yanndubs / disentangling-vae Goto Github PK
View Code? Open in Web Editor NEWExperiments for understanding disentanglement in VAE latent representations
License: Other
Experiments for understanding disentanglement in VAE latent representations
License: Other




















































































































I trained a beta TCVAE with the code from https://github.com/rtqichen/beta-tcvae which gives MIG for beta TCVAE of ~0.50. When computing MIG with your code with the same model (based on MLP), I had values close to 0.0008.
Differences with Chen's code I found important:
MIG values are not computed on shape in Chen's code (not considered a factor of variation). I had to modify the dsprites dataset to remove shape from dSprites lat_names, and write a custom _estimate_H_zCv function. I can share if you want.
Chen uses samples, not the mean as you do here
disentangling-vae/disvae/models/vae.py
Line 71 in 7b8285b
The most important change is I changed these lines
disentangling-vae/disvae/evaluate.py
Line 272 in 7b8285b
samples_zCx = samples_zCx.permute(1,0)
samples_zCx = samples_zCx.index_select(1, samples_x).view(latent_dim, n_samples)
samples_zCx = samples_zCx.view(1, latent_dim, n_samples).expand(len_dataset, latent_dim, n_samples)
mean = params_zCX[0].view(len_dataset, latent_dim, 1).expand(len_dataset, latent_dim, n_samples)
log_var = params_zCX[1].view(len_dataset, latent_dim, 1).expand(len_dataset, latent_dim, n_samples)
which are closer to Chen's code, and I get values of ~0.50 now too. I don't exactly know why the original lines where not expanding the correct way
Apologies if the following are just me not configuring properly:
I'm not seeing Gifs/Pngs being created in the model directory with e.g.
python main.py factor_celeba_cc -x factor_celeba -d celeba -l factor. I'd love to have these created every epoch
when i try to evaluate after stopping a training run I get
ization.py", line 382, in load f = open(f, 'rb') FileNotFoundError: [Errno 2] No such file or directory: 'results/best_celeba/model.pt'
To work around I then rename the e.g. model-100.pt in the model directory to model.pt, then I get
21:50:09 INFO - main: Root directory for saving and loading experiments: results/ best_celeba Traceback (most recent call last): File "main.py", line 252, in <module> main(args) File "main.py", line 233, in main test_loader = get_dataloaders(metadata["dataset"], KeyError: 'dataset'
Incidently when i run e.g. python main_viz.py best_celeba gif-traversals reconstruct-traverse -c 7 -r 6 -t 2 --is-posterior I get the same KerError: 'dataset' error
Thanks for the fantastic repo though!
When running python main.py factor_coloredmnist -x factor_coloredmnist on Python 3.8.5 I get the following error:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [256, 20]], which is output 0 of TBackward, is at version 3; expected version 2 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
Coming from d_tc_loss.backward()
I tried replacing inplace=False in the leaky_relu of the discriminator without success. The error comes from calling F.cross_entropy(d_z, zeros) in d_tc_loss (the term F.cross_entropy(d_z_perm, ones) poses no problem).
Any help would be appreciated :)
Hi!
I've been playing a little bit with the code(congratulations for the work by the way 😄 ), and I've seen that when training a FactorVAE model, both the batch size and number of epochs are duplicated:
Lines 191 to 194 in f045219
Does anybody know the reason behind this operation? I've reviewed the original paper but I couldn't find anything related to this.
Thanks for the help!
Hi. Thanks for this wonderful repo!
My question is, shouldn't beta be equal to 0 for the standard VAE loss (i.e. there's no correlation term)?
Also, wouldn't it be clearer to switch beta and gamma hyperparameter symbols, considering that we have literature like betaVAE which uses beta as the hyperparameter for the Dimension-wise KL Divergence?
Ediy: I just found a similar question #55 . Closing this now 👍
Thank u for your code.
I have a question for TC-BetaVAE's MSS
I don't understand why makes all zero columns 1/N and makes all 1st columns strat_weight i n log_importance_weight_matrix
def log_importance_weight_matrix(batch_size, dataset_size):
N = dataset_size
M = batch_size - 1
strat_weight = (N - M) / (N * M)
W = torch.Tensor(batch_size, batch_size).fill_(1 / M)
W.view(-1)[::M + 1] = 1 / N
W.view(-1)[1::M + 1] = strat_weight
W[M - 1, 0] = strat_weight
return W.log()
Below is the formula for the thesis.

I understand that all diagonal entry should be 1/N(because in that case, z is sampled from q(z|n*)) and some other entry should be strat_weight. what am I wrong about?
The problem is here log_q_zCx = log_density_gaussian(samples_zCx[..., idcs], mean[..., idcs], log_var[..., idcs]).
q_zCx is a density function, which should be integrated.
