bartabsa's Issues
是否考虑过将decoder部分的任务转换为预测词角标,而不是bpe index
以公开数据集合训练得到模型,接着在新的数据集上进行三元组任务(triplet)抽取,发现Invalid token的比例很大
是否有考虑过在encoder的embedding部分对词(word)进行编码,decoder部分的任务转换为预测词角标的,从而减少了invalid token的比例?
关于aesc(给定aspect词预测情感类别)任务的问题
这个任务inference的时候不应该是 给定golden aspect喂到bart中,bart吐出来一个情感类别么?我看代码中好像是一个token一个token inference的?
关于模型的测试问题
您好,我发现代码里没有直接在测试集上进行测试的代码。是不是仿照trainer,调用fastNLP的Tester类然后传一下测试集数据就可以了呢。
Inference
Could you please upload the inference file?
训练好的模型预测问题
您好,训练好的模型怎么用来预测新的数据呢,新手一枚,捣鼓好几天也没搞定,还请指点,最好出一个专门用来预测新数据的文件,不胜感激!
关于Embedding
非常感谢公开论文代码!
现在有个问题想请教下:
对于公式 (7), 为什么需要再加一次BARTTokenEmbed (5)?我的理解是BARTTokenEmbed 已经是BART Encoder(2)的 input. 这个是因为最后的prediction更好吗?如果不加效果会差很多吗?谢谢!
请问为什么换了一个新数据集(英文)无法跑通
作者您好,我想要将ATE任务的数据集换成一个新的数据集(ASTE-Data-V2),在我将数据转换为ATE任务要求的格式后(与wang的数据格式一致),代码跑不通了。
bug存在于BartDecoder中,具体如下:
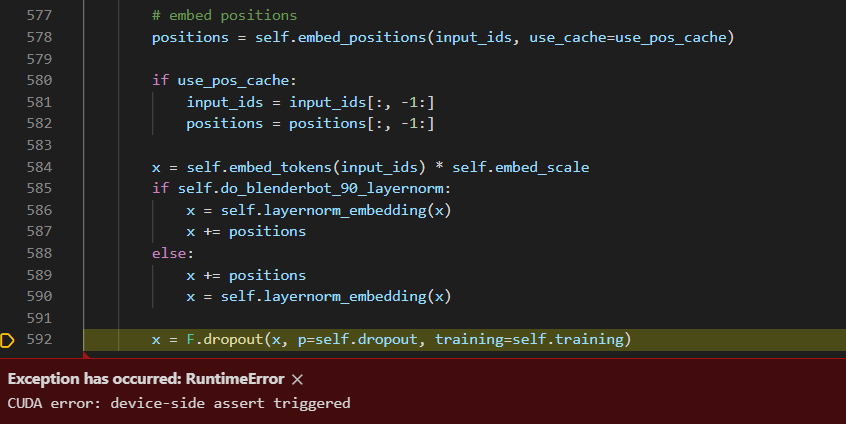
我输出了一下,这里input_ids并不是具体的tensor值,变成了数据的地址信息(比如 <torch.Tensor object at 0x7ff5ce4b2280>),positions也变成了类似情况。
请问你们在数据预处理阶段有对数据做什么特殊处理吗?或者ATE任务对数据有什么特殊要求吗?
dataset wang
wang 2017的数据出错了,为什么14res的数据只是15res打乱了而不是真正的14res
About reproduction
Hi,
I am reproducing you work, but I found that after running with the default settings on the pengb/14lab, I got the triplet metrics as follows: triple_f=57.73, triple_rec=56.81, triple_pre=58.68, while in the paper, the results should be: triple_f=58.69, triple_rec=56.19, triple_pre=61.41. Is there any suggestion?
