Please note that the original design goal of this role was more concerned with the initial installation and bootstrapping environment, which currently does not involve performing continuous maintenance, and therefore are only suitable for testing and development purposes, should not be used in production environments.
请注意,此角色的最初设计目标更关注初始安装和引导环境,目前不涉及执行连续维护,因此仅适用于测试和开发目的,不应在生产环境中使用。
![]()
Table of Contents
- Introduction
- Overview
- Data Model
- Exposition format
- Alerting
- Visualization
- Architecture
- Components
- Basic exporters
- Requirements
- Role variables
- Dependencies
- Example Playbook
- License
- Author Information
- Contributors
Systems monitoring toolkit wasn’t built to do any of all things. It was built to aid software developers and administrators in the operation of production computer systems, such as the operation system, applications, databases and networks backing popular websites.
Knowing when things are going wrong is usually the most important thing that you want monitoring for. You want the monitoring system to call in a human to take a look.
Now that you have called in a human, they need to investigate to determine the root cause and ultimately resolve whatever the issue is.
Alerting and debugging usually happen on time scales on the order of minutes to hours. While less urgent, the ability to see how your systems are being used and changing over time is also useful. Trending can feed into design decisions and processes such as capacity planning.
When all you have is a hammer, everything starts to look like a nail. At the end of the day all monitoring systems are data processing pipelines. Sometimes it is more convenient to appropriate part of your monitoring system for another purpose, rather than building a bespoke solution. This is not strictly monitoring, but it is common in practice.
Prometheus is an open-source systems monitoring and alerting toolkit that focuses on capturing measurements and exposing them via an API. Works very well in a distributed, cloud-native environment, making it ideal for mission-critical microservices applications.
Prometheus is performant and simple to run, A single Prometheus server can ingest millions of samples per second. All of the services are unburdened by load on the monitoring system. It is a single statically linked binary with a configuration file. All components of Prometheus can be run in containers, and they avoid doing anything fancy that would get in the way of configuration management tools. It is designed to be integrated into the infrastructure you already have and built on top of, not to be a management platform itself.
Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community. It is now a standalone open source project and maintained independently of any company. To emphasize this, and to clarify the project's governance structure, Prometheus joined the Cloud Native Computing Foundation in 2016, the second hosting project after Kubernetes.
As a metrics-based system, Prometheus is not suitable for storing event logs or individual events. Nor is it the best choice for high cardinality data, such as email address or username.
Prometheus is designed for operational monitoring, where small inaccuracies and race conditions due to factors like kernel scheduling and failed scrapes are a fact of life. Prometheus makes tradeoffs and prefers giving you data that is 99.9% correct over your monitoring breaking while waiting for perfect data. Thus in applications involving money or billing, Prometheus should be used with caution.
All of the data is stored as a time series. A measurement with a timestamp. Measurements are known as metrics. Each time series is uniquely identified by a metric name and a set of key-value pairs, a.k.a. labels. This means that labels represent multiple dimensions of a metric. A combination of a metric name and a label yields a single metric. In other words, each time you create a new key-value pair on a metric you will get a new timeseries in the database. An observation (they call it a sample!) is a combination of a float64 value and a millisecond precision timestamp.
When you look at the exposition format example below, you will notice that the first metric has the name node_cpu_seconds_total, a value 646836.5, and a set of labels inside curly braces {cpu="0",mode="idle"}. Labels can be omitted entirely together with the curly braces. They are separated by a single comma. The label value can be any UTF-8 string. Labels are very useful for compartmentalizing information, doing joins, and other useful stuff that we’ll mention later.
