![]()



![]()
- The documentation, user guide, sample notebooks and other information are available at
- https://py-why.github.io/dowhy
- DoWhy is part of the PyWhy Ecosystem. For more tools and libraries related to causality, checkout the PyWhy GitHub organization!
- For any questions, comments, or discussions about specific use cases, join our community on Discord (
)
- Jump right into some case studies:
- Effect estimation: Hotel booking cancellations | Effect of customer loyalty programs | Optimizing article headlines | Effect of home visits on infant health (IHDP) | Causes of customer churn/attrition
- Root cause analysis and explanations: Causal attribution and root-cause analysis of an online shop | Finding the Root Cause of Elevated Latencies in a Microservice Architecture | Finding Root Causes of Changes in a Supply Chain
For more example notebooks, see here!
Decision-making involves understanding how different variables affect each other and predicting the outcome when some of them are changed to new values. For instance, given an outcome variable, one may be interested in determining how a potential action(s) may affect it, understanding what led to its current value, or simulate what would happen if some variables are changed. Answering such questions requires causal reasoning. DoWhy is a Python library that guides you through the various steps of causal reasoning and provides a unified interface for answering causal questions.
DoWhy provides a wide variety of algorithms for effect estimation, prediction, quantification of causal influences, diagnosis of causal structures, root cause analysis, interventions and counterfactuals. A key feature of DoWhy is its refutation and falsification API that can test causal assumptions for any estimation method, thus making inference more robust and accessible to non-experts.
Graphical Causal Models and Potential Outcomes: Best of both worlds
DoWhy builds on two of the most powerful frameworks for causal inference: graphical causal models and potential outcomes. For effect estimation, it uses graph-based criteria and do-calculus for modeling assumptions and identifying a non-parametric causal effect. For estimation, it switches to methods based primarily on potential outcomes.
For causal questions beyond effect estimation, it uses the power of graphical causal models by modeling the data generation process via explicit causal mechanisms at each node, which, for instance, unlocks capabilities to attribute observed effects to particular variables or estimate point-wise counterfactuals.
For a quick introduction to causal inference, check out amit-sharma/causal-inference-tutorial We also gave a more comprehensive tutorial at the ACM Knowledge Discovery and Data Mining (KDD 2018) conference: causalinference.gitlab.io/kdd-tutorial. For an introduction to the four steps of causal inference and its implications for machine learning, you can access this video tutorial from Microsoft Research DoWhy Webinar and for an introduction to the graphical causal model API, see the PyCon presentation on Root Cause Analysis with DoWhy.
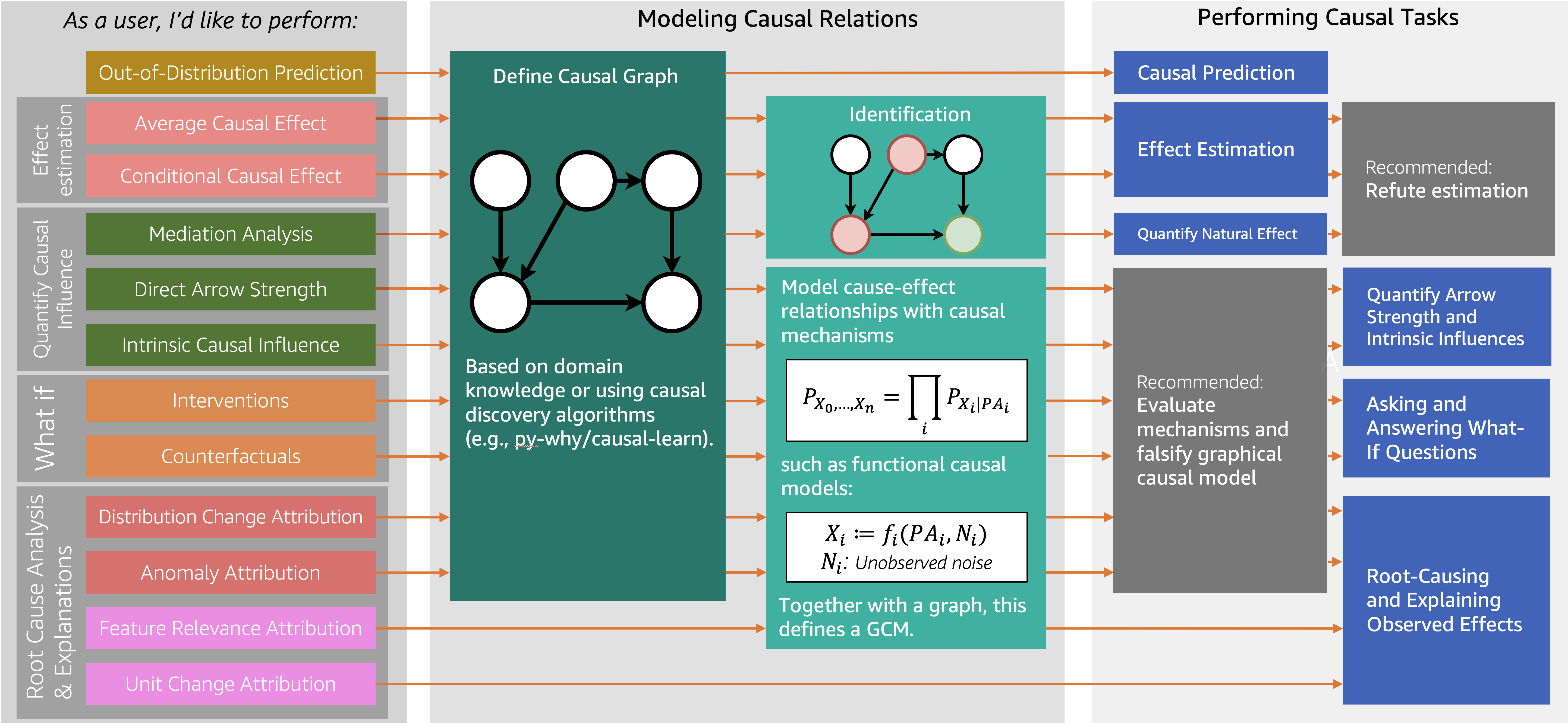
