ericguo5513 / humanml3d Goto Github PK
View Code? Open in Web Editor NEWHumanML3D: A large and diverse 3d human motion-language dataset.
License: MIT License
HumanML3D: A large and diverse 3d human motion-language dataset.
License: MIT License












































































































Hi, i know how to animation the HumanML3D dataset, however i can't animation KIT-ml,the shape is (timesteps, 21,3),
Hi Eric,
Thanks for your great work. When I run motion_representation.ipynb, I meet the following errors.
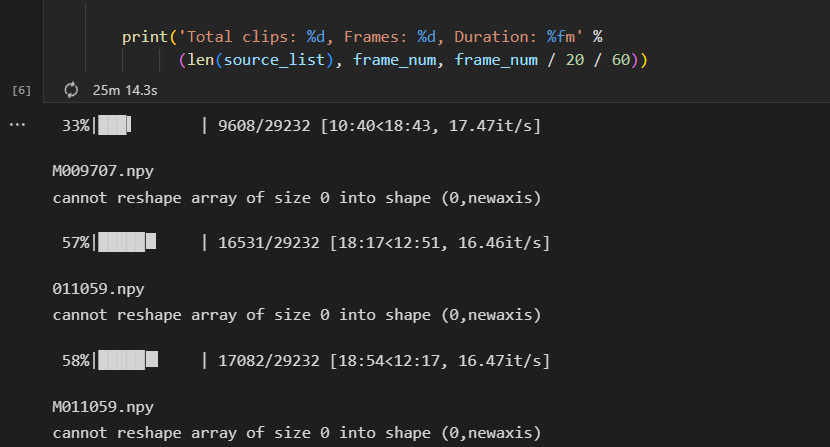
I wonder if it matters? And how to solve it.
Hi, I try to visualize the joints rotation representation, since converting from XYZ to joints rotation takes time.
And the result seems not right.
Here is my script. I have checked all the joints indexes and also make sure the bvh construction is correct.
from common.quaternion import *
from paramUtil import *
import sys
from rotation_conversions import *
mean = np.load('./HumanML3D/Mean.npy')
std = np.load('./HumanML3D/Std.npy')
ref2 = np.load('./HumanML3D/new_joint_vecs/012314.npy')
def recover_rot(data):
# dataset [bs, seqlen, 263/251] HumanML/KIT
joints_num = 22 if data.shape[-1] == 263 else 21
data = torch.Tensor(data)
r_rot_quat, r_pos = recover_root_rot_pos(data)
r_pos_pad = torch.cat([r_pos, torch.zeros_like(r_pos)], dim=-1).unsqueeze(-2)
r_rot_cont6d = quaternion_to_cont6d(r_rot_quat)
start_indx = 1 + 2 + 1 + (joints_num - 1) * 3
end_indx = start_indx + (joints_num - 1) * 6
cont6d_params = data[..., start_indx:end_indx]
cont6d_params = torch.cat([r_rot_cont6d, cont6d_params], dim=-1)
cont6d_params = cont6d_params.view(-1, joints_num, 6) # frames, joints, joints_dim
cont6d_params = torch.cat([cont6d_params, r_pos_pad], dim=-2)
return cont6d_params
def feats2rots(features):
features = features * std + mean
return recover_rot(features)
rot6d _all = feats2rots(ref2).numpy()
rot6d_all = rot6d_all.reshape(-1, 23,6)
rot6d_all_trans = rot6d_all[:,-1,:3]
rot6d_all_rot = rot6d_all[:,:-1]
matrix = rotation_6d_to_matrix(torch.Tensor(rot6d_all_rot))
euler = matrix_to_euler_angles(matrix, "XYZ")
euler = euler/np.pi*180
np.save('euler_rot_gt.npy', euler)
np.save('trans_rot_gt.npy',rot6d_all_trans)
the func 'rotation_6d_to_matrix' and 'matrix_to_euler_angles' are from https://github.com/Mathux/ACTOR/blob/master/src/utils/rotation_conversions.py
I got the skeleton results like this. (w/wo mean and std makes little different )

Have you tried to visualize rots? Need your help. Thanks so much!!
