qiskit-community / qiskit-machine-learning Goto Github PK
View Code? Open in Web Editor NEWQuantum Machine Learning
Home Page: https://qiskit-community.github.io/qiskit-machine-learning/
License: Apache License 2.0
Quantum Machine Learning
Home Page: https://qiskit-community.github.io/qiskit-machine-learning/
License: Apache License 2.0
Migrate the currently existing QGAN implementation to the new NN interfaces in Qiskit ML:
Make sure AerPauliExpectation can be used for gradients, QFI, etc
Most test_torch_connector.py tests are wrapped in logic to skip the test if pytorch isn't installed, but not test_batch_gradients(). Thus, tests would be properly skipped for all torch tests, except for test_batch_gradients.
For logic that should be there, ee e.g. https://github.com/Qiskit/qiskit-machine-learning/blob/7824bacf7c3288aa5ab8ca1f9d1ae7177a8e81ee/test/connectors/test_torch_connector.py#L450-L464
Right now QuantumKernel.evaluate() measures all qubits used in the circuit. There should be a way to take advantage of the fix given here if the MPS simulator is used with the option "mps_sample_measure_algorithm": "mps_apply_measure".
In both CircuitQNN and OpflowQNN, if RawFeatureVector is used as feature map, the following warning arises during the network initialization step:
Cannot compute gradient operator! Continuing without gradients!
This behavior was originally pointed out on issue #95, but it was only noted for the case where CircuitStateFn is used, and I initially thought that it was Opflow-related. I have now noticed that this is not a OpflowQNN or CircuitStateFn issue, but a more generalized one. I have tested out different examples using RawFeatureVector and QNNs, and all of them end up triggering this warning, including the code shown in the Creating Your First Machine Learning Programming Experiment in Qiskit section of this repo's ReadMe (not ideal).
I have traced back this warning to the following error message:
raise QiskitError("Cannot define a ParameterizedInitialize with unbound parameters")Binding the parameters looks like a solution to this message, but I am not 100% sure that it is what we want. After all, we want the feature map to be parametrized, and if we bind the parameters, it's not parametrized anymore.
During my investigation I have found some potential bugs in either RawFeatureVector or its base class BlueprintCircuit. I plan to make the corresponding issues in the Terra repo and link them below for reference, but I think that it is helpful to also keep track of the issue on the qiskit-machine-learning side.
Run the following code:
from qiskit import BasicAer
from qiskit.utils import QuantumInstance, algorithm_globals
from qiskit.algorithms.optimizers import COBYLA
from qiskit.circuit.library import TwoLocal
from qiskit_machine_learning.algorithms import VQC
from qiskit_machine_learning.datasets import wine
from qiskit_machine_learning.circuit.library import RawFeatureVector
seed = 1376
algorithm_globals.random_seed = seed
# Use Wine data set for training and test data
feature_dim = 4 # dimension of each data point
training_size = 12
test_size = 4
# training features, training labels, test features, test labels as np.array,
# one hot encoding for labels
training_features, training_labels, test_features, test_labels = \
wine(training_size=training_size, test_size=test_size, n=feature_dim)
feature_map = RawFeatureVector(feature_dimension=feature_dim)
ansatz = TwoLocal(feature_map.num_qubits, ['ry', 'rz'], 'cz', reps=3)
vqc = VQC(feature_map=feature_map,
ansatz=ansatz,
optimizer=COBYLA(maxiter=100),
quantum_instance=QuantumInstance(BasicAer.get_backend('statevector_simulator'),
shots=1024,
seed_simulator=seed,
seed_transpiler=seed)
)
vqc.fit(training_features, training_labels)
score = vqc.score(test_features, test_labels)
print('Testing accuracy: {:0.2f}'.format(score))
I would expect this warning not to appear. Furthermore, if you run the code above, you can see that the testing accuracy is still 100%, despite the warning. This is probably due to the simplicity of the dataset used (I have not found any other explanation at the moment, but haven't extensively tested this one either).
The specific error that triggers this warning is:
raise QiskitError("Cannot define a ParameterizedInitialize with unbound parameters")Doing something like feature_map = feature_map.bind_parameters([bound1, bound2, bound3, bound4]) would prevent this error. However, this line of code does not work as expected (neither does feature_map = feature_map.assign_parameters()), so these should be fixed first.
