miksus / rocketry Goto Github PK
View Code? Open in Web Editor NEWModern scheduling library for Python
Home Page: https://rocketry.readthedocs.io
License: MIT License
Modern scheduling library for Python
Home Page: https://rocketry.readthedocs.io
License: MIT License




































































































































Hi there ! Thanks for your work !
Is your feature request related to a problem? Please describe.
It'll be great to be able to run tasks that use async code.
Describe the solution you'd like
A transparent asyncio support to be able to run async code.
Describe the solution you'd like
The return values are passable via queue (if multiprocessing) or via direct modification (if thread or main). These values need to be processed in Scheduler. Probably requires a new Argument type.
The argument type can be named as ReturnArg and can be put to Parameters using the name of the task as the key or so.
Is your feature request related to a problem? Please describe.
Pandas, and Numpy, are quite large and often problematic and slow to build.
Describe the solution you'd like
Drop Pandas as a hard dependency from setup.py. This also requires refactoring some of the date-related functionalities such as timeout parsing, time periods etc.
It should also be heavily tested the substitutes work exactly the same.
Additional context
Pandas' date functionalities are quite extensive, unique and unfortunately well embedded in the library. I think they are partly written in Cython so the performance is probably better as well than writing substitutes in pure Python.
Steps to reproduce the behavior.
# coding=utf-8
from memory_profiler import profile
from rocketry import Rocketry
from rocketry.conds import every
app = Rocketry()
@profile
@app.task(every("1 seconds"), execution="async")
async def job():
print(1)
if __name__ == '__main__':
app.run()
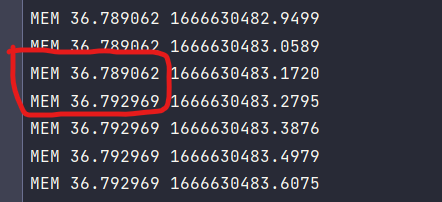
View the dat file in the same directory,memory leaks will be found
Is your feature request related to a problem? Please describe.
Sometimes, you would want the scheduler to stop running once a certain condition occurs. For instance, I want to check periodically a certain status returned by some REST API. If that status has met my condition, I would want to stop the scheduler.
Describe the solution you'd like
An app.stop() which is the logical opposite of app.run()
Describe alternatives you've considered
I could just exit() the code once the condition is met but that won't work for all cases.
I'm working on a FastAPI project. I want to add scheduling to, and Rocketry looks like a good way to do this. I understand the documentation about how to start Rocketry and FastAPI as separate asyncio tasks. But I also see where the examples modify uvicorn so Rocketry can enter the exit code.
Right now, I'm using docker_compose.yml to start the uvicorn rather than starting uvicorn in my code. Is there a way to get Rocketry connected to the asyncio loop as a task after the asyncio loop is running (by FastAPI)? And is there a way to connect the Rocketry exit work to uvicorn after it's running? Or can I connect the Rocketry exit stuff to the FastAPI "shutdown" event?
Thanks!
Doug
Is your feature request related to a problem? Please describe.
It'd be nice to gradually fix and turn on pylint errors (and maybe latest flake8/black checks). Having it as part of build CI/CD with github actions would help prevent increase of these.
Describe the solution you'd like
Add github actions for pylint eg https://github.com/marketplace/actions/github-action-for-pylint
Turn on initially with -ignore for
R0401,R0801,C0112,C0113,C0114,C0115,C0116,C0301,C0103,W0511,E0602,E1101,E1102,E0001,W2301,W0613,E0102,R0914,R0912,R1732,E0213,W0212,W0108,E1125,E0704,R0903,W0622,R0913,C0415,E0611,W0707,W0642,R1710,W0703,R0913,W0106,W0223,W0221,C0412,W0201,,R0904,R1704,E0601,R0902,W0236,W0612,W0611,W0143,W0109,W0231,W0621,W0107,W0104,W0621,E1121,W0706,W0122,R0915,W0631,C0302,E0401
and then can slowly remove those as the project quality improves.
Describe alternatives you've considered
Also might be worth considering black and / or flake8
Additional context
A measure of code quality
Describe the bug
It seems the system warns about the task_execution to be changed in the future version.
To Reproduce
Import the library.
Expected behavior
No warnings raised when importing.
Is your feature request related to a problem? Please describe.
When running a task manually (using force_run), sometimes it's useful to pass parameters for this particular manual run.
Describe the solution you'd like
Possibly a core change. An attribute manual_parameters or so that are used only once and only when the task is run with force_run.
Describe alternatives you've considered
Cannot think of such.