Hello, @EricGuo5513 thanks for releasing this dataset!
While processing dataset with the given raw_pose_processing.ipynb file, I got an error that says, no file named ./pose_data/KIT/3/kick_high_left02_poses.npy,
so I looked into the KIT dataset which I've downloaded from the AMASS webpage,
( I've downloaded SMPL-X N from the AMASS webpage, which gives me KIT.tar.bz2)
the file extension was .npz instead of .npy.
I tried to change its name to .npz but it gives the error message which says
KeyError: 'slice(0, 117, None) is not a file in the archive'
In this case, what would be the problem?
thanks!
Joseph
Is there any case that the 3D joint positions provided by the dataset are local transforms instead of global 3D positions?
Hi,
I notice that the paper says that motions in HumanML3D dataset follow the skeleton structure of SMPL with 22 joints. However, the official skeleton structure of SMPL has 23 body joints. I would like to know what is the detailed skeleton structure and indexes of body joints of HumanML3D.
Many Thanks for your reply and help.
Hi, thx for the nice work. The jupyter scripts are very helpful for learning the preprocessing pipeline. However, I don't quite understand why converting the joints representation to position in raw_pose_processing and then normalizing the position in motion_representation by ik + fk process. Is that ok to use the fixed shape to calculate the location of 'new_joints'? Thx!
An error occurs when calculating the root rotation of the skeleton data.
Accordingly, I confirmed that the nan value is generated in 007975.npy.
I think we missed the problem because I didn't get a runtime error warning while I was generating a value by changing to torch.
Therefore, we should add the _FLOAT_EPS value to the denominator during normalization.
HumanML3D/common/quaternion.py
Lines 28 to 30 in 9cc600a
to
def qnormalize(q):
assert q.shape[-1] == 4, 'q must be a tensor of shape (*, 4)'
return q / (torch.norm(q, dim=-1, keepdim=True) + _FLOAT_EPS)
Alternatively, we can replace all processes with a Numpy function so that we can view runtime errors and correct the problem.
def qnormalize_np(q):
assert q.shape[-1] == 4, 'q must be a tensor of shape (*, 4)'
return q / (np.sqrt((q ** 2).sum(axis=-1, keepdims=True)) + _FLOAT_EPS)
def qbetween_np_alternative(v0, v1):
"""
find the quaternion used to rotate v0 to v1
using only numpy
"""
assert v0.shape[-1] == 3, 'v0 must be of the shape (*, 3)'
assert v1.shape[-1] == 3, 'v1 must be of the shape (*, 3)'
v = np.cross(v0, v1)
w = np.sqrt((v0 ** 2).sum(axis=-1, keepdims=True) * (v1 ** 2).sum(axis=-1, keepdims=True)) + (v0 * v1).sum(axis=-1,
keepdims=True)
return qnormalize_np(np.concatenate([w, v], axis=-1))
Add an eps value to the code and then run motion_representation.ipynb,
My error values that occurred while running are as follows.
abs(reference1 - reference1_1).sum()
0.0047665355
abs(reference2 - reference2_1).sum()
0.0182359
In processing cal_mean_variance.ipynb, the nan value did not appear in 007975.npy
And error in mean, std are as follows.
abs(mean-reference1).sum()
0.010780404
abs(std-reference2).sum()
0.000663111
This issue was created to help others acquire a complete dataset. If need the same version, I will try to pull requests my code.
It seems like cal_mean_variance.ipynb computes mean and variance on all data, which leads data leakage since test data is used.
Hi Eric! Really nice work and also the repository is very well-explained.
I have seen that in your demo you commented the possibility to visualize the generated motions using skeleton (plot_motion_3d function).
I have tried to use that function (had to solve some errors to make use of it) and now it creates a .mp4 video with the correct time length and the title is plot correctly. However, it does not plot the skeleton (its just blank). Could you please provide me some steps to visualize the skeletons?
It's much faster and simpler to check qualitative results than the SMPL or render version.