I would like to use a CircuitQNN as an intermediate layer in a larger neural network, but I would like to treat its output as a dense N-dim vector instead of a binary single output node as presented in the examples. I get the following error:
Traceback (most recent call last):
File "/Users/disipio/development/qrnn-qiskit-ml/./scripts/train_pos.py", line 125, in <module>
loss.backward()
File "/Users/disipio/development/qrnn-qiskit-ml/venv/lib/python3.9/site-packages/torch/tensor.py", line 245, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/Users/disipio/development/qrnn-qiskit-ml/venv/lib/python3.9/site-packages/torch/autograd/__init__.py", line 145, in backward
Variable._execution_engine.run_backward(
RuntimeError: Function _TorchNNFunctionBackward returned an invalid gradient at index 0 - got [16, 16, 4] but expected shape compatible with [5, 4]
feature_map = ZZFeatureMap(n_qubits)
ansatz = RealAmplitudes(n_qubits, reps=1, entanglement='circular', insert_barriers=True)
qc = QuantumCircuit(n_qubits)
qc.append(feature_map, range(n_qubits))
qc.append(ansatz, range(n_qubits))
qi = QuantumInstance(Aer.get_backend("statevector_simulator")
qnn = CircuitQNN(qc,
input_params=feature_map.parameters,
weight_params=ansatz.parameters,
output_shape=2**n_qubits,
quantum_instance=qi)
clayer_in = nn.Linear(input_size, n_qubits)
qlayer = TorchConnector(qnn)
clayer_out = nn.Linear(2**n_qubits, hidden_size)
Setting n_qubits = 4 I have 16 different output states. If I print out the probabilities I see e.g. this:
# print((rows, *self.output_shape), key, b, v, shots)
(5, 16) (0, 0) 0000 0.158663744876569 1.0
(5, 16) (0, 1) 0001 0.101695232492148 1.0
(5, 16) (0, 2) 0010 0.109046751173843 1.0
(5, 16) (0, 3) 0011 0.001107903927808 1.0
(5, 16) (0, 4) 0100 0.065128779080939 1.0
(5, 16) (0, 5) 0101 0.023863282865949 1.0
(5, 16) (0, 6) 0110 0.009466232967798 1.0
(5, 16) (0, 7) 0111 0.007067217702229 1.0
(5, 16) (0, 8) 1000 0.016374389863522 1.0
(5, 16) (0, 9) 1001 0.072207907597972 1.0
(5, 16) (0, 10) 1010 0.124966708373814 1.0
(5, 16) (0, 11) 1011 0.088526459268843 1.0
(5, 16) (0, 12) 1100 0.137411385340253 1.0
(5, 16) (0, 13) 1101 0.013800193450224 1.0
(5, 16) (0, 14) 1110 0.064522821617036 1.0
(5, 16) (0, 15) 1111 0.006150989401053 1.0
probs =
[[1.58663745e-01 1.01695232e-01 1.09046751e-01 1.10790393e-03
6.51287791e-02 2.38632829e-02 9.46623297e-03 7.06721770e-03
1.63743899e-02 7.22079076e-02 1.24966708e-01 8.85264593e-02
1.37411385e-01 1.38001935e-02 6.45228216e-02 6.15098940e-03]
Not sure if the code is correct, but perhaps adding an example to the tutorials would clarify the matter.
In the current implementation of the neural networks it is impossible to track loss and other parameters while a model is being trained. Here, we suggest to introduce a callback that can give access some intermediate training data. This callback may make use of the callback interface of optimizers.
Hello,
i am not being able to import algorithms_globals.
Any suggestions??
For statevector simulations we can use faster classical evaluation schemes for the gradients, as proposed in https://arxiv.org/abs/2009.02823 and https://arxiv.org/abs/2011.02991. These methods are significantly faster than the current ones as they (1) asymptotically scale with one less power (linear for gradients, quadratic for natural gradients) and (2) have much less overhead from constructing circuits and opflow expressions.
The code for these methods is implemented using Qiskit in https://github.com/Cryoris/surfer. The gradient version works for any circuit, but the QFI code doesn't currently support repeated parameters.
Currently NeuralNetworkClassifier and VQC accepts only one hot encoding. Both classifiers should also accept categorical input.
When an optimizer is not passed to neural network classifier/regressor an exception occurs: AttributeError: 'NoneType' object has no attribute 'optimize'. In this issue I suggest to improve this behavior and either raise a more meaningful exception or introduce a default optimizer, e.g. Cobyla or SLSQP.
symengine installedTorchConnector tutorial fails.
A script to reproduce the error:
import numpy as np
import matplotlib.pyplot as plt
from torch import Tensor
from torch.nn import Linear, CrossEntropyLoss, MSELoss
from torch.optim import LBFGS
from qiskit import Aer, QuantumCircuit
from qiskit.utils import QuantumInstance
from qiskit.opflow import AerPauliExpectation
from qiskit.circuit import Parameter
from qiskit.circuit.library import RealAmplitudes, ZZFeatureMap
from qiskit_machine_learning.neural_networks import CircuitQNN, TwoLayerQNN
from qiskit_machine_learning.connectors import TorchConnector
if __name__ == '__main__':
qi = QuantumInstance(Aer.get_backend('statevector_simulator'))
num_inputs = 2
num_samples = 20
X = 2 * np.random.rand(num_samples, num_inputs) - 1
y01 = 1 * (np.sum(X, axis=1) >= 0) # in { 0, 1}
y = 2 * y01 - 1 # in {-1, +1}
X_ = Tensor(X)
y01_ = Tensor(y01).reshape(len(y)).long()
y_ = Tensor(y).reshape(len(y), 1)
for x, y_target in zip(X, y):
if y_target == 1:
plt.plot(x[0], x[1], 'bo')
else:
plt.plot(x[0], x[1], 'go')
plt.plot([-1, 1], [1, -1], '--', color='black')
plt.show()
# set up QNN
qnn1 = TwoLayerQNN(num_qubits=num_inputs, quantum_instance=qi)
# set up PyTorch module
initial_weights = 0.1 * (2 * np.random.rand(qnn1.num_weights) - 1)
model1 = TorchConnector(qnn1, initial_weights=initial_weights)
# test with a single input
r = model1(X_[0, :])
print(r)Fails with:
....
