有写博客的想法很久了,倒是腾不出时间折腾,先把一些东西放在这里吧。
blogs's Introduction
blogs's People
Stargazers







Watchers

Forkers
zwunixblogs's Issues
在前端打包内存泄漏之后做的事儿
继上次解决了项目无法打包之后,项目可以成功打包了,但是需要用将近300s来打包,打出来的包竟然要13M左右。虽然我们的确模块和页面比较多,但是这也并不能打出这么大的包吧,于是乎我这个业余前端又开始折腾了。
roadhog里面已经自带了一个分析模块,只要在构建的时候加上--analyze参数,就会在打包完后生成一个分析的html,可以看到各个模块的打包占比。这里用的是webpack-visualizer-plugin插件,还有一个非常好用的插件叫webpack-bundle-analyzer,可以查看每个bundle里的各个依赖包的大小。安装后直接在webpack的config里面引入,扔进plugin就可以了,这里不详述。
具体占比就没图了,最大的是echarts,原因是现在好像没有对于react的适配,只能用一个echarts-for-reacts包作为SDK调用,所以会将整个echarts都打入。(之后应该考虑将echarts作为externals打入,之后继续研究的话可以尝试
除此之外还有lodash,antd等包体积也非常大。感觉是打包的时候打入了太多不必要的东西,查阅了一些资料,在某个老哥的博客下提到了CommonsChunkPlugin插件,可以从module中提取公共的chunk。翻了一下roadhog的代码,实际上已经内置了这个插件,但是只有在roadhog的配置里开启了多页应用的时候才会生效,具体代码在roadhog/lib/config/common.js中:
if (config.multipage) {
// Support hash
var name = config.hash ? 'common.[hash]' : 'common';
ret.push(new _webpack2.default.optimize.CommonsChunkPlugin({
name: 'common',
filename: name + '.js'
}));
}
尝试在roadhog中开启了这个多页参数,但是没有任何改进,在common.js里面只有2KB的错误提示,肯定是哪里有问题,尝试搜索发现了老哥二号的博客已经按照这个思路开工了,而且给出了比较完整的解决方案。其中最有参考价值的是在entry中加入常用包的入口。尝试将常用的antd包打入,效果惊人。主要是在webpack的配置里加上这么一行。
webpackConfig.entry.antd = ['antd/lib/button',
'antd/lib/icon',
'antd/lib/form',
'antd/lib/menu',
'antd/lib/input',
'antd/lib/input-number',
'antd/lib/table',
'antd/lib/tabs',
'antd/lib/modal',
'antd/lib/row',
'antd/lib/col'];
...
...
ret.push(new _webpack2.default.optimize.CommonsChunkPlugin({
names: ['antd'],
minChunks: Infinity
}))
加上这段配置后,打包时间由270s直降到180s,打出的包从12.9M到9.2M,有质的飞跃。
之所以没有打入echarts,因为已经开启了按需加载,而画图组件只是在某些模块下使用,作为公共入口打入可能会增加别的模块不必要的加载时间。
在实际使用方面,测试发现首屏进入时会多一个antd.XXX.js,大小在175KB左右,首屏多了1s左右的加载时间,但是在进入其他页面的时候,平均少加载了50KB的JS。
由于暂时没有找到如何修改roadhog的代码,来完美替换webpack的配置,目前只能使用脚本在打包前强行替换配置文件。之后如有更好的操作方式会进行替换。
打包的优化还有许多考虑方向,我估计最容易实现的应该是在引入包的时候,只引入需要用到的包,比如在引入lodash的时候,我之前是:
import _ from 'lodash'
应该使用:
import range from 'lodash/range'
-
webpack这一块的优化应该是最关键的,有许多的插件和属性需要去调整尝试,看了几遍文档也觉得是雾里看花,还需要多实践实践。
-
最后是具体代码的写法,比如.bind方法在构造器绑定的函数,要比箭头函数更为节约内存,减少循环调用,让v8引擎能够回收无用的对象等等。
st2 History数据如何清理
测试环境中有些历史测试数据,帮助文档和web界面都没有看到有删除历史数据的地方,各位知道怎么删除历史记录吗
绕过zabbix验证
问题背景
某系统需要调zabbix下某个绘图的插件(所生成的图),在最开始有两个思路:
- 干掉插件的验证模块。其实是在同目录下cp一个副本,干掉验证模块,并且做好路由限制。
- 模拟登陆,不对zabbix系统有任何改动。
爬坑过程
干掉验证
首先肯定选更简单的干掉验证,研究了一下插件下的某个需要调用的php,开头就写着
$userData = CWebUser::$data;
if (CWebUser::isGuest()) {
$msg = '没有权限';
$code = 1001;
$content = null;
ajaxReturn(['code' => $code, 'msg' => $msg, 'content' => $content]);
}
难道这么简单就可以让我这个不懂世界上最好的编程语言的人解决这个问题了么?我不禁窃喜了一波。
然而删掉了这几行之后,请求了一波,直接返回了孤零零的false,连个报错信息的json都没有了。
那肯定是有些坑没发现,再往下看看,发现一行:
//根据分组id查询分组下的机器
$hosts = API::Host()->get([
......
这个API是什么咧,先是grep找了一波API,无果,问了下拍黄瓜的小伙伴,他说一般是大框架的接口。那接口肯定还是有权限校验的啊。。要是继续把整个zabbix的校验给干掉?那我明天肯定也被干掉了。
模拟登陆
于是乎开始考虑模拟登陆了,首先看看是如何做用户校验的。看了下发往index.php的包,应该是cookies里zbx_sessionid这个参数了。
那么顺理成章开始构建请求(拼url),基本是这样:
- Headers里需要注意类型是x-www-form-urlencoded
- Body里包括name,password,autologin,enter,需要urlencode一波
- POST 到 {ip}/index.php 就可以在响应里拿到cookie。
接下来把cookie存到redis里,设置过期时间,这套操作看起来没有问题。
但是!实际场景需要的是大量图片,按照这个方法,将会出现这样的流程:
取cookie->请求插件->请求图片->下载图片->保存图片(或者不保存)->前端调用
有几十张几百张图等着,其中的损耗感觉略大呀。那么变换一个思路,直接从中nginx层做个路由转发,直接去请求插件,免去中间商赚差价,那不就很快了么。
想法是这么想,但是nginx没办法取到cookie呀,这就很尴尬,当然还是有解决方案的,比如nginx+lua+redis的技术链,看起来是做分布式的,现在真是大炮灭蚊子呀。
所以转念一想,能不能在服务端直接把cookie写进去呢?
fake cookie
再次研究了下zabbix的验证流程,发现插件中引入了一个config.inc.php,那么问题肯定在这个文件里了,寻迹找到真正的凶手,就是include/classes/user/CWebUser.php里找到了login的逻辑:
-
就是取cookie里的zbx_sessionid,然后去sessions表里查询是否有效,然后设定用户权限。如果没有sessionid,就按照guest用户登录。主要代码是这个函数:
public static function checkAuthentication($sessionId) { try { if ($sessionId !== null) { self::$data = API::User()->checkAuthentication(['sessionid' => $sessionId]); } if ($sessionId === null || empty(self::$data)) { self::setDefault(); self::$data = API::User()->login([ 'user' => ZBX_GUEST_USER, 'password' => '', 'userData' => true ]); if (empty(self::$data)) { clear_messages(1); throw new Exception(); } $sessionId = self::$data['sessionid']; } if (self::$data['gui_access'] == GROUP_GUI_ACCESS_DISABLED) { throw new Exception(); } self::setSessionCookie($sessionId); return $sessionId; } catch (Exception $e) { self::setDefault(); return false; } }
如此一来思路就比较清晰了,我就查询一下可用的sessionid,setcookie走一波不就好了。
为了安全,我还特地在MySQL里加上了一个新的本地用户,只对sessions表有查询权限。(感觉还是很不安全啊喂)查了下之前zabbix曝出的sql注入就是因为sessions表被爆了。
结果发现setcookie只有下一次请求的时候才能用上,毕竟服务端读的是这一次的配置啊亲。这该怎么办呢,再想了一波,$_COOKIE不就是一个数组嘛,为什么我不直接把这个参数写进去呢?
操作成功!最终的代码就这么几行:
$con = mysqli_connect("localhost","sess","sess","zabbix");
$sql = "SELECT sessionid FROM sessions where status=0 limit 1;";
$result = mysqli_query($con,$sql);
mysqli_close($con);
$sessionid = mysqli_fetch_assoc($result);
$_COOKIE['zbx_sessionid'] = $sessionid["sessionid"];
但是其中的确有许多曲折的呀,而且,这样感觉留下了不少的安全隐患呐,希望各位可以指正!
