zhangjun / zhangjun.github.io Goto Github PK
View Code? Open in Web Editor NEWhttps://zhangjun.github.io
https://zhangjun.github.io




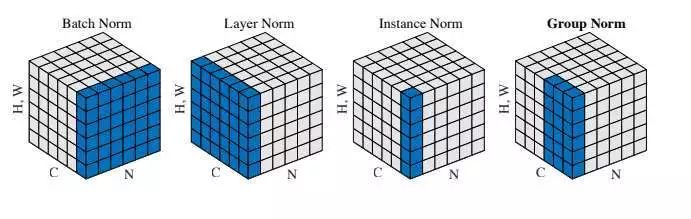
Batch Norm在通道维度进行归一化,最后得到C个统计量u,δ。假设输入特征为[N, H, W, C],在C的每个维度上对[N, H, W]计算其均值、方差,用于该维度上的归一化操作。
import numpy as np
import torch
import torch.nn as nn
from einops import rearrange, repeat, reduce
image = [np.random.randn(30, 40, 3) for _ in range(16)]
image = rearrange(image, 'b h w c -> b h w c')
# print(rearrange(image, 'b h w c -> b h w c').shape)
image_ = rearrange(image, 'b h w c -> (b h w) c')
mean = rearrange(image_.mean(axis=0), 'c -> 1 1 1 c')
std = rearrange(image_.std(axis=0), 'c -> 1 1 1 c')
y_ = (image - mean)/std
b, h, w, c = image.shape
bn = nn.BatchNorm2d(c, eps=1e-10, affine=False, track_running_stats=False)
y = bn(torch.from_numpy(image))
print('diff={}\n'.format(torch.abs(y - y_).max()))Layer Norm以样本为单位计算统计量,因此最后会得到N个u,δ。假设输入特征为[N, H, W, C],在N的每个维度上对[H, W,C]计算其均值、方差,用于该维度上的归一化操作。
import numpy as np
import torch
import torch.nn as nn
from einops import rearrange, repeat, reduce
x = torch.randn((6, 3, 20, 20))
b, c, h, w = x.shape
layer_norm = nn.LayerNorm([c, h, w], eps=1e-12, elementwise_affine=False)
y = layer_norm(x)
x_ = rearrange(x, 'b c h w -> (h w c) b')
mean = rearrange(x_.mean(axis=0), 'b -> b 1 1 1')
std = rearrange(x_.std(axis=0), 'b -> b 1 1 1')
y_ = (x - mean)/std
print('diff={}\n'.format(torch.abs(y - y_).max()))import numpy as np
import torch
import torch.nn as nn
from einops import rearrange, repeat, reduce
x = torch.randn((6, 3, 20, 20))
b, c, h, w = x.shape
instance_norm = nn.InstanceNorm2d(c, eps=1e-12, affine=False, track_running_stats=False)
y = instance_norm(x)
x_ = rearrange(x, 'b c h w -> b c (h w)')
# mean = rearrange(x_.mean(axis=2), 'b c -> b c 1 1')
# std = rearrange(x_.std(axis=2), 'b c -> b c 1 1')
mean = rearrange(x_.mean(dim=2), 'b c -> b c 1 1')
std = rearrange(x_.std(dim=2), 'b c -> b c 1 1')
y_ = (x - mean)/std
print('diff={}\n'.format(torch.abs(y - y_).max()))import numpy as np
import torch
import torch.nn as nn
from einops import rearrange, repeat, reduce
x = torch.randn((6, 6, 20, 20))
b, c, h, w = x.shape
group_num = 3
n = 2
group_norm = nn.GroupNorm(group_num, c, eps=1e-12, affine=False)
y = group_norm(x)
x_ = rearrange(x, 'b (g n) h w -> b g (n h w)', g = group_num) # [6, 3, 2*20*20]
print(x_.shape)
mean = rearrange(x_.mean(dim=2), 'b g -> b g 1') # [6, 3, 1]
std = rearrange(x_.std(dim=2), 'b g -> b g 1')
y_ = (x_ - mean)/std
y_ = rearrange(y_, 'b g (n h w) -> b (g n) h w', g = group_num, h = h, w = w)
print('diff={}\n'.format(torch.abs(y - y_).max()))theoretical peak
two Intel Xeon E5-2697 v2 (2S-E5) with 12 cores per CPU, each running at 2.7 GHz without turbo mode. These processors support the AVX extension with 256-bit SIMD instructions that can process 8 single precision (32 bits) numbers per CPU cycle.
theoretical peak Flop/s is 2.7 (GHz) × 8 (SP FP) × 2 (ADD/MULL) × 12 (cores) × 2 (CPUs) = 1036.8 GFlop/s.
memory bandwidth
theoretical memory bandwidth is computed from the memory frequency (1866 GHz), the number of channels (4), the number of bytes transferred by channel per cycle (8), which gives 1866 × 4 × 8 × 2 (# of processors) = 119 GByte/s peak bandwidth for the dual socket 2S-E5 system.



static_assert()
编译期间的断言
push_back会触发构造函数和移动构造函数
emplace_back原地构造
[ capture ] ( params ) opt -> ret { body; };
捕获列表:
docker build -f Dockerfile.manylinux2014_cuda11_4_tensorrt8_2 --network=host --build-arg POLICY=manylinux2014 --build-arg PLATFORM=x86_64 --build-arg DEVTOOLSET_ROOTPATH=/opt/rh/devtoolset-10/root --build-arg PREPEND_PATH=/opt/rh/devtoolset-10/root/usr/bin: --build-arg LD_LIBRARY_PATH_ARG=/opt/rh/devtoolset-10/root/usr/lib64:/opt/rh/devtoolset-10/root/usr/lib:/opt/rh/devtoolset-10/root/usr/lib64/dyninst:/opt/rh/devtoolset-10/root/usr/lib/dyninst:/usr/local/lib64 --tag=onnxruntime:cuda11.4_trt8.2 .
lite::Optimizer optimize a program. It utilize the mir passes to analysis the program and export an optimized program.
std::unique_ptr<RuntimeProgram> RunDefaultOptimizer(
Program&& program,
const std::vector<Place>& valid_places,
core::KernelPickFactor kernel_pick_factor,
const std::vector<std::string>& passes) {
Optimizer optim(valid_places, kernel_pick_factor);
// ...
for (auto& pass_name : passes_local) {
optim.AddPass(pass_name);
}
return optim.Run(std::move(program));
}
class Optimizer {
public:
Optimizer(const std::vector<Place>& valid_places,
core::KernelPickFactor kernel_pick_factor)
: valid_places_(valid_places), kernel_pick_factor_(kernel_pick_factor) {
CHECK(!valid_places.empty()) << "At least one valid_place should be set";
}
// Append a pass to the optimizer.
void AddPass(const std::string& pass_name);
// Optimize a program to generate a runtime program.
std::unique_ptr<RuntimeProgram> Run(Program&& program);
protected:
// Run all the added passes.
void ApplyPasses(std::vector<std::unique_ptr<mir::SSAGraph>>* graphes);
// Generate the optimized runtime program.
