goccy / bigquery-emulator Goto Github PK
View Code? Open in Web Editor NEWBigQuery emulator server implemented in Go
License: MIT License
BigQuery emulator server implemented in Go
License: MIT License


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





















































































































I'm seeing a crash when I try to use a date inside of a STRUCT in UNNEST statement.
For reference, this query does NOT crash:
SELECT DATE(2022, 1, 1) AS a, b
FROM UNNEST([
STRUCT(1 AS b)
]);
But this very similar query that should produce the same results does:
SELECT a, b
FROM UNNEST([
STRUCT(DATE(2022, 1, 1) AS a, 1 AS b)
]);
This is the error log:
2022-08-29T23:38:03.026Z ERROR server/handler.go:40 internal error {"error": "failed to query SELECT zetasqlite_get_struct_field_date(`$unnest1#1`, 0) AS `a#2`,zetasqlite_get_struct_field_int64(`$unnest1#1`, 1) AS `b#3` FROM (SELECT json_each.value AS `$unnest1#1` FROM json_each(zetasqlite_decode_array_string(zetasqlite_make_array_array(zetasqlite_make_struct_struct('zetasqlite_date_date(2022,1,1)',zetasqlite_date_date(2022,1,1),'1',1))))): no such function: zetasqlite_make_array_array"}
I also see the same crash when using a different date function:
SELECT a, b
FROM UNNEST([
STRUCT(PARSE_DATE('%Y-%m-%d', '2022-01-01') AS a, 1 AS b)
]);
Thank you!
In our automated test suite, we create tables in the setUp method and drop them again in the tearDown method. And then they will get recreated in the setUp for the next test. The emulator doesn't seem to be able to drop and recreate a table. The drop command works, but then the next create command throws this error:
ERROR server/handler.go:2037 duplicate {"error": "duplicate: table asset1669896670005735815: table is already created"}
When I run any query with an ARRAY type column in a result, the Python client (I am using 2.34.4, an older version) crashes with this trace:
File ".../lib/python3.9/site-packages/google/cloud/bigquery/job/query.py", line 1522, in result
self._query_results.schema,
File ".../lib/python3.9/site-packages/google/cloud/bigquery/query.py", line 967, in schema
return _parse_schema_resource(self._properties.get("schema", {}))
File ".../lib/python3.9/site-packages/google/cloud/bigquery/schema.py", line 356, in _parse_schema_resource
return [SchemaField.from_api_repr(f) for f in info.get("fields", ())]
File ".../lib/python3.9/site-packages/google/cloud/bigquery/schema.py", line 356, in <listcomp>
return [SchemaField.from_api_repr(f) for f in info.get("fields", ())]
File ".../lib/python3.9/site-packages/google/cloud/bigquery/schema.py", line 148, in from_api_repr
field_type = api_repr["type"].upper()
KeyError: 'type'
Here is a script that produces this result:
from typing import Iterator
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
if __name__ == '__main__':
project_id_ = 'test_project'
client = BigQueryClientWrapper(project_id=project_id_)
client.run_query(f"SELECT [1, 2, 3] as a;")
The same script does not crash for me when I swap out the bigquery.Client for one that is querying against a real BigQuery project.
Thank you!
There does not seem to be much information available in the emulator.
In my use case, requires Job and Table information.
Can you make it so that I get the same information as BigQuery?
https://cloud.google.com/bigquery/docs/reference/rest/v2/jobs
https://cloud.google.com/bigquery/docs/reference/rest/v2/tables
Job in BigQuery
$ bq query --use_legacy_sql=false --project_id=my-project --job_id=dummy-job-id 'select * from `dataset1`.`table_a`'
[
{
"id": "1",
"name": "alice"
},
{
"id": "2",
"name": "bob"
}
]
$ bq show --project_id=my-project --job=true dummy-job-id
{
"configuration": {
"jobType": "QUERY",
"query": {
"destinationTable": {
"datasetId": "<datasetId>",
"projectId": "my-project",
"tableId": "<tableId>"
},
"priority": "INTERACTIVE",
"query": "select * from `dataset1`.`table_a`",
"useLegacySql": false,
"writeDisposition": "WRITE_TRUNCATE"
}
},
"etag": "<etag>",
"id": "my-project:<location>.dummy-job-id",
"jobReference": {
"jobId": "dummy-job-id",
"location": "<location>",
"projectId": "my-project"
},
"kind": "bigquery#job",
"selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/my-project/jobs/dummy-job-id?location=<location>",
"statistics": {
"creationTime": "1662625182766",
"endTime": "1662625182927",
"query": {
"cacheHit": true,
"statementType": "SELECT",
"totalBytesBilled": "0",
"totalBytesProcessed": "0"
},
"startTime": "1662625182805",
"totalBytesProcessed": "0"
},
"status": {
"state": "DONE"
},
"user_email": "<my email address>"
}
Job in emulator
$ bq --api=http://localhost:9050/ query --use_legacy_sql=false --project_id=test --job_id=dummy-job-id 'select * from `dataset1`.`table_a`'
[
{
"id": "1",
"name": "alice"
},
{
"id": "2",
"name": "bob"
}
]
$ bq --api=http://localhost:9050/ show --project_id=test --job=true dummy-job-id{
"configuration": {
"query": {
"query": "select * from `dataset1`.`table_a`",
"useLegacySql": false
}
},
"jobReference": {
"jobId": "dummy-job-id",
"projectId": "test"
},
"status": {
"state": "DONE"
}
}
emulator logs
2022-09-08T09:08:50.000Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-09-08T09:09:04.985Z INFO server/middleware.go:41 POST /projects/test/jobs {"query": "alt=json"}
2022-09-08T09:09:04.993Z INFO contentdata/repository.go:144 {"query": "select * from `dataset1`.`table_a`", "values": []}
2022-09-08T09:09:04.994Z DEBUG contentdata/repository.go:210 query result {"rows": [[1,"alice"],[2,"bob"]]}
2022-09-08T09:09:05.007Z INFO server/middleware.go:41 GET /projects/test/queries/dummy-job-id {"query": "timeoutMs=0&startIndex=0&alt=json&maxResults=100"}
2022-09-08T09:09:10.764Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-09-08T09:09:25.770Z INFO server/middleware.go:41 GET /projects/test/jobs/dummy-job-id {"query": "alt=json"}
Table in BigQuery
$ bq show --project_id=my-project dataset1.table_a
{
"creationTime": "1662527315669",
"etag": "<etag>",
"id": "my-project:dataset1.table_a",
"kind": "bigquery#table",
"lastModifiedTime": "1662625126801",
"location": "<location>",
"numActiveLogicalBytes": "28",
"numActivePhysicalBytes": "3853",
"numBytes": "28",
"numLongTermBytes": "0",
"numLongTermLogicalBytes": "0",
"numLongTermPhysicalBytes": "0",
"numRows": "2",
"numTimeTravelPhysicalBytes": "1071",
"numTotalLogicalBytes": "28",
"numTotalPhysicalBytes": "3853",
"schema": {
"fields": [
{
"mode": "NULLABLE",
"name": "id",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
}
]
},
"selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/my-project/datasets/dataset1/tables/table_a",
"tableReference": {
"datasetId": "dataset1",
"projectId": "my-project",
"tableId": "table_a"
},
"type": "TABLE"
}
Table in emulator
$ bq --api=http://localhost:9050/ show --project_id=test dataset1.table_a
{}
emulator logs
2022-09-08T09:06:49.803Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-09-08T09:07:04.792Z INFO server/middleware.go:41 GET /projects/test/datasets/dataset1/tables/table_a {"query": "alt=json"}
Hi thanks for an awesome library!
It seems that the java lib expects that a created job populates destination table even for a query, since it uses it to actually list data: source. Right now the emulator returns anymous for dataset and table for query jobs: source.