Therefore, I write a probability implement. q_zCx calculates P(a<=z<=b|x).
def erf(x):
a1 = 0.278393
a2 = 0.230389
a3 = 0.000972
a4 = 0.078108
s = torch.sign(x)
x = x.abs()
e = 1-1/(1 + a1*x + a2*x**2 + a3*x**3 + a4*x**4)**4
return s*e
def Gab(a,b,mu,sigma):
'''
the probability of z belonging to [a,b]
:param a:
:param b:
:param mu:
:param sigma:
:return:
'''
inverse_sigma = 1/(math.sqrt(2)*sigma)
return 0.5 * (erf((b-mu)*inverse_sigma)-
erf((a-mu)*inverse_sigma))
samples,params,recons,labels = evaluator.compute(test_loader)
N_x_samples = 1000
M_z_samples = 100
mu,logvar = params
mu,logvar = mu[:N_x_samples],logvar[:N_x_samples]
mu =mu.view(1,N_x_samples,dim).repeat(M_z_samples,1,1)
logvar =logvar.view(1,N_x_samples,dim).repeat(M_z_samples,1,1)
l = torch.linspace(-3,3,M_z_samples+1)
d = l[1]-l[0]
a = l[:-1].cuda()
b = l[1:].cuda()
a = a.reshape(-1,1,1).expand(M_z_samples,N_x_samples,dim)
b = b.reshape(-1,1,1).expand(M_z_samples,N_x_samples,dim)
q_zCx = Gab(a,b,mu,torch.exp(0.5*logvar))
q_z = q_zCx.mean(1)
H_z = (-q_z*(q_z/d).log()).sum(0) ```
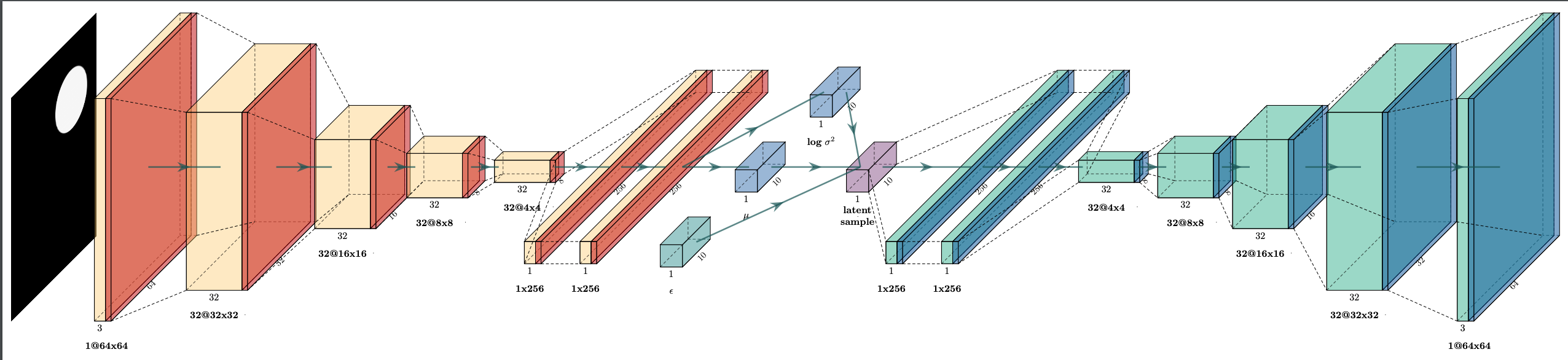
Hello! I was kindly wondering if you could share your PlotNeuralNet code (which is what I presume you used to generate this). I would really appreciate it! To my knowledge, there aren't any VAE visualization examples for this online, so I imagine it would be very helpful for others too.
Hi! I am using this code to work on a dataset of ~700 words. For each word I am varying several variables (size, font, position, etc) . This results in a too big dataset (+6M instances) to use all the possible combinations during training, so I decided to use a sample of the full dataset. That is pl for the training, but this creates an issue during the evaluation run.
In particular, in evaluate.compute_metrics() I found the first technical issue. To run this method the code tries to reshape samples_zCx and params_zCx tensors using the sizes of the dataset generation factors (lat_sizes) and the latent layer size (latent_dim). This is not a problem when using a dataset with all the possible combinations, but given that I now have a sample of all the possibilities, this is not the case. So, I cannot make the reshape.
I solved this by creating a tensor of np.nan and filling it with the available data in the corresponding cells (using metadata from the dataset that indicates how each instance was created). Technically, this works, but I now have doubts about how this solutions impacts on the following calculations. That is, I now have a tensor with NANs that will be used to compute the conditional entropy H(z|v), is this ok? Would it better to use zeros?
Additionally, computing the conditional entropy with the _estimate_H_zCv() method is pretty computationally expensive given that I have a big tensor full of NANs. Would it be ok to skip the cells with NANs to speedup the process?
