python run_lab.py slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json reinforce_baseline_cartpole search
[2020-01-30 11:38:57,177 PID:4355 INFO run_lab.py read_spec_and_run] Running lab spec_file:slm_lab/spec/benchmark/reinforce/reinforce_cartpole.json spec_name:reinforce_baseline_cartpole in mode:search
[2020-01-30 11:38:57,183 PID:4355 INFO search.py run_ray_search] Running ray search for spec reinforce_baseline_cartpole
2020-01-30 11:38:57,183 WARNING worker.py:1341 -- WARNING: Not updating worker name since `setproctitle` is not installed. Install this with `pip install setproctitle` (or ray[debug]) to enable monitoring of worker processes.
2020-01-30 11:38:57,183 INFO node.py:497 -- Process STDOUT and STDERR is being redirected to /tmp/ray/session_2020-01-30_11-38-57_183527_4355/logs.
2020-01-30 11:38:57,288 INFO services.py:409 -- Waiting for redis server at 127.0.0.1:59003 to respond...
2020-01-30 11:38:57,409 INFO services.py:409 -- Waiting for redis server at 127.0.0.1:55931 to respond...
2020-01-30 11:38:57,414 INFO services.py:806 -- Starting Redis shard with 3.35 GB max memory.
2020-01-30 11:38:57,435 INFO node.py:511 -- Process STDOUT and STDERR is being redirected to /tmp/ray/session_2020-01-30_11-38-57_183527_4355/logs.
2020-01-30 11:38:57,435 INFO services.py:1441 -- Starting the Plasma object store with 5.02 GB memory using /dev/shm.
2020-01-30 11:38:57,543 INFO tune.py:60 -- Tip: to resume incomplete experiments, pass resume='prompt' or resume=True to run()
2020-01-30 11:38:57,543 INFO tune.py:223 -- Starting a new experiment.
== Status ==
Using FIFO scheduling algorithm.
Resources requested: 0/8 CPUs, 0/1 GPUs
Memory usage on this node: 2.1/16.7 GB
2020-01-30 11:38:57,572 WARNING logger.py:130 -- Couldn't import TensorFlow - disabling TensorBoard logging.
2020-01-30 11:38:57,573 WARNING logger.py:224 -- Could not instantiate <class 'ray.tune.logger.TFLogger'> - skipping.
== Status ==
Using FIFO scheduling algorithm.
Resources requested: 4/8 CPUs, 0/1 GPUs
Memory usage on this node: 2.2/16.7 GB
Result logdir: /home/joe/ray_results/reinforce_baseline_cartpole
Number of trials: 2 ({'RUNNING': 1, 'PENDING': 1})
PENDING trials:
- ray_trainable_1_agent.0.algorithm.center_return=False,trial_index=1: PENDING
RUNNING trials:
- ray_trainable_0_agent.0.algorithm.center_return=True,trial_index=0: RUNNING
2020-01-30 11:38:57,596 WARNING logger.py:130 -- Couldn't import TensorFlow - disabling TensorBoard logging.
2020-01-30 11:38:57,607 WARNING logger.py:224 -- Could not instantiate <class 'ray.tune.logger.TFLogger'> - skipping.
(pid=4389) [2020-01-30 11:38:58,297 PID:4389 INFO logger.py info] Running sessions
(pid=4388) [2020-01-30 11:38:58,292 PID:4388 INFO logger.py info] Running sessions
(pid=4388) terminate called after throwing an instance of 'c10::Error'
(pid=4388) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4388) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcf770dedc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4388) frame #1: <unknown function> + 0xca67 (0x7fcf6f2daa67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4388) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcf6f9fbb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4388) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcfa636128a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4388) frame #4: <unknown function> + 0xc8421 (0x7fcfbb3bd421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4388) frame #5: <unknown function> + 0x76db (0x7fcfc0c466db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4388) frame #6: clone + 0x3f (0x7fcfc096f88f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4388)
(pid=4388) Fatal Python error: Aborted
(pid=4388)
(pid=4388) Stack (most recent call first):
(pid=4389) [2020-01-30 11:38:58,326 PID:4456 INFO openai.py __init__] OpenAIEnv:
(pid=4389) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4389) - eval_frequency = 2000
(pid=4389) - log_frequency = 10000
(pid=4389) - frame_op = None
(pid=4389) - frame_op_len = None
(pid=4389) - image_downsize = (84, 84)
(pid=4389) - normalize_state = False
(pid=4389) - reward_scale = None
(pid=4389) - num_envs = 1
(pid=4389) - name = CartPole-v0
(pid=4389) - max_t = 200
(pid=4389) - max_frame = 100000
(pid=4389) - to_render = False
(pid=4389) - is_venv = False
(pid=4389) - clock_speed = 1
(pid=4389) - clock = <slm_lab.env.base.Clock object at 0x7fcc1a023d30>
(pid=4389) - done = False
(pid=4389) - total_reward = nan
(pid=4389) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4389) - observation_space = Box(4,)
(pid=4389) - action_space = Discrete(2)
(pid=4389) - observable_dim = {'state': 4}
(pid=4389) - action_dim = 2
(pid=4389) - is_discrete = True
(pid=4389) [2020-01-30 11:38:58,327 PID:4453 INFO openai.py __init__] OpenAIEnv:
(pid=4389) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4389) - eval_frequency = 2000
(pid=4389) - log_frequency = 10000
(pid=4389) - frame_op = None
(pid=4389) - frame_op_len = None
(pid=4389) - image_downsize = (84, 84)
(pid=4389) - normalize_state = False
(pid=4389) - reward_scale = None
(pid=4389) - num_envs = 1
(pid=4389) - name = CartPole-v0
(pid=4389) - max_t = 200
(pid=4389) - max_frame = 100000
(pid=4389) - to_render = False
(pid=4389) - is_venv = False
(pid=4389) - clock_speed = 1
(pid=4389) - clock = <slm_lab.env.base.Clock object at 0x7fcc1a023d30>
(pid=4389) - done = False
(pid=4389) - total_reward = nan
(pid=4389) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4389) - observation_space = Box(4,)
(pid=4389) - action_space = Discrete(2)
(pid=4389) - observable_dim = {'state': 4}
(pid=4389) - action_dim = 2
(pid=4389) - is_discrete = True
(pid=4389) [2020-01-30 11:38:58,328 PID:4450 INFO openai.py __init__] OpenAIEnv:
(pid=4389) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4389) - eval_frequency = 2000
(pid=4389) - log_frequency = 10000
(pid=4389) - frame_op = None
(pid=4389) - frame_op_len = None
(pid=4389) - image_downsize = (84, 84)
(pid=4389) - normalize_state = False
(pid=4389) - reward_scale = None
(pid=4389) - num_envs = 1
(pid=4389) - name = CartPole-v0
(pid=4389) - max_t = 200
(pid=4389) - max_frame = 100000
(pid=4389) - to_render = False
(pid=4389) - is_venv = False
(pid=4389) - clock_speed = 1
(pid=4389) - clock = <slm_lab.env.base.Clock object at 0x7fcc1a023d30>
(pid=4389) - done = False
(pid=4389) - total_reward = nan
(pid=4389) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4389) - observation_space = Box(4,)
(pid=4389) - action_space = Discrete(2)
(pid=4389) - observable_dim = {'state': 4}
(pid=4389) - action_dim = 2
(pid=4389) - is_discrete = True
(pid=4389) [2020-01-30 11:38:58,335 PID:4458 INFO openai.py __init__] OpenAIEnv:
(pid=4389) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4389) - eval_frequency = 2000
(pid=4389) - log_frequency = 10000
(pid=4389) - frame_op = None
(pid=4389) - frame_op_len = None
(pid=4389) - image_downsize = (84, 84)
(pid=4389) - normalize_state = False
(pid=4389) - reward_scale = None
(pid=4389) - num_envs = 1
(pid=4389) - name = CartPole-v0
(pid=4389) - max_t = 200
(pid=4389) - max_frame = 100000
(pid=4389) - to_render = False
