时不需要额外线程。 当某个通道已经有数据时,才会用一个线程来处理它,所以,线程 “等待数据” 的时间是 0,“读取数据” 的时间还是约 1 秒。 因为 20 个通道是陆陆续续有数据的,所以服务器端最多时是 6 个线程在同时运行的,换句话说,用包含 6 个线程的线程池就可以了。 对比与结论: 处理同样的 20 个请求,一个需要用 20 个线程,一个需要用 6 个线程,节省了 70% 线程数。 在本例中,两种感兴趣的操作共用一个选择器,且选择器运行在主线程里,Worker 线程是新的线程。 其实对于选择器的个数、选择器运行在哪个线程里、是否使用新的线程来处理请求都没有要求,要根据实际情况来定。 比如说 redis,和处理请求相关的就一个线程,选择器运行在里面,处理请求的程序也运行在里面,所以这个线程既是 I/O 线程,也是 Worker 线程。 当然,也可以使用两个选择器,一个处理 OP_ACCEPT,一个处理 OP_READ,让它们分别运行在两个单独的 I/O 线程里。对于能快速完成的操作可以直接在 I/O 线程里做了,对于非常耗时的操作一定要使用 Worker 线程池来处理。
这种处理模式就是被称为的多路复用 I/O,多路指的是多个 Socket 通道,复用指的是只用一个线程来管理它们。
再稍微分析一下 一对一的形式,一个桌子配一个服务员,一个 Socket 分配一个线程,响应速度最快,毕竟是 VIP 嘛,但是效率很低,服务员大部分时间都是在站着,线程大部分时间都是在等待。 多路复用的形式,所有桌子共用一个跑腿服务员,所有 Socket 共用一个选择器线程,响应速度肯定变慢了,毕竟是一对多嘛。但是效率提高了,点餐服务员在需要点餐时才会过去,工作线程在数据就绪时才会开始工作。 从 VIP 到多路复用,形式上确实有很大的不同,其本质是从一对一到一对多的转变,其实就是牺牲了响应速度,换来了效率的提升,不过综合性能还是得到了极大的改进。
就饭店而言,究竟几张桌子配一个跑腿服务员,几张桌子配一个点餐服务员,经过一段时间运行,一定会有一个最优解。 就程序而言,究竟需要几个选择器线程,几个工作线程,经过评估测试后,也会有一个最优解。 一旦达到最优解后,就不可能再提升了,这同样是由多路复用这种一对多的形式所限制的。就像一对一的形式限制一样。 人们的追求是无止境的,如何对多路复用继续提升呢?答案一定是具有颠覆性的,即抛弃多路复用,采用全新的形式。 还以饭店为例,如何在最优解的情况下,既要继续减少服务员数量,还要使效率提升呢?可能有些朋友已经猜到了,那就是抛弃服务员服务客人这种模式,把饭店改成自助餐厅。 在客人进门时,把餐具给他,并告诉他就餐时长、不准浪费等这些规则,然后就不用管了。客人自己选餐,自己吃完,自己走人,不用再等服务员了,因此也不再需要服务员了。(收拾桌子的除外。) 这种模式对应到程序里,其实就是 AIO,在 Java 里也早就有了。 嘻嘻,Java AIO 来啦
代码的写法非常的固定,可以配合着后面的解说来看,这样就好理解了,如下:
public class AioServer {
static int clientCount \= 0; static AtomicInteger counter \= new AtomicInteger(0); static SimpleDateFormat sdf \= new SimpleDateFormat("HH:mm:ss"); public static void main(String\[\] args) { try { AsynchronousServerSocketChannel assc \= AsynchronousServerSocketChannel.open(); assc.bind(new InetSocketAddress("localhost", 8080));
@Override public void completed(AsynchronousSocketChannel asc, Object attachment) {
@Override public void failed(Throwable exc, Object attachment) { } });
static void readFromChannelAsync(AsynchronousSocketChannel asc) { @Override public void completed(Integer count, Object attachment) { counter.incrementAndGet(); if (count \> \-1) { total += count; } int size \= bb.position(); System.out.println(time() + "->count=" + count + ",total=" + total + "bs,buffer=" + size + "bs->" + Thread.currentThread().getId() + ":" + counter.get()); if (count \> \-1) {
@Override public void failed(Throwable exc, Object attachment) { } }); long end \= System.currentTimeMillis(); System.out.println(time() + "->exe read req,use=" + (end \-begin) + "ms" + "->" + Thread.currentThread().getId()); } static String time() { return sdf.format(new Date()); }}
它的大致处理过程如下: 1、初始化一个 AsynchronousServerSocketChannel 对象,并开始监听 2、通过 accept 方法注册一个 “完成处理器” 的接受连接回调,即 CompletionHandler,用于在接受到连接后的相关操作。 3、当客户端连接过来后,由系统来接受,并创建好 AsynchronousSocketChannel 对象,然后触发该回调,并把该对象传进该回调,该回调会在 Worker 线程中执行。 4、在接受连接回调里,再次使用 accept 方法注册一次相同的完成处理器对象,用于让系统接受下一个连接。就是这种注册只能使用一次,所以要不停的连续注册,人家就是这样设计的。 5、在接受连接回调里,使用 AsynchronousSocketChannel 对象的 read 方法注册另一个接受数据回调,用于在接受到数据后的相关操作。 6、当客户端数据过来后,由系统接受,并放入指定好的 ByteBuffer 中,然后触发该回调,并把本次接受到的数据字节数传入该回调,该回调会在 Worker 线程中执行。 7、在接受数据回调里,如果数据没有接受完,需要再次使用 read 方法把同一个对象注册一次,用于让系统接受下一次数据。这和上面的套路是一样的。 8、客户端的数据可能是分多次传到服务器端的,所以接受数据回调会被执行多次,直到数据接受完为止。多次接受到的数据合起来才是完整的数据,这个一定要处理好。 9、关于 ByteBuffer,要么足够的大,能够装得下完整的客户端数据,这样多次接受的数据直接往里追加即可。要么每次把 ByteBuffer 中的数据移到别的地方存储起来,然后清空 ByteBuffer,用于让系统往里装入下一次接受的数据。
注:如果出现 ByteBuffer 空间不足,则系统不会装入数据,就会导致客户端数据总是读不完,极有可能进入死循环。 启动服务器端代码,使用同一个客户端代码,按相同的套路发 20 个请求,结果如下:
时间\-\>IP:Port\-\>回调线程Id:当前连接数17:20:47\-\>127.0.0.1:56454\-\>15:1时间\-\>发起一个读请求,耗时\-\>回调线程Id17:20:47\-\>exe read req,use\=3ms\-\>1517:20:47\-\>127.0.0.1:56455\-\>15:217:20:47\-\>exe read req,use\=1ms\-\>1517:20:47\-\>127.0.0.1:56456\-\>15:317:20:47\-\>exe read req,use\=0ms\-\>1517:20:47\-\>127.0.0.1:56457\-\>16:417:20:47\-\>127.0.0.1:56458\-\>15:517:20:47\-\>exe read req,use\=1ms\-\>1617:20:47\-\>exe read req,use\=1ms\-\>1517:20:47\-\>127.0.0.1:56460\-\>15:617:20:47\-\>127.0.0.1:56459\-\>17:717:20:47\-\>exe read req,use\=0ms\-\>1517:20:47\-\>127.0.0.1:56462\-\>15:817:20:47\-\>127.0.0.1:56461\-\>16:917:20:47\-\>exe read req,use\=1ms\-\>1517:20:47\-\>exe read req,use\=0ms\-\>1617:20:47\-\>exe read req,use\=0ms\-\>1717:20:47\-\>127.0.0.1:56465\-\>16:1017:20:47\-\>127.0.0.1:56463\-\>18:1117:20:47\-\>exe read req,use\=0ms\-\>1817:20:47\-\>127.0.0.1:56466\-\>15:1217:20:47\-\>exe read req,use\=1ms\-\>1617:20:47\-\>127.0.0.1:56464\-\>17:1317:20:47\-\>exe read req,use\=1ms\-\>1517:20:47\-\>127.0.0.1:56467\-\>18:1417:20:47\-\>exe read req,use\=2ms\-\>1717:20:47\-\>exe read req,use\=1ms\-\>1817:20:47\-\>127.0.0.1:56468\-\>15:1517:20:47\-\>exe read req,use\=1ms\-\>1517:20:47\-\>127.0.0.1:56469\-\>16:1617:20:47\-\>127.0.0.1:56470\-\>18:1717:20:47\-\>exe read req,use\=1ms\-\>1817:20:47\-\>exe read req,use\=1ms\-\>1617:20:47\-\>127.0.0.1:56472\-\>15:1817:20:47\-\>127.0.0.1:56473\-\>19:1917:20:47\-\>exe read req,use\=2ms\-\>1517:20:47\-\>127.0.0.1:56471\-\>17:2017:20:47\-\>exe read req,use\=1ms\-\>1917:20:47\-\>exe read req,use\=1ms\-\>17
时间\-\>本次接受到的字节数,截至到目前接受到的字节总数,buffer中的字节总数\-\>回调线程Id:当前线程数17:20:52\-\>count\=65536,total\=65536bs,buffer\=65536bs\-\>14:117:20:52\-\>count\=65536,total\=65536bs,buffer\=65536bs\-\>14:117:20:52\-\>count\=65536,total\=65536bs,buffer\=65536bs\-\>14:117:20:52\-\>count\=230188,total\=295724bs,buffer\=295724bs\-\>12:117:20:52\-\>count\=752852,total\=1048576bs,buffer\=1048576bs\-\>14:317:20:52\-\>count\=131072,total\=196608bs,buffer\=196608bs\-\>17:2
。。。。。。。。。。。。。。。。。。。。。。
17:20:57\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:57\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:57\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:57\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:58\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:58\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:117:20:58\-\>count\=\-1,total\=1048576bs,buffer\=1048576bs\-\>15:1
系统接受到连接后,在工作线程中执行了回调。并且在回调中执行了 read 方法,耗时是 0,因为只是注册了个接受数据的回调而已。 系统接受到数据后,把数据放入 ByteBuffer,在工作线程中执行了回调。并且回调中可以直接使用 ByteBuffer 中的数据。 接受数据的回调被执行了多次,多次接受到的数据加起来正好等于客户端传来的数据。 因为系统是接受到数据后才触发的回调,所以服务器端最多时是 3 个线程在同时运行回调的,换句话说,线程池包含 3 个线程就可以了。 对比与结论: 处理同样的 20 个请求,一个需要用 20 个线程,一个需要用 6 个线程,一个需要 3 个线程,又节省了 50% 线程数。
注:不用特别较真这个比较结果,这里只是为了说明问题而已。哈哈。
三种处理方式的对比
第一种是阻塞 IO,阻塞点有两个,等待数据就绪的过程和读取数据的过程。 第二种是阻塞 IO,阻塞点有一个,读取数据的过程。 第三种是非阻塞 IO,没有阻塞点,当工作线程启动时,数据已经(被系统)准备好可以直接用了。
可见,这是一个逐步消除阻塞点的过程。 再次来谈谈各种 IO: 只有一个线程,接受一个连接,读取数据,处理业务,写回结果,再接受下一个连接,这是同步阻塞。这种用法几乎没有。 一个线程和一个线程池,线程接受到连接后,把它丢给线程池中的线程,再接受下一个连接,这是异步阻塞。对应示例一。 一个线程和一个线程池,线程运行 selector,执行 select 操作,把就绪的连接拿出来丢给线程池中的线程,再执行下一次的 select 操作,就是多路复用,这是异步阻塞。对应示例二。 一个线程和一个线程池,线程注册一个 accept 回调,系统帮我们接受好连接后,才触发回调在线程池中执行,执行时再注册 read 回调,系统帮我们接受好数据后,才触发回调在线程池中执行,就是 AIO,这是异步非阻塞。对应示例三。
redis 也是多路复用,但它只有一个线程在执行 select 操作,处理就绪的连接,整个是串行化的,所以天然不存在并发问题。只能把它归为同步阻塞了。
BIO 是阻塞 IO,可以是同步阻塞,也可以是异步阻塞。AIO 是异步 IO,只有异步非阻塞这一种。因此没有同步非阻塞这种说法,因为同步一定是阻塞的。
注:以上的说法是站在用户程序 / 线程的立场上来说的。
建议把代码下载下来,自己运行一下,体会体会:
https://github.com/coding-new-talking/java-code-demo.git
在日常使用 SpringMVC 进行开发的时候,有可能遇到前端各种类型的请求参数,这里做一次相对全面的总结。SpringMVC 中处理控制器参数的接口是 HandlerMethodArgumentResolver,此接口有众多子类,分别处理不同 (注解类型) 的参数,下面只列举几个子类:
实际上,一般在解析一个控制器的请求参数的时候,用到的是 HandlerMethodArgumentResolverComposite,里面装载了所有启用的 HandlerMethodArgumentResolver 子类。而 HandlerMethodArgumentResolver 子类在解析参数的时候使用到 HttpMessageConverter (实际上也是一个列表,进行遍历匹配解析) 子类进行匹配解析,常见的如 MappingJackson2HttpMessageConverter。而 HandlerMethodArgumentResolver 子类到底依赖什么 HttpMessageConverter 实例实际上是由请求头中的 ContentType (在 SpringMVC 中统一命名为 MediaType,见 org.springframework.http.MediaType) 决定的,因此我们在处理控制器的请求参数之前必须要明确外部请求的 ContentType 到底是什么。上面的逻辑可以直接看源码 AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters,思路是比较清晰的。在 @RequestMapping 注解中,produces 和 consumes 就是和请求或者响应的 ContentType 相关的:
另外提一点,SpringMVC 中默认使用 Jackson 作为 JSON 的工具包,如果不是完全理解透整套源码的运作,一般不是十分建议修改默认使用的 MappingJackson2HttpMessageConverter (例如有些人喜欢使用 FastJson,实现 HttpMessageConverter 引入 FastJson 做转换器)。
其实一般的表单或者 JSON 数据的请求都是相对简单的,一些复杂的处理主要包括 URL 路径参数、文件上传、数组或者列表类型数据等。另外,关于参数类型中存在日期类型属性 (例如 java.util.Date、java.sql.Date、java.time.LocalDate、java.time.LocalDateTime),解析的时候一般需要自定义实现的逻辑实现 String-> 日期类型的转换。其实道理很简单,日期相关的类型对于每个国家、每个时区甚至每个使用者来说认知都不一定相同。在演示一些例子主要用到下面的模特类:
@Data
public class User {
private String name;
private Integer age;
private List<Contact> contacts;
}
@Data
public class Contact {
private String name;
private String phone;
}
非对象类型单个参数接收:
这种是最常用的表单参数提交,ContentType 指定为 application/x-www-form-urlencoded,也就是会进行 URL 编码。
spmvc-p-1
对应的控制器如下:
@PostMapping(value = "/post")
public String post(@RequestParam(name = "name") String name,
@RequestParam(name = "age") Integer age) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
说实话,如果有毅力的话,所有的复杂参数的提交最终都可以转化为多个单参数接收,不过这样做会产生十分多冗余的代码,而且可维护性比较低。这种情况下,用到的参数处理器是 RequestParamMapMethodArgumentResolver。
对象类型参数接收:
我们接着写一个接口用于提交用户信息,用到的是上面提到的模特类,主要包括用户姓名、年龄和联系人信息列表,这个时候,我们目标的控制器最终编码如下:
@PostMapping(value = "/user")
public User saveUser(User user) {
log.info(user.toString());
return user;
}
我们还是指定 ContentType 为 application/x-www-form-urlencoded,接着我们需要构造请求参数:
spmvc-p-2
因为没有使用注解,最终的参数处理器为 ServletModelAttributeMethodProcessor,主要是把 HttpServletRequest 中的表单参数封装到 MutablePropertyValues 实例中,再通过参数类型实例化 (通过构造反射创建 User 实例),反射匹配属性进行值的填充。另外,请求复杂参数里面的列表属性请求参数看起来比较奇葩,实际上和在. properties 文件中添加最终映射到 Map 类型的参数的写法是一致的。那么,能不能把整个请求参数塞在一个字段中提交呢?