I am trying to delete a task, but Rocketry returns a KeyError.
import asyncio
from rocketry import Rocketry
from rocketry.conds import secondly
app = Rocketry()
@app.task(secondly, name='foo')
async def foo():
...
async def main():
asyncio.create_task(app.serve())
app.session.remove_task('foo')
# app.session.tasks.remove('foo')
if __name__ == '__main__':
asyncio.run(main())Is it corrected in the latest version (master branch)?
no
Latest version of the docs: https://rocketry.readthedocs.io/en/latest/
Location in the documentation you wish to improve
Describe the problem
In the first page, there seems a function(task name) typo.
To create a task:
from rocketry.conds import daily
from rocketry.args import Session
def do_things():
...
@app.task()
def remove_task(session=Session()):
session.create_task(func=do_things, start_cond=daily)For the second page, following from here, this line
app.task('daily', code='print("Hello world")')Suggestion for the fix
Is your feature request related to a problem? Please describe.
Some people might prefer Crontab-like scheduling options over the built-in time periods even though one can compose pretty much the same scheduling with it as well.
Describe the solution you'd like
The solution will consist of two parts: time periods and then a condition wrapper for it. The solution should extend the existing time system to support intervals mimicking the Cron time intervals and then it should be trivial to add that to the conditions. Then there could be a condition added in the condition API and to the condition syntax to compose such a combination.
Describe alternatives you've considered
Using existing time periods and conditions.
Is it corrected in the latest version (master branch)?
no
Latest version of the docs: https://rocketry.readthedocs.io/en/latest/
Location in the documentation you wish to improve
https://rocketry.readthedocs.io/en/latest/handbooks/logging.html#
Describe the problem
The line below causes an error:
logging.addHander(handler)
Suggestion for the fix
It should be:
logger.addHandler(handler)
Is your feature request related to a problem? Please describe.
It seems not possible to run tasks in the background.
Describe the solution you'd like
I would like to run the tasks in the background so it can do other stuff in the meantime.
Describe alternatives you've considered
I use APScheduler right now but besides it supports background tasks I feel like Rocketry would be way more convenient if it supports this feature.
Is your feature request related to a problem? Please describe.
Often it is useful to report tasks that did not run during their intended period due to dependencies did not run or so.
Describe the solution you'd like
A new condition TaskMisfire which can be used as:
@FuncTask(start_cond="daily between 08:00 and 17:00 & after task 'another'")
def run_something():
...
@FuncTask(start_cond="after task 'run_something' misfired")
def report_misfire():
... # Runs if run_something did not run during the time specified in TaskExecution condDescribe alternatives you've considered
Alternatively one could just create tasks that do something only if the intended task
did not run on its period.
Thanks for sharing this amazing software.
Describe the bug
Running Red Engine causes 100% CPU utilization. Maybe it's busy waiting?
To Reproduce
This simple app prints "Hello World" every 1 minute.
from redengine import RedEngine
app = RedEngine()
@app.task("every 1 minute")
def main():
print("Hello World")
if __name__ == "__main__":
app.run()Expected behavior
CPU not utilized at all while waiting between running tasks.
Screenshots

Desktop (please complete the following information):
Additional context
If there's some misconfiguration on my side I'd be grateful for tips.
Describe the solution you'd like
It would be nice to do this:
from rocketry.conds import daily, weekly
@app.task(daily.at("12:00", "18:00"))
def do_daily_twice():
... # Condition translates to: daily.at("12:00") | daily.at("18:00")
@app.task(weekly.on("Mon", "Fri"))
def do_weekly_twice():
... # Condition translates to: weekly.on("Mon") | weekly.on("Fri")Describe alternatives you've considered
Use OR (|) but this gets tediuous.
Description
The use of RedBird to store logs can easily lead to unexpected memleaks, and it is both a difficult problem to debug, and a little awkward to handle that on the side of the client.
Consider the following script:
import tracemalloc
from rocketry import Rocketry
app = Rocketry(execution="main")
tracemalloc.start()
last_count, _ = tracemalloc.get_traced_memory()
@app.task("every 1 second")
def do_things() -> None:
global last_count
new_count, _ = tracemalloc.get_traced_memory()
print(new_count - last_count)
last_count = new_count
if __name__ == "__main__":
app.run()Which results in the following input:
145402
14344
6636
6604
6668
6604
6604
6604
6677
7290
6604
So every run causes a memory build-up of around 6.5KB even if no logging is made, other than the default Rocketry logging. In 24h that would be over 500MB.
Using tracemalloc.take_snapshot() it is easy to check that this is caused by the RedBird in-memory log store.