File "...qiskit\circuit\parameterexpression.py", line 114, in bind
bound_symbol_expr = self._symbol_expr.subs(symbol_values)
File "symengine_wrapper.pyx", line 934, in symengine.lib.symengine_wrapper.Basic.subs
File "symengine_wrapper.pyx", line 794, in symengine.lib.symengine_wrapper.get_dict
File "symengine_wrapper.pyx", line 718, in symengine.lib.symengine_wrapper._DictBasic.add
File "symengine_wrapper.pyx", line 529, in symengine.lib.symengine_wrapper.sympify
File "symengine_wrapper.pyx", line 572, in symengine.lib.symengine_wrapper._sympify
File "symengine_wrapper.pyx", line 495, in symengine.lib.symengine_wrapper.sympy2symengine
symengine.lib.symengine_wrapper.SympifyError: sympy2symengine: Cannot convert '0.058050297' (of type <class 'numpy.float32'>) to a symengine type.
The script should run without exceptions.
In the current release loss functions docstring documentation is very scarse. It should be extended and enhanced.
The unit test below occasionally fails as below. This needs to be investigated to figure out why and code corrected as needed to ensure the result is consistent/reproducible.
test.algorithms.classifiers.test_neural_network_classifier.TestNeuralNetworkClassifier.test_classifier_with_circuit_qnn_and_cross_entropy_2___cobyla____qasm__ [7.809451s] ... FAILED
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/algorithms/classifiers/test_neural_network_classifier.py", line 254, in test_classifier_with_circuit_qnn_and_cross_entropy
self.assertGreater(score, 0.5)
File "/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/unittest/case.py", line 1251, in assertGreater
self.fail(self._formatMessage(msg, standardMsg))
File "/opt/hostedtoolcache/Python/3.7.11/x64/lib/python3.7/unittest/case.py", line 693, in fail
raise self.failureException(msg)
AssertionError: 0.4 not greater than 0.5
Exception is raised when an instance of ComposedOp is passed to OpflowQNN:
Measured Observable is not composed of only Paulis, converting to Pauli representation, which can be expensive.
Traceback (most recent call last):
File "...qiskit-machine-learning/_sandbox/shape_bug2.py", line 27, in <module>
qnn.backward(data, weights)
File "...qiskit-machine-learning/qiskit_machine_learning/neural_networks/neural_network.py", line 206, in backward
input_grad, weight_grad = self._backward(input_, weights_)
File "...qiskit-machine-learning/qiskit_machine_learning/neural_networks/opflow_qnn.py", line 199, in _backward
grad_all[row, :] = grad.transpose()
ValueError: could not broadcast input array from shape (2,1) into shape (1,1)
Run the script
import numpy as np
from qiskit import QuantumCircuit
from qiskit.circuit import Parameter
from qiskit.opflow import StateFn, PauliSumOp, ListOp
from qiskit_machine_learning.neural_networks import OpflowQNN
# initialize quantum circuit
qc = QuantumCircuit(1)
param = Parameter("param")
qc.rz(param, 0)
H1 = PauliSumOp.from_list([('Z', 1.0)])
H2 = PauliSumOp.from_list([('Z', 1.0)])
H = ListOp([H1, H2])
op = ~StateFn(H) @ StateFn(qc)
# initialize QNN
qnn = OpflowQNN(op, [], [param])
# create random data and weights for testing
data = np.random.rand(2, qnn.num_inputs)
weights = np.random.rand(qnn.num_weights)
# test backward pass
qnn.backward(data, weights)No exception is raised
The function ad_hoc_data(...) is resulting in the test dataset as an array.
type(test_input)
> numpy.ndarray
This is also evident from the following AttributeError message:
AttributeError Traceback (most recent call last)
<ipython-input-9-f11e4f763266> in <module>
10 n=feature_dim,
11 plot_data=True)
---> 12 datapoints,class_to_label=split_dataset_to_data_and_labels(test_input)
~\anaconda3\lib\site-packages\qiskit\aqua\utils\dataset_helper.py in split_dataset_to_data_and_labels(dataset, class_names)
83 labels = []
84 if class_names is None:
---> 85 sorted_classes_name = sorted(list(dataset.keys()))
86 class_to_label = {k: idx for idx, k in enumerate(sorted_classes_name)}
87 else:
AttributeError: 'numpy.ndarray' object has no attribute 'keys'
Reproduced exactly from Qiskit's tutorials from YouTube.