node_cpu_seconds_total{cpu="0",mode="idle"} 646836.5
node_cpu_seconds_total{cpu="0",mode="iowait"} 169.32
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 975.52
node_cpu_seconds_total{cpu="0",mode="softirq"} 863.66
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 5581.2
node_cpu_seconds_total{cpu="0",mode="user"} 22442.72
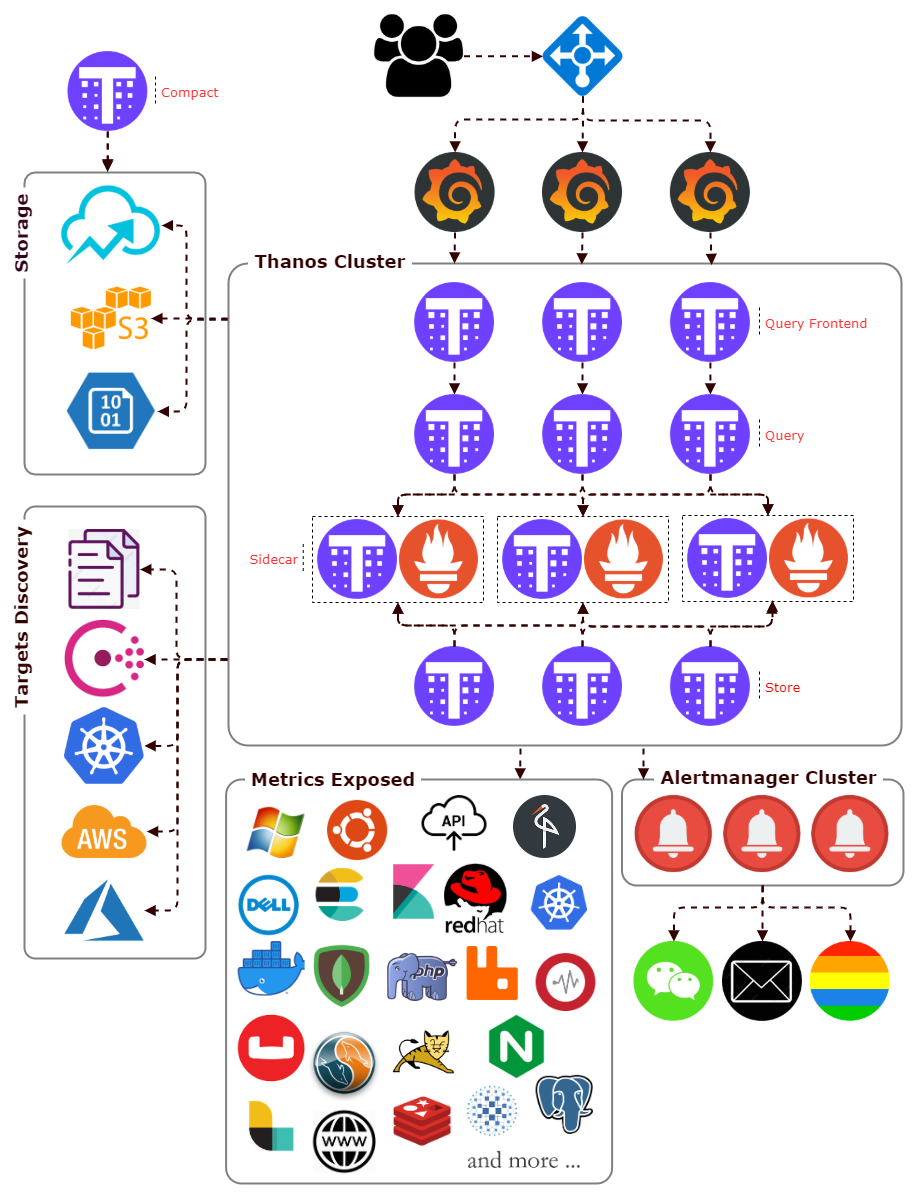
The Alertmanager receives alerts from Prometheus servers and turns them into notifications. Notifications can include email, chat applications such as Wechat. The Alertmanager does more than blindly turn alerts into notifications on a one-to-one basis. Related alerts can be aggregated into one notification, throttled to reduce message storms, and different routing and notification outputs can be configured for each of your different teams. Alerts can also be silenced, perhaps to snooze an issue you are already aware of in advance when you know maintenance is scheduled.
It is recommended that you use Grafana for dashboards. It has a wide variety of features, including official support for Prometheus as a data source. It can produce a wide variety of dashboards.