DoWhy supports the following causal tasks:
- Effect estimation (identification, average causal effect, conditional average causal effect, instrumental variables and more)
- Quantify causal influences (mediation analysis, direct arrow strength, intrinsic causal influence)
- What-if analysis (generate samples from interventional distribution, estimate counterfactuals)
- Root cause analysis and explanations (attribute anomalies to their causes, find causes for changes in distributions, estimate feature relevance and more)
For more details and how to use these methods in practice, checkout the documentation at https://py-why.github.io/dowhy
DoWhy support Python 3.8+. To install, you can use pip, poetry, or conda.
Latest Release
Install the latest release using pip.
pip install dowhyInstall the latest release using poetry.
poetry add dowhyInstall the latest release using conda.
conda install -c conda-forge dowhyIf you face "Solving environment" problems with conda, then try conda update --all and then install dowhy. If that does not work, then use conda config --set channel_priority false and try to install again. If the problem persists, please add your issue here.
Development Version
If you prefer to use the latest dev version, your dependency management tool will need to point at our GitHub repository.
pip install git+https://github.com/py-why/dowhy@mainRequirements
DoWhy requires a few dependencies. Details on specific versions can be found in pyproject.toml, under the tool.poetry.dependencies section.
If you face any problems, try installing dependencies manually.
pip install '<dependency-name>==<version>'Optionally, if you wish to input graphs in the dot format, then install pydot (or pygraphviz).
For better-looking graphs, you can optionally install pygraphviz. To proceed, first install graphviz and then pygraphviz (on Ubuntu and Ubuntu WSL).
Note
Installing pygraphviz can cause problems on some platforms. One way that works for most Linux distributions is to first install graphviz and then pygraphviz as shown below. Otherwise, please consult the documentation of pygraphviz.
sudo apt install graphviz libgraphviz-dev graphviz-dev pkg-config
pip install --global-option=build_ext \
--global-option="-I/usr/local/include/graphviz/" \
--global-option="-L/usr/local/lib/graphviz" pygraphvizMost causal tasks in DoWhy only require a few lines of code to write. Here, we exemplarily estimate the causal effect of a treatment on an outcome variable:
from dowhy import CausalModel
import dowhy.datasets
# Load some sample data
data = dowhy.datasets.linear_dataset(
beta=10,
num_common_causes=5,
num_instruments=2,
num_samples=10000,
treatment_is_binary=True)A causal graph can be defined in different way, but the most common way is via NetworkX. After loading in the data, we use the four main operations for effect estimation in DoWhy: model, identify, estimate and refute:
# I. Create a causal model from the data and given graph.
model = CausalModel(
data=data["df"],
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"]) # Or alternatively, as nx.DiGraph
# II. Identify causal effect and return target estimands
identified_estimand = model.identify_effect()