Thanks for you awesome work, I have encountered the problem when processing data
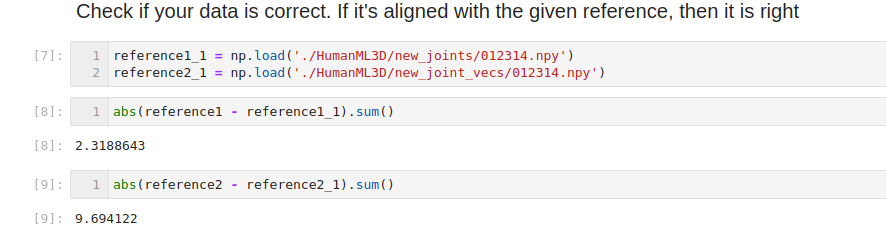
Seems the checked item is

I am wondering do you have any idea why it could happen. I follow the instruction, download SMPL+H Gdata from https://amass.is.tue.mpg.de/download.php.
Thanks
Hi, thx for the work.
I got the same question as in this issue #12. I check the downloaded data and scripts several times, they are exactly the same. Do you have any idea if the env or package may cause the difference? And could you please provide one or more other .npy for me to check. Thx!

I think the right code is
root_quat = qbetween_np(target, forward) which means rotate the [0,0,1] to the calculated vector forward
hello! thanks for your great job!
I have some question about motion represention!
In Common/Skeleton.py:forward_kinematics_np(), why do specially change first frame's root_quat , that would make root rotation discontinuous.
'''Get Root Rotation'''
target = np.array([[0,0,1]]).repeat(len(forward), axis=0)
root_quat = qbetween_np(forward, target)
'''Inverse Kinematics'''
quat_params = np.zeros(joints.shape[:-1] + (4,))
root_quat[0] = np.array([[1.0, 0.0, 0.0, 0.0]])
quat_params[:, 0] = root_quat
In get_rifke(): what it means "All pose face Z+"? In inverse_kinematics(), root rot is calculated by basis of np.array([[0, 1, 0]]), which directions to Y+.
_def get_rifke(r_rot, positions):
'''Local pose'''
positions[..., 0] -= positions[:, 0:1, 0]
positions[..., 2] -= positions[:, 0:1, 2]
'''All pose face Z+'''
positions = qrot_np(np.repeat(r_rot[:, None], positions.shape[1], axis=1), positions)
return positions_
I'm getting this error:
E:\AI\HumanML3D>conda env create -f environment.yaml
Collecting package metadata (repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 4.12.0
latest version: 22.9.0
Please update conda by running
$ conda update -n base -c defaults conda
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Installing pip dependencies: \ Ran pip subprocess with arguments:
['C:\\Users\\Abdullah\\miniconda3\\envs\\torch_render\\python.exe', '-m', 'pip', 'install', '-U', '-r', 'E:\\AI\\HumanML3D\\condaenv.842xv54t.requirements.txt']
Pip subprocess output:
Collecting absl-py==1.0.0
Using cached absl_py-1.0.0-py3-none-any.whl (126 kB)
Pip subprocess error:
ERROR: Could not find a version that satisfies the requirement body-visualizer
ERROR: No matching distribution found for body-visualizer
failed
CondaEnvException: Pip failed
E:\AI\HumanML3D>
Hello, thanks for the awesome work!
For the output of 'raw_pose_processing.ipynb' which is inside the joints folder. The numpy files have the format [number of frames, 52, 3].
I am wondering what the dimensions (52, 3) represent.
Do they represent the (x,y,z) translations of first 22 SMPL joints plus something else?
Hello, when I run run the script "raw_pose_processing.ipynb" in order to obtain HumanML3D dataset, I got the error. Can you help me?
KeyError Traceback (most recent call last)
/tmp/ipykernel_658104/704857661.py in
10 num_dmpls = 8 # number of DMPL parameters
11
---> 12 male_bm = BodyModel(bm_fname=male_bm_path, num_betas=num_betas, num_dmpls=num_dmpls, dmpl_fname=male_dmpl_path).to(comp_device)
13 faces = c2c(male_bm.f)
14
/mnt/SSD_3TB/lingling/code/HumanML3D/human_body_prior/body_model/body_model.py in init(self, bm_fname, num_betas, num_dmpls, dmpl_fname, num_expressions, use_posedirs, dtype, persistant_buffer)
71
72 # njoints = smpl_dict['posedirs'].shape[2] // 3
---> 73 njoints = smpl_dict['allow_pickle'].shape[2] // 3
74 self.model_type = {69: 'smpl', 153: 'smplh', 162: 'smplx', 45: 'mano', 105: 'animal_horse', 102: 'animal_dog', }[njoints]
75
~/miniconda3/envs/torch_render/lib/python3.7/site-packages/numpy/lib/npyio.py in getitem(self, key)
264 return self.zip.read(key)
265 else:
--> 266 raise KeyError("%s is not a file in the archive" % key)
267
268
KeyError: 'allow_pickle is not a file in the archive'
Hi, this is quite confusing. After generating all dataset, the check part show the differernt with your provided samping.