The question of results
您好,请问在运行程序时需要对模型参数进行调整吗,比如学习率什么的,我没有对模型做任何修改的前提下,得到的结果(准确率、F1、Recall)和论文中得到的结果差异很大,请问这是为什么呢,希望能尽快得到您的答复!
error
您好,在我按照readme和issue#1安装好相关库后。
我在训练时遇到一个错误,不知道怎么回事。
Traceback (most recent call last):
File "train.py", line 24, in <module>
fitlog.set_log_dir('logs')
File "miniconda3/envs/bart-absa/lib/python3.7/site-packages/fitlog/__init__.py", line 122, in set_log_dir
_logger.set_log_dir(log_dir, new_log)
File "miniconda3/envs/bart-absa/lib/python3.7/site-packages/fitlog/fastlog/logger.py", line 32, in wrapper
return func(*args, **kwargs)
File "miniconda3/envs/bart-absa/lib/python3.7/site-packages/fitlog/fastlog/logger.py", line 174, in set_log_dir
raise NotADirectoryError("`{}` is not exist.".format(log_dir))
NotADirectoryError: `logs` is not exist.
the metric
您好,很感激您的工作,但是我对metric上有点小疑惑

"这里相同的pair会被计算多次".
请问这里计算多次指的是什么呢,以AE为例,这是指的BART可能生成重复的aspects?按理说重复的aspects只能算预测对1个。但是在metric中这些重复的aspects都会被当做tp计算?
但是我看您的代码好像进行了去重操作

所以"这里相同的pair会被计算多次".到底是什么意思呢,望解答
RuntimeError freeze_support()
I'm following your readme, while using train.py in the dataset pengb I had this error:
` python train.py --dataset pengb/14lap
Read cache from caches/data_facebook/bart-base_pengb/14lap_False.pt.
The number of tokens in tokenizer 50265
50268 50273
input fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
src_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 41])
src_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
target fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
target_span: (1)type:numpy.ndarray (2)dtype:object, (3)shape:(2,)
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
training epochs started 2021-12-10-15-44-42-060416
Epoch 1/50: 0%| | 0/2850 [00:00<?, ?it/s, loss:{0:<6.5f}]Read cache from caches/data_facebook/bart-base_pengb/14lap_False.pt.
The number of tokens in tokenizer 50265
50268 50273
input fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
src_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 41])
src_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
target fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
target_span: (1)type:numpy.ndarray (2)dtype:object, (3)shape:(2,)
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
training epochs started 2021-12-10-15-44-52-779581
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 125, in _main
prepare(preparation_data)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 236, in prepare
_fixup_main_from_path(data['init_main_from_path'])
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 265, in run_path
return _run_module_code(code, init_globals, run_name,
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 97, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "C:\ProgramData\Anaconda3\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\sp\.conda\envs\BARTABSA\project\BARTABSA-main\peng\train.py", line 155, in <module>
trainer.train(load_best_model=False)
File "C:\ProgramData\Anaconda3\lib\site-packages\fastNLP\core\trainer.py", line 667, in train
raise e
File "C:\ProgramData\Anaconda3\lib\site-packages\fastNLP\core\trainer.py", line 658, in train
self._train()
File "C:\ProgramData\Anaconda3\lib\site-packages\fastNLP\core\trainer.py", line 712, in _train
for batch_x, batch_y in self.data_iterator:
File "C:\ProgramData\Anaconda3\lib\site-packages\fastNLP\core\batch.py", line 266, in __iter__
for indices, batch_x, batch_y in self.dataiter:
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 359, in __iter__
return self._get_iterator()
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 305, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 918, in __init__
w.start()
File "C:\ProgramData\Anaconda3\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\context.py", line 327, in _Popen
return Popen(process_obj)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\popen_spawn_win32.py", line 45, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 154, in get_preparation_data
_check_not_importing_main()
File "C:\ProgramData\Anaconda3\lib\multiprocessing\spawn.py", line 134, in _check_not_importing_main
raise RuntimeError('''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...`
Reading around it seems that : multiprocessing usually doesn't work in a console in Windows. When using a spawning system instead of fork, python must import modules and create state in the child process to get things to work. The outer script must be protected with a if name=="main": clause.
I don't know where to change the code however. Any hints?