This is solvable, but in an arguably awkward way:
import tracemalloc
from redbird import BaseRepo
from redbird.repos import MemoryRepo
from rocketry import Rocketry
from rocketry.log.log_record import LogRecord
logger_repo = MemoryRepo(model=LogRecord)
app = Rocketry(execution="main", logger_repo=logger_repo)
tracemalloc.start()
last_count, _ = tracemalloc.get_traced_memory()
@app.task("every 1 second")
def do_things() -> None:
global last_count
logger_repo.filter_by().delete()
new_count, _ = tracemalloc.get_traced_memory()
print(new_count - last_count)
last_count = new_count
if __name__ == "__main__":
app.run()The reason why I say this is awkward is that it requires:
Potential solution
Ideally, Rocketry's default log repo has some mechanism to evict old records automatically, which would be configurable. So for example, if we simply did:
app = Rocketry()We would get a logger repo that would keep, for example, the last 100 log messages only. If we wanted to keep all records, we'd just pass the basic MemoryRepo as in my example above. If we wanted to control the amount of records kept, we could do something like:
from redbird.repos import FIFOMemoryRepo
from rocketry.log.log_record import LogRecord
app = Rocketry(logger_repo=FIFOMemoryRepo(model=LogRecord, size=50))The FIFOMemoryRepo class would have to be implemented in RedBird, of course.
Describe the bug
I want to have periodic tasks running in my main thread, but it does not seem to work. if initialized with nothing, rocketry will:
this is ok because the log messages are helpful in suggesting that I should initialize the Rocketry app with `Rocketry(task_execution='async') or something.
Problem is that when I initialize with (task_execution='main'), the startup fails. It seems that the log message is not up to date because docs suggest using ```python
config={
'task_execution': 'main'
}
but this has apparently no affect on the configuration (see logs below)
**To Reproduce**
Here is the code I've used to initialize the tasks:
```python
from api.core.management.jobs import something_else
from api.core.management.jobs import something
from django.core.management.base import BaseCommand
import logging
from rocketry import Rocketry
from rocketry.conds import daily
from rocketry import Rocketry, Session
from rocketry.conds import daily, every
from rocketry.log import MinimalRecord
from redbird.repos import CSVFileRepo
class JobLogger(MinimalRecord):
exc_text: Optional[str] = Field(description="Exception text")
repo = CSVFileRepo(filename="/tmp/api-logs/jobs.csv", model=JobLogger)
scheduler : Rocketry = Rocketry(
logger_repo=repo,
config={
'task_execution': 'main'
}
)
# i've attempted to set scheduler.session.config.task_execution to `main` here, but to no avail
@scheduler.task(daily.at("00:10"), execution='main')
def do_something() -> None:
logging.getLogger(__name__).info("Running do_something()")
something.run()
@scheduler.task(daily.at("23:55"), execution='main')
def do_something_else() -> None:
logging.getLogger(__name__).info("Running do_something_else()")
something_else.run()
class Command(BaseCommand):
help = "Setup the periodic jobs runner"
def handle(self, *args, **options):
scheduler.run()
Expected behavior
Run the tasks in my main thread and not have the app crash on startup.
Screenshots
/usr/local/lib/python3.10/site-packages/rocketry/session.py:73: FutureWarning: Default execution will be changed to 'async'. To suppress this warning, specify task_execution, ie. Rocketry(task_execution='async') and then later on, when the job starts:
Traceback (most recent call last):
File ""/usr/local/lib/python3.10/site-packages/rocketry/core/task.py"", line 536, in _run_as_async
output = await self.execute(**params)
File ""/usr/local/lib/python3.10/site-packages/rocketry/tasks/func.py"", line 234, in execute
output = func(**params)
File ""/server/api/core/management/commands/initjobs.py"", line 40, in do_something
do_something.run()
File ""/server/api/core/management/jobs/do_something.py"", line 46, in run
for value in fetched_from_database:
File ""/usr/local/lib/python3.10/site-packages/django/db/models/query.py"", line 394, in __iter__
self._fetch_all()
File ""/usr/local/lib/python3.10/site-packages/django/db/models/query.py"", line 1866, in _fetch_all
self._result_cache = list(self._iterable_class(self))
File ""/usr/local/lib/python3.10/site-packages/django/db/models/query.py"", line 87, in __iter__
results = compiler.execute_sql(
File ""/usr/local/lib/python3.10/site-packages/django/db/models/sql/compiler.py"", line 1393, in execute_sql
cursor = self.connection.cursor()
File ""/usr/local/lib/python3.10/site-packages/django/utils/asyncio.py"", line 24, in inner
raise SynchronousOnlyOperation(message)
django.core.exceptions.SynchronousOnlyOperation: You cannot call this from an async context - use a thread or sync_to_async."Desktop (please complete the following information):
Python version: 3.10.7
Rocketry version: 2.4.1
Django version: 4.1
Additional context
N/A
Describe the bug
Log gets spammed with status:terminate messages. This bug exists for tasks, that are running on process and using multilaunch=True.