exception:
Caused by: com.google.api.client.googleapis.json.GoogleJsonResponseException: 404 Not Found
GET http://localhost:60034/bigquery/v2/projects/test-project/datasets/anonymous/tables/anonymous/data?prettyPrint=false
{
"code" : 404,
"errors" : [ {
"location" : "",
"message" : "",
"reason" : "notFound",
"debugInfo" : ""
} ],
"message" : ""
}
at com.google.api.client.googleapis.json.GoogleJsonResponseException.from(GoogleJsonResponseException.java:146)
at com.google.api.client.googleapis.services.json.AbstractGoogleJsonClientRequest.newExceptionOnError(AbstractGoogleJsonClientRequest.java:118)
at com.google.api.client.googleapis.services.json.AbstractGoogleJsonClientRequest.newExceptionOnError(AbstractGoogleJsonClientRequest.java:37)
at com.google.api.client.googleapis.services.AbstractGoogleClientRequest$1.interceptResponse(AbstractGoogleClientRequest.java:439)
at com.google.api.client.http.HttpRequest.execute(HttpRequest.java:1111)
at com.google.api.client.googleapis.services.AbstractGoogleClientRequest.executeUnparsed(AbstractGoogleClientRequest.java:525)
at com.google.api.client.googleapis.services.AbstractGoogleClientRequest.executeUnparsed(AbstractGoogleClientRequest.java:466)
at com.google.api.client.googleapis.services.AbstractGoogleClientRequest.execute(AbstractGoogleClientRequest.java:576)
at com.google.cloud.bigquery.spi.v2.HttpBigQueryRpc.listTableData(HttpBigQueryRpc.java:525)
... 105 more
kotlin code to repro:
val datasetId = DatasetId.of("test-project", "ds")
bigQueryClient.create(DatasetInfo.of(datasetId))
val tableId = TableId.of("ds", "test-table")
bigQueryClient.create(
TableInfo.of(
tableId,
StandardTableDefinition.of(Schema.of(Field.of("test_field", LegacySQLTypeName.STRING)))
)
)
bigQueryClient.insertAll(InsertAllRequest.newBuilder(tableId).addRow("row1", mapOf("test_field" to "test_val")).build())
bigQueryClient
.create(JobInfo.of(QueryJobConfiguration.of("SELECT * FROM `test-project.ds.test-table`")))
.getQueryResults()
Hey there, Thank you for your work on BQ emulator, we are really missing it in our development :(
So i am having a little issue with STRUCT datatype. I am trying to create such table (using nodejs sdk, link below)
And this works fine for other data types, but for STRUCT it fails:(
script.mjs
import { BigQuery } from '@google-cloud/bigquery';
const schema = {
"fields": [
{
"name": "tenantId",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "transactions",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "transactionType",
"type": "STRING",
"mode": "NULLABLE"
}
}
]
}
const bq = new BigQuery({
projectId: 'project-id',
apiEndpoint: 'http://localhost:9050',
});
const dataset = bq.dataset('local_testing_dataset');
if (!(await dataset.exists())[0]) {
await bq.createDataset('local_testing_dataset');
}
const table = dataset.table('transactions_table');
if (!(await table.exists())[0]) {
await dataset.createTable('transactions_table', { schema });
}Note: script is written for node 16 & es modules, so no run it you have to have node16 and have to name file exactly
script.mjs
[bigquery-emulator] listening at 0.0.0.0:9050
{"L":"INFO","T":"2022-08-10T09:19:34.399Z","C":"server/middleware.go:41","M":"GET /bigquery/v2/projects/project-id/datasets/local_testing_dataset","query":"prettyPrint=false"}
{"L":"INFO","T":"2022-08-10T09:19:34.402Z","C":"server/middleware.go:155","M":"dataset is not found","datasetID":"local_testing_dataset"}
{"L":"INFO","T":"2022-08-10T09:19:34.408Z","C":"server/middleware.go:41","M":"POST /bigquery/v2/projects/project-id/datasets","query":"prettyPrint=false"}
{"L":"INFO","T":"2022-08-10T09:19:34.422Z","C":"server/middleware.go:41","M":"GET /bigquery/v2/projects/project-id/datasets/local_testing_dataset/tables/transactions_table","query":"prettyPrint=false"}
{"L":"INFO","T":"2022-08-10T09:19:34.425Z","C":"server/middleware.go:205","M":"table is not found","tableID":"transactions_table"}
{"L":"INFO","T":"2022-08-10T09:19:34.432Z","C":"server/middleware.go:41","M":"POST /bigquery/v2/projects/project-id/datasets/local_testing_dataset/tables","query":"prettyPrint=false"}
{"L":"ERROR","T":"2022-08-10T09:19:34.442Z","C":"server/handler.go:40","M":"internal error","error":"failed to create table CREATE TABLE `transactions_table` (`tenantId` STRING,`transactions` STRUCT): failed to analyze query: CREATE TABLE `transactions_table` (`tenantId` STRING,`transactions` STRUCT): INVALID_ARGUMENT: Syntax error: Expected \"<\" but got \")\" [at 1:75]"}version: "3.3"
services:
bigquery:
env_file: .env
image: ghcr.io/goccy/bigquery-emulator:latest
ports:
- '9050:9050'
command: ["/bin/bigquery-emulator", "--port=9050", "--project=project-id", "--log-level=debug", "--log-format=json"]
Hello Team,
Thanks for providing Big Query Emulator which will definitely help in local testing.
I am trying to set this up on my local machine using docker. I am stuck and getting error like "project flag is not set" & "unknown flag c."
Could you please provide a sample Docker Compose File & Docker File which I can use to resolve the issue. (Referred to other issue raised where it is said to create new image from provided one using dockerfile)
Note :- I am using docker image to start emulator & want to use python as base for using big query emulator
Thanks
I have been trying to use the project for integration testing purposes, but when I try to install it locally ( via go install github.com/goccy/bigquery-emulator/cmd/bigquery-emulator@latest ) or integrating into my code, the process gets stuck. I wonder if this is some kind of problem with CGO and Macs with ARM chips. I see a lot of clang processes being started ( and consuming ~4gb of ram ) but they never finish and I have to force kill them.
Have had any experience running this project with this environment ? Any tips on how to run it ?
I'm open to contributions, but not sure where to start.
This Project looks awesome!
Im hoping to use this to test the transformation queries in our ETL pipeline. A pretty common use case is to select specific columns from two source tables joined on an id / target_id foreign key.
I spun up this quick POC with some simple test data and ran into issues when attempting to join two tables within a CREATE OR REPLACE TABLE where the join condition contains a column that appears on both tables (in this case id).
from pprint import pprint
from typing import List
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery
from google.cloud.bigquery import QueryJobConfig
from google.cloud.exceptions import NotFound
class EmulatorPOC:
def __init__(self, project_id: str) -> None:
self.client = self._client(project_id)
self.project_id = project_id
def _client(self, project_id: str):
client_options = ClientOptions(api_endpoint="http://0.0.0.0:9050")
client = bigquery.Client(
project_id,
client_options=client_options,
credentials=AnonymousCredentials(),
)
return client
def _json_schema_to_bq_schema(self, schema: List[dict]) -> List:
return [
bigquery.SchemaField(item.get("name"), item.get("type"), mode="REQUIRED")
for item in schema
]
def create_table(
self, dataset_id: str, table_id: str, schema: List[dict]
) -> bigquery.Table:
table_name = f"{self.project_id}.{dataset_id}.{table_id}"
try:
table = self.client.get_table(table_name)
except NotFound:
bq_schema = self._json_schema_to_bq_schema(schema)
table = bigquery.Table(table_name, schema=bq_schema)
table = self.client.create_table(table)
return table
def create_dataset(self, dataset_id: str) -> bigquery.Dataset:
dataset_ref = f"{self.project_id}.{dataset_id}"
try:
dataset = self.client.get_dataset(dataset_ref)
except NotFound:
dataset = bigquery.Dataset(dataset_ref)
dataset.location = "US"
dataset = self.client.create_dataset(dataset)
return dataset
def poc(self, dataset_id: str, source_table_id: str, join_table_id: str):
# Create dataset
dataset = self.create_dataset(dataset_id=dataset_id)
# Create tables
source_table = self.create_table(
dataset_id=dataset_id,
table_id=source_table_id,
schema=[
{"name": "id", "type": "INTEGER"},
{"name": "key", "type": "STRING"},
{"name": "thing", "type": "STRING"},
],
)
join_table = self.create_table(
dataset_id=dataset_id,
table_id=join_table_id,
schema=[
{"name": "id", "type": "INTEGER"},
{"name": "key", "type": "STRING"},
{"name": "another_thing", "type": "STRING"},
{"name": f"{source_table_id}_id", "type": "INTEGER"},
],
)
# Insert data
self.client.insert_rows_json(
source_table,
[{"id": 1, "key": "key_123", "thing": "something"}],
)
self.client.insert_rows_json(
join_table,
[{"id": 1, "key": "key_123", "another_thing": "something_else", f"{source_table_id}_id": 1}],
)
# Select thing / another_thing and join on source.id = join.source_id
transform_statement = f"""
CREATE OR REPLACE TABLE {self.project_id}.{dataset_id}.test_transformation AS (
SELECT
t.thing,
j.another_thing,
FROM {self.project_id}.{dataset_id}.{source_table_id} t
JOIN {self.project_id}.{dataset_id}.{join_table_id} j ON t.id = j.{source_table_id}_id
);
"""
# Execute query to create table
transformed_table = self.client.query(
query=transform_statement, job_config=QueryJobConfig()
).result()
# Select results and return them
result = self.client.query(query=f"select * from {self.project_id}.{dataset_id}.test_transformation", job_config=QueryJobConfig())
return [dict(row) for row in result]
resp = EmulatorPOC("poc").poc("emulator_poc", "source_table", "join_table")
pprint(resp)
As I am only selecting specific cols from the source tables I don't believe this should be an issue. To confirm I ran this same script connecting to a sandbox BQ instance in gcp and it produced the expected resulting transformation table.
Also, if I rename the join table id column to id_ this executes without issue, so the underlying CREATE OR REPLACE TABLE appears to work just fine when a duplicated column is not specified in a join condition.
Thanks again for putting this project together! Let me know if this is something you are able to replicate and if you think it can / should be addressed.
Cheers
Thanks for the goccy/bigquery-emulator, it is a very useful feature.
Can I use BigQuery Positional Parameters?
https://cloud.google.com/bigquery/docs/samples/bigquery-query-params-positional
In my environment, an error has occurred. (Using docker image)
$ bq --api http://0.0.0.0:9050 query --use_legacy_sql=false --parameter=:integer:1 --project_id=test "select * from dataset1.table_a where id = ?"
You have encountered a bug in the BigQuery CLI. Please file a bug report in our public issue tracker:
https://issuetracker.google.com/issues/new?component=187149&template=0
Please include a brief description of the steps that led to this issue, as well as any rows that can be made public from the following information:
========================================
== Platform ==
CPython:2.7.16:Darwin-19.6.0-x86_64-i386-64bit
== bq version ==
2.0.75
...
========================================
Unexpected exception in query operation: You have encountered a bug in the BigQuery CLI. Please file a bug report in our public issue tracker:
https://issuetracker.google.com/issues/new?component=187149&template=0
Please include a brief description of the steps that led to this issue, as well as any rows that can be made public from the following information:
bigquery-emulator logged the following.
