snowleopard / alga Goto Github PK
View Code? Open in Web Editor NEWAlgebraic graphs
License: MIT License
Algebraic graphs
License: MIT License
The idea is to decouple the graph creation functions from the actual graph creation. In code:
data SubGraph a = Vertex a
| Clique [a]
| Biclique [a]
| ...
clique :: [a] -> Graph (SubGraph a)
clique = vertex . Clique
expand :: Graph (SubGraph a) -> Graph a
expand (Clique as) = -- current clique implementationThis should have the same performance characteristics as the current implementation, since it is just laziness made explicit. It is also very similar to the Cached data type in #19. There could be the following benefits:
Graph data type could be made strict. I am not sure if it is a good idea, but it would be possible without too much of a performance hit.A reason not to do it is that it is so far unclear, which algorithms actually benefit from such a structure. Since the SubGraph is not necessarily a module, it is not clear whether a algorithm could take advantage of it.
Ultimately the usefulness of this proposal depends a lot on the subgraphs and algorithms. Do you have some ideas @snowleopard? I have so far experimented with Hanoi and Turan graphs, but I have not found anything useful.
I can make a PR for this is well.
It would be great to support GHC >= 7.6 (7.4 would need older containers-0.4)
Then I could ask people to add dependency on alga.
with https://github.com/hvr/multi-ghc-travis it would be easy to test them all on Travis (even OSX, if you really insist, though for alga it's IMHO waste of scarse OSX travis resources)
It was a good example: https://blogs.ncl.ac.uk/andreymokhov/graphs-in-disguise/
We should adapt it to the current implementation of the library and bring back to the repository, for example, as Algebra.Graph.Example.Todo.
Faucelme notes on reddit that modifying a single vertex by mapping over the whole graph is inefficient.
Indeed, the current implementation of replaceVertex function is quite primitive and is based on fmap:
https://github.com/snowleopard/alga/blob/master/src/Algebra/Graph/HigherKinded/Class.hs#L541-L542
While it may be difficult to optimise replaceVertex for general graphs, I think for the AdjacencyMap representation we can do better, e.g. in O(n log(n)) where n is the number of graph vertices.
Can we do even better?
Hi,
Awesome project you have! I have one very minor comment to make.
I noticed that you're using your own setProduct function:
alga/src/Algebra/Graph/Relation/Internal.hs
Line 173 in 76d01ae
cartesianProduct function recently added to containers (Since: containers-0.5.11)! And luckily you're on a stackage lts version which already has it:Hi,
I did not found a better title, but here is the idea.
Reading the Algebra.Graph code, I found there was some functions using foldg with the same two last arguments.
For example:
While searching for improvements, I thought that there was actually a duplication of information:
Overlay and Connect both kinda join two graphs.
So I came to
data Graph a = Empty
| Vertex a
| Cons Op (Graph a) (Graph a)
deriving (Foldable, Functor, Show, Traversable)
data Op = Overlay | Connect deriving (Show)(Once again I am bad for names)
You only have to change
overlay = Cons Overlay
connect = Cons Connectand then replace every occurrence of the constructor by these counterpart.
It allows to define:
foldg' :: b -> (a -> b) -> (b -> b -> b) -> Graph a -> b
foldg' e v o = go
where
go Empty = e
go (Vertex x ) = v x
go (Cons _ x y) = o (go x) (go y) Which is faster than foldg (hasVertex is about 1.40 times faster for example using hasEdge = foldg' False (==x) (||))
Uses can no more play with constructors, at least not simply.
Foldg become a bit less efficient. I had to redefine induce:
induce :: (a -> Bool) -> Graph a -> Graph a
induce p = go
where
go (Cons o x y) = case go x of
Empty -> go y
x' -> case go y of
Empty -> x'
y' -> Cons o x' y'
go (Vertex x) = if p x then Vertex x else Empty
go Empty = EmptyremoveVertex is 1.2 times better in the actual library than with this change, but hasEdge become faster of 2 times. I don't now yet why.
There is I think more Cons than Pros, but it can worth some investigation
I can make the PR if adding dependency is ok
Should it be Graph t => ToGraph t, then you can ditch the associated type family on ToGraph reusing the parent one.
Hi,
I have a dumb question. At first I thought that a SymmetricRelation being a Graph and a Graph being a Functor I just can map a function over it. I was wrong as the Graph was the the class not the data type.
Any advice on an efficient way on how to do this?
Thanks!
Hello,
This is a followup to a question I asked on Twitter. I'm working on some code to calculate "betweenness centrality", with a view to applying it to streetmap graphs. I'm not sure if Alga is an appropriate choice for this task, but maybe my query will sort this out. I'm at the design stage.
To clarify what I'm talking about, there is a concise expression of the formula for betweenness centrality in the Wikipedia page. https://en.wikipedia.org/wiki/Betweenness_centrality
The end product is a graph with a floating point value associated with each vertex. I guess my key question is whether you envisage providing Alga with something like the unionsWith function from Data.Map. I'm imagining it would be called something like overlayWith and the supplied function would be used in a revised mergeVertex function to combine the values associated with the two vertices.
