- 😄 My blog: http://yifanstar.top/
- 📫 How to reach me: [email protected]
yifanzheng / cs-notes Goto Github PK
View Code? Open in Web Editor NEW:book: Java 技术摘要(个人学习笔记),主要记录编程相关的知识点以及个人对一些知识的理解与总结,以 issue 方式记录。
License: MIT License
:book: Java 技术摘要(个人学习笔记),主要记录编程相关的知识点以及个人对一些知识的理解与总结,以 issue 方式记录。
License: MIT License



























为什么 HashMap 默认加载因子是 0.75?而不是 0.8,0.6?
HashMap 中除了哈希算法之外,有两个参数影响了性能:初始容量和加载因子。初始容量是哈希表在创建时的容量,加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少扩容 rehash 操作次数,所以,一般在使用 HashMap 时建议根据预估值设置初始容量,以便减少扩容操作。选择 0.75 作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。因为对于使用链表法的哈希表来说,查找一个元素的平均时间是 O(1+n),这里的 n 指的是遍历链表的长度,因此加载因子越大,对空间的利用就越充分,这就意味着链表的长度越长,查找效率也就越低。如果设置的加载因子太小,那么哈希表的数据将过于稀疏,对空间造成严重浪费。
为什么 Hashmap 中的链表大小超过 8 个才会自动转化为红黑树,当删除小于 6 时重新变为链表?
根据泊松分布,在负载因子默认为 0.75 的时候,单个 hash 槽内元素个数为 8 的概率小于千万分之一,所以将 7 作为一个分水岭,等于 7 的时候不转换,大于等于 8 的时候才进行转换,小于等于 6 的时候就化为链表。
泊松分布是单位时间内独立事件发生次数的概率分布
最后,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
HashMap 长度为什么设计成 2 的 n 次方?
为了在取模和扩容时做优化,同时为了减少冲突,均匀分布元素,HashMap 定位哈希桶索引位置时,也加入了高位参与运算的过程。
HashMap 为什么要引入红黑树来替代链表?
主要是解决因链表过长而导致的查询时间复杂度高的问题,提升查询性能。虽然链表的插入性能是 O(1),但查询性能确是 O(n),当哈希冲突元素非常多时,这种查询性能是难以接受的。因此,在 JDK1.8 中,如果冲突链上的元素数量大于 8,并且哈希桶数组的长度大于 64 时,会使用红黑树代替链表来解决哈希冲突,此时的节点会被封装成 TreeNode 而不再是 Node(TreeNode 其实继承了 Node,以利用多态特性),使查询具备 O(logn) 的性能。
loadFactor:负载因子,它决定了 HashMap 中 table 能够使用的比例。默认的负载因子 0.75 是对空间和时间效率的一个平衡选择。如果内存空间很多而又对时间效率要求很高,可以降低负载因子 loadFactor 的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子 loadFactor 的值,这个值可以大于 1。
取模运算 h & (length - 1):通过 h & (table.length -1) 可以得到对象的保存位置,而 HashMap 底层数组的长度总是 2 的 n 次方,这是 HashMap 在速度上的优化。当 length 总是 2 的 n 方时,h & (length-1) 运算等价于对 length 取模,也就是 h%length,但是 & 比 % 具有更高的效率。
哈希计算
以下是 HashMap 计算 hash 值的方法,使用 key 对应的 hashCode 与其 hashCode 右移 16 位的结果进行异或操作。此处,将高 16 位与低 16 位进行异或的操作称之为扰动函数,目的是将高位的特征融入到低位之中,降低哈希冲突的概率。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
M:修改状态,如果有一个线程修改了多个线程共享的资源,那么,该线程会把此线程内的该值标记为修改状态,通知其他共享了该值的线程,将其他的线程内的该值变为无效状态(I)。
E:独占状态,只有一个线程访问该资源。
S:共享状态,有一个以上线程数同时访问该资源,此时该值为共享状态。
I:无效状态,将该线程的值标记成无效状态,如果需要使用该值,需要重新到内存读取。
由于MESI 协议的消息机制,缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息的这段时间中 CPU 都会等待所有缓存响应完成,所以带来了 CPU 性能下降的问题。
于是,现代 CPU 为了提高并行度,增加写缓冲区(Store Buffer)和失效队列(Invalid Queue)将 MESI 协议的请求异步化(弱一致性),这其实是一种处理器级别的指令重排,会破坏了 CPU Cache 的一致性。所以 CPU 就提供了读、写屏障指令,让程序员或编译器明确声明,这里的修改需要立即写入 Cache, 不能在 Store Buffer 里存着,也就是修改完变量后, 需要立即刷 Store Buffer 里的数据到 Cache,不能等 CPU 空闲时再刷。只要数据刷到缓存,由于 MESI 协议的实现,可以保证各 CPU 缓存一致。
而 Java 提供的 volatile 关键字,就可以告诉 CPU 使用内存屏障来避免 Store Buffer 和 Invaild Queue 造成的指令乱序,并且让修改后的变量立即刷新到缓存中。

乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。
对于同一个数据的并发操作时,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java 中,synchronized 关键字和 Lock 的实现类都是悲观锁。
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。
乐观锁在 Java 中是通过使用无锁编程来实现,最常采用的是 CAS 算法,Java 原子类中的递增操作就通过 CAS 自旋实现的。
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
阻塞或唤醒一个 Java 线程需要操作系统切换 CPU 状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃 CPU 的执行时间,看看持有锁的线程是否很快就会释放锁。
自旋锁是指如果同步资源已经被其他线程锁定,则让当前线程进行自旋,等待其他线程释放锁;如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,节省了线程状态切换带来的开销。
自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了规定次数(默认是 10 次,可以使用 -XX:PreBlockSpin 来更改)没有成功获得锁,就应当挂起线程。
自旋锁的实现原理同样也是 CAS,AtomicInteger 中调用 unsafe 进行自增操作的源码中的 do-while 循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
自旋锁适用于并发度不是特别高的场景,以及临界区比较短小的情况,这样我们可以利用避免线程切换来提高效率。如果临界区很大,线程一旦拿到锁,很久才会释放的话,那就不合适用自旋锁,因为自旋会一直占用 CPU 却无法拿到锁,白白消耗资源。
JDK 6 中引入了自适应的自旋锁(适应性自旋锁)。
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。
优点:等待锁的线程不会饿死。
缺点:整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。
优点:可以减少唤起线程的开销,整体的运行效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程(唤起线程的开销是很大的)。
缺点:处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
可重入锁又叫递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者 class),不会因为之前已经获取过还没释放而阻塞。Java 中 ReentrantLock 和 synchronized 都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
不可重入锁,指同一个线程获取锁后,不能再次获取锁,所以容易产生死锁。
独享锁和共享锁同样是一种概念。
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程 T 对数据 A 加上排它锁后,则其他线程不能再对 A 加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK 中的 synchronized 和 JUC 中 Lock 的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程 T 对数据 A 加上共享锁后,则其他线程只能对 A 再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过 AQS 来实现的,通过实现不同的方法,来实现独享或者共享。
在 ReentrantReadWriteLock 里面,读锁和写锁的锁主体都是 Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。
Java 是半编译半解释执行的,通常我们开发的 Java 源代码通过 Javac 编译成字节码,然后在运行时,通过 Java 虚拟机内嵌的解释器转换成机器码。不过,还有一部分热点代码在运行时被 Java 虚拟机提供的 JIT 编译器(也叫动态编译器)编译成机器码,这部分热点代码就属于编译执行。
说到 equals() 和 hashCode(),这里要引出两个概念:引用相等性和对象相等性。
引用相等性:堆上同一个对象的两个引用是相等的。如果对两个引用调用 hashCode(),会得到相同的结果。
对象相等性:堆上两个不同的对象在意义上是相同的。比如,两个具有相同 name 的 Person 对象是相同的。
hashCode() 的作用是获取哈希值,也称为散列码,实际返回的是一个 int 整数。哈希值的作用是确定对象在散列表中的位置。
对象没有用在散列表中
如果类不会用在基于散列的集合中(HashSet, HashTable, HashMap),equals() 和 hashCode() 是没有关系的。在这种情况下,使用 equals() 比较两个对象的相等性时,hashCode() 是没有作用的。在覆盖了 equals() 后,即使没有覆盖 hashCode() 也不会影响 equals() 比较两个对象的相等性。
对象用在散列表的中
如果类会用在基于散列的集合中(HashSet, HashTable, HashMap),equals() 和 hashCode() 是有关系的。
当把对象加入散列表时,会先使用对象的 hashCode 值确定存储位置,如果没有发现有相同 hashCode 的对象,就直接存入散列表中;如果发现有相同 hashCode 的值对象已经存在时,就会调用 equals() 来检查 hashCode 相等的对象是否真的相同。这就是散列表的存储情况。所以在散列表中,一个类的两个实例对象用 equals() 方法比较的结果相等时,它们的 hashCode 值也一定相等。但是,两个对象有相同的 hashCode 值,它们却不一定是相等的
还有就是,Object 类中 hashCode() 是一个本地(native)方法,返回的是每个对象特有的序号。大部分的 Java 版本是依据内存位置计算此序号的,所以不会有相同的 hashCode 值。如果没有覆盖 hashCode(),则该类的两个对象永远都不会是相同的。
所以在覆盖 equals() 后,也必须覆盖 hashCode()。不然,散列表中永远都不会有两个相同的对象,即使对象的内容一样。同时, equals() 也无效。散列表也就无法正常工作。
散列表中,hashCode 是用来缩小寻找成本,减少 equals() 次数,提高存取速度。
为什么不同的对象有相同 hashCode 值(覆盖 hashCode() 后)
因为 hashCode() 使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值,越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关。
当一个对象存储进 HashSet 集合中后,就不能修改这个对象中参与计算 hashCode 值的字段了,否则会改变 hashCode 值,导致无法从 HashSet 中单独删除该对象,从而造成内存溢出。
重写方法必须要有相同的参数和返回类型。
参数必须要一样,且返回类型必须要兼容
父类的合约定义出其他的程序代码要如何来使用方法。不管父类使用了哪种参数,覆盖此方法的子类也一定要使用相同的参数。而不论父类声明的返回类型是什么,子类必须要声明返回一样的类型或该类型的子类。
不能降低方法的访问权限
这代表访问权限必须相同,或者更为开放。比如,你不能覆盖掉一个公有的方法并将它标记为私有。
重载的条件是要使用不同的参数,返回类型可以自由地定义。
返回类型可以不同
可以任意改变重载方法的返回类型,只要所有的覆盖使用不同的参数即可。
不能只改变返回类型
如果只是返回类型不同,但参数一样,这是不允许的 。
可以更改访问权限
可以任意地设定重载方法的访问权限。
Object 类作用有两个:一是作为多态可以让方法应付多种类型的机制,并且提供 Java 执行期间对任何对象都有需要的方法(让所有类都能继承到)。二是有一部分方法与线程有关。
例子:
List<Object> list = new ArrayList<Object>();
Dog dog = new Dog();
list.add(dog);
// 从集合中取出 dog
Dog dog = list.get(0); // 无法通过编译,编译器无法识别 Object 类型以外的事物
Object o = list.get(0); // 通过编译从上面例子可以看出,任何从 ArrayList 取出的对象都会被当作 Object 类型的实例而不管它原来放进去的是什么类型。
同时,取出的 Object 类型的实例只能调用 Object 类中的方法,而无法知道它原本对象的方法。比如,就算 dog 有一个 eat() 方法,也无法调用到。因为编译器是根据目前引用的类型来判断有哪些方法可以调用,而不是根据对象的真实类型。例子中,所持有的引用类型是 Object 类,实际类型是 Dog 类型,所以只能调用 Object 类的方法。
Vector 是 Java 早期提供的线程安全的动态数组,默认数组长度是 10,它的方法使用 synchronized 进行修饰,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。Vector 内部是使用对象数组(Object[])来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有数组数据,扩容后的数组长度默认是原来的两倍。
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
ArrayList 是应用更加广泛的动态数组实现,默认数组长度是 10,它本身不是线程安全的,所以性能要好很多。与 Vector 近似,ArrayList 也是可以根据需要调整容量,不过两者的调整逻辑有所区别,Vector 在扩容时会提高 1 倍,而 ArrayList 则是增加 50%,约等于原来的 1.5 倍。
Vector 和 ArrayList 作为动态数组,其内部元素以数组形式顺序存储的,所以非常适合随机访问的场合。除了尾部插入和删除元素,往往性能会相对较差,比如我们在中间位置插入一个元素,需要移动后续所有元素。
ArrayList(int initialCapacity) 会不会初始化数组大小?
会初始化数组大小,但是 List 的大小没有变,因为 List 的大小是返回的 size,而且将构造函数与 initialCapacity 结合使用,然后使用 set() 会抛出异常,尽管该数组已创建,但是大小设置不正确。
补充:Vector 和 ArrayList 实现了 RandomAccess 接口,就表明了它们具有快速随机访问功能, 但是 RandomAccess 接口与 Serializable 接口一样只是标识,没有具体的定义,并不是说它们实现 RandomAccess 接口才具有快速随机访问功能的。
LinkedList 是 Java 提供的双向链表,所以它不需要像上面两种那样调整容量,它也不是线程安全的。 LinkedList 进行节点插入、删除要高效得多,但是随机访问性能则要比动态数组慢。LinkedList 是一个实现了 List 接口和 Deque 接口的双端链表。LinkedList 底层的链表结构使它支持高效的插入和删除操作,另外它实现了 Deque 接口,使得 LinkedList 类也具有队列的特性。
CopyOnWriteList 是线程安全的,它是写时复制,往一个元素添加容器的时候,不直接往当前容器 Object[] 添加,而是先将当前容器 Object[] 进行复制,复制出一个新的容器 Object[] newElements,然后新的容器添加元素,添加完元素之后,再将原容器的引用指向新的容器 setArray(newElements),这样做可以对 CopyOnWriteList 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素,所以 CopyOnWriteList 容器也是一种读写分离的**,读和写不同的容器。
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
synchronized 是 Java 提供的原子性内置锁,它是基于操作系统层面的加锁机制(OS-based Lock)实现的,也称监视器锁(存在 Java 对象头里的),能保证线程的安全。synchronized 可以用于函数,也可以用于代码块,synchronized 为非公平锁,通过锁实现了代码中的并行计算。
作用:实现原子性操作和解决共享变量的内存可见性问题。
锁是当前 this 或者说是当前类的实例对象。
public synchronized void func () {
// ...
}或
public void func() {
synchronized (this) {
// ...
}
}对象锁只作用于同一个对象,如果调用两个对象上的同步代码块或同步方法,就不会进行同步。
锁的是当前类或者指定类的 Class 对象。一个类可能有多个实例对象,但它只能有一个 Class 对象。
public void func() {
synchronized (Test.class) {
// ...
}
}或
public synchronized static void fun() {
// ...
}类锁作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
synchronized 除了具有可见性、有序性、原子性这些基本的锁特性外,它还具有可重入性、不可中断性 的特性。
可重入性:synchronized 锁对象的时候有个计数器,它会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会-1,直到计数器清零,就释放锁了。
不可中断性:指一个线程获取锁之后,另外一个线程处于阻塞或者等待状态,前一个不释放,后一个也一直会阻塞或者等待,不可以被中断。值得一提的是,Lock 的 tryLock 方法是可以被中断的。
synchronized 通过进入和退出 Monitor 对象来实现方法同步和代码块同步,但两者的实现细节不一样。Monitor 是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的线程同步。
当使用 synchronized 修饰代码块时,是使用 monitorenter 和 monitorexit 指令实现同步。monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处, JVM 要保证每个 monitorenter 必须有对应的 monitorexit 与之配对。
当使用 synchronized 修饰方法时,会在编译之后的方法中添加 ACC_SYNCHRONIZED 标志位。ACC_SYNCHRONIZED 会去隐式调用刚才的两个指令:monitorenter 和 monitorexit。
synchronized 实际上有两个队列 waitSet 和 entryList 来实现同步:
synchronized 是排它锁,当一个线程获得锁之后,其他线程必须等待该线程释放锁后才能获得锁,而且由于 Monitor 是依赖于底层的操作系统实现,每当同一个线程请求锁资源时,都会发生一次用户态和内核态的切换(进程间的切换),这种转换非常消耗性能。
从内存语义来说,加锁的过程会清除工作内存中的共享变量,再从主内存读取;而释放锁的过程则是将工作内存中的共享变量写回主内存。所以加锁和释放锁的过程,非常消耗性能。
为了提升性能,JDK1.6 引入了偏向锁、轻量级锁、重量级锁概念,来减少锁竞争带来的上下文切换,而正是新增的 Java 对象头实现了锁升级功能。
synchronized 是悲观锁,锁状态升级从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级,不能降级。

无锁
无锁是通过 CAS 实现的,没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
偏向锁主要用来优化同一线程多次申请同一个锁的竞争。如果自始至终,对于这把锁都不存在竞争,那么其实就没必要上锁,只需要打个标记就行了,这就是偏向锁的**。在某些情况下,大部分时间是同一个线程竞争锁资源,例如,在创建一个线程并在线程中执行循环监听的场景下,或单线程操作一个线程安全集合时,同一线程每次都需要获取和释放锁,每次操作都会发生用户态与内核态的切换。
偏向锁的作用就是,当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的 Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor 去竞争对象了,从而减少用户态与内核态的切换。
当对象被当作同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程(stop the world),同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
偏向锁在 JDK1.6 及以后的 JVM 里是默认启用的,可以通过 JVM 参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态。在高并发场景下,可以关闭偏向锁来调优系统性能。
轻量级锁
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁,如果获取成功,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁,线程会通过自旋的形式尝试获取锁,而不会陷入阻塞。轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的 Mark Word 复制到锁记录中,官方称为 Displaced Mark Word。
复制成功后,虚拟机将使用 CAS 操作尝试将对象头中的 Mark Word 更新为指向锁记录的指针,并将锁记录里的 owner 指针指向对象的 Mark Word。如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象 Mark Word 的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。如果更新操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
轻量级锁解锁时,会使用原子的 CAS 操作来将 Displaced Mark Word 替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
重量级锁
升级为重量级锁时,锁标志的状态值变为“10”,此时 Mark Word 中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
偏向锁
优点:加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。
缺点:如果线程间存在锁竞争,会带来额外的锁撤销的消耗 (stop the world)。
适用场景:适用于只有一个线程访问同步块场景。
轻量级锁
优点:竞争的线程不会阻塞,提高了程序的响应速度。
缺点:如果始终得不到锁竞争的线程使用自旋会消耗 CPU。
适用场景:追求响应时间,并且同步块执行速度非常快。
重量级锁
优点:线程竞争不使用自旋,不会消耗 CPU。
缺点:线程阻塞,响应时间缓慢。
适用场景:追求吞吐量,并且同步块执行速度较长。
TCP 是面向连接、可靠的、基于字节流的运输层通信协议,提供全双工、点对点通信。它采用三次握手建立一个连接和四次挥手来关闭一个连接。