Maybe this comes from the downloaded version of AMASS (might not be all from SMPLH+G).
./HumanML3D/motion_representation.ipynb
abs(reference1 - reference1_1).sum()
0.0031513844
abs(reference2 - reference2_1).sum()
0.01839152
./HumanML3D/cal_mean_variance.ipynb
abs(mean-reference1).sum()
0.010486759
abs(std-reference2).sum()
0.0014993595
Hi! Thank you for the wonderful dataset.
I got some error by running raw_pose_processing.ipynb: No such file or directory: './pose_data/KIT/3/kick_high_left02_poses.npy'.
It seems that there were no 3 folder in the KIT dataset too.
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Input In [12], in <cell line: 1>()
2 source_path = index_file.loc[i]['source_path']
3 new_name = index_file.loc[i]['new_name']
----> 4 data = np.load(source_path)
5 start_frame = index_file.loc[i]['start_frame']
6 end_frame = index_file.loc[i]['end_frame']
File ~\anaconda3\envs\TM2T\lib\site-packages\numpy\lib\npyio.py:390, in load(file, mmap_mode, allow_pickle, fix_imports, encoding)
388 own_fid = False
389 else:
--> 390 fid = stack.enter_context(open(os_fspath(file), "rb"))
391 own_fid = True
393 # Code to distinguish from NumPy binary files and pickles.
FileNotFoundError: [Errno 2] No such file or directory: './pose_data/KIT/3/kick_high_left02_poses.npy'
It appears that the time taken to execute raw_pose_preprocessing.py over all the amass data as 3-4 days. Is it expected or am I doing something wrong.
Everything was fine, the double checks were all fairly close to 0 (for example 0.0047665355)
But the last code block of code in animation.ipynb gave me this error.

I am attempting to run this on Windows.
In the raw_pose_processing.ipynb script, I get this error.

I noticed that the hand poses are reserved in the raw pose processing, but are discarded in the motion representation. If I want to reserve the hand poses in motion representation, what can I do? What should I change in your code?
Hi @EricGuo5513,
First of all, thanks for your work and for releasing this dataset.
I have a question concerning the creation/conversion of this dataset. At the end of the file raw_pose_processing.ipynb, there is this bloc of line which I don't understand:
I have some questions:
Thanks a lot for your help
Hello!
Thank you for sharing the dataset. May I ask how to generate data in the same format as HumanML3D from my own recorded video?
As far as I know, we can use the VIBE method to extract smpl data from the video, but the smpl data generated by VIBE is still different from the smplh data provided by AMASS. Can you give me some advice?
How can I extract SMPLH thetas (21 joints * 6d) from your 263/251 pose vector?
Thanks!
Hello, In the paper it was mentioned that an external dictionary was manually constructed to collect motion-related
words and categorize them into four types: direction, body part, object and action
I can't find where it was defined in this project code ?
Hi,
I downloaded the KIT dataset and I am getting confused about how to understand it. So I am looking at the 00001.npy and these are the shapes I am getting.
new_joint_vecs
(47, 251)
new_joints
(47, 21, 3)
I am assuming that 47 is the number of frames. I am confused by what 251 is. The 21,3 is clearly the x,y,z joints. Thanks
Hi,
I found the following output from the motion_representation.ipynb script. I wonder is this an issue or we can just ignore it?

Dear author,
Could you share the code you use to get the part of speech of a word?
Running the repository in Torch CPU.
In mdm.py for the class MDM in the method "load_and_freeze_clip".
def load_and_freeze_clip(self, clip_version):
clip_model, clip_preprocess = clip.load(clip_version, device='cpu',
jit=False) # Must set jit=False for training
clip.model.convert_weights(
clip_model) # Actually this line is unnecessary since clip by default already on float16.
The comment solved the problem, but in the class Transformer init ResidualAttentionBlock continue with default float16.
