

Python Machine Learning Jupyter Notebooks (ML website)
Dr. Tirthajyoti Sarkar, Fremont, California (Please feel free to connect on LinkedIn here)
- Python 3.6+
- NumPy (
pip install numpy) - Pandas (
pip install pandas) - Scikit-learn (
pip install scikit-learn) - SciPy (
pip install scipy) - Statsmodels (
pip install statsmodels) - MatplotLib (
pip install matplotlib) - Seaborn (
pip install seaborn) - Sympy (
pip install sympy) - Flask (
pip install flask) - WTForms (
pip install wtforms) - Tensorflow (
pip install tensorflow>=1.15) - Keras (
pip install keras) - pdpipe (
pip install pdpipe)
You can start with this article that I wrote in Heartbeat magazine (on Medium platform):

Jupyter notebooks covering a wide range of functions and operations on the topics of NumPy, Pandans, Seaborn, Matplotlib etc.
- Detailed Numpy operations
- Detailed Pandas operations
- Numpy and Pandas quick basics
- Matplotlib and Seaborn quick basics
- Advanced Pandas operations
- How to read various data sources
- PDF reading and table processing demo
- How fast are Numpy operations compared to pure Python code? (Read my article on Medium related to this topic)
- Fast reading from Numpy using .npy file format (Read my article on Medium on this topic)
Tutorial-type notebooks covering regression, classification, clustering, dimensionality reduction, and some basic neural network algorithms
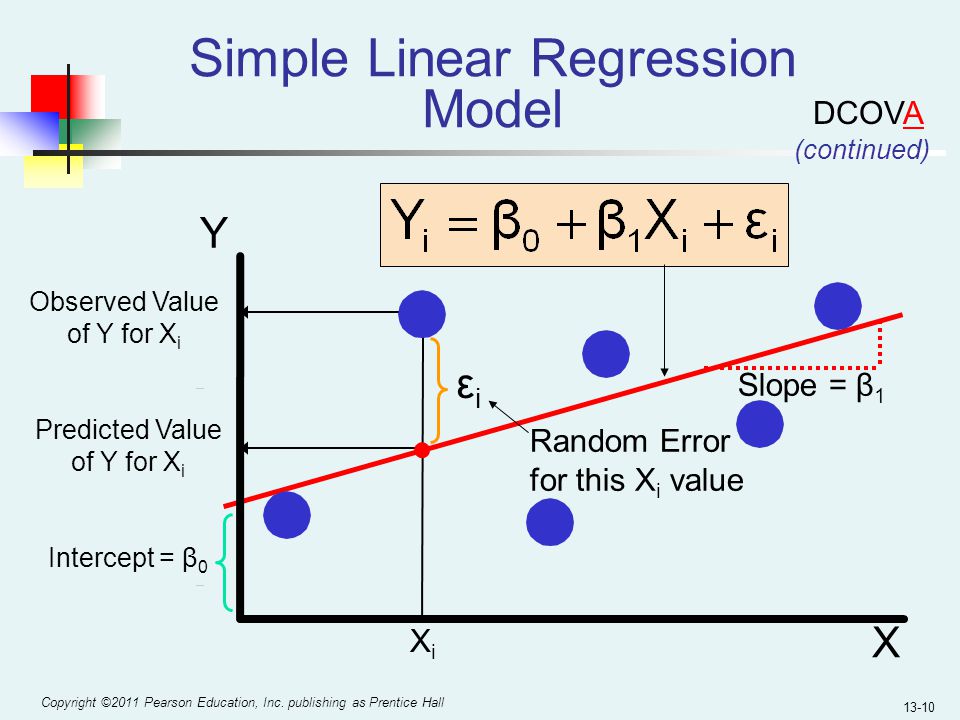
- Simple linear regression with t-statistic generation
-
Multiple ways to perform linear regression in Python and their speed comparison (check the article I wrote on freeCodeCamp)