标识含义
ACK(确认):仅当 ACK = 1 时确认号字段才有效。当 ACK = 0 时,确认号无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置为 1。
SYN(同步):在建立连接时用来同步序号。当 SYN = 1 而 ACK = 0 时,表明这是一个连接请求报文段。若对方同意建立连接,则应在响应的报文段中使 SYN = 1 和 ACK = 1。因此, SYN = 1,就表示这是一个连接请求或连接接受报文。
RST(复位):表示连接复位请求。RST = 1 时用来复位那些产生错误的连接,也被用来拒绝错误和非法的报文段 。
FIN(终止):用来释放一个连接。当 FIN = 1 时,表示该报文段的发送方已经结束向对方发送数据,并要求释放运输连接。
Sequence Number(序列号):用来标识从 TCP 发送端向 TCP 接收端发送的数据字节流,它表示在这个报文段中的的第一个数据字节在数据流中的序号;主要用来解决网络报文乱序的问题。
TCP 连接的建立采用客户服务器方式。主动发起连接建立的应用进程叫做客户,被动等待连接建立的应用进程叫做服务。
由于信道是不可靠的,但是传输又要求可靠,三次握手的作用就是确认双方的接收和发送能力是正常的。
为什么需要三次握手?
TCP 协议的通信双方都必须维护一个序列号(Sequence number),以标识已经发送出去的数据包中,哪些是已经被对方收到的。所以三次握手的过程是通信双方相互告知与确认序列号起始值的必经步骤。如果只是两次握手,则至多只有连接发起方的序列号能够被确认;
比如,Client 发出的第一个连接请求报文段 (SYN = 1) 在某些网络结点长时间滞留,以致延误到连接释放以后的某个时间才到达 Server 端。本来这是一个已经失效的报文段,但 Server 收到此失效的连接请求报文段后,就误认为是 Client 又发出一次新的连接请求。于是 Server 就向 Client 发出 ACK 报文段,同意建立连接。假如,不是三次握手,是两次握手,那么只要 Server 发出确认,新的连接就会建立。由于现在 Client 并没有发出建立连接的请求,因此不会回应 Server 的确认,也不会向 Server 发送数据。但 Server 以为新的连接已经建立了,并会一直等待 Client 发来数据,Server 的资源就这样白白浪费了。
保活计时器(Server 端维护):作用是防止 Client 和 Server 建立连接后,Client 突然宕机,导致 Server 一直等下去。当保活时间用完后, Server 会自动关闭连接。 Server 每接收到 Client 的一次数据,就会重置保活计时器。
为什么序号不从 0 开始
相同四元组(源 IP 地址+源端口号+目标 IP 地址+目标端口号)的数据,会认为是重复的。
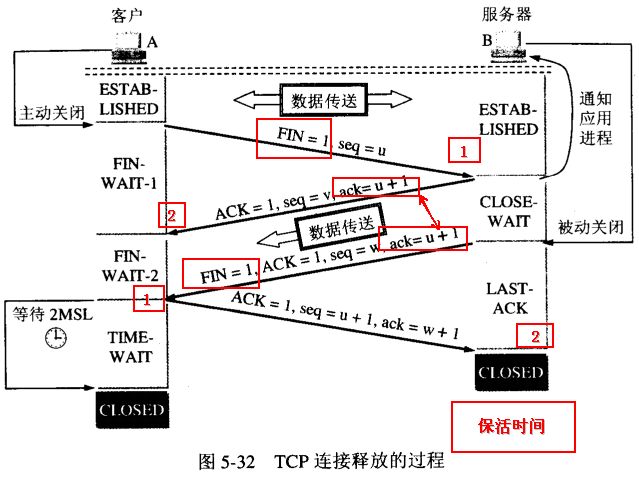
第一次挥手:Client 发送一个 FIN,用来关闭 Client 到 Server 的数据传送,Client 进入 FIN_WAIT_1 状态;
第二次挥手:Server 收到 FIN 后,发送一个 ACK 给 Client,确认序号为收到序号 +1(与 SYN 相同,一个 FIN 占用一个序号),Server 进入 CLOSE_WAIT 状态。Client 收到 Server 的确认后,就进入 FIN_WAIT_2 状态,等待 Server 发送 FIN;
第三次挥手:Server 发送一个 FIN + ACK,用来关闭 Server 到 Client 的数据传送,Server 进入 LAST_ACK 状态;
第四次挥手:Client 收到 FIN 后,Client 进入 TIME_WAIT 状态,接着发送一个 ACK 给 Server,确认序号为收到序号+1,Server 进入 CLOSED 状态,完成四次挥手。
为什么挥手要四次?
关闭连接时,当服务端收到 FIN 报文时,很可能并不会立即关闭 SOCKET,所以只能先回复一个 ACK 报文告诉客户端,"你发的 FIN 报文我收到了"。只有等到服务端所有的报文都发送完了,才能发送 FIN 报文,因此不能一起发送,故需要四次挥手。
为什么 Client 在 TIME-WAIT 状态要等待 2MSL 时间?
由于 Client 发送的 ACK 报文段有可能丢失,因而使 Server 收不到对 Client 发送的 FIN+ACK 报文段的确认。Server 会超时重传这个 FIN+ACK 报文段,而 Client 就能在 2MSL 时间内收到这个重传的 FIN+ACK 报文段。接着 Client 重传一次确认,重新启动 2MSL 计时器。最后,Client 和 Server 都正常进入到 CLOSED 状态。如果 Client 在 TIME_WAIT 状态不等待一段时间,而是在发送完 ACK 确认后立即释放连接,那么就无法收到 Server 重传的 FIN+ACK 报文段,因而也不会再发送一次 ACK 报文段,这样,Server 就无法正常进入 CLOSED 状态。
时间 MSL 叫作最长报文段寿命,RFC 793 建议设为 2 分钟。但这完全是从工程角度考虑的,对于现在的网络, MSL = 2 分钟太长了一些。
Client 在发送完最后一个 ACK 报文段后,经过时间 2MSL ,就会使本连接持续的时间内所产生的所有报文段从网络中清除。所以为了避免已失效连接请求报文段(或重复分组)出现,TCP 协议不允许处于 TIME_WAIT 状态的连接启动一个新的可用连接,因为 TIME_WAIT 状态持续 2MSL,就可以保证当成功建立一个新 TCP 连接的时候,来自旧连接重复分组已经在网络中消逝。
为什么 TIME_WAIT 设置成 2MSL?
去向 ACK 消息最大存活时间(MSL) + 来向 FIN 消息的最大存活时间(MSL),刚好是 2MSL。如果 Server 重发了 FIN,且网络没有故障(重发的FIN被丢弃或错误转发),那么 Client 一定能在 2MSL 之内收到该 FIN,因此 Client 只需要等待 2MSL。
TCP 通过校验和(Checksum)、序列号(Seq)、确认(ACK)、连接管理、超时重传、窗口控制等机制,在不可靠的信道上实现可靠的通信。
当 Client 向 Server 发送数据后,超过一段时间没有收到 Server 的确认,就认为刚才发送的数据丢失了,会重新向 Server 发送刚才发过的数据。Client 每次发送完数据,就会设置一个超时计时器(Client 端维护)。
超时重传时间如何确认?
重传时间的确定是非常复杂的,如果重传时间设置过长,那么通信效率就会很低;但如果重传时间设定太短,又会产生很多不必要的重传,浪费网络资源。
TCP 规定,重传时间应当比数据在分组传输的平均往返时间更长一些,所以一开始超时重传时间(RTO)是加权平均往返时间 + 报文段往返时间(RTT)的偏差。报文段每重传一次 RTO 就会增大一些,新的 RTO 应是旧的 RTO 的 2 倍。
滑动窗口以字节为单位。通过发送窗口向对方发送数据时,在没有收到对方的确认情况下,发送方可以连续把窗口内的数据都发出去。当收到对方的确认号在窗口内时,发送方就可以使窗口向前滑动。凡是已经发送过的数据,在没有收到确认前都必须缓存在窗口中,以便超时重传时使用。在实际通信过程中,窗口大小是可以根据接收能力进行动态调整的(流量控制)。
网络中的顺序问题、丢包问题、流量控制都是通过滑动窗口来解决的。
所谓流量控制,就是让发送方的发送速率不要太快,要让接收方来得及接收,防止因接收方处理不过来数据,导致数据丢失。
TCP 通过滑动窗口协议来进行流量控制,发送窗口可以根据接收方返回的确认(ACK)中包含的接收窗口大小信息进行动态调整发送窗口的大小,以控制数据发送的速率。
流量控制出现的死锁问题?
当 Server 向 Client 发送零窗口(rwnd = 0)后不久,又向 Client 发送一个非零窗口的报文段,但是这个报文段在传输过程中丢失了。Client 一直等待 Server 的非零窗口通知,而 Server 一直等待 Client 发送的数据,就形成了相互等待的死锁局面。
解决方法:持续计时器 + 零窗口探测
TCP 每一个连接都设有一个持续计时器。只要一方收到对方的零窗口通知,就会启动持续计时器。若时间到期,就发送一个零窗口探测报文段(1 字节),对方在确认这个探测报文时给出现在的窗口值。
TCP 规定,即使在零窗口状态下,也必须接收:零窗口探测报文段、确认报文段和携带紧急数据的报文段。
糊涂窗口综合症
糊涂窗口综合症是指 TCP 接收方的缓存空间刚有一点空闲,就向发送方发送窗口大小。假设接收方缓存已满,应用进程每次只从缓存中读取了 1 字节的数据,然后向发送方发送确认并设置窗口大小为 1 字节。接着,发送方又发送 1 字节数据给接收方,接收方发送确认,窗口大小仍然是 1。这样进行下去,网络利用率就很低。
解决方法:
所谓拥塞控制,是为了防止过多的数据注入网络中,避免网络负载过大的情况。
常用的方法:
不管是慢开始还是拥塞避免,只要出现超时(出现网络拥塞),就把拥塞窗口设置为当前的一半。慢开始和拥塞避免算法合起来常称为 AIMD 算法(加法增大乘法减小算法)。
从拥塞控制和流量控制角度考虑,发送窗口的上限值应当取为接收窗口和拥塞窗口中较小的一个值。
进程是程序的一次执行,是系统进行资源分配和调度的独立单位,它的作用是让程序能够并发执行提高资源利用率和吞吐率。由于进程是资源分配和调度的基本单位,因为进程的创建、销毁、切换产生大量的时间和空间的开销,进程的数量不能太多。进程包含多个线程,每个进程是相互独立的,文件或网络资源是进程共用的。
线程是比进程更小的能独立运行的基本单位,它是进程的一个实体,可以减少程序并发执行时的时间和空间开销,使得操作系统具有更好的并发性。线程没有自己的地址空间,没有自己的内存,数据都在进程中,所以线程无法独立执行,必须依存于应用程序中。
线程基本不拥有系统资源,只有一些运行时必不可少的资源,比如程序计数器、寄存器和栈,进程则占有堆、栈。
”==“ 作用是比较两个对象是否相等。对于基本数据类型,”==“ 比较的是值是否相等;对于引用类型,”==“ 比较的是引用地址是否相等。
例子:
public static void main(String[] args) {
int a = 1;
int b = 1;
Integer c = new Integer(1);
Integer d = new Integer(1);
System.out.println(a == b); // true
System.out.println(c == d); // false
}”equals()“ 作用是比较两个对象是否相等。默认比较的是引用地址。Java 中的包装类(如,Integer、Long 等)、String 等重写了 equals 方法,将它变成了值比较。
Object 类中 equals 方法源码
public boolean equals(Object obj) {
return (this == obj); // 本质还是 "=="
}例子:
public static void main(String[] args) {
Integer a = new Integer(1);
Integer b = new Integer(1);
System.out.println(a.equals(b)); // true
}Integer 类中 equals 方法源码
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}null.equals() 语句出现,将已知的变量放在 equals 方法前面;例如:
"abc".equals(str)Objects.equals(a, b) 语句比较两个对象是否相等,这样可避免上述 null.equals() 造成的空指针异常;继承表示的是 is-a 的关系,它可以让子类都会有父类持有的全部可继承(public 或 protected)方法,避免了重复的程序代码,达到复用的目的。并且,子类可以重写从父类继承下来的方法。
三种方法可以阻止继承:
1. 继承打破了封装性
当子类依赖于父类中的某些特定方法功能时,如果父类方法在后续发生了变化,子类可能会遭到破坏。因此,子类也必须跟着父类的变化进行演变。
2. 继续会存在覆盖问题
如果父类在后续增加了新的方法,如果这个新方法与子类中的某个方法具有相同的签名但返回类型不同,那么子类将无法通过编译;如果这个新方法与子类的某个方法具有相同的签名和返回类型,那子类就覆盖了父类方法。这两种情况都会对子类进行破坏。
Java 有 8 种基本类型:
| 名称 | 字节 |
|---|---|
| byte | 1 个字节 |
| char | 2 个字节 |
| short | 2 个字节 |
| int | 4 个字节 |
| float | 4 个字节 |
| long | 8 个字节 |
| double | 8 个字节 |
| boolean | - |
其中,bolean 类型没有明确规定占几个字节。
基本类型都有对应的包装类型,它们依次是 Byte、Character、Short、Integer、Short、Long、Double、Boolean。
自动装箱,就是自动将基本数据类型转换为包装器类型。自动拆箱,也就是自动将包装器类型转化为基本数据类型。
例子:
Integer a = 59;// 底层执行的是:Integer a = Integer.valueOf(59);
int b = a // 底层执行的是:int b = a.intValue();另外,Byte、Character、Short、Integer、Short、Long、Boolean 包装类实现了常量池技术(享元模式),常量池大小范围分别是:
Integer.valueOf() 源码
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}例子:
public static void main(String[] args) {
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
int h = 1;
Integer i = new Integer(1);
System.out.println(a == h); // true
System.out.println(a == i); // false 执行 Integer.valueOf() 才会使用到常量池
System.out.println(c == d); // true
System.out.println(e == f); // false
System.out.println(c == (a + b)); // true
System.out.println(c.equals(a + b)); // true
System.out.println(g == (a + b)); // true
System.out.println(g.equals(a + b)); // false
}注:包装类的 ‘==’ 运算在不遇到算术运算符的情况下不会自动拆箱;equals() 方法不会处理数据转型的关系。
HTTP2 目前还没有普及,但肯定是未来的主流。HTTP2 主要解决了传输性能的问题。
所有数据以二进制传输:在 HTTP 1.1 版本中大部分数据是以文本形式传输,在 HTTP2 版本中,所有数据以二进制传输,统称为“帧”。
多工(并行请求):因为有了以二进制传输的好处,同一个连接里面发送多个请求不再需要按照顺序来进行返回处理,而是同时返回。在返回第一个请求的同时也可以返回第二个请求,这样它就是一个并行的效率,可以更大限度地让整个 Web 应用的传输效率有一个质的提升。
头信息压缩:在 HTTP 1.1 中,每次发送请求和返回请求,它的 HTTP 头信息总是要完整发送和返回,而这部分头信息内容是以字符串形式保存,所以它占用的带宽量是很大的。而 HTTP2 中,对头信息进行了压缩,减少了对带宽的占用。
服务器推送:HTTP/2 允许服务器未经请求,主动向客户端发送资源。常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析 HTML 源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
就是不同的 key 经过一个函数f(key)得到的结果的作为地址去存放当前的 key-value 键值对,却发现算出来的地址上已经存在有其他键值对,这就是哈希冲突。
常用的散列冲突解决方法有两类:开放寻址法(open addressing)和链表法(chaining)。
每个哈希地址对应的一个线性表,将地址相同的记录按序写入链表中。
优点
缺点
当关键字 key 的哈希地址 p 出现冲突时,以 p 为基础,产生另一个哈希地址 p1,如果 p1 仍然冲突,再以 p 为基础,产生另一个哈希地址 p2,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。
简单地说,开放寻址法的核心**就是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
关于开放地址探测新位置的方法有:线性探测法、二次探测法、双重哈希法(也叫再哈希法)。
线性探测法:当往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
二次探测法:二次探测,跟线性探测很像,只是步长是二次方,线性探测步长是 1。
双重哈希法:先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
优点
缺点
1. 客户端发起 HTTPS 请求
用户在浏览器里输入一个 https 网址,然后连接到 server 的 443 端口。
2. 服务端的配置
采用 HTTPS 协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥。
如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3. 传送证书
服务端把自己的信息以数字证书的形式返回给客户端(证书内容有密钥公钥,网站地址,证书颁发机构,失效日期等)。证书中有一个公钥来加密信息,私钥由服务器持有。
4. 客户端解析证书
这部分工作是有客户端的 TLS 来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题或用户接受了不受信任的证书,那么就生成一个随机值(即对称密钥)。然后用证书的公钥对该随机值进行加密。
5. 传送加密信息
这部分传送的是用证书的公钥加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6. 服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(对称密钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和密钥通过某种算法混合在一起,这样除非知道密钥,不然无法获取内容,而正好客户端和服务端都知道这个密钥。
7. 传输加密后的信息
这部分信息是服务段用随机值加密后的信息,可以在客户端被还原
8. 客户端解密信息
客户端用之前生成的随机值解密服务端传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
服务端如何保证随机值是客户端发送的,而不是黑客发送的?
每次收到“客户”发来的要加密的的字符串时,“服务器”并不是真正的加密这个字符串本身,而是把这个字符串进行一个 hash 计算,加密这个字符串的 hash 值(不加密原来的字符串)后发送给“客户”,“客户”收到后解密这个 hash 值并自己计算字符串的 hash 值然后进行对比是否一致。也就是说,“服务器”不直接加密收到的字符串,而是加密这个字符串的一个 hash 值,这样就避免了加密那些有规律的字符串,从而降低被破解的机率。“客户”自己发送的字符串,因此它自己可以计算字符串的 hash 值,然后再把“服务器”发送过来的加密的 hash 值和自己计算的进行对比,同样也能确定对方是否是“服务器”。
如何保证内容完整性,即如何得知内容是否被篡改过?
在每次发送信息时,先对信息的内容进行一个 hash 计算得出一个 hash 值,将信息的内容和这个hash值一起加密后发送。接收方在收到后进行解密得到明文的内容和 hash 值,然后接收方再自己对收到信息内容做一次 hash 计算,与收到的 hash 值进行对比看是否匹配,如果匹配就说明信息在传输过程中没有被修改过。如果不匹配说明中途有人故意对加密数据进行了修改,立刻中断通话过程后做其它处理。
mysql -h [ip] -P 3306 -u [user] -p [password];AtomicLong 的 Add() 是依赖自旋不断的 CAS 去累加一个 Long 值。如果在竞争激烈的情况下,CAS 操作不断的失败,就会有大量的线程不断的自旋尝试 CAS 会造成 CPU 的极大的消耗,而 LongAdder 在性能方面进行了优化,使用空间换时间的方法,解决了这个问题。
LongAdder 是基于 Striped64 实现,Striped64 内部维护了一个懒加载的 cells 数组和一个 base 值,数组大小是 2 的 N 次方,使用每个线程内部的哈希值进行访问。
LongAdder 核心**是热点数据分离,将 value 值分离成一个数组,即将对单一共享变量的操作压力分散到多个变量值上。当多线程访问时,通过 hash 算法将竞争的每个写线程的 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的 value 值进行 CAS 操作,最后在读取值的时候会将原子操作的共享变量与各个分散在数组的 value 值相加,返回一个近似准确的数值。这相当于将 AtomicLong 的单点的更新压力分担到各个节点上。在低并发的时候通过对 base 的直接更新,可以保障和 AtomicLong 的性能基本一致,而在高并发的时候通过分散提高了性能。
简言之,当只有一个写线程,没有竞争的情况下,LongAdder 会直接使用 base 变量作为原子操作变量,通过 CAS 操作修改变量;当有多个写线程竞争的情况下,除了占用 base 变量的一个写线程之外,其它各个线程会将修改的变量写入到自己的槽 cell[] 数组中。
与 AtomicLong 相比,LongAdder 更多地用于收集统计数据,而不是细粒度的同步控制。在低并发环境下,两者性能很相似。但在高并发环境下,LongAdder 有着明显更高的吞吐量,但是有着更高的空间复杂度(缺点就是内存占用偏高点)。
LongAdder 使用了一个 cell 列表去承接并发的 CAS,以提升性能,但是 LongAdder 在统计的时候如果有并发更新,可能导致统计的数据有误差。
当需要保证线程安全,可允许一些性能损耗,要求高精度时,可以使用 AtomicLong。
当需要在高并发下有较好的性能表现,且对值的精确度要求不高时,可以使用 LongAdder(例如网站访问人数计数)。
使用场景选择
补充:在 Java 9 之后,String、StringBuilder 和 StringBuffer 改用 byte 数组存储字符串。
String 常量池比较特殊,它主要有两种使用方法:
String a = “abc”: JVM 会在字符串常量池中寻找有没有 “abc” 这个字符串,如果有,就直接返回地址;如果没有,就在字符串常量池中创建一个 String 对象,并把地址返回给 a。
String a = new String("abc"):首先,会在常量池中去寻找有没有 "abc" 这个字符串,如果有,就不做任何事情,否则会在常量池中创建一个 String 对象。然后,在堆内存中再创建一个 String 对象(“abc”),并把这个对象的地址返回给 a。不严谨地说,这条语句会创建了 2 个对象,第一个对象是 ”abc” 字符串存储在常量池中,第二个对象在堆内存中的 String 对象。
例子:
public static void main(String[] args) {
String a = new String("abc");
String b = "abc";
String c = "abc";
System.out.println(a == b); // false
System.out.println(b == c); // true,由于常量池中已经存在 “abc”,所以 b, c 得到的引用是一样的。
}“a” + ”c“ 实则是创建了一个 StringBuilder 对象,并为每个字符串调用一次 StringBuilder 的 append() 方法,最后调用 toString() 方法创建一个最终的 String 对象返回。
StringBulder.toString() 源码
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count); // 此方法不会在常量池中存一份对象。
}String.intern() 方法是一个 native 方法。如果常量池中存在当前字符串,就会直接返回当前字符串;如果常量池中没有此字符串,就会将此字符串放入常量池中后再返回。
例子:
public static void main(String[] args) {
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}这段代码在 JDK 6 及以前版本中运行,会得到两个 false,而在 JDK 7 及更高版本中运行,会得到一个 false 和 一个 true。
产生差异的原因是,在 JDK 6 及以前版本中,常量池是放在 “永久代” 区域中的, “永久代” 区域和正常的 Java 堆区域是完全分开的。
我们先来看 s3 和 s4 字符串,s3 得到的引用对象内容是 “11”,但此时常量池中是没有 “11” 对象的,调用 s3.intern() 后,常量池中生成了一个 “11” 的对象。前面说到“永久代” 区域和正常的 Java 堆区域是完全分开的,所以 s3 和 s4 的字符串引用地址是不同的。再来说 s1 和 s2 ,上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 Java 堆区域。所以 s1 和 s2 拿到的字符串引用也是不同的,即使调用 s1.intern() 也是没有任何关系的。
而在 JDK 7 及更高版本中,字符串常量池从“永久代”区域中移到了 Java 堆区域中,在 JDK 8 开始直接取消了 “永久代” 区域,使用了一个叫 “元空间” 的区域进行取代。在调用 s3.intern() 后,就不需要再拷贝字符串的实例到 “永久代” 了,而是直接在字符串常量池中记录一下首次出现的实例引用即可,所以 s3 和 s4 拿到的字符串引用是相同的。
使用 getBytes() 相关的转换时根据业务需要建议指定编码方式,如果不指定则看看 JVM 参数里有没有指定 file.encoding 参数;如果 JVM 没有指定,那使用的默认编码就是运行的操作系统环境的编码,那这个编码就变得不确定了。
常见的编码 iso8859-1 是单字节编码,UTF-8 是变长的编码。
Kafka 是消息引擎系統,也是分布式实时流式处理平台。而流式处理框架的优势在于更容易实现端到端的正确性,轻量型,嵌入式流式计算的定位;
在开始前,首先准备好自己的 docker 环境,可以安装 Docker Desktop.
为了更方便的搭建学习环境,推荐使用 confluent 公司社区版 docker 镜像。
对于 confluent 版本和 apache 版本对照表见:Confluent Platform and Apache Kafka Compatibility
docker-compose.yml,并写入如下内容:---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.1
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1docker-compose up -d 启动;docker-compose down 可以关闭创建好的集群;实践
原理
面向对象是将事物进行抽象化,分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
面向对象易复用、易维护、易扩展,具有封装、继承、抽象、多态的特性,可以设计出高内聚、低耦合的系统。但是,面向对象性能比面向过程低。
面向过程更接近正常人的逻辑思维模式,将一个问题的解决方案拆解成一个个步骤,然后用函数把这些步骤进行实现,使用的时候一个一个依次调用执行。
面向过程相对于面向对象而言,代码重用性低,扩展性差,后期维护难度比较大,但性能相对面向对象较高。
Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译半解析语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码。
而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。
HTTP 通信使用的是明文进行传输,存在安全性问题,而 HTTPS 是在 HTTP 基础上进行了安全性增强。
HTTP 默认端口是 80,HTTPS 默认端口是 443。
HTTP 存在以下安全性问题:
HTTPS 在 HTTP 基础上增加了 SSL/TLS 通信,让 HTTP 先和 SSL/TLS(Secure Sockets Layer)通信,再由 SSL/TLS 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
(HTTPS 在传统的 HTTP 和 TCP 之间加了一层用于加密解密的 SSL/TLS 层(安全套接层 Secure Sockets Layer/安全传输层Transport Layer Security)层。)
HTTPS 采用的是对称密钥加密和非对称密钥加密混合的方式进行通信。使用非对称密钥加密方式,传输对称密钥加密方式所需要的密钥(Secret Key),然后获取到密钥后,再使用对称密钥加密方式进行通信。这样既保证了安全性,又保证了效率。
对称密钥加密,加密和解密使用同一密钥,运算速度快,但无法安全地将密钥传输给通信方。
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥,可以更安全地将公开密钥传输给通信发送方,但运算速度慢。
HTTPS 通过使用证书来对通信方进行认证。使用 HTTPS 必须要有一套自己的数字证书(包含公钥和私钥)。
在进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
证书需要向 CA 进行申请。数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
SSL 提供报文摘要功能来进行完整性保护。HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
JRE,也就是 Java 运行环境,它包含了 JVM 和 Java 类库,以及一些模块等,是运行已编译的 Java 程序所需内容的集合,它不能用于构建新程序。
JDK 是 Java Development Kit 的缩写,它可以看作是 JRE 的一个超集,提供了更多工具,如编译器、各种诊断工具等,它能够创建和编译程序。
Single Dispatch ,中文翻译是单分派,指的是执行哪个对象的方法,由对象的运行时类型来决定;执行对象的哪个方法,由方法参数的编译时类型来决定。即执行哪个对象的哪个方法,只跟“对象”的运行时类型有关。
Double Dispatch,中文翻译是双分派,指的是执行哪个对象的方法,由对象的运行时类来决定,执行对象的哪个方法,由方法参数的运行时类型来决定。 即执行哪个对象的哪个方法,跟“对象”和“方法参数”两者的运行时类型有关。
Java 支持多态特性,代码可以在运行时获得对象的实际类型,然后根据实际类型决定调用哪个方法。尽管 Java 支持函数重载,但 Java 设计的函数重载的语法规则是,并不是在运行时,根据传递进函数的参数的实际类型,来决定调用哪个重载函数,而是在编译时,根据传递进函数的参数的声明类型(也就是前面提到的编译时类型),来决定调用哪个重载函数。也就是说,具体执行哪个对象的哪个方法,只跟对象的运行时类型有关,跟参数的运行时类型无关。所以,Java 语言只支持 Single Dispatch。
下面,通过一个示列来理解,代码如下:
public class ParentClass {
public void f() {
System.out.println("parent");
}
}
public class ChildClass extends ParentClass {
@Override
public void f() {
System.out.println("child");
}
}
public class SingleDispatchClass {
public void overloadFun(ParentClass p) {
System.out.print("overloadFun(ParentClass p) ==>");
p.f();
}
public void overloadFun(ChildClass c) {
System.out.print("overloadFun(ChildClass c) ==>");
c.f();
}
public void fun(ParentClass p) {
p.f();
}
}
public class Main {
public static void main(String[] args) {
SingleDispatchClass singleDispatchClass = new SingleDispatchClass();
ParentClass c = new ChildClass();
singleDispatchClass.fun(c);
singleDispatchClass.overloadFun(c);
}
}
// 执行结果
child
overloadFun(ParentClass p) ==>child通过程序运行的结果可以看出,singleDispatchClass.fun(c) 函数执行 c 的实际类的 f() 函数,也就是 ChildClass 的 f() 函数。singleDispatchClass.overloadFun(c) 函数,执行的是重载函数中的 overloadFun(ParentClass p),是根据 p 的声明类型来决定匹配哪个重载函数。
Exception 和 Error 都继承 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出或捕获。
Exception 和 Error 体现了 Java 平台对不同异常情况的分类。Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应的处理。Error 用来表示编译时和系统错误,绝大部分 Error 都会导致程序处于非正常、不可恢复状态,比如 OutOfMemoryError。
Exception 又分为可检查异常和未检查异常。可检查异常必须在代码中显示捕获,在编译期就会发现;未检查异常就是所谓运行时异常,如 NullPointException 异常,一般是编码上的逻辑错误。
问题:ClassNotFoundException 与 NoClassDefFoundError 的区别
ClassNotFoundException:当应用程序运行的过程中尝试使用类加载器去加载 Class 文件的时候,如果没有在 classpath 中查找到指定的类,就会抛出 ClassNotFoundException。(即在动态加载 Class 文件的时候找不到类,就会抛出此异常)一般在执行Class.forName()、ClassLoader.loadClass() 或 ClassLoader.findSystemClass() 的时候抛出。
NoClassDefFoundError:如果这个类在编译时是可用的,但是在运行时找不到这个类的定义的时候,JVM 就会抛出一个NoClassDefFoundError 错误。
OSI 七层模型:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
TCP/IP 四层模型:应用层、传输层、网络层、数据链路层。
五层模型:应用层、传输层、网络层、数据链路层、物理层。