feature_dim=2
training_dataset_size=20
testing_dataset_size=10
random_seed=10598
shots=10000
sample_Total,training_input,test_input,class_labels = ad_hoc_data(training_size=training_dataset_size,
test_size=testing_dataset_size,
gap=0.3,
n=feature_dim,
plot_data=True)
datapoints,class_to_label=split_dataset_to_data_and_labels(test_input)
ad_hoc_data should be returning a dictionary for the test dataset. As shown in the code, split_dataset_to_data_and_labels(test_input) also expects the test_input to be in dict type
Algorithms normally have any random behavior done via the algorithm globals random generator as a simple central place to set seed to accommodate reproducibility.
QSVC - subclasses sklearn SVC which has random_state param. It might be desirable to pass up the algorithm globals seed to the parent during construction to allow the random state to be set based on the global seed.
And for VQC since it use TrainableModel this would benefit from using algorithm globals for the random initial point computation https://github.com/Qiskit/qiskit-machine-learning/blob/c1df4d545f74fd166ee973868013a66478c07a20/qiskit_machine_learning/algorithms/trainable_model.py#L197
See also https://quantumcomputing.stackexchange.com/questions/18384/ramdon-accuracy-using-vqc-and-iris-dataset where the current behavior was initially brought up.
Now in NeuralNetworkClassifier/Regressor forward pass is computed at least two times, in objective and objective_grad. This should be changed in a way forward pass is computed only once and the results are stored for re-use in the backward pass.
Qiskit Documentation is currently published in 7 languages (including English). The translation effort is driven by a team of volunteer translators. Now that the tutorials are in separate repository, the team would like to start translating the Machine learning translations which can benefit the community especially during the upcoming Qiskit Summer School, as well is of importance to several of Qiskit's internal teams.
In the current implementation there are a few TODOs left in the code that mention batch support. These places should be reviewed and batch support should be enabled.
The parameter quantum_instance in the CircuitQNN and OpflowQNN may have value of None. In such cases there should be additional checks:
if statements to be sure code runs smoothly when no quantum instance is passes and it is not required at this moment.QiskitMachineLearning exception.As a feedback from #44, we should add a parameter input_gradients to NeuralNetwork to expose it explicitly to users. By default it should be turned off. Also, we should not turn on input gradients explicitly in TorchConnector every time, turning on/off gradients is up a user via this new parameter.
upon calling the iris() function from datasets module, the size of the testinput is always a single data point. This is because the test_size parameter for the train_test_split() function in used has been hardcoded to 1 instead of the parameter test_size of the iris() function
from qiskit.ml.datasets import iris
datapoints, training_input, test_input, class_labels=iris(120,30,4)
print(test_input)
clearly gives a single element in the test_input. This can also be replicated by using any other value for test_size
We get a test_input of the given size
I believe this is an easy fix changing the test_size attribute in the train_test_split() function within datasets.iris
This message occurs when using RawFeatureVector with CircuitStateFn
Cannot compute gradient operator! Continuing without gradients!
from qiskit import QuantumCircuit
from qiskit.opflow import StateFn, PauliSumOp, AerPauliExpectation, Gradient
from qiskit.utils import QuantumInstance
from qiskit_machine_learning.neural_networks import OpflowQNN
from qiskit_machine_learning.circuit.library import RawFeatureVector
expval = AerPauliExpectation()
gradient = Gradient()
qi_sv = QuantumInstance(Aer.get_backend('statevector_simulator'))
inputs = RawFeatureVector(16)
qc = QuantumCircuit(4)
qc.append(inputs,range(4))
qc_sfn = StateFn(qc)
H1 = StateFn(PauliSumOp.from_list([('Z', 1.0)]))
op = ~H1 @ qc_sfn
qnn4 = OpflowQNN(operator = op, input_params = inputs.parameter, weight_params = [], exp_val = expval, gradient = gradient, quantum_instance = qi_sv)Can pass the Parameter or ParameterVector to OpflowQNN or another Opflow from qiskit_machine_learning.neural_networks
Check the Gradient condition on qiskit.opflow
There is an indentation error on line 166 of the torch connector.
For now identified tasks/issues:
forward pass only once and store the results. Re-use the results of forward in backward.NeuralNetworkClassifier and NeuralNetworkRegressorCurrently TorchConnector does not handle batches correctly. This should be improved.
In skimming over the changes that black did I noticed the strings 'l1' and 'l2'. Normally for names lower case l is avoided as it can be mistaken for capital I and even for numeric 1 depending on font. I think it would be preferable to have these as uppercase L, since the docstring even talks about L2 loss where L is in capitals. This is in code like NetworkNeuralClassifier/Regressor among others. And where we test the value, if we choose to accept lower case for compatibility, then maybe do an upper() so it can be compared to 'L2' etc.