spmvc-p-3
直接这样做是不行的,因为实际提交的 form 表单,key 是 user,value 实际上是一个字符串,缺少一个 String->User 类型的转换器,实际上 RequestParamMethodArgumentResolver 依赖 WebConversionService 中 Converter 列表进行参数转换:
spmvc-p-4
解决办法还是有的,添加一个 org.springframework.core.convert.converter.Converter 实现即可:
@Component
public class StringUserConverter implements Converter<String, User> {
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public User convert(String source) {
try {
return MAPPER.readValue(source, User.class);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
上面这种做法属于曲线救国的做法,不推荐使用在生产环境,但是如果有些第三方接口的对接无法避免这种参数,可以选择这种实现方式。
一般来说,直接 POST 一个 JSON 字符串这种方式对于 SpringMVC 来说是比较友好的,只需要把 ContentType 设置为 application/json,提交一个原始的 JSON 字符串即可:
spmvc-p-5
后端控制器的代码也比较简单:
@PostMapping(value = "/user-2")
public User saveUser2(@RequestBody User user) {
log.info(user.toString());
return user;
}
因为使用了 @RequestBody 注解,最终使用到的参数处理器为 RequestResponseBodyMethodProcessor,实际上会用到 MappingJackson2HttpMessageConverter 进行参数类型的转换,底层依赖到 Jackson 相关的包。
URL 参数,或者叫请求路径参数是基于 URL 模板获取到的参数,例如 /user/{userId} 是一个 URL 模板 (URL 模板中的参数占位符是 {}),实际请求的 URL 为 /user/1,那么通过匹配实际请求的 URL 和 URL 模板就能提取到 userId 为 1。在 SpringMVC 中,URL 模板中的路径参数叫做 PathVariable,对应注解 @PathVariable,对应的参数处理器为 PathVariableMethodArgumentResolver。注意一点是,@PathVariable 的解析是按照 value (name) 属性进行匹配,和 URL 参数的顺序是无关的。举个简单的例子:
spmvc-p-6
后台的控制器如下:
@GetMapping(value = "/user/{name}/{age}")
public String findUser1(@PathVariable(value = "age") Integer age,
@PathVariable(value = "name") String name) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
这种用法被广泛使用于 Representational State Transfer (REST) 的软件架构风格,个人觉得这种风格是比较灵活和清晰的 (从 URL 和请求方法就能完全理解接口的意义和功能)。下面再介绍两种相对特殊的使用方式。
带条件的 URL 参数
其实路径参数支持正则表达式,例如我们在使用 /sex/{sex} 接口的时候,要求 sex 必须是 F (Female) 或者 M (Male),那么我们的 URL 模板可以定义为 /sex/{sex:M|F},代码如下:
@GetMapping(value = "/sex/{sex:M|F}")
public String findUser2(@PathVariable(value = "sex") String sex){
log.info(sex);
return sex;
}
只有 /sex/F 或者 /sex/M 的请求才会进入 findUser2 控制器方法,其他该路径前缀的请求都是非法的,会返回 404 状态码。这里仅仅是介绍了一个最简单的 URL 参数正则表达式的使用方式,更强大的用法可以自行摸索。
@MatrixVariable 的使用
MatrixVariable 也是 URL 参数的一种,对应注解 @MatrixVariable,不过它并不是 URL 中的一个值 (这里的值指定是两个 "/" 之间的部分),而是值的一部分,它通过 ";" 进行分隔,通过 "=" 进行 K-V 设置。说起来有点抽象,举个例子:假如我们需要打电话给一个名字为 doge,性别是男,分组是码畜的程序员,GET 请求的 URL 可以表示为:/call/doge;gender=male;group=programmer,我们设计的控制器方法如下:
@GetMapping(value = "/call/{name}")
public String find(@PathVariable(value = "name") String name,
@MatrixVariable(value = "gender") String gender,
@MatrixVariable(value = "group") String group) {
String content = String.format("name = %s,gender = %s,group = %s", name, gender, group);
log.info(content);
return content;
}
当然,如果你按照上面的例子写好代码,尝试请求一下该接口发现是报错的:400 Bad Request - Missing matrix variable 'gender' for method parameter of type String。这是因为 @MatrixVariable 注解的使用是不安全的,在 SpringMVC 中默认是关闭对其支持。要开启对 @MatrixVariable 的支持,需要设置 RequestMappingHandlerMapping#setRemoveSemicolonContent 方法为 false:
@Configuration
public class CustomMvcConfiguration implements InitializingBean {
@Autowired
private RequestMappingHandlerMapping requestMappingHandlerMapping;
@Override
public void afterPropertiesSet() throws Exception {
requestMappingHandlerMapping.setRemoveSemicolonContent(false);
}
}
除非有很特殊的需要,否则不建议使用 @MatrixVariable。
文件上传在使用 POSTMAN 模拟请求的时候需要选择 form-data,POST 方式进行提交:
spmvc-p-8
假设我们在 D 盘有一个图片文件叫 doge.jpg,现在要通过本地服务接口把文件上传,控制器的代码如下:
@PostMapping(value = "/file1")
public String file1(@RequestPart(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
控制台输出是:
name = file1,originName = doge.jpg,size = 68727
可能有点疑惑,参数是怎么来的,我们可以用 Fildder 抓个包看下:
spmvc-p-7
可知 MultipartFile 实例的主要属性分别来自 Content-Disposition、content-type 和 content-length,另外,InputStream 用于读取请求体的最后部分 (文件的字节序列)。参数处理器用到的是 RequestPartMethodArgumentResolver (记住一点,使用了 @RequestPart 和 MultipartFile 一定是使用此参数处理器)。在其他情况下,使用 @RequestParam 和 MultipartFile 或者仅仅使用 MultipartFile (参数的名字必须和 POST 表单中的 Content-Disposition 描述的 name 一致) 也可以接收上传的文件数据,主要是通过 RequestParamMethodArgumentResolver 进行解析处理的,它的功能比较强大,具体可以看其 supportsParameter 方法,这两种情况的控制器方法代码如下:
@PostMapping(value = "/file2")
public String file2(MultipartFile file1) {
String content = String.format("name = %s,originName = %s,size = %d",
file1.getName(), file1.getOriginalFilename(), file1.getSize());
log.info(content);
return content;
}
@PostMapping(value = "/file3")
public String file3(@RequestParam(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
其他参数主要包括请求头、Cookie、Model、Map 等相关参数,还有一些并不是很常用或者一些相对原生的属性值获取 (例如 HttpServletRequest、HttpServletResponse 等) 不做讨论。
请求头的值主要通过 @RequestHeader 注解的参数获取,参数处理器是 RequestHeaderMethodArgumentResolver,需要在注解中指定请求头的 Key。简单实用如下:
spmvc-p-9
控制器方法代码:
@PostMapping(value = "/header")
public String header(@RequestHeader(name = "Content-Type") String contentType) {
return contentType;
}
Cookie 的值主要通过 @CookieValue 注解的参数获取,参数处理器为 ServletCookieValueMethodArgumentResolver,需要在注解中指定 Cookie 的 Key。控制器方法代码如下:
@PostMapping(value = "/cookie")
public String cookie(@CookieValue(name = "JSESSIONID") String sessionId) {
return sessionId;
}
Model 类型参数的处理器是 ModelMethodProcessor,实际上处理此参数是直接返回 ModelAndViewContainer 实例中的 Model (ModelMap 类型),因为要桥接不同的接口和类的功能,因此回调的实例是 BindingAwareModelMap 类型,此类型继承自 ModelMap 同时实现了 Model 接口。举个例子:
@GetMapping(value = "/model")
public String model(Model model, ModelMap modelMap) {
log.info("{}", model == modelMap);
return "success";
}
注意调用此接口,控制台输出 Info 日志内容为:true。ModelMap 或者 Model 中添加的属性项会附加到 HttpRequestServlet 中带到页面中进行渲染。
@ModelAttribute 注解处理的参数处理器为 ModelAttributeMethodProcessor,@ModelAttribute 的功能源码的注释如下:
Annotation that binds a method parameter or method return value to a named model attribute, exposed to a web view.
简单来说,就是通过 key-value 形式绑定方法参数或者方法返回值到 Model (Map) 中,区别下面三种情况:
在一个控制器 (使用了 @controller) 中,如果存在一到多个使用了 @ModelAttribute 的方法,这些方法总是在进入控制器方法之前执行,并且执行顺序是由加载顺序决定的 (具体的顺序是带参数的优先,并且按照方法首字母升序排序),举个例子:
@Slf4j
@RestController
public class ModelAttributeController {
@ModelAttribute
public void before(Model model) {
log.info("before..........");
model.addAttribute("before", "beforeValue");
}
@ModelAttribute(value = "beforeArg")
public String beforeArg() {
log.info("beforeArg..........");
return "beforeArgValue";
}
@GetMapping(value = "/modelAttribute")
public String modelAttribute(Model model, @ModelAttribute(value = "beforeArg") String beforeArg) {
log.info("modelAttribute..........");
log.info("beforeArg..........{}", beforeArg);
log.info("{}", model);
return "success";
}
@ModelAttribute
public void after(Model model) {
log.info("after..........");
model.addAttribute("after", "afterValue");
}
@ModelAttribute(value = "afterArg")
public String afterArg() {
log.info("afterArg..........");
return "afterArgValue";
}
}
调用此接口,控制台输出日志如下:
after..........
before..........
afterArg..........
beforeArg..........
modelAttribute..........
beforeArg..........beforeArgValue
{after=afterValue, before=beforeValue, afterArg=afterArgValue, beforeArg=beforeArgValue}
可以印证排序规则和参数设置、获取。
Errors 其实是 BindingResult 的父接口,BindingResult 主要用于回调 JSR 参数校验异常的属性项,如果 JSR 校验异常,一般会抛出 MethodArgumentNotValidException 异常,并且会返回 400 (Bad Request),见全局异常处理器 DefaultHandlerExceptionResolver。Errors 类型的参数处理器为 ErrorsMethodArgumentResolver。举个例子:
@PostMapping(value = "/errors")
public String errors(@RequestBody @Validated ErrorsModel errors, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
for (ObjectError objectError : bindingResult.getAllErrors()) {
log.warn("name={},message={}", objectError.getObjectName(), objectError.getDefaultMessage());
}
}
return errors.toString();
}
@Data
@NoArgsConstructor
public class ErrorsModel {
@NotNull(message = "id must not be null!")
private Integer id;
@NotEmpty(message = "errors name must not be empty!")
private String name;
}
调用接口控制台 Warn 日志如下:
name=errors,message=errors name must not be empty!