As far as I can see Alga doesn't seem to currently provide any tools for dealing with graphs with a value associated to each vertex, i.e. "labels". If it were to do so I assume that Data.Map would be one possible model for the interface. But I don't know if this is practical, or in any way on your roadmap.
I'm impressed by the elegance of your monoidal "overlay" approach to combining graphs, so I'd like to use it, with or without Alga. It solves the problem of folding all the routes together in the betweenness centrality calculation (represent each route as a graph, then overlay the whole lot while summing values at each vertex).
(As mentioned on Twitter, comonads might also come into this, but I'm not sure that they are really necessary. As the calculation involves a summation over shortest paths between every pair of vertices (resulting in an updated copy of the original graph) it seems like it could fit the comonad model. That's maybe not relevant to this Alga query, though graph algorithms expressed with comonads seems to be a fresh topic.)
There have been multiple discussions about making Graph higher-kinded, so I decided to create a separate issue for this -- let's discuss higher-kinded graphs here.
The key idea is:
class Monad g => Graph g where
empty :: g a
overlay :: g a -> g a -> g a
connect :: g a -> g a -> g a
vertex :: Graph g => a -> g a
vertex = pureThis is very nice from many points of view: we know that any graph is a monad, this leads to better type signatures, we can reuse fmap and do-notation, etc.
However, there is a big drawback: we lose non-fully-parametric instances, such as Relation, IntAdjacencyMap, and many others.
We could potentially have both versions in the library, with Algebra.Graph.HigherKinded dedicated to higher-kinded version of the Graph type class. I've already implemented this, see the commit below.
I can't decide whether we need to make Data.Graph an instance of Foldable or not.
On the one hand, just by deriving Foldable we get useful methods like toList, length, elem, which have a sensible behaviour on Data.Graph expressions.
On the other hand, methods like foldMap and fold are quite confusing, because we'd like to define graph folds differently.
For example, here is a generalised graph fold foldg:
foldg :: b -> (a -> b) -> (b -> b -> b) -> (b -> b -> b) -> Graph a -> b
foldg e v o c = go
where
go Empty = e
go (Vertex x) = v x
go (Overlay x y) = o (go x) (go y)
go (Connect x y) = c (go x) (go y)It's very useful, because we can implement a lot of functions using it:
g >>= f = foldg Empty f Overlay Connect g
toList = foldg [] return (++) (++)
size = foldg 0 (const 1) (+) (+)
isEmpty = foldg True (const False) (&&) (&&)We also have fold which is currently defined as:
fold :: Class.Graph g => Graph (Vertex g) -> g
fold = foldg empty vertex overlay connectNote that fold could probably be renamed to fromGraph, as suggested in #5.
What do you think: shall we derive Foldable? If yes, do we also derive Traversable?
Hi,
I have been working on a different implementation of Algebra.Graph, based on Algebra.Graph.NonEmpty.
The idea is to have:
newtype Graph a = G (Maybe (NonEmptyGraph a))Using patterns, with:
pattern Empty :: Graph a
pattern Empty = G Nothing
pattern Vertex :: a -> Graph a
pattern Vertex a = G (Just (N.Vertex a))
pattern Overlay :: NonEmptyGraph a -> NonEmptyGraph a -> Graph a
pattern Overlay a b = G (Just (N.Overlay a b))
pattern Connect :: NonEmptyGraph a -> NonEmptyGraph a -> Graph a
pattern Connect a b = G (Just (N.Connect a b))One can reproduce the traditional Algebra.Graph interface.
This big change can be summarized with some functions:
overlay :: Graph a -> Graph a -> Graph a
overlay l@(G a) r@(G b) = maybe r (\x -> maybe l (Overlay x) b) aWe now check the neutrality of empty directly into the overlay and connect functions.
edges :: [(a, a)] -> Graph a
edges = G . fmap N.edges1 . NL.nonEmptyedges become more complicated and slower.
foldg :: b -> (a -> b) -> (b -> b -> b) -> (b -> b -> b) -> Graph a -> b
foldg e v o c (G g) = maybe e (N.foldg1 v o c) gfoldg is directly based on foldg1 (and this is the case for others functions, when possible).
removeEdge :: Eq a => a -> a -> Graph a -> Graph a
removeEdge s t (G g) = G $ N.removeEdge s t <$> gfmap allow a pretty syntax when a function will act as the identity on the empty graph.