2022-08-26T03:24:31.949Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-08-26T03:24:31.977Z INFO server/middleware.go:41 POST /projects/test/jobs {"query": "alt=json"}
2022-08-26T03:24:31.982Z INFO contentdata/repository.go:145 {"query": "select * from dataset1.table_a where id = ?", "values": ["1"]}
2022-08-26T03:24:31.990Z INFO server/middleware.go:41 GET /projects/test/queries/bqjob_r4eb0707bb65b00af_00000182d82e0938_1 {"query": "timeoutMs=0&startIndex=0&alt=json&maxResults=100"}
2022-08-26T03:24:32.097Z ERROR server/handler.go:41 internal error {"error": "INVALID_ARGUMENT: Positional parameters are not supported [at 1:43]"}
In actual Google BigQuery, it works as follows.
$ bq query --use_legacy_sql=false --parameter=:integer:1 --project_id=my-project 'select * from dataset1.table_a where id = ?'
[
{
"id": "1",
"name": "alice"
}
]
Is there any option to make Positional Parameters available?
Code snippet in kotlin :
val bigQuery = BigQueryOptions.newBuilder()
.setHost("http://0.0.0.0:9050")
.setProjectId("test")
.setCredentials(NoCredentials.getInstance())
.build().service
val tableDefinition: TableDefinition = StandardTableDefinition.newBuilder()
.setSchema(Schema.of(
Field.of("id", LegacySQLTypeName.STRING)
)).build()
val tableInfo = TableInfo.of(TableId.of("internal", "test"), tableDefinition)
bigQuery.update(tableInfo) // first call it with .create() so it will create the table
so I have the issue:
Caused by: com.google.api.client.googleapis.json.GoogleJsonResponseException: 500 Internal Server Error
POST http://0.0.0.0:9050/bigquery/v2/projects/test/datasets/internal/tables/test?prettyPrint=false
{
"code" : 500,
"errors" : [ {
"location" : "",
"message" : "unexpected request path: /bigquery/v2/projects/test/datasets/internal/tables/test",
"reason" : "internalError",
"debugInfo" : ""
} ],
"message" : "unexpected request path: /bigquery/v2/projects/test/datasets/internal/tables/test"
}
When I try to delete a dataset with a table in it, it appears that the table is not being deleted properly. When I do this:
my_datasetmy_dataset.my_tablemy_dataset with deleteContents=Truemy_dataset againmy_dataset.my_table againI see this crash:
2022-08-24T17:58:17.432Z ERROR server/handler.go:41 internal error {"error": "failed to create table CREATE TABLE `my_table` (`a` INT64): failed to exec CREATE TABLE `my_table` (`a` INT64): table `recidiviz-bq-emulator-project_my_dataset_my_table` already exists"}
Here is a script that reproduces the issue:
from typing import List
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def dataset_exists(self, dataset_id: str) -> bool:
dataset_ref = self._dataset_ref(dataset_id)
try:
self.client.get_dataset(dataset_ref)
return True
except exceptions.NotFound:
return False
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def delete_table(self, dataset_id: str, table_id: str) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
self.client.delete_table(table_ref)
def delete_dataset(self, dataset_id: str) -> None:
dataset_ref = self._dataset_ref(dataset_id)
return self.client.delete_dataset(dataset_ref, delete_contents=True)
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
if __name__ == '__main__':
project_id_ = 'my-project'
dataset_id_ = 'my_dataset'
table_id_ = 'my_table'
schema_1 = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id_)
client.create_table(dataset_id_, table_id_, schema_1)
# Delete the whole dataset
client.delete_dataset(dataset_id_)
if client.dataset_exists(dataset_id_):
raise ValueError("Dataset still exists after it has been deleted")
# Creating the dataset succeeds
client.create_dataset(dataset_id_)
# !! This crashes: table `recidiviz-bq-emulator-project_my_dataset_my_table` already exists
client.create_table(dataset_id_, table_id_, schema_1)
Thank you!
Hi, I REALLY want to use your emulator (also, thank you for taking the initiative to put this together!) but I am having several issues with it.
bigquery_1 | unknown flag `c'
spdb_bigquery_1 exited with code 1
> ls -l data.yaml
-rw-r--r-- 1 cb871d 10050 316 Sep 10 17:46 data.yaml
> docker run -it ghcr.io/goccy/bigquery-emulator:latest --project=test --data-from-yaml=./data.yaml
open ./data.yaml: no such file or directory
I'd start the container with:
> docker run -it ghcr.io/goccy/bigquery-emulator:latest --project=test --port=9050 --log-level=debug --dataset=dataset1
[bigquery-emulator] listening at 0.0.0.0:9050
And any http request, e.g., http://0.0.0.0:9050/bigquery/v2/projects would get the following response:
"sql: connection is already closed"
Is there some prerequisites perhaps not listed?
Would it be possible to provide support for table-valued functions? In particular, I am trying to use the change history feature of bigquery.
To reproduce the issue:
Run the big query emulator like the example in the example docs.
./bigquery-emulator --project=test --data-from-yaml=./server/testdata/data.yaml
Then run the change history query against the emulator with
bq --api http://0.0.0.0:9050 query --project_id=test "SELECT * FROM APPENDS(TABLE dataset1.table_a, NULL, NULL)"
which results in this error:
BigQuery error in query operation: Error processing job
'test:bqjob_r428ff2cbc7cf45e0_00000184cf2e3298_1': failed to analyze:
INVALID_ARGUMENT: Table-valued functions are not supported [at 1:15]
Also, thanks so much for your work on the emulator! i really appreciate it.
Hi, I'm in a project that uses a metadata column of type repeated record:
bq show project:dataset.table
...
+- metadata: record (repeated)
| |- name: string (required)
| |- value: string
I've been able to create our table with bigquery-emulator but I'm not able to get the values properly from the metadata column.
./bigquery-emulator --project=test_project --log-level=debug
# ...
bq --api http://0.0.0.0:9050 mk --project_id=test_project --dataset test_dataset
bq --api http://0.0.0.0:9050 mk --project_id=test_project --table test_project:test_dataset.test_metadata ./metadata_schema.json
bq --api http://0.0.0.0:9050 show --project_id=test_project --schema test_project:test_dataset.test_metadata
# [{"fields":[{"mode":"REQUIRED","name":"name","type":"STRING"},{"mode":"NULLABLE","name":"value","type":"STRING"}],"mode":"REPEATED","name":"metadata","type":"RECORD"}]
bq --api http://0.0.0.0:9050 query --project_id=test_project 'INSERT INTO test_dataset.test_metadata (metadata) VALUES (ARRAY[ STRUCT("FOO","BAR") ])'
bq --api http://0.0.0.0:9050 query --project_id=test_project 'SELECT * FROM test_dataset.test_metadata'
# +--------------+
# | metadata |
# +--------------+
# | [{"":"BAR"}] |
# +--------------+
The schema file is as follows:
[
{
"fields": [
{
"mode": "REQUIRED",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "value",
"type": "STRING"
}
],
"mode": "REPEATED",
"name": "metadata",
"type": "RECORD"
}
]
and when I query our test table, I get:
+-----------+-----------------------------------------+
| service | metadata |
+-----------+-----------------------------------------+
| XxxxXxxx | [{"name":"NNNNNNN","value":"VVVVVVV1"}] |
| XxxxXxxx | [{"name":"NNNNNNN","value":"VVVVVVV2"}] |
+-----------+-----------------------------------------+
Am I doing the insert correctly and can I achieve the same result as google bigquery?
Hey @goccy
I have written one query regarding BIG QUERY Like the below for inserting data and fetching data
Whenever insert data it will work fine but when I tried to fetch data using group by or count or order by or using subquery it will not give me a proper record and it will give me error.
This is below code I tried.
type MockUsageEvent struct {
Key string `json:"key" binding:"required" conform:"trim"`
Product string `json:"product" conform:"trim"`
Version string `json:"version" conform:"trim"`
Platform string `json:"platform" conform:"trim"`
Event string `json:"event" binding:"required,oneofCI=activation" conform:"trim,lower"`
InstallId string `json:"installid" conform:"trim"`
Created string `json:"created"`
}
func (i *MockUsageEvent) Save() (map[string]bigquery.Value, string, error) {
return map[string]bigquery.Value{
"key": i.Key,
"product": i.Product,
"version": i.Version,
"platform": i.Platform,
"event": i.Event,
"installid": i.InstallId,
"created": i.Created,
}, bigquery.NoDedupeID, nil
}
ctx := context.Background()
meta := &bigquery.DatasetMetadata{
Location: "US", // See https://cloud.google.com/bigquery/docs/locations
}
if err := bigQueryClient.Dataset("dataset").Create(ctx, meta); err != nil {
return
}
sampleSchema := bigquery.Schema{
{Name: "key", Type: bigquery.StringFieldType},
{Name: "product", Type: bigquery.StringFieldType},
{Name: "version", Type: bigquery.StringFieldType},
{Name: "platform", Type: bigquery.StringFieldType},
{Name: "event", Type: bigquery.StringFieldType},
{Name: "installid", Type: bigquery.StringFieldType},
{Name: "created", Type: bigquery.StringFieldType},
}
metaData := &bigquery.TableMetadata{
Schema: sampleSchema,
ExpirationTime: time.Now().Add(time.Duration(1*60) * time.Second), // Table will be automatically deleted in 1 day.