To Reproduce
python my_file_name.pyExpected behavior
Screenshots
Uploading screenshot of logs

Desktop (please complete the following information):
Additional context
Here I paste the code
from datetime import timedelta
from time import sleep
from rocketry import Rocketry
from rocketry.log import TaskLogRecord
from redbird.repos import CSVFileRepo
# #
# Rocketry app
repo = CSVFileRepo(filename="check_me_after_30_seconds.csv", model=TaskLogRecord)
app = Rocketry(
config={
"task_execution": "async",
"max_process_count": 4,
"timeout": timedelta(seconds=30),
},
logger_repo=repo,
)
# #
# tasks
@app.task("every 10 seconds")
async def mark_10_seconds():
print("10 seconds have passed")
@app.task(execution="process")
async def run_me_sir():
print("Sir, I am going to sleep for 20 seconds")
sleep(20)
print("Sir, I am done with sleeping")
@app.task(execution="process", multilaunch=True)
async def run_multilaunch_me_madam():
print("Madam, I as multilaunch am going to sleep for 20 seconds")
sleep(20)
print("Madam, I as multilaunch am done with sleeping")
if __name__ == "__main__":
app.session["run_me_sir"].run()
app.session["run_multilaunch_me_madam"].run()
app.run()
I really like the potential of this library. I might be misinterpreting the documentation, but I believe this feature is not (easily) available.
Is your feature request related to a problem? Please describe.
The tasks are not known beforehand/statics. I would like to be able to dynamically create tasks and add them to the scheduler (both before running and while running).
Describe the solution you'd like
Something along the lines of:
app.add_task(name="my_task",interval="every 10 minutes",callback=my_fun)
app.remove_task(name="my_task")
Describe alternatives you've considered
I have tried messing with the Session() and Task() things, as from the documentation it hints that you can create tasks this way.
However, I did not understand from the documentation how this would work other than manipulating existing tasks.
Additional context
I am writing a CLI app where I would like the load the schedule from a configuration file and also allow the user to dynamically add tasks to the schedule.
Is your feature request related to a problem? Please describe.
Proposal for new task class: create a task directly from a class.
Requires possibly a new metaclass. The task will be created when the class itself is initiated.
from redengine.tasks import ClassTask
class MyTask(ClassTask):
name = 'my-task'
start_cond = 'daily'
execution = 'process'
def __init__(self, session):
... # Do whatever
def execute(self):
... # Do whateverWhy? You can bundle all the functions related to the task nicely to one place.
Example, now one can do:
from redengine.tasks import ClassTask
def extract():
...
def transform(data):
...
return data
def load(data):
...
@FuncTask(name="etl", start_cond="daily")
def process_etl():
data = extract()
data = transform(data)
load(data)Proposed:
from redengine.tasks import ClassTask
class ProcessETL(ClassTask):
name = 'etl'
start_cond = 'daily'
def execute(self):
data = self.extract()
data = self.transform(data)
self.load(data)
def extract(self):
....
def transform(self, data):
....
return data
def load(self, data):
...Describe the bug
I was going through the documentation here: https://rocketry.readthedocs.io/en/stable/cookbook/robust_applications.html?highlight=email#to-csv , and following the steps to add a repo to an app session, I get the error:
AttributeError: 'Session' object has no attribute 'set_repo'
To Reproduce
This simple scripts will produce the error:
from rocketry import Rocketry
from rocketry.log import LogRecord
from redbird.repos import CSVFileRepo
app = Rocketry(config={
'task_execution': 'async',
'silence_task_prerun': True,
'silence_task_logging': True,
'silence_cond_check': True
})
repo = CSVFileRepo(model=LogRecord, filename="tasks.csv")
repo.create()
app.session.set_repo(repo, delete_existing=True)Expected behavior
The repo is set without any errors
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
What else can I do to set the repo in the meantime?
Is it corrected in the latest version (master branch)?
Yes
Latest version of the docs: https://rocketry.readthedocs.io/en/latest/
Location in the documentation you wish to improve
https://rocketry.readthedocs.io/en/stable/examples/index.html
Describe the problem
I didn't find examples for use with django, is it possible to use with django?
Suggestion for the fix
Explain usage with Django.
Describe the bug
Latest codebase, pulle down.
Run pytest
test_build.py is failing, and /schedule/test_core.py runs for 30 min and is still going?
I also tried running them all individually from vscode, got some more intermittent failures.
To Reproduce
Latest codebase, pulle down.