-
Polynomial regression using scikit-learn pipeline feature (check the article I wrote on Towards Data Science)
-
Decision trees and Random Forest regression (showing how the Random Forest works as a robust/regularized meta-estimator rejecting overfitting)
-
Detailed visual analytics and goodness-of-fit diagnostic tests for a linear regression problem
-
Robust linear regression using
HuberRegressorfrom Scikit-learn
- Logistic regression/classification (Here is the Notebook)
-
k-nearest neighbor classification (Here is the Notebook)
-
Decision trees and Random Forest Classification (Here is the Notebook)
-
Support vector machine classification (Here is the Notebook) (check the article I wrote in Towards Data Science on SVM and sorting algorithm)

- Naive Bayes classification (Here is the Notebook)
-
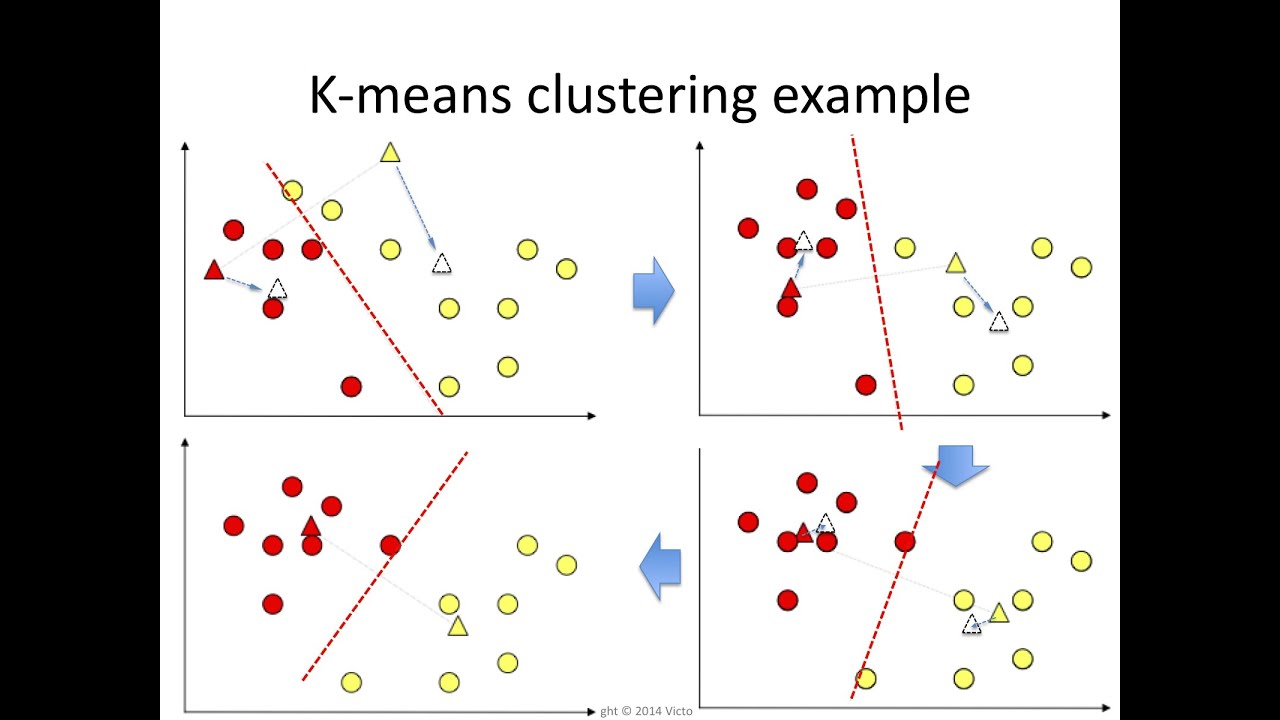
K-means clustering (Here is the Notebook)
-
Affinity propagation (showing its time complexity and the effect of damping factor) (Here is the Notebook)
-
Mean-shift technique (showing its time complexity and the effect of noise on cluster discovery) (Here is the Notebook)
-
DBSCAN (showing how it can generically detect areas of high density irrespective of cluster shapes, which the k-means fails to do) (Here is the Notebook)
-
Hierarchical clustering with Dendograms showing how to choose optimal number of clusters (Here is the Notebook)

