🤙 Contact info:

👋 Hi, I'm Wenjie Du (杜文杰 in Chinese). My research majors in modeling time series with machine learning, especially partially-observed time series (POTS), namely, incomplete time series with missing values, A.K.A. irregularly-sampled time series. I strongly advocate open-source and reproducible research, and I always devote myself to building my work into valuable real-world applications. Unix philosophy "Do one thing and do it well" is also my life philosophy, and I always strive to walk my talk. My research goal is to model this non-trivial and kaleidoscopic world with machine learning to make it a better place for everyone. It's my honor if my work could help you in any way.
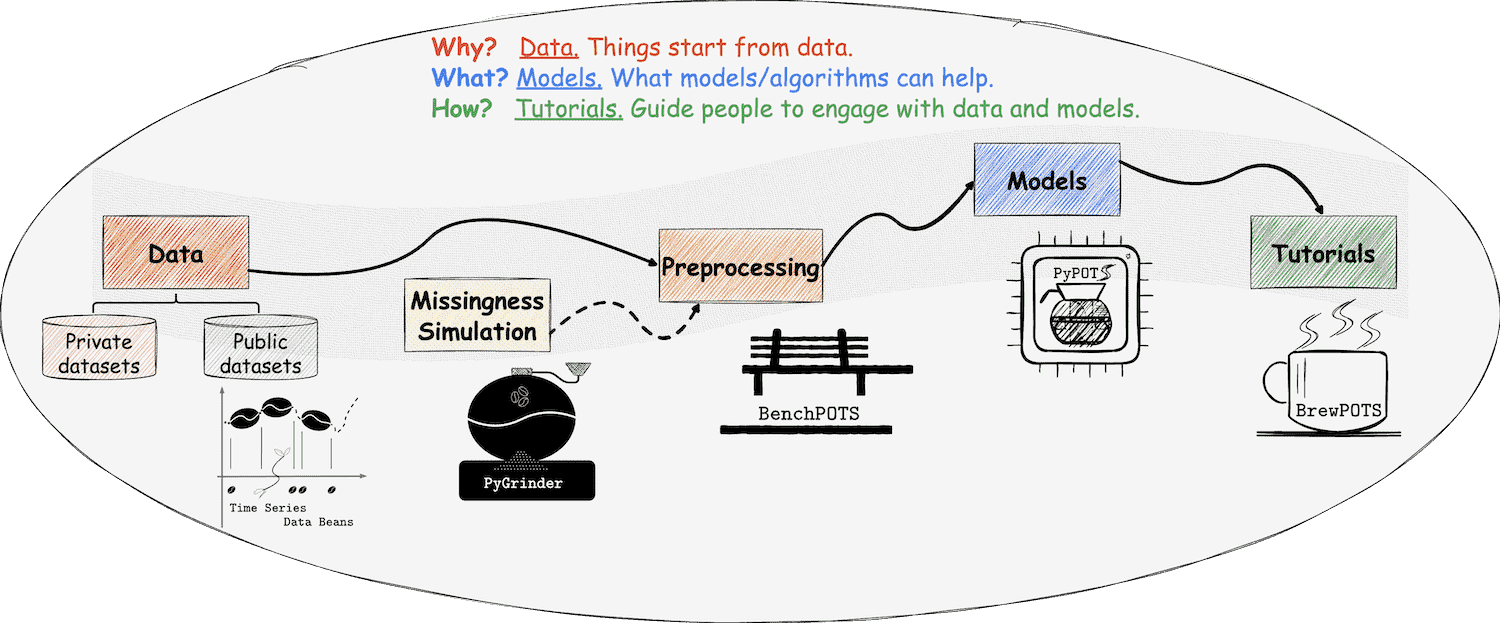
🤔 POTS is ubiquitous in the real world and is vital to AI landing in the industry. However,
it still lacks attention from academia and is also in short of a dedicated toolkit even in a community as vast as Python.
Therefore, to facilitate our researchers and engineers' work related to POTS, I'm leading PyPOTS Research Team (pypots.com)
to build a comprehensive Python toolkit ecosystem for POTS modeling, including data preprocessing, neural net training, and benchmarking.
Stars🌟 on our repos are also very welcome of course if you like what we're trying to achieve with PyPOTS.
💬 I'm open to questions related to my research and always try my best to help others. I love questioning myself and I never stop. If you have questions for discussion or have interests in collaboration, please feel free to drop me an email or ping me on LinkedIn/WeChat/Slack (contact info is at the top) 😃 You can follow me on Google Scholar and GitHub to get notified of our latest publications and open-source projects. Note that I'm very glad to help review papers related to my research, but ONLY for open-source ones with readable code.
❤️ If you enjoy what I do, you can fund me and become a sponsor. And I assure you that every penny from sponsorships will be used to support impactful open-science research.
😊 Thank you for reading my profile. Feel free to contact me if you'd like to trigger discussions.








































































