}
tableRef := bigQueryClient.Dataset("dataset").Table("table")
if err := tableRef.Create(ctx, metaData); err != nil {
return
}
inserter := bigQueryClient.Dataset("dataset").Table("table").Inserter()
items := []*MockUsageEvent{
{Key: "1bjCljWkq6tinyAMuu0tEAhB80", Product: "Phrased Flintstones0", Version: "Phrased Flintstones0", Platform: "Phrased Flintstones0", Event: "license-request", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB81", Product: "Phrased Flintstones1", Version: "Phrased Flintstones1", Platform: "Phrased Flintstones1", Event: "camera", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB82", Product: "Phrased Flintstones2", Version: "Phrased Flintstones2", Platform: "Phrased Flintstones2", Event: "activation", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB83", Product: "Phrased Flintstones3", Version: "Phrased Flintstones3", Platform: "Phrased Flintstones3", Event: "textsearch", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB84", Product: "Phrased Flintstones4", Version: "Phrased Flintstones4", Platform: "Phrased Flintstones4", Event: "barcode", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB85", Product: "Phrased Flintstones5", Version: "Phrased Flintstones5", Platform: "Phrased Flintstones5", Event: "ocr", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB86", Product: "Phrased Flintstones6", Version: "Phrased Flintstones6", Platform: "Phrased Flintstones6", Event: "fooddetection", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB87", Product: "Phrased Flintstones7", Version: "Phrased Flintstones7", Platform: "Phrased Flintstones7", Event: "classifications", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB88", Product: "Phrased Flintstones8", Version: "Phrased Flintstones8", Platform: "Phrased Flintstones8", Event: "customdetection", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB89", Product: "Phrased Flintstones9", Version: "Phrased Flintstones9", Platform: "Phrased Flintstones9", Event: "detectinimage", InstallId: "1", Created: "2022-10-11T17:31:39"},
{Key: "1bjCljWkq6tinyAMuu0tEAhB89", Product: "Phrased Flintstones9", Version: "Phrased Flintstones10", Platform: "Phrased Flintstones10", Event: "packagedfood", InstallId: "1", Created: "2022-10-11T17:31:39"},
}
if err := inserter.Put(ctx, items); err != nil {
fmt.Println("err=>", err)
return
}
While I try to fetch the record using the below query it is not working
HERE THIS QUERY WILL NOT WORKING
SELECT yearMonth, count, key
FROM (
SELECT key, FORMAT_DATE('%Y-%m', PARSE_DATETIME('%Y-%m-%d %H:%M:%S', STRING(created))) AS yearMonth, count(distinct installid) as count
FROM test.dataset.table
WHERE created BETWEEN '2022-09-14' AND DATE_ADD(DATE '2022-10-14', INTERVAL 1 DAY)
AND installid IS NOT NULL AND length(installid) > 0
GROUP BY key, yearMonth
ORDER BY yearMonth
) AS counts
WHERE key IN ("1bjCljWkq6tinyAMuu0tEAhB80","1bjCljWkq6tinyAMuu0tEAhB82","1bjCljWkq6tinyAMuu0tEAhB86") ORDER BY key
It will give me the error panic: runtime error: invalid memory address or nil pointer dereference [recovered]
Whenever I run this SIMPLE query it will give me 11 records and its works fine but whenever I run the above query it would not work yet.
rows := bigQueryClient.Query(`
SELECT *
FROM ` + "`test.dataset.table`" + `
`)
it, err := rows.Read(ctx)
fmt.Println("TOTAL ROWS COUNT", it.TotalRows)
// OUTPUT : TOTAL ROWS COUNT 11
Please suggest me proper solution for the above query
Thank you @goccy
For testing we create new datasets for each test suite. Would it be possible to add this to the emulator?
Hello, first of all thank you for this amazing project!
I'm trying to build using the Dockerfile provided and I'm getting this error, not sure how to proceed to fix.
Here is the log:
> [stage-0 7/7] RUN make emulator/build:
#0 0.188 CGO_ENABLED=1 CXX=clang++ go build -o bigquery-emulator \
#0 0.188 -ldflags='-s -w -X main.version=latest -X main.revision=353f38c -linkmode external -extldflags "-static"' \
#0 0.188 ./cmd/bigquery-emulator
#0 805.4 # github.com/goccy/bigquery-emulator/cmd/bigquery-emulator
#0 805.4 /usr/local/go/pkg/tool/linux_arm64/link: running clang++ failed: exit status 1
#0 805.4 /usr/bin/ld: /usr/bin/ld: DWARF error: could not find variable specification at offset 62f34c
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 6ef417
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 6f16b9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e4b4f7
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e5329a
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e53315
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e53374
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e533d3
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e5341a
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e53461
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e66d11
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset e67919
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fa8c72
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd21fe
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd26c2
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd2a08
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd2d4e
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd3094
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd33da
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd3720
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd3a66
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd3df9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset fd418c
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1060adf
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10632b0
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1063a71
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1078783
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 108bc96
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 108befd
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 108c166
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10e8ab6
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10ee31e
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10eeff5
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f0771
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f29d8
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f348f
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f3f54
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f49e1
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f5a9e
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f67cd
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f746e
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10f8950
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10fcbf5
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10fd6ba
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 10fe171
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1100611
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11027ba
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1102c0d
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1102e5c
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11030af
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 110330a
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1103579
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11037e8
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11039e9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1103bec
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1103df3
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104004
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104216
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11044f9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11047de
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104b8c
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104c05
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104c63
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1104ca9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1158e10
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1159939
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 115a54b
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 115b277
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 115bf30
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1164bd2
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1164d92
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 116507a
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11768c5
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1177ca5
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1179160
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 117a0e9
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 117a96f
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 117b2d5
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 117c2cf
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 117cf32
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11883c8
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a020b
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a0ebd
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a196b
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a2263
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a3167
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11a4103
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11e1fa3
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11ee64b
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11f271a
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11f4a57
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11f5900
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11f67b4
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 11fefe3
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 1200093
#0 805.4 /usr/bin/ld: DWARF error: could not find variable specification at offset 123b56c
#0 805.4 /tmp/go-link-3564573297/000024.o: in function `export_zetasql_uprv_dl_open':
#0 805.4 /go/pkg/mod/github.com/goccy/[email protected]/internal/ccall/icu/common/putil.cpp:2294: warning: Using 'dlopen' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000054.o: in function `mygetgrouplist':
#0 805.4 /_/os/user/getgrouplist_unix.go:15: warning: Using 'getgrouplist' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000053.o: in function `mygetgrgid_r':
#0 805.4 /_/os/user/cgo_lookup_unix.go:37: warning: Using 'getgrgid_r' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000053.o: in function `mygetgrnam_r':
#0 805.4 /_/os/user/cgo_lookup_unix.go:42: warning: Using 'getgrnam_r' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000053.o: in function `mygetpwnam_r':
#0 805.4 /_/os/user/cgo_lookup_unix.go:32: warning: Using 'getpwnam_r' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000053.o: in function `mygetpwuid_r':
#0 805.4 /_/os/user/cgo_lookup_unix.go:27: warning: Using 'getpwuid_r' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/ld: /tmp/go-link-3564573297/000004.o: in function `_cgo_6cc2654a8ed3_C2func_getaddrinfo':
#0 805.4 /tmp/go-build/cgo-gcc-prolog:58: warning: Using 'getaddrinfo' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
#0 805.4 /usr/bin/../lib/gcc/aarch64-linux-gnu/10/../../../aarch64-linux-gnu/libc.a(init-first.o): in function `__libc_init_first':
#0 805.4 (.text+0x14): relocation truncated to fit: R_AARCH64_LD64_GOTPAGE_LO15 against undefined symbol `_dl_starting_up'
#0 805.4 /usr/bin/ld: (.text+0x14): warning: too many GOT entries for -fpic, please recompile with -fPIC
#0 805.4 clang: error: linker command failed with exit code 1 (use -v to see invocation)
#0 805.4
#0 805.8 make: *** [Makefile:9: emulator/build] Error 2
I'm having performance issues using the default image, as Docker for Mac emulates the amd64 environment, that's why I'm trying this operation.
Thanks!
I would love to be able to run a query like this against the emulator:
SELECT TO_JSON([1, 2, 3]) as a;
Which would return a result like this:
| a |
|---|
| "[1,2,3]" |
Right now, that query throws an error:
ERROR server/handler.go:41 internal error {"error": "INVALID_ARGUMENT: Function not found: TO_JSON [at 1:8]"}
Thank you!
I tried to figure out how to use the Emulator with Apache Beam's BigQuery IOConnector. But the connector seems to have hardwired flow that it downloads data first to GCP and then loads it from there. I couldn't see any way to insert the Emulator into it.
Has anyone tried this and figured out how to make it work?
Will also post this question on the Apache Beam mailing list.
First of all thanks for your amazing work on this project.
It would be nice to know which features are implemented and which are not yet / impossible to implement (maybe a table in readme?).
I think this will be very helpful for everyone who is considering to use the emulator.
Example POST to /bigquery/v2/projects/{project-id}/jobs
{
"configuration": {
"query": {
"defaultDataset": {
"datasetId": "<my dataset ID>"
},
"query": "begin transaction;",
"useLegacySql": false,
"useQueryCache": true,
"scriptOptions.keyResultStatement": "FIRST_SELECT"
}
},
"jobReference": {
"jobId": "SimbaJDBC_Job_12312312312313"
}
}This is a query originating from a spring JPA Repository using the Simba Bigquery Driver. The emulator never responds to this request and from that point forward can't respond to other requests, and I have to kill it and restart.
When inserting data using the dart bigquery API the client crashes.
Unhandled exception:
ApiRequestError(message: Unable to read response with content-type text/plain; charset=utf-8.)