Parameters in Terra QuantumCIrcuit are now ordered. N-Local was updated to remove ordered_parameters as its no longer needed. This library circuit should be updated in a consistent manner (no need to deprecate here though, just remove, since this repo/pkg is new)
NLocal change as reference Qiskit/qiskit#5949 (also see Qiskit/qiskit#5759)
We have been working on an implementation of a quantum autoencoder as part of the Qiskit Hackathon Europe: Research Study Groups. The quantum autoencoder is based on these two papers:
I would be happy to adapt our work so that it could be merged into the qiskit code base, if there is interest in having it included.
I am sorry that this isn’t a proper “feature request” but I wasn’t sure where to ask.
If a CircuitQNN is used with a TorchConnector, the result PyTorch model have some issues calculating the gradients of the parameters in the circuit, when the model is evaluated on a batch of data, and not a single sample.
Here is an example to reproduce the problem. I use the same circuitry defined in the tutorial (https://github.com/Qiskit/qiskit-machine-learning/blob/master/docs/tutorials/05_torch_connector.ipynb), using CircuitQNN and the TorchConnector to create a quantum neural network. I try to evaluate the gradients of the parameters on a regression task with a trivial dataset, consisting of 20 identical inputs and corresponding targets.
As a loss function, I consider the MSELoss with reduction=sum, and I try to evaluate the loss and its gradients in different ways:
MSELoss on the full dataset (consisting of 20 identical item)(output-target).pow(2).sum() again on the whole datasetThen, the gradients are evaluated using the loss.backward() and extracted with model.weights.grad.
Note that there is no optimizer step! I only evaluated the gradients without updating the weights.
All these methods should be fully equivalent, since the data are always the same, and there is no seed, ordering, or strange twists. Note that while Methods 1, 2 and 3 use the full dataset of 20 samples, Method 4 uses only a single item, so its gradient is expected to be 20 times smaller (since we are using MSELoss(reduction="sum")).
### Imports
import numpy as np
import matplotlib.pyplot as plt
from torch import Tensor
import torch
from torch.nn import MSELoss
from torch.optim import SGD
from qiskit import Aer, QuantumCircuit
from qiskit.utils import QuantumInstance
from qiskit.opflow import AerPauliExpectation
from qiskit.circuit import Parameter
from qiskit.circuit.library import RealAmplitudes, ZZFeatureMap
from qiskit_machine_learning.neural_networks import CircuitQNN, TwoLayerQNN
from qiskit_machine_learning.connectors import TorchConnector
qi = QuantumInstance(Aer.get_backend('statevector_simulator'))
### Create QNN
num_inputs = 2
feature_map = ZZFeatureMap(num_inputs)
ansatz = RealAmplitudes(num_inputs, entanglement='linear', reps=1)
qc = QuantumCircuit(num_inputs)
qc.append(feature_map, range(num_inputs))
qc.append(ansatz, range(num_inputs))
parity = lambda x: '{:b}'.format(x).count('1') % 2
output_shape = 2 # parity = 0, 1
qnn2 = CircuitQNN(qc, input_params=feature_map.parameters, weight_params=ansatz.parameters,
interpret=parity, output_shape=output_shape, quantum_instance=qi)
# set up PyTorch module
initial_weights = np.array([0.1]*qnn2.num_weights)
model2 = TorchConnector(qnn2, initial_weights)
### Trivial dataset
X = Tensor(np.stack(([0.5, 0.5],)*20))
y = Tensor(np.stack(([-0.5, -0.5],)*20))
### Define optimizer and loss
optimizer = SGD(model2.parameters(), lr = 0.1)
f_loss = MSELoss(reduction = "sum")
### Method 1
output1 = model2(X)
loss1 = (output1-y).pow(2).sum()
optimizer.zero_grad()
loss1.backward()
print("Loss:", loss1) # ->
print("Gradients:", model2.weights.grad)
# Loss: tensor(40.0025, grad_fn=<SumBackward0>)
# Gradients: tensor([1.1921e-07, 1.9073e-06, 2.3842e-07, 1.1921e-07])
### Method 2
output2 = model2(X)
loss2 = f_loss(output2, y)
optimizer.zero_grad()
loss2.backward()
print("Loss:", loss2)
print("Gradients:", model2.weights.grad)
# Loss: tensor(40.0025, grad_fn=<MseLossBackward>)
# Gradients: tensor([1.1921e-07, 1.9073e-06, 2.3842e-07, 1.1921e-07])
### Method 3
loss3 = 0.0
for xt, yt in zip(X,y):
output3 = model2(xt)
loss3 += f_loss(output3, yt)
optimizer.zero_grad()
loss3.backward()
print("Loss:", loss3)
print("Gradients:", model2.weights.grad)
# Loss: tensor(40.0025, grad_fn=<AddBackward0>)
# Gradients: tensor([-0.0311, 0.3078, 0.0567, -0.0312])
### Method 4
output4 = model2(X[0])
loss4 = f_loss(output4, y[0])
optimizer.zero_grad()
loss4.backward()
print("Loss:", loss4)
print("Gradients:", model2.weights.grad)
# Loss: tensor(2.0001, grad_fn=<MseLossBackward>)
# Gradients: tensor([-0.0016, 0.0154, 0.0028, -0.0016])
The gradients should be all equals. In particular, evaluating the loss using a batch of data (Methods 1 and 2) yields vanishing gradients.