std::unique_ptr<RuntimeProgram> GenRuntimeProgram(
std::vector<std::unique_ptr<mir::SSAGraph>>* graphs);
void InitTargetTypeTransformPass();
void InitControlFlowOpUnusedInputsAndOutputsEliminatePass();
void InitControlFlowOpSharedInputsAndOutputsPlaceSyncPass();
void SpecifyKernelPickTactic(core::KernelPickFactor factor);
Scope* exec_scope() { return exec_scope_; }
private:
std::vector<Place> valid_places_;
Scope* exec_scope_{};
std::vector<mir::Pass*> passes_;
std::vector<std::unique_ptr<mir::SSAGraph>> graphs_;
core::KernelPickFactor kernel_pick_factor_;
};
file_path = './onnx_model/rec_large.onnx'
model = onnx.load(file_path)
model.graph.input[0].type.tensor_type.shape.dim[0].dim_param = '?'
model.graph.input[0].type.tensor_type.shape.dim[2].dim_param = '?'
model.graph.input[0].type.tensor_type.shape.dim[3].dim_param = '?'
onnx.save(model, './onnx_model/rec_large_dynamic.onnx')
https://github.com/microsoft/onnxruntime/tree/master/onnxruntime/core/optimizer
性能、内存/磁盘、召回率、实时更新、增量更新、删除
| 算法 | 召回效果 | 内存 | 增量更新 |
|---|---|---|---|
| HNSW | 好 | 略高 | 是 |
| PQ | 好 | 低 | 否 |
| ANNOY | 较好 | 中 | 是 |
| 实现 | 性能 | 内存 | 易用性 |
|---|---|---|---|
| FAISS | 较好 | 低 | 好 |
| Nmslib | 好 | 高 | 差 |
https://github.com/THUDM/ChatGLM-6B
https://github.com/mymusise/ChatGLM-Tuning
https://github.com/LianjiaTech/BELLE
https://zhuanlan.zhihu.com/p/616969812
Awesome-LLM-System-Papers
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
https://flexflow.ai/specInfer/
https://www.gabrieleoliaro.com/publication/expertflow/expertflow.pdf

PaddleSlim主要包含三种量化方法:量化训练(Quant Aware Training, QAT)、动态离线量化(Post Training Quantization Dynamic, PTQ Dynamic)、静态离线量化(Post Training Quantization Static, PTQ Static)。

综合对比了模型量化方法的使用条件、易用性、精度损失和预期收益。

| 量化方法 | API接口 | 功能 | 经典适用场景 |
|---|---|---|---|
| 在线量化 (QAT) | 动态图:paddleslim.QAT; 静态图:paddleslim.quant.quant_aware | 通过finetune训练将模型量化误差降到最小 | 对量化敏感的场景、模型,例如目标检测、分割, OCR |
| 静态离线量化 (PTQ Static) | paddleslim.quant.quant_post_static | 通过少量校准数据得到量化模型 | 对量化不敏感的场景,例如图像分类任务 |
| 动态离线量化 (PTQ Dynamic) | paddleslim.quant.quant_post_dynamic | 仅量化模型的可学习权重 | 模型体积大、访存开销大的模型,例如BERT模型 |
| Embedding量化(Quant Embedding) | paddleslim.quant.quant_embedding | 仅量化模型的Embedding参数 | 任何包含Embedding层的模型 |
静态离线量化中,有两种计算量化因子的方法,非饱和量化方法和饱和量化方法。非饱和量化方法计算整个Tensor的绝对值最大值abs_max,将其映射为127。饱和量化方法使用KL散度计算一个合适的阈值T (0<T<mab_max),将其映射为127。一般而言,待量化Op的权重采用非饱和量化方法,待量化Op的激活(输入和输出)采用饱和量化方法 。
ssh-keygen -t rsa -f ~/.ssh/baidu_id_rsa
#GitHub
Host github.com
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa
~/.ssh/config 文件权限必须为644
git clone --depth 1 --branch v5.0.8 --no-checkout https://github.com/emqx/emqx.git
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS="mlir;clang" \
-DLLVM_BUILD_EXAMPLES=OFF \
-DLLVM_TARGETS_TO_BUILD="host;NVPTX;X86" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DMLIR_ENABLE_BINDINGS_PYTHON=ON /// Policy object describing MmaTensorOp
template <
/// Warp-level GEMM operator (concept: gemm::warp::Mma)
typename Operator_,
/// Padding used for A operand in shared memory (concept: MatrixShape)
typename SmemPaddingA_,
/// Padding used for B operand in shared memory (concept: MatrixShape)
typename SmemPaddingB_,
/// Number of partitions of K dimension of GEMM
int PartitionsK = 1>
struct MmaPolicy {
/// Warp-level GEMM operator (concept: gemm::warp::MmaTensorOp or gemm::warp::MmaSimt)
using Operator = Operator_;
/// Padding used for A operand in shared memory
using SmemPaddingA = SmemPaddingA_;
/// Padding used for B operand in shared memory
using SmemPaddingB = SmemPaddingB_;
/// Number of partitions of K dimension
static int const kPartitionsK = PartitionsK;
};/// Structure to compute the matrix product targeting CUDA cores and SIMT math
/// instructions.
template <
/// Size of the Gemm problem - concept: gemm::GemmShape<>
typename Shape_,
/// Policy describing tuning details (concept: MmaPolicy)
typename Policy_,
/// Number of stages,
int Stages,
/// Used for partial specialization
typename Enable = bool>
class MmaBase {
public:
///< Size of the Gemm problem - concept: gemm::GemmShape<>
using Shape = Shape_;
///< Policy describing tuning details
using Policy = Policy_;
//
// Dependent types
//
/// Warp-level Mma
using Operator = typename Policy::Operator;
/// Shape describing the overall GEMM computed from shared memory
/// by each warp.