这波神操作被我厂的安全审计给抓到了,做了一些比较简单的安全策略。
在zabbix前面的nginx里面配置了一个策略:
location /xxx.php {
allow 127.0.0.1;
allow xxx.x.x.xx;
deny all;
}
既这个php只能够由某个特定的ip访问,然后在项目机子上也做了类似的nginx转发操作,总算弥补了一些之前不安全带来的隐患
Orm初探——Sqlalchemy
SQLAlchemy学习笔记
2017-9-18
(九月份写的了,有空再好好修补一番)
概述
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。因此,SQLAlchmey采用了类似于Java里Hibernate的数据映射模型,而不是其他ORM框架采用的Active Record模型。不过,Elixir和declarative等可选插件可以让用户使用声明语法。(via 维基百科)
使用
pip install sqlalchemy
版本为1.1.13 官方文档:http://docs.sqlalchemy.org/en/rel_1_1/
官方最新版本为1.2,但是为测试版。
使用mysqlconnetcor进行mysql连接时遇到问题:
ImportError: No module named mysql
解决:pip install mysql-connector-python-rf
1 引入及初始化
1.1 引入
# 引入列定义,创建连接,逻辑运算符等基础方法
# from sqlalchemy import Column, String, Integer ,create_engine ,update ,and_ ,or_,func,PrimaryKeyConstraint
from sqlalchemy import *
# 引入session创建方法
from sqlalchemy.orm import sessionmaker
# 引入基类定义方法
from sqlalchemy.ext.declarative import declarative_base,as_declarative,declared_attr
1.2 基类定义
# 默认基类
Base = declarative_base()
# 自定义基类
@as_declarative()
class Base(object):
id = Column(Integer, primary_key=True)
@declared_attr
def __tablename__(cls):
return cls.__name__.lower()
1.3 映射类定义
class Setting(Base):
__tablename__ = 'table_name'
name = Column('name_in_database',String(10),default=as_u_like,primary_key=False,)
parameter = Column()
stype = Column()
projectid = Column()
add_time = Column()
-
查阅发现建表时需要指定Column以及数据类型等,常用数据类型见:http://docs.sqlalchemy.org/en/rel_1_1/core/type_basics.html
-
对Json格式的支持见:http://docs.sqlalchemy.org/en/rel_1_1/core/type_basics.html#sqlalchemy.types.JSON
-
只需要增删查改时可以使用自动加载数据表:
class Setting(Base): __table__ = Table("table_name",Base.metadata,autoload=True,autoload_with=engine) -
自动加载在插入时不会操作未定义的列,在数据表列名使用python保留字时无法定义,灵活性不够,可以换下面这种方法进行加载。
class Setting(Base): __tablename__ = 'table_name' __table_args__ = {'autoload': True} from_ = Column('from')
使用这种方法定义时,需要在基类定义时声明:
Base.metadata.bind = engine
1.4 session获取及使用
# 数据库连接
engine = create_engine('mysql+mysqlconnector://user:[email protected]:3306/database?charset=utf8')
# 定义session类
DBSession = sessionmaker(bind = engine)
# 实例session
session = DBSession()
# 上下文使用session,保持session持有时间尽量短
from contextlib import contextmanager
@contextmanager
def session_scope():
session = DBSession()
try:
yield session
session.commit()
except :
session.rollback()
raise
finally:
session.close()
# 实际调用
with session_scope() as session:
session.add(Model)
print Model.id ### None
session.flush() ### 不知道冲洗放哪里好
2 增删查改 (以下表名列名随意定义)
2.1 增
-
插入时先创建一个实例,将数据写入,再使用session.add()
with session_scope() as session: new_release = Setting() #已定义的映射类 new_release.commit_time = data['commit_time'] new_release.confirm_time = data['confirm_time'] new_release.filelist = data['filelist'] new_release.parameter = data['parameter'] new_release.name = data['name'] session.add(new_release)
2.2 查
with session_scope() as session:
makes = session.query(name,other.name.label('other|name')).\
outerjoin(other,other.id==setting.id).filter(and_(1==1,or_(2==2,3==3))).\
order_by(setting.time.desc()).offset(0).limit(10).all()
total = session.query(func.count('*').label('row_count')).select_from(setting).\
outerjoin(other,other.id==settingid).filter(1==1).\
scalar()
对于返回结果:
- first():返回查询的第一个结果,select*时为对象,某些列时为tuple。
- all():返回查询的所有结果list,对象列表/元组列表。
- scalar():返回某个值,适用于查询某个属性时如id,count。
- one():返回一个结果,返回一个或多个时会报错。
- 对于返回的对象,可以使用obj.__dict__方法来得到字典,None没有__dict__方法。
warning:
- order_by必须在offset和limit之前声明。
- outerjoin使用时query中必须将连接的主表属性放在query最前面。
2.3 改
直接将需要修改好的dict提交即可。
with session_scope() as session:
session.query(setting).filter(setting.id==1).update(setting.attr)
也可以先将需要修改的对象select出来,修改对象属性后再进行commit。
warning:
- update有一个可选参数为synchronize_session,有三个可选项:
- 'evaluate':默认值,会修改当前session中的对象属性;
- 'fetch':修改前,先select查询条目的值,会显著影响性能。
- False:不修改当前session的对象属性。
2.4 删
session.query(setting).filter(setting.id==1).delete(synchronize_session='evaluate')
同样可以先将需要删除的对象select出来,session.delete(obj),再进行commit。
warning:
- 此操作会删除所有匹配的行,绕过ORM工作单元,批量操作。
- 同样需要考虑synchronize_session参数。
参考http://docs.sqlalchemy.org/en/rel_1_1/orm/query.html?#sqlalchemy.orm.query.Query.delete
3 json支持
- MySQL-5.7.8开始支持JSON格式数据。
- 自动验证JSON格式,无效会报错。
- 以二进制形式存储,优化性能。
- 现在受索引中偏移量和存储大小四个字节大小的限制,单个JSON文档的大小不能超过4G;单个KEY的大小不能超过两个字节,即64K。
3.1 create
with session_scope() as session:
demo = test()
form_reslut = 'error'
json = {
'code': 1,
'error': form_reslut
}
demo.info = json
session.add(demo)
- 直接插入dict
3.2 query
result = session.query(test.info['error']).filter(test.info['code']==1).order_by(test.info['code'].cast(Integer)).all()
- 查询时调用方法有三个:通过key值调用,通过数组下标调用,通过路径调用。
3.3 update
-
整个json进行更新时,可以使用,会覆盖整个json:
session.query(obj).filter().update({"json_name":new_json}) -
部分更新时,可以先查询得到对象,修改后使用flag_modified()函数标记这个json已经修改过,再提交才能生效。
from sqlalchemy.orm.attributes import flag_modified result = session.query(obj).filter(obj.id==1).first() result.json_name["json_key"] = somevalue ##修改 flag_modified(result, "json_name")
compare
-
json属性的比较,先比较数据类型优先级,再考虑各个类型的规则。优先级如下:
BLOB
BIT
OPAQUE
DATETIME
TIME
DATE
BOOLEAN
ARRAY
OBJECT
STRING
INTEGER, DOUBLE
NULL -
各个类型的规则:
- BLOB/BIT/OPAQUE: 比较两个值前N个字节,如果前N个字节相同,短的值小
- DATETIME/TIME/DATE: 按照所表示的时间点排序
- BOOLEAN: false小于true
- ARRAY: 两个数组如果长度和在每个位置的值相同时相等,如果不想等,取第一个不相同元素的排序结果,空元素最小
- OBJECT: 如果两个对象有相同的KEY,并且KEY对应的VALUE也都相同,两者相等。否则,两者大小不等,但相对大小未规定。
- STRING: 取两个STRING较短的那个长度为N,比较两个值utf8mb4编码的前N个字节,较短的小,空值最小
- INTEGER/DOUBLE: 包括精确值和近似值的比较。
-
参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/json.html#json-comparison
-
使用json_type可以返回json数据的数据类型:
result = session.query(func.JSON_TYPE(test.info['error'])).select_from(test).filter(test.id==1).first()
index
-
不支持对json列进行索引,可以使用虚拟列进行建立索引以及快速搜索。
alter table test add vir varchar(10) as (json_unquote(info ->"$.error")) result = session.query(test.vir).filter(test.id==1).first()
4 其他功能以及爬坑
4.1 rlike
SqlAlchemy:
query = session.query(setting.text.op('regexp')('(.*)')).filter(setting.text.op('regexp')('(.*)')).first()
SQL:
SELECT setting.text regexp '(.*)' AS anon_1
FROM setting
WHERE setting.text regexp '(.*)'
LIMIT 1
4.2 前缀
query = session.query(setting).prefix_with('SQL_NO_CACHE').all()
4.3 爬坑(不断更新)
-
处理时间时,使用func.date()和func.date_format()。
from datetime import datetime searchstart = datetime.now() searchend = datetime.now() with session_scope() as session: result = session.query(func.count('*').label('row_count'),func.date_format(deliver_flow_log.ctime,"%Y-%m-%d").label('dd')).select_from(deliver_flow_log).\ filter(and_(deliver_flow_log.ctime>=searchstart,deliver_flow_log.ctime<=searchend)).\ group_by(func.date_format(deliver_flow_log.ctime,"%Y-%m-%d")).all() -
处理时间差值,func.adddate()。
with session_scope() as session: chart2 = session.query(setting.group,func.count('*').label('total')).\ filter(setting.ctime >= func.adddate(func.now(), -365)).\ group_by(setting.group).all() -
绝大部分方法藏在func里。
-
SQL语句与线上ORM不同,所得到的也不是之前的torndb.row(dict),所以无法使用dict[key]来进行调用。
-
尝试了将对象中varchar类型的String改成Integer,发现并不会报错,返回unicode。将int类型的Integer改为String,返回仍然是int。无论如何修改都无效,插入数据时再试。
-
定义对象时,必须有一个primary_key,定义时缺少某个属性也可以进行查询。
-
使用one()返回且仅返回单个数据tuple,为0或是大于1都会报错;all()返回list;first()最多返回一个数据。
-
得到的字符串type为unicode,之后可能会有编码问题,查了下文档,可以在数据库连接时指定编码,如下
engine = create_engine('mysql+mysqlconnector://user:[email protected]:3306/database?charset=utf8&use_unicode=0')
但是在指定use_unicode=0后,得到的类型是bytearray。官方文档中提到,在python3下不要指定use_unicode=0,但是在python2使用mysql时,可以获得性能提高。官方文档
Under Python 3, the use_unicode=0 flag should never be used. SQLAlchemy under Python 3 generally assumes the DBAPI receives and returns string values as Python 3 strings, which are inherently unicode objects. Under Python 2 with MySQLdb, the use_unicode=0 flag will offer superior performance, as MySQLdb’s unicode converters under Python 2 only have been observed to have unusually slow performance compared to SQLAlchemy’s fast C-based encoders/decoders.