An exporter is a piece of software that you deploy right beside the application you want to obtain metrics from. It takes in requests from Prometheus, gathers the required data from the application, transforms them into the correct format, and finally returns them in a response to Prometheus.
Trickster's proxy inspects the time range of a client query to determine what data points are already cached, and requests from Prometheus only the data points still needed to service the client request. This results in dramatically faster chart load times for everyone.
The Query component is stateless and horizontally scalable and can be deployed with any number of replicas. Once connected to the Sidecars, it automatically detects which Prometheus servers need to be contacted for a given PromQL query. Also capable of deduplicating data collected from Prometheus distributed.
Sidecar is to backup Prometheus data into an Object Storage bucket, and giving other Thanos components access to the Prometheus instance the Sidecar is attached to.
As the sidecar backs up data into the object storage of your choice, you can decrease Prometheus retention and store less locally. It can find in your object storage bucket.
The compact component simple scans the object storage and processes compaction where required. At the same time it is responsible for creating downsampled copies of data to speed up queries.
The bucket component is a set of commands to inspect data in object storage buckets. It is normally run as a stand alone command to aid with troubleshooting.
Consul is a distributed, highly available, and data center aware solution to connect and configure applications across dynamic, distributed infrastructure. Prometheus has integrations with consul as service discovery mechanisms.
Offer a clustered storage solution to Long-Term Storage data across multiple machines, support Google Cloud Storage / AWS S3 / Azure Storage Account / etc.
Installed on Linux operation machine. Exports statistics about network, I/O, CPU, memory, filesystems for hardware and OS metrics by kernels.
Using the Windows Management Instrumentation for Windows machines.
Exposes CPU, memory, network and I/O usage from containers.
Collection methods are supported on MySQL/MariaDB, PostgrSQL and MongoDB.
Export from a wide variety of JVM-based applications, for example Zookeeper and Tomcat.
Some of these exporters are maintained as part of the official Prometheus GitHub organization, those are marked as official, others are externally contributed and maintained.
This Ansible role installs standalone or distributed prometheus v2 server on linux operating system, including establishing a filesystem structure and server configuration with some common operational features. This role will work on the following operating systems:
- CentOS 7
The following list of supported the Prometheus releases:
- Prometheus v2.2.1+
- Targets will be dispersed if greater than 3 prometheus nodes.
- Use the last digital of the IP Address or host number to spread the load between multiple prometheus nodes.
Performance is severely affected by remote reading and deduplicating data queries, thanos store components + object storage offers only if need long term storage.
for example:
node01: - source_labels: [__address__]
regex: .+[02468]:.+
action: drop
node02: - source_labels: [__address__]
regex: .+[13579]:.+
action: drop
node03: - source_labels: [__address__]
regex: .+[02468]:.+
action: drop
node04: - source_labels: [__address__]
regex: .+[13579]:.+
action: drop
There are some variables in defaults/main.yml which can (Or needs to) be overridden:
thanos_is_install: A boolean value, whether install the Thanos.trickster_is_install: A boolean value, whether install the Trickster.thanos_bucket_is_used: A boolean value, whether use object storage.prometheus_conf_path: Specify the Prometheus data directory.prometheus_data_path: Specify the Prometheus configure directory.
prometheus_consul_server: The consul address and port.prometheus_consul_token: The consul acl token.
prometheus_k8s_api: The API server addresses.prometheus_k8s_token: Authentication token.
prometheus_grafana_dept: A boolean value, whether install the Grafana for metrics visualization.prometheus_grafana_redis_dept: A boolean value, whether installs Redis.prometheus_grafana_ngx_dept: A boolean value, whether proxy Grafana web interface using NGinx.
