Requirement: tensorflow 1.14, seqeval 1.2.2, bert-base 0.0.9
细节详见data中README
- 实体识别: MSRA, people_daily
- 分词:MSR【只用于增强实体识别效果不单独使用】
- 单任务
- bilstm_crf
- bert_ce
- bert_crf
- bert_bilstm_crf
- bert_cnn_crf
- bert_bilstm_crf_bigram
- bert_bilstm_crf_softword
- bert_bilstm_crf_ex_softword
- bert_bilstm_crf_softlexicon
- 多任务
- bert_bilstm_crf_mtl: 共享Bert的多任务联合学习,部分参考 paper/Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning
- bert_bilstm_crf_adv: 对抗迁移联合学习,部分参考 paper/adversarial transfer learning for Chinese Named Entity Recognition with Self-Attention Mechanism
- pretrain_model中下载对应预训练模型到对应Folder,具体详见Folder中README.md
- data中运行对应数据集preprocess.py得到tfrecord和data_params,这里用了Bert的wordPiece tokenizer,所以依赖以上预训练的vocab文件
- 运行单任务NER模型
python main.py --model bert_bilstm_crf --data msra
tensorboard --logdir ./checkpoint/ner_msra_bert_bilstm_crf- 运行多任务NER模型:按输入数据集类型可以是NER+NER的迁移/联合任务,也可以是NER+CWS的分词增强的NER任务。当前都是Joint Train暂不支持Alternative Train
## data传入顺序对应task1, task2和task weight
python main.py --model bert_bilstm_crf_mtl --data msra,people_daily
python main.py --model bert_bilstm_crf_adv --data msra,msr - 评估:以上模型训练完会dump测试集的预测结果到data,repo里已经上传了现成的预测结果可用
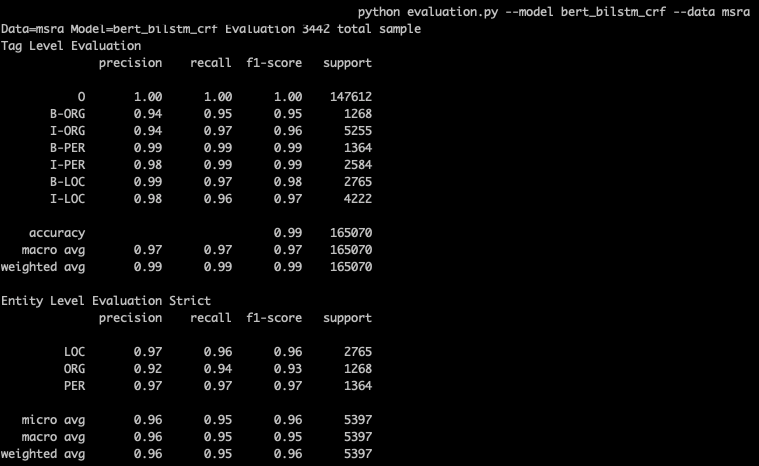
## 单模型:输出tag级别和entity级别详细结果
python evaluation.py --model bert_bilstm_crf --data msra
python evaluation.py --model bert_bilstm_crf_mtl_msra_msr --data msra ##注意多任务model_name=model_name_{task1}_{task2}
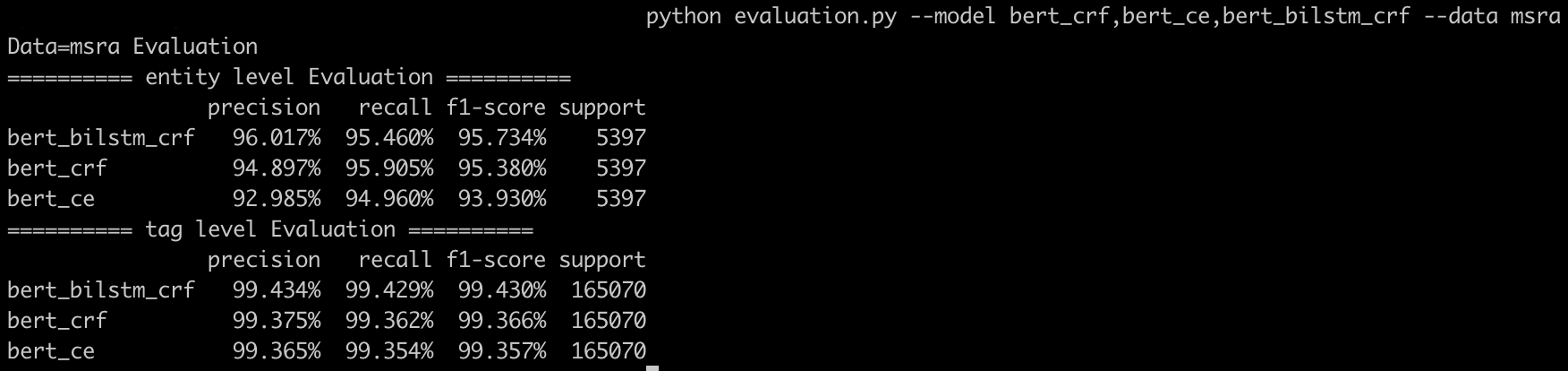
## 多模型对比:按F1排序输出tag和entity的weighted average结果
python evaluation.py --model bert_crf,bert_bilstm_crf,bert_bilstm_crf_mtl_msra_msr --data msra