Overlay or Connect that the two graphs are both non-empty.Empty constructor, foldg1 is faster than foldg. Thus, inspection functions are faster.induce because we have to wrap the intermediate results into the Maybe monad.Using the pretty little script I made (on my own computer with graph with 1000 vertices):
isEmpty: 0.63 (good)
vertexList: 0.98 (OK)
vertexCount: 1.01 (OK)
hasVertex: 0.85 (good)
edgeCount: 0.91 (OK)
edgeList: 0.74 (good)
hasEdge: 0.45 (good)
addEdge: 1.22 (bad)
addVertex: 1.06 (OK)
removeVertex: 1.25 (bad)
equality: 1.01 (OK)
removeEdge: 1.00 (OK)
transpose: 0.84 (good)
creation: 1.29 (bad)
So for example addEdge was so fast, that there is drop here when we pattern match to see if it the previous gaph was empty or not.
(Note that I have sneaked the improvement on hasEdge of #88 (but it is even better here)).
The benchmarked code is here: https://github.com/nobrakal/alga/blob/MaybeNonEmpty/src/Algebra/Graph.hs
As suspected by @ndmitchell, the current implementation of removeEdge is not linear w.r.t. the size of the resulting expression. An example where the result explodes by the factor of 10 found by QuickCheck:
g = clique [2,2,0,1,0,0,2,1,2,1,0,1,2,0,2,0,0,0,0,2,1,1,0,2,2,0,2,0,0,2,1,2,0
,2,0,1,1,2,0,0,0,1,2,1,0,1,1,2,2,0,2,2,2,1,0,0,1,2,0,1,0,0,2,0,2]
> size g
66
> size (removeEdge 0 1 g)
681Although this example is contrived (it's just a fully connected graph on vertices {0,1,2} with a lot of redundancy), it still demonstrates the problem.
This is what remains to be done after the merge of #107
The objective is to use rewrite rules to optimize transpose . star and remove the need of something like a starTranspose function.
This is already made for all modules except Algebra.Graph.Relation for which the actual solution seems not to be working.
Ideally transpose . stars will optimized away. This is already the case for Algebra.Graph and Algebra.Graph.NonEmpty.
The following set of rules is used for now:
{-# RULES
"transpose/Empty" transpose Empty = Empty
"transpose/Vertex" forall x. transpose (Vertex x) = Vertex x
"transpose/Overlay" forall g1 g2. transpose (Overlay g1 g2) = Overlay (transpose g1) (transpose g2)
"transpose/Connect" forall g1 g2. transpose (Connect g1 g2) = Connect (transpose g2) (transpose g1)
"transpose/overlays" forall xs. transpose (overlays xs) = overlays (map transpose xs)
"transpose/connects" forall xs. transpose (connects xs) = connects (reverse (map transpose xs))
"transpose/vertices" forall xs. transpose (vertices xs) = vertices xs
"transpose/clique" forall xs. transpose (clique xs) = clique (reverse xs)
#-}
Note that the transpose/vertices and transpose/clique should ideally not be needed, since they are built using overlays and connects.
Sadly, the rules used in #103 seems to prevent the transpose/overlays to fire correctly in star once vertices gets inlined.
While writing my benchmark experiment I noticed that no graph implementation but data Graph has a NFData instance. Is there a reason for this?
Adding them would for example provide a way to fully evaluate a Relation a without relying on equality with itself. The biggest design decision here seems to be the question of whether to evalute the graphKL field on AdjacencyMap a. On the one hand the docs clearly state that rnf should "fully evaluate all sub-components", but then the field is only meant to be cached for some computations that might not be needed. What do you think @snowleopard @nobrakal?
Related: #14
Hey,
Awesome work with this project, really interesting stuff. I had done lots of graph theory stuff in the past and am thinking about getting back into it. I'm looking to potentially build some stuff on top of alga and was wondering if you have any plans on publishing it soon?
On a related note it does look like there's already an alga on Hackage: https://hackage.haskell.org/package/alga
Thanks!
Hi,
I just passed by:
-- TODO: Here if @context (==s) g == Just ctx@ then we know for sure that
-- @induce1 (/=s) g == Just subgraph@. Can we exploit this?
filterContext :: Eq a => a -> (a -> Bool) -> (a -> Bool) -> NonEmptyGraph a -> NonEmptyGraph a
filterContext s i o g = maybe g go $ G.context (==s) (T.toGraph g)(Here: https://github.com/snowleopard/alga/blob/master/src/Algebra/Graph/NonEmpty.hs#L628 )
So I tried and tests failed (one could have guessed it) with removeEdge 0 0 $ edge 0 0 .
In fact:
>>> isJust $ context (==0) $ edge 0 0
True
>>> induce1 (/= 0 ) $ edge 0 0
Nothing
His this true for non loop edges ?
@phadej makes a very good observation in #24: Alga currently does not provide any support for type-safe handling of non-empty graphs.
I also wanted NonEmptyGraph a few times. Many graph transformations become much simpler when graph expressions cannot contain the Empty leaf. (And conversely, many graph transformations become simpler when Empty leafs are allowed, so general graphs are also useful -- we need both.)
