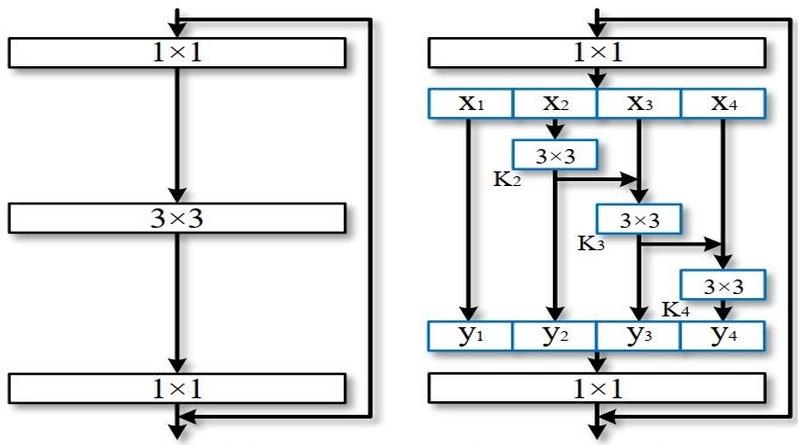
I tried to implement Res2NeXt-29, 8cx25wx4s by pytorch but could only got classification accuracy 82.32% instead of 83.07% reported in this paper on the CIFAR-100. This error was resulted by randomly initializing parameters of network?
And the detail of architecture is as below. It's correct?
CifarRes2NeXt(
(conv_1_3x3): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn_1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(stage_1): Sequential(
(stage_1_bottleneck_0): ResNeXtBottleneck(
(conv_reduce): Conv2d(64, 800, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(800, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(stage_1_bottleneck_1): ResNeXtBottleneck(
(conv_reduce): Conv2d(64, 800, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(800, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(stage_1_bottleneck_2): ResNeXtBottleneck(
(conv_reduce): Conv2d(64, 800, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(800, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(stage_2): Sequential(
(stage_2_bottleneck_0): ResNeXtBottleneck(
(conv_reduce): Conv2d(64, 1600, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(1600, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): AvgPool2d(kernel_size=3, stride=2, padding=1)
(convs): ModuleList(
(0): Conv2d(400, 400, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(400, 400, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(400, 400, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(1600, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(shortcut_conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(shortcut_bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stage_2_bottleneck_1): ResNeXtBottleneck(
(conv_reduce): Conv2d(128, 1600, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(1600, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(1600, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(stage_2_bottleneck_2): ResNeXtBottleneck(
(conv_reduce): Conv2d(128, 1600, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(1600, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(400, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(1600, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(stage_3): Sequential(
(stage_3_bottleneck_0): ResNeXtBottleneck(
(conv_reduce): Conv2d(128, 3200, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(3200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): AvgPool2d(kernel_size=3, stride=2, padding=1)
(convs): ModuleList(
(0): Conv2d(800, 800, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(800, 800, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(800, 800, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(3200, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(shortcut_conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(shortcut_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stage_3_bottleneck_1): ResNeXtBottleneck(
(conv_reduce): Conv2d(256, 3200, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(3200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(3200, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(stage_3_bottleneck_2): ResNeXtBottleneck(
(conv_reduce): Conv2d(256, 3200, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_reduce): BatchNorm2d(3200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(convs): ModuleList(
(0): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(2): Conv2d(800, 800, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
)
(bns): ModuleList(
(0): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_expand): Conv2d(3200, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn_expand): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(classifier): Linear(in_features=256, out_features=100, bias=True)
)