# III. Estimate the target estimand using a statistical method.
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_matching")
# IV. Refute the obtained estimate using multiple robustness checks.
refute_results = model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")DoWhy stresses on the interpretability of its output. At any point in the analysis, you can inspect the untested assumptions, identified estimands (if any), and the estimate (if any). Here's a sample output of the linear regression estimator:
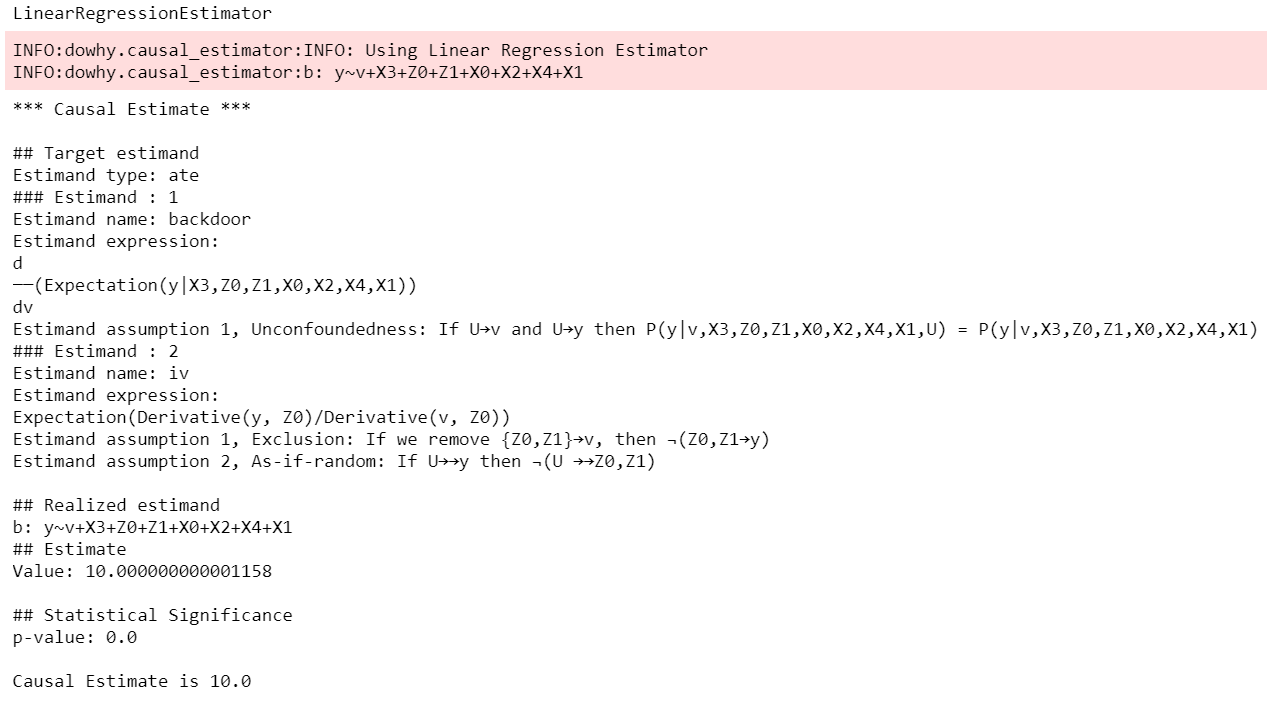
For a full code example, check out the Getting Started with DoWhy notebook.
You can also use Conditional Average Treatment Effect (CATE) estimation methods from EconML, as shown in the Conditional Treatment Effects notebook. Here's a code snippet.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LassoCV
from sklearn.ensemble import GradientBoostingRegressor
dml_estimate = model.estimate_effect(identified_estimand, method_name="backdoor.econml.dml.DML",
control_value = 0,
treatment_value = 1,
target_units = lambda df: df["X0"]>1,
confidence_intervals=False,
method_params={
"init_params":{'model_y':GradientBoostingRegressor(),
'model_t': GradientBoostingRegressor(),
'model_final':LassoCV(),
'featurizer':PolynomialFeatures(degree=1, include_bias=True)},
"fit_params":{}})DoWhy's graphical causal model framework offers powerful tools to address causal questions beyond effect estimation. It is based on Pearl's graphical causal model framework and models the causal data generation process of each variable explicitly via causal mechanisms to support a wide range of causal algorithms. For more details, see the book Elements of Causal Inference.