(pid=4389) - is_venv = False
(pid=4389) - clock_speed = 1
(pid=4389) - clock = <slm_lab.env.base.Clock object at 0x7fcc1a023d30>
(pid=4389) - done = False
(pid=4389) - total_reward = nan
(pid=4389) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4389) - observation_space = Box(4,)
(pid=4389) - action_space = Discrete(2)
(pid=4389) - observable_dim = {'state': 4}
(pid=4389) - action_dim = 2
(pid=4389) - is_discrete = True
(pid=4388) [2020-01-30 11:38:58,313 PID:4440 INFO openai.py __init__] OpenAIEnv:
(pid=4388) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4388) - eval_frequency = 2000
(pid=4388) - log_frequency = 10000
(pid=4388) - frame_op = None
(pid=4388) - frame_op_len = None
(pid=4388) - image_downsize = (84, 84)
(pid=4388) - normalize_state = False
(pid=4388) - reward_scale = None
(pid=4388) - num_envs = 1
(pid=4388) - name = CartPole-v0
(pid=4388) - max_t = 200
(pid=4388) - max_frame = 100000
(pid=4388) - to_render = False
(pid=4388) - is_venv = False
(pid=4388) - clock_speed = 1
(pid=4388) - clock = <slm_lab.env.base.Clock object at 0x7fce28f7fcf8>
(pid=4388) - done = False
(pid=4388) - total_reward = nan
(pid=4388) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4388) - observation_space = Box(4,)
(pid=4388) - action_space = Discrete(2)
(pid=4388) - observable_dim = {'state': 4}
(pid=4388) - action_dim = 2
(pid=4388) - is_discrete = True
(pid=4388) [2020-01-30 11:38:58,318 PID:4445 INFO openai.py __init__] OpenAIEnv:
(pid=4388) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4388) - eval_frequency = 2000
(pid=4388) - log_frequency = 10000
(pid=4388) - frame_op = None
(pid=4388) - frame_op_len = None
(pid=4388) - image_downsize = (84, 84)
(pid=4388) - normalize_state = False
(pid=4388) - reward_scale = None
(pid=4388) - num_envs = 1
(pid=4388) - name = CartPole-v0
(pid=4388) - max_t = 200
(pid=4388) - max_frame = 100000
(pid=4388) - to_render = False
(pid=4388) - is_venv = False
(pid=4388) - clock_speed = 1
(pid=4388) - clock = <slm_lab.env.base.Clock object at 0x7fce28f7fcf8>
(pid=4388) - done = False
(pid=4388) - total_reward = nan
(pid=4388) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4388) - observation_space = Box(4,)
(pid=4388) - action_space = Discrete(2)
(pid=4388) - observable_dim = {'state': 4}
(pid=4388) - action_dim = 2
(pid=4388) - is_discrete = True
(pid=4388) [2020-01-30 11:38:58,319 PID:4449 INFO openai.py __init__] OpenAIEnv:
(pid=4388) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4388) - eval_frequency = 2000
(pid=4388) - log_frequency = 10000
(pid=4388) - frame_op = None
(pid=4388) - frame_op_len = None
(pid=4388) - image_downsize = (84, 84)
(pid=4388) - normalize_state = False
(pid=4388) - reward_scale = None
(pid=4388) - num_envs = 1
(pid=4388) - name = CartPole-v0
(pid=4388) - max_t = 200
(pid=4388) - max_frame = 100000
(pid=4388) - to_render = False
(pid=4388) - is_venv = False
(pid=4388) - clock_speed = 1
(pid=4388) - clock = <slm_lab.env.base.Clock object at 0x7fce28f7fcf8>
(pid=4388) - done = False
(pid=4388) - total_reward = nan
(pid=4388) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4388) - observation_space = Box(4,)
(pid=4388) - action_space = Discrete(2)
(pid=4388) - observable_dim = {'state': 4}
(pid=4388) - action_dim = 2
(pid=4388) - is_discrete = True
(pid=4388) [2020-01-30 11:38:58,323 PID:4452 INFO openai.py __init__] OpenAIEnv:
(pid=4388) - env_spec = {'max_frame': 100000, 'max_t': None, 'name': 'CartPole-v0'}
(pid=4388) - eval_frequency = 2000
(pid=4388) - log_frequency = 10000
(pid=4388) - frame_op = None
(pid=4388) - frame_op_len = None
(pid=4388) - image_downsize = (84, 84)
(pid=4388) - normalize_state = False
(pid=4388) - reward_scale = None
(pid=4388) - num_envs = 1
(pid=4388) - name = CartPole-v0
(pid=4388) - max_t = 200
(pid=4388) - max_frame = 100000
(pid=4388) - to_render = False
(pid=4388) - is_venv = False
(pid=4388) - clock_speed = 1
(pid=4388) - clock = <slm_lab.env.base.Clock object at 0x7fce28f7fcf8>
(pid=4388) - done = False
(pid=4388) - total_reward = nan
(pid=4388) - u_env = <TrackReward<TimeLimit<CartPoleEnv<CartPole-v0>>>>
(pid=4388) - observation_space = Box(4,)
(pid=4388) - action_space = Discrete(2)
(pid=4388) - observable_dim = {'state': 4}
(pid=4388) - action_dim = 2
(pid=4388) - is_discrete = True
(pid=4389) [2020-01-30 11:38:58,339 PID:4453 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4389) [2020-01-30 11:38:58,340 PID:4450 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4389) [2020-01-30 11:38:58,343 PID:4456 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4389) [2020-01-30 11:38:58,345 PID:4450 INFO base.py __init__][2020-01-30 11:38:58,345 PID:4453 INFO base.py __init__] Reinforce:
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bddcc0>
(pid=4389) - algorithm_spec = {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1}
(pid=4389) - name = Reinforce
(pid=4389) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4389) - net_spec = {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bddcc0>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56cc0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bcb710>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bddd68>"
(pid=4389) }
(pid=4389) - action_pdtype = default
(pid=4389) - action_policy = <function default at 0x7fcc21560620>
(pid=4389) - center_return = False
(pid=4389) - explore_var_spec = None
(pid=4389) - entropy_coef_spec = {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01}
(pid=4389) - policy_loss_coef = 1.0
(pid=4389) - gamma = 0.99
(pid=4389) - training_frequency = 1
(pid=4389) - to_train = 0
(pid=4389) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bddd30>
(pid=4389) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bdda20>
(pid=4389) - net = MLPNet(
(pid=4389) (model): Sequential(
(pid=4389) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4389) (1): SELU()
(pid=4389) )
(pid=4389) (model_tail): Sequential(
(pid=4389) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4389) )
(pid=4389) (loss_fn): MSELoss()
(pid=4389) )
(pid=4389) - net_names = ['net']
(pid=4389) - optim = Adam (
(pid=4389) Parameter Group 0
(pid=4389) amsgrad: False
(pid=4389) betas: (0.9, 0.999)
(pid=4389) eps: 1e-08
(pid=4389) lr: 0.002
(pid=4389) weight_decay: 0
(pid=4389) )
(pid=4389) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fcc10ba20b8>
(pid=4389) - global_net = None
(pid=4389) Reinforce:
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bdddd8>
(pid=4389) - algorithm_spec = {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) [2020-01-30 11:38:58,330 PID:4445 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4388) [2020-01-30 11:38:58,330 PID:4449 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4388) [2020-01-30 11:38:58,335 PID:4452 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4388) [2020-01-30 11:38:58,335 PID:4449 INFO base.py __init__] Reinforce:
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e097f60>
(pid=4388) - algorithm_spec = {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1}
(pid=4388) - name = Reinforce