- 更改参数类型无效,考虑为建表时生效。
- 尝试了一下修改某个属性再提交,后台SQL的确是按照主键做update,在已存在目标数据对象时非常方便。
- 多条件查询时可以使用多个filter,也可以使用and,or等操作,如filter(and_(Release.id==id,Release.port==port))
- sqlalchemy支持rollback,在特殊情况下可以使用。
论一次前端打包内存泄露
作为一个前端框架侠,这次使用的是react框架中的dva作为脚手架,本来一切顺风顺水,但是在临上线打包的时候遇到打包时内存泄露的问题。具体报错如下:
roadhog版本:1.3.1
<--- Last few GCs --->
[3020:000000000035DE90] 241312 ms: Mark-sweep 1334.4 (1446.4) -> 1320.9 (1447.9) MB, 485.3 / 0.0 ms (average mu = 0.150, current mu = 0.075) allocation failure scavenge might not succeed
[3020:000000000035DE90] 241848 ms: Mark-sweep 1335.6 (1447.9) -> 1322.1 (1449.4) MB, 483.5 / 0.0 ms (average mu = 0.125, current mu = 0.096) allocation failure scavenge might not succeed
<--- JS stacktrace --->
==== JS stack trace =========================================
0: ExitFrame [pc: 000002F27D6DC6C1]
Security context: 0x01265c21e681 <JSObject>
1: /* anonymous */ [000002415BDC6409] [0x02c7ee9826f1 <undefined>:~1155] [pc=000002F2802145C4](this=0x0035eef97c69 <AST_Object map = 000002EC92917C29>)
2: _visit [000001E1048365E1] [0x02c7ee9826f1 <undefined>:~1337] [pc=000002F2800FBD91](this=0x030c3fcaed81 <TreeWalker map = 000000FF20E59759>,node=0x0035eef97c69 <AST_Object map=000002EC92917C29>,...
FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory
1: 000000013F64EEE5
2: 000000013F628CD6
3: 000000013F6296E0
4: 000000013FA90D3E
5: 000000013FA90C6F
6: 000000013F9DC594
7: 000000013F9D2B67
8: 000000013F9D10DC
9: 000000013F9DA0B7
10: 000000013F9DA136
11: 000000013FAFF7B7
12: 000000013FBD87FA
13: 000002F27D6DC6C1
error Command failed with exit code 134.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
经过分模块打包之后发现,排除我出品的某个模块就可以打包成功,但是单独打包这个模块也可以成功,这就难倒了我这个前端门外汉,不就是几个图表展示页面么,也没用什么*操作呀。做了些功课,原因应该是这样:
- Node的底层引擎v8,为了防止内存泄露导致机器内存爆炸,在64位的电脑上限制了最多只能使用1.5G的内存
- 当达到最大内存,并且无法进行垃圾回收的时候,无法给对象分配内存,于是会出现内存泄露的问题
但是当前我只是打包,并不是使用node运行服务端什么的,怎么会有内存泄露呢,我又仔细看了几遍我的代码,除了一段略微复杂的foreach之外都很稀疏平常。在roadhog的issue中发现有其他人也有遇到过这样的问题,主要解决方案有这么几个:
- 提高node使用内存,也就是指定 node --max_old_space_size=4096
- 使用插件 increase-memory-limit ,直接npm install ,在项目目录运行这个插件,就会自动在.bin目录下面所有可执行文件的命令上加上这个参数 --max_old_space_size=10240,妈妈再也不怕我没有内存用了
- 在roadhog底层webpack里指定不生成sourceMap,节约空间
使用这三种解决方案,一开始都没有能够成功解决这个问题。面对我出品的模块,也没有发现跟其他模块代码有任何的差异,也没有引入一些新的组件,到底是为何呢?百思不得其解,只能先打个未压缩的包扔到线上,但是这样就导致每个页面进去js都要下载好几秒。
近日灵机一动,为什么不探究一下打包这一条路是怎么走的呢。先从现有打包命令开始:
"node --max_old_space_size=4096 node_modules/roadhog/bin/roadhog.js build"
看起来没有任何问题,看看roadhog.js里面是如何写的
switch (script) {
case '-v':
case '--version':
console.log(require('../package.json').version);
break;
case 'build':
case 'buildDll':
case 'server':
case 'test':
require('atool-monitor').emit();
result = spawn.sync(
'node',
[require.resolve(`../lib/${script}`)].concat(args),
{ stdio: 'inherit'} // eslint-disable-line
);
process.exit(result.status);
break;
default:
console.log(`Unknown script ${chalk.cyan(script)}.`);
break;
}
看来主体就是用spawn起一个子进程去执行../lib里面的相应脚本嘛,还带上了参数,好像没什么问题,于是想着打开build.js来找问题。
这时突然发现,在打包命令中带上的参数max_old_space_size,实际上是没有传入给spawn所起的子进程的。即我只是用4G内存启动了roadhog.js,而在roadhog.js里面是起了子进程来重新调用node运行build.js,实质上build.js使用的内存还是v8的默认值!
于是修改了一下打包命令,直接调用build.js:
"node --max_old_space_size=4096 node_modules/roadhog/lib/build.js"
完美,内存最多时会打到3G,最终成功打包。最后再去看了下之前提到解决方案的老哥,别人写的就是让我直接用node调用build.js而不是roadhog.js。。怪在下眼拙
当然,打包是成功了,但是事情还没有结束。虽然不排除可能是因为该系统模块过多导致打包内存泄露,但是跟我们打包的配置肯定有很大关系,也需要排查下代码是否逻辑有误,导致对象引用一直存在无法被回收等等问题,如果有后续研究成果再写一下~
StackStorm介绍&实践
简介
概述
StackStorm(以下简称ST2)是一个时下非常流行的事件驱动型自动化引擎,擅长处理自动化流程,支持各种服务及工具的自动化和集成。可以轻松实现故障诊断和自动修复,利用st2来实现故障自动诊断以及修复是不错的选择。
优势
- 操作原子化,串成工作流执行,避免重复造轮子。
- 架构简单,支持所有编程语言(脚本语言最佳,官推Python),以简单的yaml格式书写流程。
- Web可视化操作界面,还有ChatOps这种更人性化的操作平台。
- 社区中已有众多平台的集成工具。详情点这儿
结构&流程
基础结构
- Sensors,传感器 :传感器是将外部系统和事件与ST2集成在一起的一种方式,Python编写,可以定期轮询一些外部系统,或者被动地等待入站事件。
- Triggers,触发器 :触发器用于识别传入的事件,继而触发下一步操作(工作流/规则)。传感器通常需要对应触发器。
- Actions,动作 :动作是ST2自动化操作的最小单元,支持所有编程语言。
- WorkFlow,工作流 :工作流将原子操作引入到更高级别的自动化中,并在正确的时间通过正确的输入调用正确的操作来编排它们的执行。它保持状态,在操作之间传递数据,并为执行提供可靠性和透明性。
- Rules,规则 :规则由触发器、触发条件(criteria,可选)与动作组成。将触发器映射到动作/工作流,提供可配置的触发条件。
- Packs,包 :包是以平台(AWS、Zabbix等)为分类,包括一些常用的规则以及操作,方便加载及调用。
流程

- 事件发生,ST2通过sensors或是已定义的webhook(钩子)接收到信息。
- 信息进入消息队列,与已定义的rules中的triggers进行匹配,或是触发已定义的workflow。
- ST2按workflow或是ruls执行动作并记录日志。
以上算是ST2最为简单的流程应用了,其中可定制化的东西非常多,在数据量足够大时,可以考虑使用机器学习等方法进行进一步的智能化。
尝试
前期准备
- 搭建ST2环境,推荐比较干净的64位Linux环境,官方推荐生产环境配置为4核CPU,16GB以上内存,40G硬盘。可定制化东西非常多,目前只是测试,使用一键脚本安装。具体参考
- 搭建zabbix环境,为了方便我把server和agent扔在一部机器上,顺便装了一个redis用于监控,由于不是本实验重点,略过不提。
ST2
认证
ST2需要认证使用,可以使用token或是API key进行认证,区别是API key不会自动过期,token默认一天过期。
使用前先登录:
st2 login "st2admin" -p "Ch@ngeMe"
当然我感觉这种方式更方便:
export ST2_AUTH_TOKEN=`st2 auth -t -p 'Ch@ngeMe' st2admin`
也可以远程请求:
curl -X POST -k -u yourusername:'yourpassword' https://myhost.example.com/auth/v1/tokens
基础操作
#列出所有动作/触发器/规则/包
st2 action/trigger/rule/pack list
#某个动作/触发器/规则/包的详情
st2 action/trigger/rule/pack get XXXX
#执行某个操作,可以传入参数
st2 run core.remote hosts='localhost'
#查看执行历史
st2 execution list -n 10
ST2-Zabbix通道搭建
- 关于zabbix,ST2社区已有相关的工具包,具体参考。需要注意的点:
- 已验证支持的是zabbix3.0/3.2版本。
- 需要在zabbix机器上安装Py依赖包。
- 配置config在文档里实在没找到,提了issue后得到解决办法:按照zabbix.yaml.example中配置好,将其mv到/opt/stackstorm/configs/zabbix.yaml,运行st2ctl reload --register-configs。
- 在ST2中已有zabbix.event_handler触发器,不过研究了很久,这个触发器写得非常简单,应该是需要定制化的。不过查看社区提供zabbix用的告警脚本,直接将信息post到ST2,最终也是webhook处理。这里我自己写了一条简单的规则,用钩子监听某接口的信息,如果payload匹配我写的规则,那么就远程执行命令把redis再调起来。
rule.yaml如下:
---
name: "redis_restart"
pack: "test"
description: "just a test"
enabled: true
trigger: #必选
type: "core.st2.webhook"
parameters:
url: "test" #此处配url
criteria: #可选
trigger.body.name:
pattern: "st2"
type: "equals"
action: #必选
ref: "core.remote"
parameters:
cmd: "redis-server&"
hosts: "XXXXXXX"
password: "XXXXXXXX"
username: "root"
- 使用命令st2 rule create /path/to/rule.yaml 注册规则。
- 定义了一个钩子,url是“https://($ip)/api/v1/webhooks/test”,带着token,post到这个接口就可以调用这个规则。
- 其中criteria(匹配规则)支持非常多的自定义,最方便应用的应该就是正则了。
- action可以填写某个指令,也可以由不同动作组成,更好的是写成动作链(ActionChain),非常灵活&健壮。(以上详见下文Further)
- 介于对zabbix的变量传递还不熟悉,原本的告警脚本中拼接url的部分被我简化,直接写了个拼url的脚本,将数据直接传输过去。流程就是:申请token,拼url,Post到指定接口。
非常简单的监控脚本:
#!/usr/bin/env python
import requests
import simplejson
#头部包括类型&认证token
headers = {
'x-auth-token': 'Token_Here',
'Content-Type': 'application/json',
}
#传递数据
payload = {
"you": "too",
"name": "st2"
}
payload = simplejson.dumps(payload)
requests.post("https://($ip)/api/v1/webhooks/test",data=payload,headers=headers,verify=False)
-
将这个脚本放入zabbix服务器器的某目录下,在zabbix_server.conf中指定目录:
grep 'AlertScriptsPath' /etc/zabbix/zabbix_server.conf // Option: AlertScriptsPath // AlertScriptsPath=${datadir}/zabbix/alertscripts AlertScriptsPath=/usr/lib/zabbix/alertscripts