物理层:通过网线、光缆等这种物理方式将电脑连接起来。传递的数据是比特流,0101010100。
数据链路层: 首先把比特流封装成数据帧的格式,对0、1进行分组。电脑连接起来之后,数据都经过网卡来传输,而网卡上定义了全世界唯一的 MAC 地址;然后再通过广播的形式向局域网内所有电脑发送数据,再根据数据中 MAC 地址和自身对比判断是否是发给自己的。
网络层:广播的形式太低效,为了区分哪些 MAC 地址属于同一个子网,网络层定义了 IP 和子网掩码,通过对 IP 和子网掩码进行与运算就知道是否是同一个子网,再通过路由器和交换机进行传输。IP 协议属于网络层的协议。
传输层:有了网络层的 MAC+IP 地址之后,为了确定数据包是从哪个进程发送过来的,就需要端口号,通过端口来建立通信,比如 TCP 和 UDP 属于这一层的协议。
会话层:负责建立和断开连接。
表示层:为了使得数据能够被其他的计算机理解,再次将数据转换成另外一种格式,比如文字、视频、图片等。
应用层:最高层,面对用户,提供计算机网络与最终呈现给用户的界面。
数据链路层:也有称作网络访问层、网络接口层,它包含了 OSI 模型的物理层和数据链路层,把电脑连接起来。
网络层:也叫做 IP 层,处理 IP 数据包的传输、路由,建立主机间的通信。
传输层:为两台主机设备提供端到端的通信。
应用层:包含 OSI 的会话层、表示层和应用层,提供了一些常用的协议规范,比如 FTP、SMPT、HTTP 等。
总结下来,就是物理层通过物理手段把电脑连接起来;数据链路层则对比特流的数据进行分组;网络层来建立主机到主机的通信;传输层建立端口到端口的通信;应用层最终负责建立连接,数据格式转换,最终呈现给用户。
原子操作(atomic operation)意为"不可被中断的一个或一系列操作"。
处理器和物理内存之间的通信速度要远慢于处理器间的处理速度,所以处理器有自己的内部缓存。在执行操作时,频繁使用的内存数据会缓存在处理器的 L1、L2 和 L3 高速缓存中,以加快频繁读取的速度,如下图:

一般情况下,一个单核处理器能自我保证基本的内存操作是原子性的,当一个线程读取一个字节时,所有进程和线程看到的字节都是同一个缓存里的字节,其它线程不能访问这个字节的内存地址。
但现在的服务器通常是多处理器,并且每个处理器都是多核的。每个处理器维护了一块字节的内存,每个内核维护了一块字节的缓存,这时候多线程并发就会存在缓存不一致的问题,从而导致数据不一致。
但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性,比如跨总线宽度,跨多个缓存行,跨页表的访问。
所谓总线锁就是使用处理器提供一个提供的一个 LOCK # 信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占共享内存。
但是总线锁定把 CPU 和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,可能导致大量阻塞,从而增加系统的性能开销。
所谓“缓存锁定”就是如果缓存在处理器缓存行中内存区域在 LOCK 操作期间被锁定,当它执行锁操作回写内存时,处理器不在总线上声明 LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时会使缓存行无效。
简单地说就是,当某个处理器对缓存中的共享变量进行了操作,就会通知其它处理器放弃存储该共享资源或者重新读取该共享资源。
但是有两种情况下处理器不会使用缓存锁定:
缓存一致性协议(MESI)
当 CPU 写数据时,如果发现操作的变量是共享变量,即在其他 CPU 中也存在该变量的副本,会发出信号通知其他 CPU 将该变量的缓存行置为无效状态,因此当其他 CPU 需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
Java 中可以通过锁和循环 CAS 的方式来实现原子操作。
锁机制保证了只有获得锁的线程能够操作锁定的内存区域。JVM 内部实现了很多种锁机制,有偏向锁,轻量级锁和互斥锁,有意思的是除了偏向锁,JVM 实现锁的方式都用到的循环 CAS,当一个线程想进入同步块的时候使用循环 CAS 的方式来获取锁,当它退出同步块的时候使用循环 CAS 释放锁。
JVM 中的 CAS 操作是利用了处理器提供的 cmpxchg 指令实现的。自旋 CAS 实现的基本思路就是循环进行 CAS 操作直到成功为止。
总结:静态的优先于非静态的。其中,静态变量和静态代码的初始化顺序取决于它们在类中出现的顺序;变量和初始化块的初始化顺序也取决于它们在类中出现的顺序。
因为子类对象可能需要调用到从父类继承下来的东西,所以那些东西必须要先完成。父类构造函数必须在子类构造函数之前初始化。
CAS(Compare and Swap) 就是一次比较并交换的过程,是一种乐观锁的实现方式。CAS 有三个操作数:内存值(V)、预期原值(A)和新值(B)。使用预期原值与内存值进行比较,如果内存值与预期原值相等,就使用一个新值替换当前的内存值。如果不相等,则会继续循环重试,直到赋值成功。
java.util.concurrent 包中的原子类就是通过 CAS 来实现了乐观锁。
JNI(Java Native Interface) 中是借助一个 CPU 硬件支持的机器指令(cmpxchg 指令)完成 CAS 操作,属于原子操作,可以保证多个线程都能够看到同一个变量的修改值,不会造成所谓的数据不一致问题。Unsafe 提供的 CAS 方法(如compareAndSwapXXX)底层实现即为 CPU 的 cmpxchg 指令。
设计层面上,抽象类是为了代码复用,而接口更侧重于解耦。抽象类是一种自下而上的设计思路,先有子类的代码重复,然后再抽象成上层的父类。而接口正好相反,它是一种自上而下的设计思路,一般都是先设计接口,再去考虑具体的实现。
开发工具
JVM 分析工具
伪共享,指的是由于共享缓存行导致缓存无效的场景。
伪共享和 CPU 内部的缓存有关,缓存内部是按照缓存行(Cache Line)管理的,缓存行的大小通常是 64 个字节,因此不足 64 字节的变量会共享同一个缓存行,而 CPU 从内存中加载变量 X 时,会同时把缓存行中的其他变量一起加载出来。并且,当 CPU 对缓存行中的任意一个变量进行修改时,都会导致其所在的所有核上的缓存行均失效。
为了更好地利用缓存,我们可以使用缓存行填充技术, 即每个变量独占一个缓存行,不与其他变量共享缓存行,来避免伪共享。
所谓强引用(Strongly Reference),就是普通对象引用,即“Object obj = new Object()” 这种引用关系。无论在任何情况下,只要强引用关系还存在,垃圾收集器就永远不会回收掉被引用的对象。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用(Soft Reference),是一种相对强引用弱化一些的引用,用来描述一些还有用,但非必需的对象,只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象。JVM 会确保在发生内存溢出异常之前,回收软引用指向的对象,如果这次回收还没有足够的内存,才会抛出内存溢出异常。
软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用(Weak Reference)它的强度比软引用更弱,被弱引用关联的对象只能生存到下一次垃圾收集(GC)发生为止。当垃圾收集器开始工作时,不管当前内存是否足够,都会回收掉被弱引用关联的对象。
弱引用仅仅是提供一种访问在弱引用状态下对象的途径,可以用来构建一种没有特定约束的关系,比如,维护一种非强制性的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
虚引用(Phantom Reference)也称幻影引用,无法通过一个虚引用来访问与之关联的对象实例,且当对象仅被虚引用引用时,在任何发生 GC 的时候,其均可被回收,它的 get() 方法永远返回 null。对象设置虚引用关联的唯一目的只是为了能在这个对象被回收时收到一个系统通知,类似于回调通知。
PhantomReference 通常与引用队列 ReferenceQueue 结合使用,当一个被 PhantomReference 关联过的对象是虚可达时,垃圾收集器会把这些对象放到我们构造 PhantomReference 时关联的 ReferenceQueue 里面,然后我们可以去 ReferenceQueue 里取出这些对象,从而知道哪些对象在 GC 时被回收了或做一些额外的清理工作。
典型应用:
DirectByteBuffer 构造函数,创建 DirectByteBuffer 的时候,会构建 Cleaner 对象用于跟踪 DirectByteBuffer 对象的垃圾回收,以实现当 DirectByteBuffer 被垃圾回收时,分配的堆外内存一起被释放。
Cleaner 继承自 Java 虚引用 PhantomReference,通常虚引用与引用队列 ReferenceQueue 结合使用,可以实现虚引用关联对象被垃圾回收时能够进行系统通知、资源清理等功能。当某个被 Cleaner 引用的对象将被回收时,JVM 垃圾收集器会将此对象的引用放入到对象引用中的 pending 链表中,等待 Reference-Handler进行相关处理。其中,Reference-Handler 为一个拥有最高优先级的守护线程,会循环不断的处理 pending 链表中的对象引用,执行 Cleaner 的 clean 方法进行相关清理工作。
当 DirectByteBuffer 仅被 Cleaner 引用(即为虚引用)时,其可以在任意 GC 时段被回收。当 DirectByteBuffer 实例对象被回收时,在 Reference-Handler 线程操作中,会调用 Cleaner 的 clean 方法根据创建 Cleaner 时传入的 Deallocator 来进行堆外内存的释放。
如图所示