#0 ApiRequester.request (package:_discoveryapis_commons/src/clients.dart:86:9)
<asynchronous suspension>
#1 DatasetsResourceApi.insert (package:googleapis/bigquery/v2.dart:234:32)The problem seems to be that although the response is JSON the Content-Type header is text/plain. You can see the dart code checking for this here:
Stream<String>? _decodeStreamAsText(http.StreamedResponse response) {
// TODO: Correctly handle the response content-types, using correct
// decoder.
// Currently we assume that the api endpoint is responding with json
// encoded in UTF8.
if (isJson(response.headers['content-type'])) {
return response.stream.transform(const Utf8Decoder(allowMalformed: true));
} else {
return null;
}
}Would suggest fixing by setting Content-Type: application/json; charset=utf-8 on all JSON responses.
For example, bq --api="http://localhost:9050" --project_id="test" mk --dataset test (with ./bigquery-emulator --project test) failed with following error:
BigQuery error in mk operation: Could not connect with BigQuery server.
Http response status: 404
Http response content:
b'dataset test is not found'
bq checks if dataset/table/etc already exists before creating it. Of course bigquery-emulator already returns 404, but bq can't handle plain text error.
bigquery-emulator/server/middleware.go
Line 182 in d7a7d9a
I fixed errors by following https://cloud.google.com/bigquery/docs/error-messages with minimal example:
--- a/server/middleware.go
+++ b/server/middleware.go
diff --git a/server/middleware.go b/server/middleware.go
index 7a51ae9..25a8d8a 100644
--- a/server/middleware.go
+++ b/server/middleware.go
@@ -153,8 +153,18 @@ func withDatasetMiddleware() func(http.Handler) http.Handler {
dataset := project.Dataset(datasetID)
if dataset == nil {
logger.Logger(ctx).Info("dataset is not found", zap.String("datasetID", datasetID))
+ w.Header().Add("Content-Type", "application/json")
w.WriteHeader(http.StatusNotFound)
- fmt.Fprintf(w, "dataset %s is not found", datasetID)
+ encodeResponse(ctx, w, map[string]interface{}{
+ "error": map[string]interface{}{
+ "errors": []interface{}{
+ map[string]interface{}{
+ "message": fmt.Sprintf("dataset %s is not found", datasetID),
+ "reason": "notFound",
+ },
+ },
+ },
+ })
return
}
ctx = withDataset(ctx, dataset)I am running into issues when I try to use certain aggregate functions as window functions. For example, for this query:
SELECT MIN(a) OVER (PARTITION BY b)
FROM UNNEST([STRUCT(1 AS a, 2 AS b)]);
I get this error:
internal error {"error": "failed to format query SELECT MIN(a) OVER (PARTITION BY b) AS min_a FROM UNNEST([STRUCT(1 AS a, 2 as b)]);: min function is unimplemented"}
I am seeing a similar crash for MAX and COUNT functions as well, but not AVG and SUM.
Thanks!
Tables are created successfully but query gives Error for the following script
MERGE transaction_raw_dev.tradeTable USING UNNEST([struct<orderChainUuid STRING, userId INTEGER, ...
Hello, first of all, I would like to congrats for this amazing project.
I'm trying to do a simple UPDATE using the python example provided in this repo:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
def main():
client = bigquery.Client(
"test",
client_options=ClientOptions(api_endpoint="http://bigquery:9050"),
credentials=AnonymousCredentials(),
)
job = client.query(
# query="SELECT * FROM dataset1.table_a;",
query="UPDATE dataset1.table_a SET name = 'foo' WHERE id = 1;",
job_config=bigquery.QueryJobConfig(),
)
print(list(job.result()))
main()The program freezes for some reason. Can someone help me? Is this normal?
Thanks
Thanks for this great project!
For users who run the emulator as a docker container or even inside a kubernetes cluster, it makes things more convenient to provide arguments through env vars.
--project can be replaced as is with a simple string env var $PROJECT_NAME for example.--data-from-yml would perhaps be better replaced with a env var named $SCHEMA where the actual contents of the schema yaml can be placed. It saves the need to mount a volume with the yml file that holds the schema which makes things a bit more complex.https://cloud.google.com/bigquery/docs/reference/standard-sql/data-manipulation-language
BigQuery supports DML statements.
It can be run with the bq command line tool.
$ bq query --use_legacy_sql=false --project_id=my-project 'insert into `dataset1`.`table_a` (`id`, `name`) values (3, "cook")'
Waiting on bqjob_r1064c0f0fe670c54_00000183165a9c07_1 ... (0s) Current status: DONE
Number of affected rows: 1
But when I run INSERT DML on emulator, it does not return any results.
$ bq --api=http://localhost:9050/ query --use_legacy_sql=false --project_id=test 'insert into `dataset1`.`table_a` (`id`, `name`) values (3, "cook")'
^C
The emulator outputs the following logs.
2022-09-07T05:13:48.496Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-09-07T05:14:03.481Z INFO server/middleware.go:41 POST /projects/test/jobs {"query": "alt=json"}
2022-09-07T05:14:03.489Z INFO contentdata/repository.go:144 {"query": "insert into `dataset1`.`table_a` (`id`, `name`) values (3, \"cook\")", "values": []}
schema
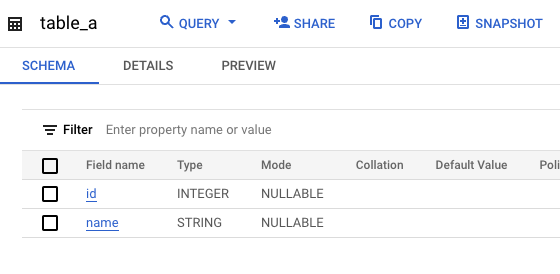
data
$ bq --api=http://localhost:9050/ query --project_id=test 'select * from `dataset1`.`table_a`'
[
{
"id": "1",
"name": "alice"
},
{
"id": "2",
"name": "bob"
}
]
When I run this query in the BigQuery UI, I get a runtime execution error: 'Array cannot have a null element; error in writing field a_list''
SELECT b, ARRAY_AGG(a) AS a_list
FROM UNNEST([
STRUCT(1 AS a, 2 AS b),
STRUCT(NULL AS a, 2 AS b)
])
GROUP BY b;
However, I do an ARRAY_AGG the same data in the emulator, the row with NULL values in the ARRAY_AGG result is just silently dropped with no runtime error.
Here is the script that reproduces:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def get_table(self, dataset_id: str, table_id: str) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
return self.client.get_table(table_ref)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
def load_data(
self,
dataset_id: str,
table_id: str,
rows: List[Dict[str, Any]],
) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
table = self.client.get_table(table_ref)
errors = self.client.insert_rows(table, rows)
if errors:
raise RuntimeError(
f"Failed to insert rows into {dataset_ref.dataset_id}.{table_id}:\n"
+ "\n".join(str(error) for error in errors)
)
if __name__ == '__main__':
project_id_ = 'recidiviz-bq-emulator-project'
dataset_id = 'my_dataset'
table_id = 'my_table'
schema = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
bigquery.SchemaField(
"b",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="REQUIRED",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id)
client.create_table(dataset_id, table_id, schema)
client.load_data(dataset_id, table_id, [{"a": 1, "b": 1}, {"a": None, "b": 1}, {"a": 2, "b": 2}])
# This query does not crash and returns an empty list, but should throw a runtime error.
result = client.run_query(f"""
SELECT b, ARRAY_AGG(a) AS a_list
FROM `{project_id_}.{dataset_id}.{table_id}`
GROUP BY b;
""")
(Note: I couldn't actually test with the UNNEST statement above because of #30)
Thank you!
The emulator fails to write query result with a timestamp column value to the destination table with the error like the following.
googleapi: Error 400: failed to add table data: failed to convert value from {Name: Ordinal:1 Value:1668610120.347600}: failed to convert 1668610120.347600 to time.Time type, jobInternalError
Here's the code to reproduce the error. It uses CURRENT_TIMESTAMP() but I confirmed that the same error occurs when the query refers to a timestamp column of a table.
func TestQueryWithDestination(t *testing.T) {
const (
projectName = "test"
datasetName = "dataset1"
tableName = "table_a"
)
ctx := context.Background()
bqServer, err := server.New(server.TempStorage)
if err != nil {
t.Fatal(err)
}
project := types.NewProject(projectName, types.NewDataset(datasetName))
if err := bqServer.Load(server.StructSource(project)); err != nil {
t.Fatal(err)
}
testServer := bqServer.TestServer()
defer func() {
testServer.Close()
bqServer.Close()
}()
client, err := bigquery.NewClient(
ctx,
projectName,
option.WithEndpoint(testServer.URL),
option.WithoutAuthentication(),
)
if err != nil {
t.Fatal(err)
}
defer client.Close()
table := client.Dataset(datasetName).Table(tableName)
if err := table.Create(ctx, &bigquery.TableMetadata{
Schema: []*bigquery.FieldSchema{
{Name: "ts", Type: bigquery.TimestampFieldType},
},
}); err != nil {
t.Fatalf("%+v", err)
}
query := client.Query("SELECT CURRENT_TIMESTAMP() AS ts")
query.QueryConfig.Dst = &bigquery.Table{
ProjectID: projectName,
DatasetID: datasetName,
TableID: table.TableID,
}
job, err := query.Run(ctx)
if err != nil {
t.Fatal(err) // Fails here.
}
status, err := job.Wait(ctx)
if err != nil {
t.Fatalf("%+v", err)
}
if err := status.Err(); err != nil {
t.Fatalf("%+v", err)
}
}
Hi there! Thank you so much for your work on this project. It has the potential to be incredibly useful for my work.