using WarpGemm = typename Policy::Operator::Shape;
/// Shape describing the number of warps filling the CTA
using WarpCount = GemmShape<Shape::kM / WarpGemm::kM,
Shape::kN / WarpGemm::kN,
Shape::kK / WarpGemm::kK>;
/// Number of warp-level GEMM oeprations
static int const kWarpGemmIterations =
(WarpGemm::kK / Operator::Policy::MmaShape::kK);
/// Number of stages
static int const kStages = Stages;
/// Tensor reference to the A operand
using TensorRefA = TensorRef<typename Operator::ElementA, typename Operator::LayoutA>;
/// Tensor reference to the B operand
using TensorRefB = TensorRef<typename Operator::ElementB, typename Operator::LayoutB>;
static_assert(kWarpGemmIterations > 1,
"The pipelined structure requires at least two warp-level "
"GEMM operations.");
static_assert((kWarpGemmIterations % 2) == 0,
"Inner loop iteration must be an even number.");
//
// Nested structs
//
/// Shared storage object needed by threadblock-scoped GEMM
class SharedStorage {
public:
//
// Type definitions
//
/// Shape of the A matrix operand in shared memory
using ShapeA = MatrixShape<Shape::kM + Policy::SmemPaddingA::kRow,
Shape::kK * kStages +
Policy::SmemPaddingA::kColumn>;