一般情况下,不建议用这种方式处理 JSR 校验异常的属性项,因为会涉及到大量的重复的硬编码工作,建议直接继承 ResponseEntityExceptionHandler,覆盖对应的方法。
控制器方法的参数可以是 @value 注解修饰的参数,会从 Environment 中装配和转换属性值到对应的参数中 (也就是参数的来源并不是请求体),参数处理器为 ExpressionValueMethodArgumentResolver。举个例子:
@GetMapping(value = "/value")
public String value(@Value(value = "${spring.application.name}") String name) {
log.info("spring.application.name={}", name);
return name;
}
Map 类型参数的范围相对比较广,对应一系列的参数处理器,注意区别使用了上面提到的部分注解的 Map 类型和完全不使用注解的 Map 类型参数,两者的处理方式不相同。下面列举几个相对典型的 Map 类型参数处理例子。
不使用任何注解的 Map<String,Object> 参数
这种情况下参数实际上直接回调 ModelAndViewContainer 中的 ModelMap 实例,参数处理器为 MapMethodProcessor,往 Map 参数中添加的属性将会带到页面中。
使用 @RequestParam 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestParamMapMethodArgumentResolver,使用的请求方式需要指定 ContentType 为 x-www-form-urlencoded,不能使用 application/json 的方式:
spmvc-p-10
控制器代码为:
@PostMapping(value = "/map")
public String mapArgs(@RequestParam Map<String, Object> map) {
log.info("{}", map);
return map.toString();
}
使用 @RequestHeader 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 RequestHeaderMapMethodArgumentResolver,作用是获取请求的所有请求头的 Key-Value。
使用 @PathVariable 注解的 Map<String,Object> 参数
这种情况下的参数处理器为 PathVariableMapMethodArgumentResolver,作用是获取所有路径参数封装为 Key-Value 结构。
批量文件上传的时候,我们一般需要接收一个 MultipartFile 集合,可以有两种选择:
getFiles 方法获取 MultipartFile 列表。spmvc-p-11
控制器方法代码如下:
@PostMapping(value = "/parts")
public String partArgs(@RequestParam(name = "file") List<MultipartFile> parts) {
log.info("{}", parts);
return parts.toString();
}
日期处理个人认为是请求参数处理中最复杂的,因为一般日期处理的逻辑不是通用的,过多的定制化处理导致很难有一个统一的标准处理逻辑去处理和转换日期类型的参数。不过,这里介绍几个通用的方法,以应对各种奇葩的日期格式。下面介绍的例子中全部使用 Jdk8 中引入的日期时间 API,围绕 java.util.Date 为核心的日期时间 API 的使用方式类同。
这种是最原始但是最奏效的方式,统一以字符串形式接收,然后自行处理类型转换,下面给个小例子:
@PostMapping(value = "/date1")
public String date1(@RequestBody UserDto userDto) {
UserEntity userEntity = new UserEntity();
userEntity.setUserId(userDto.getUserId());
userEntity.setBirthdayTime(LocalDateTime.parse(userDto.getBirthdayTime(), FORMATTER));
userEntity.setGraduationTime(LocalDateTime.parse(userDto.getGraduationTime(), FORMATTER));
log.info(userEntity.toString());
return "success";
}
@Data
public class UserDto {
private String userId;
private String birthdayTime;
private String graduationTime;
}
@Data
public class UserEntity {
private String userId;
private LocalDateTime birthdayTime;
private LocalDateTime graduationTime;
}
spmvc-p-12
@DateTimeFormat 注解配合 @RequestBody 的参数使用的时候,会发现抛出 InvalidFormatException 异常,提示转换失败,这是因为在处理此注解的时候,只支持 form 提交 (ContentType 为 x-www-form-urlencoded),例子如下:
spmvc-p-13
@Data
public class UserDto2 {
private String userId;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime birthdayTime;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime graduationTime;
}
@PostMapping(value = "/date2")
public String date2(UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@PostMapping(value = "/date2")
public String date2(@RequestParam("name"="userId")String userId,
@RequestParam("name"="birthdayTime")LocalDateTime birthdayTime,
@RequestParam("name"="graduationTime")LocalDateTime graduationTime) {
return "success";
}
而 @jsonformat 注解可使用在 form 或者 Json 请求参数的场景,因此更推荐使用 @jsonformat 注解,不过注意需要指定时区 (timezone 属性,例如在**是东八区 "GMT+8"),否则有可能导致出现 "时差",举个例子:
@PostMapping(value = "/date2")
public String date2(@RequestBody UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@Data
public class UserDto2 {
private String userId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime birthdayTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime graduationTime;
}
因为 SpringMVC 默认使用 Jackson 处理 @RequestBody 的参数转换,因此可以通过定制序列化器和反序列化器来实现日期类型的转换,这样我们就可以使用 application/json 的形式提交请求参数。这里的例子是转换请求 Json 参数中的字符串为 LocalDateTime 类型,属于 Json 反序列化,因此需要定制反序列化器:
@PostMapping(value = "/date3")
public String date3(@RequestBody UserDto3 userDto3) {
log.info(userDto3.toString());
return "success";
}
@Data
public class UserDto3 {
private String userId;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime birthdayTime;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime graduationTime;
}
public class CustomLocalDateTimeDeserializer extends LocalDateTimeDeserializer {
public CustomLocalDateTimeDeserializer() {
super(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
}
前面三种方式都存在硬编码等问题,其实最佳实践是直接修改 MappingJackson2HttpMessageConverter 中的 ObjectMapper 对于日期类型处理默认的序列化器和反序列化器,这样就能全局生效,不需要再使用其他注解或者定制序列化方案 (当然,有些时候需要特殊处理定制),或者说,在需要特殊处理的场景才使用其他注解或者定制序列化方案。使用钩子接口 Jackson2ObjectMapperBuilderCustomizer 可以实现 ObjectMapper 的属性定制:
@Bean
public Jackson2ObjectMapperBuilderCustomizer jackson2ObjectMapperBuilderCustomizer(){
return customizer->{
customizer.serializerByType(LocalDateTime.class,new LocalDateTimeSerializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
customizer.deserializerByType(LocalDateTime.class,new LocalDateTimeDeserializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
};
}
这样就能定制化 MappingJackson2HttpMessageConverter 中持有的 ObjectMapper,上面的 LocalDateTime 序列化和反序列化器对全局生效。
前面基本介绍完了主流的请求参数处理,其实 SpringMVC 中还会按照 URL 的模式进行匹配,使用的是 Ant 路径风格,处理工具类为 org.springframework.util.AntPathMatcher,从此类的注释来看,匹配规则主要包括下面四点:
? 匹配 1 个字符。* 匹配 0 个或者多个字符。** 匹配路径中 0 个或者多个目录。{spring:[a-z]+} 将正则表达式 [a-z]+ 匹配到的值,赋值给名为 spring 的路径变量。举些例子:
? 形式的 URL:
@GetMapping(value = "/pattern?")
public String pattern() {
return "success";
}
/pattern 404 Not Found
/patternd 200 OK
/patterndd 404 Not Found
/pattern/ 404 Not Found
/patternd/s 404 Not Found
* 形式的 URL:
@GetMapping(value = "/pattern*")
public String pattern() {
return "success";
}
/pattern 200 OK
/pattern/ 200 OK
/patternd 200 OK
/pattern/a 404 Not Found
** 形式的 URL:
@GetMapping(value = "/pattern/**/p")
public String pattern() {
return "success";
}
/pattern/p 200 OK
/pattern/x/p 200 OK
/pattern/x/y/p 200 OK
{spring:[a-z]+} 形式的 URL:
@GetMapping(value = "/pattern/{key:[a-c]+}")
public String pattern(@PathVariable(name = "key") String key) {
return "success";
}
/pattern/a 200 OK
/pattern/ab 200 OK
/pattern/abc 200 OK
/pattern 404 Not Found
/pattern/abcd 404 Not Found
上面的四种 URL 模式可以组合使用,千变万化。
URL 匹配还遵循精确匹配原则,也就是存在两个模式对同一个 URL 都能够匹配成功,则选取最精确的 URL 匹配,进入对应的控制器方法,举个例子:
@GetMapping(value = "/pattern/**/p")
public String pattern1() {
return "success";
}
@GetMapping(value = "/pattern/p")
public String pattern2() {
return "success";
}
上面两个控制器,如果请求 URL 为 /pattern/p,最终进入的方法为 pattern2。
最后,org.springframework.util.AntPathMatcher 作为一个工具类,可以单独使用,不仅仅可以用于匹配 URL,也可以用于匹配系统文件路径,不过需要使用其带参数构造改变内部的 pathSeparator 变量,例如:
AntPathMatcher antPathMatcher = new AntPathMatcher(File.separator);
笔者在前一段时间曾经花大量时间梳理和分析过 Spring、SpringMVC 的源码,但是后面一段很长的时间需要进行业务开发,对架构方面的东西有点生疏了,毕竟东西不用就会生疏,这个是常理。这篇文章基于一些 SpringMVC 的源码经验总结了请求参数的处理相关的一些知识,希望帮到自己和大家。
参考资料:
一次性能提高 30 倍的 JAVA 类反射性能优化实践
文章来源:宜信技术学院 & 宜信支付结算团队技术分享第 4 期 - 支付结算部支付研发团队高级工程师陶红《JAVA 类反射技术 & 优化》
分享者:宜信支付结算部支付研发团队高级工程师陶红
原文首发于宜信支付结算技术团队公号:野指针
在实际工作中的一些特定应用场景下,JAVA 类反射是经常用到、必不可少的技术,在项目研发过程中,我们也遇到了不得不运用 JAVA 类反射技术的业务需求,并且不可避免地面临这个技术固有的性能瓶颈问题。
通过近两年的研究、尝试和验证,我们总结出一套利用缓存机制、大幅度提高 JAVA 类反射代码运行效率的方法,和没有优化的代码相比,性能提高了 20~30 倍。本文将与大家分享在探索和解决这个问题的过程中的一些有价值的心得体会与实践经验。
首先,用最简短的篇幅介绍 JAVA 类反射技术。
如果用一句话来概述,JAVA 类反射技术就是:
绕开编译器,在运行期直接从虚拟机获取对象实例 / 访问对象成员变量 / 调用对象的成员函数。
抽象的概念不多讲,用代码说话…… 举个例子,有这样一个类:
public class ReflectObj {
private String field01;
public String getField01() {
return this.field01;
}
public void setField01(String field01) {
this.field01 = field01;
}
}```
如果按照下列代码来使用这个类,就是传统的 “创建对象-调用” 模式:
```null
ReflectObj obj = new ReflectObj();
obj.setField01("value01");
System.out.println(obj.getField01());```
如果按照如下代码来使用它,就是 “类反射” 模式:
```null
ReflectObj obj = ReflectObj.class.newInstance();
Field field = ReflectObj.class.getField("field01");
field.setAccessible(true);
field.set(obj, "value01");
Method method = ReflectObj.class.getMethod("getField01");
System.out.println((String) method.invoke(obj));```
类反射属于古老而基础的 JAVA 技术,本文不再赘述。
从上面的代码可以看出:
* 相比较于传统的 “创建对象-调用” 模式,“类反射” 模式的代码更抽象、一般情况下也更加繁琐;
* 类反射绕开了编译器的合法性检测 —— 比如访问了一个不存在的字段、调用了一个不存在或不允许访问的函数,因为编译器设立的防火墙失效了,编译能够通过,但是运行的时候会报错;
* 实际上,如果按照标准模式编写类反射代码,效率明显低于传统模式。在后面的章节会提到这一点。
缘起:为什么使用类反射
-----------
前文简略介绍了 JAVA 类反射技术,在与传统的 “创建对象-调用” 模式对比时,提到了类反射的几个主要弱点。但是在实际工作中,我们发现类反射无处不在,特别是在一些底层的基础框架中,类反射是应用最为普遍的核心技术之一。最常见的例子:Spring 容器。
这是为什么呢?我们不妨从实际工作中的具体案例出发,分析类反射技术的不可替代性。
大家几乎每天都和银行打交道,通过银行进行存款、转帐、取现等金融业务,这些动账操作都是通过银行核心系统(包括交易核心 / 账务核心 / 对外支付 / 超级网银等模块)完成的,因为历史原因造成的技术路径依赖,银行核心系统的报文几乎都是 xml 格式,而且以这种格式最为普遍:
```null
<?xml version='1.0' encoding='UTF-8'?>
<service>
<sys-header>
<data name="SYS_HEAD">
<struct>
<data name="MODULE_ID">
<field type="string" length="2">RB</field>
</data>
<data name="USER_ID">
<field type="string" length="6">OP0001</field>
</data>
<data name="TRAN_TIMESTAMP">
<field type="string" length="9">003026975</field>
</data>
</struct>
</data>
</sys-header>
<body>
<data name="REF_NO">
<field type="string" length="23">OPS18112400302633661837</field>
</data>
</body>
</service>```
和常用的 xml 格式进行对比:
```null
<?xml version="1.0" encoding="UTF-8"?>
<recipe>
<recipename>Ice Cream Sundae</recipename>
<ingredlist>
<listitem>
<quantity>3</quantity>
<itemdescription>chocolate syrup or chocolate fudge</itemdescription>
</listitem>
<listitem>
<quantity>1</quantity>
<itemdescription>nuts</itemdescription>
</listitem>
<listitem>
<quantity>1</quantity>
<itemdescription>cherry</itemdescription>
</listitem>
</ingredlist>
<preptime>5 minutes</preptime>
</recipe>```
银行核心系统的 xml 报文不是用标签的名字区分元素,而是用属性(name 属性)区分,在解析的时候,不管是用 DOM、SAX,还是 Digester 或其它方案,都要用条件判断语句、分支处理,伪代码如下:
```null
// ……
接口类实例 obj = new 接口类();
List<Node> nodeList = 获取xml标签列表
for (Node node: nodeList) {
if (node.getProperty("name") == "张三") obj.set张三 (node.getValue());
else if (node.getProperty("name") == "李四") obj.set李四 (node.getValue());
// ……
}
// ……```
显而易见,这样的代码非常粗劣、不优雅,每解析一个接口的报文,都要写一个专门的类或者函数,堆砌大量的条件分支语句,难写、难维护。如果报文结构简单还好,如果有一百个甚至更多的字段,怎么办?毫不夸张,在实际工作中,我遇到过一个银行核心接口有 140 多个字段的情况,而且这还不是最多的!