重启zabbix_server即可。
- 至此所有准备工作结束。
执行
- 非常简单,把redis干掉,zabbix监控到ping不通redis,调用脚本,脚本将预设好的信息发送给ST2,触发已有规则中的触发器,并且匹配规则,调用动作执行命令,远程拉起redis。
- 录了一个非常简陋的GIF,可以凑合看看(右键新页签打开可以好看点)。

Further
关于Webhook
Webhook与Sensors都可以接收信息,不同之处在于:
- Sensors除了被动接收,还可以对外部系统进行定期轮询,可以直接监听某个端口,并且可以使用任何自定义的协议接收数据,具有更好的原子性&紧密性。
- Webhook只能通过POST接收json格式/url编码的表单数据,而且只能由外部系统发起请求到ST2。优点是容易使用&修改。
认证
Webhook提供两种认证方式,API key和tokens,认证时将st2-api-key / x-auth-token参数写入headers即可。
请求内容
仅提供两种类型 application/json 或是 application/x-www-form-urlencoded
添加Webhook
在trigger中添加url,如上述yaml文件中:
trigger:
type: "core.st2.webhook"
parameters:
url: "test" #此处配url
- 注意的点是,/test 或是 /test/ 或是 test/ 都会被ST2认为是相同的url
- 此trigger被添加后,接口为 https://($ip)/api/v1/webhooks/test
Webhook缺点
- 被动接收数据并处理,无法直接反馈数据到外部系统,需要在工作流中自己处理。
- 无法确保执行动作:(英文翻译)ST2中的Webhooks无法确保其执行。这依赖于规则的配置。基于Webhooks的内容,他可能不执行任何动作,也可能执行多种动作。
校验规则
校验规则由三个元素组成,上面demo中的简单例子:
criteria:
trigger.body.name: # 元素
pattern: "st2" # 参数
type: "equals" # 匹配类型
- 在单个规则中只能支持AND逻辑,官方在此提到如果要实现OR逻辑请多写几个RULE。
校验的所有类型在st2/st2common/st2common/operators.py中定义,节选部分如下表:
| 操作符 | 描述 |
|---|---|
| equals | 触发器值与所给值相等(任意类型) |
| nequals | 触发器值与所给值不相等(任意类型) |
| lessthan | 触发器值小于所给值 |
| regex | 正则匹配(基本是PY的re库实现) |
| contains | 触发器值包含所给值(触发器值可为string或是list) |
| startswith | 字符类型触发器值的开头匹配所给值 |
| exists | Key存在于Payload中 |
动作
动作是ST2执行的最小单元,可以使用任意编程语言撰写。每个动作基本由两个文件组成:动作描述文件(yaml),执行文件(类型不定)。
动作描述文件:
找了个ST2内置的发邮件的动作,其描述文件如下:
---
name: sendmail
description: This sends an email
entry_point: send_mail/send_mail
runner_type: "local-shell-script"
enabled: true
parameters:
from:
description: Sender email address.
position: 0
required: false
type: string
default: "stanley"
to:
description: Recipient email address.
position: 1
required: true
type: string
subject:
description: Subject of the email.
position: 2
required: true
type: string
send_empty_body:
description: Send a message even if the body is empty.
position: 3
required: false
type: boolean
default: True
content_type:
type: string
description: Content type of message to be sent
default: "text/html"
position: 4
body:
description: Body of the email.
position: 5
required: true
type: string
sudo:
immutable: true
attachments:
description: Array of attachment file paths, comma-delimited.
position: 6
required: false
type: "string"
由以下几部分组成:
- name - 动作名称
- runner_type - 执行类型
- enabled - 能否调用
- entry_point - 执行文件路径(相对/绝对)
- parameters - 参数
执行文件
执行文件可以支持任何编程语言,不过推荐还是用官方喜欢的PY或是bash。
工作流
ST2触发的动作可能涉及到跨系统的多个原子操作,为了自动化&准确性,引入了工作流的概念。
- 保证在正确的时间,以正确的输入调用正确的操作。
- 保持状态,传递数据,并为执行提供可靠性&透明性。
- 公开,可手动调用/规则触发,甚至可以在工作流之间调用。
- 根据需求提供两种运行器:需要简洁和速度->ActionChain ;需要健壮和韧性->Mistral。
ActionChain
官方文档中在动作链开头就放了一句话:
- 如果你需要更复杂的工作流逻辑,如在错误处理时添加forks,joins,重试,延迟或是保障等操作,请使用Mistral。。
一个动作链需要两个文件组成,描述文件&执行文件,均采用yaml语法。描述文件定义了名称、入口文件、参数和通知。而执行文件列了一系列的动作,并且提供了每一步成功或是失败的回调。简单执行文件如下:
---
chain:
-
name: "c1"
ref: "core.local"
parameters:
cmd: "echo c1"
on-success: "c2"
on-failure: "c4"
-
name: "c2"
ref: "core.local"
parameters:
cmd: "echo \"c2: parent exec is {{action_context.parent.execution_id}}.\""
on-success: "c3"
on-failure: "c4"
-
name: "c3"
ref: "core.local"
parameters:
cmd: "echo c3"
on-failure: "c4"
-
name: "c4"
ref: "core.local"
parameters:
cmd: "echo fail c4"
default: "c1"
Mistral
- 需要yaql或是jinja2语法支持
feat
只是做了些简单的了解,其中能自定义的部分非常多,我个人有几点想法:
- 在公开的文字里感觉携程他们只是用webhook做了一些简单的应用,更多是一个中间件,不知道实际如何,需要好好思考下应用场景
- Sensors如何去写,感觉需要构建一套信息系统非常复杂,即如何拆解一个故障为多个参数,方便后续的规则修改,在数据量更多的时候可以通过机器学习来进一步智能化
- 对于官方提供的webUI说不定可以自定义一波,现有的仅提供了基础功能
- 关于ChatOps还未了解,可能会是下一个流行点。
参考:
axios中abort请求
目前有个项目前端使用的架构是Dva+antd的方案,官方提供的网络请求方式是fetch。
fetch不能说是不好,毕竟还用了Promise呢,但是就目前看来道阻且长,可定制化程度太高,主要是不满足业务场景。详见
于是在我们的项目里将原本的fetch改成了尤神(尤雨溪)推荐的axios。主要封装都是在**/src/utils/request.js**里,主要有这么几点功能:
- 统一的错误处理,即解析状态码
- 带上cookies请求
- response处理
- QueryString的处理
回到正题,是使用axios来abort一些请求。在讲这个之前,要先明确一下什么情景下我们需要abort一些请求。
- 页面刷新过快,导致大量请求,占用服务器资源。
- 上一个请求等待过久,用户只想要后一个请求的结果,比如切换路由。
- 防止表单重复提交
对业务来说比较关键的就是防止表单重复提交了,比如添加一条记录,在某些暴躁老哥的操作下就会变成十条,除了帮暴躁老哥换电脑换网线之外,我还想了几种解决方案:
- 服务端解决,每个客户端会从服务端获取一个token,表单提交的时候会提交这个token,每个token只会消费一次,客户端需要重新获取。当然可以每个表单获取独立token,问题不大。
- 前端解决,每个需要防止重复提交的表单,维护一个变量,点击按钮时将按钮置为不可按,等处理完了再重置。简单有效,就是前端工作量提高了不少。
- 前端解决,利用xhr提供的abort接口,这里只针对表单提交的post请求做处理。逻辑为如果已经有相同的请求在处理中,直接abort后面的请求。
其中第三种实际上是改造成本最小的,只需要改造一下request.js即可。
先查一下文档,大概是这样。
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// An executor function receives a cancel function as a parameter
cancel = c;
})
});
// cancel the request
cancel();首先定义一个handler来处理request和response。
let pendingObj = {};
const { CancelToken } = axios;
const pendingHandler = (flag, params, cancelFn) => {
if (Object.keys(pendingObj).indexOf(flag) > -1){
const dParams = pendingObj[flag];
const sign = deepCompare(params, dParams); //比较参数是否一致
if (sign && cancelFn) {
cancelFn('cancel');
} else {
delete pendingObj[flag];
}
} else if (cancelFn) {
pendingObj[flag] = params;
}
}将逻辑加到request
axios.interceptors.request.use((config) => {
const configs = config;
if (configs.method && configs.method === 'post') {
configs.cancelToken = new CancelToken((cancelFn) => {
pendingHandler(`${config.baseURL}${config.url}`, config.data, cancelFn);
});
}
.......//其他操作
return configs;
}, (error) => {
pendingObj = {}
return Promise.reject(error);
});将逻辑加到response
axios.interceptors.request.use((response) => {
if (response.config.method === 'post'){
pendingHandler(`${response.config.baseURL}${response.config.url}`,JSON.parse(response.config.data);
}
return response;
}, (error) => {
return Promise.reject(error);
});按照dva的错误处理,我在全局的错误处理中捕获了这个错误,还比较有强迫症的去掉了控制台的输出。
const dvaConfig = {
onError(error, dipatch) {
if (error.message === 'cancel') {
error.preventDefault();
dispatch({
type: 'global/showMsg',
payload: { message: '请求过快,请稍后再试', type: 'info'},
});
return;
}
}
}大概就是如此,实际上服务器做校验最为靠谱,毕竟前端的所有数据都是不可信的。
但是实际上有一点小小的问题,因为dva是使用dva-loading来维护全局变量,实际代码比较简单,就是在请求前后去计算一个全局的loading,又分为: global,effects和models。不赘述。
问题就在于请求A在Pending,跟请求A一样的请求B来了,我们判定他是一样的,abort,然后这个请求的loading状态就没了,因为dva-loading是没办法识别到底是哪个请求在loading的。阅读了dva-loading的源码和调用,在不大动的情况下可能避免不了这个问题了。
不过这个问题已经可以解决一部分表单重复提交的问题,目前已经应用到线上。
bizchart的点击事件爬坑
bizchart点击事件
由于echarts没有很好的react适配,在新的项目里打算用antd官方推荐的bizcharts来做图表,发现还是有些坑会踩到。(其实有一个个人项目echarts-for-react做了不错的react适配,但是不能支持按需加载,会导致打出的包较大
需求是一个简单的折线图,按照bizcharts的官方文档,图表组件化,每个图表都是由许多组件组成的,跟echarts里由一个配置json来决定完全不同。甚至还提供了数据转换的模块@antv/data-set,不过这里不详谈,可以看官方文档。
按照官方文档配置的折线图代码简化如下:
import { Chart, Geom, Axis, Tooltip, Legend } from 'bizcharts';
......