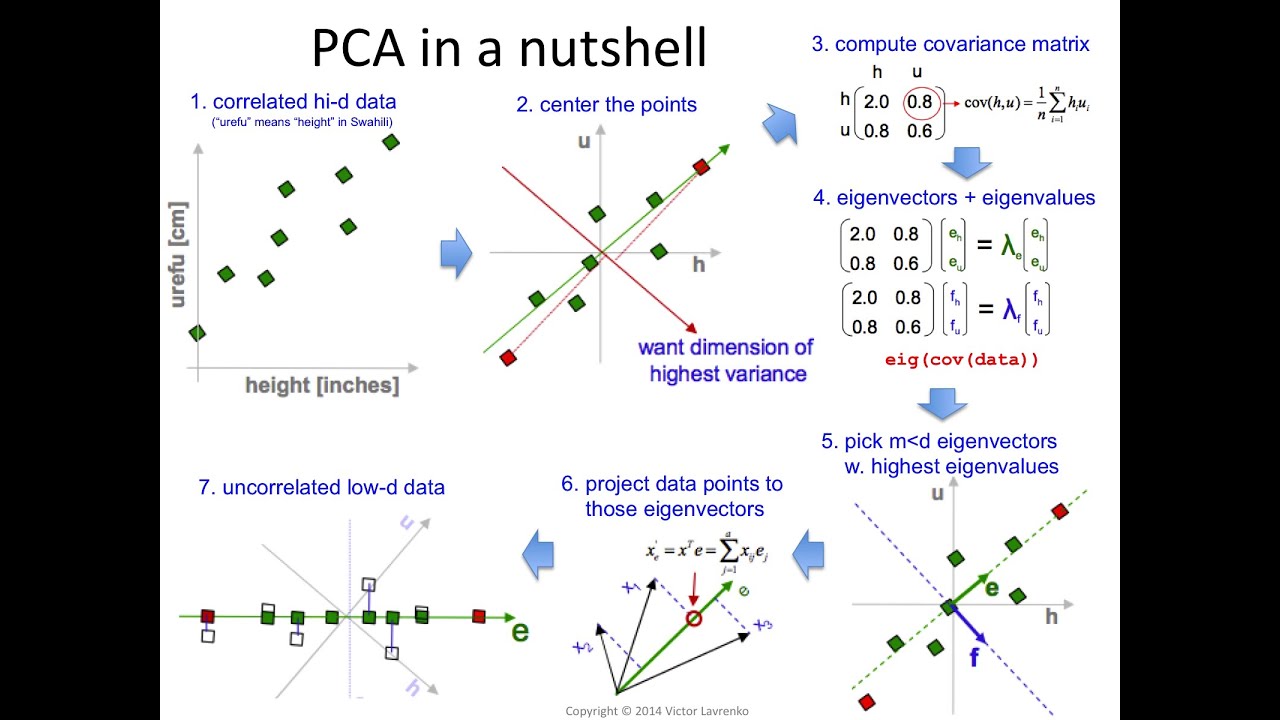
- Principal component analysis
- Demo notebook to illustrate the superiority of deep neural network for complex nonlinear function approximation task
- Step-by-step building of 1-hidden-layer and 2-hidden-layer dense network using basic TensorFlow methods
-
How to use Sympy package to generate random datasets using symbolic mathematical expressions.
-
Here is my article on Medium on this topic: Random regression and classification problem generation with symbolic expression
-
Serving a linear regression model through a simple HTTP server interface. User needs to request predictions by executing a Python script. Uses
FlaskandGunicorn. -
Serving a recurrent neural network (RNN) through a HTTP webpage, complete with a web form, where users can input parameters and click a button to generate text based on the pre-trained RNN model. Uses
Flask,Jinja,Keras/TensorFlow,WTForms.
Implementing some of the core OOP principles in a machine learning context by building your own Scikit-learn-like estimator, and making it better.
See my articles on Medium on this topic.
- Object-oriented programming for data scientists: Build your ML estimator
- How a simple mix of object-oriented programming can sharpen your deep learning prototype
Check the files and detailed instructions in the Pytest directory to understand how one should write unit testing code/module for machine learning models
Profiling data science code and ML models for memory footprint and computing time is a critical but often overlooed area. Here are a couple of Notebooks showing the ideas,

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")









































































































































































