试水:优雅地解析 XML
------------
当我们碰到这种结构的 xml、而且字段还特别多的时候,解决问题的钥匙就是类反射技术,基本思路是:
* 从 xml 中解析出字段的 name 和 value,以键值对的形式存储起来;
* 用类反射的方法,用键值对的 name 找到字段或字段对应的 setter(这是有规律可循的);
* 然后把 value 直接 set 到字段,或者调用 setter 把值 set 到字段。
接口类应该是这样的结构:


* nodes 是存储字段的 name-value 键值对的列表,MessageNode 就是键值对,结构如下:
```null
public class MessageNode {
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public MessageNode() {
super();
}
}```
* createNode 是在解析 xml 的时候,把键值对添加到列表的函数;
* initialize 是用类反射方法,根据键值对初始化每个字段的函数。
这样,解析 xml 的代码可以变得非常优雅、简洁。如果用 Digester 解析之前列举的那种格式的银行报文,可以这样写:
```null
Digester digester = new Digester();
digester.setValidating(false);
digester.addObjectCreate("service/sys-header", SysHeader.class);
digester.addCallMethod("service/sys-header/data/struct/data", "createNode", 2);
digester.addCallParam("service/sys-header/data/struct/data", 0, "name");
digester.addCallParam("service/sys-header/data/struct/data/field", 1);
parseObj = (SysHeader) digester.parse(new StringReader(msg));
parseObj.initialize();```
initialize 函数的代码,可以写在一个基类里面,子类继承基类即可。具体代码如下:
```null
public void initialize() {
for (MessageNode node: nodes) {
try {
/**
* 直接获取字段、然后设置字段值
*/
//String fieldName = StringUtils.camelCaseConvert(node.getName());
// 只获取调用者自己的field(private/protected/public修饰词皆可)
//Field field = this.getClass().getDeclaredField(fieldName);
// 获取调用者自己的field(private/protected/public修饰词皆可)和从父类继承的field(必须是public修饰词)
//Field field = this.getClass().getField(fieldName);
// 把field设为可写
//field.setAccessible(true);
// 直接设置field的值
//field.set(this, node.getValue());
/**
* 通过setter设置字段值
*/
Method method = this.getSetter(node.getName());
// 调用setter
method.invoke(this, node.getValue());
} catch (Exception e) {
log.debug("It's failed to initialize field: {}, reason: {}", node.getName(), e);
};
}
}```
上面被注释的段落是直接访问 Field 的方式,下面的段落是调用 setter 的方式,两种方法在效率上没有差别。
考虑到 JAVA 语法规范(书写 bean 的规范),调用 setter 是更通用的办法,因为接口类可能是被继承、派生的,子类无法访问父类用 private 关键字修饰的 Field。
getSetter 函数很简单,就是用 Field 的名字反推 setter 的名字,然后用类反射的办法获取 setter。代码如下:
```null
private Method getSetter(String fieldName) throws NoSuchMethodException, SecurityException {
String methodName = String.format("set%s", StringUtils.upperFirstChar(fieldName));
return this.getClass().getMethod(methodName, String.class);
}```
如果设计得好,甚至可以用一个解析函数处理所有的接口,这涉及到 Digerser 的运用技巧和接口类的设计技巧,本文不作深入讲解。
2017 年,我们在一个和银行有关的金融增值服务项目中使用了这个解决方案,取得了非常不错的效果,之后在公司内部推广开来成为了通用技术架构。经过一年多的实践,证明这套架构性能稳定、可靠,极大地简化了代码编写和维护工作,显著提高了生产效率。
问题:类反射性能差
---------
但是,随着业务量的增加,2018 年末在进行压力测试的时候,发现解析 xml 的代码占用 CPU 资源居高不下。进一步分析、定位,发现问题出在类反射代码上,在某些极端的业务场景下,甚至会占用 90%的 CPU 资源!这就提出了性能优化的迫切要求。
类反射的性能优化不是什么新课题,因此有一些成熟的第三方解决方案可以参考,比如运用比较广泛的 ReflectASM,据称可以比未经优化的类反射代码提高 1/3 左右的性能。
(参考资料:[Java 高性能反射工具包 ReflectASM](https://www.cnblogs.com/juetoushan/p/7724793.html),[ReflectASM-invoke, 高效率 java 反射机制原理](https://www.cnblogs.com/tohxyblog/p/8661090.html))
在研究了 ReflectASM 的源代码以后,我们决定不使用现成的第三方解决方案,而是从底层入手、自行解决类反射代码的优化问题。主要基于两点考虑:
* ReflectASM 的基本技术原理,是在运行期动态分析类的结构,把字段、函数建立索引,然后通过索引完成类反射,技术上并不高深,性能也谈不上完美;
* 类反射是我们系统使用的关键技术,使用场景、调用频率都非常高,从自主掌握和控制基础、核心技术,实现系统的性能最优化角度考虑,应该尽量从底层技术出发,独立、可控地完成优化工作。
思路和实践:缓存优化
----------
前面提到 ReflectASM 给类的字段、函数建立索引,借此提高类反射效率。进一步分析,这实际上是变相地缓存了字段和函数。那么,在我们面临的业务场景下,能不能用缓存的方式优化类反射代码的效率呢?
我们的业务场景需要以类反射的方式频繁调用接口类的 setter,这些 setter 都是用 public 关键字修饰的函数,先是 getMethod ()、然后 invoke ()。基于以上特点,我们用如下逻辑和流程进行了技术分析:
* 用调试分析工具统计出每一句类反射代码的执行耗时,结果发现性能瓶颈在 getMethod ();
* 分析 JAVA 虚拟机的内存模型和管理机制,寻找解决问题的方向。JAVA 虚拟机的内存模型,可以从下面两个维度来描述:
A. 类空间 / 对象空间维度

B. 堆 / 栈维度

* 从 JAVA 虚拟机内存模型可以看出,getMethod () 需要从不连续的堆中检索代码段、定位函数入口,获得了函数入口、invoke () 之后就和传统的函数调用差不多了,所以性能瓶颈在 getMethod ();
* 代码段属于类空间(也有资料将其描述为 “函数空间”/“代码空间”),类被加载后,除非虚拟机关闭,函数入口不会变化。那么,只要把 setter 函数的入口缓存起来,不就节约了 getMethod () 消耗的系统资源,进而提高了类反射代码的执行效率吗?
把接口类修改为这样的结构(标红的部分是新增或修改):


setterMap 就是缓存字段 setter 的 HashMap。为什么是两层嵌套结构呢?因为这个 Map 是写在基类里面的静态变量,每个从基类派生出的接口类都用它缓存 setter,所以第一层要区分不同的接口类,第二层要区分不同的字段。如下图所示:

当 ClassLoader 加载基类时,创建 setterMap(内容为空):
```null
static {
setterMap = new HashMap<String, Map<String, Method>>();
}```
这样写可以保证 setterMap 只被初始化一次。
Initialize () 函数作如下改进:
```null
public void initialize() {
// 先检查子类的setter是否被缓存
String className = this.getClass().getName();
if (setterMap.get(className) == null) setterMap.put(className, new HashMap<String, Method>());
Map<String, Method> setters = setterMap.get(className);
// 遍历报文节点
for (MessageNode node: nodes) {
try {
// 检查对应的setter是否被缓存了
Method method = setters.get(node.getName());
if (method == null) {
// 没有缓存,先获取、再缓存
method = this.getSetter(node.getName());
setters.put(node.getName(), method);
}
// 用类反射方式调用setter
method.invoke(this, node.getValue());
} catch (Exception e) {
log.debug("It's failed to initialize field: {}, reason: {}", node.getName(), e);
};
}
}```
基本思路就是把 setter 缓存起来,通过 MessageNode 的 name(字段的名字)找 setter 的入口地址,然后调用。
因为只在初始化第一个对象实例的时候调用 getMethod (),极大地节约了系统资源、提高了效率,测试结果也证实了这一点。
验证:测试方法和标准
----------
1)先写一个测试类,结构如下:


2)在构造函数中,用 UUID 初始化存储键值对的列表 nodes:
```null
this.createNode("test001", String.valueOf(UUID.randomUUID().toString().hashCode()));
this.createNode("test002", String.valueOf(UUID.randomUUID().toString().hashCode()));
```
之所以用 UUID,是保证每个实例、每个字段的值都不一样,避免 JAVA 编译器自动优化代码而破坏测试结果的原始性。
3)Initialize\_ori () 函数是用传统的硬编码方式直接调用 setter 的方法初始化实例字段,代码如下:
```null
for (MessageNode node: this.nodes) {
if (node.getName().equalsIgnoreCase("test001")) this.setTest001(node.getValue());
else if (node.getName().equalsIgnoreCase("test002")) this.setTest002(node.getValue());
// ……
}```
优化效果就以它作为对照标准 1,对照标准 2 就是没有优化的类反射代码。
4)checkUnifomity () 函数用来验证:代码是否用 name-value 键值对正确地初始化了各字段。
```null
for (MessageNode node: nodes) {
if (node.getName().equalsIgnoreCase("test001") && !node.getValue().equals(this.test001)) return false;
else if (node.getName().equalsIgnoreCase("test002") && !node.getValue().equals(this.test002)) return false;
// ……
}
return true;```
每一种优化方案,我们都会用它验证实例的字段是否正确,只要出现一次错误,该方案就会被否定。
5)创建 100 万个 TestInvoke 类的实例,然后循环调用每一个实例的 initialize\_ori () 函数(传统的硬编码,非类反射方法),记录执行耗时(只记录初始化耗时,创建实例的耗时不记录);再创建 100 万个实例,循环调用每一个实例的类反射初始化函数(未优化),记录执行耗时;再创建 100 万个实例,改成调用优化后的类反射初始化函数,记录执行耗时。
6) 以上是一个测试循环,得到三种方法的耗时数据,重复做 10 次,得到三组耗时数据,把记录下的数据去掉最大、最小值,剩下的求平均值,就是该方法的平均耗时。某一种方法的平均耗时越短则认为该方法的效率越高。
7) 为了进一步验证三种方法在不同负载下的效率变化规律,改成创建 10 万个实例,重复 5/6 两步,得到另一组测试数据。
测试结果显示:在确保测试环境稳定、一致的前提下,8 个字段的测试实例、初始化 100 万个对象,传统方法(硬编码)耗时 850~1000 毫秒;没有优化的类反射方法耗时 23000~25000 毫秒;优化后的类反射代码耗时 600~800 毫秒。10 万个测试对象的情况,三种方法的耗时也大致是这样的比例关系。这个数据取决于测试环境的资源状况,不同的机器、不同时刻的测试,结果都有出入,但总的规律是稳定的。
基于测试结果,可以得出这样的结论:缓存优化的类反射代码比没有优化的代码效率提高 30 倍左右,比传统的硬编码方法提高了 10~20%。有必要强调的是,这个结论偏向保守。和 ReflecASM 相比,性能大幅度提高也是毋庸置疑的。
第一次迭代:忽略字段
----------
缓存优化的效果非常好,但是,这个方案真的完美无缺了么?
经过分析,我们发现:如果数据更复杂一些,这个方案的缺陷就暴露了。比如键值对列表里的值在接口类里面并没有定义对应的字段,或者是没有对应的、可以访问的 setter,性能就会明显下降。
这种情况在实际业务中是很常见的,比如对接银行核心接口,往往并不需要解析报文的全部字段,很多字段是可以忽略的,所以接口类里面不用定义这些字段,但解析代码依然会把这些键值对全部解析出来,这时就会给优化代码造成麻烦了。
分析过程如下:
1)举例而言,如果键值对里有两个值在接口类(Interface01)并未定义,假定名字是 fieldX、filedY,第一次执行 initialize () 函数:

初始状态下,setterMap 检索不到 Interface01 类的 setter 缓存,initialize () 函数会在第一次执行的时候,根据键值对的名字(field01/field02/……/fieldN/fieldX/fieldY)调用 getMethod () 函数、初始化 sertter 引用的缓存。因为 fieldX 和 fieldY 字段不存在,找不到它们对应的 setter,缓存里也没有它们的引用。
2)第二次执行 initialize () 函数(也就是初始化第二个对象实例),field01/field02/……/fieldN 键值对都能在缓存中找到 setter 的引用,调用速度很快;但缓存里找不到 fieldX/fieldY 的 setter 的引用,于是再次调用 getMethod () 函数,而因为它们的 setter 根本不存在(连这两个字段都不存在),做的是无用功,setterMap 的状态没有变化。
3)第三次、第四次…… 第 N 次,都是如此,白白消耗系统资源,运行效率必然下降。
测试结果印证了这个推断:在 TestInvoke 的构造函数增加了两个不存在对应字段和 setter 的键值对(姑且称之为 “无效键值对”),进行 100 万个实例的初始化测试,经过优化的类反射代码,耗时从原来的 600~800 毫秒,增加到 7000~8000 毫秒,性能下降 10 倍左右。如果增加更多的键值对(不存在对应字段),性能下降更严重。
所以必须进一步完善优化代码。为了加以区分,我们把之前的优化代码称为 V1 版;进一步完善的代码称为 V2 版。
怎么完善?从上面的分析不难找到思路:增加忽略字段(ignore field)缓存。
基类 BaseModel 作如下修改(标红部分是新增或者修改),增加了 ignoreMap:

ignoreMap 的数据结构类似于 setterMap,但第二层不是 HashMap,而是 Set,缓存每个子类需要忽略的键值对的名字,使用 Set 更节约系统资源,如下图所示:

同样的,当 ClassLoader 加载基类的时候,创建 ignoreMap(内容为空):
```null
static {
setterMap = new HashMap<String, Map<String, Method>>();
ignoreMap = new HashMap<String, Set<String>>();
}```
Initialize () 函数作如下改进:
```null
public void initialize() {
String className = this.getClass().getName();
if (setterMap.get(className) == null) setterMap.put(className, new HashMap<String, Method>());
if (ignoreMap.get(className) == null) ignoreMap.put(className, new HashSet<String>());
Map<String, Method> setters = setterMap.get(className);
Set<String> ignores = ignoreMap.get(className);
for (MessageNode node: nodes) {
String sName = node.getName();
try {
if (ignores.contains(sName)) continue;
Method method = setters.get(sName);
if (method == null) {
method = this.getSetter(sName);
setters.put(sName, method);
}
method.invoke(this, node.getValue());
} catch (NoSuchMethodException | SecurityException e) {
log.debug("It's failed to initialize field: {}, reason: {}", sName, e);
ignores.add(sName);
} catch (IllegalAccessException | IllegalArgumentException | InvocationTargetException e) {
log.error("It's failed to initialize field: {}, reason: {}", sName, e);
try {
Method method = this.getSetter(sName);
setters.put(sName, method);
method.invoke(this, node.getValue());
} catch (Exception e1) {
log.debug("It's failed to initialize field: {}, reason: {}", sName, e1);
}
} catch (Exception e) {
log.error("It's failed to initialize field: {}, reason: {}", sName, e);
}
}
}```
虽然代码复杂了一些,但思路很简单:用键值对的名字寻找对应的 setter 时,如果找不到,就把它放进 ignoreMap,下次不再找了。另外还增加了对 setter 引用失效的处理。虽然理论上说 “只要虚拟机不重启,setter 的入口引用永远不会变”,在测试中也从来没有遇到过这种情况,但为了覆盖各种异常情况,还是增加了这段代码。
继续沿用前面的例子,分析改进后的代码的工作流程:
1)第一次执行 initialize () 函数,实例的状态是这样变化的:

因为 fieldX 和 fieldY 字段不存在,找不到它们对应的 setter,它们被放到 ignoreMap 中。
2)再次调用 initialize () 函数的时候,因为检查到 ignoreMap 中存在 fieldX 和 fieldY,这两个键值对被跳过,不再徒劳无功地调用 getMethod ();其它逻辑和 V1 版相同,没有变化。
还是用上面提到的 TestInvoke 类作验证(8 个字段+2 个无效键值对),V2 版本虽然代码更复杂了,但 100 万条纪录的初始化耗时为 600~800 毫秒,V1 版代码这个时候的耗时猛增到 7000~8000 毫秒。哪怕增加更多的无效键值对,V2 版代码耗时增加也不明显,而这种情况下 V1 版代码的效率还会进一步下降。
至此,对 JAVA 类反射代码的优化已经比较完善,覆盖了各种异常情况,如前所述,我们把这个版本称为 V2 版。
第二次迭代:逆向思维
----------
这样就代表优化工作已经做到最好了吗?不是这样的。
仔细观察 V1、V2 版的优化代码,都是循环遍历键值对,用键值对的 name(和字段的名字相同)推算 setter 的函数名,然后去寻找 setter 的入口引用。第一次是调用类反射的 getMethod () 函数,以后是从缓存里面检索,如果存在无效键值对,那就必然出现空转循环,哪怕是 V2 版代码,ignoreMap 也不能避免这种空转循环。虽然单次空转循环耗时非常短,但在无效键值对比较多、负载很大的情况下,依然有无效的资源开销。
如果采用逆向思维,用 setter 去反推、检索键值对,又会如何?
