This project (JobRunr+) is a fork of JobRunr.
The main changes and extensions are:
- Support HTTPS (dashboard)
- Support automatic (self-signed) and user-specified certificates (dashboard)
- Allow disabling automatic job state changes (core)
- Allow automatic job deletion for failed jobs (core)
- Allow jobs to signal through an exception that no retries should be performed (core)
- Allow users to specify job metadata at the same time (transactionally) a job is submitted, so that it can be used to make decisions during the enqueue of other jobs (core)
- Allow users to specify custom external resources (e.g.: files on disk, files in S3, data in databases, ...) that are automatically removed (as specified by the user) when a job is permanently removed. This can be used to store resources for the completion of the job (so that it can be retried as long as it is visible in the dashboard) or logs (so that they are available until the job is visible in the dashboard)
- Allow users to manually specify the json mapper (JSONB, GSON, JACKSON) so that a selection can be made even if some library pollutes the classpath with its transitive dependencies.
- Support additional databases (Marklogic, ...)
- Support extra static configuration options (dashboard)
- Removal of messages meant more for developer than users
- Extra controls for recurring jobs
- The same recurring job can no longer be run in parallel
- Exceptions are not swallowed by the dashboard logger
- Recurring jobs scheduling allows extra arguments

The ultimate library to perform background processing on the JVM.
Dead simple API. Extensible. Reliable.
Distributed and backed by persistent storage.
Open and free for commercial use.



BackgroundJob.enqueue(() -> System.out.println("This is all you need for distributed jobs!"));Incredibly easy way to perform fire-and-forget, delayed, scheduled and recurring jobs inside Java applications using only Java 8 lambda's. CPU and I/O intensive, long-running and short-running jobs are supported. Persistent storage is done via either RDBMS (e.g. Postgres, MariaDB/MySQL, Oracle, SQL Server, DB2 and SQLite) or NoSQL (ElasticSearch, MongoDB and Redis).
JobRunr provides a unified programming model to handle background tasks in a reliable way and runs them on shared hosting, dedicated hosting or in the cloud (hello Kubernetes) within a JVM instance.
Thanks for building JobRunr, I like it a lot! Before that I used similar libraries in Ruby and Golang and JobRunr so far is the most pleasant one to use. I especially like the dashboard, it’s awesome! Alex Denisov
View more feedback on jobrunr.io.
- Simple: just use Java 8 lambda's to create a background job.
- Distributed & cluster-friendly: guarantees execution by single scheduler instance using optimistic locking.
- Persistent jobs: using either a RDMBS (four tables and a view) or a noSQL data store.
- Embeddable: built to be embedded in existing applications.
- Minimal dependencies: (ASM, slf4j and either jackson and jackson-datatype-jsr310, gson or a JSON-B compliant library).
Some scenarios where it may be a good fit:
- within a REST api return response to client immediately and perform long-running job in the background
- mass notifications/newsletters
- calculations of wages and the creation of the resulting documents
- batch import from xml, csv or json
- creation of archives
- firing off web hooks
- image/video processing
- purging temporary files
- recurring automated reports
- database maintenance
- updating elasticsearch/solr after data changes
- …and so on
You can start small and process jobs within your web app or scale horizontally and add as many background job servers as you want to handle a peak of jobs. JobRunr will distribute the load over all the servers for you. JobRunr is also fault-tolerant - is an external web service down? No worries, the job is automatically retried 10-times with a smart back-off policy.
JobRunr is a Java alternative to HangFire, Resque, Sidekiq, delayed_job, Celery and is similar to Quartz and Spring Task Scheduler.
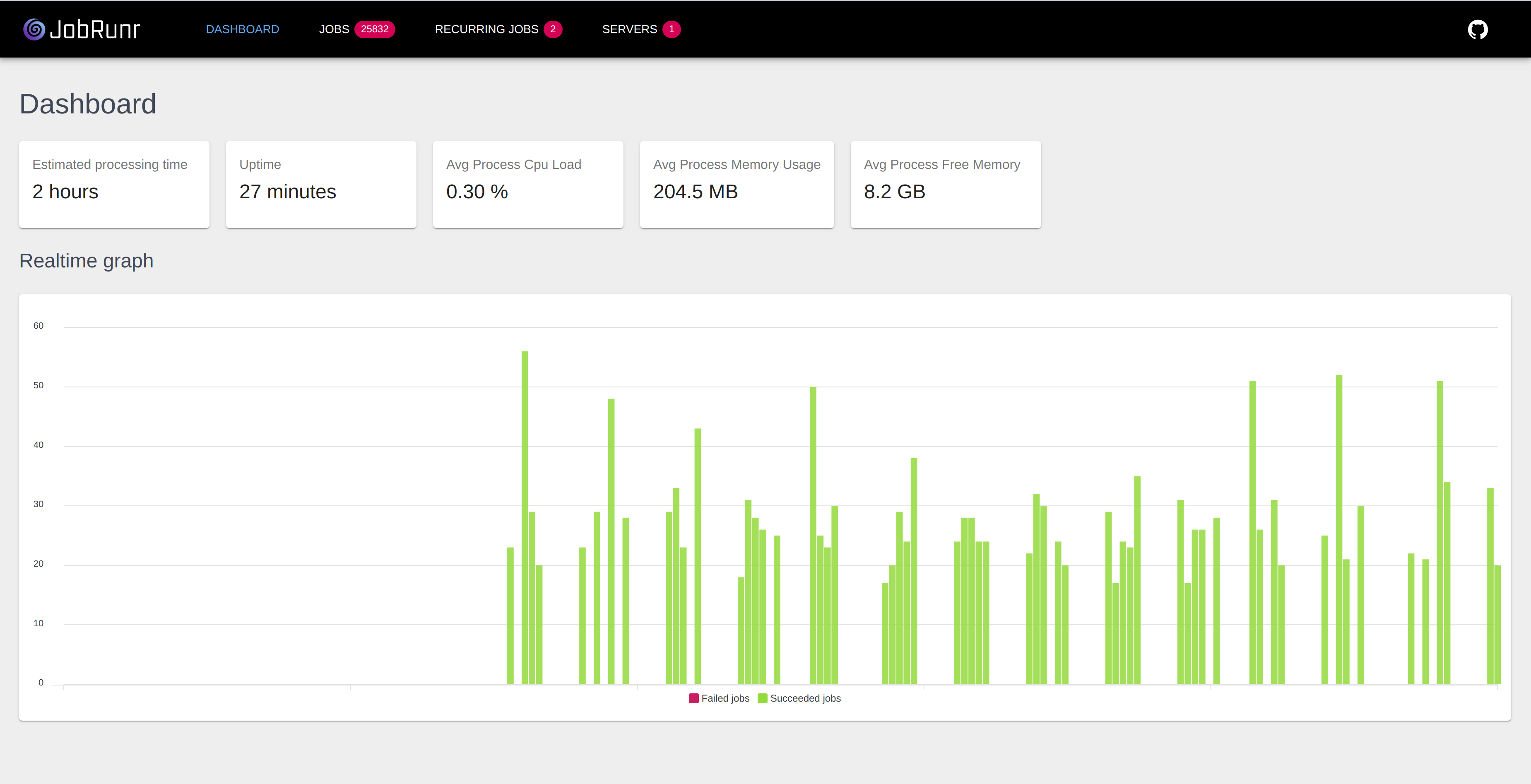