prometheus_port.alertmanager: alertmanager instance listen port.prometheus_port.cluster: alertmanager cluster listen port.prometheus_port.prometheus: Prometheus instance listen port.thanos_port.bucket_http: Port for bucket HTTP endpoints.thanos_port.compact_http: Port for compact HTTP endpoints.thanos_port.query_grpc: Port for query gRPC endpoints.thanos_port.query_http: Port for query HTTP endpoints.thanos_port.sidecar_grpc: Port for sidecar gRPC endpoints.thanos_port.sidecar_http: Port for sidecar HTTP endpoints.thanos_port.store_grpc: Port for store gRPC endpoints.thanos_port.store_http: Port for store HTTP endpoints.trickster_port.proxy_server: Defines the port on which Trickster's Proxy server listens.trickster_port.metrics: Defines the port that Trickster's metrics server listens on at /metrics.
prometheus_grafana_path: Specify the Grafana data directory.prometheus_grafana_version: Specify the Grafana version.prometheus_grafana_admin_user: The name of the default Grafana admin user.prometheus_grafana_admin_password: The password of the default Grafana admin.prometheus_grafana_port: Grafana instance listen port.prometheus_grafana_proxy: Whether running behind a HaProxy.prometheus_grafana_redis_path: Specify the Redis data directory.prometheus_grafana_redis_requirepass: Authorization clients password.prometheus_grafana_redis_maxmemory: A memory usage limit to the specified amount in MB.prometheus_grafana_redis_hosts: Redis hosts address.prometheus_grafana_redis_port: Redis listen port.prometheus_grafana_ngx_block_agents: Enables or disables block unsafe User Agents.prometheus_grafana_ngx_block_string: Enables or disables block includes Exploits / File injections / Spam / SQL injections.prometheus_grafana_ngx_compress: Enables or disables compression.prometheus_grafana_ngx_domain: Defines domain name.prometheus_grafana_ngx_pagespeed: Enables or disables pagespeed modules.prometheus_grafana_ngx_port_http: NGinx HTTP listen port.prometheus_grafana_ngx_port_https: NGinx HTTPs listen port.prometheus_grafana_ngx_ssl_protocols: intermediate or modern, defines SSL protocol profile.prometheus_grafana_ngx_version: extras or standard
prometheus_arg.evaluation_interval: How frequently to evaluate rules.prometheus_arg.query_max_concurrency: Maximum number of queries executed concurrently.prometheus_arg.refresh_interval: Refresh interval to re-read the instance list.prometheus_arg.scrape_interval: How frequently to scrape targets from this job.prometheus_arg.scrape_timeout: How long until a scrape request times out.prometheus_arg.storage_tsdb_block_duration: Must be set to equal values to disable local compaction.prometheus_arg.storage_tsdb_retention: How long to retain samples in storage.prometheus_arg.ulimit_core: The number of coredump launched by systemd.prometheus_arg.ulimit_memlock: The number of memory lock launched by systemd.prometheus_arg.ulimit_nofile: The number of files launched by systemd.prometheus_arg.ulimit_nproc: The number of processes launched by systemd.
prometheus_prober_arg: Prober configuration.
alertmanager_arg.mail_to_user: The email address to send notifications to.alertmanager_arg.group_by: They are grouped by alertname.alertmanager_arg.group_wait: How long to initially wait to send a notification for a group of alerts.alertmanager_arg.group_interval: How long to wait before sending a notification about new alerts that are added to a group.alertmanager_arg.repeat_interval: How long to wait before sending a notification again if it has already been sent successfully for an alert.alertmanager_arg.smtp_auth_password: SMTP authentication password.alertmanager_arg.smtp_auth_username: SMTP authentication username.alertmanager_arg.smtp_from: The sender address.alertmanager_arg.smtp_require_tls: The SMTP TLS requirement.alertmanager_arg.smtp_smarthost: The SMTP host through which emails are sent.alertmanager_arg.wechat_api_agentid: The wechat agent ID.alertmanager_arg.wechat_api_url: The WeChat API URL.alertmanager_arg.wechat_to_party: The WeChat department to send notifications to.alertmanager_arg.wechat_api_corpid: The corp id for authentication.alertmanager_arg.wechat_api_secret: The API key to use when talking to the WeChat API.