Run pytest
Expected behavior
Tests to execute in full and pass
Screenshots


Desktop (please complete the following information):
Additional context
Test failure for build:

For example, running a task in 10 sec interval produces the following output:
time to run: 2022-07-05 10:03:14.170614
time to run: 2022-07-05 10:03:24.659828
time to run: 2022-07-05 10:03:35.116288
time to run: 2022-07-05 10:03:45.570992
time to run: 2022-07-05 10:03:56.041514
time to run: 2022-07-05 10:04:06.542453
time to run: 2022-07-05 10:04:17.028015
time to run: 2022-07-05 10:04:27.530127
time to run: 2022-07-05 10:04:38.023248
time to run: 2022-07-05 10:04:48.461072
time to run: 2022-07-05 10:04:58.944541
time to run: 2022-07-05 10:05:09.412248
time to run: 2022-07-05 10:05:19.871020
time to run: 2022-07-05 10:05:30.386063
time to run: 2022-07-05 10:05:40.858525
time to run: 2022-07-05 10:05:51.296365
time to run: 2022-07-05 10:06:01.766899
time to run: 2022-07-05 10:06:12.253105
time to run: 2022-07-05 10:06:22.742304
time to run: 2022-07-05 10:06:33.174691
time to run: 2022-07-05 10:06:43.657969
time to run: 2022-07-05 10:06:54.157131
I'm wondering this will cause problem with task in long run.
The code:
from redengine import RedEngine
import datetime
app = RedEngine()
@app.task('every 10 sec')
def do_things():
print("time to run: ", datetime.datetime.now())
if __name__ == "__main__":
app.run()Is your feature request related to a problem? Please describe.
Hi! I'm thinking of using this library as part of a scheduler / manager to automate various tasks including web-scraping and running parts of a multi-agent system. I have some tasks that either shouldn't or don't need to be run at exactly defined moments (e.g. web-scrapers and randomized load balancing) and it would be very helpful to be able to set a spread or error bar to a time / trigger condition. I.e. set some acceptable leeway that's non-fixed.
Describe the solution you'd like
Specifically I want to introduce non-fixed acceptable leeway -- randomly sampled error from a range -- to defined start- and end-times in a way that has the errors change each time a condition is evaluated (not set the error once and re-use it). This should be handled under the hood by Rocketry to minimize boilerplate code / code complexity.
In practice what I envision is one or more of the following extensions:
@app.task("daily after 07:00 +/- 10 minutes") and "daily after 07:00 +/- 2 hours. Would apply to the Condition API as well: every("10 seconds +/- 2 seconds").spread or error attribute to the members of rocketry.cond (after, between, on, ...).Choice of sampling method used to set the final offset can in theory also be a user choice but I'm not sure where that parameter is best defined -- it adds more complexity to the language syntax. Passed as an argument or maybe set on the Session beforehand might be better options. I see two viable sampling methods: Uniform random and Gaussian.
Then there's a question of the spread size. It makes no sense to say "+/- 1 day" or "+/- 7 hours" in the above examples, so there should perhaps be some constraint handling in place. Exactly which ones is unclear.
Describe alternatives you've considered
I have considered dynamically setting or adjusting times on a per run basis using my own code external to Rocketry. Functionally this will likely be fine but it adds complexity to my code and I believe others might enjoy this feature too. It's unclear to me how I can implement variation on the timing in a way that's handled under the hood by Rocketry. I know the request might seem odd in the face of Rocketry trying to be as precise and timely as possible but I like this library and I see my suggestions here as an extension to fill a niche.
Additional context
I had a look at #89 (comment) and like the idea presented there but as far as I see that fulfills a different need (i.e. setting a probability of running a task at all, time still being exact). I would love to provide a similarly small example but haven't yet figured out the internals of Rocketry to do so.
Is it corrected in the latest version (master branch)?
No
Latest version of the docs: https://rocketry.readthedocs.io/en/latest/
Location in the documentation you wish to improve
Bigger Applications
Describe the problem
If you add the code exactly as is, you get AttributeError: 'Rocketry' object has no attribute 'include_group'.
Suggestion for the fix
Instead of include_group it should be include_grouper
Is your feature request related to a problem? Please describe.
Update automatically the scheduler according to file changes.
Describe the solution you'd like
At least the tasks should be auto reloaded: changes in the tasks should be reflected automatically
and removed tasks should be automatically removed in run time.
Possibly solved by good and more structured support for tasks read from YAML files. Could work like this:
Also, this is possibly supported but requires documentation and possibly more testing.
Describe alternatives you've considered
Alternatively a robust restart mechanism so the scheduler is easy to restart when needed. This is probably already supported.
Or the user can make a Reload task that reloads all the relevant Python modules and deletes tasks that are no longer specified in these.
Install
pip install rocketry==2.4.1Code
import datetime
from rocketry import Rocketry
from redbird.repos import CSVFileRepo
app = Rocketry(logger_repo=CSVFileRepo(filename='logs.csv'))
@app.task('secondly')
def do_things():
print(datetime.datetime.now())
if __name__ == '__main__':
app.run()It raise NotImplementedError.
Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\templates.py", line 68, in last
return self.repo.query_read_last(self.query_)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\templates.py", line 309, in query_read_last
raise NotImplementedError("Read using first not implemented.")