(pid=4388) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4388) - net_spec = {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e097f60>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044eb8>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e097fd0>"
(pid=4388) }
(pid=4388) - action_pdtype = default
(pid=4388) - action_policy = <function default at 0x7fce304ad620>
(pid=4388) - center_return = True
(pid=4388) - explore_var_spec = None
(pid=4388) - entropy_coef_spec = {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01}
(pid=4388) - policy_loss_coef = 1.0
(pid=4388) - gamma = 0.99
(pid=4388) - training_frequency = 1
(pid=4388) - to_train = 0
(pid=4388) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e097c88>
(pid=4388) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e083940>
(pid=4388) - net = MLPNet(
(pid=4388) (model): Sequential(
(pid=4388) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4388) (1): SELU()
(pid=4388) )
(pid=4388) (model_tail): Sequential(
(pid=4388) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4388) )
(pid=4388) (loss_fn): MSELoss()
(pid=4388) )
(pid=4388) - net_names = ['net']
(pid=4388) - optim = Adam (
(pid=4388) Parameter Group 0
(pid=4388) amsgrad: False
(pid=4388) betas: (0.9, 0.999)
(pid=4388) eps: 1e-08
(pid=4388) lr: 0.002
(pid=4388) weight_decay: 0
(pid=4388) )
(pid=4388) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fce0e0562e8>
(pid=4388) - global_net = None
(pid=4388) [2020-01-30 11:38:58,335 PID:4445 INFO base.py __init__] Reinforce:
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e098da0>
(pid=4388) - algorithm_spec = {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1}
(pid=4389) - name = Reinforce
(pid=4389) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4389) - net_spec = {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bdddd8>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56da0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc5828>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bdde80>"
(pid=4389) }
(pid=4389) - action_pdtype = default
(pid=4389) - action_policy = <function default at 0x7fcc21560620>
(pid=4389) - center_return = False
(pid=4389) - explore_var_spec = None
(pid=4389) - entropy_coef_spec = {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01}
(pid=4389) - policy_loss_coef = 1.0
(pid=4389) - gamma = 0.99
(pid=4389) - training_frequency = 1
(pid=4389) - to_train = 0
(pid=4389) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bdde48>
(pid=4389) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bddb38>
(pid=4389) - net = MLPNet(
(pid=4389) (model): Sequential(
(pid=4389) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4389) (1): SELU()
(pid=4389) )
(pid=4389) (model_tail): Sequential(
(pid=4389) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4389) )
(pid=4389) (loss_fn): MSELoss()
(pid=4389) )
(pid=4389) - net_names = ['net']
(pid=4389) - optim = Adam (
(pid=4389) Parameter Group 0
(pid=4389) amsgrad: False
(pid=4389) betas: (0.9, 0.999)
(pid=4389) eps: 1e-08
(pid=4389) lr: 0.002
(pid=4389) weight_decay: 0
(pid=4389) )
(pid=4389) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fcc10ba11d0>
(pid=4389) - global_net = None
(pid=4389) [2020-01-30 11:38:58,347 PID:4453 INFO __init__.py __init__][2020-01-30 11:38:58,347 PID:4450 INFO __init__.py __init__] Agent:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1},
(pid=4389) 'memory': {'name': 'OnPolicyReplay'},
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1}
(pid=4388) - name = Reinforce
(pid=4388) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4388) - net_spec = {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e098da0>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044da0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e098e48>"
(pid=4388) }
(pid=4388) - action_pdtype = default
(pid=4388) - action_policy = <function default at 0x7fce304ad620>
(pid=4388) - center_return = True
(pid=4388) - explore_var_spec = None
(pid=4388) - entropy_coef_spec = {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01}
(pid=4388) - policy_loss_coef = 1.0
(pid=4388) - gamma = 0.99
(pid=4388) - training_frequency = 1
(pid=4388) - to_train = 0
(pid=4388) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e098e10>
(pid=4388) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e098f28>
(pid=4388) - net = MLPNet(
(pid=4388) (model): Sequential(
(pid=4388) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4388) (1): SELU()
(pid=4388) )
(pid=4388) (model_tail): Sequential(
(pid=4388) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4388) )
(pid=4388) (loss_fn): MSELoss()
(pid=4388) )
(pid=4388) - net_names = ['net']
(pid=4388) - optim = Adam (
(pid=4388) Parameter Group 0
(pid=4388) amsgrad: False
(pid=4388) betas: (0.9, 0.999)
(pid=4388) eps: 1e-08
(pid=4388) lr: 0.002
(pid=4388) weight_decay: 0
(pid=4388) )
(pid=4388) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fce0e05b1d0>
(pid=4388) - global_net = None
(pid=4388) [2020-01-30 11:38:58,336 PID:4449 INFO __init__.py __init__] Agent:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1},
(pid=4388) 'memory': {'name': 'OnPolicyReplay'},
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'net': {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}}
(pid=4389) - name = Reinforce
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bdddd8>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56da0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc5828>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bdde80>"
(pid=4389) }
(pid=4389) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fcc10bdde10>
(pid=4389) Agent:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1},
(pid=4389) 'memory': {'name': 'OnPolicyReplay'},
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'net': {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}}
(pid=4389) - name = Reinforce
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bddcc0>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56cc0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bcb710>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bddd68>"
(pid=4389) }
(pid=4389) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fcc10bddcf8>
(pid=4389) [2020-01-30 11:38:58,347 PID:4458 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search[2020-01-30 11:38:58,347 PID:4450 INFO logger.py info][2020-01-30 11:38:58,347 PID:4453 INFO logger.py info]
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'net': {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}}
(pid=4388) - name = Reinforce
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e097f60>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044eb8>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e097fd0>"
(pid=4388) }
(pid=4388) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fce0e097f98>
(pid=4388) [2020-01-30 11:38:58,337 PID:4449 INFO logger.py info] Session:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - index = 2
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e097f60>
(pid=4388) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044eb8>
(pid=4388) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044eb8>
