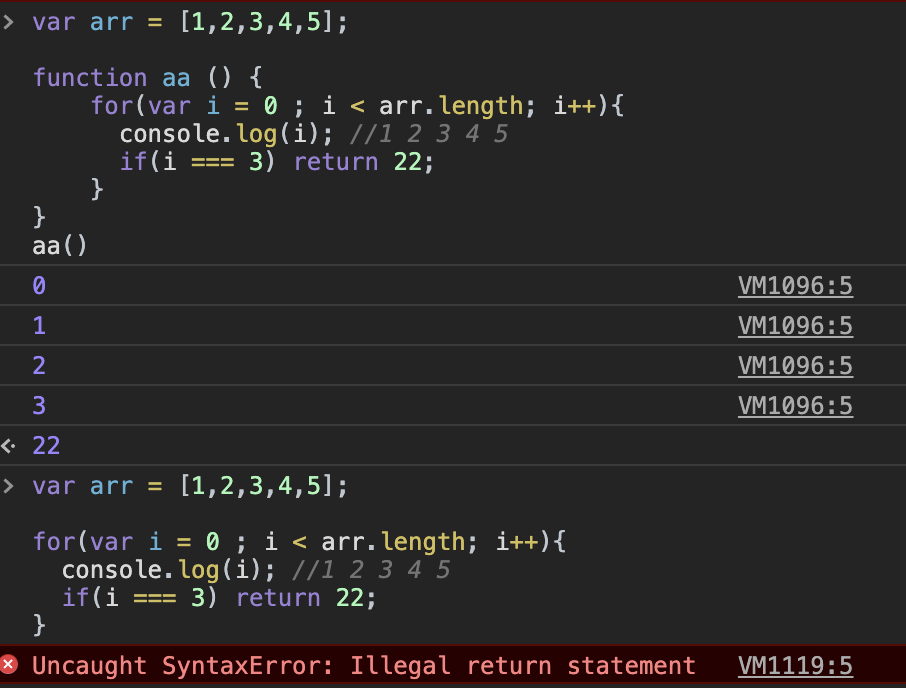
先来个经典数组操作题:
求斐波那契数列的前20 个数字。已知斐波那契数列中第一个数字是1 ,
第二个是2 ,从第三项开始,每一项都等于前两项之和
var fibonacci = [];
fibonacci[0] = 1;
fibonacci[1] = 2;
for(var i = 2; i < 20; i++){
fibonacci[i] = fibonacci[i-1] + fibonacci[i-2];
}
console.log(fibonacci); //[1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946]数组增删
push unshift shift pop
var numbers = [0,1,2,3,4,5,6,7,8,9];
numbers[numbers.length] = 10; //插入尾
numbers.push(11);//插入尾
numbers.push(12, 13); //插入尾
numbers.unshift(-2); //插入头
numbers.unshift(-4, -3);//插入头
numbers.shift();//删除并返回第一个数
numbers.pop(); // 删除并返回最后一个数
console.log(numbers); //[-3, -2, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,]
通过push和pop方法,就能用数组来模拟栈
通过shift和unshift方法,就能用数组模拟基本的队列数据结构
var averageTemp = [];
averageTemp[0] = [72,75,79,79,81,81];
averageTemp[1] = [81,79,75,75,73,72];
function printMatrix(myMatrix) {
for (var i=0; i<myMatrix.length; i++){
for (var j=0; j<myMatrix[i].length; j++){
console.log(myMatrix[i][j]);
}
}
}
printMatrix(averageTemp); //72 75 79 79 81 81 81 79 75 75 73 72三维就三个for循环,以此类推。
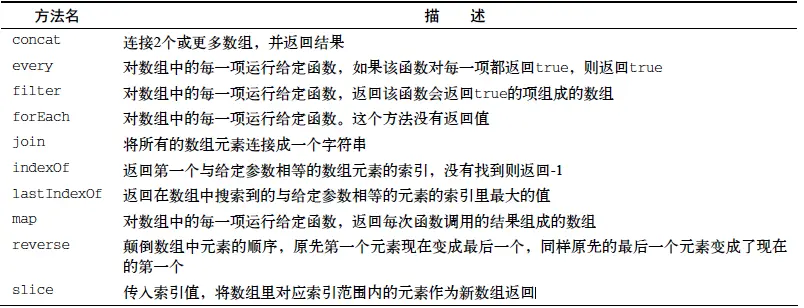
数组迭代方法

var zero = 0;
var positiveNumbers = [1,2,3];
var negativeNumbers = [-3,-2,-1];
console.log(negativeNumbers.concat(zero, positiveNumbers))//-3 -2 -1 0 1 2 3
console.log(negativeNumbers.concat(positiveNumbers))//-3 -2 -1 1 2 3
var isEven = function (x) {
// 如果x是2的倍数,就返回true
console.log(x);
return (x % 2 == 0) ? true : false;
// 也可以写成return (x % 2 == 0) ? true : false
};
var numbers = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15];
[every]数组numbers的第一个元素是1,它不是2的倍数, 因此isEven 函数返回false,然后every执行结束。
numbers.every(isEven); // 1 false
[some] some方法和every的行为类似,不过some方法会迭代数组的每个元素,直到函数返回true:
numbers.some(isEven); //1 2 true
[forEach]如果要迭代整个数组,可以用forEach方法。它和使用for循环的结果相同:
numbers.forEach(function(x){
console.log((x % 2 == 0));
}); // [false, true, false, true, false, true, false, true,
false, true, false, true, false, true, false]