volatile 能保证变量的可见性,禁止指令重排序,但是无法保证原子性,使用了 Lock 前缀指令。atomic 类内部的值使用了 volatile 进行修饰,并且使用 CAS 算法来实现原子性操作,弥补了 volatile 的不足。
Java 并发包(java.util.concurrent)中大量使用了 CAS 操作,涉及到并发的地方都调用了 sun.misc.Unsafe 类方法进行 CAS 操作。JVM 中的 CAS 操作是通过 CPU 的 cmpxchg 指令实现(一条原子指令,也是一个 lock 前缀指令),不会造成所谓的数据不一致问题,Unsafe 提供的 CAS 方法,如 compareAndSwapXXX() 底层实现即为 CPU 指令 cmpxchg 指令。
atomic 类中 compareAndSet 和所有其他的诸如 getAndIncrement 这种读然后更新的操作拥有和 volatile 读、写一样的内存语义。
见 Java 官方文档:https://docs.oracle.com/javase/8/docs/api/

AtomicInteger 类部分源码
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset; // 字段 value 的内存偏移地址
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}UnSafe 类的 objectFieldOffset() 方法是一个本地方法,AtomicInteger 类中的静态字段 valueOffset 的值就通过该方法获取。 通过 valueOffset 字段的值可以定位 value 的内存地址。
既然 atomic 类中,compareAndSet() 同时具有 volatile 读和 volatile 写的内存语义,为什么 value 还需要被 volatile 修饰呢?
个人理解是,保证在调用 compareAndSet() 方法进行自旋 CAS 操作时, get() 方法获取的值永远是最新的。