Note that if one substitutes the quantum model created through Qiskit, with a simple model2 = torch.nn.Linear(2,2) then the gradients are correctly equals, so the problem is somewhere in the Qiskit's Machine Learning module.
(to run the code above with the classical linea layer, also substitute model2.weights.grad with model2.weight.grad).
Since we are going to introduce categorical labels (and perhaps categorical features), I think, we can re-consider type hints for the classifiers and regressors and make them more like in Scikit-Learn: array_like. This may allow to pass plain lists or other types. As an example take a look at the interface here: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
This issue is just for discussion.
Currently we use sparse for multidimensional sparse arrays/tensors. This library depends on numba which, in turns, has compiled code with support/wheels for various machines but not all of them, e.g. if someone has been using a Raspberry Pi 4 and llvmlite, which is installed as part of numba, and its not supported there and QML fails to install. This issue propose to make sparse as an optional dependency with the default value of sparse=False. If someone wanted to use sparse=True QML would raise an exception saying it needed to be installed, rather than QML failing to get installed at all.
Failed to try the example of the first Machine Learning Programming Experiment in Qiskit:
Cannot compute gradient operator! Continuing without gradients!
Run without issue
TestTorchConnector fails intermittently with exceptions like here:
test.connectors.test_torch_connector.TestTorchConnector.test_circuit_qnn_1_8_4
------------------------------------------------------------------------------
Captured traceback:
~~~~~~~~~~~~~~~~~~~
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.9.5/x64/lib/python3.9/site-packages/ddt.py", line 182, in wrapper
return func(self, *args, **kwargs)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/machine_learning_test_case.py", line 49, in wrapper
test_item(self, *args)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/connectors/test_torch_connector.py", line 365, in test_circuit_qnn_1_8
self.validate_output_shape(model, test_data)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/connectors/test_torch_connector.py", line 107, in validate_output_shape
self.assertEqual(c_worked, q_worked)
File "/opt/hostedtoolcache/Python/3.9.5/x64/lib/python3.9/unittest/case.py", line 831, in assertEqual
assertion_func(first, second, msg=msg)
File "/opt/hostedtoolcache/Python/3.9.5/x64/lib/python3.9/unittest/case.py", line 824, in _baseAssertEqual
raise self.failureException(msg)
AssertionError: True != False
test.connectors.test_torch_connector.TestTorchConnector.test_circuit_qnn_1_1_1__None__None__False___sv__
--------------------------------------------------------------------------------------------------------
Captured traceback:
~~~~~~~~~~~~~~~~~~~
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/site-packages/ddt.py", line 182, in wrapper
return func(self, *args, **kwargs)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/machine_learning_test_case.py", line 49, in wrapper
test_item(self, *args)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/connectors/test_torch_connector.py", line 309, in test_circuit_qnn_1_1
self.validate_output_shape(model, test_data)
File "/home/runner/work/qiskit-machine-learning/qiskit-machine-learning/test/connectors/test_torch_connector.py", line 107, in validate_output_shape
self.assertEqual(c_worked, q_worked)
File "/opt/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/unittest/case.py", line 852, in assertEqual
assertion_func(first, second, msg=msg)
File "/opt/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/unittest/case.py", line 845, in _baseAssertEqual
raise self.failureException(msg)
AssertionError: True != False
Run the test several times. There are no specific conditions observed.
The test should pass every time.
There are minor improvements to do:
algorithms/init
NNC/NNR/VQR are missing in docstring
datasets
Return np.ndarrays, optionally one-hot encoded (remove all functions not used)
neural_networks/init
OpflowQNN missing in docstring
loss_functions
Should we rename the file loss.py to loss_functions.py?
Should we include the actual loss functions in the init.py to make them importable directly, e.g. "from qml.utils.lossfunctions import CrossEntropyLoss"? (currently there is only the copyright header in the loss_functions init)
Are we using L2LossProbability or should we remove it? Or is it tested somewhere?
We should extend the docstrings of the loss functions a little bit to include what exactly they are computing.
Did we test the KLDiv somewhere (it doesn't have a gradient implemented)?
Do we need softmax/stable_softmax, doesn't seem to be used anywhere, maybe remove?
The Search Function of Qiskit Machine Learning is not working.