onClick = (e) => {
console.log(e);
}
<Chart height={500} data={data} scale={cols} forceFit onPointClick={this.onClick}>
<Legend />
<Axis name="x" />
<Axis name="y" />
<Tooltip crosshairs={{ type: 'y' }} title="x" />
<Geom
type="line"
position="x*y"
size={2}
tooltip={['x*y*z', (x, y, z) => { return { name: z, title: x, value: y }; }]}
color="z"
shape="smooth"
/>
</Chart>
官方对于每一个元素都提供了类似Click之类的方法,详见链接,但是在使用这个函数之后,无论怎么点都无法触发。
于是我灵机一动,用了公用的触发事件onPlotClick,成功获取到了返回值,但是这个返回值里面只有横纵坐标x和y值,完全拿不到跟图形相关的参数。参考了官方的demo,我在state里存放了Chart的实例,点击后再用坐标去Chart里获取图形相关的数据。代码大致如下:
onSaveChart = (chart) => {
this.setState({ chart });
}
onClick = (e) => {
const point = {
x: e.x,
y: e.y,
};
const { chart } = this.state;
const items = chart.getTooltipItems(point);
console.log( items );
}
<Chart onGetG2Instance={this.onSaveChart} onPlotClick={this.onClick}>
......
</Chart>
这次的返回值的确有相关数据了,但是我只是点击了其中一个点,却返回了同一横坐标的所有线的数据,明显不符合我的需求。搜索了许多相关的API和Issue,都没有发现这个问题,但这种很简单的需求难道没有人用?肯定是我的打开方式不对。
于是我打开了官方折线图的DEMO,进了codepen,加上了onPointClick函数,竟然可以生效!!检查了版本之后,我细细看起了官方给的代码跟我的有什么不同,结果发现,他的代码里多了一个type为point的Geom!原来是没有点图的组件,于是没有办法监听跟点相关的点击事件。。这个设计,也是很精妙了,毕竟组件化的东西,没有加载就没有,很是合理。
最后的代码大致是这样:
import { Chart, Geom, Axis, Tooltip, Legend } from 'bizcharts';
......
onClick = (e) => {
console.log(e);
}
<Chart height={500} data={data} scale={cols} forceFit onPointClick={this.onClick}>
<Legend />
<Axis name="x" />
<Axis name="y" />
<Tooltip crosshairs={{ type: 'y' }} title="x" />
<Geom
type="line"
position="x*y"
size={2}
tooltip={['x*y*z', (x, y, z) => { return { name: z, title: x, value: y }; }]}
color="z"
shape="smooth"
/>
<Geom
type="point"
position="x*y"
size={2}
/>
</Chart>
虽然只是个很简单的问题,但是也花费了我好些时间去解决。搜索引擎并没有找到像我一样情况的人(也许是我关键字写得不对233333希望这篇东西能够帮到其他困惑的人。
关于Tornado-MySQL异步
场景
团队定下用比较简洁的Tornado作为后端框架,既然使用万恶的Python作为后端的话,跟数据库的I/O爱恨情仇总是绕不过的一关。当然最简单的选择就是MySQLdb啦,C语言写好的底层总是那么靠谱,但是总归是同步的阻塞操作,有没有什么办法能够实现异步呢?
- 同步阻塞和异步非阻塞这两个概念提到的非常多,在我个人看法里,同步异步主要是由调用方视角来看,需要等待结果的操作是同步,执行完毕通知结果的操作是异步;而阻塞和非阻塞更多是程序的视角,线程挂起等到执行结果的是阻塞,不挂起线程的则是非阻塞。
解决方案
Python自带异步库
首先考虑的是Python本身带的异步I/O库,比如gevent或是比较新的asyncio,基石还是Py2.7,所以先尝试了gevent。打上猴子补丁之后,所有标准库中的thread/socket都被替换掉了,自然都变成非阻塞的了。但是有一个问题,他只能支持Python的原生库,比如Pymysql或者是Oracle写的mysql-connector,这里选择pymysql先做尝试。
-
gevent通过greenlet提供了比较完善的协程,基本**是每当遇到I/O操作的时候,就自动切换到其他的greenlet,以保证程序不会因为I/O操作卡住等待。
import pymysql from gevent import socket,monkey monkey.patch_socket() import time def asyn_query(sql): try: conn = pymysql.connect( use_unicode=True, host='localhost', passwd='testtest', user='test', db='test', init_command=('SET time_zone = "+8:00"'), charset="utf8", sql_mode="TRADITIONAL" ) except Exception as e: print 'connection error.' cursor = conn.cursor() cursor.execute(sql) cursor.close() conn.close() import gevent sql = "SELECT * from test;" sql2 = "SELECT * from test1;" sql1 = "SELECT SLEEP(2);" jobs = [] for i in xrange(1,5): jobs.append(gevent.spawn(asyn_query,(sql))) jobs.append(gevent.spawn(asyn_query,(sql2))) gevent.joinall(jobs) -
通过process_list可以看到的确是同时执行多条SQL,方案可行。
-
不过已经能明显感觉到,pymysql的执行效率貌似不算高,做了一个比较简单的对比测试,在pymysql查询需要10S左右的SQL时,MySQLdb只需要7S左右,已经有明显的性能对比了。当然我的测试非常简陋,于是找到了比较专业的测评数据:
DBAPI: <module 'pymysql' from '/Users/classic/dev/PyMySQL/pymysql/__init__.pyc'>, total seconds 10.046012 DBAPI: <module 'mysql.connector' from '/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/mysql/connector/__init__.pyc'>, total seconds 15.403260 DBAPI: <module 'MySQLdb' from '/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/MySQLdb/__init__.pyc'>, total seconds 1.028737 -
数据来源:参考链接
-
可以看到MySQLdb的效率非常高,用strace看了下,使用Python实现的方法,其中有非常多看不懂的函数调用。。以后有时间可以仔细研究下。
-
最后提下asyncio既然是新入的标准库,肯定是非常简洁非常Cooooool了,也写在feat里吧!
