![]()




Contextual AI adds explainability to different stages of machine learning pipelines - data, training, and inference - thereby addressing the trust gap between such ML systems and their users.
Contextual AI has been tested with Python 3.6, 3.7, and 3.8. You can install it using pip:
$ pip install contextual-ai
$ sh build.sh
$ pip install dist/*.whl
In this simple example, we will attempt to generate explanations for some ML model trained on 20newsgroups, a text classification dataset. In particular, we want to find out which words were important for a particular prediction.
from pprint import pprint
from sklearn import datasets
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
# Main Contextual AI imports
import xai
from xai.explainer import ExplainerFactory
# Train on a subset of the 20newsgroups dataset (text classification)
categories = [
'rec.sport.baseball',
'soc.religion.christian',
'sci.med'
]
# Fetch and preprocess data
raw_train = datasets.fetch_20newsgroups(subset='train', categories=categories)
raw_test = datasets.fetch_20newsgroups(subset='test', categories=categories)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(raw_train.data)
y_train = raw_train.target
X_test = vectorizer.transform(raw_test.data)
y_test = raw_test.target
# Train a model
clf = MultinomialNB(alpha=0.1)
clf.fit(X_train, y_train)
############################
# Main Contextual AI steps #
############################
# Instantiate the text explainer via the ExplainerFactory interface
explainer = ExplainerFactory.get_explainer(domain=xai.DOMAIN.TEXT)
# Build the explainer
def predict_fn(instance):
vec = vectorizer.transform(instance)
return clf.predict_proba(vec)
explainer.build_explainer(predict_fn)
# Generate explanations
exp = explainer.explain_instance(
labels=[0, 1, 2], # which classes to produce explanations for?
instance=raw_test.data[9],
num_features=5 # how many words to show?
)
print('Label', raw_train.target_names[raw_test.target[9]], '=>', raw_test.target[9])
pprint(exp)From: [email protected] (Stephen A. Creps)\nSubject: Re: The doctrine of Original Sin\nOrganization: Indiana University\nLines: 63\n\nIn article <[email protected]> [email protected] writes:\n>>If babies are not supposed to be baptised then why doesn\'t the Bible\n>>ever say so. It never comes right and says "Only people that know\n>>right from wrong or who are taught can be baptised."\n>\n>This is not a very sound argument for baptising babies
...
Label soc.religion.christian => 2
{0: {'confidence': 6.79821e-05,
'explanation': [{'feature': 'Bible', 'score': -0.0023500809763485468},
{'feature': 'Scripture', 'score': -0.0014344577715211986},
{'feature': 'Heaven', 'score': -0.001381196356886895},
{'feature': 'Sin', 'score': -0.0013723724408794883},
{'feature': 'specific', 'score': -0.0013611914394935848}]},
1: {'confidence': 0.00044,
'explanation': [{'feature': 'Bible', 'score': -0.007407412195931125},
{'feature': 'Scripture', 'score': -0.003658367757678809},
{'feature': 'Heaven', 'score': -0.003652181996607397},
{'feature': 'immoral', 'score': -0.003469502264458387},
{'feature': 'Sin', 'score': -0.003246609821338066}]},
2: {'confidence': 0.99948,
'explanation': [{'feature': 'Bible', 'score': 0.009736539971486623},
{'feature': 'Scripture', 'score': 0.005124375636024145},
{'feature': 'Heaven', 'score': 0.005053514624616295},
{'feature': 'immoral', 'score': 0.004781252244149238},
{'feature': 'Sin', 'score': 0.004596128058053568}]}}
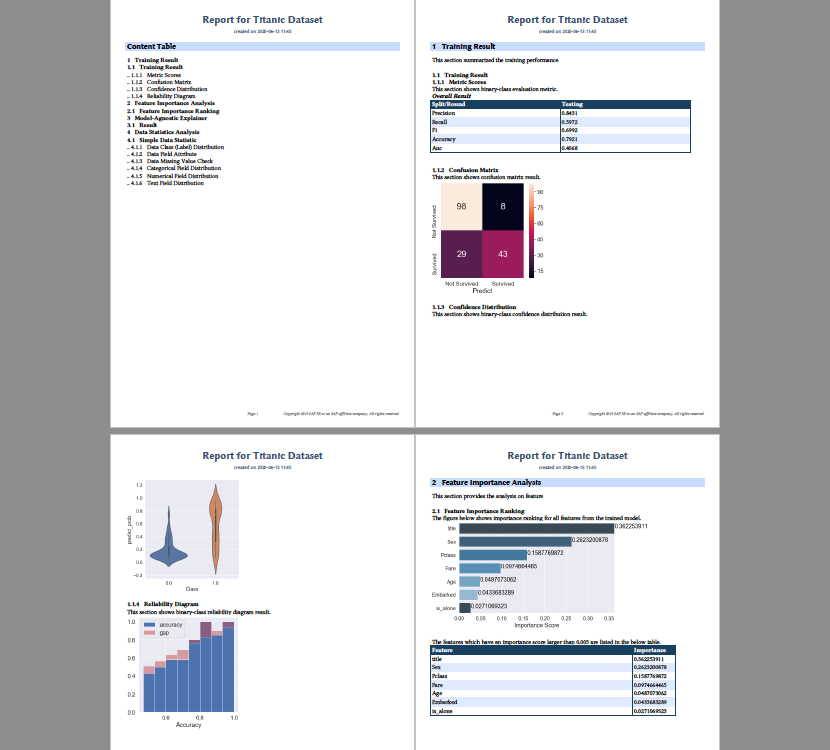
Another functionality of contextual-ai is the ability to generate PDF reports that compile the results of data analysis, model training, feature importance, error analysis, and more. Here's a simple example where we provide an explainability report for the Titanic dataset. The full tutorial can be found here.