NotImplementedError: Read using first not implemented.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:/mycode/Rocketry_examples/04 日志.py", line 11, in <module>
def do_things():
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\tasks\func.py", line 193, in __call__
super().__init__(func=func, **self._delayed_kwargs)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\core\task.py", line 275, in __init__
self.set_cached()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\core\task.py", line 825, in set_cached
self.last_run = self._get_last_action("run", from_logs=True, logger=logger)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\core\task.py", line 1064, in _get_last_action
value = self._get_last_action_from_log(action, logger)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\core\task.py", line 1074, in _get_last_action_from_log
record = logger.get_latest(action=action)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\rocketry\core\log\adapter.py", line 91, in get_latest
return self.filter_by(**kwargs).last()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\templates.py", line 70, in last
return super().last()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\base.py", line 57, in last
for item in self.query():
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\templates.py", line 23, in query
yield from items
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\repos\csv.py", line 82, in query_items
yield from read_items(self, self.read_file(), query)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\utils\query.py", line 39, in read_items
for data in reader:
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\repos\csv.py", line 114, in read_file
reader = self.get_reader(file)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\repos\csv.py", line 143, in get_reader
return csv.DictReader(buff, fieldnames=self.get_headers(), **self.kwds_csv)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\site-packages\redbird\repos\csv.py", line 105, in get_headers
raise TypeError("Cannot determine CSV headers")
TypeError: Cannot determine CSV headers
Is your feature request related to a problem? Please describe.
Allow creating groups of tasks so they can be modified at once, like:
Can also have view functionality for easier handling of the group. Also adds options for new conditions like GroupSucceeded (True if all tasks in the group has succeeded).
Describe the solution you'd like
Possibly new parameter to Task initiation (group) and a new class (maybe to extensions).
Is your feature request related to a problem? Please describe.
The scheduling syntax is easy but it is error-prone and does not work with static code analysis.
For example, this has no highlighting and it is hard to validate before runtime:
@app.task("daily between 12:00 and 15:00 & time of week on Monday ")
def do_daily():
...The syntax parser turns the strings to the Python instances that represent the conditions but the naming of these conditions is not always the best.
Describe the solution you'd like
Candidate A): use the existing (but maybe think better names):
@app.task(TaskExecutable(period=TimeOfDay("12:00", "15:00") & IsPeriod(period=TimeOfWeek("Mon", "Mon"))))
def do_daily():
...Candidate B): have similarly named instances as in the string expressions:
@app.task(daily.between("12:00", "15:00") & time_of_week.on("Monday"))
def do_daily():
...These also could be used in generating the condition syntax items instead of the ugly class methods that exist for them.
Additional context
This is related to the part of the library that is quite old and could have some cleaning. The logic of these conditions is based on ideas that evolved into better ones which means the code in this area is not as clear as it could be.
Describe the bug
When Rocketry works in async fashion through app.serve(), it becomes frozen when specific manual-run task sequence is executed.
Task sequence:
run_me_madam starts on async
run_me_madam finishes
run_me_sir starts on process (not async)
app.serve() becomes frozen
To Reproduce
For reproducing the bug I will paste code at the bottom of issue and will pinpoint commit, after which the aforementioned bug arose.
Expected behavior
starting manually a task after one has finished, should not freeze the async Rocketry.serve(). In this case it is expected to see run_me_sir finish.
Screenshots
When trying to KeyboardInterrupt the frozen async Rocketry.serve(), such error always appears:

Desktop (please complete the following information):
pip install git+https://github.com/Miksus/rocketry.git@c9480a9c847704a0a57b4c6770eeb1028bf029a0Additional context
Here I paste the code.
from time import sleep
import asyncio
from rocketry import Rocketry
# #
# Rocketry app
app = Rocketry(
config={
"execution": "async",
"max_process_count": 100,
}
)
# #
# tasks
@app.task("every 10 seconds")
async def mark_10_seconds():
print("10 seconds have passed")
@app.task(execution="async")
async def run_me_madam():
print("Madam, I am going to sleep for 2 seconds")
sleep(2)
print("Madam, I am done with sleeping")
@app.task(execution="process")
async def run_me_sir():
print(f"Sir, I am going to sleep for 2 seconds.")
sleep(2)
print("Sir, I am done with sleeping")
if __name__ == "__main__":
async def task_manual_run_flow():
await asyncio.sleep(3)
print(
"will run run_me_madam task - on async (or even if on process, result would be the same)"
)
app.session["run_me_madam"].run()
await asyncio.sleep(10)
print("madam task should be done by now")
print("will run run_me_sir - on process")
app.session["run_me_sir"].run()
print("doing await asyncio.sleep(5). If it takes forever, you are stuck here.")
await asyncio.sleep(5)
print(
"launched run me sir through session. If you do not see this message, it means that app.serve() never returned control via await."
)
async def main_main():
return await asyncio.gather(app.serve(), task_manual_run_flow())
asyncio.run(main_main())
Is your feature request related to a problem? Please describe.