先分析业务场景以及由业务场景所决定的数据结构特点:
* 接口类的字段数量可能大于 setter 函数的数量,因为可能需要一些内部使用的功能性字段,并不是从 xml 报文里解析出来的;
* xml 报文里解析出的键值对和字段是交集关系,多数情况下,键值对的数量包含了接口类的字段,并且大概率存在一些不需要的键值对;
* 相比较字段,setter 函数和需要解析的键值对最接近于一一对应关系,出现空转循环的概率最小;
* 因为接口类编写要遵守 JAVA 编程规范,从 setter 函数的名字反推字段的名字,进而检索键值对,是可行、可靠的。
综上所述,逆向思维用 setter 函数反推、检索键值对,初始化接口类,就是第二次迭代的具体方向。
需要把接口类修改成这样的结构(标红的部分是新增或者修改):


1)为了便于逆向检索键值对,nodes 字段改成 HashMap,key 是键值对的名字、value 是键值对的值。
2)为了提高循环遍历的速度,setterMap 的第二层改成链表,链表的成员是内部类 FieldSetter,结构如下:
```null
private class FieldSetter {
private String name;
private Method method;
public String getName() {
return name;
}
public Method getMethod() {
return method;
}
public void setMethod(Method method) {
this.method = method;
}
public FieldSetter(String name, Method method) {
super();
this.name = name;
this.method = method;
}
}```
setterMap 的第二层继续使用 HashMap 也能实现功能,但循环遍历的效率,HashMap 不如链表,所以我们改用链表。
3)同样的,setterMap 在基类被加载的时候创建(内容为空):
```null
static {
setterMap = new HashMap<String, List<FieldSetter>>();
}```
4)第一次初始化某个接口类的实例时,调用 initSetters () 函数,初始化 setterMap:
```null
protected List<FieldSetter> initSetters() {
String className = this.getClass().getName();
List<FieldSetter> setters = new ArrayList<FieldSetter>();
for (Method method: this.getClass().getMethods()) {
String methodName = method.getName();
if (methodName.startsWith("set")) {
String fieldName = StringUtils.lowerFirstChar(methodName.substring(3));
setters.add(new FieldSetter(fieldName, method));
}
}
setterMap.put(className, setters);
return setters;
}```
5)Initialize () 函数修改为如下逻辑:
```null
public void initialize() {
List<FieldSetter> setters = setterMap.get(this.getClass().getName());
if (setters == null) setters = this.initSetters();
for (FieldSetter setter: setters) {
String fieldName = setter.getName();
String fieldValue = nodes.get(fieldName);
if (StringUtils.isEmpty(fieldValue)) continue;
try {
Method method = setter.getMethod();
method.invoke(this, fieldValue);
} catch (IllegalAccessException | IllegalArgumentException | InvocationTargetException e) {
log.error("It's failed to initialize field: {}, reason: {}", fieldName, e);
try {
Method method = this.getSetter(fieldName);
setter.setMethod(method);
method.invoke(this, fieldValue);
} catch (Exception e1) {
log.debug("It's failed to initialize field: {}, reason: {}", fieldName, e1);
}
} catch (Exception e) {
log.error("It's failed to initialize field: {}, reason: {}", fieldName, e);
}
}
}```
不妨把这版代码称为 V3…… 继续沿用前面 TestInvoke 的例子,分析改进后代码的工作流程:
1)第一次执行 initialize () 函数,实例的状态是这样变化的:

通过 setterMap 反向检索键值对的值,fieldX、fieldY 因为不存在对应的 setter,不会被检索,避免了空转。
2)之后每一次初始化对象实例,都不需要再初始化 setterMap,也不会消耗任何资源去检索 fieldX、fieldY,最大限度地节省资源开销。
3)因为取消了 ignoreMap,取消了 V2 版判断字段是否应该被忽略的逻辑,代码更简洁,也能节约一部分资源。
结果数据显示:用 TestInvoke 测试类、8 个 setter+2 个无效键值对的情况下,进行 100 万 / 10 万个实例两个量级的对比测试,V3 版比 V2 版性能最多提高 10%左右,100 万实例初始化耗时 550~720 毫秒。如果增加无效键值对的数量,性能提高更为明显;没有无效键值对的最理想情况下,V1、V2、V3 版本的代码效率没有明显差别。
至此,用缓存机制优化类反射代码的尝试,已经比较接近最优解了,V3 版本的代码可以视为到目前为止最好的版本。
总结和思考:方法论
---------
总结过去两年围绕着 JAVA 类反射性能优化这个课题,我们所进行的探索和研究,提高到方法论层面,可以提炼出一个分析问题、解决问题的思路和流程,供大家参考:
1)从实践中来
多数情况下,探索和研究的课题并不是坐在书斋里凭空想出来的,而是在实际工作中遇到具体的技术难点,在现实需求的驱动下发现需要研究的问题。
以本文为例,如果不是在对接银行核心系统的时候遇到了大量的、格式奇特的 xml 报文,不会促使我们尝试用类反射技术去优雅地解析报文,也就不会面对类反射代码执行效率低的问题,自然不会有后续的研究成果。
2)拿出手术刀,解剖一只麻雀
在实践中遇到了困难,首先要分析和研究面对的问题,不能着急,要有解剖一只麻雀的精神,抽丝剥茧,把问题的根源找出来。
这个过程中,逻辑分析和实操验证都是必不可少的。没有高屋建瓴的分析,就容易迷失大方向;没有实操验证,大概率会陷入坐而论道、脑补的怪圈。还是那句话:实践是最宝贵的财富,也是验证一切构想的终极考官,是我们认识世界改造世界的力量源泉。但我们也不能陷入庸俗的经验主义,不管怎么说,这个世界的基石是有逻辑的。
回到本文的案例,我们一方面研究 JAVA 内存模型,从理论上探寻类反射代码效率低下的原因;另一方面也在实务层面,用实实在在的时间戳验证了 JAVA 类反射代码的耗时分布。理论和实践的结合,才能让我们找到解决问题的正确方向,二者不可偏废。
3)头脑风暴,勇于创新
分析问题,找到关键点,接下来就是寻找解决方案。JAVA 程序员有一个很大的优势,同时也是很大的劣势:第三方解决方案非常丰富。JAVA 生态比较完善,我们面临的麻烦和问题几乎都有成熟的第三方解决方案,“吃现成的” 是优势也是劣势,很多时候,我们的创造力也因此被扼杀。所以,当面临高价值需求的时候,应该拿出大无畏的勇气,啃硬骨头,做底层和原创的工作。
就本文案例而言,ReflexASM 就是看起来很不错的方案,比传统的类反射代码性能提升了至少三分之一。但是,它真的就是最优解么?我们的实践否定了这一点。JAVA 程序员要有吃苦耐劳、以底层技术为原点解决问题的精神,否则你就会被别人所绑架,失去寻求技术自由空间的机会。**的软件行业已经发展到了这个阶段,提出了这样的需求,我们应该顺应历史潮流。
4)螺旋式发展,波浪式前进
研究问题和解决问题,迭代是非常有效的工作方法。首先,要有精益求精的态度,不断改进,逼近最优方案,迭代必不可少。其次,对于比较复杂的问题,不要追求毕其功于一役,把一个大的目标拆分成不同阶段,分步实施、逐渐推进,这种情况下,迭代更是解决问题的必由之路。
我们解决 JAVA 类反射代码的优化问题,就是经过两次迭代、写了三个版本,才得到最终的结果,逼近了最优解。在迭代的过程中会逐渐发现一些之前忽略的问题,这就是宝贵的经验,这些经验在解决其他技术问题时也能发挥作用。比如 HashMap 的数据结构非常合理、经典,平时使用的时候效率是很高的,如果不是迭代开发、逼近极限的过程,我们又怎么可能发现在循环遍历状态下、它的性能不如链表呢?
行文至此,文章也快要写完了,细心的读者一定会有一个疑问:自始至终,举的例子、类的字段都是 String 类型,类反射代码根本没有考虑 setter 的参数类型不同的情况。确实是这样的,因为我们解决的是银行核心接口报文解析的问题,接口字段全部是 String,没有其它数据类型。
其实,对类反射技术的研究深入到这个程度,解决这个问题、并且维持代码的高效率,易如反掌。比如,给 FieldSetter 类增加一个数据类型的字段,初始化 setterMap 的时候把接口类对应的字段的数据类型解析出来,和 setter 函数的入口一起缓存,类反射调用 setter 时,把参数格式转换一下,就可以了。限于篇幅、这个问题就不展开了,感兴趣的读者可以自己尝试一下。
**版权声明:** 本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《[阿里云开发者社区用户服务协议](https://developer.aliyun.com/article/768092)》和《[阿里云开发者社区知识产权保护指引](https://developer.aliyun.com/article/768093)》。如果您发现本社区中有涉嫌抄袭的内容,填写[侵权投诉表单](https://yida.alibaba-inc.com/o/right)进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
[https://developer.aliyun.com/article/726813](https://developer.aliyun.com/article/726813)
前两天 4S 店保养车子,顺带想给本子清下灰,结果 CPU 风扇给我干稀碎。。。
x 宝紧急下单,45 块包邮。
路上要 3 天,这 3 天又不得不开机,还好强度不大的工作 CPU 温度能稳在 80℃以下,这个真要赞下暗影 4 的热管理设计,西安那几天可是 37 度的高温天呢,临时租的房子又没空调。
暗影 4 的后盖不是很好拆,有点小技巧:
背后螺丝全松掉,8 颗,6 短 2 长。
从下图位置下手比较容易,
把红色线三边都撬开,看拇指位置,从中间往上推,大力出奇迹,但是不要太猛哦
第一步,拆电池!拆电池!拆电池!忘记拍照片了,就 4 颗螺丝锁的,很容易,但很重要,一定要做。
第二步,拆出风口的罩子,红圈 4 颗螺丝卸掉,用小刀轻轻撬起罩子在绿色圈里的定位销部分,向绿色箭头方向往下拉就能拆下来了。
第三步,拆风扇上的罩子,红色圈圈里的螺丝卸掉,把电源线轻轻拿出来,罩子就拆下来了。
正真固定风扇的好像就红圈里 1 颗螺丝,记不清了,真该早点写。按箭头方向把风扇提起来向后拉就行了。风扇电源插头记得拔掉,有胶布的该撕就撕。
换上新的原路装回,10 分钟搞定。
https://blog.csdn.net/tomcash/article/details/118163763
JMM 简介
JMM 即为 JAVA 内存模型(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。
Java 内存模型,就是为了屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。
在 C/C++ 语言中直接使用物理硬件和操作系统内存模型,导致不同平台下并发访问出错。
而 JMM 的出现,能够屏蔽掉各种硬件和操作系统的内存访问差异,实现平台一致性,使得 Java 程序能够一次编写,到处运行。
在 Java JVM 系列文章中有朋友问为什么要 JVM,Java 虚拟机不是已经帮我们处理好了么?
同样,学习 Java 内存模型也有同样的问题,为什么要学习 Java 内存模型。他们的答案是一致的:能够让我们更好的理解底层原理,书写出更好的代码。
就 Java 内存模型而言,它是深入了解 Java 并发编程的先决条件。往后对于多线程中的线程安全、同步异步处理高难度的操作更是有大大的帮助。
Java 内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样底层细节。
此处的变量与 Java 编程时所说的变量不一样,指包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数,后者是线程私有的,不会被共享。
JMM 规定了内存主要划分为主内存和工作内存两种。此处的主内存和工作内存跟 JVM 内存划分(堆、栈、方法区)是在不同的层次上进行的。
如果非要对应起来,主内存对应的是 Java 堆中的对象实例部分,工作内存对应的是栈中的部分区域。
从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
JMM 在设计时候考虑到,如果 JAVA 线程每次读取和写入变量都直接操作主内存,对性能影响比较大,所以每条线程拥有各自的工作内存。
JMM 中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面讲的处理器的高速缓存类比)。
线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的**所有操作(读取、赋值)**都必须在工作内存中进行,而不能直接读写主内存中的变量。
不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成。
但是这样就会出现一个问题,当一个线程修改了自己工作内存中变量,对其他线程是不可见的,会导致线程不安全的问题。
因此 JMM 制定了一套标准来保证开发者在编写多线程程序的时候,能够控制什么时候内存会被同步给其他线程。
线程、主内存和工作内存的交互关系如下所示:
JMM 中规定内存交互操作有 8 种,每种操作都有自己作用的的区域,具体操作如下:
JMM 中的 8 中操作规定了线程对主内存的操作过程,隐式的规定:线程之间要通信必须通过主内存,JMM 的线程通信如下:
从上图来看,线程 A 与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
要把一个变量从主内存中复制到工作内存,就需要按顺序地执行 read 和 load 操作,如果把变量从工作内存中同步回主内存中,就要按顺序地执行 store 和 write 操作。
Java 内存模型只要求上述两个操作必须按顺序执行,而没有保证必须是连续执行。也就是 read 和 load 之间,store 和 write 之间是可以插入其他指令的。
Java 内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
在这里插入图片描述
1、现代计算机系统在存储设备与处理器之间加了一层读写速度尽可能解决处理器运算速度的高速缓存来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写. 2、缓存一致性问题:在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一组内存,当多个处理器的运算任务都涉及到同一个块主内存区域时,将可能导致各自的缓存数据不一致.