/// Shape of the B matrix operand in shared memory
using ShapeB =
MatrixShape<Shape::kK * kStages + Policy::SmemPaddingB::kRow,
Shape::kN + Policy::SmemPaddingB::kColumn>;
public:
//
// Data members
//
/// Buffer for A operand
AlignedBuffer<typename Operator::ElementA, ShapeA::kCount> operand_A;
/// Buffer for B operand
AlignedBuffer<typename Operator::ElementB, ShapeB::kCount> operand_B;
public:
//
// Methods
//
/// Returns a layout object for the A matrix
CUTLASS_DEVICE
static typename Operator::LayoutA LayoutA() {
return Operator::LayoutA::packed({ShapeA::kRow, ShapeA::kColumn});
}
/// Returns a layout object for the B matrix
CUTLASS_HOST_DEVICE
static typename Operator::LayoutB LayoutB() {
return Operator::LayoutB::packed({ShapeB::kRow, ShapeB::kColumn});
}
/// Returns a TensorRef to the A operand
CUTLASS_HOST_DEVICE
TensorRefA operand_A_ref() {
return TensorRefA{operand_A.data(), LayoutA()};
}
/// Returns a TensorRef to the B operand
CUTLASS_HOST_DEVICE
TensorRefB operand_B_ref() {
return TensorRefB{operand_B.data(), LayoutB()};
}
};
protected:
//
// Data members
//
/// Iterator to load a warp-scoped tile of A operand from shared memory