The algebraic data type for non-empty graphs is straightforward:
data NonEmptyGraph a = Vertex a
| Overlay (NonEmptyGraph a) (NonEmptyGraph a)
| Connect (NonEmptyGraph a) (NonEmptyGraph a)However, there are a couple of design questions that need to be answered:
Algebra.Graph.NonEmpty. This will lead to quite a bit of code/docs/tests duplication, but I don't see a better way. Incidentally, this is what happens with the standard Data.List.NonEmpty, which has quite a bit of overlap with Data.List.class Graph g, we'll then add class NonEmptyGraph g that will be the superclass of class Graph g.Relation, AdjacencyMap, etc.? Do we need their non-empty versions? I think the answer is No, but I'm not sure.Thoughts?
UPDATE: We moved benchmarks to a separate repository to keep this package lightweight and fast to build, see some comments below.
Current benchmarks are a mess: https://github.com/snowleopard/alga/blob/master/doc/benchmarks.md
At the moment we have type class Graph and data type called Basic that is its direct deep embedding (I also sometimes refer to it as Expr). However, it would be really nice to call the data type Graph too, to add it to Tree, Forest and the rest of the family of nice algebraic data types.
So, I propose the following:
The data type Graph lives in Algebra.Graph.Data: Of course we need to convince GHC to add it to See #5 (comment).containers, but it's really very lightweight.
data Graph a = Empty | Vertex a | Overlay (Graph a) | Connect (Graph a) deriving ShowThe type class Graph lives in Algebra.Graph. It also defines the instance Graph Data.Graph.
Presumably, if I'm implementing cool algorithms on the data type Graph, I don't care about Algebra.Graph and don't need to include it.
Alternatively, if I'm coding polymorphic functions, I don't need Algebra.Graph.Data and don't include it.
So, even though having the same name for the type class and data type sounds potentially confusing, they would probably rarely get mixed in the same file, and so can happily live in separate modules.
Having them in different modules also allows you to always be specific through qualified imports, like Data.Graph and Class.Graph, which seems nicer than inventing names like IGraph or GraphLike or what not for the type class.
Hi there, I'm the author of a particular package manager written in Haskell. About 6 months ago you offered your help for when I reached the stage of evaluating algebraic-graphs. I'm there now, so hi!
Here's the general problem I'm looking to solve:
Packages on a Linux system have dependencies, and these dependency relationships form a graph. I'd like to implement the function:
-- | A `Package` contains a list of other `Package` names (Text) it depends on,
-- which is a good starting point for a real Graph.
sortPackages :: [Package] -> [[Package]]the return value of which corresponds to the following:
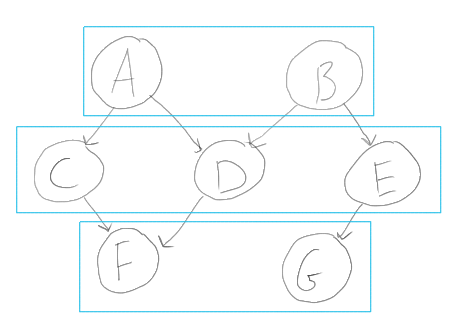
Each cyan box of packages are sibling-like and "safe" to build and install at the same time, since they aren't interdependent. For this example, I'd expect the output of sortPackages to resemble:
[ [F, G], [C, D, E], [A, B] ]Looking at your API, I suspect these functions are probably what I'm looking for. In the current version of my code, I'm using topSort from Data.Graph to naively get the overall safe ordering, then building one-at-a-time since topSort loses other "elevation information".
Can algebraic-graphs help me here?
Please and thanks,
Colin
It would be great to have a table (say, in the doc folder) comparing different graph instances in terms of provided functionality (e.g., does it have removeVertex?) and performance (e.g. how fast is removeVertex?).
Here are the current graph instances: Graph, AdjacencyMap, IntAdjacencyMap, Fold, Relation.
Hi,
This is just for the record:
I saw: https://github.com/snowleopard/alga/blob/master/src/Algebra/Graph.hs#L449 :
-- TODO: Benchmark to see if this implementation is faster than the default
-- implementation provided by the ToGraph type class.