现代的处理器使用写缓冲区来临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。
同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。
这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读 / 写操作的执行顺序,不一定与内存实际发生的读 / 写操作顺序一致!为了具体说明,请看下面示例:
假设处理器 A 和处理器 B 按程序的顺序并行执行内存访问,最终却可能得到 x = y = 0 的结果。具体的原因如下图所示:
这里处理器 A 和处理器 B 可以同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3,B3)。当以这种时序执行时,程序就可以得到 x = y = 0 的结果。
从内存操作实际发生的顺序来看,直到处理器 A 执行 A3 来刷新自己的写缓存区,写操作 A1 才算真正执行了。虽然处理器 A 执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,处理器 A 的内存操作顺序被重排序了。
这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写 - 读操作重排序。
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
在这里插入图片描述
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
从 JDK5 开始,java 使用新的 JSR -133 内存模型(本文除非特别说明,针对的都是 JSR- 133 内存模型)。JSR-133 提出了 happens-before 的概念,通过这个概念来阐述操作之间的内存可见性。
如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。与程序员密切相关的 happens-before 规则如下:
注意,两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。
happens-before 与 JMM 的关系如下图所示:
从 Java 源代码到最终实际执行的指令序列,会经过三种重排序。但是,为了保证内存的可见性,Java 编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。
在 Java 中提供了一系列和并发处理相关的关键字,比如 volatile、synchronized、final、concurrent 包等解决原子性、有序性和可见性三大问题。
其实这些就是 Java 内存模型封装了底层的实现后提供给程序员使用的一些关键字。
在开发多线程的代码的时候,我们可以直接使用 synchronized 等关键字来控制并发,从来就不需要关心底层的编译器优化、缓存一致性等问题。
线程切换带来的原子性问题:我们把一个或者多个操作在 CPU 执行的过程中不能被中断的特性称之为原子性,这里说的是 CPU 指令级别的原子性。在。
Java 中,为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit。这两个字节码,在 Java 中对应的关键字就是 synchronized。
因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。
缓存导致的可见性问题:一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称之为可见性。
JMM 是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值的这种依赖主内存作为传递媒介的方式来实现的。
Java 中的 volatile 关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次使用之前都从主内存刷新。因此,可以使用 volatile 来保证多线程操作时变量的可见性。
除了 volatile,Java 中的 synchronized 和 final 两个关键字也可以实现可见性。
编译优化带来的有序性问题:有序性指的是程序要按照代码的先后顺序执行,编译器为了优化性能,有时候会改变程序中语句的先后顺序。
在 Java 中,可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。实现方式有所区别:
volatile 关键字会禁止指令重排。synchronized 关键字保证同一时刻只允许一条线程操作。
好了,这里简单的介绍完了 Java 并发编程中解决原子性、可见性以及有序性可以使用的关键字。读者可能发现了,好像 synchronized 关键字是万能的,它可以同时满足以上三种特性,这其实也是很多人滥用 synchronized 的原因。
但是 synchronized 是比较影响性能的,虽然编译器提供了很多锁优化技术,但是也不建议过度使用。
来源:https://mp.weixin.qq.com/s/EDGREpwwip6GwcO6WCdVLA
https://zhuanlan.zhihu.com/p/136623445
我们总是讨论没有对象就去 new 一个对象,创建对象的方式在我这里变成了根深蒂固的 new 方式创建,但是其实创建对象的方式还是有很多种的,不单单有 new 方式创建对象,还有使用反射机制创建对象,使用 clone 方法去创建对象,通过序列化和反序列化的方式去创建对象。这里就总结一下创建对象的几种方式,来好好学习一下 java 创建对象的方式。
这是我们最常见的也是最简单的创建对象的方式,通过这种方式我们还可以调用任意的构造函数(无参的和有参的)。
例如:
User user = new User();```
运用反射手段,调用 Java.lang.Class 或者 java.lang.reflect.Constructor 类的 newInstance () 实例方法。
**1 使用 Class 类的 newInstance 方法**
--------------------------------
可以使用 Class 类的 newInstance 方法创建对象。这个 newInstance 方法调用无参的构造函数创建对象。
```null
//创建方法1
User user = (User)Class.forName("根路径.User").newInstance()
//创建方法2(用这个最好)
User user = User.class.newInstance()```
**2 使用 Constructor 类的 newInstance 方法**
--------------------------------------
和 Class 类的 newInstance 方法很像, java.lang.reflect.Constructor 类里也有一个 newInstance 方法可以创建对象。我们可以通过这个 newInstance 方法调用有参数的和私有的构造函数。
```null
Constructor<User> constructor = User.class.getConstructor();
User user = constructor.newInstance();```
这两种 newInstance 方法就是大家所说的反射。事实上 Class 的 newInstance 方法内部调用 Constructor 的 newInstance 方法。
无论何时我们调用一个对象的 clone 方法,jvm 就会创建一个新的对象,将前面对象的内容全部拷贝进去。用 clone 方法创建对象并不会调用任何构造函数。
要使用 clone 方法,我们需要先实现 Cloneable 接口并实现其定义的 clone 方法。
```null
public class CloneTest implements Cloneable{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public CloneTest(String name, int age) {
super();
this.name = name;
this.age = age;
}
public static void main(String[] args) {
try {
CloneTest cloneTest = new CloneTest("wangql",18);
CloneTest copyClone = (CloneTest) cloneTest.clone();
System.out.println("newclone:"+cloneTest.getName());
System.out.println("copyClone:"+copyClone.getName());
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}```
执行
```null
newclone:wangql
copyClone:wangql```
当我们序列化和反序列化一个对象,jvm 会给我们创建一个单独的对象。在反序列化时,jvm 创建对象并不会调用任何构造函数。
为了反序列化一个对象,我们需要让我们的类实现 Serializable 接口。
学习文章:[Java 对象的序列化与反序列化](http://www.importnew.com/17964.html)
对象的序列化和反序列化涉及的东西比较多,等补充后再总结。
参考文章:
[java 中创建对象的方法](http://blog.csdn.net/mhmyqn/article/details/7943411)
[Java 中创建对象的 5 种方式](http://www.cnblogs.com/wxd0108/p/5685817.html)
[Java 中创建对象的几种方式](http://www.cnblogs.com/baizhanshi/p/5896092.html)
[JAVA 中创建对象的四种方式](http://www.cnblogs.com/draem0507/archive/2013/01/17/2864554.html)
[https://blog.csdn.net/w410589502/article/details/56489294](https://blog.csdn.net/w410589502/article/details/56489294)
服务端编程需要构建高性能的 IO 模型,常见的 IO 模型主要有以下四种
同步与异步 用户线程与内核的交互方式;同步是指用户发起 IO 请求后,需要等待或者轮询内核 IO 操作完成后才能继续执行;异步是指用户线程发起 IO 请求后继续执行,当内核操作完成后会通知线程或者调用用户线程注册的回调函数
阻塞与非阻塞 用户线程调用内核 IO 操作的方式;阻塞是指 IO 操作需要彻底完成后才返回到用户空间,而非阻塞是指 IO 操作被调用后立即返回给用户一个状态值
用户线程通过系统调用 read 发起 IO 操作,由用户空间转到内核空间,内核等到数据包到达以后,将接受的数据拷贝到用户空间,完成 read,用户需要等待 read 将 socket 中的数据读取到 buffer 后,才继续处理接收的数据,整个 IO 请求过程中,用户线程是被阻塞的,导致用户发起请求时,不能做任何事情,对 CPU 资源利用不够。
同步非阻塞 io,在同步阻塞 io 的基础上,将 socket 设置为 nonblock,用户线程可以在发起 io 请求后立即返回;socket 是非阻塞的方式,用户线程发起 IO 请求时立即返回,但并未读取到任何数据,用户线程需要不断发起 IO 请求,直到数据到达后,才真正读取到数据,继续执行;在整个 IO 请求的过程中,虽然用户线程每次发起 IO 请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求、消耗大量 CPU 资源,一般很少使用这种模型,而是在其他 IO 模型中使用非阻塞 IO
IO 多路复用,是建立在内核上提供的多路分离函数 select 基础之上的,使用 select 函数可以避免同步非阻塞 IO 模型中轮询等待的问题;用户将需要进行 IO 操作的 socket 添加到 select 中,然后阻塞等待 select 系统调用返回。当数据到达时,socket 被激活,select 函数返回,用户线程发起 read 请求,读取数据并继续执行。使用 select 函数进行 IO 请求与同步阻塞模型并无太大区别,甚至多添加监视 socket,select 函数额外操作,使用优势主要在于用户可以在一个线程内同时处理多个 socket 的 IO 请求,用户可以注册多个 socket,然后不断调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的,同步阻塞模型中,必须使用多线程。
使用 select 允许单线程内处理多个 IO 请求,但是每个 IO 请求的过程还是阻塞的,平均时间甚至比同步阻塞 IO 模型还要长,IO 多路复用模型使用 Reactor 设计模式实现了这一机制,用户线程只注册自己感兴趣的 socket 或者 IO 请求,去做自己的事情,等到数据到来时再进行处理,可以提高 cpu 利用率;EventHandler 抽象类表示 IO 事件处理器,拥有 IO 句柄 get-handle,以及对 Handle 的操作 handle-event,继承于 EventHandler 的子类可以对事件处理器的行为进行定制,Reactor 类用于管理 EventHandler 注册、删除,并使用 handle-events 实现事件循环,不断调用内核中的多路分离函数 select,只要某个文件句柄被激活,select 就返回,就会调用 handle-event 事件处理器进行操作。
通过 reactor 的方式,将用户线程轮询 IO 操作状态的工作交给 handle-even 进行处理,用户线程进行事件注册之后进行其他工作(异步),而 reactor 线程负责调用内核 select 函数,当存在 socket 被激活时,通知相应的用户线程,执行 handle-event 进行数据读取、处理工作,由于 select 函数是阻塞的,所以多路 IO 复用也被称为异步阻塞 IO 模型,socket 是不被阻塞的,用户发起 IO 请求时,数据已经到达,用户线程一定不会被阻塞。其使用会阻塞线程的 select 系统调用,因此 IO 多路复用只能称为异步阻塞 IO,而非真正的异步 IO。
真正的异步 IO,需要操作系统更强的支持,在 IO 多路复用中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据,而在异步 IO 模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在用户线程指定的缓冲区内,内核在 IO 完成后通知用户线程直接使用即可。异步模型使用 Proactor 设计模式实现这一机制。
Proactor 和 Reactor 模式在结构上比较相似,在 Client 使用方式上差别较大,Proactor 模式中,用户线程将 AO、Proactor 以及操作完成时的 CompletionHandler 注册到 AOP。AOP 使用 Facade 模式提供一组异步操作 API 供用户使用,当用户线程调用异步 API 后,便执行自己的任务。AOP 会开启独立的内核线程执行异步操作,当异步 IO 完成时,AOP 将用户线程与 AOP 一起注册的 Proactor 和 CompletionHandler 取出,然后将 CompletionHandler 与 IO 操作的结果一致转发给 Proactor,Proactor 负责回调每一个异步操作事件完成处理函数 handle-event,Proactor 模式中每个异步操作都可以绑定一个 proactor 对象,一般操作系统中 Proactor 为单例模式,以便集中化分发操作完成事件。
异步 IO 模型中,用户线程直接使用内核提供的异步 IO API 发起 read 请求,发起后立即返回,继续执行用户线程代码。此时用户线程已经将调用的 AO 与 CH 注册到了内核,然后操作系统开启独立的内核线程去处理 IO 操作。当 read 请求的数据到达时,由内核负责读取 socket 中的数据,并写入用户指定的缓冲区中。最后内核将 read 的数据和用户线程注册的 CH 分发给内部 Proactor,Proactor 将 IO 完成的信息通知给用户线程,完成异步 IO。
异步 IO 并不常见,高性能并发服务程序,使用 IO 多路复用模型 + 多线程任务处理的架构基本可以满足要求,目前操作系统对异步 IO 的支持并非特别完善,更多的是采用 IO 多路复用模型模拟异步 IO 的方式,IO 事件触发时不直接通知用户线程,而是将数据读写完毕后放到用户指定的缓冲区中。
https://www.cnblogs.com/jianzihao/p/14814838.html
最近在使用最新版本的 nacos 和 feign 的过程中,启动时遇到一个错误:
Caused by: java.lang.IllegalStateException: No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalancer?
百思不得其解,之前的 spring cloud 版本没有遇到这样的问题。花了将近几个小时,终于解决,记录一下,希望能给大家带来一点帮助。
项目中的父 pom 文件版本依赖管理如下:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.4</version>
</parent>
<properties>
<spring-cloud.version>2020.0.2</spring-cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
用的是最新版本的 springboot 和 springcloud,然后在子项目中,我用到了 feign 和 nacos,依赖如下:
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
</dependencies>
第一时间想到的,spring cloud 和 springboot 版本不兼容。查看 spring cloud 官网,发现 spring boot 版本号和 spring cloud 版本号可以对应:
说明项目是没问题的,就上网查找了一下,结果参考了这两位仁兄说的:
在项目中加入 eureka 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
再次启动,报错:
Field autoServiceRegistration in org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationAutoConfiguration required a single bean, but 2 were found:
- nacosAutoServiceRegistration: defined by method 'nacosAutoServiceRegistration' in class path resource [com/alibaba/cloud/nacos/registry/NacosServiceRegistryAutoConfiguration.class]
- eurekaAutoServiceRegistration: defined by method 'eurekaAutoServiceRegistration' in class path resource [org/springframework/cloud/netflix/eureka/EurekaClientAutoConfiguration.class]
Action:
Consider marking one of the beans as @Primary, updating the consumer to accept multiple beans, or using @Qualifier to identify the bean that should be consumed
这是因为项目中已经用到了 nacos,再次引入 eureka,会造成有两个注册中心的问题,说明这种解决方案无效。
既然之前的版本没问题,那我就降级回去不就完事了,于是乎,我把项目的父 pom 中 spring cloud 版本降级到 Hoxton SR1,spring boot 版本也随之降级到 2.2.1,即:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
maven clean 后再次启动,仍然报错:
错误信息:
Caused by: java.lang.IllegalStateException: No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalancer?
at org.springframework.cloud.openfeign.FeignClientFactoryBean.loadBalance(FeignClientFactoryBean.java:333) ~[spring-cloud-openfeign-core-3.0.2.jar:3.0.2]
at org.springframework.cloud.openfeign.FeignClientFactoryBean.getTarget(FeignClientFactoryBean.java:360) ~[spring-cloud-openfeign-core-3.0.2.jar:3.0.2]
at org.springframework.cloud.openfeign.FeignClientFactoryBean.getObject(FeignClientFactoryBean.java:339) ~[spring-cloud-openfeign-core-3.0.2.jar:3.0.2]
at org.springframework.cloud.openfeign.FeignClientsRegistrar.lambda$registerFeignClient$0(FeignClientsRegistrar.java:230) ~[spring-cloud-openfeign-core-3.0.2.jar:3.0.2]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.obtainFromSupplier(AbstractAutowireCapableBeanFactory.java:1231) ~[spring-beans-5.3.5.jar:5.3.5]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1173) ~[spring-beans-5.3.5.jar:5.3.5]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:564) ~[spring-beans-5.3.5.jar:5.3.5]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:524) ~[spring-beans-5.3.5.jar:5.3.5]
... 34 common frames omitted
这次的错误信息跟第一次一样,可见降低版本这事已经行不通了,于是我复原了父 pom。
在 stackoverflow 上看到了这两种解决方案:
因为不想在 feign 上加 url,显得比较麻烦,于是我选择了第二种方案,加 ribbon 并配置了相关属性,启动还是报错:
Caused by: java.lang.IllegalStateException: No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalancer?