Don't considering the inference on cpu.
Dear Eric:
As for the text coding, I am not very familiar with it.
When I ran the text_process.py file, I was prompted that the contents of this folder of dataset were missing.
Could you tell me where I can download this folder?
Looking forward to your reply!
Thanks for your great work! I wonder what the raw_offsets in paramUtil.py stands for?
Lines 32 to 57 in e8417a6
Hi! I have an issue when pre-processing the data. I follow the instructions and use the jupter notebook to process. It turns out the motion representation result has large error but the mean and std seem like in a reasonable range. Do you have any idea of why I get these results? Thanks.


Hi, thanks for your dataset and work. I quickly review your code, but don't find any rendering for your figures of paper. Sorry to ask about the rendering results for smpl.
A small error:
envi or nment.yaml => environment.yaml
How to convert the kit-ml dataset into the human-3d dataset?
Whether it can be or not?
In addition, how to obtain the data for kit-ml dataset?
Can you provide some information about representations of 21 joints of KIT, like joint 0 represents MidHip or something else?
name: torch_render
channels:
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- argon2-cffi=21.3.0
- argon2-cffi-bindings=21.2.0
- attrs=21.4.0
- backcall=0.2.0
- beautifulsoup4=4.11.1
- blas=1.0=mkl
- bleach=4.1.0
- bottleneck=1.3.4
- brotli=1.0.9
- ca-certificates=2022.4.26
- certifi=2022.5.18.1
- cffi=1.15.0
- cycler=0.11.0
- debugpy=1.5.1
- decorator=5.1.1
- defusedxml=0.7.1
- entrypoints=0.4
- expat=2.4.4
- fonttools=4.25.0
- giflib=5.2.1
- glib=2.69.1
- icu=58.2
- importlib-metadata=4.11.3
- importlib_metadata=4.11.3
- importlib_resources=5.2.0
- intel-openmp=2021.4.0
- ipykernel=6.9.1
- ipython=7.31.1
- ipython_genutils=0.2.0
- ipywidgets=7.6.5
- jedi=0.18.1
- jinja2=3.0.3
- jpeg=9e
- jsonschema=4.4.0
- jupyter=1.0.0
- jupyter_client=7.2.2
- jupyter_console=6.4.3
- jupyter_core=4.10.0
- jupyterlab_pygments=0.1.2
- jupyterlab_widgets=1.0.0
- kiwisolver=1.4.
- libpng=1.6.37
- libsodium=1.0.18
- libtiff=4.2.0
- libwebp=1.2.2
- libwebp-base=1.2.2
- libxml2=2.9.12
- lz4-c=1.9.3
- markupsafe=2.0.1
- matplotlib=3.3.4
- matplotlib-base=3.3.4
- matplotlib-inline=0.1.2