(pid=4388) [2020-01-30 11:38:58,337 PID:4449 INFO logger.py info] Running RL loop for trial 0 session 2
(pid=4388) [2020-01-30 11:38:58,337 PID:4445 INFO __init__.py __init__] Agent:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1},
(pid=4388) 'memory': {'name': 'OnPolicyReplay'},
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'net': {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}}
(pid=4388) - name = Reinforce
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e098da0>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044da0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4389) Session:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - index = 0
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bddcc0>
(pid=4389) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56cc0>
(pid=4389) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56cc0> Session:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - index = 1
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bdddd8>
(pid=4389) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56da0>
(pid=4389) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56da0>
(pid=4389)
(pid=4389) [2020-01-30 11:38:58,347 PID:4450 INFO logger.py info] Running RL loop for trial 1 session 0[2020-01-30 11:38:58,347 PID:4453 INFO logger.py info]
(pid=4389) Running RL loop for trial 1 session 1
(pid=4389) [2020-01-30 11:38:58,348 PID:4456 INFO base.py __init__] Reinforce:
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bdcf28>
(pid=4389) - algorithm_spec = {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1}
(pid=4389) - name = Reinforce
(pid=4389) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4389) - net_spec = {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bdcf28>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56eb8>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc7940>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bdcfd0>"
(pid=4389) }
(pid=4389) - action_pdtype = default
(pid=4389) - action_policy = <function default at 0x7fcc21560620>
(pid=4389) - center_return = False
(pid=4389) - explore_var_spec = None
(pid=4389) - entropy_coef_spec = {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01}
(pid=4389) - policy_loss_coef = 1.0
(pid=4389) - gamma = 0.99
(pid=4389) - training_frequency = 1
(pid=4389) - to_train = 0
(pid=4389) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bdcf98>
(pid=4389) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10bdcc50>
(pid=4389) - net = MLPNet(
(pid=4389) (model): Sequential(
(pid=4389) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4389) (1): SELU()
(pid=4389) )
(pid=4389) (model_tail): Sequential(
(pid=4389) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4389) )
(pid=4389) (loss_fn): MSELoss()
(pid=4389) )
(pid=4389) - net_names = ['net']
(pid=4389) - optim = Adam (
(pid=4389) Parameter Group 0
(pid=4389) amsgrad: False
(pid=4389) betas: (0.9, 0.999)
(pid=4389) eps: 1e-08
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e098e48>"
(pid=4388) }
(pid=4388) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fce0e098dd8>
(pid=4388) [2020-01-30 11:38:58,338 PID:4445 INFO logger.py info] Session:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - index = 1
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e098da0>
(pid=4388) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044da0>
(pid=4388) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044da0>
(pid=4388) [2020-01-30 11:38:58,338 PID:4445 INFO logger.py info] Running RL loop for trial 0 session 1
(pid=4388) [2020-01-30 11:38:58,340 PID:4449 INFO __init__.py log_summary] Trial 0 session 2 reinforce_baseline_cartpole_t0_s2 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4388) [2020-01-30 11:38:58,340 PID:4452 INFO base.py __init__] Reinforce:
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e082a58>
(pid=4388) - algorithm_spec = {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1}
(pid=4388) - name = Reinforce
(pid=4388) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4388) - net_spec = {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e082a58>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044fd0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e0540b8>"
(pid=4388) }
(pid=4388) - action_pdtype = default
(pid=4388) - action_policy = <function default at 0x7fce304ad620>
(pid=4388) - center_return = True
(pid=4388) - explore_var_spec = None
(pid=4388) - entropy_coef_spec = {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01}
(pid=4388) - policy_loss_coef = 1.0
(pid=4388) - gamma = 0.99
(pid=4388) - training_frequency = 1
(pid=4388) - to_train = 0
(pid=4388) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e054080>
(pid=4388) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e054160>
(pid=4388) - net = MLPNet(
(pid=4388) (model): Sequential(
(pid=4388) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4388) (1): SELU()
(pid=4388) )
(pid=4388) (model_tail): Sequential(
(pid=4388) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4388) )
(pid=4388) (loss_fn): MSELoss()
(pid=4388) )
(pid=4388) - net_names = ['net']
(pid=4388) - optim = Adam (
(pid=4388) Parameter Group 0
(pid=4388) amsgrad: False
(pid=4388) betas: (0.9, 0.999)
(pid=4388) eps: 1e-08
(pid=4389) lr: 0.002
(pid=4389) weight_decay: 0
(pid=4389) )
(pid=4389) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fcc10b9a2e8>
(pid=4389) - global_net = None
(pid=4389) [2020-01-30 11:38:58,350 PID:4456 INFO __init__.py __init__] Agent:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1},
(pid=4389) 'memory': {'name': 'OnPolicyReplay'},
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'net': {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}}
(pid=4389) - name = Reinforce
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bdcf28>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56eb8>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc7940>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10bdcfd0>"
(pid=4389) }
(pid=4389) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fcc10bdcf60>
(pid=4389) [2020-01-30 11:38:58,351 PID:4456 INFO logger.py info] Session:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - index = 2
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bdcf28>
(pid=4389) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56eb8>
(pid=4389) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56eb8>
(pid=4389) [2020-01-30 11:38:58,351 PID:4456 INFO logger.py info] Running RL loop for trial 1 session 2
(pid=4389) [2020-01-30 11:38:58,351 PID:4450 INFO __init__.py log_summary] Trial 1 session 0 reinforce_baseline_cartpole_t1_s0 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4389) [2020-01-30 11:38:58,351 PID:4453 INFO __init__.py log_summary] Trial 1 session 1 reinforce_baseline_cartpole_t1_s1 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4389) [2020-01-30 11:38:58,352 PID:4458 INFO base.py __init__] Reinforce:
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bddd68>
(pid=4389) - algorithm_spec = {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1}
(pid=4389) - name = Reinforce