If a task was missed (due to system failure, performance reasons or missing conditions), in some cases it is desired to run the missed task(s).
Describe the solution you'd like
Run stacks or a condition that allows running tasks that were missed.
Maybe something like this:
@app.task("daily | missed")
def do_daily():
...If this was missed (did not run yesterday), the missed should return True and the task should run again.
The solution needs to check the last time the task ran and compare whether that was inside the previous timespan of the condition.
Describe alternatives you've considered
A metatask or a custom condition with a stack.
Is your feature request related to a problem? Please describe.
Some people would like to use Rocketry with other timezones. For example, if the code is developed on a timezone +2 and the machine where it is run is at timezone +0, there could be problems. Running the application in the developer's machine vs in the production environment would result tasks to be run at different times between these environments.
For example, there is a task scheduled to run at 10:00. If the developer runs the application, the task will be run 10:00 in his/her local time but it would be 08:00 in the production server's time. The development environment probably should run tasks at the same universal times as the production environment.
Describe the solution you'd like
Optionally specify a timezone in the session object. Probably also requires the time measurement will be done in the same function throughout the library.
Single function for measurement has the added benefit that one could override it in order to build unit tests: check a task is indeed runned when the current time is 10:00, for example.
Describe alternatives you've considered
One could override the time.time but that has added problems. Possibly no feasible alternatives without core changes.
Additional context
The measurement of time is done using time.time (instead of datetime.datetime.now) in order to work together with logging (as it uses time.time). There is a bug in Python that datetime.datetime.now and time.time do rounding differently causing problems in quickly executed tasks if datetime.datetime.now was used.
The logs store the timestamps in timezone agnostic way (using Unix epoch).
Describe the solution you'd like
At the moment this is not possible:
from redengine.args import Task
@app.cond("is things")
def is_things(task=Task()):
return True or FalseIf this was a starting condition of a task, that task should be put as the argument.
Additional context
Maybe the task injection to the conditions could be a bit reworked to work uniformly with user-defined conditions.
Maybe we could have a check method in the conditions for such purposes instead of relying to __bool__.
Describe the bug
When using Rocketry with FastAPI, I return all tasks using such code: return rocketry_app.session.tasks .
But if I dynamically create task (rocketry_app.session.create_task(...)) and set its start_cond to conds.cron(...), then endpoint raises exception on returning tasks:
AttributeError: Condition <class 'rocketry.conditions.task.task.TaskRunnable'> is missing __str__.
To Reproduce
Create task in session, set its start cond to future date using conds.cron(...), return session.tasks via FastAPI endpoint (found reference example in Rocketry docs)
Expected behavior
No 500 internal error (no AttributeError)
I expect it to print something, to stringify the condition
Screenshots
I am sorry, no screenshots.
Desktop (please complete the following information):
Additional context
I am creating a pull request to fix this issue. Link:
pull request
I have previously used APScheduler in Flask for some things I need to do in background.
The problem with flask is if you load it in gunicorn, or debug mode and have multiple threads, the tasks will get scheduled multiple times as its run multiple times.
Is there a workaround in red engine for this?
BUG-how to set the particular time zone for the schedule
how set the particular time zone for the schedular.. if I designed a stock market & deployed an application to some other zone all scheduler work deployed time zone.
Expected behavior
Should have somewhere to set the time zone.
Is your feature request related to a problem? Please describe.
Allow running custom code after task failure/success.
Describe the solution you'd like
Possibly:
hook_success, hook_failure etc.callback_fail, callback_successfail_callback, success_callbackfail_cb, success_cbcb_fail, cb_successon_fail, on_successDescribe alternatives you've considered
Subclass and override process_success and process_failure.
I tried to follow the example in the url https://rocketry.readthedocs.io/en/stable/tutorial/advanced.html to execute a task by command, but, following the example app.task('daily', command ='echo "Hello world"'), an error occurs. To work, it was necessary to include the parameter shell=True. app.task('daily', shell=True, command='echo "Hello world"')
Is your feature request related to a problem? Please describe.
There may be a situation in which checking the state of a condition consumes too much from the processor, is too slow or prone for freezing thus one may want a condition which check is parallelized.
Describe the solution you'd like
A TaskCond that could be used as:
from redengine.conditions import TaskCond
@TaskCond(start_cond="every 10 minutes", cooldown="10 minutes", syntax="site is on")
def site_is_on():
... # Expensive code
return True or FalseThis condition is False when the state is not checked and then when it is, the condition is True or False depending on the state. Then there is a cooldown meaning that the condition is True for the specified time without actually rechecking the task.
If start_cond not specified, the task runs every time the cooldown is over. If cooldown is not specified, cooldown is specified as ethernal: the state changes only when rechecked. If cooldown ends before recheck (start_cond fulfilled and rerun), the state should be false.