- mistune=0.8.4
- mkl=2021.4.0
- mkl-service=2.4.0
- mkl_fft=1.3.1
- mkl_random=1.2.2
- munkres=1.1.4
- nbclient=0.5.13
- nbconvert=6.4.4
- nbformat=5.3.0
- nest-asyncio=1.5.5
- notebook=6.4.11
- numexpr=2.8.1
- numpy-base=1.21.5
- openssl=1.1.1o
- packaging=21.3
- pandas=1.3.5
- pandocfilters=1.5.0
- parso=0.8.3
- pcre=8.45
- pexpect=4.8.0
- pickleshare=0.7.5
- pip=21.0.1
- prometheus_client=0.13.1
- prompt-toolkit=3.0.20
- prompt_toolkit=3.0.20
- ptyprocess=0.7.0
- pycparser=2.21
- pygments=2.11.2
- pyparsing=3.0.4
- pyqt=5.9.2
- pyrsistent=0.18.0
- python=3.7.10
- python-dateutil=2.8.2
- python-fastjsonschema=2.15.1
- pytz=2021.3
- pyzmq=22.3.0
- qt=5.9.7
- qtconsole=5.3.0
- qtpy=2.0.1
- send2trash=1.8.0
- setuptools=52.0.0
- sip=4.19.8
- six=1.16.0
- soupsieve=2.3.1
- sqlite=3.35.4
- terminado=0.13.1
- testpath=0.5.0
- tk=8.6.10
- tornado=6.1
- traitlets=5.1.1
- typing-extensions
- typing_extensions=4.1.1
- wcwidth=0.2.5
- webencodings=0.5.1
- wheel=0.36.2
- widgetsnbextension=3.5.2
- xz=5.2.5
- zeromq=4.3.4
- zipp=3.8.0
- zlib=1.2.11
- zstd=1.4.9
- pip:
- absl-py==1.0.0
- body-visualizer==1.1.0
- cachetools==4.2.4
- charset-normalizer==2.0.12
- configer==1.4.1
- configparser==5.2.0
- dotmap==1.3.23
- freetype-py==2.3.0
- future==0.18.2
- google-auth==1.35.0
- google-auth-oauthlib==0.4.6
- grpcio==1.46.3
- idna==3.3
- imageio==2.19.3
- install==1.3.5
- markdown==3.3.7
- networkx==2.6.3
- numpy==1.18.5
- oauthlib==3.2.0
- opencv-python==4.5.5.64
- pillow==9.1.1
- protobuf==3.20.1
- psbody-mesh==0.4
- pyasn1==0.4.8
- pyasn1-modules==0.2.8
- pyglet==1.5.26
- pyopengl==3.1.0
- pyrender==0.1.45
- pytorch-lightning==0.9.0
- pywavelets==1.3.0
- pyyaml==5.4.1
- requests==2.27.1
- requests-oauthlib==1.3.1
- rsa==4.8
- scikit-image==0.19.2
- scipy==1.7.3
- smplx==0.1.28
- tensorboard==2.2.0
- tensorboard-plugin-wit==1.8.1
- tensorboardx==2.5.1
- tifffile==2021.11.2
- torch==1.7.1
- torchgeometry==0.1.2
- tqdm==4.47.0
- transforms3d==0.3.1
- trimesh==3.12.5
- urllib3==1.26.9
- werkzeug==2.1.2
prefix: /home/chuan/anaconda3/envs/torch_render
Hi,
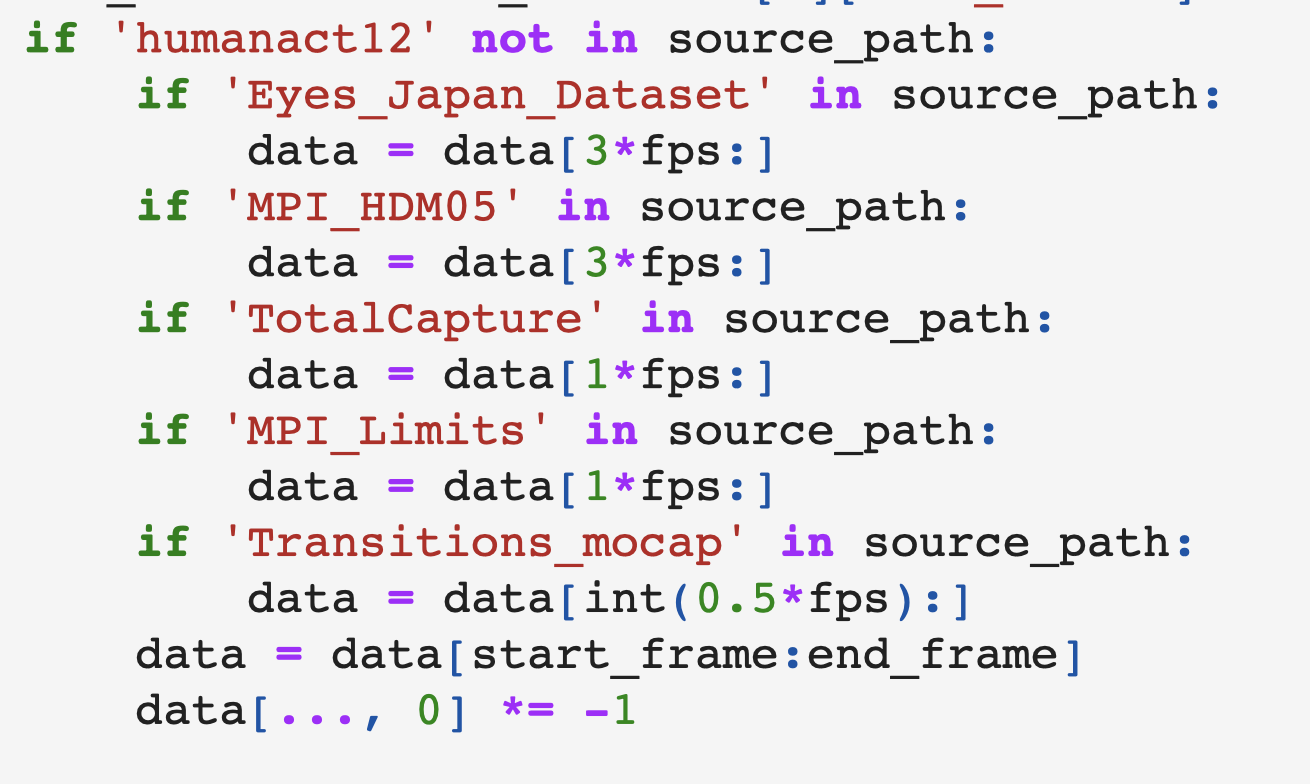
the following code is from raw_pose_processing.ipynb, and I am confused that why the first dimension of the data should be multiplied -1 before being send to the function swap_left_right?