So here is the benchmarks:
Alga use the the ToGraph definition, AlgaOld is the current implementation:
Description: Test if the given edge is in the graph (with arguments both in the graph and not in the graph (where applicable))
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 30.38 ns | 783.9 ns | 11.84 μs | 270.4 μs |
| AlgaOld | 385.7 ns | 2.330 μs | 19.89 μs | 219.1 μs |
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 30.28 ns | 2.733 μs | 1.758 ms | 870.8 ms |
| AlgaOld | 384.7 ns | 6.709 μs | 588.7 μs | 94.03 ms |
SUMMARY:
ABSTRACT:
(Based on an average of the ratio between largest benchmarks)
As the ToGraph option is faster on small graphs, I tried a combination of the two:
hasEdge :: Ord a => a -> a -> Graph a -> Bool
hasEdge s t = (\g -> case foldg e v o c g of (_, _, r) -> r) . induce (`elem` [s, t])
where
e = (False , False , False )
v x = (x == s , x == t , False )
o (xs, xt, xst) (ys, yt, yst) = (xs || ys, xt || yt, xst || yst)
c (xs, xt, xst) (ys, yt, yst) = (xs || ys, xt || yt, xs && yt || xst || yst)Which sadly is not better:
Description: Test if the given edge is in the graph (with arguments both in the graph and not in the graph (where applicable))
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 61.87 ns | 1.545 μs | 18.95 μs | 210.9 μs |
| AlgaOld | 362.6 ns | 2.288 μs | 19.88 μs | 215.3 μs |
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 62.05 ns | 5.046 μs | 541.8 μs | 123.9 ms |
| AlgaOld | 362.1 ns | 6.668 μs | 560.4 μs | 105.9 ms |
SUMMARY:
There was 13 ex-aequo
ABSTRACT:
(Based on an average of the ratio between largest benchmarks)
I investigated about poor results of alga in https://github.com/haskell-perf/graphs
I found that the edges function from Algebraic.Graph is a bit naive:
edges = overlays . map (uncurry edge)This can lead to very poor graph representation: For example with a clique [0..9]
Connect (Vertex 0) (Connect (Vertex 1) (Connect (Vertex 2) (Connect (Vertex 3) (Connect (Vertex 4) (Connect (Vertex 5) (Connect (Vertex 6) (Connect (Vertex 7) (Connect (Vertex 8) (Vertex 9)))))))))
Doing a edges $ edgeList $ clique [0..9] will produce:
Overlay (Connect (Vertex 0) (Vertex 1)) (Overlay (Connect (Vertex 0) (Vertex 2)) (Overlay (Connect (Vertex 0) (Vertex 3)) (Overlay (Connect (Vertex 0) (Vertex 4)) (Overlay (Connect (Vertex 0) (Vertex 5)) (Overlay (Connect (Vertex 0) (Vertex 6)) (Overlay (Connect (Vertex 0) (Vertex 7)) (Overlay (Connect (Vertex 0) (Vertex 8)) (Overlay (Connect (Vertex 0) (Vertex 9)) (Overlay (Connect (Vertex 1) (Vertex 2)) (Overlay (Connect (Vertex 1) (Vertex 3)) (Overlay (Connect (Vertex 1) (Vertex 4)) (Overlay (Connect (Vertex 1) (Vertex 5)) (Overlay (Connect (Vertex 1) (Vertex 6)) (Overlay (Connect (Vertex 1) (Vertex 7)) (Overlay (Connect (Vertex 1) (Vertex 8)) (Overlay (Connect (Vertex 1) (Vertex 9)) (Overlay (Connect (Vertex 2) (Vertex 3)) (Overlay (Connect (Vertex 2) (Vertex 4)) (Overlay (Connect (Vertex 2) (Vertex 5)) (Overlay (Connect (Vertex 2) (Vertex 6)) (Overlay (Connect (Vertex 2) (Vertex 7)) (Overlay (Connect (Vertex 2) (Vertex 8)) (Overlay (Connect (Vertex 2) (Vertex 9)) (Overlay (Connect (Vertex 3) (Vertex 4)) (Overlay (Connect (Vertex 3) (Vertex 5)) (Overlay (Connect (Vertex 3) (Vertex 6)) (Overlay (Connect (Vertex 3) (Vertex 7)) (Overlay (Connect (Vertex 3) (Vertex 8)) (Overlay (Connect (Vertex 3) (Vertex 9)) (Overlay (Connect (Vertex 4) (Vertex 5)) (Overlay (Connect (Vertex 4) (Vertex 6)) (Overlay (Connect (Vertex 4) (Vertex 7)) (Overlay (Connect (Vertex 4) (Vertex 8)) (Overlay (Connect (Vertex 4) (Vertex 9)) (Overlay (Connect (Vertex 5) (Vertex 6)) (Overlay (Connect (Vertex 5) (Vertex 7)) (Overlay (Connect (Vertex 5) (Vertex 8)) (Overlay (Connect (Vertex 5) (Vertex 9)) (Overlay (Connect (Vertex 6) (Vertex 7)) (Overlay (Connect (Vertex 6) (Vertex 8)) (Overlay (Connect (Vertex 6) (Vertex 9)) (Overlay (Connect (Vertex 7) (Vertex 8)) (Overlay (Connect (Vertex 7) (Vertex 9)) (Connect (Vertex 8) (Vertex 9)))))))))))))))))))))))))))))))))))))))))))))
This representation can lead to very poor performance on big graphs.
I just tried a little amelioration, converting the list [(a,a)] into an adjacency map Map a [a], and then producing a graph using foldrWithKey (\k v acc -> Overlay acc $ Connect (Vertex k) $ vertices v).
Only this little trick divided the running-time of function like hasEdge by two on big graphs. I am sure finding a better implementation for edges can improve alga times a lot.
(I think this is mostly relevant for undirected graphs.)