(pid=4389) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4389) - net_spec = {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bddd68>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56fd0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4388) lr: 0.002
(pid=4388) weight_decay: 0
(pid=4388) )
(pid=4388) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fce0e054400>
(pid=4388) - global_net = None
(pid=4388) [2020-01-30 11:38:58,342 PID:4445 INFO __init__.py log_summary] Trial 0 session 1 reinforce_baseline_cartpole_t0_s1 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4388) [2020-01-30 11:38:58,342 PID:4452 INFO __init__.py __init__] Agent:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1},
(pid=4388) 'memory': {'name': 'OnPolicyReplay'},
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'net': {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}}
(pid=4388) - name = Reinforce
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e082a58>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044fd0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e0540b8>"
(pid=4388) }
(pid=4388) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fce0e054048>
(pid=4388) [2020-01-30 11:38:58,342 PID:4452 INFO logger.py info] Session:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - index = 3
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e082a58>
(pid=4388) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044fd0>
(pid=4388) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044fd0>
(pid=4388) [2020-01-30 11:38:58,342 PID:4452 INFO logger.py info] Running RL loop for trial 0 session 3
(pid=4388) [2020-01-30 11:38:58,343 PID:4440 INFO base.py post_init_nets] Initialized algorithm models for lab_mode: search
(pid=4388) [2020-01-30 11:38:58,346 PID:4452 INFO __init__.py log_summary] Trial 0 session 3 reinforce_baseline_cartpole_t0_s3 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4388) [2020-01-30 11:38:58,348 PID:4440 INFO base.py __init__] Reinforce:
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e09ac88>
(pid=4388) - algorithm_spec = {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1}
(pid=4388) - name = Reinforce
(pid=4388) - memory_spec = {'name': 'OnPolicyReplay'}
(pid=4388) - net_spec = {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e09ac88>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044cc0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) terminate called after throwing an instance of 'c10::Error'
(pid=4388) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4388) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcf770dedc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4388) frame #1: <unknown function> + 0xca67 (0x7fcf6f2daa67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4388) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcf6f9fbb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4388) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcfa636128a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4388) frame #4: <unknown function> + 0xc8421 (0x7fcfbb3bd421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4388) frame #5: <unknown function> + 0x76db (0x7fcfc0c466db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4388) frame #6: clone + 0x3f (0x7fcfc096f88f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4388)
(pid=4388) Fatal Python error: Aborted
(pid=4388)
(pid=4388) Stack (most recent call first):
(pid=4388) terminate called after throwing an instance of 'c10::Error'
(pid=4388) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4388) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcf770dedc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4388) frame #1: <unknown function> + 0xca67 (0x7fcf6f2daa67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4388) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcf6f9fbb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4388) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcfa636128a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4388) frame #4: <unknown function> + 0xc8421 (0x7fcfbb3bd421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4388) frame #5: <unknown function> + 0x76db (0x7fcfc0c466db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4388) frame #6: clone + 0x3f (0x7fcfc096f88f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4388)
(pid=4388) Fatal Python error: Aborted
(pid=4388)
(pid=4388) Stack (most recent call first):
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc6a58>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10b9a0b8>"
(pid=4389) }
(pid=4389) - action_pdtype = default
(pid=4389) - action_policy = <function default at 0x7fcc21560620>
(pid=4389) - center_return = False
(pid=4389) - explore_var_spec = None
(pid=4389) - entropy_coef_spec = {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01}
(pid=4389) - policy_loss_coef = 1.0
(pid=4389) - gamma = 0.99
(pid=4389) - training_frequency = 1
(pid=4389) - to_train = 0
(pid=4389) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10b9a080>
(pid=4389) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fcc10b9a160>
(pid=4389) - net = MLPNet(
(pid=4389) (model): Sequential(
(pid=4389) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4389) (1): SELU()
(pid=4389) )
(pid=4389) (model_tail): Sequential(
(pid=4389) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4389) )
(pid=4389) (loss_fn): MSELoss()
(pid=4389) )
(pid=4389) - net_names = ['net']
(pid=4389) - optim = Adam (
(pid=4389) Parameter Group 0
(pid=4389) amsgrad: False
(pid=4389) betas: (0.9, 0.999)
(pid=4389) eps: 1e-08
(pid=4389) lr: 0.002
(pid=4389) weight_decay: 0
(pid=4389) )
(pid=4389) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fcc10b9a400>
(pid=4389) - global_net = None
(pid=4389) [2020-01-30 11:38:58,354 PID:4458 INFO __init__.py __init__] Agent:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4389) 'action_policy': 'default',
(pid=4389) 'center_return': False,
(pid=4389) 'entropy_coef_spec': {'end_step': 20000,
(pid=4389) 'end_val': 0.001,
(pid=4389) 'name': 'linear_decay',
(pid=4389) 'start_step': 0,
(pid=4389) 'start_val': 0.01},
(pid=4389) 'explore_var_spec': None,
(pid=4389) 'gamma': 0.99,
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'training_frequency': 1},
(pid=4389) 'memory': {'name': 'OnPolicyReplay'},
(pid=4389) 'name': 'Reinforce',
(pid=4389) 'net': {'clip_grad_val': None,
(pid=4389) 'hid_layers': [64],
(pid=4389) 'hid_layers_activation': 'selu',
(pid=4389) 'loss_spec': {'name': 'MSELoss'},
(pid=4389) 'lr_scheduler_spec': None,
(pid=4389) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4389) 'type': 'MLPNet'}}
(pid=4389) - name = Reinforce
(pid=4389) - body = body: {
(pid=4389) "agent": "<slm_lab.agent.Agent object at 0x7fcc10bddd68>",
(pid=4389) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56fd0>",
(pid=4389) "a": 0,
(pid=4389) "e": 0,
(pid=4389) "b": 0,
(pid=4389) "aeb": "(0, 0, 0)",
(pid=4389) "explore_var": NaN,
(pid=4389) "entropy_coef": 0.01,
(pid=4389) "loss": NaN,
(pid=4389) "mean_entropy": NaN,
(pid=4389) "mean_grad_norm": NaN,
(pid=4389) "best_total_reward_ma": -Infinity,