Just a small issue with quick fix, seems the FashionMNIST class doesn't have the background_color property set.
disentangling-vae/utils/datasets.py
Line 370 in 535bbd2
python main.py btcvae_fashion -d fashion and got the error
File "./disentangling-vae/utils/datasets.py", line 46, in get_background
return get_dataset(dataset).background_color
AttributeError: type object 'FashionMNIST' has no attribute 'background_color'18:49:06 INFO - main: Root directory for saving and loading experiments: results\test01
Traceback (most recent call last):
File "main.py", line 252, in
main(args)
File "main.py", line 199, in main
logger=logger)
File "R:\disentangling-vae-master\utils\datasets.py", line 71, in get_dataloaders
**kwargs)
File "B:\Program_Files\Anaconda3\envs\dis-VAE\lib\site-packages\torch\utils\data\dataloader.py", line 802, in __init__
sampler = RandomSampler(dataset)
File "B:\Program_Files\Anaconda3\envs\dis-VAE\lib\site-packages\torch\utils\data\sampler.py", line 64, in __init__
"value, but got num_samples={}".format(self.num_samples))
ValueError: num_samples should be a positive integeral value, but got num_samples=0
Is there any place to set the value to > 0
Line 109 in disvae/models/losses.py:
if not is_train or self.n_train_steps % self.record_loss_every == 1:This does not work when self.record_loss_every is 1 (recording all mini-batches).
Fix:
if not is_train or (self.n_train_steps - 1) % self.record_loss_every == 0:Got an error while running:
python main.py btcvae_celeba_mini -d dsprites -l celeba --lr 0.001 -b 256 -e 5
Pointing to ./utils/visualize.py line 429:
Changing the argument from fps to duration in the following code which converts from frames per second (fps) to duration seem to resolve the issue
imageio.mimsave(self.save_filename, self.images, duration=(1000 * 1/FPS_GIF))
I want to know which paper does Axis Alignment Metric publish?
I am trying to compute MIG and AAM for another dataset which has a different structure from dsprites, in the sense that the number of samples does not match the product of the size of each latent. Thus, the line fails
disentangling-vae/disvae/evaluate.py
Line 141 in 7b8285b
since the size of samples_zCx is (len(dataset), latent_dim) but len(dataset) != *lat_sizes. Any reason why you explicitly choose to use the product of latent sizes, or should it be the length of the dataset?
Thanks !
Hi,
Looking at this part of the readme, this doesn't seem right:
Standard VAE Loss: α=β=ɣ=1. Each term is computed exactly by a closed form solution (KL between the prior and the posterior). Tightest lower bound.
β-VAEH: α=β=ɣ>1. Each term is computed exactly by a closed form solution. Simply adds a hyper-parameter (β in the paper) before the KL.
β-VAEB: α=β=ɣ>1. Same as β-VAEH but only penalizes the 3 terms once they deviate from a capacity C which increases during training.
The standard VAE is simply gamma=1 with no alpha or beta. For Beta-VAE it is simply gamma > 0 with again no alpha or beta. Did I miss something?
Thanks.
Hello,
Firstly, just wanted to state that this is a great repo with a very understandable code base!
I seem to be getting extremely low MIG / AAM scores (around 1e-3 to 1e-2) when training with any of the pretrained models, even using the recommended hyperparams in the .ini file in the main directory. Is this something you were noticing in your own tests?
Visual inspection of the traversals in DSprites seem to show that the network is learning quite disentangled representations (attached, with rows arranged in order of descending KL-divergence from Gaussian prior), so I am quite confused as to why the MIG score is so low.
Even introducing supervision (matching latent factors to generative factors, the maximum MIG score I have been able to attain is around 0.01, but AAM is a lot higher, at around 0.6 for the model that produced the attached latent traversals.
Cheers,
Justin

Hi @YannDubs,
I have a problem in my own code, and I do not know how to solve that as I am new to VAEs models,
My kl divergence loss becomes so small close to zero, I did put some annealing function , but still the KL-loss becomes close too zero even when the annealing weight is zero,
In your opinion what should I do to train correctly :( ?

Thanks,
Nice Work!!!!!!!!!
I tried the beta-TC VAE, but I found that tc_loss is negetive. Actually, this term is KL divergence which is always positive.
I am confused about it.
Thanks!!!!
Hi! Thank u for this wonderful work!
In evaluate.py-->compute_losses(self, dataloader), it seems that only one batch of data is used for evaluation.
But when it comes to loss computation,
losses = {k: sum(v) / len(dataloader) for k, v in storer.items()}
it uses len(dataloader) to average the loss. Should that be the length of element v?
I wonder if I misunderstand the above computation.
Any help will be appreciated!
Thanks for the excellent repo!
I cloned the repo and installed the dependencies in a virtual environment. When training using the sample command in the README:
python main.py btcvae_celeba_mini -d celeba -l btcvae --lr 0.001 -b 256 -e 5
I see that the training is running on CPU, even though I am running on a machine with multiple cuda GPUs available and which are not being utilized by any other running processes.
...
12:36:40 INFO - main: Train celeba with 202599 samples
12:36:40 INFO - main: Num parameters in model: 504055
12:36:40 INFO - __init__: Training Device: cpu
...
Do I need to do something to enable GPU training? It looks like GPU training should be happening by default...
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}