Just go to this https://qiskit.org/documentation/machine-learning/ and type anything you want to search.
It will not work as expected.
I think search function have some sort of bug internally and needs to be fixed ASAP
In the backward propagation this code checks input_grad and if not None under certain a condition sets it to None
later in the same method it makes this call
which fails inside Torch einsum util with a complaint about NoneType (which seems to be about input_grad being None)
Similar logic is in the weight_grad part too.
I will note that the above logic path, where input_grad is set to None, is not covered by unit tests and so this failure does not arise there.
I was trying to apply "Phase shift rule" for gradient calculation in quantum GAN using the tutorial :
https://qiskit.org/documentation/tutorials/machine_learning/04_qgans_for_loading_random_distributions.html.
To do so, I replaced the line :
qgan.set_generator(generator_circuit=g_circuit, generator_init_params=init_params)by
qgan.set_generator(generator_circuit=g_circuit, generator_init_params=init_params, generator_gradient = Gradient())with qiskit.aqua.operators.gradients.Gradient.
However, while running
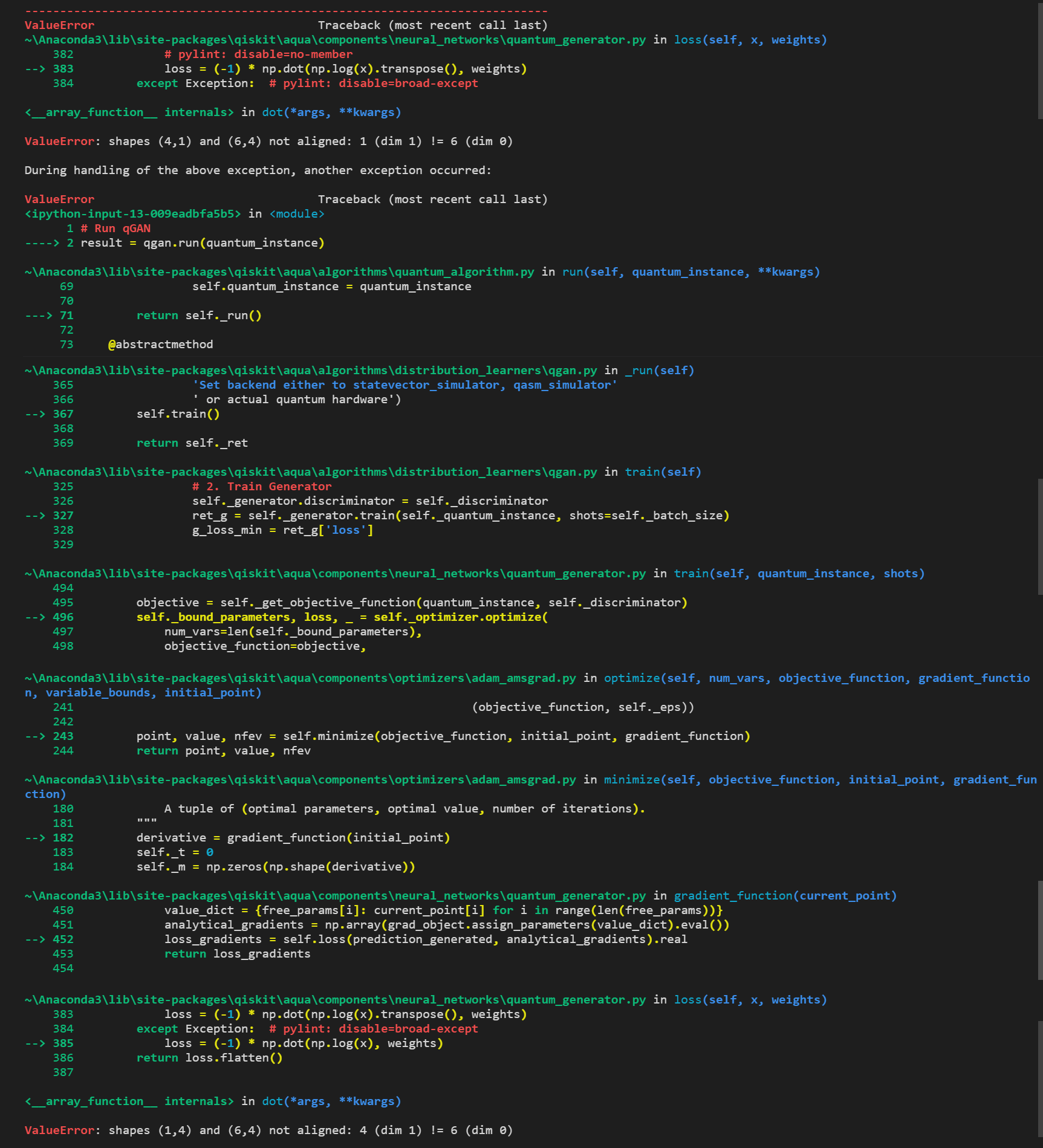
result = qgan.run(quantum_instance)with reps = 2 (2 blocks in the quantum generator), the code shows me an error message below :
ValueError Traceback (most recent call last)
~\Anaconda3\lib\site-packages\qiskit\aqua\components\neural_networks\quantum_generator.py in loss(self, x, weights)
382 # pylint: disable=no-member
--> 383 loss = (-1) * np.dot(np.log(x).transpose(), weights)
384 except Exception: # pylint: disable=broad-except
<__array_function__ internals> in dot(*args, **kwargs)
ValueError: shapes (4,1) and (6,4) not aligned: 1 (dim 1) != 6 (dim 0)Please also find the full error message below
 .