(pid=4389) "total_reward_ma": NaN,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e09ad30>"
(pid=4388) }
(pid=4388) - action_pdtype = default
(pid=4388) - action_policy = <function default at 0x7fce304ad620>
(pid=4388) - center_return = True
(pid=4388) - explore_var_spec = None
(pid=4388) - entropy_coef_spec = {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01}
(pid=4388) - policy_loss_coef = 1.0
(pid=4388) - gamma = 0.99
(pid=4388) - training_frequency = 1
(pid=4388) - to_train = 0
(pid=4388) - explore_var_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e09acf8>
(pid=4388) - entropy_coef_scheduler = <slm_lab.agent.algorithm.policy_util.VarScheduler object at 0x7fce0e09ae10>
(pid=4388) - net = MLPNet(
(pid=4388) (model): Sequential(
(pid=4388) (0): Linear(in_features=4, out_features=64, bias=True)
(pid=4388) (1): SELU()
(pid=4388) )
(pid=4388) (model_tail): Sequential(
(pid=4388) (0): Linear(in_features=64, out_features=2, bias=True)
(pid=4388) )
(pid=4388) (loss_fn): MSELoss()
(pid=4388) )
(pid=4388) - net_names = ['net']
(pid=4388) - optim = Adam (
(pid=4388) Parameter Group 0
(pid=4388) amsgrad: False
(pid=4388) betas: (0.9, 0.999)
(pid=4388) eps: 1e-08
(pid=4388) lr: 0.002
(pid=4388) weight_decay: 0
(pid=4388) )
(pid=4388) - lr_scheduler = <slm_lab.agent.net.net_util.NoOpLRScheduler object at 0x7fce0e05c0b8>
(pid=4388) - global_net = None
(pid=4388) [2020-01-30 11:38:58,350 PID:4440 INFO __init__.py __init__] Agent:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - agent_spec = {'algorithm': {'action_pdtype': 'default',
(pid=4388) 'action_policy': 'default',
(pid=4388) 'center_return': True,
(pid=4388) 'entropy_coef_spec': {'end_step': 20000,
(pid=4388) 'end_val': 0.001,
(pid=4388) 'name': 'linear_decay',
(pid=4388) 'start_step': 0,
(pid=4388) 'start_val': 0.01},
(pid=4388) 'explore_var_spec': None,
(pid=4388) 'gamma': 0.99,
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'training_frequency': 1},
(pid=4388) 'memory': {'name': 'OnPolicyReplay'},
(pid=4388) 'name': 'Reinforce',
(pid=4388) 'net': {'clip_grad_val': None,
(pid=4388) 'hid_layers': [64],
(pid=4388) 'hid_layers_activation': 'selu',
(pid=4388) 'loss_spec': {'name': 'MSELoss'},
(pid=4388) 'lr_scheduler_spec': None,
(pid=4388) 'optim_spec': {'lr': 0.002, 'name': 'Adam'},
(pid=4388) 'type': 'MLPNet'}}
(pid=4388) - name = Reinforce
(pid=4388) - body = body: {
(pid=4388) "agent": "<slm_lab.agent.Agent object at 0x7fce0e09ac88>",
(pid=4388) "env": "<slm_lab.env.openai.OpenAIEnv object at 0x7fce28044cc0>",
(pid=4388) "a": 0,
(pid=4388) "e": 0,
(pid=4388) "b": 0,
(pid=4388) "aeb": "(0, 0, 0)",
(pid=4388) "explore_var": NaN,
(pid=4388) "entropy_coef": 0.01,
(pid=4388) "loss": NaN,
(pid=4388) "mean_entropy": NaN,
(pid=4388) "mean_grad_norm": NaN,
(pid=4388) "best_total_reward_ma": -Infinity,
(pid=4389) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4389) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fcc10bc6a58>",
(pid=4389) "tb_actions": [],
(pid=4389) "tb_tracker": {},
(pid=4389) "observation_space": "Box(4,)",
(pid=4389) "action_space": "Discrete(2)",
(pid=4389) "observable_dim": {
(pid=4389) "state": 4
(pid=4389) },
(pid=4389) "state_dim": 4,
(pid=4389) "action_dim": 2,
(pid=4389) "is_discrete": true,
(pid=4389) "action_type": "discrete",
(pid=4389) "action_pdtype": "Categorical",
(pid=4389) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4389) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fcc10b9a0b8>"
(pid=4389) }
(pid=4389) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fcc10b9a048>
(pid=4389) [2020-01-30 11:38:58,354 PID:4458 INFO logger.py info] Session:
(pid=4389) - spec = reinforce_baseline_cartpole
(pid=4389) - index = 3
(pid=4389) - agent = <slm_lab.agent.Agent object at 0x7fcc10bddd68>
(pid=4389) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56fd0>
(pid=4389) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fcc10c56fd0>
(pid=4389) [2020-01-30 11:38:58,354 PID:4458 INFO logger.py info] Running RL loop for trial 1 session 3
(pid=4389) [2020-01-30 11:38:58,355 PID:4456 INFO __init__.py log_summary] Trial 1 session 2 reinforce_baseline_cartpole_t1_s2 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4389) [2020-01-30 11:38:58,358 PID:4458 INFO __init__.py log_summary] Trial 1 session 3 reinforce_baseline_cartpole_t1_s3 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4388) "total_reward_ma": NaN,
(pid=4388) "train_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "eval_df": "Empty DataFrame\nColumns: [epi, t, wall_t, opt_step, frame, fps, total_reward, total_reward_ma, loss, lr, explore_var, entropy_coef, entropy, grad_norm]\nIndex: []",
(pid=4388) "tb_writer": "<torch.utils.tensorboard.writer.SummaryWriter object at 0x7fce2b00a780>",
(pid=4388) "tb_actions": [],
(pid=4388) "tb_tracker": {},
(pid=4388) "observation_space": "Box(4,)",
(pid=4388) "action_space": "Discrete(2)",
(pid=4388) "observable_dim": {
(pid=4388) "state": 4
(pid=4388) },
(pid=4388) "state_dim": 4,
(pid=4388) "action_dim": 2,
(pid=4388) "is_discrete": true,
(pid=4388) "action_type": "discrete",
(pid=4388) "action_pdtype": "Categorical",
(pid=4388) "ActionPD": "<class 'torch.distributions.categorical.Categorical'>",
(pid=4388) "memory": "<slm_lab.agent.memory.onpolicy.OnPolicyReplay object at 0x7fce0e09ad30>"
(pid=4388) }
(pid=4388) - algorithm = <slm_lab.agent.algorithm.reinforce.Reinforce object at 0x7fce0e09acc0>
(pid=4388) [2020-01-30 11:38:58,350 PID:4440 INFO logger.py info] Session:
(pid=4388) - spec = reinforce_baseline_cartpole
(pid=4388) - index = 0
(pid=4388) - agent = <slm_lab.agent.Agent object at 0x7fce0e09ac88>
(pid=4388) - env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044cc0>
(pid=4388) - eval_env = <slm_lab.env.openai.OpenAIEnv object at 0x7fce28044cc0>
(pid=4388) [2020-01-30 11:38:58,350 PID:4440 INFO logger.py info] Running RL loop for trial 0 session 0
(pid=4388) [2020-01-30 11:38:58,354 PID:4440 INFO __init__.py log_summary] Trial 0 session 0 reinforce_baseline_cartpole_t0_s0 [train_df] epi: 0 t: 0 wall_t: 0 opt_step: 0 frame: 0 fps: 0 total_reward: nan total_reward_ma: nan loss: nan lr: 0.002 explore_var: nan entropy_coef: 0.01 entropy: nan grad_norm: nan
(pid=4388) terminate called after throwing an instance of 'c10::Error'
(pid=4388) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4388) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcf770dedc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4388) frame #1: <unknown function> + 0xca67 (0x7fcf6f2daa67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4388) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcf6f9fbb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4388) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcfa636128a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4388) frame #4: <unknown function> + 0xc8421 (0x7fcfbb3bd421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4388) frame #5: <unknown function> + 0x76db (0x7fcfc0c466db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4388) frame #6: clone + 0x3f (0x7fcfc096f88f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4388)
(pid=4388) Fatal Python error: Aborted
