This repository is the official implementation of Tune-A-Video.
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Jay Zhangjie Wu,
Yixiao Ge,
Xintao Wang,
Stan Weixian Lei,
Yuchao Gu,
Yufei Shi,
Wynne Hsu,
Ying Shan,
Xiaohu Qie,
Mike Zheng Shou
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
🚨 Announcing LOVEU-TGVE: A CVPR competition for AI-based video editing! Submissions due Jun 5. Don't miss out! 🤩
- [02/22/2023] Improved consistency using DDIM inversion.
- [02/08/2023] Colab demo released!
- [02/03/2023] Pre-trained Tune-A-Video models are available on Hugging Face Library!
- [01/28/2023] New Feature: tune a video on personalized DreamBooth models.
- [01/28/2023] Code released!
pip install -r requirements.txtInstalling xformers is highly recommended for more efficiency and speed on GPUs.
To enable xformers, set enable_xformers_memory_efficient_attention=True (default).
[Stable Diffusion] Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input. The pre-trained Stable Diffusion models can be downloaded from Hugging Face (e.g., Stable Diffusion v1-4, v2-1). You can also use fine-tuned Stable Diffusion models trained on different styles (e.g, Modern Disney, Anything V4.0, Redshift, etc.).
[DreamBooth] DreamBooth is a method to personalize text-to-image models like Stable Diffusion given just a few images (3~5 images) of a subject. Tuning a video on DreamBooth models allows personalized text-to-video generation of a specific subject. There are some public DreamBooth models available on Hugging Face (e.g., mr-potato-head). You can also train your own DreamBooth model following this training example.
To fine-tune the text-to-image diffusion models for text-to-video generation, run this command:
accelerate launch train_tuneavideo.py --config="configs/man-skiing.yaml"Note: Tuning a 24-frame video usually takes 300~500 steps, about 10~15 minutes using one A100 GPU.