.
Please also find the code here.
In the tutorial 04_qgans_for_loading_random_distributions.ipynb,
from qiskit.opflow import Gradientqgan.set_generator(generator_circuit=g_circuit, generator_init_params=init_params)by
qgan.set_generator(generator_circuit=g_circuit, generator_init_params=init_params, generator_gradient = Gradient())`var_form = TwoLocal(int(np.sum(num_qubits)), 'ry', 'cz', entanglement=entangler_map, reps=1)by
var_form = TwoLocal(int(np.sum(num_qubits)), 'ry', 'cz', entanglement=entangler_map, reps=2)Add two more values for init_params (array of size 6)
Run the quantum GAN.
By the chain rule, the gradient of the generator is calculated as :
.
(c.f. Appendix B in Supplementary Information: Quantum Generative Adversarial Networks
for Learning and Loading Random Distributions)
As we are summing over , the matrix multiplication performed in
loss_gradients = self.loss(prediction_generated, analytical_gradients).real(line 411 in quantum_machine_learning.algorithms.distribution_learners.qgan.quantum_generator)
should take the form :
where
,
However,
analytical_gradients = np.array(grad_object.assign_parameters(value_dict).eval())in
def _convert_to_gradient_function(self, gradient_object, quantum_instance, discriminator)currently returns:
(line 410 in quantum_machine_learning.algorithms.distribution_learners.qgan.quantum_generator)
,
so the code returns an error for matrix multiplication.
I think the analytical gradients should be transposed :
analytical_gradients = np.array(grad_object.assign_parameters(value_dict).eval())to
analytical_gradients = np.transpose(np.array(grad_object.assign_parameters(value_dict).eval()))Compute gradient w.r.t. input data only when it is required. Now all gradients are computed at every time.
Statevector simulator is deprecated now and use of this simulator generates a lot of deprecation warnings in the unit tests. This simulator must be replaced with a new version.
I'm running a script, based on the tutorial for distribution learning with qGAN's.
I have two variants of the script, grounded on the two different implementations of the qGAN discriminator, namely the NumPyDiscriminator and the PyTorchDiscriminator.
The two variants should provide the same results, as they both run the amsgrad optimizer, but I get significantly different worse results with NumPyDiscriminator. This suggests a bug in the NumPyDiscriminator implementation or in the ADAM class of qiskit.
I attach a simple script to run a single instance of the problem with either one or the other discriminator. Runtime is around 7-8min on my computer. testqGAN_bug.py.zip
To make the results more directly comparable, I made the following modifications to the standard qiskit classes:
512 with 50 and 256 with 20 to match the same architecture as in rows 52-56 of script numpy_discriminator.0.self._optimizer = optim.Adam(self._discriminator.parameters(), lr=1e-3, betas = (.7, .99), eps=1e-6, amsgrad=True), to match parameters at row 226 of numpy_discriminator.The script provided in the attachment should give similar results both if run with qgan.set_discriminator(discriminator1) or qgan.set_discriminator(discriminator2) (small differences in different runs are possible, due to randomness in the algorithms).
None at the moment.
Should the NeuralNetwork algorithms should support passing an initial_point for the weights?
It seems that right now this is technically possible by setting warm_start to true and setting the private _fit_result property, but that's rather hacky 🙂
Provide way to extract train and test kernel matrices after the QSVC is fit/predicted, without having to invoke evaluate - since that doubles the run time needed:
qsvc = QSVC(quantum_kernel=qkernel)
qsvc.fit(sample_train,label_train)
qsvc.predict(sample_test)
train_kernel = qsvc.get_train_kernel() # returns train x train kernel matrix
test_kernel = qsvc.get_test_kernel() # returns test x train kernel matrix
spvec = qsvc.get_support_vectors(). # return actual support vectors
Recently, the tests in TestQuantumKernelConstructCircuit were broken, a quick fix (PR: #148) showed that these tests construct circuits and validate the number of gates in the circuits. Since the way how complex gates are represented in circuits has been changed (PR: Qiskit/qiskit#6634) these tests became less valueable. This goal of this issue is to analyze these tests and come up with a decision what to do with them. There are a few options: remove the tests, rewrite it in a way to make them better, or restructure them completely, e.g. test circtuits slightly differently.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.