(pid=4388)
(pid=4388) Stack (most recent call first):
(pid=4389) terminate called after throwing an instance of 'c10::Error'
(pid=4389) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4389) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcd68190dc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4389) frame #1: <unknown function> + 0xca67 (0x7fcd6038ca67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4389) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcd60aadb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4389) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcd9741328a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4389) frame #4: <unknown function> + 0xc8421 (0x7fcdac471421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4389) frame #5: <unknown function> + 0x76db (0x7fcdb1cfa6db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4389) frame #6: clone + 0x3f (0x7fcdb1a2388f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4389)
(pid=4389) Fatal Python error: Aborted
(pid=4389)
(pid=4389) Stack (most recent call first):
(pid=4389) terminate called after throwing an instance of 'c10::Error'
(pid=4389) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4389) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcd68190dc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4389) frame #1: <unknown function> + 0xca67 (0x7fcd6038ca67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4389) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcd60aadb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4389) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcd9741328a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4389) frame #4: <unknown function> + 0xc8421 (0x7fcdac471421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4389) frame #5: <unknown function> + 0x76db (0x7fcdb1cfa6db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4389) frame #6: clone + 0x3f (0x7fcdb1a2388f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4389)
(pid=4389) Fatal Python error: Aborted
(pid=4389)
(pid=4389) Stack (most recent call first):
(pid=4389) terminate called after throwing an instance of 'c10::Error'
(pid=4389) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4389) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcd68190dc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4389) frame #1: <unknown function> + 0xca67 (0x7fcd6038ca67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4389) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcd60aadb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4389) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcd9741328a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4389) frame #4: <unknown function> + 0xc8421 (0x7fcdac471421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4389) frame #5: <unknown function> + 0x76db (0x7fcdb1cfa6db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4389) frame #6: clone + 0x3f (0x7fcdb1a2388f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4389)
(pid=4389) Fatal Python error: Aborted
(pid=4389)
(pid=4389) Stack (most recent call first):
(pid=4389) terminate called after throwing an instance of 'c10::Error'
(pid=4389) what(): CUDA error: initialization error (getDevice at /opt/conda/conda-bld/pytorch_1556653114079/work/c10/cuda/impl/CUDAGuardImpl.h:35)
(pid=4389) frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x45 (0x7fcd68190dc5 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10.so)
(pid=4389) frame #1: <unknown function> + 0xca67 (0x7fcd6038ca67 in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libc10_cuda.so)
(pid=4389) frame #2: torch::autograd::Engine::thread_init(int) + 0x3ee (0x7fcd60aadb1e in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch.so.1)
(pid=4389) frame #3: torch::autograd::python::PythonEngine::thread_init(int) + 0x2a (0x7fcd9741328a in /home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
(pid=4389) frame #4: <unknown function> + 0xc8421 (0x7fcdac471421 in /home/joe/anaconda3/envs/lab/bin/../lib/libstdc++.so.6)
(pid=4389) frame #5: <unknown function> + 0x76db (0x7fcdb1cfa6db in /lib/x86_64-linux-gnu/libpthread.so.0)
(pid=4389) frame #6: clone + 0x3f (0x7fcdb1a2388f in /lib/x86_64-linux-gnu/libc.so.6)
(pid=4389)
(pid=4389) Fatal Python error: Aborted
(pid=4389)
(pid=4389) Stack (most recent call first):
(pid=4388) 2020-01-30 11:38:58,550 ERROR function_runner.py:96 -- Runner Thread raised error.
(pid=4388) Traceback (most recent call last):
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 90, in run
(pid=4388) self._entrypoint()
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 141, in entrypoint
(pid=4388) return self._trainable_func(config, self._status_reporter)
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 249, in _trainable_func
(pid=4388) output = train_func(config, reporter)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/search.py", line 90, in ray_trainable
(pid=4388) metrics = Trial(spec).run()
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/control.py", line 181, in run
(pid=4388) metrics = analysis.analyze_trial(self.spec, session_metrics_list)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 265, in analyze_trial
(pid=4388) trial_metrics = calc_trial_metrics(session_metrics_list, info_prepath)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 187, in calc_trial_metrics
(pid=4388) frames = session_metrics_list[0]['local']['frames']
(pid=4388) IndexError: list index out of range
(pid=4388) Exception in thread Thread-1:
(pid=4388) Traceback (most recent call last):
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 90, in run
(pid=4388) self._entrypoint()
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 141, in entrypoint
(pid=4388) return self._trainable_func(config, self._status_reporter)
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 249, in _trainable_func
(pid=4388) output = train_func(config, reporter)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/search.py", line 90, in ray_trainable
(pid=4388) metrics = Trial(spec).run()
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/control.py", line 181, in run
(pid=4388) metrics = analysis.analyze_trial(self.spec, session_metrics_list)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 265, in analyze_trial
(pid=4388) trial_metrics = calc_trial_metrics(session_metrics_list, info_prepath)
(pid=4388) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 187, in calc_trial_metrics
(pid=4388) frames = session_metrics_list[0]['local']['frames']
(pid=4388) IndexError: list index out of range
(pid=4388)
(pid=4388) During handling of the above exception, another exception occurred:
(pid=4388)
(pid=4388) Traceback (most recent call last):
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/threading.py", line 917, in _bootstrap_inner
(pid=4388) self.run()
(pid=4388) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 102, in run
(pid=4388) err_tb = err_tb.format_exc()
(pid=4388) AttributeError: 'traceback' object has no attribute 'format_exc'
(pid=4388)
(pid=4389) 2020-01-30 11:38:58,570 ERROR function_runner.py:96 -- Runner Thread raised error.