I was trying to integrate the emulator into some Python unit tests and I think I have found a bug related to table creation. In particular, if I create a table, delete the table, then create a table at the same location, I see a crash like this:
google.api_core.exceptions.BadRequest: 400 POST http://0.0.0.0:9050/bigquery/v2/projects/test_project/datasets/my_dataset/tables?prettyPrint=false: failed to create table CREATE TABLE `my_table` (`a` INT64): failed to exec CREATE TABLE `my_table` (`a` INT64): table `test_project_my_dataset_my_table` already exists.
Here is the script I'm using to reproduce the issue:
from typing import List, Iterator
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def table_exists(self, dataset_id: str, table_id: str) -> bool:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
try:
self.client.get_table(table_ref)
return True
except exceptions.NotFound:
return False
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def delete_table(self, dataset_id: str, table_id: str) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
self.client.delete_table(table_ref)
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
if __name__ == '__main__':
project_id_ = 'test_project'
dataset_id_ = 'my_dataset'
table_id_ = 'my_table'
schema_ = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
client.create_dataset(dataset_id_)
# Verify table does not yet exist
if client.table_exists(dataset_id_, table_id_):
raise ValueError(
f"Table already exists: {dataset_id_}.{table_id_}."
)
# Create the table
client.create_table(dataset_id_, table_id_, schema_)
# Verify the table now does exist
if not client.table_exists(dataset_id_, table_id_):
raise ValueError(
f"Table does not exist: {dataset_id_}.{table_id_}."
)
# Verify that we can query the table successfully
client.run_query(f"SELECT * FROM `{project_id_}.{dataset_id_}.{table_id_}`")
# Delete the table
client.delete_table(dataset_id_, table_id_)
# Verify table does not yet exist (according to the API)
if client.table_exists(dataset_id_, table_id_):
raise ValueError(
f"Table already exists: {dataset_id_}.{table_id_}."
)
# Create the table a second time - !!! This crashes, saying table exists !!!
client.create_table(dataset_id_, table_id_, schema_)
Thanks!
When I download the bigquery emulator using go install ..., I am able to hit the API after starting up the server with the CLI bigquery-emulator. However, when I run
docker run -it ghcr.io/goccy/bigquery-emulator:latest --project=test
I only receive timeout errors when trying to hit the API. For example, when trying to create a dataset in python
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery
client_options = ClientOptions(api_endpoint="http://0.0.0.0:9050")
client = bigquery.Client(
"test",
client_options=client_options,
credentials=AnonymousCredentials(),
)
client.create_dataset(bigquery.Dataset("test.dataset1"), timeout=30)
will just timeout, but on the bigquery-emulator CLI, I am succesfully able to create a dataset.
However, this may also be because I am running this on an M1 Macbook, since when I run docker run, i get
>>> docker run -it ghcr.io/goccy/bigquery-emulator:latest --project=test
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
[bigquery-emulator] REST server listening at 0.0.0.0:9050
[bigquery-emulator] gRPC server listening at 0.0.0.0:9060
So I instead did
docker run --platform linux/amd64 -it ghcr.io/goccy/bigquery-emulator:latest --project=test
[bigquery-emulator] REST server listening at 0.0.0.0:9050
[bigquery-emulator] gRPC server listening at 0.0.0.0:9060
to make the warning go away, but the issue still persisted. But maybe this is because there is no support for the bigquery emulator for the M1 arm images?
Thanks!
Hey,
Thanks for creating the bigquery emulator.
Can i use the BigQuery Storage Write API?
I tried to create a write stream in Python for the emulator, and when creating it the execution get stuck.
The emulator was deployed on a docker container
Thanks
Hi! Thank you for creating bigquery-emulator. This gives hope for regular testing experience which we all need :)
I have tried to use it with google-cloud-bigquery java library from Google and encountered some problems. I hope that it will be possible to include fixes in bigquery-emulator.
I have made a simple example which shows problems in here: SampleTest.kt
When library sends requests with Content-Encoding: gzip header emulator is not handling this properly which gives an error:
invalid character '\x1f' looking for beginning of value
com.google.cloud.bigquery.BigQueryException: invalid character '\x1f' looking for beginning of value
at app//com.google.cloud.bigquery.spi.v2.HttpBigQueryRpc.translate(HttpBigQueryRpc.java:115)
at app//com.google.cloud.bigquery.spi.v2.HttpBigQueryRpc.create(HttpBigQueryRpc.java:170)
at app//com.google.cloud.bigquery.BigQueryImpl$1.call(BigQueryImpl.java:269)
at app//com.google.cloud.bigquery.BigQueryImpl$1.call(BigQueryImpl.java:266)
at app//com.google.api.gax.retrying.DirectRetryingExecutor.submit(DirectRetryingExecutor.java:105)
at app//com.google.cloud.RetryHelper.run(RetryHelper.java:76)
at app//com.google.cloud.RetryHelper.runWithRetries(RetryHelper.java:50)
at app//com.google.cloud.bigquery.BigQueryImpl.create(BigQueryImpl.java:265)
at app//info.szadkowski.bqissue.SampleTest.create dataset and table(SampleTest.kt:41)
And in logs of bigquery-emulator can be seen:
2022-10-31T13:33:43.563+0100 ERROR server/handler.go:608 invalid {"error": "invalid: invalid character '\\x1f' looking for beginning of value"}
\\x1f is a first byte when request is gzipped.
Compression of requests cannot be turned off in google-cloud-bigquery, but on debug this behaviour can be altered by putting break point in com.google.api.client.http.HttpRequest:889 and evaluating encoding=null. This allowed me to encounter next issue.
When request is sent without compression there is another issue which appears. google-cloud-bigquery expects "type" key in response which informs what kind of "table" is it. This key is not sent by library by itself.
Empty enum constants not allowed.
java.lang.IllegalArgumentException: Empty enum constants not allowed.
at com.google.cloud.StringEnumType.valueOf(StringEnumType.java:66)
at com.google.cloud.bigquery.TableDefinition$Type.valueOf(TableDefinition.java:102)
at com.google.cloud.bigquery.TableDefinition.fromPb(TableDefinition.java:159)
at com.google.cloud.bigquery.TableInfo$BuilderImpl.<init>(TableInfo.java:195)
at com.google.cloud.bigquery.Table.fromPb(Table.java:630)
at com.google.cloud.bigquery.BigQueryImpl.create(BigQueryImpl.java:291)
at info.szadkowski.bqissue.SampleTest.create dataset and table(SampleTest.kt:48)
...
I would really appreciate any assistance.
When I run a query like this:
SELECT b, ARRAY_AGG(a IGNORE NULLS) AS a_list
FROM `project.my_dataset.my_table`
GROUP BY b;
It works if any null values in column a are NOT the first row. However, if the first inserted row has a null value for a, I am seeing this crash:
Traceback (most recent call last):
File ".../test.py", line 107, in <module>
print(list(result))
File ".../lib/python3.9/site-packages/google/api_core/page_iterator.py", line 209, in _items_iter
for item in page:
File ".../lib/python3.9/site-packages/google/api_core/page_iterator.py", line 131, in __next__
result = self._item_to_value(self._parent, item)
File ".../lib/python3.9/site-packages/google/cloud/bigquery/table.py", line 2684, in _item_to_row
_helpers._row_tuple_from_json(resource, iterator.schema),
File ".../lib/python3.9/site-packages/google/cloud/bigquery/_helpers.py", line 429, in _row_tuple_from_json
row_data.append(_field_from_json(cell["v"], field))
File ".../lib/python3.9/site-packages/google/cloud/bigquery/_helpers.py", line 403, in _field_from_json
return [converter(item["v"], field) for item in resource]
TypeError: 'NoneType' object is not iterable
Here is the script I am using to reproduce:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def get_table(self, dataset_id: str, table_id: str) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
return self.client.get_table(table_ref)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
def load_data(
self,
dataset_id: str,
table_id: str,
rows: List[Dict[str, Any]],
) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
table = self.client.get_table(table_ref)
errors = self.client.insert_rows(table, rows)
if errors:
raise RuntimeError(
f"Failed to insert rows into {dataset_ref.dataset_id}.{table_id}:\n"
+ "\n".join(str(error) for error in errors)
)
if __name__ == '__main__':
project_id_ = 'recidiviz-bq-emulator-project'
dataset_id = 'my_dataset'
table_id = 'my_table'
schema = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
bigquery.SchemaField(
"b",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="REQUIRED",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id)
client.create_table(dataset_id, table_id, schema)
client.load_data(dataset_id, table_id, [{"a": None, "b": 2}, {"a": 1, "b": 2}])
result = client.run_query(f"""
SELECT b, ARRAY_AGG(a IGNORE NULLS) AS a_list
FROM `{project_id_}.{dataset_id}.{table_id}`
GROUP BY b;
""")
print(list(result))
If you change the load_data line to client.load_data(dataset_id, table_id, [{"a": 1, "b": 2}, {"a": None, "b": 2}]), the query works perfectly.
Thank you!
Is there a recommended health check for use with docker?
# docker-compose.yaml
version: '3'
services:
bigquery:
container_name: bigquery-local
image: ghcr.io/goccy/bigquery-emulator:latest
healthcheck:
test: # HERE
interval: 5s
timeout: 5s
retries: 5thanks!
Hi @goccy,
We use the BigQuery JDBC driver (see documentation) in our project and would like to add integration tests using bigquery-emulator.
It's possible to specify a custom endpoint for the driver using the undocumented RootURL argument, e.g.:
jdbc:bigquery://http://localhost/:9050;RootURL=http://localhost:9050;ProjectId=test;OAuthType=2;OAuthAccessToken=<token>
During our tests we found the following issues caused by the JDBC driver's behavior. We would like to contribute to your project and fix these issues if that's ok for you.
The driver always uses path prefix /bigquery/v2, e.g. POST /bigquery/v2/projects/test/queries. This is not configurable.