typename Operator::IteratorA warp_tile_iterator_A_;
/// Iterator to load a warp-scoped tile of B operand from shared memory
typename Operator::IteratorB warp_tile_iterator_B_;
public:
/// Construct from tensor references
CUTLASS_DEVICE
MmaBase(
///< Shared storage needed for internal use by threadblock-scoped GEMM
SharedStorage &shared_storage,
///< ID within the threadblock
int thread_idx,
///< ID of warp
int warp_idx,
///< ID of each thread within a warp
int lane_idx
):
warp_tile_iterator_A_(shared_storage.operand_A_ref(), lane_idx),
warp_tile_iterator_B_(shared_storage.operand_B_ref(), lane_idx) {
}
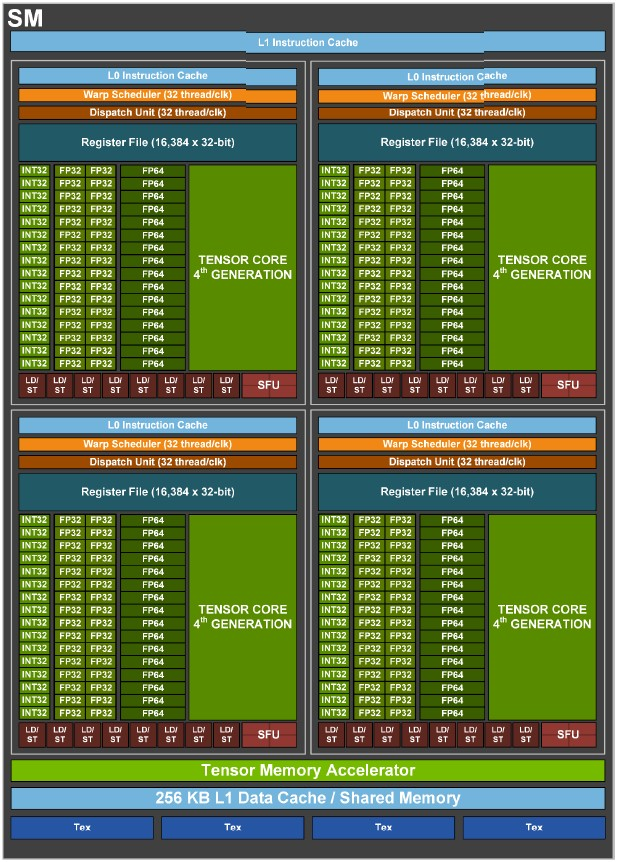
};| Brand Name | GPU Architecture | Tensor Core | NVIDIA CUDA® Cores | TensorFLOPS | Single-Precision | Double-Precision | Mixed-Precision(FP16/FP32) | INT8 | INT4 | GPU Memory | Interconnect Bandwidth | System Interface |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| V100 PCle | NVIDIA Volta | 640 1nd | 5,120 | 112 TFLOPS | 14 TFLOPS | 7 TFLOPS | 12x TFLOPS | 32 GB HBM2 900 GB/sec | 32 GB/sec | x16 PCIe Gen3 | ||
| V100 SXM2 | NVIDIA Volta | 640 1nd | 5,120 | 125 TFLOPS | 15.7 TFLOPS | 7.8 TFLOPS | 32 GB HBM2 900 GB/sec | 300 GB/sec | x6 NVLink 2.0 | |||
