This project aims to make the GBIF Integrated Publish Toolkit (IPT) compliant with the Data Catalog Vocabulary application profile (DCAT-AP), by exposing Catalog, Dataset, and Distribution information in the IPT. This repository defines the EML to DCAT-AP mapping and describes the functional requirements to implement it in the IPT.
- Fork of the IPT source code: this is where we'll implement the DCAT-AP functionality
- DCAT to IPT mapping
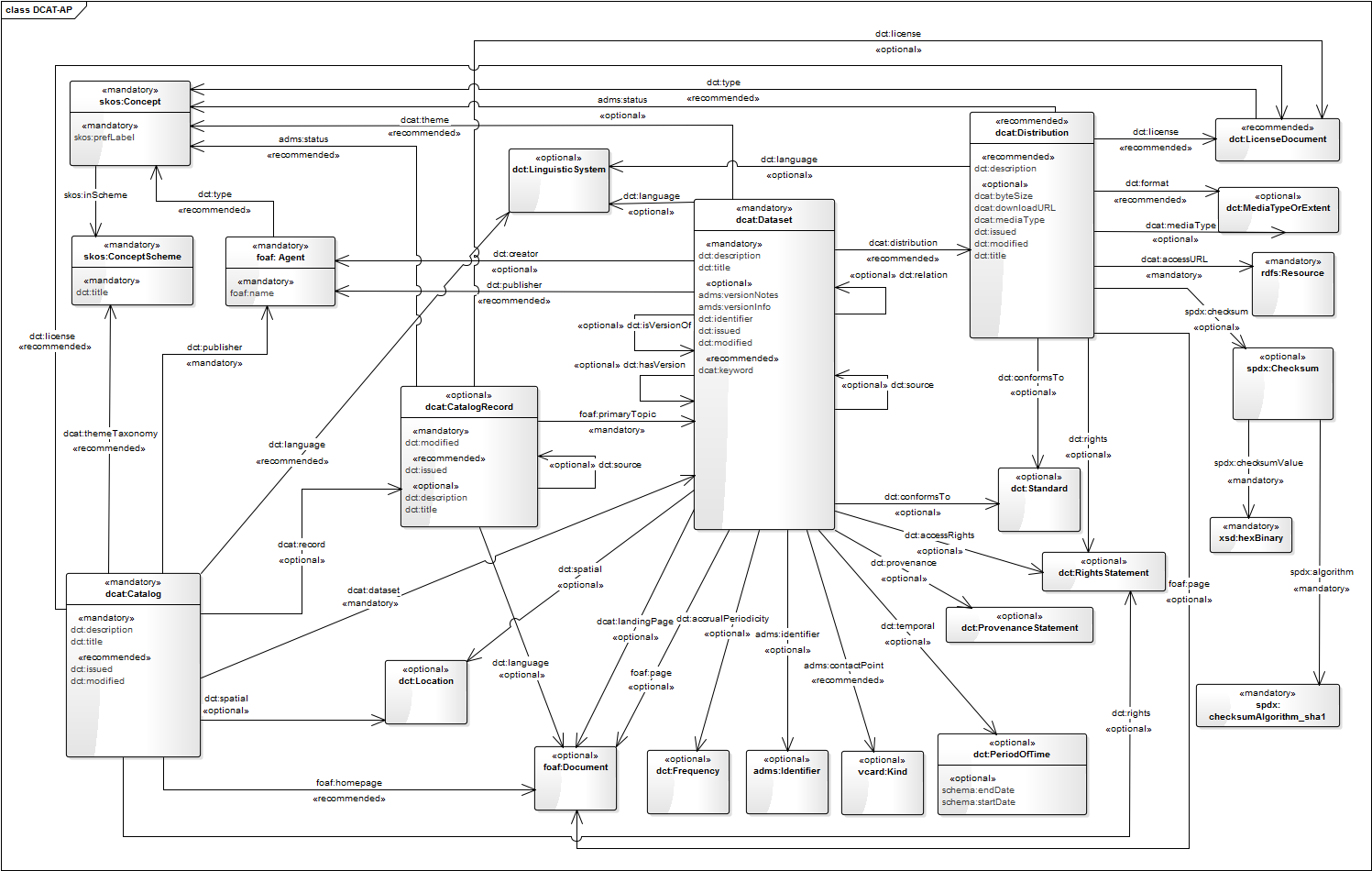
- DCAT-AP model: image of the DCAT-AP objects, properties and relationships.
- DCAT-AP validator: in Swedish, but should work for Belgian DCAT-AP too




















{kind=link}