但是其中的第一种方案,我还是有点感兴趣,于是就根据第一种方案中的关键字 spring-cloud-loadbalancer,搜索了一下。
继续搜索,发现如下结果:
根据这位大佬的说法,这是因为:
由于 SpringCloud Feign 在 Hoxton.M2 RELEASED 版本之后不再使用 Ribbon 而是使用 spring-cloud-loadbalancer,所以不引入 spring-cloud-loadbalancer 会报错
解决方法
加入 spring-cloud-loadbalancer 依赖 并且在 nacos 中排除 ribbon 依赖,不然 loadbalancer 无效
问题突然有了点头目,于是乎,加入如下依赖:
//我是在这引入了spring-cloud-starter-alibaba-nacos-discovery
<dependency>
<groupId>com.oyz.gulimall</groupId>
<artifactId>gulimall-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</exclusion>
</exclusions>
</dependency>
//加入spring-cloud-loadbalancer依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-loadbalancer</artifactId>
</dependency>
之后,再次启动项目:
问题完美解决,还是得关注问题报错点:Did you forget to include spring-cloud-starter-loadbalancer,一开始没有注意到这个点,浪费了许多时间。
某一天逛网上帖子的时候,突然发现了下面这一篇文章,但是着实没有想到一篇文章能牵扯出这么多东西,这篇文章介绍的是由于使用了 JDK 的线程池引发的一个 BUG,牵扯到了 GC 和方法内联的优化对于代码运行产生的影响,线程池 BUG 在 JDK8 中就已经存在但是直到 JDK11 才被修复,这里在原文的基础上补充相关的知识点,算是给自己做一个笔记。
这里先说明一下这篇文章的相关知识点直接进行一个总结,如果读者对于相关内容十分熟悉的话这里也不浪费各位的时间,可以直接关闭本文了(哈哈)
Executors.newSingleThreadExecutor 中通过 finalize () 方式回收资源导致线程池提前回收的 BUG。Executors.newSingleThreadExecutor().submit(runnable) 方法会抛出异常的讨论(参考下方资料第四条),但是直到 JDK11 才进行修复。 下面这些参考资料都是十分优质,花不多的时间就能有很大的收获,特别是 R 大的回答,简直就是移动的百科全书,赞。
Java 中,为什么一个对象的实例方法在执行完成之前其对象可以被 GC 回收?(必读)
Can java finalize an object when it is still in scope?
Executors.newSingleThreadExecutor().submit(runnable) throws RejectedExecutionException
JVM Anatomy Quark #8: Local Variable Reachability
这里有点同情写 Executors.newSingleThreadExecutor(); 这个方法的老哥了,网上的文章基本都要拿他写的代码来反复鞭尸(当然 JDK 官方错误使用 finalize () 确实不应该),这里我也不客气也要来鞭尸一番,为了分析这些内容我们必须要了解源代码怎么写的。这里先给一下个人参考各种资料之后得出的结论:
Executors.newSingleThreadExecutor(); 在 Jdk1.8 中存在较大的隐患,当线程调用执行完成的同时如果此时线程对象的 this 引用没有发挥作用的时候,此时 JIT 优化和方法内联会提前判定当前的对象已死,GC 会立马将对象资源释放,导致偶发性的线程池调用失败抛出拒绝访问异常。finalize也可能会被执行,本质上由于 JIT 优化以及方法中的对象生命周期并不是直到方法执行结束才会结束,而是有可能提前结束生命周期。Executors.newSingleThreadExecutor 的实现里通过 finalize 来自动关闭线程池的做法是有 Bug 的,在经过优化后可能会导致线程池的提前 shutdown 从而导致异常。 下面我们一步步来解释这个 BUG 的来源,以及相关的知识点,最后我们再讲讲如何规避这个问题。
JDK 版本:代码异常是在 HotSpot java8 (1.8.0_221) 模拟情况中出现的(实际上直到 jdk11 才被正式修复)。
下面我们从原文直接介绍一下这个线程池的 BUG 带来的奇怪现象。
问题:线上偶发线程池的问题,线程池执行带有返回结果的任务,但是发现被拒绝执行。
复制代码 隐藏代码ava.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@a5acd19 rejected from java.util.concurrent.ThreadPoolExecutor@30890a38[Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 0]
原因分析:线程池中的线程被提前回收,下面给出一段模拟线程池的操作代码,在模拟代码中虽然 futureTask 显然是在线程池里面,同时按照正常的理解思路线程池对象肯定是在栈帧中存活的,但是实际上对象却在方法执行的周期内直接被 GC 线程给回收了,导致了 “拒绝访问” 的 BUG(也就是出现了线程池关了,内部的任务却还在执行的情况):
复制代码 隐藏代码`public class ThreadPoolTest {
public static void main(String[] args) {
final ThreadPoolTest threadPoolTest = new ThreadPoolTest();
for (int i = 0; i < 8; i++) {
new Thread(new Runnable() {
@OverRide
public void run() {
while (true) {
Future future = threadPoolTest.submit();
try {String s = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
}
}
}).start();
}
new Thread(new Runnable() {
@OverRide
public void run() {
while (true) {
System.gc();
}
}
}).start();
}
public Future submit() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
FutureTask futureTask = new FutureTask(new Callable() {
@OverRide
public Object call() throws Exception {
Thread.sleep(50);
return System.currentTimeMillis() + "";
}
});
executorService.execute(futureTask);
return futureTask;
}
}`
个人的运行情况和原文不太一样,有时候是刚跑起来直接抛出异常,有时候在执行几秒之后才报错,所以这一段代码在不同电脑上呈现的效果是不太一样的,但是可以确定的是 JDK 的写法是存在 BUG 的。
对于上面的代码,我们要如何验证 JIT 编辑器提前结束对象生命周期?这里我们接着引申一下,这里摘录了 Stackflow 中的一篇文章,来验证一下 JIT 优化的导致对象提前结束生命周期的一个理解案例。这篇文章的老哥提了一个很有意思的问题,原文问的是 Can java finalize an object when it is still in scope? 也就是当对象依然在栈帧里面对象会提前结束生命周期么?这里我们挑回答中给的一个测试代码进行分析。
复制代码 隐藏代码`public class FinalizeTest {
@OverRide
protected void finalize() {System.out.println(this + "was finalized!");
}
public static void main(String[] args) {
FinalizeTest a = new FinalizeTest();
System.out.println("Created" + a);
for (int i = 0; i < 1_000_000_000; i++) {
if (i % 1_000_000 == 0)
System.gc();
}
}
}`
在上面这一段代码中,如果把最后一行注释,发现在进行 GC 的时候,虽然 A 这时候应该还是存在于 main 的栈帧中,可以看到如果不放开注释出现了很奇怪的现象那就是对象 a 被提前终止生命周期了,这也就导致和前文一样的现象,对象在方法块内提前结束了自己的生命周期,或者换个角度说由于垃圾收集线程的切换,此时发现 a 已经没有任何 this 引用被释放掉内存。当然如果我们加上被注释这段代码的效果就比较符合预期了,对象 a 的生命周期被保住了直到整个程序运行完成,这里就引出了一个结论:当对象仍存在于作用域(stack frame)时,finalize 也可能会被执行。
那么为什么会出现上面的奇怪现象呢?在原文中讨论的是 toString() 方法的底层是否会延长对象的生命周期,其实这是一种和 JIT 优化对抗的处理方式,使用打印语句将 a 的生命周期延长到方法出栈,这样就不会出现 for 循环执行到一半对象 a 却提前 “死掉” 的情况了。在 JIT 的优化中,上面的代码中的对象 A 被认为是不可达对象所以被回收,这种优化和我们长久的编程习惯可能会背道而驰,作为编程人员来说我们总是希望对象的生命周期能坚持到方法完成,但是实际上 JIT 和方法内联会尽可能的回收不可达的对象,下面我们就来了解一下什么是方法内联。
在结论中讲述了内联优化代码的情况,下面我们来看一下《深入理解 JVM 虚拟机》是如何介绍方法内联的,方法内联简单的理解就是我们常说的消灭方法的嵌套,尽量让代码 “合并” 到一个方法体中执行,这样做最直观的体现就是可以减少栈帧的入栈出栈操作,我们都知道虽然程序计数器不会内存溢出,但是虚拟机栈的大小是有限的,并且在 JDK5 之后每一个线程具备的虚拟机栈大小默认为 1M,显然减少入栈和出栈的次数是一种 “积少成多” 的优化方式,也是能直观并且显著的提升效率的一种优化手段。
为了更好理解方法内联,这里我们举一个案例,下面的方法是有可能进行方法内联的:
复制代码 隐藏代码`public int add(int a, int b , int c, int d){
return add(a, b) + add(c, d);
}
public int add(int a, int b){
return a + b;
}`
值得注意的是只有使用 invokespecial 指令调用的私有方法、实例构造器、父类方法和使用 invokestatic 指令调用的静态方法才会被方法内联,也就是说如果可以话我们还是尽量把方法设置为 private、static、final,特别是静态方法可以直接内联到一个代码块。除此之外大部分的实例方法都是无法被内联的,因为他设计的是分派和多态的选择,并且由于 java 是一门面向对象的语言,最基本的方法函数就是虚方法,所以对虚方法的内联是一个难题。
小贴士:
非虚方法:如果方法在编译期就确定了具体的调用版本,这个版本在运行时是不变的,这样的方法称为非虚方法。
虚方法:静态方法、私有方法、final 方法、实例构造器、父类方法都是非虚方法。
顺带一提是方法内联绝对不是在代码中完成的,其实仔细想想也是可以理解,如果在代码里面完成方法的合并那么原有的逻辑就乱套了,所以为了解决上面这一系列问题 Java 的虚拟机首先引入叫做类型继承关系分析(class Hierarchy Analysis CHA)技术,个人理解这种优化方式为 “富贵险中求”,主要是分析某个类的继承树以及重写或者重写方法的信息,如果发现是非虚的方法,直接内联就可以了,但是如果是虚方法,则对于当前的方法进行检查,如果检查到 “可能” 只有一个版本尼玛就可以假设这一段代码就是它最终完成的样子,这种方法也被叫做 “守护内联”,当然由于 Java 动态连接的特性还有代理等情况,所以这种守护内联的方式最终是要留下逃生门的,一旦这样的激进优化出现失败或者异常,则需要马上切回到纯解析的模式进行工作。
吐槽:这种优化方式有点像考试作弊,老师没有发现就能一直瞄一直抄,效率提升 200%,但是一旦被老师发现,哼哼,成绩不仅全部作废,你还要单独安排到一个教室全部重考!所以作弊是富贵险中求呀。
当然这种激进优化一旦出问题并不是马上就放弃优化,这时候还有一个技术叫做 “内联缓存”,内联缓存 大致的工作原理如下:
以上就是方法内联干的一些事情,既然了解了方法内联和 JIT 优化
虽然我们通过一系列的手段排查发现了一个 GC 中隐藏的 “漏洞”,但是我们可以发现这其实归根结底是 JDK 代码的 BUG 导致了这一系列奇怪的问题产生,下面我们回过头来简单分析一下这个 BUG,下面是 JDK 源代码:
复制代码 隐藏代码 public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); }
这个方法的 JavaDoc 的描述如下(英语水平有限,直接把 API 文档拿来机翻了):
创建一个执行器,它使用单个工作线程操作无界队列,并在需要时使用提供的 ThreadFactory 创建一个新线程。 与其等效的 {@code newFixedThreadPool (1, threadFactory)} 不同,返回的实例并不能保证给其他的线程使用,其实从名字也可以看出,这里就是新建一个单线程的线程池。
这里可以看到 FinalizableDelegatedExecutorService 这个类重写了 finalize 方法,并且实际上内部调用的是一个包装器对象的终结方法,这样也就是一切奇怪现象的 “罪魁祸首” 了:
复制代码 隐藏代码` public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
static class FinalizableDelegatedExecutorService
extends DelegatedExecutorService {FinalizableDelegatedExecutorService(ExecutorService executor) {
super(executor);
}
protected void finalize() {super.shutdown();
}
}`
关于 finalize 的相关细节会在下文进行总结,这里稍安毋躁,在代码中可以看到 newSingleThreadExecutor 返回的是一个包装类而不是本身,所以它是通过调用包装类的的顶级接口的 super.shutdown(); 进行资源关闭的,同时 super.shutdown(); 的动作是在终结方法里面完成,其实可以看到代码本身的意图是好的,让线程池在不再使用的情况下保证随着 GC 会进行回收。但是其实只要稍微了解 finalize 的同学就应该清楚,抛开 JIT 和方法内联不谈这种写法的代码本身执行结果就是 “不确定” 的,因为 finalize 执行取决于垃圾收集器的实现,同时他也不一定会调用(比如 main 线程刚执行完成就 exits 了),所以如果对象的生命周期和作用域控制不当就会在垃圾收集线程 GC 的时候出现 this 引用丢失提前回收问题(当然这里是多线程切换导致的 GC)。
此时我们可以回顾一下之前原文中的测试代码,线程池在开启之后他看上去好像就没有在干活了(实际上内部有线程对象在执行任务),显然这里想要利用 finalize () 作为 “安全网” 进行线程资源的回收的手段有失偏颇,最后这个关于 JDK 的线程池 BUG 是在 JDK11 修复的,他的处理代码如下:
复制代码 隐藏代码JUC Executors.FinalizableDelegatedExecutorService public void execute(Runnable command) { try { e.execute(command); } finally { reachabilityFence(this); } }
提示:当然还有一种方法是在代码中手动执行一下关闭线程池,也可以规避 JIT 优化带来的奇怪现象。
如何解决上面的问题以及如何和 JIT 和方法内联对抗?以 JDK9 为界的两种方法(技巧),JDK 官方给出这种解决办法也说明了目前情况下不会对于这种 JIT 优化做兜底处理,意思就是说不能让编译优化器去配合你的代码工作,而是要让你的代码可以符合预期行为,个人来看其实四个字:关我屁事。
在 Java 9 里只要加上一个 reachabilityFence () 调用就没事了
复制代码 隐藏代码Reference.reachabilityFence(executor);
JDK8 以及之前的版本中则需要 手动调用的方式让对象不会因为线程切换 this 引用被 GC 误判为不可达:
复制代码 隐藏代码executor.shutdown();
其实通篇看下来发现最后好像有点实际技巧和理论的东西好像就这两个方法。NONONO,软件的领域有一句话说的好,叫做知其然知其所以然,如果我们以为的选择去知其然那么很有可能沦为 “代码工具人” 而不是一个会认真思考的程序员。
下面我们再挖掘一下终结方法的使用和细节,这些教条在《effective Java》这本神书里面介绍了,所以我们直接从书中的内容进行总结吧。
try - final 的方式进行处理,在学习基础的时候我们都知道 final 语句是必然会执行的,也可以保证 this 引用直到 final 执行完成才被释放引用。 其实阿里巴巴的手册很早之前就禁止使用 Executors 去创建线程,现在看来这里其实隐藏着另一个陷阱,那就是 SingleThreadPool 重写了 finalize 方法可能因为 JIT 优化和方法内联而进坑里面,也算是不使用的一个理由吧。
下面是手册的介绍,这里直接贴过来了:
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
1) FixedThreadPool 和 SingleThreadPool : 允许的请求队列长度为 Integer.MAX_VALUE ,可能会堆积大量的请求,从而导致 OOM 。
2) CachedThreadPool 和 ScheduledThreadPool : 允许的创建线程数量为 Integer.MAX_VALUE ,可能会创建大量的线程,从而导致 OOM
(感兴趣的同学可以翻翻手册的 “并发” 部分,在靠前的几条就有介绍(说明翻车的人还挺多?))