| T4 | NVIDIA Turing | 320 2nd | 2,560 | 8.1 TFLOPS | 65 TFLOPS | 130 TOPS | 260 TOPS | 16 GB GDDR6 300 GB/sec | 32 GB/sec | x16 PCIe Gen3 |


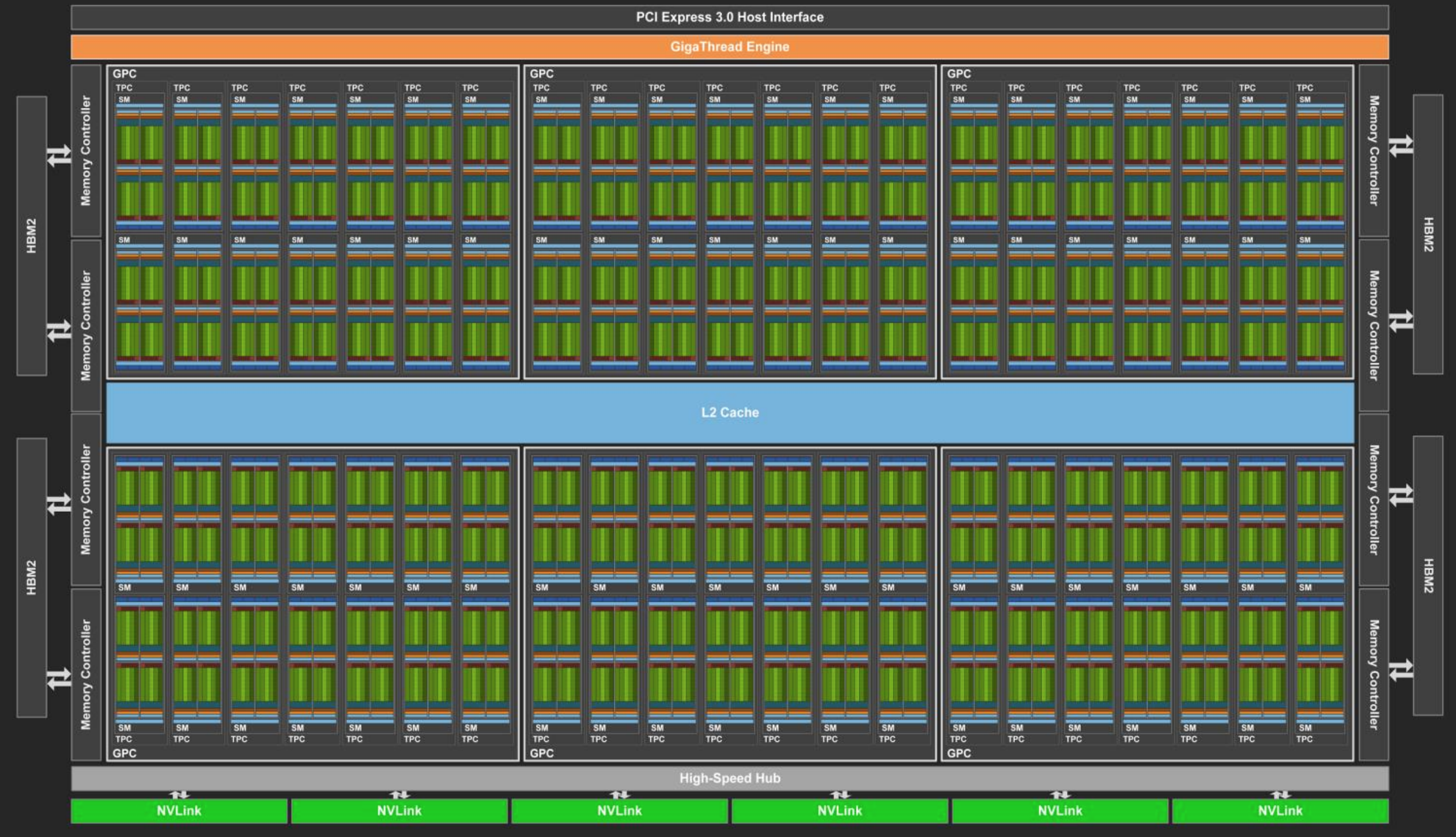
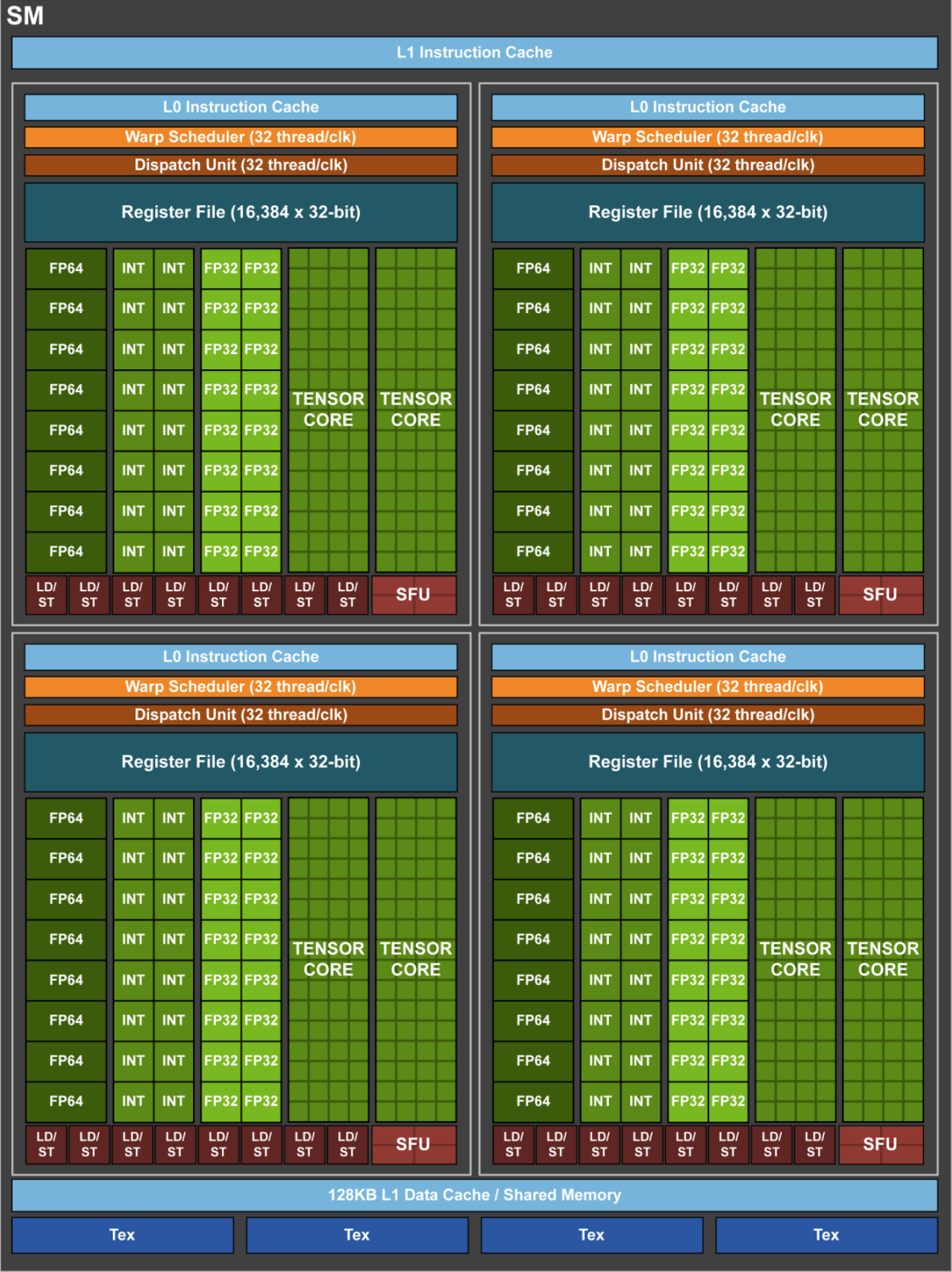
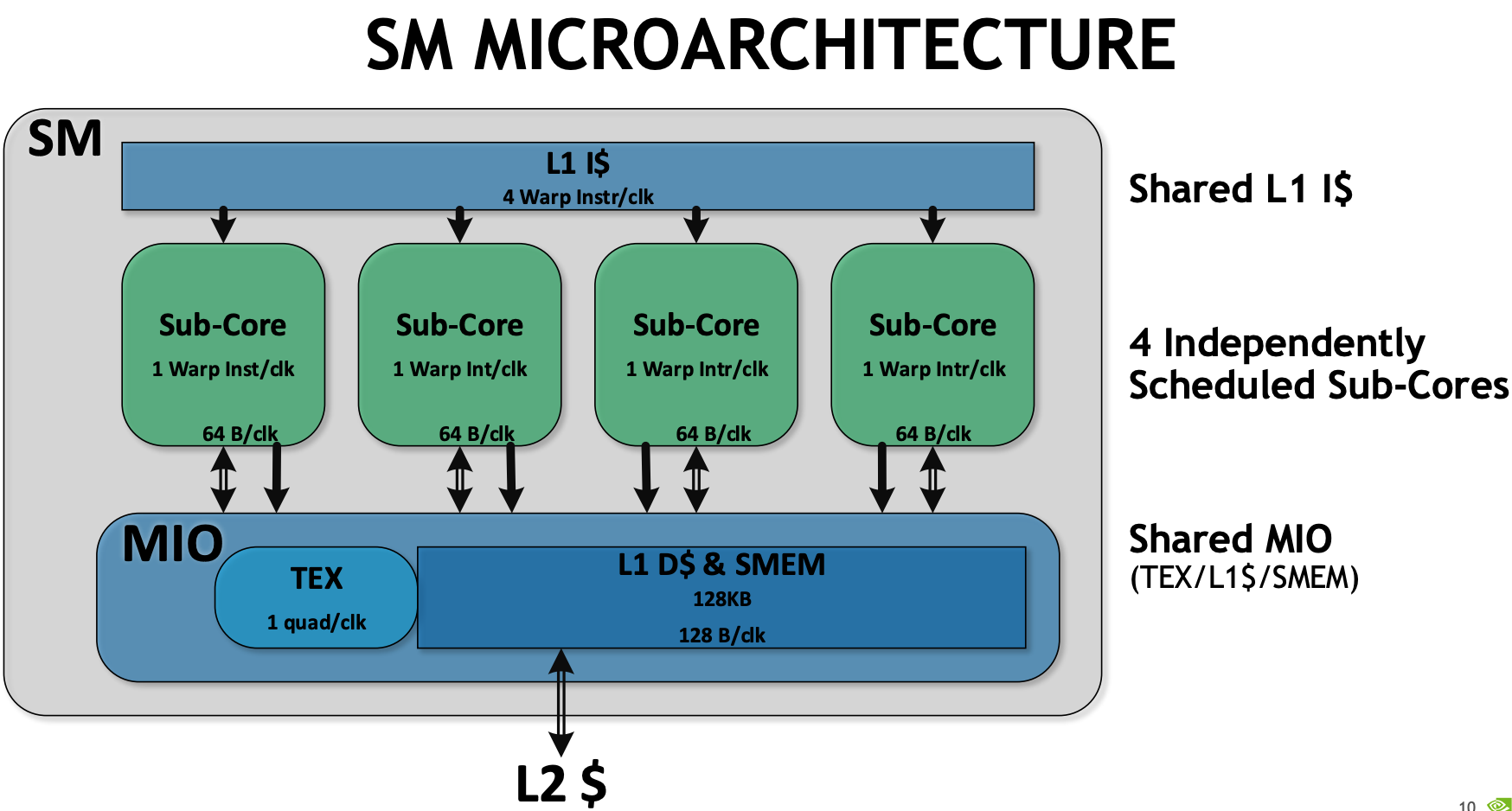
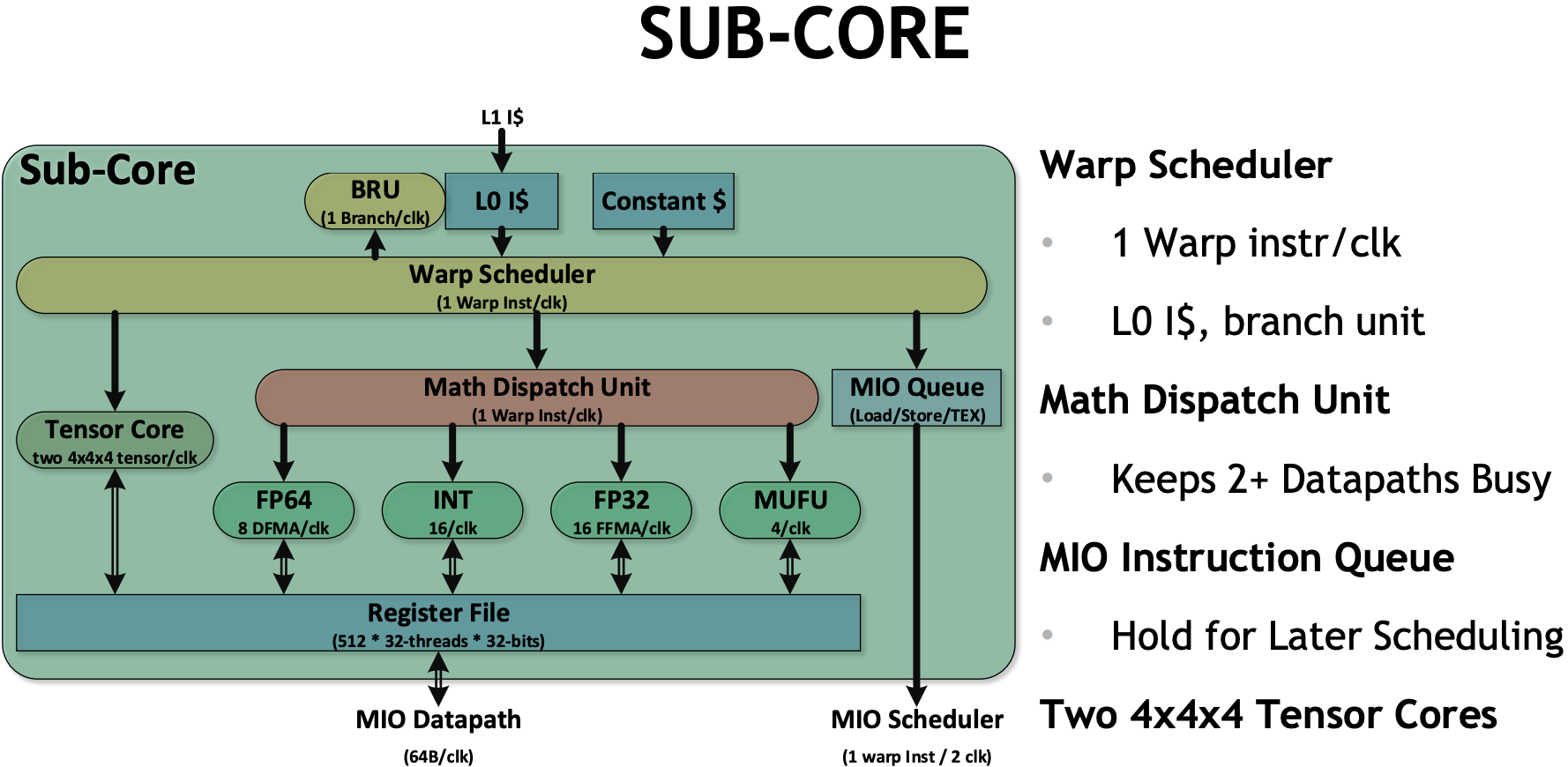

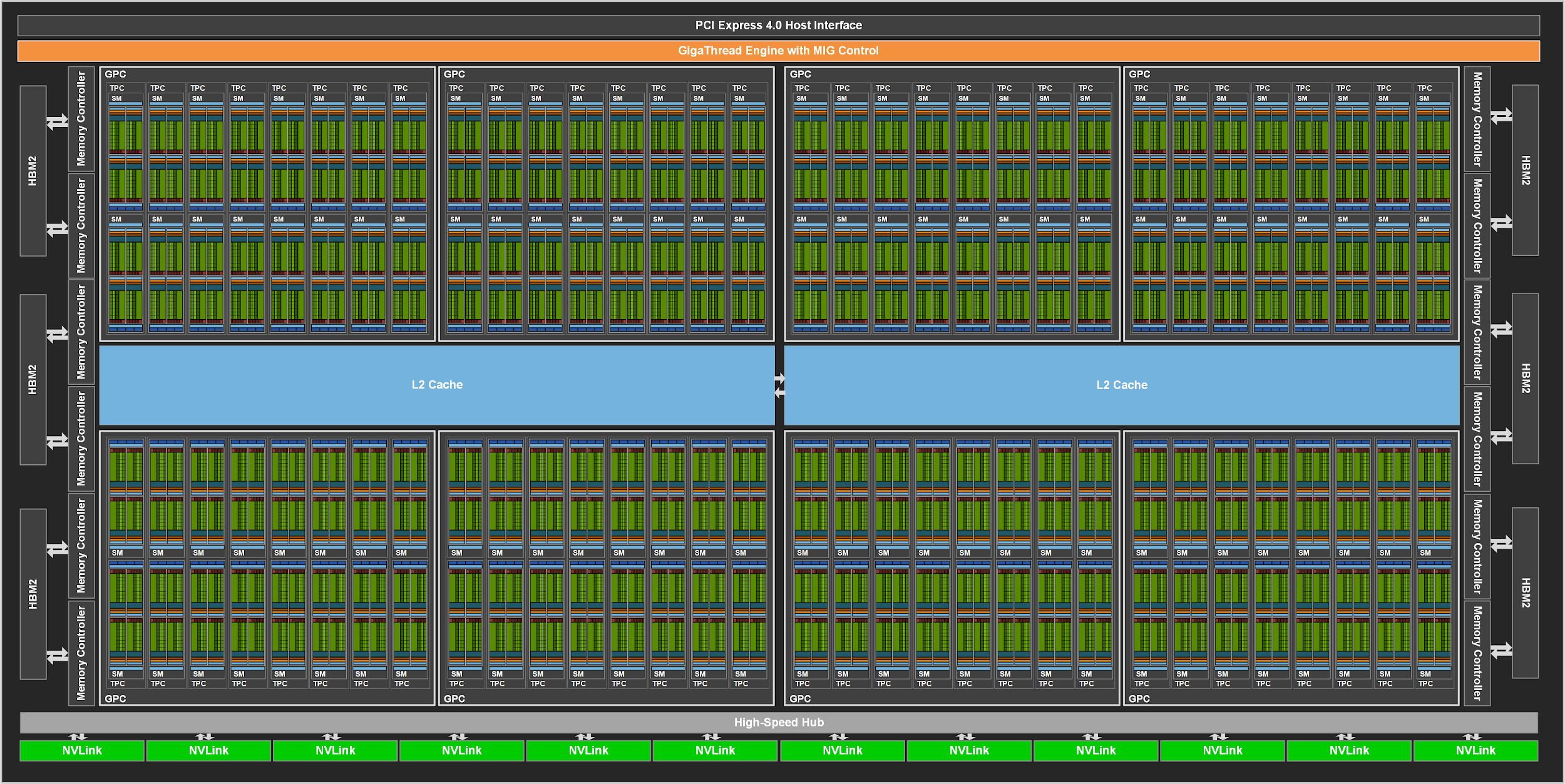
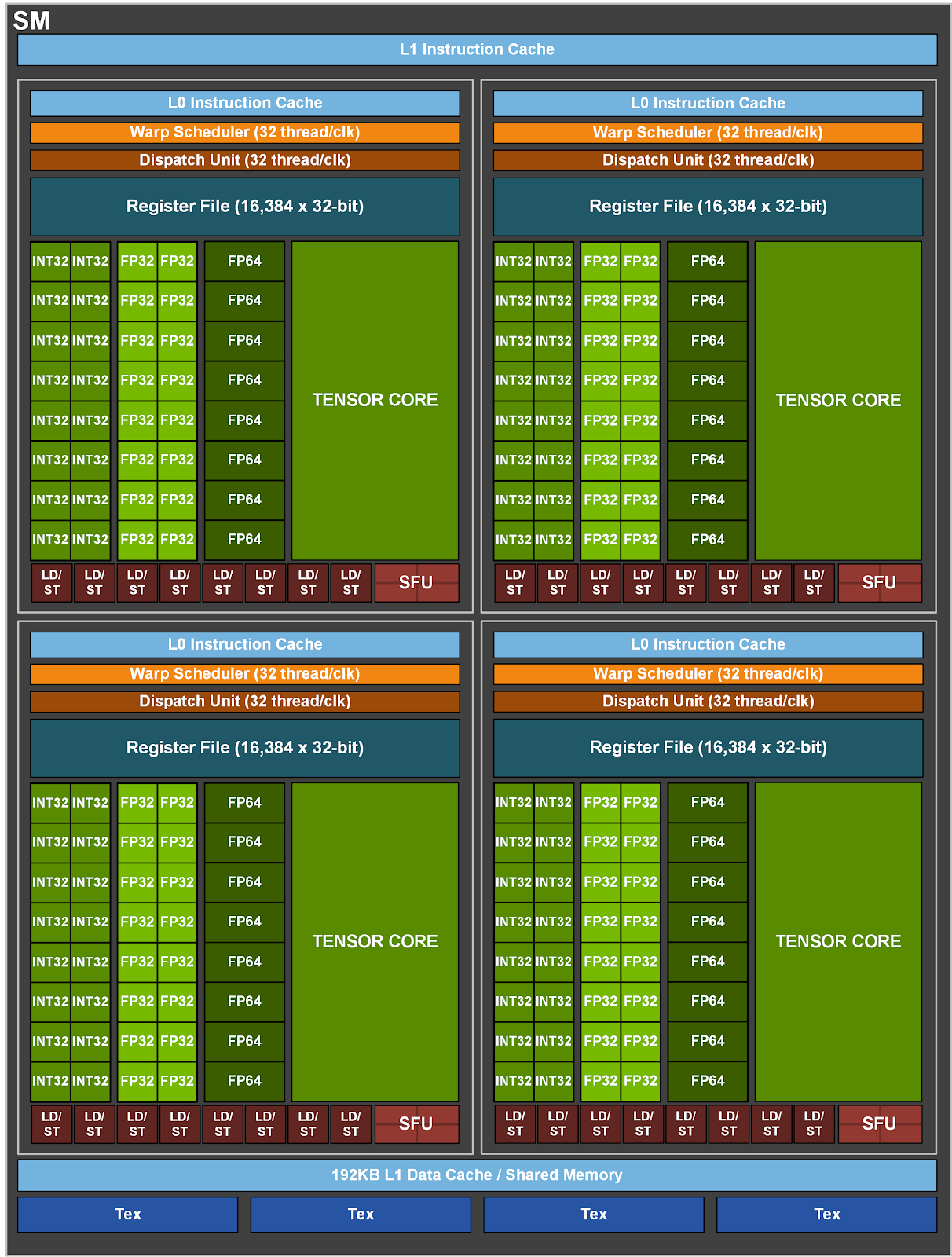
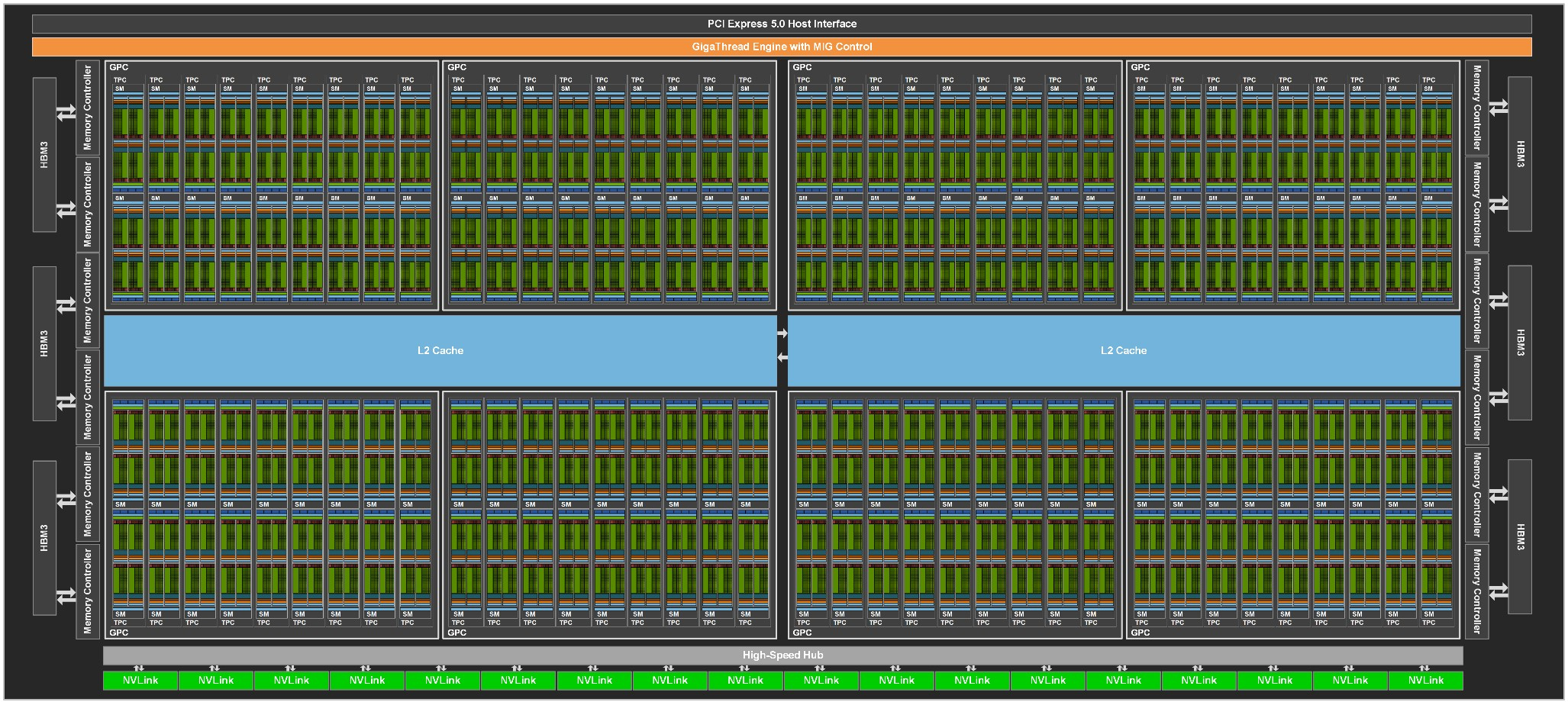
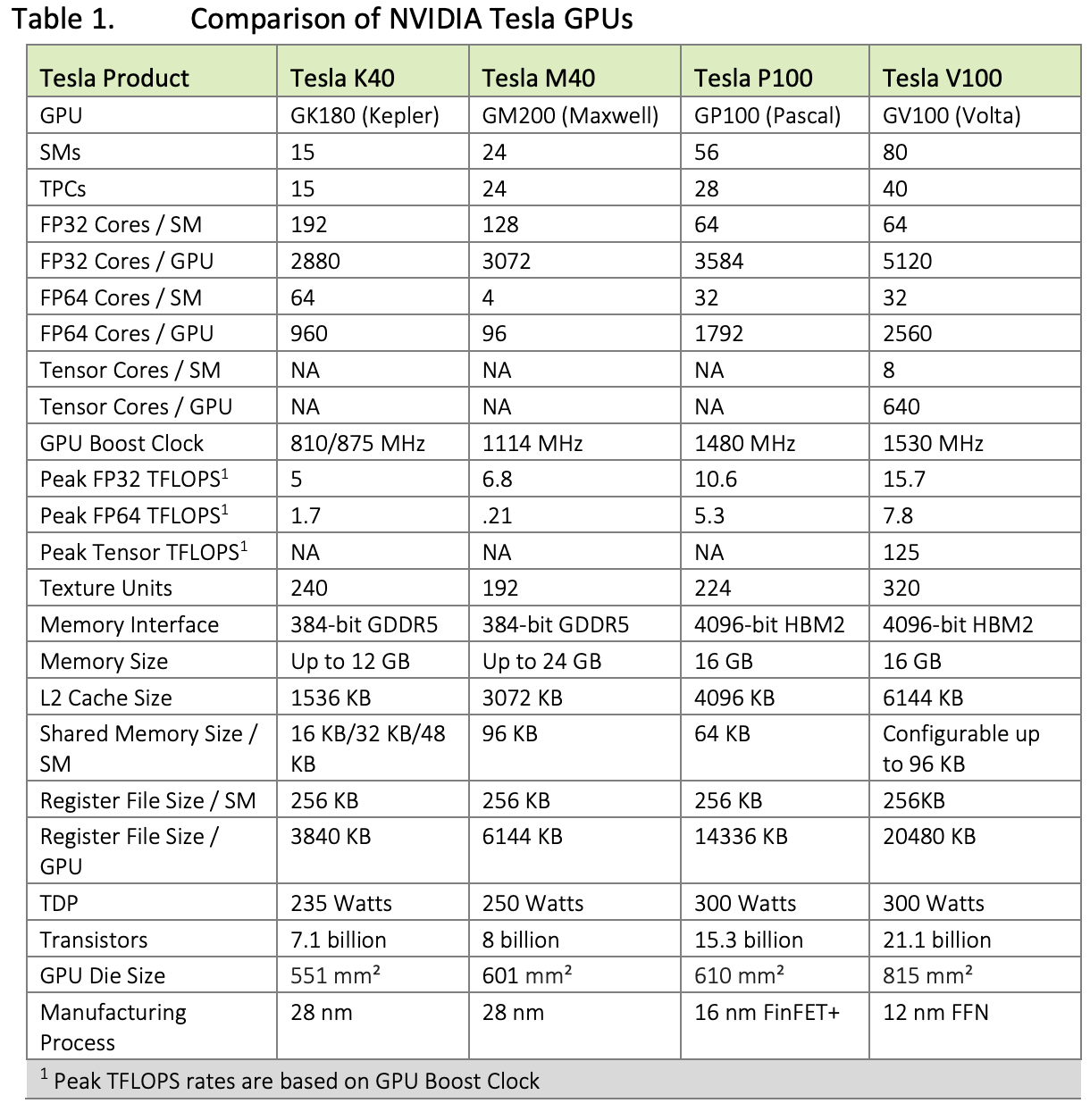
| Data Center GPU | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA A100 |
|---|---|---|---|
| GPU Codename | GP100 | GV100 | GA100 |
| GPU Architecture | NVIDIA Pascal | NVIDIA Volta | NVIDIA Ampere |
| GPU Board Form Factor | SXM | SXM2 | SXM4 |
| SMs | 56 | 80 | 108 |
| TPCs | 28 | 40 | 54 |
| FP32 Cores / SM | 64 | 64 | 64 |
| FP32 Cores / GPU | 3584 | 5120 | 6912 |
| FP64 Cores / SM | 32 | 32 | 32 |
| FP64 Cores / GPU | 1792 | 2560 | 3456 |
| INT32 Cores / SM | NA | 64 | 64 |
| INT32 Cores / GPU | NA | 5120 | 6912 |
| Tensor Cores / SM | NA | 8 | 42 |
| Tensor Cores / GPU | NA | 640 | 432 |