Graph complement of an undirected graph (V, E) is (V, K \ E), where K is the clique on all vertices V, e.g. see https://en.wikipedia.org/wiki/Complement_graph.
Interestingly, complements of sparse graphs have as compact algebraic representations as sparse graphs.
Haddock is not sufficient. We need a beginner-friendly overview of the library with a few simple use-cases.
Everyone who has a graph wants to view it. Alga should provide some function that given a graph, and a way of labelling/styling the nodes, generates the appropriate DOT source.
https://en.wikipedia.org/wiki/Bipartite_graph
Note that Graph (Either a b) with vertices of types a and b allows connecting vertices of the same type, that is, the resulting graph is not bipartite.
One possible approach to this has been discussed in this twitter thread.
As discovered working on #103
Using:
edges :: [(a, a)] -> Graph a
edges = overlays . map edge'
edge' :: (a,a) -> Graph a
edge' (x,y) = connect (vertex x) (vertex y)(so uncurryfying "by-hand"),
lead to better performances:
Using [("Mesh",4),("Clique",4)] as graphs
## edges
### Mesh
#### 1000
+---------++----------+-------+
| || Time | R² |
+=========++==========+=======+
| Alga || 75.10 μs | 1.000 |
| AlgaOld || 105.4 μs | 0.998 |
+---------++----------+-------+
### Clique
#### 1000
+---------++----------+-------+
| || Time | R² |
+=========++==========+=======+
| Alga || 20.04 ms | 0.998 |
| AlgaOld || 26.76 ms | 0.995 |
+---------++----------+-------+
ABSTRACT:
(Based on an average of the ratio between largest benchmarks)
* Alga was 1.37 times faster than AlgaOld
I was reading GHC options, and one can use RULES to use specialized functions when needed.
Because Graph Int is a common type, I think that providing some specialized functions can be a good idea.
The specialisation will look like
vertexList :: Ord a => Graph a -> [a]
vertexList = Set.toAscList . vertexSet
{-# INLINE[1] vertexList #-}
{-# RULES "vertexList/Int" vertexList = vertexIntList #-}
vertexIntList :: Graph Int -> [Int]
vertexIntList = IntSet.toAscList . vertexIntSet
Particularly for vertexList and vertexCount.
Some bench on vertexCount using Graph Int:
Descritpion: Count the vertices of the graph
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 32.81 ns | 498.9 ns | 9.443 μs | 155.5 μs |
| AlgaOld | 29.64 ns | 4.620 μs | 118.0 μs | 2.045 ms |
| 1 | 10 | 100 | 1000 | |
|---|---|---|---|---|
| Alga | 32.63 ns | 1.657 μs | 371.9 μs | 82.46 ms |
| AlgaOld | 29.84 ns | 15.87 μs | 3.838 ms | 585.7 ms |
SUMMARY:
ABSTRACT:
GraphKL records are defined in AdjacencyMap and IntAdjacencyMap modules for interoperability with King-Launchbury graphs. Specifically, they provide a way to reuse the algorithms from Data.Graph.
While reviewing #18, I realised that GraphKL's getVertex function is partial, and I'd like to avoid having partial functions in the API where possible.
I propose to remove GraphKL, because there are not too many algorithms left in Data.Graph that we haven't yet wrapped in a clean interface: dfs (which is added in #18), bcc, plus a few reachability tests.
My plan is therefore to provide clean interfaces to all of these functions instead of exposing GraphKL.
Please shout if you are using GraphKL!
Hi,
Working on #71 I just discovered that the mesh function is making graphs with a very big size:
> let m = mesh [1..10] [1..10] :: Graph (Int,Int)
> size m
685
> length $ edgeList m
180
> size $ edges $ edgeList m
361
One part of this is due to Empty graphs hidden at the end of each path (here path introduces 36 empty leaves), but there still a strange too big size :)
box seems to introduce duplicated edges...
The current implementation defines the Graph type class using an associated type family:
{-# LANGUAGE TypeFamilies #-}
class Graph g where
type Vertex g
empty :: g
vertex :: Vertex g -> g
overlay :: g -> g -> g
connect :: g -> g -> gAn alternative is to use MultiParamTypeClasses and FunctionalDependencies:
{-# LANGUAGE MultiParamTypeClasses, FunctionalDependencies #-}
class Graph g a | g -> a where
empty :: g
vertex :: a -> g
overlay :: g -> g -> g
connect :: g -> g -> gMy current preference is the type families approach, but @ndmitchell suggests to give MPTC a serious consideration. What are the pros and cons?
Two example type signatures:
-- Type families
ab :: (Graph g, Vertex g ~ Char) => g
ab = connect (vertex 'a') (vertex 'b')
-- MPTC:
ab :: Graph g Char => g
ab = connect (vertex 'a') (vertex 'b')-- Type families
path :: Graph g => [Vertex g] -> g
-- MPTC:
path :: Graph g a => [a] -> gI think I prefer type families in both cases, although MPTC are a little terser. Are there cases where MPTC is clearly much better? Is there any difference in type inference and error messages?