显示的batch size问题
无论设置的batch size是多少(4/8/32等都试过),都会显示一次如下信息。
input fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
src_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 41])
src_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
target fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 22])
target_span: (1)type:numpy.ndarray (2)dtype:object, (3)shape:(2,)
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
这一块输出没有看懂。请求作者帮忙解释一下,谢谢。
OSError
python train.py --dataset pengb/14lap
你好,我尝试运行你的代码然后遇到了这个问题,但是本地能正常运行,在服务器上就有这个问题,我以为是python版本太低,换了python3.8还是出现了这个问题。
OSError: libstdc++.so.6: cannot open shared object file: No such file or directory
建议
首先,恭喜你们成功发表该论文,也很感谢你们开源代码。
但是,我看了论文和代码,发现代码结构和论文阐述有很大出入,特别是涉及每个子任务的时候,因为没有合理的注释注解,看起来非常晦涩。所以我建议作者再更新一下readme,把整个代码思路和结构再次阐述一遍(尤其是每个子任务),非常感谢。
请问下,这篇论文使用的fastnlp装的是哪一个版本
请问下,这篇论文使用的fastnlp装的是哪一个版本
fastnlp与fitlog安装包问题
您好!我想请问下按照readme.md文件中的pip install git+https://github.com/fastnlp/fastNLP@dev
pip install git+https://github.com/fastnlp/fitlog装不成功这两个包,能给一下具体的流程吗?主要是不清楚目前哪里出的问题。网上好多方法都试了
关于logs日志loss文件为空及fitlog展示问题
您好,我使用fitlog观察指标发现只有metric的曲线,发现logs目录中loss.log是空文件,请问是为什么呢,如果想添加应该如何修改呢?此外best_metric参数能否在metric曲线上表示出来呢?期待早些回复,谢谢
NotADirectoryError: `logs` is not exist.
Hello,
I'm following your instruction in the readme but when I try to launch
python train.py --dataset pengb/14lap
I get this error. What could be the cause?
Traceback (most recent call last):
File ".\train.py", line 24, in <module>
fitlog.set_log_dir('logs')
File "C:\ProgramData\Anaconda3\lib\site-packages\fitlog\__init__.py", line 122, in set_log_dir
_logger.set_log_dir(log_dir, new_log)
File "C:\ProgramData\Anaconda3\lib\site-packages\fitlog\fastlog\logger.py", line 32, in wrapper
return func(*args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\fitlog\fastlog\logger.py", line 174, in set_log_dir
raise NotADirectoryError("`{}` is not exist.".format(log_dir))
NotADirectoryError: `logs` is not exist.
中文数据集使用及模型加载问题
你好:
我参考你们的文章A Unified Generative Framework for Aspect-Based Sentiment ,想用这个模型作中文的ABSA,于是我将原文的facebook/bart-base替换成fnlp/bart-base-chinese,但是我这里有以下几个问题:
- 1:transformers在4.4.1版本加载模型时会报错:RuntimeError: Error(s) in loading state_dict for BartModel:
size mismatch for encoder.embed_positions.weight: copying a param with shape torch.Size([514, 768]) from checkpoint, the
shape in current model is torch.Size([512, 768]).
size mismatch for encoder.embed_positions.weight: copying a param with shape torch.Size([514, 768]) from checkpoint, the
shape in current model is torch.Size([512, 768]).
这主要是在这里:model = BartSeq2SeqModel.build_model(bart_name, tokenizer, label_ids=label_ids,
decoder_type=decoder_type,copy_gate=False, use_encoder_mlp=use_encoder_mlp, use_recur_pos=False)
- 2:facebook提供的batr-base中有一些文件是merges.txt和json形式的vocab,这与您在huggingface上提供的不一致。我将您在
huggingface上提供的有关bart-base-chinese提供的文件用tokenizer.from_pretrained("bart-base-chinese")使用时,pytorch报错:
OSError: Can't load tokenizer for 'bart-base-chinese'. Make sure that:
'bart-base-chinese' is a correct model identifier listed on 'https://huggingface.co/models'
or 'bart-base-chinese' is the correct path to a directory containing relevant tokenizer files
请问这个该怎么解决?
使用中文数据集做测试
你好,我想用自己的中文数据集做测试,但是发现中文无法做bpe,能否不使用这一模块,让模型能正常训练中文的数据集?

Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.