![]()
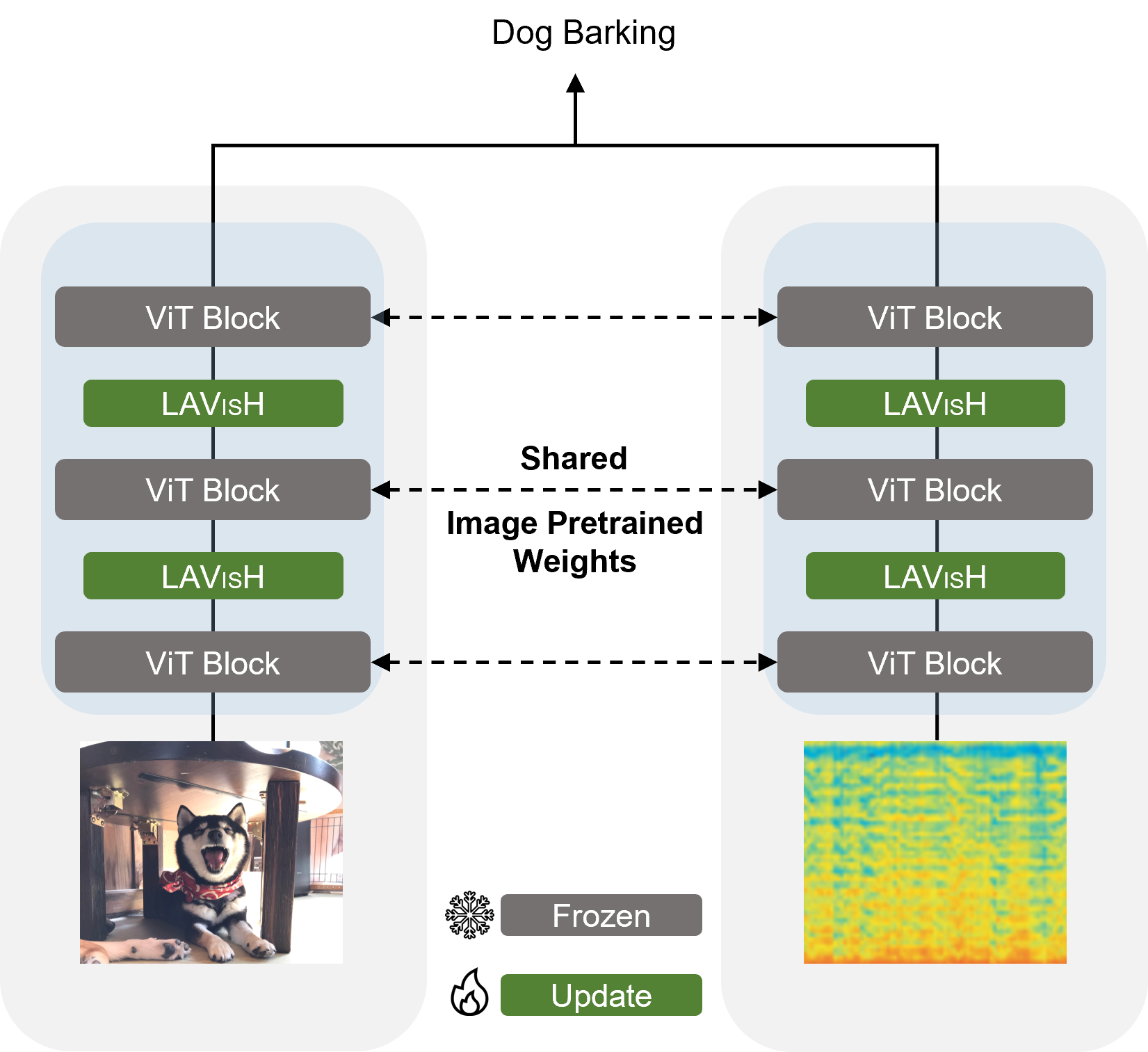
This is the PyTorch implementation of our paper:
Yan-Bo Lin, Yi-Lin Sung, Jie Lei, Mohit Bansal, and Gedas Bertasius
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
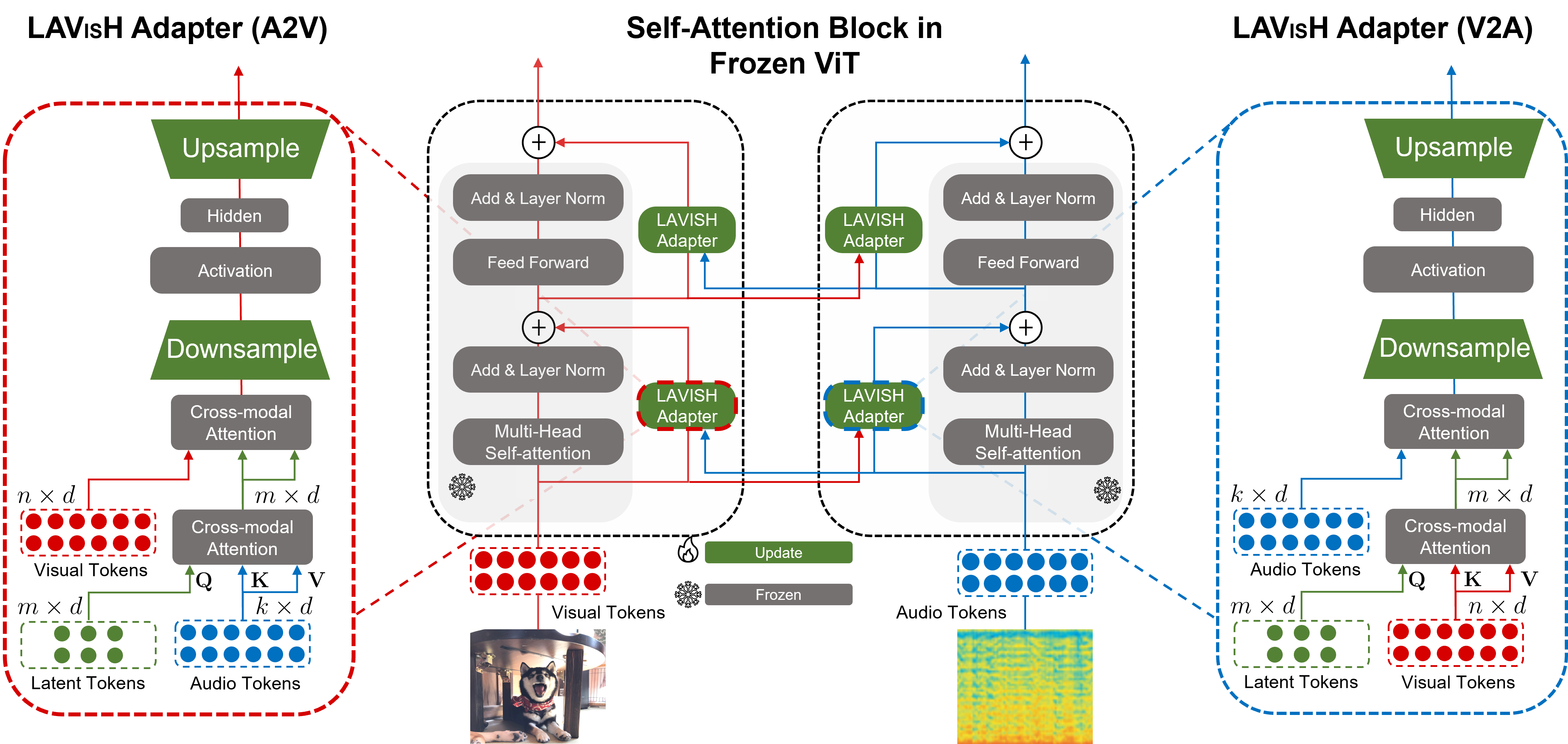
Our Method
See each foloder for more detailed settings- Audio-Visual Event Localization: ./AVE
- Audio-Visual Segmentation: ./AVS
- Audio-Visual Question Answering: ./AVQA
If you use this code in your research, please cite:
@InProceedings{LAVISH_CVPR2023,
author = {Lin, Yan-Bo and Sung, Yi-Lin and Lei, Jie and Bansal, Mohit and Bertasius, Gedas},
title = {Vision Transformers are Parameter-Efficient Audio-Visual Learners},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2023}
}Our code is based on AVSBench and MUSIC-AVQA
| Tasks | Checkpoints |
|---|---|
| AVE | model |
| AVS | model |
| AVQA | model |



























































