Reduce n_sample_frames if your GPU memory is limited.
Once the training is done, run inference:
from tuneavideo.pipelines.pipeline_tuneavideo import TuneAVideoPipeline
from tuneavideo.models.unet import UNet3DConditionModel
from tuneavideo.util import save_videos_grid
import torch
pretrained_model_path = "./checkpoints/stable-diffusion-v1-4"
my_model_path = "./outputs/man-skiing"
unet = UNet3DConditionModel.from_pretrained(my_model_path, subfolder='unet', torch_dtype=torch.float16).to('cuda')
pipe = TuneAVideoPipeline.from_pretrained(pretrained_model_path, unet=unet, torch_dtype=torch.float16).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_vae_slicing()
prompt = "spider man is skiing"
ddim_inv_latent = torch.load(f"{my_model_path}/inv_latents/ddim_latent-500.pt").to(torch.float16)
video = pipe(prompt, latents=ddim_inv_latent, video_length=24, height=512, width=512, num_inference_steps=50, guidance_scale=12.5).videos
save_videos_grid(video, f"./{prompt}.gif")| Input Video | Output Video | ||
 |
 |
 |
 |
| "A man is skiing" | "Spider Man is skiing on the beach, cartoon style” | "Wonder Woman, wearing a cowboy hat, is skiing" | "A man, wearing pink clothes, is skiing at sunset" |
 |
 |
 |
 |
| "A rabbit is eating a watermelon on the table" | "A rabbit is |
"A cat with sunglasses is eating a watermelon on the beach" | "A puppy is eating a cheeseburger on the table, comic style" |
 |
 |
 |
 |
| "A jeep car is moving on the road" | "A Porsche car is moving on the beach" | "A car is moving on the road, cartoon style" | "A car is moving on the snow" |
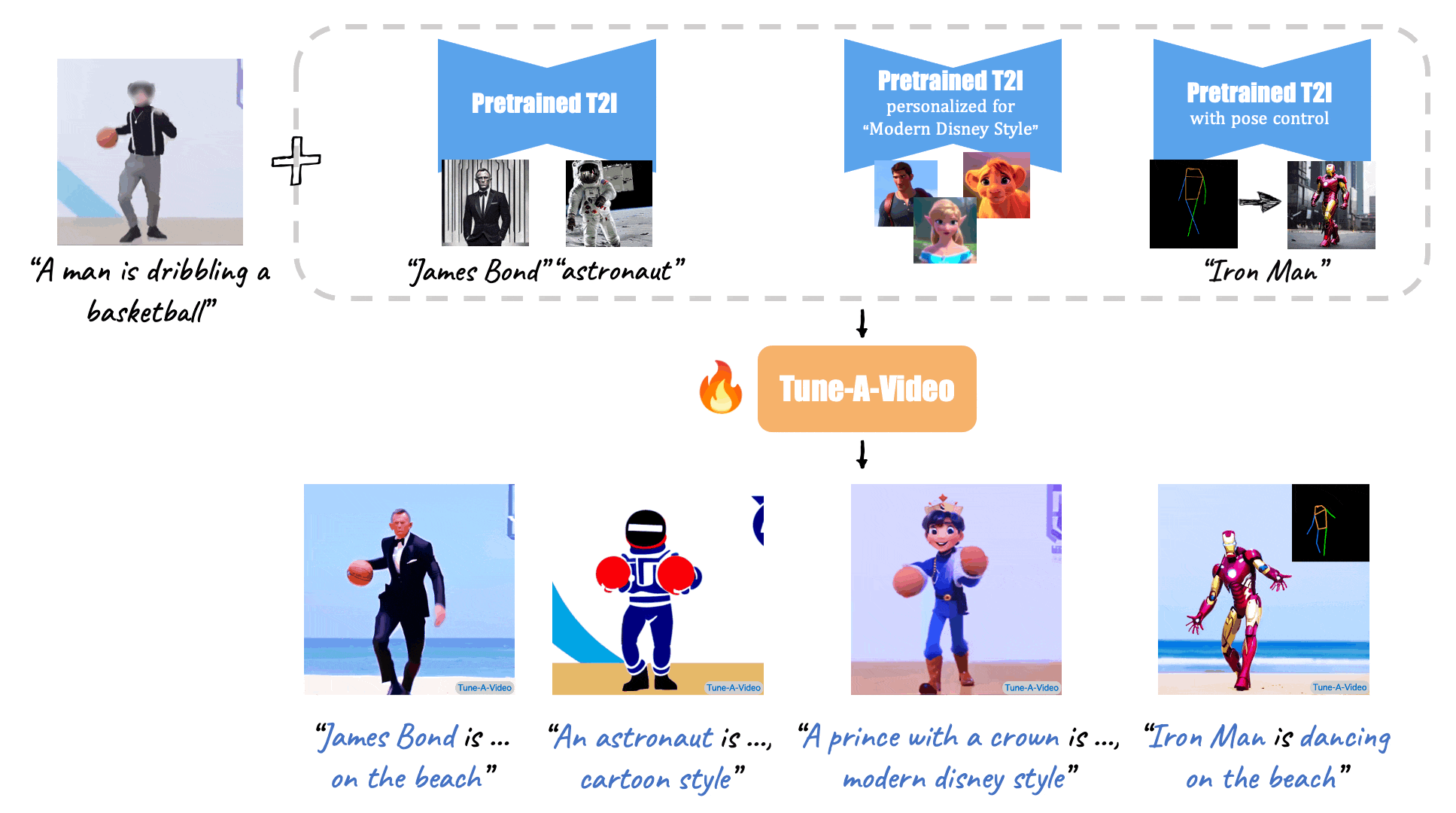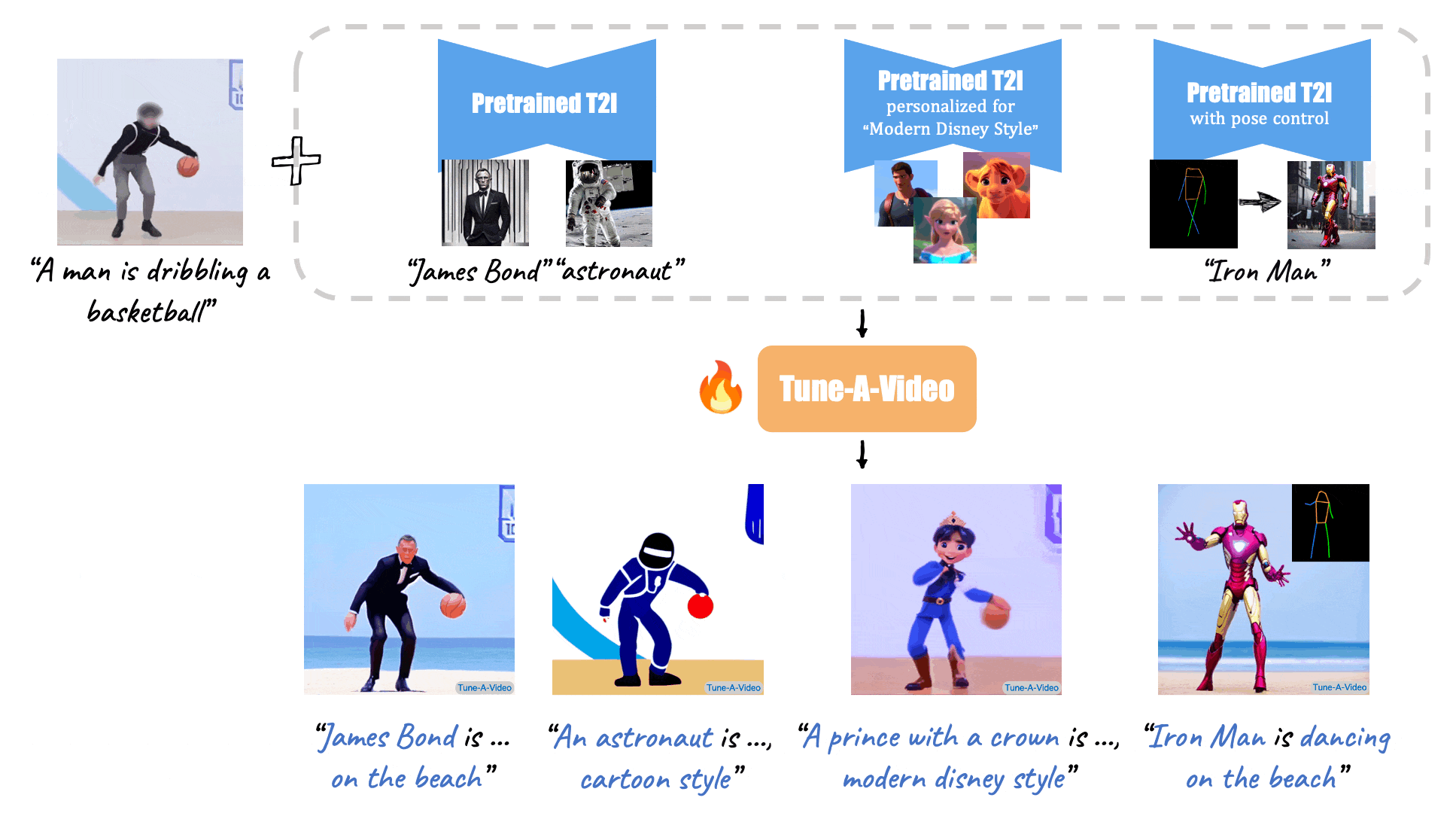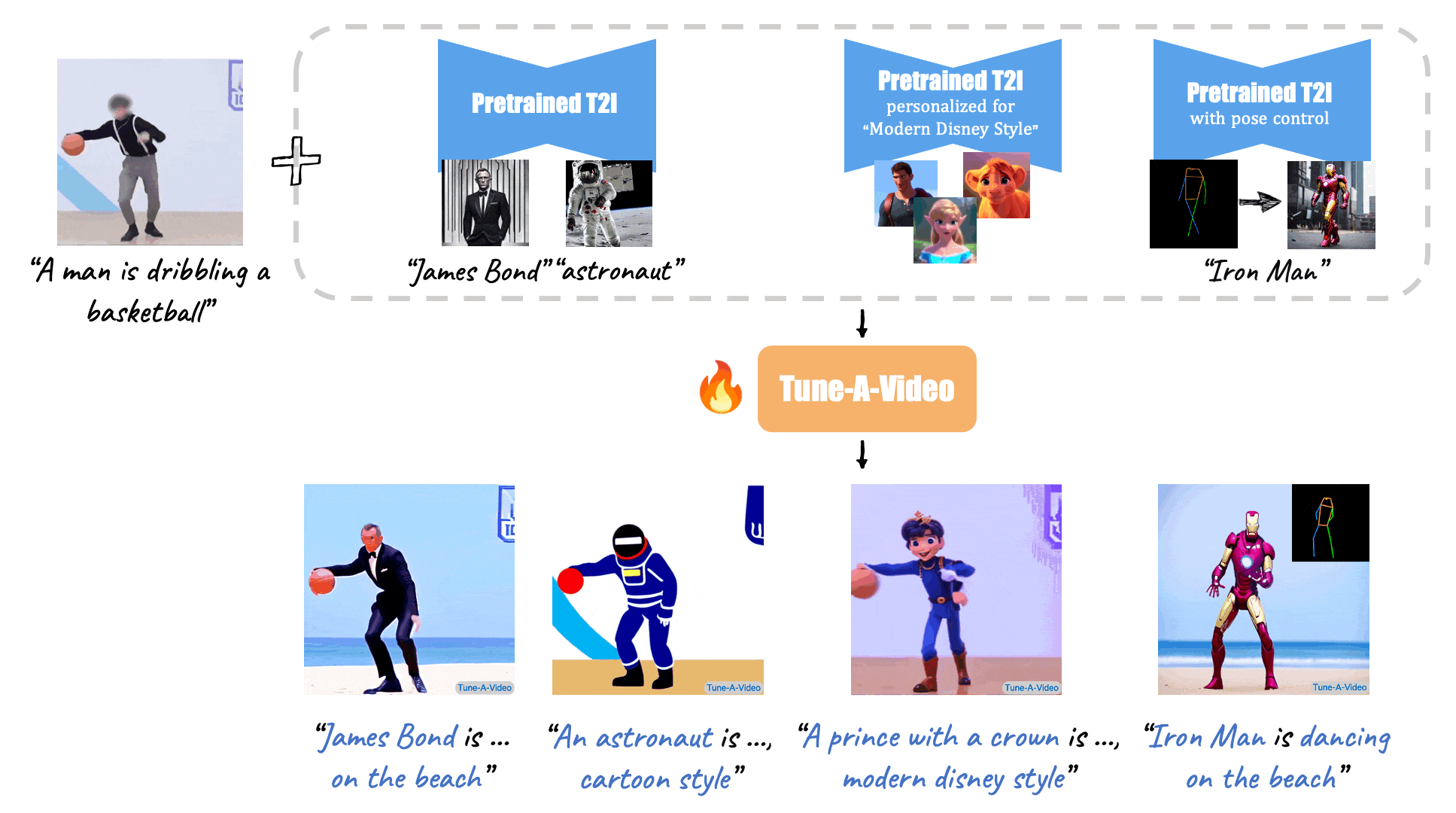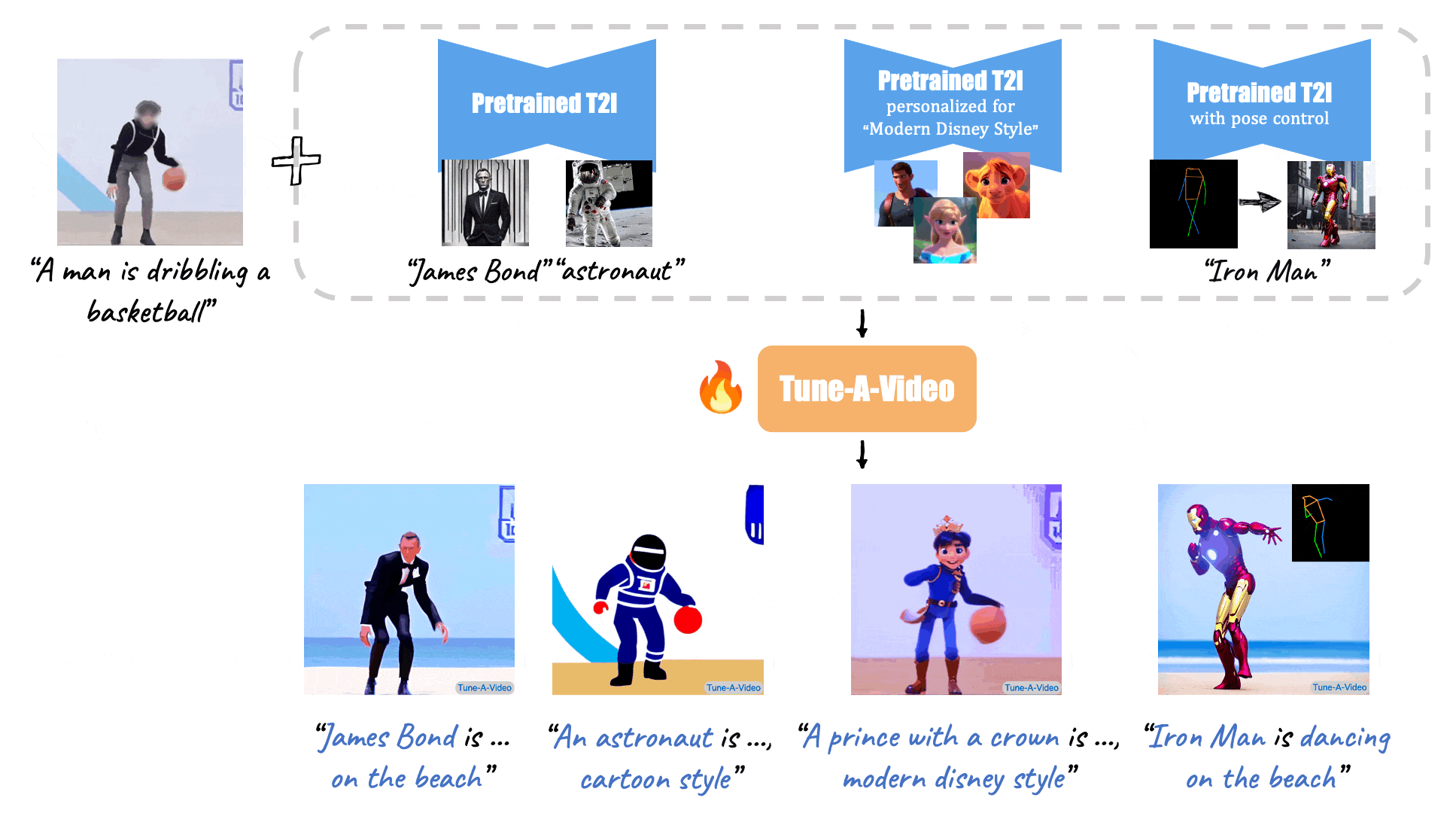
 |
 |
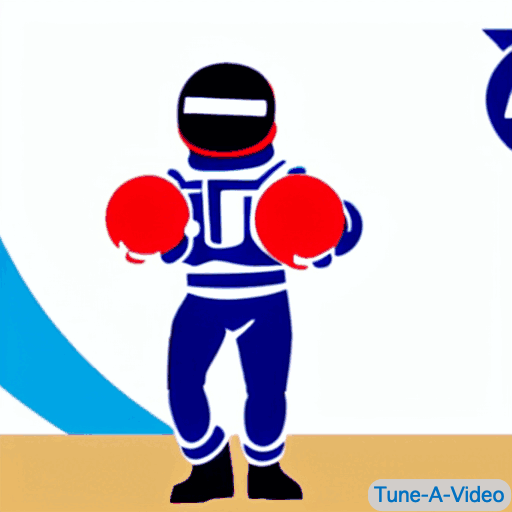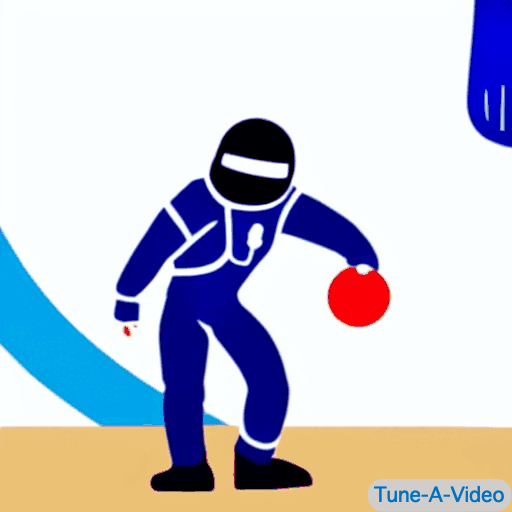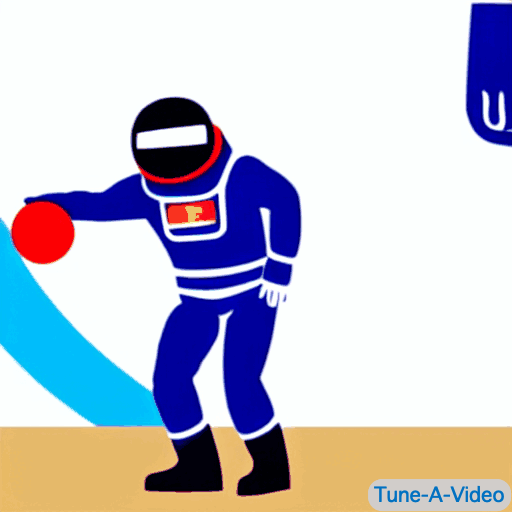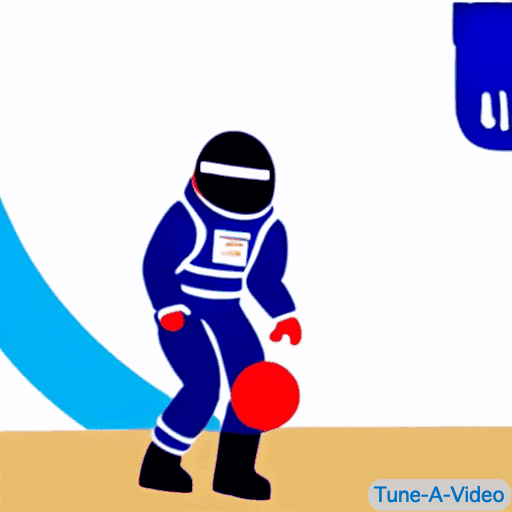 |