We propose to add a command line switch that allows overriding the default prefix "", e.g.:
--path-prefix="/bigquery/v2"
The driver sends payload with Content-Encoding: gzip. This is not configurable.
We propose to add a middleware function to server.go that unzips the request payload if necessary.
This would require adding an additional dependency, e.g. github.com/klauspost/compress/gzip.
When sending a SQL query, the JDBC driver sends request POST /bigquery/v2/projects/test/queries with the following payload:
{"dryRun":false,"maxResults":10000,"query":"select 2*5","timeoutMs":10000,"useLegacySql":false,"useQueryCache":true}The emulator replies with this response:
{"jobComplete":true,"jobReference":{"projectId":"test"},"rows":[{"f":[{"v":"10"}]}],"schema":{"fields":[{"name":"$col1","type":"INTEGER"}]},"totalRows":"1"}This causes the following exception in the JDBC driver which is caused by the missing jobId in jobReference.
java.sql.SQLException: [Simba][BigQueryJDBCDriver](100030) Error trying to obtain Google Bigquery object.
at com.simba.googlebigquery.googlebigquery.dataengine.BQResultSet.<init>(Unknown Source)
at com.simba.googlebigquery.googlebigquery.dataengine.BQSQLExecutor.execute(Unknown Source)
at com.simba.googlebigquery.jdbc.common.SStatement.executeNoParams(Unknown Source)
at com.simba.googlebigquery.jdbc.common.BaseStatement.executeQuery(Unknown Source)
at com.exasol.adapter.dialects.bigquery.BigQueryJdbcTest.test(BigQueryJdbcTest.java:23)
The emulator uses r.queryRequest.RequestId as jobId (see handler.go) which is nil in this case.
We propose to generate a random ID in case r.queryRequest.RequestId is nil.
If these changes are OK for you, we would like create separate pull requests for each of these issues, or discuss how to solve them in a different way.
Thank you very much for your support!
I'm seeing incorrect query behavior on nested usages of TO_JSON. For example for this query:
SELECT TO_JSON(
STRUCT(
"foo" AS a,
TO_JSON(STRUCT("bar" AS c)) AS b
)
) AS result;
Expected result:
| result |
|---|
| {"a":"foo","b":{"c":"bar"}} |
Actual result:
| result |
|---|
| {"\"foo\"":"foo","zetasqlite_to_json_json(\"zetasqlitestruct:eyJjIjoiYmFyIn0=\",false)":{"c":"bar"}} |
This query should also produce the exact same result, but produces a slightly different, still incorrect result:
WITH inner_json AS (
SELECT TO_JSON(STRUCT("bar" AS c)) AS b
)
SELECT TO_JSON(STRUCT("foo" as a, b)) AS result
FROM inner_json;
Actual result:
| result |
|---|
| {"\"foo\"":"foo","b":{"c":"bar"}} |
(Looks like you're using the value as the column name instead of the proper column name?)
Thank you!
I am seeing this crash running SQL queries when I use the emulator with a project_id value that has a hyphen in it :
google.api_core.exceptions.BadRequest: 400 GET http://0.0.0.0:9050/bigquery/v2/projects/test-project/queries/483be6fb-cb54-40b7-83fc-73e86deb2f46?maxResults=0&location=US&prettyPrint=false: failed to query SELECT `a#1` FROM (SELECT `a` AS `a#1` FROM test-project_my_dataset_my_table): near "-": syntax error
The following script crashes when I use project_id = 'test-project' but does not crash if I use project_id = 'test_project':
from typing import List, Iterator
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def table_exists(self, dataset_id: str, table_id: str) -> bool:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
try:
self.client.get_table(table_ref)
return True
except exceptions.NotFound:
return False
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
if __name__ == '__main__':
project_id_ = 'test-project'
dataset_id_ = 'my_dataset'
table_id_ = 'my_table'
schema_ = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
client.create_dataset(dataset_id_)
client.create_table(dataset_id_, table_id_, schema_)
# Verify the table now does exist
if not client.table_exists(dataset_id_, table_id_):
raise ValueError(
f"Table already exists: {dataset_id_}.{table_id_}."
)
# !! This crashes !!
client.run_query(f"SELECT * FROM `{project_id_}.{dataset_id_}.{table_id_}`")
The Google Cloud docs do mention that project ids can contain hyphens: https://cloud.google.com/resource-manager/docs/creating-managing-projects.
Thank you!
Hi again, now I have a numeric field with a value of 1234.567 and I want to get a sum of the values as string with CAST(SUM(quantity) as STRING) as quantity to show elsewhere. From bq + Google (BigQuery) I get the usual 1234.567 decimal-looking sum but from the emulator, I get 1234567/1000 (which is technically correct but it looks like some evaluation is missing).
New beta feature allows for column default values. Would love to see support.
I am seeing a handful of issues on version v0.1.6 when I do the following:
my_dataset.my_table with column amy_dataset.my_table with column bBoth insert and query operations seem to think that the table has the original schema, even though the GET table operation returns the correct info.
Here is a script that reproduces the issues:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def get_table(self, dataset_id: str, table_id: str) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
return self.client.get_table(table_ref)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
def load_data(
self,
dataset_id: str,
table_id: str,
rows: List[Dict[str, Any]],
) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
table = self.client.get_table(table_ref)
errors = self.client.insert_rows(table, rows)
if errors:
raise RuntimeError(
f"Failed to insert rows into {dataset_ref.dataset_id}.{table_id}:\n"
+ "\n".join(str(error) for error in errors)
)
def delete_table(self, dataset_id: str, table_id: str) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
self.client.delete_table(table_ref)
if __name__ == '__main__':
project_id_ = 'my-project'
dataset_id_ = 'my_dataset'
table_id_ = 'my_table'
schema_1 = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id_)
client.create_table(dataset_id_, table_id_, schema_1)
# Delete that table
client.delete_table(dataset_id_, table_id_)
schema_2 = [
bigquery.SchemaField(
"b",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
# Create the same table again, this time with a different schema
client.create_table(dataset_id_, table_id_, schema_2)
table = client.get_table(dataset_id_, table_id_)
# The get_table() call returns the correct, new schema :-)
if table.schema != schema_2:
raise ValueError(f"Found incorrect table schema: {table.schema}")
# !! This crashes: INVALID_ARGUMENT: Column b is not present in table !!
client.load_data(dataset_id_, table_id_, [{"b": 1}])
# !! This crashes: INVALID_ARGUMENT: Unrecognized name: b !!
client.run_query(f"SELECT b FROM `{project_id_}.{dataset_id_}.{table_id_}`")
Thank you!
Using the following schema and data.
| id (INTEGER) | name (STRING) | created_at (TIMESTAMP) |
|---|---|---|
| 1 | alice | 2020-01-01T00:00:00+09:00 |
| 2 | bob | 2020-06-15T09:00:00+09:00 |
The following image shows data on Big Query.

The emulator is populated with data using the following yaml.
projects:
- id: test
datasets:
- id: dataset1
tables:
- id: table_a
columns:
- name: id
type: INTEGER
- name: name
type: STRING
- name: created_at
type: TIMESTAMP
data:
- id: 1
name: alice
created_at: 2020-01-01T00:00:00+09:00
- id: 2
name: bob
created_at: 2020-06-15T09:00:00+09:00I can get the following response from Big Query. (Using bq command line tool)
$ bq query --use_legacy_sql=false --project_id=my-project 'select * from dataset1.table_a'
[
{
"created_at": "2019-12-31 15:00:00",
"id": "1",
"name": "alice"
},
{
"created_at": "2020-06-15 00:00:00",
"id": "2",
"name": "bob"
}
]
But I can get the following response from the emulator.
$ bq --api http://0.0.0.0:9050 query --use_legacy_sql=false --project_id=test 'select * from dataset1.table_a'
[
{
"created_at": "<date out of range for display>",
"id": "1",
"name": "alice"
},
{
"created_at": "<date out of range for display>",
"id": "2",
"name": "bob"
}
]
The emulator outputs the following logs.
2022-08-30T03:48:52.030Z INFO server/middleware.go:41 GET /discovery/v1/apis/bigquery/v2/rest {"query": ""}
2022-08-30T03:48:52.061Z INFO server/middleware.go:41 POST /projects/test/jobs {"query": "alt=json"}
2022-08-30T03:48:52.065Z INFO contentdata/repository.go:144 {"query": "select * from dataset1.table_a", "values": []}
2022-08-30T03:48:52.066Z DEBUG contentdata/repository.go:207 query result {"rows": [[1,"alice","2019-12-31T15:00:00Z"],[2,"bob","2020-06-15T00:00:00Z"]]}
2022-08-30T03:48:52.076Z INFO server/middleware.go:41 GET /projects/test/queries/bqjob_r95c129985562ba2_00000182ecddc0bb_1 {"query": "timeoutMs=0&startIndex=0&alt=json&maxResults=100"}
Also, (I'm using a PHP client.) I can get microtime format response like 1577836800.0 from Big Query whereas I can get datetime format response like 2020-01-01 00:00:00 +0000 UTC from the emulator.
Because of this difference, I am having trouble parsing to Timestamp type objects on the client.
when i include the package for the big query emulator, i am getting the following error
bind.cc:97:10: fatal error: 'absl/time/internal/cctz/include/cctz/time_zone.h' file not found
Any resolution for this would be greatly helpful. Thanks
Hi @goccy, one more case: we have a parameterized select query in golang. We utilise a named parameter in 2 places in the query (with @param syntax) and I get an error with the emulator. The workaround is to add the parameter a second time to the parameter list which seems redundant. Can this be fixed?