Dedicated worker pool threads execute queued background jobs as soon as possible, shortening your request's processing time.
BackgroundJob.enqueue(() -> System.out.println("Simple!"));Scheduled background jobs are executed only after a given amount of time.
BackgroundJob.schedule(Instant.now().plusHours(5), () -> System.out.println("Reliable!"));Recurring jobs have never been simpler; just call the following method to perform any kind of recurring task using the CRON expressions.
BackgroundJob.scheduleRecurringly("my-recurring-job", Cron.daily(), () -> service.doWork());Process background tasks inside a web application…
You can process background tasks in any web application and we have thorough support for Spring - JobRunr is reliable to process your background jobs within a web application.
… or anywhere else
Like a Spring Console Application, wrapped in a docker container, that keeps running forever and polls for new background jobs.
See https://www.jobrunr.io for more info.
JobRunr is available in Maven Central - all you need to do is add the following dependency:
<dependency>
<groupId>org.jobrunr</groupId>
<artifactId>jobrunr</artifactId>
<version>4.0.3</version>
</dependency>Just add the dependency to JobRunr:
implementation 'org.jobrunr:jobrunr:4.0.3'Add the jobrunr-spring-boot-starter to your dependencies and you're almost ready to go! Just set up your application.properties:
# the job-scheduler is enabled by default
# the background-job-server and dashboard are disabled by default
org.jobrunr.job-scheduler.enabled=true
org.jobrunr.background-job-server.enabled=true
org.jobrunr.dashboard.enabled=true
Define a javax.sql.DataSource and put the following code on startup:
@SpringBootApplication
public class JobRunrApplication {
public static void main(String[] args) {
SpringApplication.run(JobRunrApplication.class, args);
}
@Bean
public JobScheduler initJobRunr(DataSource dataSource, JobActivator jobActivator) {
return JobRunr.configure()
.useJobActivator(jobActivator)
.useStorageProvider(SqlStorageProviderFactory
.using(dataSource))
.useBackgroundJobServer()
.useDashboard()
.initialize();
}
}See CONTRIBUTING for details on submitting patches and the contribution workflow.
- Take a look at issues with tag called
Good first issue - Join the discussion on Github discussion - we won't be using Gitter anymore.
- Answer questions on issues.
- Fix bugs reported on issues, and send us pull request.
git clone https://github.com/jobrunr/jobrunr.gitcd jobrunrcd core/src/main/resources/org/jobrunr/dashboard/frontendnpm inpm run buildcd -./gradlew :core:publishToMavenLocal./gradlew :jobrunr-kotlin-14-support:publishToMavenLocal./gradlew :jobrunr-kotlin-15-support:publishToMavenLocal./gradlew :jobrunr-spring-boot-starter:publishToMavenLocal./gradlew :platform:publishToMavenLocal
Then, in your own project you can depend on org.jobrunr:jobrunr:1.0.0-SNAPSHOT.
*
git checkout fc-master
git reset --hard HEAD
git clean -qdfx
git pull origin fc-master
git checkout master
git reset --hard HEAD
git clean -qdfx
git pull upstream master
git checkout -b fc-merge-upstream-20xx-yy-zz
git push origin fc-merge-upstream-20xx-yy-zz
git merge fc-master
Then fix conflicts and increase version.









![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")