Tornado的协程支持
Tornado自身提供了协程支持,配合Python带的yield可以实现异步。主要用到了以下两个装饰器:
- tornado.web.asynchronous 长连接,需要手动调用self.finish()结束连接
- tornado.gen.coroutine 将请求模式改为协程模式
Demo埋在废电脑里了,主要是这么几个Handler:
class MainHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
self.write("Hello, world")
self.finish()
class NoBlockingHnadler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
yield gen.sleep(10)
self.write('NoBlocking')
class BlockingHnadler(tornado.web.RequestHandler):
def get(self):
time.sleep(10)
self.write('Blocking')
- 在保持阻塞的连接时(Blocking),MainHandler是无法访问的,但是在使用协程的连接时(NoBlocking),可以访问。
- 有两个不好的点:1. yield无法返回值(Py2.7),需要用raise来返回结果。2. 协程只能支持异步库,比如上面的gen.sleep()换成time.sleep()就没有任何效果了。官方异步库
Tornado的多线程支持
虽然CPython有万恶的GIL,但是仍然会有多线程的解决办法嘛。框架中有ThreadPoolExecutor这样的装饰器可以让本身线程再启动一个线程去执行阻塞的程序,实现本身的非阻塞。
- Python2.7中需要安装futures依赖。
将上面的Handlers做一点修改:
from tornado import gen
from tornado.concurrent import run_on_executor
from concurrent.futures import ThreadPoolExecutor
class NoBlockingHnadler(tornado.web.RequestHandler):
executor = ThreadPoolExecutor(4)
@run_on_executor
def sleep(self, second):
time.sleep(second)
return second
@gen.coroutine
def get(self):
second = yield self.sleep(5)
self.write('noBlocking')
- 个人感觉比上一种方法写起来顺手一点,可用性也比较高,缺点是如果线程过多的话,进程就会变得响应非常缓慢,无非是换了个问题。。
使用Celery
如果要依赖分布式队列来调用任务,其实应该是最为健壮的解决方式了。不过这个实现方法略显复杂,如果每个需要非阻塞的地方都需要调Celery的话,会添加许多开发成本。
结论
个人觉得线程算是一个不错的解决办法,一些更为耗时更需要健壮性的操作可以丢给Celery等分布式队列,当然也可以寻求一些其他的实现方法。
Open-Falcon中Transfer源码学习
Open-Falcon是小米开源的一款企业级、高可用、可扩展的开源监控解决方案,而Transfer是Open-Falcon中负责数据处理的中间件,根据官网的介绍,Transfer是一个无状态的集群,接收agent上报的数据,使用一致性哈希进行数据分片、并把分片后的数据转发给graph以及judge集群。
拓扑图大致如下:图源Open-Falcon官网
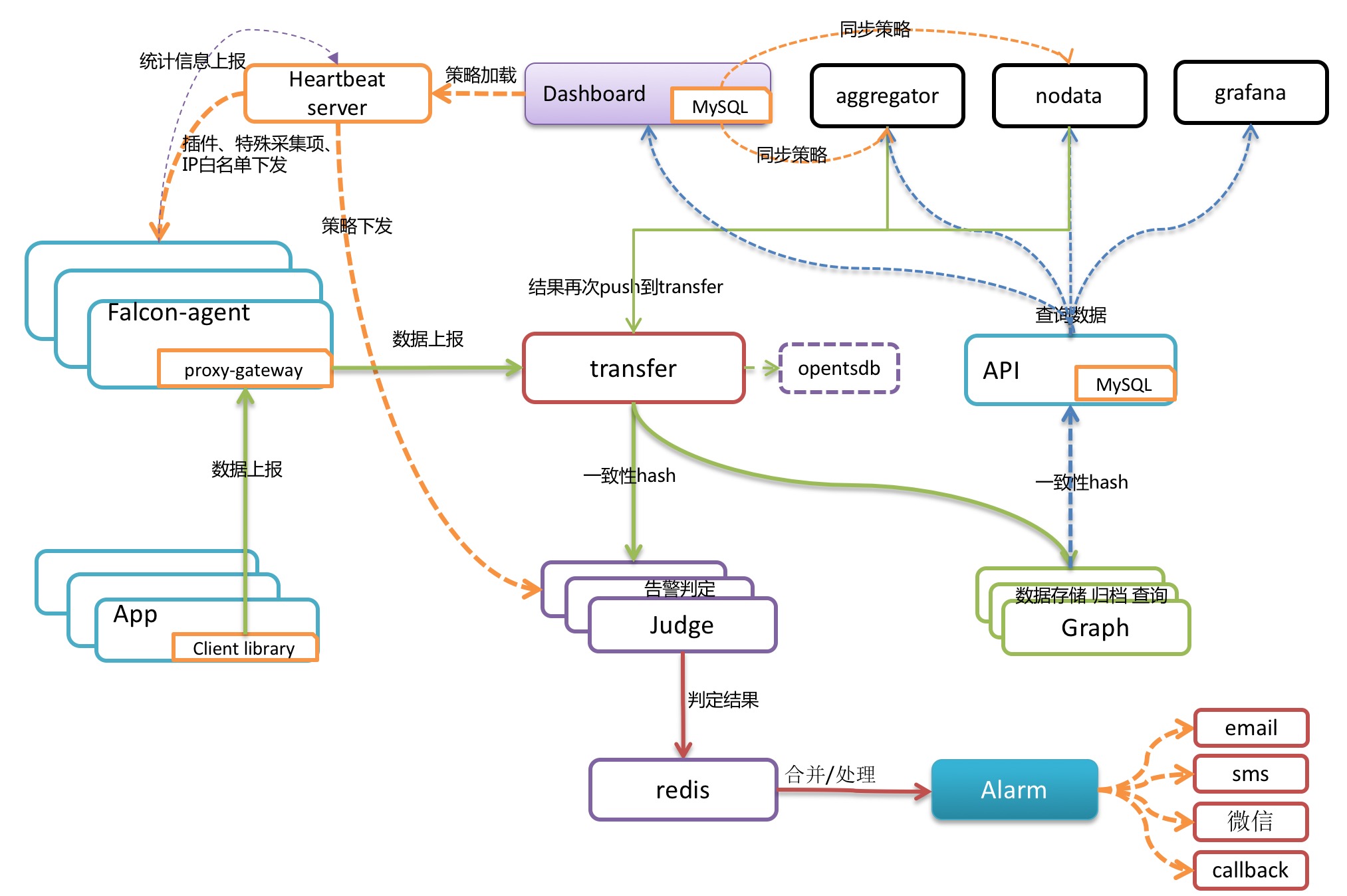
本文使用版本 Open-Falcon:0.2.1
我们先看一下Transfer的目录结构
.
├── LICENSE # 开源许可证
├── NOTICE # 官方声明
├── README.md # 官方说明
├── cfg.example.json # 示例配置文件
├── control # 控制脚本
├── g # 全局模块
│ ├── cfg.go # 配置读取
│ ├── g.go # 全局变量
│ └── git.go # Git变量
├── http # http模块
│ ├── api.go # 自定义监控数据接口
│ ├── common.go # 管理接口
│ ├── debug_http.go # debug模式接口
│ ├── http.go # http请求方法
│ └── proc_http.go # transfer状态请求接口
├── main.go # 入口
├── proc # 分析模块
│ └── proc.go # 自身数据分析&http接口查询
├── receiver # 接收模块
│ ├── receiver.go # 接收入口
│ ├── rpc # rpc
│ │ ├── rpc.go # rpc入口
│ │ └── rpc_transfer.go # rpc数据处理发送
│ └── socket # socket
│ ├── socket.go # socket入口
│ └── socket_telnet.go # socket数据转换
├── scripts # 示例脚本
│ ├── info
│ ├── info.py
│ ├── last
│ ├── last_raw
│ ├── query
│ └── query.py
├── sender # 发送模块
│ ├── conn_pools.go # 连接池
│ ├── node_rings.go # 节点哈希环
│ ├── send_queues.go # 发送队列
│ ├── send_tasks.go # 发送任务推送
│ ├── sender.go # 数据处理&发送
│ └── sender_cron.go # 定时任务
└── test # 测试模块
├── debug
└── rpcclient.py
代码目录简洁明了,核心分为三个部分:
-
receiver:数据接收
-
sender:数据发送
-
http:接口
receiver
入口是分别开启rpc和socket的监听端口(socket据说之后会被放弃,官方未有明确解释)。rpc的主函数如下:
func StartRpc() {
if !g.Config().Rpc.Enabled {
return
}
addr := g.Config().Rpc.Listen
tcpAddr, err := net.ResolveTCPAddr("tcp", addr)
if err != nil {
log.Fatalf("net.ResolveTCPAddr fail: %s", err)
}
listener, err := net.ListenTCP("tcp", tcpAddr)
if err != nil {
log.Fatalf("listen %s fail: %s", addr, err)
} else {
log.Println("rpc listening", addr)
}
server := rpc.NewServer()
server.Register(new(Transfer))
for {
conn, err := listener.Accept()
if err != nil {
log.Println("listener.Accept occur error:", err)
continue
}
go server.ServeCodec(jsonrpc.NewServerCodec(conn))
}
}
主要就是读取配置并注册rpc监听。而同目录下的rpc_transfer .go文件中有个RecvMetricValues函数,是数据预处理的主要函数,做了许多数据校验,也很方便二次开发添加自定义的校验条件:
func RecvMetricValues(args []*cmodel.MetricValue, reply *cmodel.TransferResponse, from string) error {
start := time.Now()
reply.Invalid = 0
items := []*cmodel.MetaData{}
for _, v := range args {
# 许多数据校验规则
if v == nil {
reply.Invalid += 1
continue
}
// 历史遗留问题.