| GPU Boost Clock | 1480 MHz | 1530 MHz | 1410 MHz |
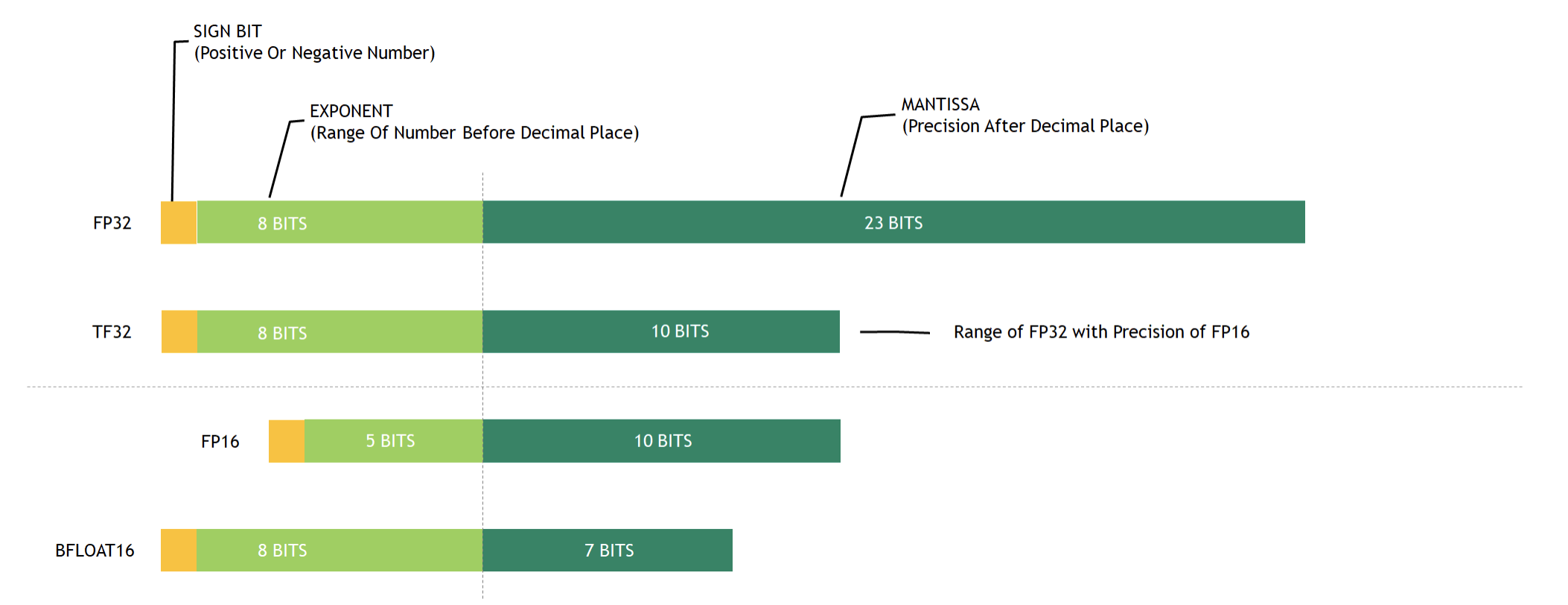
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 | NA | 125 | 312/6243 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 | NA | 125 | 312/6243 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 | NA | NA | 312/6243 |
| Peak TF32 Tensor TFLOPS1 | NA | NA | 156/3123 |
| Peak FP64 Tensor TFLOPS1 | NA | NA | 19.5 |
| Peak INT8 Tensor TOPS1 | NA | NA | 624/12483 |
| Peak INT4 Tensor TOPS1 | NA | NA | 1248/24963 |
| Peak FP16 TFLOPS1 | 21.2 | 31.4 | 78 |
| Peak BF16 TFLOPS1 | NA | NA | 39 |
| Peak FP32 TFLOPS1 | 10.6 | 15.7 | 19.5 |
| Peak FP64 TFLOPS1 | 5.3 | 7.8 | 9.7 |
| Peak INT32 TOPS1,4 | NA | 15.7 | 19.5 |
| Texture Units | 224 | 320 | 432 |
| Memory Interface | 4096-bit HBM2 | 4096-bit HBM2 | 5120-bit HBM2 |
| Memory Size | 16 GB | 32 GB / 16 GB | 40 GB |
| Memory Data Rate | 703 MHz DDR | 877.5 MHz DDR | 1215 MHz DDR |
| Memory Bandwidth | 720 GB/sec | 900 GB/sec | 1555 GB/sec |
| L2 Cache Size | 4096 KB | 6144 KB | 40960 KB |
| Shared Memory Size / SM | 64 KB | Configurable up to 96 KB | Configurable up to 164 KB |
| Register File Size / SM | 256 KB | 256 KB | 256 KB |