[map]JavaScript还有两个会返回新数组的遍历方法。第一个是map:
var myMap = numbers.map(isEven); //:[false, true, false, true, false, true, false, true,false, true, false, true, false, true, false]
[filter]。它返回的新数组由使函数返回true的元素组成:
var evenNumbers = numbers.filter(isEven);//[2, 4, 6, 8, 10, 12, 14]
[reduce]reduce方法接收一个函数作为参数,这个函数有四个参数:previousValue、currentValue、index和array。这个函数会返回一个将被叠加到累加器的值,reduce方法停止执行后会返回这个累加器。对一个数组中的所有元素求和:
numbers.reduce(function(previous, current, index){
return previous + current;
}); //120slice
概念:
slice() 方法返回一个从开始到结束(不包括结束)选择的数组的一部分浅拷贝到一个新数组对象。原始数组不会被修改。
实例
//如果不传入参数二,那么将从参数一的索引位置开始截取,一直到数组尾
var a=[1,2,3,4,5,6];
var b=a.slice(0,3); //[1,2,3]
var c=a.slice(3); //[4,5,6]
//如果两个参数中的任何一个是负数,array.length会和它们相加,试图让它们成为非负数,举例说明:
//当只传入一个参数,且是负数时,length会与参数相加,然后再截取
var a=[1,2,3,4,5,6];
var b=a.slice(-1); //[6]
//当只传入一个参数,是负数时,并且参数的绝对值大于数组length时,会截取整个数组
var a=[1,2,3,4,5,6];
var b=a.slice(-6); //[1,2,3,4,5,6]
var c=a.slice(-8); //[1,2,3,4,5,6]
//当传入两个参数一正一负时,length也会先于负数相加后,再截取
var a=[1,2,3,4,5,6];
var b=a.slice(2,-3); //[3]
//当传入一个参数,大于length时,将返回一个空数组
var a=[1,2,3,4,5,6];
var b=a.slice(6); //[]
另外一种用法:
slice 方法可以用来将一个类数组(Array-like)对象/集合转换成一个新数组。你只需将该方法绑定到这个对象上。 一个函数中的 arguments 就是一个类数组对象的例子。
实例
function list() {
console.log(arguments); //Arguments(3) [1, 2, 3, callee: ƒ, Symbol(Symbol.iterator): ƒ]
console.log(Array.prototype.slice.call(arguments)) ; //[1, 2, 3]
}
list(1, 2, 3); splice
概念:
splice() 方法通过删除现有元素或添加新元素来更改一个数组的内容。
用法:array.splice(start,deleteCount,item...)
实例:
var myFish = ['angel', 'clown', 'mandarin', 'sturgeon'];
myFish.splice(2, 0, 'drum'); // 在索引为2的位置插入'drum'
// myFish 变为 ["angel", "clown", "drum", "mandarin", "sturgeon"]
myFish.splice(2, 1); // 从索引为2的位置删除一项(也就是'drum'这一项)
// myFish 变为 ["angel", "clown", "mandarin", "sturgeon"]
join
概念:
将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串。作用与split相反。
join() 方法,不会改变数组!
实例:
var arr = ["0", "1", "2"];
var b = arr.join("");// "012" 还有我写的另外一篇 js各种遍历方法总结