import os
import sys
from pprint import pprint
from xai.compiler.base import Configuration, Controller
json_config = 'basic-report-explainer.json'
controller = Controller(config=Configuration(json_config))
pprint(controller.config)The Controller is responsible for ingesting the configuration file basic-report-explainer.json and parsing the specifications of the report. The configuration file looks like this:
{'content_table': True,
'contents': [{'desc': 'This section summarized the training performance',
'sections': [{'component': {'attr': {'labels_file': 'labels.json',
'y_pred_file': 'y_conf.csv',
'y_true_file': 'y_true.csv'},
'class': 'ClassificationEvaluationResult',
'module': 'compiler',
'package': 'xai'},
'title': 'Training Result'}],
'title': 'Training Result'},
{'desc': 'This section provides the analysis on feature',
'sections': [{'component': {'_comment': 'refer to document '
'section xxxx',
'attr': {'train_data': 'train_data.csv',
'trained_model': 'model.pkl'},
'class': 'FeatureImportanceRanking'},
'title': 'Feature Importance Ranking'}],
'title': 'Feature Importance Analysis'},
{'desc': 'This section provides a model-agnostic explainer',
'sections': [{'component': {'attr': {'domain': 'tabular',
'feature_meta': 'feature_meta.json',
'method': 'lime',
'num_features': 5,
'predict_func': 'func.pkl',
'train_data': 'train_data.csv'},
'class': 'ModelAgnosticExplainer',
'module': 'compiler',
'package': 'xai'},
'title': 'Result'}],
'title': 'Model-Agnostic Explainer'},
{'desc': 'This section provides the analysis on data',
'sections': [{'component': {'_comment': 'refer to document '
'section xxxx',
'attr': {'data': 'titanic.csv',
'label': 'Survived'},
'class': 'DataStatisticsAnalysis'},
'title': 'Simple Data Statistic'}],
'title': 'Data Statistics Analysis'}],
'name': 'Report for Titanic Dataset',
'overview': True,
'writers': [{'attr': {'name': 'titanic-basic-report'}, 'class': 'Pdf'}]}
The Controller also triggers the rendering of the report:
controller.render()Which produces this PDF report which visualizes data distributions, training results, feature importances, local prediction explanations, and more!
Contextual AI spans three pillars, or scopes, of explainability, each addressing a different stage of a machine learning solution's lifecycle. We provide several features and functionalities for each:
- Distributional analysis of data and features
- Data validation
- Tutorial
- Training performance
- Feature importance
- Per-class explanations
- Simple error analysis
- Tutorial
- Explanations per prediction instance
- Tutorial
We currently support the following explainers for each data type:
Tabular:
Text:
Looking to integrate your own explainer into contextual AI? Look at the following documentation to see how you can use our AbstractExplainer class to create your own explainer that satisfies our interface!
- Produce PDF/HTML reports of outputs from the above using only a few lines of code
- Tutorial
We welcome contributions of all kinds!
- Reporting bugs
- Requesting features
- Creatin pull requests
- Providing discussions/feedback
Please refer to CONTRIBUTING.md for more.
- Sean Saito
- Wang Jin
- Chai Wei Tah
- Ni Peng
- Amrit Raj
- Karthik Muthuswamy
Copyright 2020-2021 SAP SE or an SAP affiliate company and contextual-ai contributors. Please see our LICENSE for copyright and license information. Detailed information including third-party components and their licensing/copyright information is available via the REUSE tool.

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























































