for i in tqdm(range(total_amount)):
source_path = index_file.loc[i]['source_path']
new_name = index_file.loc[i]['new_name']
data = np.load(source_path)
start_frame = index_file.loc[i]['start_frame']
end_frame = index_file.loc[i]['end_frame']
if 'humanact12' not in source_path:
if 'Eyes_Japan_Dataset' in source_path:
data = data[3*fps:]
if 'MPI_HDM05' in source_path:
data = data[3*fps:]
if 'TotalCapture' in source_path:
data = data[1*fps:]
if 'MPI_Limits' in source_path:
data = data[1*fps:]
if 'Transitions_mocap' in source_path:
data = data[int(0.5*fps):]
data = data[start_frame:end_frame]
data[..., 0] *= -1
data_m = swap_left_right(data)
# save_path = pjoin(save_dir, )
np.save(pjoin(save_dir, new_name), data)
np.save(pjoin(save_dir, 'M'+new_name), data_m)
Hi, thanks for your nice work!
The errors are shown in the following images. I am not sure whether those errors are in the normal range?


No offense. I notice there is a similar dataset BABEL (also mentioned in your paper). Is there any comparison or differences between the two datasets (like Tab. 1 in your paper)? I think both two works are valuable, but try to figure out their features or focus.
In raw_pose_processing.ipynb, you choose example_id = "000021" and the first frame of it to calculate the target offsets. But it seems that different id and different frame will result in different target offsets. Can you tell me why you choose the first frame of "000021" but not calculate the target offsets for each frame of each id?
Hi, Sorry, I am a little bit new to this area. I am wondering how to augment the current HumanML3D data by simply concatenating the same or different motion sequences together. For example, 'jumping jack four times.' Is it possible to achieve that? And how exactly? Thank you.
More than an issue i have some questions. would thank you if you can answer to make everyone know.
1-Amass is a database different from HumanML3D? and the job of HumanML3D is to mix them and also put labels?
2-i'm not sure if this dataset has inside the "The kit motion-language dataset". Because inside of AMASS there is a dataset called KIT

Thanks
Stefano
Hi, Eric! I'm trying to make a real time AI controlled motion agent. Because the skeleton of the agent is different, I have to convert the XYZ coordinate to the joint rotations first and then conduct FK to calculate the new joint positions. When I use the function from Skeleton.py, I meet the same problem as #26
May I ask why do you use xyz coordinate as the ouput but not joint rotation? Is there any real-time way to transfer the xyz coordinates to the joint rotation?
Thanks for your time. I'll appreciate a lot if you can help me.
Hi, I'm curious about the root rotation recovery.
the recovery of root rotation use rot_vel = data[..., 0] in function recover_root_rot_pos(), which is calculated by r_velocity.

This is delta_theta/2.0 as I understand, which has no XYZ (axis) information in it. I wonder how this representation represents the rotation in other axes(like XZ).
Hello,
how is it obtained the Mean.npy and Std.npy values?
Line 39 in dbe45f0
I believe this line should be conda env create -f environment.yaml. Correct me if I'm wrong.
Thanks for your great work! I encountered a problem when installing the environment.
"Error: Could not find a version that satisfies the requirement body-visualizer, Error: No matching distribution found for body-visualizer" appeared when installing body-visualizer.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.