Describe alternatives you've considered
A condition that is False if parameter value does not exist and a task that populates this parameter.
Is your feature request related to a problem? Please describe.
Sometimes it may be beneficial to know when a task has not been launched in the given execution period due to other constraints in other conditions.
Describe the solution you'd like
In addition to last_success, last_fail etc. log similarly the last_misfire when a task did not execute in its period. This could be logged in __bool__ of a task.
Then one could build conditions like:
@FuncTask(start_cond="after task 'mytask' misfired")
def handle_misfire():
...There could be an option to store the misfires in logs in session.config, for example "log_misfire": True.
Describe alternatives you've considered
Alternatively one could make a task that inspects the same thing and executes constantly.
Great project. I just switched an app over from Schedule.
One question, and I may be asking Rocketry to do something not in its nature. Is there an option to use Timedeltas lower than one second? ms and milliseconds are in the source and parsing them doesn't seem to explode Task assignment. However, they don't fire as often as expected.
In the example below I've fiddled with cycle_sleep down to 0.005 and None, but still only get 2-3 per second.
Is this supported? No problem if not, I'll have my tasks do it internally.
app = Rocketry(config={"cycle_sleep": None})
@app.task("every 100 ms")
def do_things():
print(str(datetime.now()) + " hello")
if __name__ == "__main__":
app.run()2022-08-31 15:16:12.324561 hello
2022-08-31 15:16:12.713914 hello
2022-08-31 15:16:13.102267 hello
2022-08-31 15:16:13.488618 hello
2022-08-31 15:16:13.874968 hello
2022-08-31 15:16:14.261318 hello
2022-08-31 15:16:14.647670 hello
2022-08-31 15:16:15.035021 hello
2022-08-31 15:16:15.422372 hello
2022-08-31 15:16:15.812726 hello
2022-08-31 15:16:16.207084 hello
2022-08-31 15:16:16.599441 hello
2022-08-31 15:16:16.993798 hello
Is your feature request related to a problem? Please describe.
There is (possibly not completely working) HTTP API for communicating with the session but the communication is not really standardized.
Describe the solution you'd like
Make a base class for communication tasks. (ie. BaseCommunicator)
A communication task could:
Possible example runtime communicators:
HTTPCommunicator (already somewhat implemented)MongoCommunicator: Read instructions from a MongoDB collectionIOCommunicator: Read instructions from a file (JSON, CSV etc.)These should be permanently running tasks running on startup.
Problems:
Is your feature request related to a problem? Please describe.
Creating simple conditions like a function that returns True-False and having that to the string parser engine could be easier.
Describe the solution you'd like
Proposed syntax:
from redengine.conditions import FuncCond
@FuncCond(syntax="is foo time"):
def is_foo():
return True
# Then use
@FuncTask(start_cond="is foo time & daily")
def do_stuff():
...The FuncCond could have following parameters:
syntax: (List[re.compile, str], str, re.compile): Syntax(es) that are parsed. Named groups are passed to the function like with BaseCondition.name: Name of the resulted class, optional. By default the same name as the function.Describe alternatives you've considered
Alternatively using the standard method:
import re
from pathlib import Path
from redengime.core import BaseCondition
class IsFoo(BaseCondition):
__parsers__ = {
"is foo time": "__init__"
}
def __init__(self):
pass
def __bool__(self):
return True
# Then use
@FuncTask(start_cond="is foo time & daily")
def do_stuff():
...Is your feature request related to a problem? Please describe.
This is too laboursome:
@FuncTask(start_cond="after task 'task-1' & after task 'task-2' & after task 'task-3'")
def do_things():
...Describe the solution you'd like
Instead it could work like:
@FuncTask(start_cond="after tasks 'task-1', 'task-2', 'task-3'")
def do_things():
...or:
@FuncTask(start_cond="after tasks 'task-1', 'task-2', 'task-3' succeeded")
def do_things():
...What its advantages over Airflow and other mature schedule framework are?
Is your feature request related to a problem? Please describe.
Currently, a task can run only once at a time. It does not support launching the same task simultaneously.
Describe the solution you'd like
Something like this:
@app.task(multilaunch=True)
def do_things(arg):
print("Doing", arg)
time.sleep(2)
print("Did", arg)If it was called like this:
task.run(arg="1")
task.run(arg="2")This should print:
Doing 1
Doing 2
Did 1
Did 2
Currently, Rocketry checks whether the task is already running before running it. And it will block second run if it was running.
Describe alternatives you've considered
Create duplicate tasks with different names.
Additional context
By default this should be not permitted as the logs may become a mess.
Hello,
Do you have any plans to add distributed execution?
Something like:
@app.task(daily, queue: RedbirdQueue | RabbitMQQueue | RedisQueue | InMemoryQueue | SQLALchemyQueue)
def do_daily():
...
worker = RocketryWorker(queues=[my_queues])
worker.run()A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.