// 老版本agent上报的metric=kernel.hostname的数据,其取值为string类型,现在已经不支持了;所以,这里硬编码过滤掉
if v.Metric == "kernel.hostname" {
reply.Invalid += 1
continue
}
if v.Metric == "" || v.Endpoint == "" {
reply.Invalid += 1
continue
}
if v.Type != g.COUNTER && v.Type != g.GAUGE && v.Type != g.DERIVE {
reply.Invalid += 1
continue
}
if v.Value == "" {
reply.Invalid += 1
continue
}
if v.Step <= 0 {
reply.Invalid += 1
continue
}
if len(v.Metric)+len(v.Tags) > 510 {
reply.Invalid += 1
continue
}
# 时间戳重置
// TODO 呵呵,这里需要再优雅一点
now := start.Unix()
if v.Timestamp <= 0 || v.Timestamp > now*2 {
v.Timestamp = now
}
fv := &cmodel.MetaData{
Metric: v.Metric,
Endpoint: v.Endpoint,
Timestamp: v.Timestamp,
Step: v.Step,
CounterType: v.Type,
Tags: cutils.DictedTagstring(v.Tags), //TODO tags键值对的个数,要做一下限制
}
# 数据类型校验
valid := true
var vv float64
var err error
switch cv := v.Value.(type) {
case string:
vv, err = strconv.ParseFloat(cv, 64)
if err != nil {
valid = false
}
case float64:
vv = cv
case int64:
vv = float64(cv)
default:
valid = false
}
if !valid {
reply.Invalid += 1
continue
}
fv.Value = vv
items = append(items, fv)
}
# 数据自省分析
// statistics
cnt := int64(len(items))
proc.RecvCnt.IncrBy(cnt)
if from == "rpc" {
proc.RpcRecvCnt.IncrBy(cnt)
} else if from == "http" {
proc.HttpRecvCnt.IncrBy(cnt)
}
# 数据插入各自的发送队列
cfg := g.Config()
if cfg.Graph.Enabled {
sender.Push2GraphSendQueue(items)
}
if cfg.Judge.Enabled {
sender.Push2JudgeSendQueue(items)
}
if cfg.Tsdb.Enabled {
sender.Push2TsdbSendQueue(items)
}
reply.Message = "ok"
reply.Total = len(args)
reply.Latency = (time.Now().UnixNano() - start.UnixNano()) / 1000000
return nil
}
在socket_telnet.go文件当中,也有类似的处理函数convertLine2MetaData,将数据标准化:
func convertLine2MetaData(fields []string) (item *cmodel.MetaData, err error) {
if len(fields) != 4 && len(fields) != 5 && len(fields) != 6 {
err = fmt.Errorf("not_enough_fileds")
return
}
endpoint, metric := fields[0], fields[1]
ts, err := strconv.ParseInt(fields[2], 10, 64)
if err != nil {
return
}
v, err := strconv.ParseFloat(fields[3], 64)
if err != nil {
return
}
type_ := g.COUNTER
if len(fields) >= 5 {
type_ = fields[4]
}
if type_ != g.DERIVE && type_ != g.GAUGE && type_ != g.COUNTER {
err = fmt.Errorf("invalid_counter_type")
return
}
var step int64 = g.DEFAULT_STEP
if len(fields) == 6 {
dst_args := strings.Split(fields[5], ":")
if len(dst_args) == 1 {
step, err = strconv.ParseInt(dst_args[0], 10, 64)
if err != nil {
return
}
} else if len(dst_args) == 4 {
// for backend-compatible
// heartbeat:min:max:step
step, err = strconv.ParseInt(dst_args[3], 10, 64)
if err != nil {
return
}
} else {
err = fmt.Errorf("invalid_counter_step")
return
}
}
item = &cmodel.MetaData{
Metric: metric,
Endpoint: endpoint,
Timestamp: ts,
Step: step,
Value: v,
CounterType: type_,
Tags: make(map[string]string),
}
return item, nil
}
同rpc的处理函数相比简化了许多,数据校验也没有那么严格,可能是历史遗留产物,之后版本会废弃掉。
sender
sender主要有三个数据去向:Judge供告警,Graph供绘图,Tsdb供留档。
conn_pools.go
主要是对以上三个方向的连接做连接池的初始化以及销毁的操作。
node_rings.go
初始化Judge和Graph哈希环。哈希环之后详谈。
send_queue.go
初始化发送队列
send_tasks.go
数据发送函数
sender.go
主流程控制,将数据插入发送队列
sender_cron.go
发送模块定时任务,会定时更新缓存以及打日志等。
一致性哈希
数据从Agent经过Transfer转发给Graph,之后对数据的查询都会到Graph上,而Graph和Transfer都可以分布式部署,由某个主机上报的某类型数据,我们肯定希望能存在同一个Graph里。
按照哈希算法,大致是通过一个算式来算出该发到哪部机器上:
machine = machines[unique_key mod len(machines)]
看起来没什么问题,只要key够随机,数据就能够平均落到每个机器上。但是在机器变更的时候就会有大问题,删减机器都会造成hash的大变动,从而导致以前的数据全部混乱。为了解决这个问题,麻省理工在1997年提出了一致性哈希算法。
算法主体是将上述取模的长度由机器数量改为对2^32取模,相当于一个0到2^32-1的数组,头尾相接视为一个环,如下图:
而服务器也需要算自身哈希并且插入到这个哈希表中,如下图:
此时我们使用唯一key来算某个数据的hash,Open-Falcon中具体的算法在common/utils下的func.go文件里:
func PK(endpoint, metric string, tags map[string]string) string {
ret := bufferPool.Get().(*bytes.Buffer)
ret.Reset()
defer bufferPool.Put(ret)
if tags == nil || len(tags) == 0 {
ret.WriteString(endpoint)
ret.WriteString("/")
ret.WriteString(metric)
return ret.String()
}
ret.WriteString(endpoint)
ret.WriteString("/")
ret.WriteString(metric)
ret.WriteString("/")
ret.WriteString(SortedTags(tags))
return ret.String()
}
可以看到如果没有tags,直接用endpoint和metric算出key,如果有tags则加上tags进行计算,可以将tag不同的数据进行分离。
此处提到的bufferPool,是go标准库sync中提供的方法,主要是提供了可复用的内存空间进行计算,在go本身的GC机制之前就会被销毁,节约内存。不详述。
继续说到哈希环,此处计算出当条数据的hash后,将数据插入到hash环上,取右侧最近的一个点作为结果:
数据A就会取右侧最近的ServerC作为数据点,考虑增加/删减一个服务器,只有在服务器左侧区间的数据会受到影响,比直接取余的哈希算法有更好的可用性&扩展性。
而这样的算法也有一定的局限,考虑到各服务器左侧数据区间大小不一致,可能会存在多数数据落在大区间内,导致数据倾斜,存储不均匀的情况。为了解决数据倾斜,一致性哈希算法引入了虚拟节点的概念,每一个服务器可以有N个虚拟节点,比如我们现有3个服务器,设置500个虚拟节点,相当于哈希环上有1500个节点,其中每500个代表同一个服务器。将哈希环划分得更细,可以避免一部分数据倾斜的问题。
Transfer的配置文件中就有相关的参数replicas,默认是500。
而Transfer中用于计算哈希的算法是crc32,具体代码在这里,简单来说就是不断移位取异或,算出一个类似MD5的值。不过这是业界公认安全性不算高的哈希算法,目前没有看到官方相关的说明,之后可以考虑自行更换算法。
http
http模块提供了许多接口以供调用。
api.go
- /api/push 自定义数据推送接口
common.go
- /health Open-Falcon各组件都有的组件状态判断接口
- /version 版本信息
- /workdir 工作目录查询
- /config 配置查询
- /config/reload 配置重置接口
debug_http.go
- /debug/connpool/(judge||graph) 连接池情况查询
http.go
提供http中的request,response处理方法
proc_http.go
- /counter/all 数据计数
- /statistics/all 数据分析(即将废弃)
- /proc/step 获取数据推送频率
- /trace/(condition) 数据追踪
- /filter/(condition) 数据筛选
以上就是对Open-Falcon中Transfer的一些学习,从整体看这个组件已经将数据接收、预处理、一致性哈希、发送等方面都考虑得比较妥当,代码简洁清晰,也比较方便进行二次开发。现在也不像以前的版本只支持MySQL存储,现在可以直接对接TSDB做数据持久化,获取的数据也可以很方便得进行二次使用。
ThreeJS开荒
ThreeJS
背景:
- 最近在Web开发中需要用到3D的模块,看了下WebGL,发现其中的接口太底层了,需要计算机图形学以及3D建模的知识,并且提高了问题的复杂度。
- 所以找了一些已有的库,threejs感觉是比较完善的Web3D开发库了,对WebGL中的东西有了一个很好的封装,提供了功能非常完善的接口,代码托管在github上,使用非常简单。Threejs也可以加载诸如3Dmax,Blender等3D建模软件所建模型,但是由于笔者不会用这一类的软件,所以略过不谈。
- 当然缺点也有,就是文档以及使用的人并不是很多,我觉得有新技术的原因也有这个东西性能上的确有缺陷,并且实现的功能在实用中并不是那么需要。并且因为版本更迭的接口写的不是很清楚,留下了许多坑。
- 市面上也有一些提供Web3D解决方案的公司,也要了一些demo代码回来看了看,接口的逻辑真的太像了,猜测可能是三次开发(个人臆想)。不过threejs在github上写的协议是MIT,那也没什么关系了。
测试环境
- Threejs:87版本
- 浏览器:Chrome 61.0.3163.100 正式版本
- 依赖库:源于github
基础场景
一个基础场景主要由渲染器、照相机和场景组成。
渲染器
要在浏览器实现一个3D的效果,但最后实现的实际上是一个2D的画面,这个映射的过程称之为三维渲染,首先需要一个渲染器。Threejs中提供Canvas以及WebGL渲染器(还有其他的,但是文档含糊其辞),当然会选用WebGL渲染器,相比Canvas在性能以及效果上都有提升。
var renderer;
// 参数不详细列啦,这里是打开抗锯齿。
renderer = new THREE.WebGLRenderer({antialias:true});
// 场景背景色以及透明度。
renderer.setClearColor(0xFFFFFF,0.5)
// 场景大小,这里就设为窗口大小了
renderer.setSize(window.innerWidth,window.innerHeight);
document.body.appendChild(renderer.domElement);
照相机
有了2D画面,还需要在场景中添加一个照相机充当人眼,如何摆放那当然要看个人习惯(瞎放),不,要看设计师的美感了,我们这里只是随意创建一个相机。
ThreeJS中提供了4种相机:
-
CubeCamera:全景相机
-
OrthographicCamera:正投影相机
-
PerspectiveCamera:透视投影相机,类似人眼,最常用
-
StereoCamera:3D相机
var camera; // 焦距为45mm,宽高比,近切,远切 camera = new THREE.PerspectiveCamera(45, window.innerWidth / window.innerHeight, 1, 10000); // 相机摆放位置 camera.position.set(500, 500, 0) // 相机视角位置; camera.lookAt(new THREE.Vector3(0,0,0)); -
说到位置就要提一下threejs里面的三维坐标系了,采用右手坐标系,说起来就是高中的“右手张开,四指指向X轴,旋转小于180°到Y轴,大拇指指向的就是Z轴”。当然所看到的画面是和相机摆放很有关系的,不过还是推荐摆个正一点的相机以及场景,不然空间感有点奇怪。
场景
别忘了最重要的场景,他是所有物体的爸爸(parent),只有添加到场景的物体才能够显示出来的。
var scene = new THREE.Scene();
那么有了渲染器、照相机和场景之后,通过渲染器渲染一下,就能够得到画面了。
renderer.render(scene, camera);
打开浏览器,就能看到一块大白板了。这就是一个最简单最基础的场景啦。
场景元素
主要涉及到物体、纹理、光和贴图。
物体
在threejs中,除了线之外的几何体,都是Mesh或是由Mesh衍生的,在文档中提供了很多的几何形状,我们就先摆一个最简单的正方体吧。
// 创建一个100×100×100的正方体
// 这里有一个CubeGeometry在各种教程中都出现,但是在文档中没有找到,而在发布的js中又存在这个几何体,算是一个小坑。
var cubeGeo = new THREE.BoxGeometry(100,100,100);
// 将几何体转化为Mesh。
var cube = new THREE.Mesh(cubeGeo);
// 一定要添加到场景中。
scene.add(cube);
打开就可以看到一个孤零零的正方体放在中间了。
纹理
一个孤零零的正方体没有图案实在是太无趣了,没有纹理的物体只能有一个随机颜色,怎样添加纹理呢。
Threejs中提供一大串的纹理,官方文档比较乱,大致就用到了以下两种:
- MeshPhongMaterial:金属材质,镜面反射,会反光。
- MeshLambertMaterial:兰比达材质,漫反射,不会反光。
那现在就把材质加上去吧。
// 创建一个100×100×100的正方体
var cubeGeo = new THREE.BoxGeometry(100,100,100);
// 随便定义了一个*紫色。有许多许多的参数,不详细列啦。
var cubeMaterial = new THREE.MeshPhongMaterial({color:'#921a99'})
var cube = new THREE.Mesh(cubeGeo,cubeMaterial);
// 一定要添加到场景中。
scene.add(cube);
咦,但是我们定义的*紫色正方体没有出现在屏幕中间,而是一个黑色的正方体,那是为什么咧?因为我们能看到物体的材质,是因为有光的反射,嗯所以我们还需要一个光源。
光
光在场景里扮演了一个非常重要的角色,可以照亮场景,让我们看到物体的材质,也可以让物体产生阴影,让场景更有真实感。
Threejs里提供了很多种光:
- AmbientLight:环境光,均匀,常用于淡化阴影等
- DirectionalLight:平行光
- HemisphereLight:半球光
- PointLight:点光源
- RectAreaLight:特殊光源,模拟窗户射入光线
- SpotLight:锥形光源
光和照相机一样,摆放的技巧应该可以称之为艺术。那作为笔记,就直接加一个环境光看看效果好了。
//创建环境光
var light1 = new THREE.AmbientLight(0xFFFFFF);
scene.add(light1);
//创建点光源
light2 = new THREE.PointLight('0xFFFFFF');
//放置点光源
light2.position.set(0,200,0);
scene.add(light2);
然后打开浏览器,就能看到一个*紫色的正方体了!