我们结合《effective Java》中的第八条了解一下终结方法是什么,这里会介绍终结方法的各种使用方法和隐患,以及如果重写 finalize () 在 GC 中会产生什么变化。
finalize() 在垃圾回收确定不再有对对象的引用时执行。finalize() 并不是保证被调用的,所以不会出现因为内存清理的操作导致 OOM。 这里也是从 R 大的回答里总结过来的,真可谓听君一席话,胜读十年书。对于一个对象来说我们需要区分重写 finalize () 和不重写 finalize (),如果不重写 finalize (),其实对象的生命周期只有一次,也就是一旦 GC 对象是不会经过 finalize () 直接进行回收的,这和《深入理解 JVM 虚拟机》中是有出入的(书中介绍的是对象经历 GC 至少需要两次考验,其实不重写 finalize () 一次考验就挂了),但是如果重写了 finalize (),那么此时对象从失去强引用到真正被 GC 回收会经历两次 GC,重写过 finalize () 的方法的对象的时候虚拟机会对这个对象做特殊处理, 把他放入一个 finalize () 的低优先级特殊队列,在 GC 的时候如果通过队列判断当前对象是一个不可达对象,如果是则会进行回收的操作。
finalizers 的一个潜在严重问题在终结的时候如果抛出未被捕获的异常,该对象的总结过程也会一并终止,并且此时对象会进入 broken 状态,如果此时这个对象被另一个对象使用,会出现不确定的行为,正常情况下未被捕获的异常基本会被 Jvm 捕获最终强制终止线程,并且打印堆栈,但是如果异常在终结方法中则完全报不出错来。清除方法虽然没有问题,但是清除方法有一个和 finalize 一样的性能问题。
另一个问题是终结方法和清除方法一样存在很严重的性能问题,经过测试发现使用 jdk7 的 AutoCLoseable 接口和 try-catch-resources,比增加一个终结方法要快上 50 倍,虽然使用清除方法清除类的实例比终结方法要快一些,但是也是五十步笑百步的区别。
清除方法:
最后终结方法有严重的安全问题,那就是终结方法攻击,如果一个异常在构造方法或它的序列化等价方法 - readObject () 和 readResolve () 方法抛出,虽然构造方法可以正常抛出异常并且提前结束线程的生命周期,但是对于终结方法并不是如此,终结方法可以在静态字段中记录对象的引用,防止被垃圾回收,同时一旦被记录异常,那么就可以调用任何原本不应该允许出现的方法,所以从构造器抛出异常虽然足以阻止对象存活,但是对于终结方法来说,这一点无法实现。
为了解决这个问题,最终建议的方法是重写一个空的并且为 final 的终结方法。同时如果想要让类似文件或者数据库的资源自动回收,最好的方式是实现 jdk7 之后提供的 autoClosed 接口,然后使用 try-catch-resources 自动关闭资源,即使遇到异常也会自动回收对象。和终结的漏洞不同的是,使用 autoclosed 必须记录自己是否关闭,同时如果资源是在被回收之后调用的,则必须要检查这个标记,最终抛出 java.lang.IllegalStateException 异常。
如果需要重写 finalize 需要注意下面的事项。
finalize 当然并不是完全一无是处,因为在 java 中确实有不少常见的类进行使用,所以有必要介绍一下他的正确方法,当然还是建议读者不要去触碰使用终结方法和避免使用清除对象 Cleaner,即使终结方法能发挥一定作用,也很容易不正确的使用导致上面提到一些问题,有的问题甚至会导致对象被污染攻击,所以需要十分小心。下面来看一下终结方法有哪些用途:
终结的第一个用途,是作为资源释放的一个安全网,保证客户端在无法正确操作的情况下依然可以用一道安全网作为资源释放的兜底,但是需要考虑这样使用的代价,下面我们从 fileInputStream 类的终结方法看一下它是如何安全使用的。从下面的代码可以看到,如果当前被释放的资源不为 Null 并且不是 System#in 控制流的时候就释放资源。
复制代码 隐藏代码 `protected void finalize() throws IOException {if ((fd != null) && (fd != FileDescriptor.in)) {
close();}
}`
从个人的的角度来看,这样的使用方式一方面是由于 JDK 早期版本没有 try-catch-resource 导致某些异常情况下 IO 流无法正常关闭所以使用这样的写法,另一方面是考虑极端情况下依然需要释放资源的情况,所以重写 finalize 作为一张安全网释放 IO 资源。
本地对等体的解释和实际使用(机翻):
一个 AWT 组件通常是一个包含了对等体接口类型引用的组件类。这个引用指向本地对等体实现。 以
java.awt.Label为例,它的对等体接口是 LabelPeer。LabelPeer 是平台无关的。 在不同平台上,AWT 提供不同的对等体类来实现 LabelPeer。在 Windows 上,对等体类是 WlabelPeer,它调用 JNI 来实现 label 的功能。 这些 JNI 方法用 C 或 C++ 编写。它们关联一个本地的 label,真正的行为都在这里发生。 作为整体,AWT 组件由 AWT 组件类和 AWT 对等体提供了一个全局公用的 API 给应用程序使用。 一个组件类和它的对等体接口是平台无关的。底层的对等体类和 JNI 代码是平台相关的。下面是原文,英语水平还不错的可以尝试阅读一下:
(An AWT component is usually a component class which holds a reference with a peer interface type. This reference points to a native peer implementation.
Take java.awt.Label for example, its peer interface is LabelPeer.
LabelPeer is platform independent. On every platform, AWT provides different peer class which implements LabelPeer. On Windows, the peer class is WlabelPeer, which implement label functionalities by JNI calls.
These JNI methods are coded in C or C++. They do the actual work, interacting with a native label.
Let's look at the figure.
You can see that AWT components provide a universal public API to the application by AWT component class and AWT peers. A component class and its peer interface are identical across platform. Those underlying peer classes and JNI codes are different. )
值得一提的是,在《effective Java》这本书的最后部分,给到了一个正确使用的案例,但是在最后通过一个客户端的错误使用发现依然会导致各种奇怪的现象,这里也说明了 finalize 这个方法的不确定性,同时一旦重写了这个方法就要考量对于程序性能的影响,因为它的调用与否取决于 GC 的实现。
总之不要使用终结器,除非将其用作安全网或终止非关键本机资源。在极少数情况下,如果您确实使用终结器,请记住调用 super.finalize()。最后如果使用终结器作为安全网,请记住从终结器中记录无效使用情况。
最后再提一句:JDK9 已经将 finalize 废弃,但是为了兼容考虑依然还有类在使用。
在这篇文章中笔者根据一篇文章总结了一些个人学习到的 GC 的细节知识,同时根据文章提到的知识点去回顾了关于方法内联优化以及终结方法的细节,从这篇文章看出一个简单的 BUG 就能牵扯出如此多的知识点,最后甚至涉及到了优化器和解释器的设计层面,当然如果读者不是从事 JVM 领域的研究或者涉及的人,其实只要简单知道优化器会干出一些正常逻辑下 “不能理解” 的事情即可,比如 this 局部变量表中的对象如果 this 引用没有被使用很容易被 JIT 给内联优化掉。
最后,希望这篇文章可以切实的帮到你,学习任何内容一定不要简单的复制粘贴形成惯性和固定思维,而是要广泛阅读和汇总思考不断的纠错和回顾,最后形成的观点才有可能的是正确的,毕竟就连周大神的 JVM 书籍里也有让读者会误解的知识点。
又是一篇长文,新的一年里希望能给读者带来更多更有质量的文章。
https://www.52pojie.cn/thread-1578006-1-1.html
B/S 网络架构从前端到后端都得到了简化,都基于统一的应用层协议 HTTP 来交互数据,HTTP 协议采用无状态的短链接的通信方式,通常情况下,一次请求就完成了一次数据交互,通常也对应一个业务逻辑,然后这次通信连接就断开了。采用这种方式是为了能够同时服务更多的用户,因为当前互联网应用每天都会处理上亿的用户请求,不可能每个用户访问一次后就一直保持住这个连接。
①输入 URL:www.google.com;
②DNS 域名解析:域名与 IP 映射(发送到 DNS (域名服务器) 获得域名对应的 WEB 服务器的 IP 地址);
③建立 TCP 连接: 客户端浏览器与 WEB 服务器建立 TCP (传输控制协议) 连接,三次握手;
④发送 Http Request:请求信息(客户端浏览器向对应 IP 地址的 WEB 服务器发送相应的 HTTP 或 HTTPS 请求);
⑤WEB 服务器:Nginx 反向代理(客户端本来可以直接通过 HTTP 协议访问某网站应用服务器,网站管理员可以在中间加上一个 Nginx,客户端请求 Nginx,Nginx 请求应用服务器,然后将结果返回给客户端,此时 Nginx 就是反向代理服务器);
⑥应用服务器:Server 处理请求(数据库等交互.....);
⑦用户浏览器:渲染响应页面(客户端浏览器下载数据,解析 HTML 源文件,解析的过程中实现对页面的排版,解析完成后,在浏览器中显示基础的页面);
⑧关闭 TCP 连接:响应完成(非持久连接);
一句话概括:浏览器本身是一个客户端,当你输入 URL 的时候,首先浏览器会去请求 DNS 服务器,通过 DNS 获取相应的域名对应的 IP,然后通过 IP 地址找到 IP 对应的服务器后,要求建立 TCP 连接,等浏览器发送完 HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回 HTTP Response(响应)包;客户端收到来自服务器的响应后开始渲染这个 Response 包里的主体(body),等收到全部的内容随后断开与该服务器之间的 TCP 连接;
一些具体详细的补充:
浏览器是怎么查找域名对应的 IP 地址的?
浏览器向 web 服务器发送一个 HTTP 请求的过程大概是?
拿到域名对应的 IP 地址之后,浏览器会以一个随机端口(1024 < 端口 < 65535)向服务器的 WEB 程序(常用的有 httpd,nginx 等)80 端口发起 TCP 的连接请求。这个连接请求到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的 TCP/IP 协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过 Netfilter 防火墙(属于内核的模块)的过滤,最终到达 WEB 程序,最终建立了 TCP/IP 的连接。
建立了 TCP 连接之后,发起一个 http 请求。一个典型的 http request header 一般需要包括请求的方法,例如 GET 或者 POST 等,不常用的还有 PUT 和 DELETE 、HEAD、OPTION 以及 TRACE 方法,一般的浏览器只能发起 GET 或者 POST 请求。
客户端向服务器发起 http 请求的时候,会有一些请求信息,请求信息包含三个部分:
------- 请求方法 URI 协议 / 版本
------- 请求头 (Request Header)
------- 请求正文:
GET/sample.php
HTTP/1.1 Accept:image/gif.image/jpeg,*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
注意:最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
服务器是如何处理请求的呢?
后端从在固定的端口接收到 TCP 报文开始,它会对 TCP 连接进行处理,对 HTTP 协议进行解析,并按照报文格式进一步封装成 HTTP Request 对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过 HTTP 协议访问某网站应用服务器,而是先请求到 Nginx,Nginx 再请求应用服务器,然后将结果返回给客户端,这里 Nginx 的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
通过 Nginx 的反向代理,我们到达了 web 服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容。
服务器返回一个 HTTP 响应大概包括哪些?
HTTP 响应与 HTTP 请求相似,HTTP 响应也由 3 个部分构成,分别是:
----- 状态行
----- 响应头 (Response Header)
----- 响应正文
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122 <html>
<head>
<title>http</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>
Navicat Keygen Patch DFoX 集合了数据开发软件 Navicat premium 全系列解锁注册的补丁文件,相信很多从事编程开发的朋友使用的比较的多,软件主要使用适用于数据开发软件,它能够帮助用户解锁 Navicat 全系列的文件资源,可以无需另外的注册码就可以轻松的注册激活软件,而且软件使用非常的简单,只需要简单的设置就可以轻松的完成软件的注册激活,如果您需要 Navicat 注册机的话,那么就千万不要错过这款注册机文件哦。
下载地址:https://www.downkuai.com/soft/128926.html
Navicat Keygen Patch 使用说明
1、下载并解后得到注册机文件,如下图;
2、将注册机文件复制到需要注册激活的软件的安装的路径下;
3、然后在软件安装路径下双击运行注册机 “patch.exe” 文件;
4、这个时候就可以根据自己的需求来注册破解文件了;
附上一张中文界面的文件,方便您对照使用。
Navicat Keygen Patch 怎么用
1、先根据自己的软件选择版本,然后在点击 patch。
2、选择 Navicat 的执行文件,然后点击打开 (此操作只能执行一次,若执行多次则注册失败,必须卸载重装 Navicate)。
3、弹出执行成功框之后说明执行成功了。
4、然后在根据自己安装的软件选择版本和语言。
5、然后在选择注册的有效期。
6、在点击 generate 生成注册码,然后在点击 copy 复制注册码
7、在打开 Navicat 软件,输入注册码点击激活,选择手动激活,然后在复制请求码。
8、将请求码复制到注册工具的文本框中,在点击 generate 生成激活码。
9、生成激活码之后,软件会自动填入,没有自动填入的就手动复制上去,在点击激活,软件就注册激活成功了。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.