Hi, I have noticed an issue with your time warping and it's already mentioned in #12. I think that not how time warp should be (maybe my opinion is wrong since I'm not familiar with TF so I can't try tfa.image.sparse_image_warp to see the expected result myself).
# Reimplement from: https://stackoverflow.com/questions/61616810/how-to-do-cubic-spline-interpolation-and-integration-in-pytorch
def h_poly(t):
tt = t[None, :]**torch.arange(4, device=t.device)[:, None]
A = torch.tensor([
[1, 0, -3, 2],
[0, 1, -2, 1],
[0, 0, 3, -2],
[0, 0, -1, 1]
], dtype=t.dtype, device=t.device)
return A @ tt
def interp(x, y, xs):
m = (y[1:] - y[:-1]) / (x[1:] - x[:-1])
m = torch.cat([m[[0]], (m[1:] + m[:-1]) / 2, m[[-1]]])
idxs = torch.searchsorted(x[1:], xs)
dx = (x[idxs + 1] - x[idxs])
hh = h_poly((xs - x[idxs]) / dx)
return hh[0] * y[idxs] + hh[1] * m[idxs] * dx + hh[2] * y[idxs + 1] + hh[3] * m[idxs + 1] * dx
def time_warp(spec, W=50):
# Input spec has shape (channel, freq_bin, frame)
num_rows = spec.shape[-2]
spec_len = spec.shape[-1]
mid_y = num_rows//2
mid_x = spec_len//2
device = spec.device
pt = torch.randint(W, spec_len - W, (1,), device=device)
w = torch.randint(-W, W, (1,), device=device) # distance
# Make source control point with 3 points in time axis: 2 anchor points and 1 control point
src_ctr_pt_time = torch.tensor([0, warp_p, spec_len-1])
dst_ctr_pt_time = torch.tensor([0,warp_p-warp_d, spec_len-1])
dst_ctr_pt_time = dst_ctr_pt_time*2/(spec_len-1) - 1 # Normalize into the range [-1, 1] to match with grid_sample requirement
# Interpolate
src_ctr_pts = torch.linspace(0, spec_len-1, spec_len)
dst_ctr_pts= interp(src_ctr_pt_time ,dst_ctr_pt_time , src_ctr_pts)
# Destination
grid = torch.cat((ys.view(1,1,-1,1).expand(1,num_rows,-1,1),
torch.linspace(-1, 1, num_rows).view(-1,1,1).expand(1,-1,spec_len,1)), -1)
# warp
# unsqueeze since grid_sample require 4D tensor, meanwhile our tensor is only 3D
warped_spectro = torch.nn.functional.grid_sample(spec.unsqueeze(0), grid, align_corners=True)
return warped_spectro.squeeze(0)
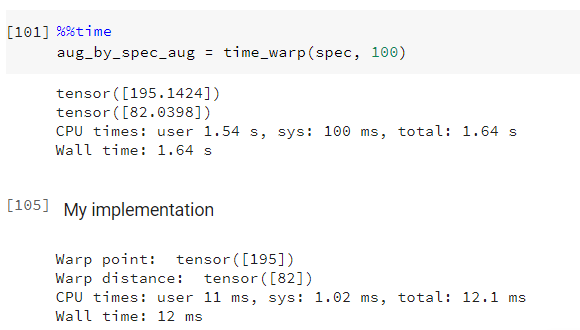
As you can see, the warped spectrogram looks more reasonable now when the warp distance is large (82 in comparison to audio with roughly 400 frames).
In addition to that, the run time is much faster. I run the code on colab using CPU and the original time_warp takes around 1.64s to run, while my implement takes only 12ms.
Lastly, I send you the final code that can perform augment on a batch of spectrograms at the end of this issue.
I haven't tested if this code uses less memory than sparse_image_warp or not, but the speed up given is a real deal. Hope this helps with simpler and faster implementation for our problem.
def h_poly(t):
tt = t.unsqueeze(-2)**torch.arange(4, device=t.device).view(-1,1)
A = torch.tensor([
[1, 0, -3, 2],
[0, 1, -2, 1],
[0, 0, 3, -2],
[0, 0, -1, 1]
], dtype=t.dtype, device=t.device)
return A @ tt
def hspline_interpolate_1D(x, y, xs):
'''
Input x and y must be of shape (batch, n) or (n)
'''
m = (y[..., 1:] - y[..., :-1]) / (x[..., 1:] - x[..., :-1])
m = torch.cat([m[...,[0]], (m[...,1:] + m[...,:-1]) / 2, m[...,[-1]]], -1)
idxs = torch.searchsorted(x[..., 1:], xs)
dx = (x.take_along_dim(idxs+1, dim=-1) - x.take_along_dim(idxs, dim=-1))
hh = h_poly((xs - x.take_along_dim(idxs, dim=-1)) / dx)
return hh[...,0,:] * y.take_along_dim(idxs, dim=-1) \
+ hh[...,1,:] * m.take_along_dim(idxs, dim=-1) * dx \
+ hh[...,2,:] * y.take_along_dim(idxs+1, dim=-1) \
+ hh[...,3,:] * m.take_along_dim(idxs+1, dim=-1) * dx
def time_warp(specs, W=50):
'''
Timewarp augmentation
param:
specs: spectrogram of size (batch, channel, freq_bin, length)
W: strength of warp
'''
device = specs.device
batch_size, _, num_rows, spec_len = specs.shape
mid_y = num_rows//2
mid_x = spec_len//2
warp_p = torch.randint(W, spec_len - W, (batch_size,), device=device)
# Uniform distribution from (0,W) with chance to be up to W negative
# warp_d = torch.randn(1)*W # Not using this since the paper author make random number with uniform distribution
warp_d = torch.randint(-W, W, (batch_size,), device=device)
x = torch.stack([torch.tensor([0], device=device).expand(batch_size),
warp_p, torch.tensor([spec_len-1], device=device).expand(batch_size)], 1)
y = torch.stack([torch.tensor([-1.], device=device).expand(batch_size),
(warp_p-warp_d)*2/(spec_len-1)-1, torch.tensor([1], device=device).expand(batch_size)], 1)
# Interpolate from 3 points to spec_len
xs = torch.linspace(0, spec_len-1, spec_len, device=device).unsqueeze(0).expand(batch_size, -1)
ys = hspline_interpolate_1D(x, y, xs)
grid = torch.cat(
(ys.view(batch_size,1,-1,1).expand(-1,num_rows,-1,-1),
torch.linspace(-1, 1, num_rows, device=device).view(-1,1,1).expand(batch_size,-1,spec_len,-1)), -1)
return torch.nn.functional.grid_sample(specs, grid, align_corners=True)