| Register File Size / GPU | 14336 KB | 20480 KB | 27648 KB |
| TDP | 300 Watts | 300 Watts | 400 Watts |
| Transistors | 15.3 billion | 21.1 billion | 54.2 billion |
| GPU Die Size | 610 mm² | 815 mm² | 826 mm2 |
| TSMC Manufacturing Process | 16 nm FinFET+ | 12 nm FFN | 7 nm N7 |
nsight systems 和 nsight compute都是基于CUDA Profiling Tools Interface(CUPTI) 构建。
nsys profile --stats=true ./main
CUDA_VISIBLE_DEVICES=3 nsys profile -t cuda,nvtx,cublas,cublas-verbose,cusparse,cusparse-verbose,cudnn --stats=true --cuda-memory-usage true python main.py --model_file=../../../work/test/infer_bench/Models/MobileNetV1/inference.pdmodel --params_file=../../../work/test/infer_bench/Models/MobileNetV1/inference.pdiparams --use_gpu=1 --repeat=2
"C_Cpp.clang_format_style": "{BasedOnStyle: Webkit, BreakBeforeBraces: Attach, IndentWidth: 4, BinPackParameters: false, NamespaceIndentation: None, BreakConstructorInitializers: AfterColon, ContinuationIndentWidth: 8, ConstructorInitializerIndentWidth: 8, ColumnLimit: 120, AlwaysBreakTemplateDeclarations: Yes, AllowShortFunctionsOnASingleLine: None}"
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.