Complex causal queries, such as attributing observed anomalies to nodes in the system, can be performed with just a few lines of code:
import networkx as nx, numpy as np, pandas as pd
from dowhy import gcm
# Let's generate some "normal" data we assume we're given from our problem domain:
X = np.random.normal(loc=0, scale=1, size=1000)
Y = 2 * X + np.random.normal(loc=0, scale=1, size=1000)
Z = 3 * Y + np.random.normal(loc=0, scale=1, size=1000)
data = pd.DataFrame(dict(X=X, Y=Y, Z=Z))
# 1. Modeling cause-effect relationships as a structural causal model
# (causal graph + functional causal models):
causal_model = gcm.StructuralCausalModel(nx.DiGraph([('X', 'Y'), ('Y', 'Z')])) # X -> Y -> Z
gcm.auto.assign_causal_mechanisms(causal_model, data)
# 2. Fitting the SCM to the data:
gcm.fit(causal_model, data)
# Optional: Evaluate causal model
print(gcm.evaluate_causal_model(causal_model, data))
# Step 3: Perform a causal analysis.
# results = gcm.<causal_query>(causal_model, ...)
# For instance, root cause analysis:
anomalous_sample = pd.DataFrame(dict(X=[0.1], Y=[6.2], Z=[19])) # Here, Y is the root cause.
# "Which node is the root cause of the anomaly in Z?":
anomaly_attribution = gcm.attribute_anomalies(causal_model, "Z", anomalous_sample)
# Or sampling from an interventional distribution. Here, under the intervention do(Y := 2).
samples = gcm.interventional_samples(causal_model, interventions={'Y': lambda y: 2}, num_samples_to_draw=100)The GCM framework offers many more features beyond these examples. For a full code example, check out the Online Shop example notebook.
For more functionalities, example applications of DoWhy and details about the outputs, see the User Guide or checkout Jupyter notebooks.
Microsoft Research Blog | Video Tutorial for Effect Estimation | Video Tutorial for Root Cause Analysis | Arxiv Paper | Arxiv Paper (Graphical Causal Model extension) | Slides
If you find DoWhy useful for your work, please cite both of the following two references:
- Amit Sharma, Emre Kiciman. DoWhy: An End-to-End Library for Causal Inference. 2020. https://arxiv.org/abs/2011.04216
- Patrick Blöbaum, Peter Götz, Kailash Budhathoki, Atalanti A. Mastakouri, Dominik Janzing. DoWhy-GCM: An extension of DoWhy for causal inference in graphical causal models. 2022. https://arxiv.org/abs/2206.06821
Bibtex:
@article{dowhy,
title={DoWhy: An End-to-End Library for Causal Inference},
author={Sharma, Amit and Kiciman, Emre},
journal={arXiv preprint arXiv:2011.04216},
year={2020}
}
@article{dowhy_gcm,
author = {Bl{\"o}baum, Patrick and G{\"o}tz, Peter and Budhathoki, Kailash and Mastakouri, Atalanti A. and Janzing, Dominik},
title = {DoWhy-GCM: An extension of DoWhy for causal inference in graphical causal models},
journal={arXiv preprint arXiv:2206.06821},
year={2022}
}
If you encounter an issue or have a specific request for DoWhy, please raise an issue.
This project welcomes contributions and suggestions. For a guide to contributing and a list of all contributors, check out CONTRIBUTING.md and our docs for contributing code. Our contributor code of conduct is available here.

![allcontributors[bot] avatar](https://avatars.githubusercontent.com/in/23186?v=4 "allcontributors[bot]")










![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")






















































































































































































