prometheus_alert_rules: Defining alerting rules.
thanos_arg.chunk_pool_size: Maximum size of concurrently allocatable bytes for chunks.thanos_arg.index_cache_size: Maximum size of items held in the index cache.thanos_arg.log_format: Log format.thanos_arg.log_level: Log level.thanos_arg.query_auto_downsampling: Enable automatic adjustment source data.thanos_arg.query_max_concurrent: Maximum number of queries processed concurrently.thanos_arg.query_timeout: Maximum time to process query.thanos_arg.ulimit_core: The number of coredump launched by systemd.thanos_arg.ulimit_memlock: The number of memory lock launched by systemd.thanos_arg.ulimit_nofile: The number of files launched by systemd.thanos_arg.ulimit_nproc: The number of processes launched by systemd.
thanos_obj_arg.retention: Days to retain samples in bucket.thanos_obj_arg.type: Objstore service type.thanos_obj_arg.bucket: Object storage bucket name.thanos_obj_arg.endpoint: Objstore service endpoint.thanos_obj_arg.insecure: Objstore service.thanos_obj_arg.signature_version2: I real don't know what that means.thanos_obj_arg.access_key: AccessKeyID.thanos_obj_arg.secret_key: SecretAccessKey.
trickster_arg.cache_type: Defines what kind of cache Trickster uses.trickster_arg.fast_forward_disable: Turn off the 'fast forward' feature for any requests proxied.trickster_arg.max_size_bytes: How large the cache can grow in bytes before the Index evicts least-recently-accessed items.trickster_arg.timeseries_retention_factor: Defines the maximum number of recent timestamps to cache for a given query.trickster_arg.record_ttl_secs: Defines the relative expiration of cached queries.trickster_arg.ulimit_core: The number of coredump launched by systemd.trickster_arg.ulimit_memlock: The number of memory lock launched by systemd.trickster_arg.ulimit_nofile: The number of files launched by systemd.trickster_arg.ulimit_nproc: The number of processes launched by systemd.trickster_arg.version: Specify the Trickster version.
environments: Define the service environment.tags: Define the service custom label.exporter_is_install: Whether to install prometheus exporter.consul_public_register: Whether register a exporter service with public consul client.consul_public_exporter_token: Public Consul client ACL token.consul_public_http_prot: The consul Hypertext Transfer Protocol.consul_public_clients: List of public consul clients.consul_public_http_port: The consul HTTP API port.
There are some variables in vars/main.yml:
See tests/inventory for an example, all host must belong to one child group.
[demo_mon]
node01 ansible_host='192.168.1.10' prometheus_is_install='true'
node02 ansible_host='192.168.1.11' prometheus_is_install='true'
node03 ansible_host='192.168.1.12' prometheus_is_install='true'
Including an example of how to use your role (for instance, with variables passed in as parameters) is always nice for users too:
- hosts: all
roles:
- role: ansible-role-linux prometheus
prometheus_is_install: true
You can also use the group_vars or the host_vars files for setting the variables needed for this role. File you should change: group_vars/all or host_vars/group_name
prometheus_conf_path: '/etc/prometheus'
prometheus_data_path: '/data'
thanos_is_install: true
trickster_is_install: true
thanos_bucket_is_used: true
prometheus_consul_server: '127.0.0.1:8500'
prometheus_consul_token: '7471828c-d50a-4b25-b6a5-d80f02a03bae'
prometheus_k8s_api: '127.0.0.1:6443'
prometheus_k8s_token: 'xxxxxxxxxxxxxxxxxxxxxxx'