lock 前缀
根据 IA32 架构软件开发者手册可以知道,lock 前缀的指令的作用:
intel 的手册对 lock 前缀的说明如下:
cmpxchg 指令
程序会根据当前处理器的类型来决定是否为 cmpxchg 指令添加 lock 前缀。如果程序是在多处理器上运行,就为 cmpxchg 指令加上 lock 前缀(lock cmpxchg)。反之,如果程序是在单处理器上运行,就省略 lock 前缀(单处理器自身会维护单处理器内的顺序一致性,不需要 lock 前缀提供的内存屏障效果)。
HTTP Cookie(也叫 Web Cookie或浏览器 Cookie)是服务器发送给用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上,用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。由于服务器指定 Cookie 后,浏览器的每次请求都会携带 Cookie 数据,会带来额外的性能开销(尤其是在移动环境下)。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
Cookie 主要用于以下三个方面:
Cookie 的生命周期
Cookie 的生命周期可以通过两种方式定义:
Session 代表着服务器和客户端一次会话的过程。Session 对象存储指定用户会话所需的属性及配置信息。当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的信息将不会丢失,而是在整个用户会话中一直存在下去。当客户端关闭会话,或者 Session 超时失效时会话结束。
HTTP 是无状态协议,使用浏览器与服务端进行交互时,浏览器并不知道是哪个用户在与服务端打交道。这个时候就需要有一个机制来告诉服务端,本次操作用户是否登录,是哪个用户在执行的操作,那这套机制的实现就需要 Cookie 和 Session 的配合。
如果浏览器禁止 Cookie,如何保证上面的机制正常运转?
xxx?SessionID=xxxx。在互联网公司为了可以支撑更大的流量,后端往往需要多台服务器共同来支撑前端用户请求,那如果用户在 A 服务器登录了,第二次请求跑到服务 B 就会出现登录失效问题。
分布式 Session 一般会有以下几种解决方案:
Nginx ip_hash 策略,服务端使用 Nginx 代理,每个请求按访问 IP 的 hash 分配,这样来自同一 IP 固定访问一个后台服务器,避免了在服务器 A 创建 Session,第二次分发到服务器 B 的现象。
Session 复制,任何一个服务器上的 Session 发生改变(增删改),该节点会把这个 Session 的所有内容序列化,然后广播给所有其它节点。
共享 Session,服务端无状态话,将用户的 Session 等信息使用缓存中间件来统一管理,保障分发到每一个服务器的响应结果都一致。
建议采用第三种方案。

git checkout 命令可用于切换版本号,也可以用于撤销工作空间的修改(没有 git add 前的修改)。
git checkout version_1.0 // 切换到 version_1.0
git checkout . // 撤销本次修改,还没有 git add 的修改
git checkout -b version_1.0 // 新建 version_1.0 分支,并切换到 version_1.0git commit --amend // 修改最近一次的 commit 的备注git branch 用于分支的操作。
git branch -b <分支名> 新建本地分支
git branch -m oldName newName 修改本地分支名
git branch -d <分支名> 删除本地分支
git push origin :<分支名> 删除远程分支git rebase 命令对一个分支进行变基操作,可以合并多次 commit 的记录,可以合并分支,但不会合并 commit 记录。
git merge 用于合并分支,commit 记录也会合并。
git rebase -i HEAD~4 // 合并最近 4 次的提交记录
git rebase <分支名> // 合并分支,不会将分支的 commit 记录合并git reset <commit_id> 用于撤销或回退还没有 push 到远程仓库的内容,会丢弃之前的提交历史。
git reset --soft HEAD~1

git reset --mixed HEAD~1

git reset --hard HEAD~1

如果想回滚提交到远程仓库的内容,可以使用(不推荐):
git reset --hard HEAD~1
git push -f // 强制推送到远程分支git revert <commit_id> 用于回退到指定版本。在当前提交后面,新增一次提交,抵消掉上一次提交导致的所有变化。它不会改变过去的历史,所以是首选方式,没有任何丢失代码的风险。另外,已经 push 的内容如果要回滚,只能使用 revert。
git revert HEAD // 回退到上一个版本,当前版本内容全部消失
git push // 提交到远程分支git reflog 用于查看本地的操作记录,是恢复本地历史的强力工具。简单地说,可以通过它恢复丢失的内容,比如被 reset 丢弃掉的 commit、被删掉的分支等。
恢复丢弃的 commit

恢复删除的分支

最后,回滚操作都是借助 commit log 进行的,所以清晰、有意义的 commit log 是非常有帮助的。
Linux 系统的体系结构,分为用户空间(应用程序的活动空间)和内核。
所有的程序都在用户空间运行,进入用户运行状态也就是用户态,但是很多操作可能涉及内核运行,比如 I/O,就会进入内核运行状态(内核态)。

大致流程:
AbstractQueuedSynchronizer 简称 AQS,是一个用于构建锁和同步容器的框架。事实上 concurrent 包内许多类都是基于 AQS 构建,例如 ReentrantLock,Semaphore,CountDownLatch,ReentrantReadWriteLock,FutureTask 等。AQS 解决了在实现同步容器时设计的大量细节问题。
AQS 使用一个 FIFO 的队列表示排队等待锁的线程,它维护一个 status 的变量,每个节点维护一个 waitstatus 的变量,当线程获取到锁的时候,队列的 status 置为 1,此线程执行完了,那么它的 waitstatus 为 -1;队列头部的线程执行完毕之后,它会调用它的后继的线程。
AQS 核心**是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是 CLH 队列的变体实现的,将暂时获取不到锁的线程加入到队列中。
CLH:Craig、Landin and Hagersten 队列,是单向链表,AQS 中的队列是 CLH 变体的虚拟双向队列(FIFO),AQS 是通过将每条请求共享资源的线程封装成一个节点来实现锁的分配。
原理图:

AQS 使用一个 volatile 修饰的 int 类型的成员变量 state 来表示同步状态,用于展示当前临界资源的获锁情况,通过内置的 FIFO 队列来完成资源获取的排队工作,通过 CAS 完成对 State 值的修改。
/**
* The synchronization state.
*/
private volatile int state;protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
protected final void setState(int newState) {
state = newState; // 当对基本类型的变量进行直接赋值时,如果加了 volatile 就可以保证它的线程安全
}AQS 是一个用于构建锁、同步器等线程协作工具类的框架,很多用于线程协作的工具类都可以基于 AQS 很方便的被写出来,可以让更上层的开发极大的减少工作量,避免重复造轮子,同时也避免了上层因处理不当而导致的线程安全问题。
AQS 屏蔽了线程协作的底层实现:
某个线程获取锁失败的后续流程是什么?
存在某种排队等候机制,使线程排队等待,并保持进行获取锁的可能。
当执行 acquire(1) 时,会通过 tryAcquire() 获取锁。在这种情况下,如果获取锁失败,就会调用 addWaiter() 加入到等待队列中去。
acquire 源码:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}排队等候机制队列是什么数据结构?
CLH 变体的 FIFO 双端队列,最主要的作用是存储等待的线程。
处于排队等候机制中的线程,什么时候可以有机会获取锁?
一个线程获取锁失败后,会被放入等待队列,acquireQueued 会把放入队列中的线程不断去获取锁,直到获取成功或者不再需要获取(中断)。
如果处于排队等候机制中的线程一直无法获取锁,需要一直等待么?
线程所在节点的状态会变成取消状态,取消状态的节点会从队列中释放。
Lock 函数通过 Acquire 方法进行加锁,具体是如何加锁的?
AQS 的 Acquire 会调用 tryAcquire 方法,tryAcquire 由各个自定义同步器实现,通过 tryAcquire 完成加锁过程。
静态代理,就是代理类在程序运行前就已经存在。静态代理实现时,需要定义接口或者父类,被代理类(即原始类)与代理类一起实现相同接口或者父类。
特点:静态代理的局限在于运行前必须编写好代理对象,如果需要代理的类很多的话,会增加维护成本。
JDK 动态代理,就是代理类在运行时才进行创建,底层是利用反射机制。JDK 动态代理实现时,是基于接口实现的,被代理类要实现同样的接口。
CGlib 代理模式是基于继承被代理类生成代理子类,不用实现接口。由于底层是基于 ASM 第三方框架,利用字节码技术生成代理类,然后重写父类的方法,性能上比使用 Java 反射要高。
CGLib 不能对声明为 final 的方法进行代理, 因为 CGLib 原理是动态生成被代理类的子类,是基于继承实现的。
Unsafe 是位于 sun.misc 包下的一个类,主要提供一些用于执行低级别、不安全操作的方法,如直接访问系统内存资源、自主管理内存资源等,这些方法在提升 Java 运行效率、增强 Java 语言底层资源操作能力方面起到了很大的作用。但由于 Unsafe 类使 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过度、不正确使用 Unsafe 类会使得程序出错的概率变大,使得 Java 这种安全的语言变得不再“安全”,因此对 Unsafe 的使用一定要慎重。
Unsafe 类是一单例实现,提供静态方法 getUnsafe 获取 Unsafe 实例,当且仅当调用 getUnsafe 方法的类是引导类加载器所加载时才合法,否则抛出 SecurityException 异常。
Unsafe 部分源码:
public final class Unsafe {
// 单例对象
private static final Unsafe theUnsafe;
private Unsafe() {
}
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
// 仅在引导类加载器`BootstrapClassLoader`加载时才合法
if(!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
}Unsafe 提供的 API 大致可分为内存操作、CAS、Class 相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类。

