"""
Build some nlp function as an package.
"""
def __init__(self,model_path="model/ch-corpus-3sg.bin",
rule_path="RuleMatcher/rule/",
stopword="jieba_dict/stopword.txt",
jieba_dic="jieba_dict/dict.txt.big",
jieba_user_dic="jieba_dict/userdict.txt"):
print("[Console] Building a console...")
cur_dir = os.getcwd()
curPath = os.path.dirname(__file__)
os.chdir(curPath)
# jieba custom setting.
self.init_jieba(jieba_dic, jieba_user_dic)
self.stopword = self.load_stopword(stopword)
# build the rulebase.
self.rb = rulebase.RuleBase()
print("[Console] Loading the word embedding model...")
try:
self.rb.load_model(model_path)
# models.Word2Vec.load('word2vec.model')
except FileNotFoundError as e:
print("[Console] 請確定詞向量模型有正確配置")
print(e)
exit()
except Exception as e:
print("[Gensim]")
print(e)
exit()
print("[Console] Loading pre-defined rules.")
self.rb.load_rules_from_dic(rule_path)
print("[Console] Initialized successfully :>")
os.chdir(cur_dir)
def listen(self):
#into interactive console
while True:
self.show_information()
choice = input('Your choice is: ')
choice = choice.lower()
if choice == 'e':
res = self.jieba_tf_idf()
for tag, weight in res:
print('%s %s' % (tag, weight))
elif choice == 'g':
res = self.jieba_textrank()
for tag, weight in res:
print('%s %s' % (tag, weight))
elif choice == 'p':
print(self.rb)
elif choice == 'r':
self.rb.load_rules('RuleMatcher/rule/',reload=True)
elif choice == 'd':
self.test_speech()
elif choice == 'm':
speech = input('Input a sentence:')
res,path = self.rule_match(speech)
self.write_output(speech,res,path)
elif choice == 'b':
exit()
elif choice == 's':
rule_id = input('Input a rule id:')
res = self.get_response(rule_id)
if res is not None:
print(res)
elif choice == 'o':
self.rb.output_as_json()
else:
print('[Opps!] No such choice: ' + choice + '.')
def jieba_textrank(self):
"""
Use textrank in jieba to extract keywords in a sentence.
"""
speech = input('Input a sentence: ')
return jieba.analyse.textrank(speech, withWeight=True, topK=20)
def jieba_tf_idf(self):
"""
Use tf/idf in jieba to extract keywords in a sentence
"""
speech = input('Input a sentence: ')
return jieba.analyse.extract_tags(speech, topK=20, withWeight=True)
def show_information(self):
print('Here is chatbot backend, enter your choice.')
print('- D)emo the data in speech.txt.')
print('- E)xtract the name entity.')
print('- G)ive me the TextRank.')
print('- M)atch a sentence with rules.')
print('- P)rint all rules in the rulebase.')
print('- R)eload the base rule.')
print('- O)utput all rules to rule.json.')
print('- S)how me a random response of a rule')
print('- B)ye.')
def init_jieba(self, seg_dic, userdic):
"""
jieba custom setting.
"""
jieba.load_userdict(userdic)
jieba.set_dictionary(seg_dic)
with open(userdic,'r',encoding='utf-8') as input:
for word in input:
word = word.strip('\n')
jieba.suggest_freq(word, True)
def load_stopword(self, path):
stopword = set()
with open(path,'r',encoding='utf-8') as stopword_list:
for sw in stopword_list:
sw = sw.strip('\n')
stopword.add(sw)
return stopword
def word_segment(self, sentence):
words = jieba.cut(sentence, HMM=False)
#clean up the stopword
keyword = []
for word in words:
if word not in self.stopword:
keyword.append(word)
return keyword
def rule_match(self, sentence, best_only=False, search_from=None, segmented=False):
"""
Match the sentence with rules.
Args:
- sentence : the string you want to match with rules.
- best_only : if True, only return the best matched rule.
- root : a domain name, then the rule match will start
at searching from that domain, not from forest roots.
- segmented : the sentence is segmented or not.
Return:
- a list of candiate rule
- the travel path of classification tree.
"""
keyword = []
if segmented:
keyword = sentence
else:
keyword = self.word_segment(sentence)
if search_from is None: # use for classification (rule matching).
result_list,path = self.rb.match(keyword,threshold=0.1)
else: # use for reasoning.
result_list,path = self.rb.match(keyword,threshold=0.1,root=search_from)
if best_only:
return [result_list[0], path]
else:
return [result_list, path]
def get_response(self, rule_id):
"""
Get a random response from the given rule's response'list.
"""
rule = self.rb.rules[rule_id]
res_num = rule.has_response()
if res_num == 0:
return None
else:
return rule.response[random.randrange(0,res_num)]
def test_speech(self):
"""
Try matching all sentence in 'example/output.txt'
"""
output = open('example/output.txt','w',encoding='utf-8')
# load sample data
with open('example/speech.txt','r',encoding='utf-8') as input:
for speech in input:
speech = speech.strip('\n')
result,path = self.rule_match(speech)
self.write_output(speech, result, path, output)
def write_output(self, org_speech, result, path, output = None):
"""
Show the matching result.
Args:
- org_speech: the original input string.
- result: a sorted array, refer match() in rulebase.py.
- path: the travel path in classification tree.
- output: expect as a file writer, if none, print
the result to stdio.
"""
result_information = ''
result_information += "Case# " + str(org_speech) + '\n'
result_information += "------------------\n"
for similarity,rule,matchee in result:
str_sim = '%.4f' % similarity
result_information += str_sim+'\t'+path+rule+'\t\t'+matchee+'\n'
result_information += "------------------\n"
if output is None:
print(result_information)
else:
output.write(result_information)
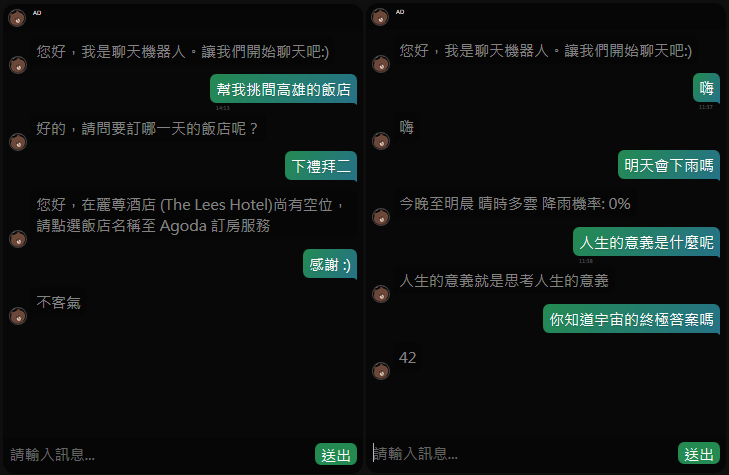

















































































































































































{kind=link}
{kind=link}