prometheus_grafana_dept: false
prometheus_grafana_redis_dept: false
prometheus_grafana_ngx_dept: false
prometheus_port:
alertmanager: '9093'
cluster: '9094'
prometheus: '9090'
thanos_port:
bucket_http: '19195'
compact_http: '19194'
query_grpc: '19092'
query_http: '19192'
sidecar_grpc: '19091'
sidecar_http: '19191'
store_grpc: '19093'
store_http: '19193'
trickster_port:
proxy_server: '19090'
metrics: '8082'
prometheus_grafana_path: '/data'
prometheus_grafana_version: '6.5'
prometheus_grafana_admin_user: 'admin'
prometheus_grafana_admin_password: 'password'
prometheus_grafana_port: '3000'
prometheus_grafana_proxy: false
prometheus_grafana_redis_path: '{{ prometheus_data_path }}'
prometheus_grafana_redis_requirepass: 'password'
prometheus_grafana_redis_maxmemory: '1'
prometheus_grafana_redis_hosts: '{{ prometheus_server[0] }}'
prometheus_grafana_redis_port: '6379'
prometheus_grafana_ngx_block_agents: false
prometheus_grafana_ngx_block_string: false
prometheus_grafana_ngx_compress: false
prometheus_grafana_ngx_domain: 'visual.example.com'
prometheus_grafana_ngx_pagespeed: false
prometheus_grafana_ngx_port_http: '80'
prometheus_grafana_ngx_port_https: '443'
prometheus_grafana_ngx_ssl_protocols: 'modern'
prometheus_grafana_ngx_version: 'extras'
prometheus_arg:
evaluation_interval: '30s'
query_max_concurrency: '1024'
refresh_interval: '60s'
scrape_interval: '60s'
scrape_timeout: '10s'
storage_tsdb_block_duration: '2h'
storage_tsdb_retention: '30d'
ulimit_core: 'infinity'
ulimit_memlock: 'infinity'
ulimit_nofile: '262144'
ulimit_nproc: '262144'
prometheus_prober_arg:
smokeping_hosts:
- '223.5.5.5'
- '119.29.29.29'
alertmanager_arg:
mail_to_user: '[email protected]'
group_by:
- 'alertname'
- 'cluster'
- 'service'
group_wait: '60s'
group_interval: '60s'
repeat_interval: '2h'
smtp_auth_password: 'password'
smtp_auth_username: 'user'
smtp_from: '[email protected]'
smtp_require_tls: false
smtp_smarthost: '127.0.0.1:25'
wechat_api_agentid: '0'
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_to_party: '1'
wechat_api_corpid: 'wxe787605fxxxxxxxx'
wechat_api_secret: 'fm6Ehm6DI8PlGWxtKcgkDOZCLMTsNqKqTxxxxxxxxxx'
prometheus_alert_rules:
- 'Consul'
- 'ElasticSearch'
thanos_arg:
chunk_pool_size: '2GB'
index_cache_size: '1GB'
log_format: 'logfmt'
log_level: 'info'
query_auto_downsampling: false
query_max_concurrent: '1024'
query_timeout: '1m'
ulimit_core: 'infinity'
ulimit_memlock: 'infinity'
ulimit_nofile: '262144'
ulimit_nproc: '262144'
thanos_obj_arg:
retention: '365'
type: 'S3'
bucket: 'public'
endpoint: '127.0.0.1:9001'
insecure: true
signature_version2: false
access_key: 'QTNTQZZP1NOBNCL5LPRX'
secret_key: 'b1mPOhMQc8JP49Jy8pJLsDwHayDtBFC3M9YxSmzM'
trickster_arg:
cache_type: 'memory'
fast_forward_disable: false
timeseries_retention_factor: '1024'
max_size_bytes: '536870912'
record_ttl_secs: '43200'
ulimit_core: 'infinity'
ulimit_memlock: 'infinity'
ulimit_nofile: '262144'
ulimit_nproc: '262144'
version: '1.0.1'
environments: 'Development'
tags:
subscription: 'default'
owner: 'nobody'
department: 'Infrastructure'
organization: 'The Company'
region: 'IDC01'
exporter_is_install: false
consul_public_register: false
consul_public_exporter_token: '00000000-0000-0000-0000-000000000000'
consul_public_http_prot: 'https'
consul_public_http_port: '8500'
consul_public_clients:
- '127.0.0.1'
Please send your suggestions to make this role better.
Special thanks to the Connext Information Technology for their contributions to this role.