(pid=4389) Traceback (most recent call last):
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 90, in run
(pid=4389) self._entrypoint()
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 141, in entrypoint
(pid=4389) return self._trainable_func(config, self._status_reporter)
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 249, in _trainable_func
(pid=4389) output = train_func(config, reporter)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/search.py", line 90, in ray_trainable
(pid=4389) metrics = Trial(spec).run()
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/control.py", line 181, in run
(pid=4389) metrics = analysis.analyze_trial(self.spec, session_metrics_list)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 265, in analyze_trial
(pid=4389) trial_metrics = calc_trial_metrics(session_metrics_list, info_prepath)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 187, in calc_trial_metrics
(pid=4389) frames = session_metrics_list[0]['local']['frames']
(pid=4389) IndexError: list index out of range
(pid=4389) Exception in thread Thread-1:
(pid=4389) Traceback (most recent call last):
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 90, in run
(pid=4389) self._entrypoint()
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 141, in entrypoint
(pid=4389) return self._trainable_func(config, self._status_reporter)
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 249, in _trainable_func
(pid=4389) output = train_func(config, reporter)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/search.py", line 90, in ray_trainable
(pid=4389) metrics = Trial(spec).run()
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/control.py", line 181, in run
(pid=4389) metrics = analysis.analyze_trial(self.spec, session_metrics_list)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 265, in analyze_trial
(pid=4389) trial_metrics = calc_trial_metrics(session_metrics_list, info_prepath)
(pid=4389) File "/home/joe/SLM-Lab/slm_lab/experiment/analysis.py", line 187, in calc_trial_metrics
(pid=4389) frames = session_metrics_list[0]['local']['frames']
(pid=4389) IndexError: list index out of range
(pid=4389)
(pid=4389) During handling of the above exception, another exception occurred:
(pid=4389)
(pid=4389) Traceback (most recent call last):
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/threading.py", line 917, in _bootstrap_inner
(pid=4389) self.run()
(pid=4389) File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 102, in run
(pid=4389) err_tb = err_tb.format_exc()
(pid=4389) AttributeError: 'traceback' object has no attribute 'format_exc'
(pid=4389)
2020-01-30 11:38:59,690 ERROR trial_runner.py:497 -- Error processing event.
Traceback (most recent call last):
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/trial_runner.py", line 446, in _process_trial
result = self.trial_executor.fetch_result(trial)
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/ray_trial_executor.py", line 316, in fetch_result
result = ray.get(trial_future[0])
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/worker.py", line 2197, in get
raise value
ray.exceptions.RayTaskError: ray_worker (pid=4388, host=Gauss)
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/trainable.py", line 151, in train
result = self._train()
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 203, in _train
("Wrapped function ran until completion without reporting "
ray.tune.error.TuneError: Wrapped function ran until completion without reporting results or raising an exception.
2020-01-30 11:38:59,694 INFO ray_trial_executor.py:180 -- Destroying actor for trial ray_trainable_0_agent.0.algorithm.center_return=True,trial_index=0. If your trainable is slow to initialize, consider setting reuse_actors=True to reduce actor creation overheads.
2020-01-30 11:38:59,705 ERROR trial_runner.py:497 -- Error processing event.
Traceback (most recent call last):
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/trial_runner.py", line 446, in _process_trial
result = self.trial_executor.fetch_result(trial)
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/ray_trial_executor.py", line 316, in fetch_result
result = ray.get(trial_future[0])
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/worker.py", line 2197, in get
raise value
ray.exceptions.RayTaskError: ray_worker (pid=4389, host=Gauss)
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/trainable.py", line 151, in train
result = self._train()
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/function_runner.py", line 203, in _train
("Wrapped function ran until completion without reporting "
ray.tune.error.TuneError: Wrapped function ran until completion without reporting results or raising an exception.
2020-01-30 11:38:59,707 INFO ray_trial_executor.py:180 -- Destroying actor for trial ray_trainable_1_agent.0.algorithm.center_return=False,trial_index=1. If your trainable is slow to initialize, consider setting reuse_actors=True to reduce actor creation overheads.
== Status ==
Using FIFO scheduling algorithm.
Resources requested: 0/8 CPUs, 0/1 GPUs
Memory usage on this node: 2.5/16.7 GB
Result logdir: /home/joe/ray_results/reinforce_baseline_cartpole
Number of trials: 2 ({'ERROR': 2})
ERROR trials:
- ray_trainable_0_agent.0.algorithm.center_return=True,trial_index=0: ERROR, 1 failures: /home/joe/ray_results/reinforce_baseline_cartpole/ray_trainable_0_agent.0.algorithm.center_return=True,trial_index=0_2020-01-30_11-38-57n2qc80ke/error_2020-01-30_11-38-59.txt
- ray_trainable_1_agent.0.algorithm.center_return=False,trial_index=1: ERROR, 1 failures: /home/joe/ray_results/reinforce_baseline_cartpole/ray_trainable_1_agent.0.algorithm.center_return=False,trial_index=1_2020-01-30_11-38-57unqmlqvg/error_2020-01-30_11-38-59.txt
Traceback (most recent call last):
File "run_lab.py", line 80, in <module>
main()
File "run_lab.py", line 72, in main
read_spec_and_run(*args)
File "run_lab.py", line 56, in read_spec_and_run
run_spec(spec, lab_mode)
File "run_lab.py", line 35, in run_spec
Experiment(spec).run()
File "/home/joe/SLM-Lab/slm_lab/experiment/control.py", line 203, in run
trial_data_dict = search.run_ray_search(self.spec)
File "/home/joe/SLM-Lab/slm_lab/experiment/search.py", line 124, in run_ray_search
server_port=util.get_port(),
File "/home/joe/anaconda3/envs/lab/lib/python3.7/site-packages/ray/tune/tune.py", line 265, in run
raise TuneError("Trials did not complete", errored_trials)
ray.tune.error.TuneError: ('Trials did not complete', [ray_trainable_0_agent.0.algorithm.center_return=True,trial_index=0, ray_trainable_1_agent.0.algorithm.center_return=False,trial_index=1])


















































































































































































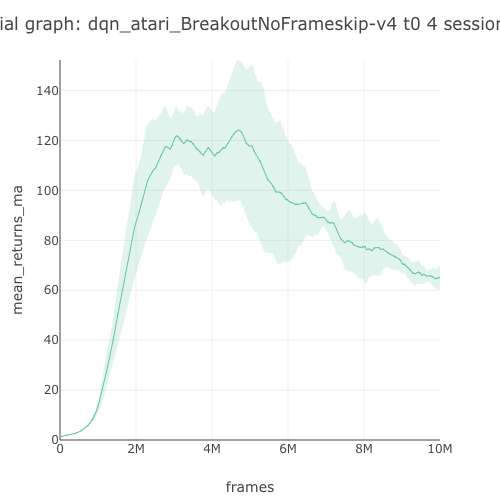{kind=link}