Note: in this issue we do not discuss whether Graph should be higher-kinded. This is an orthogonal design question, deserving a separate issue.
The following relational graph composition operation is useful for various reachability algorithms but I can't figure out an efficient implementation.
Let z = compose x y. Then:
Ez = Ey ∘ Ex, i.e. we compose edge sets using the relational composition ∘. In other words, an edge (a,c) belongs to z only if there are edges (a,b) and (b,c) in x and y, respectively.Vz contains all non-isolated vertices from both graphs.This is a very natural composition operator and ideally I'd like to get the linear size complexity, i.e. the size of the resulting expression |z| should be O(|x|+|y|). However, I suspect that this may be impossible, so something like O((|x|+|y|)*log(|x|+|y|)) would be interesting too.
Also note that this (roughly) corresponds to the multiplication of the underlying connectivity matrices.
As spotted while writing the recent blog post:
λ> topSort $ 3 * (1 * 4 + 2 * 5)
Just [3,2,1,4,5]The lexicographically first topological sort should in fact be Just [3,1,2,4,5].
I believe this is also the reason why the TopSort graph instance doesn't satisfy the closure axiom:
These are potentially two different issues, but I believe they have the same cause.
Hi,
I am working to improve the regression suite on travis, and I just realized that the script don't make any backup of the built deps. The building of dependencies is now approx 30mins of the running time, and will be more since I added a dependency on Chart. We will certainly hit the 1 hour time limit of travis.
I personally use stack for https://travis-ci.org/haskell-perf/graphs/ because it allows to backup the .stack directory and thus backup the built dependencies, and speedup the rest.
I don't know if it is possible to achieve the same thing by only modifying a bit the .travis.yml file, or if we need to rewrite it totally to use stack.
The current implementation has no support for edge labels and this is a serious limitation. Let's use this issue to discuss possible designs.
As an example, consider a graph with vertices 1, 2, 3 and labelled edges 1 -{a}-> 2 and 2 -{b}-> 3.
The paper mentions this approach:
type LabelledGraph b a = b -> Graph a
g :: LabelledGraph Char Int
g 'a' = 1 * 2
g 'b' = 2 * 3
g _ = emptyHere b stands for the type of labels that can be attached not only to edges, but also vertices and arbitrary subgraphs. Function application g x acts as a projection: it extracts the subgraph labelled with x.
A similar, but somewhat simpler approach is to use lists of pairs instead of functions:
type LabelledGraph b a = [(b, Graph a)]
g :: LabelledGraph Char Int
g = [('a', 1 * 2), ('b', 2 * 3)]To obtain a projection, we filter the list by the edge label and overlay the graphs. The advantage of this approach compared to the above is that it's more explicit, and we can easily implement equality checking.
A very different approach is to add a new labelling operator [b] to the algebra. Here to obtain a nice algebraic structure the type of labels b need to form an idempotent semiring. For example, this works very well for Boolean labels:
[0]a = empty[1]a = a[x]a + [y]a = [x | y]a[x][y]a = [x & y]a[x](a + b) = [x]a + [x]b[x](a * b) = [x]a * [x]bThis should also work well for numeric labels, e.g. usually a distance label x on an edge corresponds to the interval [x; infinity) in terms of possible time it takes to traverse the edge, and such intervals, I believe form an idempotent semiring.
The cost is a new graph construction primitive:
data G b a = Empty
| Vertex a
| Overlay (G b a) (G b a)
| Connect (G b a) (G b a)
| Label b (G b a)
g :: G Char Int
g = Overlay (Label 'a' $ Vertex 1 `Connect` Vertex 2) (Label 'b' $ Vertex 2 `Connect` Vertex 3)I haven't yet tried any of these approaches on a serious example.
I'm pretty sure there are other approaches and the design space is quite large. Do you have any suggestions?
0.0.5 is the latest on Hackage.
I'd suggest only exposing the data type in the internal, so people only import it if they need the internals, not just because it's a handy source of all the functions. Another way to go might be to have Data.Graph.Internal which has all the internal definitions, and then hide the other Internal modules from Cabal?
A Graph type's show implementation might generate strings that result in invalid dot output. For example
> putStrLn (export defaultStyleViaShow (path ["test \"1\"", "2"]) :: String)
digraph
{
""2""
""test \"1\"""
""test \"1\""" -> ""2""
}
or even
> putStrLn (export defaultStyleViaShow (path ["1", "2"]) :: String)
digraph
{
""1""
""2""
""1"" -> ""2""
}
Coincidentally the latter is legal Dot, but unexpected:

I think the legal characters for identifiers are [['a'..'z'],['A'..'Z'],['\200'..'\377'],"_"]
There is a lot of code duplication in the testsuite currently. For example, see this commit: fc2854d.
It should be possible to get rid of most duplication by defining generic testsuites like this one.
