
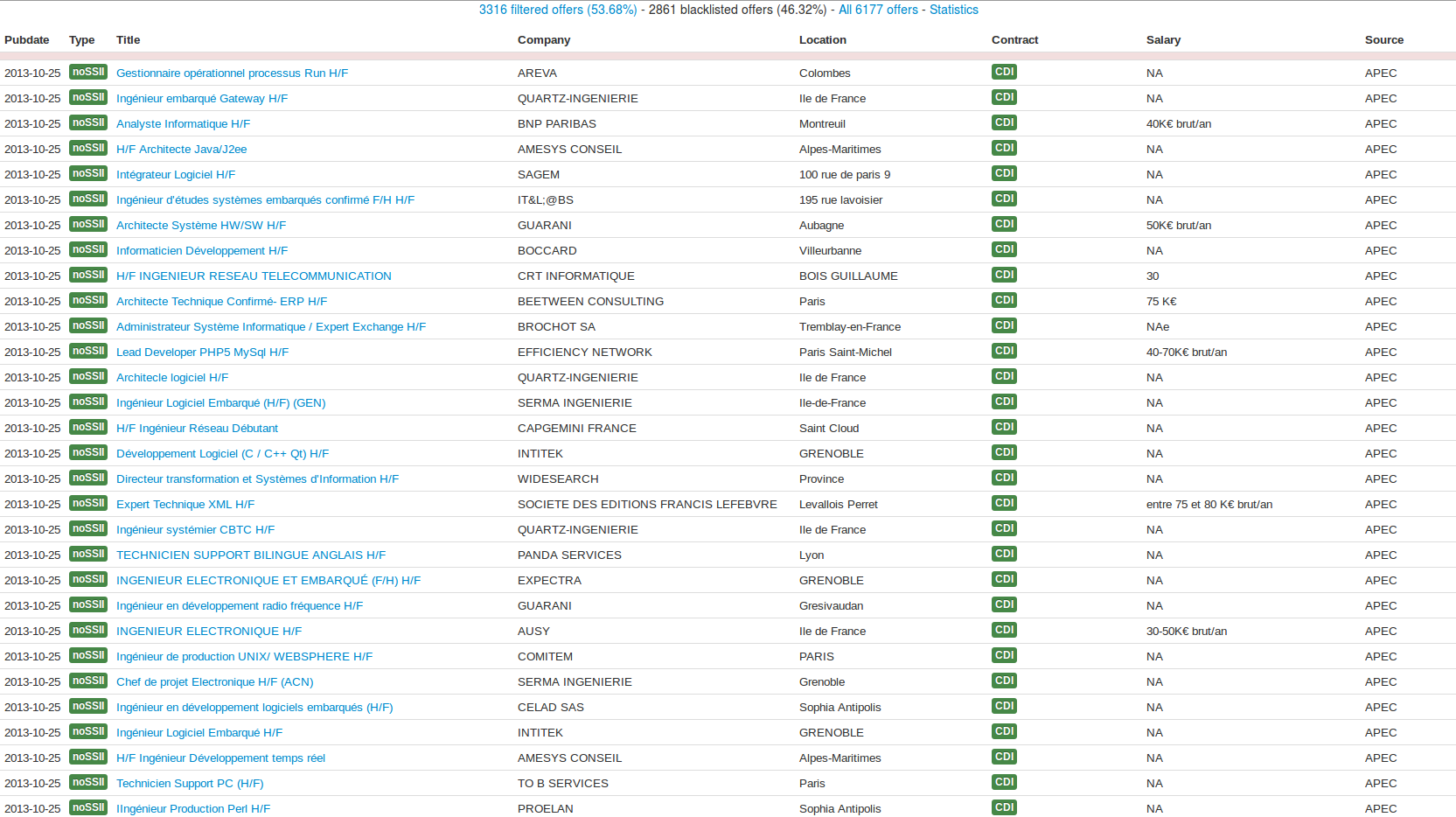
JobCatcher is a daemon that retrieves job offers from multiple job boards feeds and generates custom RSS feeds and HTML reports for you. This is a decentralized software meant to run of your own server.
JobCatcher comes with a filter feature, so you can filter company names with black or whitelists.
Think of it as a RSS feed reader with filter feature.
I would like this software to be under GPLv2 License. But I need to check if this is compatible with dependencies I've choosen.
The project is fully in development and many features need to be implemented. It is developed in Python. This is my first time I use Python on a non-basic project. So I guess my code is not so pythonic ... yet. Feel free to help me or show me mistakes I could have made or improvements I could do.
python-html2text, python-requests, python-beautifulsoup
--all sync the blacklist, fetch the offers and generates reports.
--feeds download the all feeds in the config
--feed=JOBBOARD download only the feed from JOBBOARD in the config
--pages download the all pages in the config
--page=JOBBOARD download only the pages from JOBBOARD in the config
--inserts inserts all pages to offers
--insert=JOBBOARD insert JOBBOARD pages to offers
--moves move datas to offer
--move=JOBBOARD move JOBBOARD datas to offer
--clean=JOBBOARD clean offers from JOBBOARD source
--report generate a full report
--version output version information and exit
Reports are generated into the local "www" directory.
I start jobcatcher.py -s manually with crontab for now. But this should change soon.
- Apec.fr (France)
- Cadreonline (France)
- Eures (Europe)
- PoleEmploi (France)
- Progressive Recruitment (France)
- RegionsJob
- CentreJob (France)
- NordJob (France)
- PacaJob (France)
- RhoneJob (France)
- EstJob (France)
- OuestJob (France)
- SudOuestJob (France)
- ParisJob (France)
- Lolix.org (France)
- Linux.com (Int.)
- L'eXpress-Board (France)
- Remixjobs.com (France)
# Install a packages
apt-get update
apt-get install sqlite3 python-pip git
pip install virtualenv virtualenvwrapper
# Configure virtualenvwrapper
cat << EOF >> ~/.bashrc
export WORKON_HOME=$HOME/.virtualenvs
export PROJECT_HOME=$HOME/Devel
source /usr/local/bin/virtualenvwrapper.sh
EOF
source ~/.bashrc
# Prepare jobcatcher environment
mkvirtualenv --no-site-packages -p /usr/bin/python2.7 jobcatcher
add2virtualenv /opt/JobCatcher
# Install jobcatcher project
cd opt
git clone -b unstable https://github.com/badele/JobCatcher.git
cd JobCatcher
pip install -r requirements.txt
Modify the config.py and execute
workon jobcatcher
python jobcatcher.py --all
Help us to add new job boards to JobCatcher ! :)
- Yoann Sculo - www.yoannsculo.fr
- Bruno Adelé - bruno.adele.im
- Yankel Scialom - github


