这部分主要包含堆外内存的分配、拷贝、释放、给定地址值操作等方法。
通常,我们在 Java 中创建的对象都处于堆内内存(heap)中,堆内内存是由 JVM 所管控的 Java 进程内存,并且它们遵循 JVM 的内存管理机制,JVM 会采用垃圾回收机制统一管理堆内存。与之相对的是堆外内存,存在于 JVM 管控之外的内存区域,Java 中对堆外内存的操作,依赖于 Unsafe 提供的操作堆外内存的 native 方法。
// 分配内存, 相当于 C++ 的 malloc 函数
public native long allocateMemory(long bytes);
// 扩充内存
public native long reallocateMemory(long address, long bytes);
// 释放内存
public native void freeMemory(long address);
// 在给定的内存块中设置值
public native void setMemory(Object o, long offset, long bytes, byte value);
// 内存拷贝
public native void copyMemory(Object srcBase, long srcOffset, Object destBase, long destOffset, long bytes);
// 获取给定地址值,忽略修饰限定符的访问限制。与此类似操作还有: getInt,getDouble,getLong,getChar等
public native Object getObject(Object o, long offset);
// 为给定地址设置值,忽略修饰限定符的访问限制,与此类似操作还有: putInt,putDouble,putLong,putChar等
public native void putObject(Object o, long offset, Object x);
// 获取给定地址的 byte 类型的值(当且仅当该内存地址是 allocateMemory 分配时,此方法结果为确定的)
public native byte getByte(long address);
// 为给定地址设置 byte 类型的值(当且仅当该内存地址是 allocateMemory 分配时,此方法结果才是确定的)
public native void putByte(long address, byte x);使用堆外内存的原因:
- 对垃圾回收停顿的改善。由于堆外内存是直接受操作系统管理而不是 JVM,所以当我们使用堆外内存时,即可保持较小的堆内内存规模。从而在 GC 时减少回收停顿对于应用的影响。
- 提升程序 I/O 操作的性能。通常在 I/O 通信过程中,会存在堆内内存到堆外内存的数据拷贝操作,对于需要频繁进行内存间数据拷贝且生命周期较短的暂存数据,都建议存储到堆外内存。
典型应用
DirectByteBuffer 是 Java 用于实现堆外内存的一个重要类,通常用在通信过程中做缓冲池,如在 Netty、MINA 等 NIO 框架中应用广泛。DirectByteBuffer 对于堆外内存的创建、使用、销毁等逻辑均由 Unsafe 提供的堆外内存 API 来实现。使用DirectByteBuffer 构造函数,创建 DirectByteBuffer 的时候,通过 Unsafe.allocateMemory 分配内存、Unsafe.setMemory 进行内存初始化,而后构建 Cleaner 对象用于跟踪 DirectByteBuffer 对象的垃圾回收,以实现当 DirectByteBuffer 被垃圾回收时,分配的堆外内存一起被释放。
Unsafe 提供了一些 CAS 相关操作的方法,如下:
/**
* CAS
* @param o 包含要修改field的对象
* @param offset 对象中某field的偏移量
* @param expected 期望值
* @param update 更新值
* @return true | false
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);典型应用
CAS 在 java.util.concurrent.atomic 相关类、Java AQS、CurrentHashMap 等实现上有非常广泛的应用。比如,AtomicInteger 的实现中,AtomicInteger 初始化时,在静态代码块中通过 Unsafe 的 objectFieldOffset 方法获取 valueOffset。在 AtomicInteger 中提供的线程安全方法中,通过字段 valueOffset 的值可以定位到 AtomicInteger 对象中 value 的内存地址,从而可以根据 CAS 实现对 value 字段的原子操作。
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
}这部分,包括线程挂起、恢复、锁机制等方法。
// 取消阻塞线程
public native void unpark(Object thread);
// 阻塞线程
public native void park(boolean isAbsolute, long time);方法 park、unpark 即可实现线程的挂起与恢复,将一个线程进行挂起是通过 park 方法实现的,调用 park 方法后,线程将一直阻塞直到超时或者中断等条件出现;unpark 可以终止一个挂起的线程,使其恢复正常。
典型应用
Java 锁和同步器框架的核心类 AbstractQueuedSynchronizer,就是通过调用 LockSupport.park() 和 LockSupport.unpark() 实现线程的阻塞和唤醒的,而 LockSupport 的 park、unpark 方法实际是调用 Unsafe 的 park、unpark 方式来实现。
此部分主要提供 Class 和它的静态字段的操作相关方法,包含静态字段内存定位、定义类、定义匿名类、检验&确保初始化等。
典型应用
从 Java 8 开始,JDK 使用 invokedynamic 及 VM Anonymous Class 结合来实现 Java 语言层面上的 Lambda 表达式。
在 Lambda 表达式实现中,通过 invokedynamic 指令调用引导方法(BootstrapMethods)生成调用点,在此过程中,会通过 ASM 动态生成字节码,而后利用 Unsafe 的 defineAnonymousClass 方法定义实现相应的函数式接口的匿名类,然后再实例化此匿名类,并返回与此匿名类中函数式方法的方法句柄关联的调用点;而后可以通过此调用点实现调用相应 Lambda 表达式定义逻辑的功能。
此部分主要包含对象成员属性相关操作及非常规的对象实例化方式等相关方法。
// 绕过构造方法、初始化代码来创建对象
public native Object allocateInstance(Class<?> cls) throws InstantiationException;典型应用
这部分主要介绍与数据操作相关的 arrayBaseOffset 与 arrayIndexScale 这两个方法,两者配合起来使用,即可定位数组中每个元素在内存中的位置。
// 返回数组中第一个元素的偏移地址
public native int arrayBaseOffset(Class<?> arrayClass);
// 返回数组中一个元素占用的大小
public native int arrayIndexScale(Class<?> arrayClass);典型应用
这两个与数据操作相关的方法,在 java.util.concurrent.atomic 包下的 AtomicIntegerArray(可以实现对 Integer 数组中每个元素的原子性操作)中有典型的应用。
AtomicIntegerArray 部分源码
public class AtomicIntegerArray implements java.io.Serializable {
private static final long serialVersionUID = 2862133569453604235L;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final int base = unsafe.arrayBaseOffset(int[].class); // 获取数组元素的首地址
private static final int shift;
private final int[] array;
static {
int scale = unsafe.arrayIndexScale(int[].class); // 获取每个元素所占大小
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
private long checkedByteOffset(int i) {
if (i < 0 || i >= array.length)
throw new IndexOutOfBoundsException("index " + i);
return byteOffset(i);
}
private static long byteOffset(int i) {
return ((long) i << shift) + base; // 通过数据元素的位置计算偏移地址
}
public final int getAndSet(int i, int newValue) {
return unsafe.getAndSetInt(array, checkedByteOffset(i), newValue);
}
}从源码可知,通过 Unsafe 的 arrayBaseOffset、arrayIndexScale 分别获取数组首元素的偏移地址 base 及单个元素大小因子scale。后续相关原子性操作,均依赖于这两个值进行数组中元素的定位,getAndSet 方法即通过 checkedByteOffset 方法获取某数组元素的偏移地址,而后通过 CAS 实现原子性操作。
在 Java 8 中引入,用于定义内存屏障(也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作),避免代码重排序。
// 内存屏障,禁止 load 操作重排序。屏障前的 load 操作不能被重排序到屏障后,屏障后的 load 操作不能被重排序到屏障前
public native void loadFence();
// 内存屏障,禁止 store 操作重排序。屏障前的 store 操作不能被重排序到屏障后,屏障后的 store 操作不能被重排序到屏障前
public native void storeFence();
// 内存屏障,禁止 load、store 操作重排序
public native void fullFence();典型应用
在 Java 8 中引入了一种锁的新机制——StampedLock,它可以看成是读写锁的一个改进版本。StampedLock 提供了一种乐观读锁的实现,这种乐观读锁类似于无锁的操作,完全不会阻塞写线程获取写锁,从而缓解读多写少时写线程“饥饿”现象。
StampedLock 的 validate 方法会通过 Unsafe 的 loadFence 方法加入一个 load 内存屏障。
public boolean validate(long stamp) {
U.loadFence(); // load 屏障
return (stamp & SBITS) == (state & SBITS);
}这部分包含两个获取系统相关信息的方法。
// 返回系统指针的大小。返回值为 4(32 位系统)或 8(64 位系统)。
public native int addressSize();
// 内存页的大小,此值为 2 的幂次方。
public native int pageSize();为 java.nio 下的工具类 Bits 中计算待申请内存所需内存页数量的静态方法,其依赖于 Unsafe 中 pageSize 方法获取系统内存页大小实现后续计算逻辑。
| 区别 | synchronized | ReentrantLock |
|---|---|---|
| 实现方式 | JVM 层面 | JDK 层面 |
| 锁实现机制 | 监视器模式 | 依赖 AQS |
| 锁类型 | 非公平锁 | 公平锁 & 非公平锁 |
| 灵活性 | 代码简单,自动获取、释放锁 | 相对繁琐,需要手动获取、释放锁 |
| 可重入性 | 可重入 | 可重入 |
| 条件队列 | 关联一个条件队列 | 可关联多个 Condition 条件对象 |
| 作用位置 | 可作用在方法和代码块 | 只能用在代码块 |
| 获取、释放锁的方式 | monitorenter/monitorexit(修饰代码块)、ACC_SYNCHRONIZED(修饰方法) | 尝试非阻塞获取锁 tryLock()、超时获取锁 tryLock(long timeout,TimeUnit unit)、unlock() |
| 获取锁的结果 | 无法得知 | 可知,tryLock( ) 返回 boolean |
| 使用注意事项 | 1、锁对象不能为空(锁保存在对象头中,null 没有对象头)2、作用域不宜过大 | 1、切记要在 finally 中 unlock(),否则会形成死锁 2、不要将获取锁的过程写在 try 块内,因为如果在获取锁时发生了异常,异常抛出的同时,也会导致锁无故被释放。 |
ReentrantLock 是等待可中断的,当持有锁的线程长时间不释放锁的时候,等待中的线程可以选择放弃等待,转而处理其他的任务。
可再(重)入:它是表示当一个线程试图获取一个它已经获取的锁时,这个获取动作就自动成功,这是对锁获取粒度的一个概念,也就是锁的持有是以线程为单位而不是基于调用次数。
补充:ReentrantLock 基于 AQS 和 CAS 实现的,在加锁的时候通过 CAS 算法,将线程对象放到一个双向链表中,然后每次取出链表中的头节点,看这个节点是否和当前线程相等,是否相等比较的是线程的 ID。
final 关键字可以用在类、方法、字段上。
final 作用
finally 则是 Java 保证重点代码一定要被执行的一种机制。我们可以使用 try-finally 或者 try-catch-finally 来进行类似关闭 JDBC 连接、保证 unlock 锁等动作。
要点
finally 语句在 return 语句执行之后,return 返回之前执行的,即在 finally 执行完后才返回值;
finally 块中的 return 语句会覆盖 try 块中的 return 返回;
try 块中的 return 语句和 catch 块中的 return 语句效果相同;
finally 块里对 return 值的修改语句可能会影响 try 块中的 return 的值;
下面 finally 里面的代码是不会被执行的
try {
// do something
System.exit(1);
} finally {
System.out.println(“Print from finally”);
}finalize 是基础类 java.lang.Object 的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。finalize 本质上成为了快速回收的阻碍者,可能导致你的对象经过多个垃圾收集周期才能被回收。finalize 机制现在已经不推荐使用,并且在 JDK 9 开始被标记为 deprecated。
char 是基本类型,基本类型所占的字节数是固定的,Java 中 char 固定占 2 个字节,使用单引号包裹,字符常量相当于一个整型值,可以参与运算。
String 是引用类型,一个英文占 1 个字节,一个汉字占 3 个字节(UTF-8 编码),使用双引号包裹。
示列:
public static void main(String[] args) {
char a = 'a';
String b = "a";
System.out.println(a + 10); // 107
System.out.println(b + 10); // a10
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.