I'm seeing a crash when I try to use MIN/MAX as a window function with a date value as an argument, i.e. a query of this form:
SELECT MAX(some_date_column) OVER (PARTITION BY another_column) FROM `project.dataset.table`;
Here is a script that reproduces the issue:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def get_table(self, dataset_id: str, table_id: str) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
return self.client.get_table(table_ref)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
def load_data(
self,
dataset_id: str,
table_id: str,
rows: List[Dict[str, Any]],
) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
table = self.client.get_table(table_ref)
errors = self.client.insert_rows(table, rows)
if errors:
raise RuntimeError(
f"Failed to insert rows into {dataset_ref.dataset_id}.{table_id}:\n"
+ "\n".join(str(error) for error in errors)
)
if __name__ == '__main__':
project_id_ = 'test-project'
dataset_id = 'my_dataset'
table_id = 'my_table'
schema = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.DATE.value,
mode="REQUIRED",
),
bigquery.SchemaField(
"b",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id)
client.create_table(dataset_id, table_id, schema)
client.load_data(dataset_id, table_id, [{"a": "2022-01-01", "b": 1}])
# This query does not crash
client.run_query(f"SELECT MIN(b) OVER (PARTITION BY a) FROM `test-project.{dataset_id}.{table_id}`;")
# This query does crash with 'no such function: zetasqlite_window_min_date'
client.run_query(f"SELECT MIN(a) OVER (PARTITION BY b) FROM `test-project.{dataset_id}.{table_id}`;")
Logs:
2022-08-29T23:53:39.372Z ERROR server/handler.go:40 internal error {"error": "failed to query SELECT `$analytic1#4` FROM (SELECT `a#1`,`b#2`,( SELECT zetasqlite_window_min_date(`a#1`,zetasqlite_window_partition_string(`b#2`),zetasqlite_window_order_by_string(`b#2`, true),zetasqlite_window_frame_unit_string(1),zetasqlite_window_boundary_start_string(1, 0),zetasqlite_window_boundary_end_string(5, 0),zetasqlite_window_rowid_string(`row_id`)) FROM (SELECT `a` AS `a#1`,`b` AS `b#2` FROM `test-project_my_dataset_my_table`) ) AS `$analytic1#4` FROM (SELECT *, ROW_NUMBER() OVER() AS `row_id` FROM (SELECT `a` AS `a#1`,`b` AS `b#2` FROM `test-project_my_dataset_my_table`)) ORDER BY `b#2`,`a#1`): no such function: zetasqlite_window_min_date"}
This is a follow-up to #19, which did correctly implement MIN/MAX/COUNT as window functions for integer values.
Thank you!
I am seeing a number of issues when I create two tables that have the same table_id but different dataset_ids and schemas.
If I create table my_dataset_1.my_table with single column a and table my_dataset_2.my_table with single column b, the emulator seems to be confused about which table/schema to use.
If I try to load data into my_dataset_2.my_table after creating both tables, I get this error:
google.api_core.exceptions.BadRequest: 400 POST http://0.0.0.0:9050/bigquery/v2/projects/test_project/datasets/my_dataset_2/tables/my_table/insertAll?prettyPrint=false: INVALID_ARGUMENT: Column b is not present in table my_table [at 1:20]
If I try to load data into my_dataset_1.my_table after adding creating both tables, I get this error:
google.api_core.exceptions.BadRequest: 400 POST http://0.0.0.0:9050/bigquery/v2/projects/test_project/datasets/my_dataset_2/tables/my_table/insertAll?prettyPrint=false: unknown column name a
Finally, if I query the table information of my_dataset_1.my_table after creating both tables, it returns info for my_dataset_2.my_table.
Here is the script I have been using to reproduce:
from typing import List, Iterator, Dict, Any
from google.api_core.client_options import ClientOptions
from google.auth.credentials import AnonymousCredentials
from google.cloud import bigquery, exceptions
class BigQueryClientWrapper:
def __init__(self, project_id: str) -> None:
self.project_id = project_id
self.client = bigquery.Client(
project_id,
client_options=ClientOptions(api_endpoint="http://0.0.0.0:9050"),
credentials=AnonymousCredentials(),
)
def create_dataset(
self,
dataset_id: str
) -> bigquery.Dataset:
dataset = bigquery.Dataset(self._dataset_ref(dataset_id))
return self.client.create_dataset(dataset)
def create_table(
self,
dataset_id: str,
table_id: str,
schema: List[bigquery.SchemaField],
) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = bigquery.TableReference(dataset_ref, table_id)
table = bigquery.Table(table_ref, schema)
return self.client.create_table(table)
def get_table(self, dataset_id: str, table_id: str) -> bigquery.Table:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
return self.client.get_table(table_ref)
def run_query(self, query_str: str) -> Iterator[bigquery.Row]:
query_job = self.client.query(
query=query_str,
location="US",
job_config=bigquery.QueryJobConfig(),
)
return query_job.result()
def _dataset_ref(self, dataset_id: str) -> bigquery.DatasetReference:
return bigquery.DatasetReference.from_string(
dataset_id, default_project=self.project_id
)
def load_data(
self,
dataset_id: str,
table_id: str,
rows: List[Dict[str, Any]],
) -> None:
dataset_ref = self._dataset_ref(dataset_id)
table_ref = dataset_ref.table(table_id)
table = self.client.get_table(table_ref)
errors = self.client.insert_rows(table, rows)
if errors:
raise RuntimeError(
f"Failed to insert rows into {dataset_ref.dataset_id}.{table_id}:\n"
+ "\n".join(str(error) for error in errors)
)
if __name__ == '__main__':
project_id_ = 'test_project'
dataset_id_1 = 'my_dataset'
table_id_1 = 'my_table'
schema_1 = [
bigquery.SchemaField(
"a",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
dataset_id_2 = 'my_dataset_2'
schema_2 = [
bigquery.SchemaField(
"b",
field_type=bigquery.enums.SqlTypeNames.INTEGER.value,
mode="NULLABLE",
),
]
client = BigQueryClientWrapper(project_id=project_id_)
# Create the first table
client.create_dataset(dataset_id_1)
client.create_table(dataset_id_1, table_id_1, schema_1)
# Create a second table with the same table name in a different dataset, with a
# different schema.
client.create_dataset(dataset_id_2)
client.create_table(dataset_id_2, table_id_1, schema_2)
# Querying the proper columns works without crashing.
client.run_query(f"SELECT a FROM `{project_id_}.{dataset_id_1}.{table_id_1}`")
client.run_query(f"SELECT b FROM `{project_id_}.{dataset_id_2}.{table_id_1}`")
try:
# This throws, as expected: 'INVALID_ARGUMENT: Unrecognized name: a'
client.run_query(f"SELECT a FROM `{project_id_}.{dataset_id_2}.{table_id_1}`")
except Exception as e:
print(e)
# !! This returns info for dataset_id_2.table_id_1 !!
table_1 = client.get_table(dataset_id_1, table_id_1)
try:
# !! This throws: 'unknown column name a' !!
client.load_data(dataset_id_1, table_id_1, [{"a": 1}])
except Exception as e:
print(e)
try:
# !! This throws: 'Column b is not present in table my_table' !!
client.load_data(dataset_id_2, table_id_1, [{"b": 1}])
except Exception as e:
print(e)
Thank you!
Hi, I found that when UDF and table name like dataset.table_a exists in query at the same time, it doesn't work.
A sample is here.
package main
import (
"context"
"fmt"
"cloud.google.com/go/bigquery"
"github.com/goccy/bigquery-emulator/server"
"github.com/goccy/bigquery-emulator/types"
"google.golang.org/api/iterator"
"google.golang.org/api/option"
)
func main() {
ctx := context.Background()
const (
projectName = "test"
)
bqServer, err := server.New(server.TempStorage)
if err != nil {
panic(err)
}
if err := bqServer.Load(
server.StructSource(
types.NewProject(
projectName,
types.NewDataset(
"dataset1",
types.NewTable(
"table_a",
[]*types.Column{
types.NewColumn("id", types.INTEGER),
types.NewColumn("name", types.STRING),
},
types.Data{
{
"id": 1,
"name": "alice",
},
{
"id": 2,
"name": "bob",
},
},
),
),
),
),
); err != nil {
panic(err)
}
testServer := bqServer.TestServer()
defer func() {
testServer.Close()
bqServer.Close()
}()
client, err := bigquery.NewClient(
ctx,
projectName,
option.WithEndpoint(testServer.URL),
option.WithoutAuthentication(),
)
if err != nil {
panic(err)
}
defer client.Close()
query := client.Query(`
CREATE TEMP FUNCTION DoubleFn(x INT64)
RETURNS INT64
AS (
x + x
);
SELECT
id
FROM
dataset1.table_a;
`)
it, err := query.Read(ctx)
if err != nil {
panic(err)
}
for {
var row []bigquery.Value
if err := it.Next(&row); err != nil {
if err == iterator.Done {
break
}
panic(err)
}
fmt.Println("row = ", row)
}
if err := client.Dataset("dataset1").DeleteWithContents(ctx); err != nil {
panic(err)
}
}and got
panic: googleapi: Error 400: INVALID_ARGUMENT: Table not found: dataset1.table_a [at 10:9], jobInternalError
goroutine 1 [running]:
main.main()
/workspaces/bigquery-emulator/main.go:109 +0x907
exit status 2
Of couce, change query to
query := client.Query(`
SELECT
id
FROM
dataset1.table_a;
`)or to
query := client.Query(`
CREATE TEMP FUNCTION DoubleFn(x INT64)
RETURNS INT64
AS (
x + x
);
SELECT
id
FROM
UNNEST([1,2]) AS id;
`)works properly.
and got
row = [1]
row = [2]
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.