贴图
如果只有颜色渲染的话,那不是很无趣,那我们贴个图吧。随便找了一张地板纹理的图片。把他贴到正方体上。
var cubeGeo = new THREE.BoxGeometry(100,100,100);
var texture = new THREE.TextureLoader().load("/img/floor.jpg");
var cubeMaterial = new THREE.MeshPhongMaterial({map: texture});
var cube = new THREE.Mesh(cubeGeo,cubeMaterial);
//一定要添加到场景中。
scene.add(cube);
这样就能看到点光源照到的地方能够有图片纹理啦。其实六面都有纹理,但是都是相同的图片,有没有办法贴不一样的图呢。
这时就可以使用纹理数组啦,就是将六面纹理放到一个数组里,再用这个数据进行渲染就可以了。
//顺序为 右,左,上,下,前,后
var material1 = new THREE.MeshLambertMaterial({
color: "#D6E4EC"
});
var material2 = new THREE.MeshLambertMaterial({
color: "#D6E4EC"
});
var material3 = new THREE.MeshLambertMaterial({
color: "#B8CAD5"
});
var material4 = new THREE.MeshLambertMaterial({
color: "#A5BDDD"
});
var material5 = new THREE.MeshLambertMaterial({
color: "#D6E4EC"
});
var material6 = new THREE.MeshLambertMaterial({
color: "#D6E4EC"
});
var materials;
materials = [material1, material2, material3, material4, material5, material6];
动态场景组件
只有一个静态的场景肯定是满足不了需求的,于是我们需要一个动态的场景,最好还有很多的触发事件~
这里开始就需要借助一些基于threejs的库来实现了。这些代码都托管在github上。
动画效果
要实现一个简单的动画效果,比较简单的想法就是,每秒进行一次渲染,在此时将正方体的位置进行一个微调,就能让物体动起来了。
于是稍微修改一下我们渲染的方式。
function render(){
// 正方体的x不断改变
cube.position.x +=1;
// 场景渲染
renderer.render(scene,camera);
// 反复调用这个渲染函数
requestAnimationFrame(render);
}
render();
于是,我们得到了一个不断往下移的正方体,哈哈哈,虽然是比较简陋的动画,但是也是迈出的第一步呢。
补间动画
当然我们有了4.1那种简单(简陋)的动画,也会有想要做精致一点的动画的想法。TWEEN这个库提供了非常多种不同的动画,需要用的时候可以扒一扒。主要是threejs中如何使用这个库。
// 传入正方体的位置参数(当然也可以传角度rotation)
// 延迟五秒进行
// 移到x坐标减去500,z坐标加上500的位置,用一秒钟。
var tween = new TWEEN.Tween(cube.position)
.delay(5000)
.to({x: "-" + 500, z: "+" + 500},1000)
.start();
再在animate方法中加入:
Tween.update();
就能实现一个比较平滑的动画啦。
视角变换
单单让物体动起来并不能满足我们,我们还想要像3D游戏一样,可以自由控制自己的视角。那如何实现一个可以用鼠标操作的场景呢,这里使用一个名为OrbitControls的js库。
进行视角转换时,要对当前画面进行重新渲染。示例如下:
var controls;
function initControls() {
controls = new THREE.OrbitControls(camera, renderer.domElement);
// 使动画循环使用时阻尼或自转 意思是否有惯性
controls.enableDamping = true;
// 动态阻尼系数 鼠标拖拽旋转灵敏度
//controls.dampingFactor = 0.25;
// 是否可以缩放
controls.enableZoom = true;
// 是否自动旋转
controls.autoRotate = false;
// 设置相机距离原点的最近距离
controls.minDistance = 100;
// 设置相机距离原点的最远距离
controls.maxDistance = 2000;
// 是否开启右键拖拽
controls.enablePan = true;
}
function render(){
renderer.render(scene,camera);
}
function animate(){
render();
// 刷新鼠标视角
controls.update();
requestAnimationFrame(animate);
}
initControls();
animate();
这样就得到了一个可以通过鼠标左键旋转,滚轮缩放,右键移动的画面了!
性能监控
有了动态画面,我们也要看看动态画面的性能。这里用到了另外一个threejs的库叫做stat.js。直接引入就可以使用啦。
var stats = new Stats();
document.body.appendChild(stats.dom);
然后在不断刷新的animate方法中加上
stats.update()
左上角就会出现一个显示当前FPS的插件啦,是不是很有FPS游戏的即视感。
触发事件
有了平滑的动画,但是场景还是一个没办法跟用户交互的场景,这样就很没有乐趣。如何能够选中场景里的物体从而触发事件呢。
当然肯定不止一种办法,比较简单的想法是这样,原理是由照相机开始,按照鼠标点击的位置定义一条射线,射线所穿过的物体们可以形成一个数组,取数组的第一个就是所选中的目标。然后我们再去定义选中后会产生的效果。
// 事件触发函数
function ondblclick(event){
// 坐标转换
x = (event.clientX / window.innerWidth) * 2 - 1;
y = -(event.clientY / window.innerHeight) * 2 + 1;
// 重定向照相机
dir = new THREE.Vector3(x, y, -1);
dir.unproject(camera);
// 定义射线
ray = new THREE.Raycaster(camera.position, dir.sub(camera.position).normalize());
// 射线所经过的对象数组
var intersects = ray.intersectObjects(scene.children);
for(var i = 0;i < intersects.length;i++){
new TWEEN.Tween(intersects[i].object.position)
.to({x: "-" + 500, z: "+" + 500},1000)
.start();
}
}
// 双击触发
renderer.domElement.addEventListener("dblclick", ondblclick,false);
接着就可以双击改变对象的位置了!
物体组合
单纯使用threejs里提供的各种几何体,可能会有不方便,而自己定义每个坐标来实现一个几何体,那就太过复杂了。我们可以使用一个ThreeBSP的库,对各种几何体进行操作,比如在正方体上挖一个圆什么的。(好像没啥用)当然比较复杂的几何体都可以通过建模的方式,再导入到ThreeJS里,不过对于笔者来说太超纲了!
ThreeBSP中定义了三种比较常用的方法:
-
subtract:相减
-
intersect:相交
-
union:合并
var cubeMaterial = new THREE.MeshLambertMaterial({color:'#39609B'}); //创建正方体 var cubeGeo = new THREE.BoxGeometry(100,100,100); var cube = new THREE.Mesh(cubeGeo); //创建球体 var sphereGeo = new THREE.SphereGeometry(60,20,20); var sphere = new THREE.Mesh(sphereGeo); //转化为BSP var cubeBSP = new ThreeBSP(cube); var sphereBSP = new ThreeBSP(sphere); //相减 var resBSP = cubeBSP.subtract(sphereBSP); //转化为Mesh var mesh = resBSP.toMesh(); //重定位 mesh.geometry.computeVertexNormals(); scene.add(mesh);
这样就成功在边长100的立方体中挖了一个半径为60的球体,不过是不规则的球体,因为在3D中没有曲线的概念,只是将他类似经纬度般分为许多块,在块数越大的情况下,越接近球体。
小结
大致写了一些基础的threejs的用法,由于笔者对JS的理解不深,对于如何去封装使用有很多的不足。再者是threejs也提供更多更复杂的功能,这里涉及到的只是一些基础用法,需要用到的时候会继续去研究!
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.