There is also duplication in the documentation (see the same commit example above), but I'm not sure if it's possible to do anything about it.
Consider
import Algebra.Graph
import Algebra.Graph.Export.Dot
data SillyList = Slist Int Char deriving (Ord,Eq)
instance Show SillyList where
show (Slist _ c) = show c
v0 = (Slist 0 'a')
v1 = (Slist 1 'a')
v2 = (Slist 2 'b')
v3 = (Slist 3 'c')
g = path [v0,v1,v2,v3]
exportViaShow g results in:

But we want

In graphviz language this is achieved by unique node IDs but labelling them with the show value e.g. 0 [label="a"] (although the hard part here is choosing unique node ID values per vertex for arbitrary types)
The current definition of the Graph type class is very minimalistic:
class Graph g where
type Vertex g
empty :: g
vertex :: Vertex g -> g
overlay :: g -> g -> g
connect :: g -> g -> gI like the minimalism, because it makes the library very simple.
However, for the sake of efficiency, it may useful to add optional methods to the type class, such as:
removeVertex :: Eq (Vertex g) => Vertex g -> g -> gWe already have an implementation (see Algebra.Graph.Util), which we could try to make the default (although it seems tricky). It works in O(n) time, where n is the size of the algebraic expression, and some instances could provide faster implementations by overriding the removeVertex method.
What are the pros and cons?
Good: the user of the library doesn't have to think when calling removeVertex -- the fastest available implementation will be called, depending on the specific instance.
Bad: reasoning about performance may become harder. At the moment we know that removeVertex runs in O(n) time. If it becomes a class method, polymorphic code will have unpredictable performance characteristics.
Bad: the type class becomes heavier and more difficult to understand. When do we stop? There are many graph transformation primitives -- do we have to add them all to the type class?
Bad: what if a graph instance provides more than one implementation of removeVertex with different characteristics? Which one do we choose?
A possible alternative: use additional type classes to specify performance constraints. For example:
class Graph g => GraphWithFastRemoveVertex g where fastRemoveVertex = ...
-- UGr is a graph data structure defined in the fgl library.
-- It provides an efficient delNode realisation.
instance GraphWithFastRemoveVertex UGr where fastRemoveVertex = delNodeNow you can demand graph data structures with particular performance characteristics via the type signature.
/cc @ndmitchell
It's quite inconvenient to use class and data at the same time.
As data Graph directly encodes methods of the class, i'd name it Syntax, Grammar or Alg, but those might be quite weird names to use.
[ 5 of 14] Compiling Algebra.Graph.Test.Generic ( test/Algebra/Graph/Test/Generic.hs, dist/build/test-alga/test-alga-tmp/Algebra/Graph/Test/Generic.dyn_o )
test/Algebra/Graph/Test/Generic.hs:371:77: error:
Variable not in scope: applyFun2 :: t0 -> Int -> Int -> Int
test/Algebra/Graph/Test/Generic.hs:371:94: error:
Variable not in scope: applyFun2 :: t1 -> Int -> Int -> Int
builder for '/nix/store/83kmp44pqq2fnb7zwmv4xs5adz857hcn-algebraic-graphs-0.2.drv' failed with exit code 1
We currently expose the implementation of the Graph datatype:
data Graph a = Empty
| Vertex a
| Overlay (Graph a) (Graph a)
| Connect (Graph a) (Graph a)
deriving (Foldable, Functor, Show, Traversable)This is problematic:
Users can observe different graph structures even though underlying graphs are equal according to the laws of the algebra, e.g. Empty == Overlay Empty Empty.
Other representations may be more efficient (e.g. see #90) but we can't experiment with them without potentially breaking user code.
While doing this, we should probably dump awkward instance such as Foldable, since one can also use it to reveal internal structure, e.g. toList [1] == [1] but toList [1 + 1] == [1, 1]. We have an equivalent of the Foldable type class tailored for graphs, which we call ToGraph, which relies on the user to provide correct folding functions to avoid such issues.
I have a case where I need to model a graph (of labeled edges) via an adjacency map representation (I need, among other things, to sort the graphs topologically and compute the cycles via scc). It looks like the Diode (Set e) would take care of the labeling issue (my labels function only as edge identifiers) but I'm not sure what the best representation would be for the adjacency map itself given that I also need a King-Launchbury representation if I'm to avoid writing the sorts myself. Could anyone advise?
Or likewise, isCircular. Basically, a top-level function to determine if some Graph type is a DAG or not.
As last time (thanks again), I suspect there's some composition of the exposed primitives that "just works", but nothing jumped out at me after a brief scan of the API.
Thoughts?
I've been dabbling with taking all the middle school algebraic identities and expressing them as type signature refactorings:
http://chadbrewbaker.github.io/algebra/haskell/functional/programming/2016/01/27/algebraRules.html
Have you tried adding an exponentiation operator to your graph algebra? If so would it correspond directly to all functions from graph A to graph B, or would it be more esoteric?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.