 |
| "A man is dribbling a basketball" | "James Bond is dribbling a basketball on the beach" | "An astronaut is dribbling a basketball, cartoon style" | "A lego man in a black suit is dribbling a basketball" |

| Input Video | Output Video | ||
 |
 |
 |
 |
| "A bear is playing guitar" | "1girl is playing guitar, white hair, medium hair, cat ears, closed eyes, cute, scarf, jacket, outdoors, streets" | "1boy is playing guitar, bishounen, casual, indoors, sitting, coffee shop, bokeh" | "1girl is playing guitar, red hair, long hair, beautiful eyes, looking at viewer, cute, dress, beach, sea" |

| Input Video | Output Video | ||
|
 |
 |
 |
| "A bear is playing guitar" | "A rabbit is playing guitar, modern disney style" | "A handsome prince is playing guitar, modern disney style" | "A magic princess with sunglasses is playing guitar on the stage, modern disney style" |

| Input Video | Output Video | ||
|
 |
 |
 |
| "A bear is playing guitar" | "Mr Potato Head, made of lego, is playing guitar on the snow" | "Mr Potato Head, wearing sunglasses, is playing guitar on the beach" | "Mr Potato Head is playing guitar in the starry night, Van Gogh style" |
If you make use of our work, please cite our paper.
@inproceedings{wu2023tune,
title={Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation},
author={Wu, Jay Zhangjie and Ge, Yixiao and Wang, Xintao and Lei, Stan Weixian and Gu, Yuchao and Shi, Yufei and Hsu, Wynne and Shan, Ying and Qie, Xiaohu and Shou, Mike Zheng},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7623--7633},
year={2023}
}- This code builds on diffusers. Thanks for open-sourcing!
- Thanks hysts for the awesome gradio demo.
































































































































































