yancie-yjr / streamyolo Goto Github PK
View Code? Open in Web Editor NEWReal-time Object Detection for Streaming Perception, CVPR 2022
License: Apache License 2.0
Real-time Object Detection for Streaming Perception, CVPR 2022
License: Apache License 2.0


















































































































Hey @yancie-yjr, this project looks great! I had a question regarding using multiple cameras with one model.
Imagine a situation where you have N number of cameras for a car and a device that can run only one StreamYOLO model for inferencing. Can we get away with detecting on those N cameras by generating N feature buffers and swapping them out for each camera?
How can I use the repo to train a model?
hi everyone, I got this issue
...File "cfgs/m_s50_onex_dfp_tal_flip.py", line 189, in get_trainer
from exps.train_utils.double_trainer import Trainer
ModuleNotFoundError: No module named 'exps'
Actually I ran code on local I got this error but when I try "echo export PYTHONPATH=$PYTHONPATH:$ADDPATH >> " it worked. But as you can guess my local GPU didn't enough for training. And I established everything on colab but this time "echo export..." didn't save me.
Hi, @GOATmessi7 @yancie-yjr great wokrs. Can you enrich the readme about datasets preparing、how to training & validation and so on. hope to finish it soon. thanks
Hi, I have read your paper.
I have a question in figure 2.
On the page3 in the paper, you wrote the expression "the output y1 of the frame F1 is matched and evaluated with the ground truth of F3 and the result of F2 is missed" about Figure 2.
I understood like that expression mean y1 is the output of the none-real-time detectors of frame F1.
But, before the frame F3 is received, the frame F2 is received in first.
So I can't understand that point and I also want to ask when the output of the frame f0 come out.
page not found
Hi, thank you for suggesting your nice code.
I trained the model using Argoverse dataset following your readme.
I want to run demo and save detection results (image or video), how can i do that?
thank you.
请问可视化怎么实现呀
您好,我通过下载yolox==0.3对应的.whl文件来安装,找了好几个镜像源都没有找到我需要的yolox-0.3.0-cp37-cp37m-manylinux1_x86_64.whl,我要在哪里能找到呢
Hi!
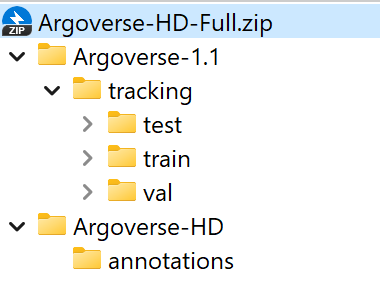
When reproducing your results on Argoverse-HD, I found that the directory structure you provided in Quick Start - Dataset preparation section doesn't match the original directory structure of Argoverse-HD dataset, as well as your code required.
The directory structure in Quick Start - Dataset preparation section:
StreamYOLO
├── exps
├── tools
├── yolox
├── data
│ ├── Argoverse-1.1
│ │ ├── annotations
│ │ ├── tracking
│ │ ├── train
│ │ ├── val
│ │ ├── test
│ ├── Argoverse-HD
│ │ ├── annotations
│ │ ├── test-meta.json
│ │ ├── train.json
│ │ ├── val.json
should be edited as:
StreamYOLO
├── exps
├── tools
├── yolox
├── data
│ ├── Argoverse-1.1
│ │ ├── tracking
│ │ ├── train
│ │ ├── val
│ │ ├── test
│ ├── Argoverse-HD
│ │ ├── annotations
│ │ ├── test-meta.json
│ │ ├── train.json
│ │ ├── val.json
which matches the directory structure of the Argoverse-HD dataset:
BTW, if anyone manually modifies the directory structure to fit the one provided in README, an AssertionError will occur: (some parts of file path was edited)
AssertionError: Caught AssertionError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "%HOME%\anaconda3\envs\streamyolo\lib\site-packages\torch\utils\data\_utils\worker.py", line 198, in _worker_loop
data = fetcher.fetch(index)
File "%HOME%\anaconda3\envs\streamyolo\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "%HOME%\anaconda3\envs\streamyolo\lib\site-packages\torch\utils\data\_utils\fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "%HOME%\anaconda3\envs\streamyolo\lib\site-packages\yolox\data\datasets\datasets_wrapper.py", line 110, in wrapper
ret_val = getitem_fn(self, index)
File "%WORKSPACE%\StreamYOLO\exps\data\tal_flip_mosaicdetection.py", line 255, in __getitem__
img, support_img, label, support_label, img_info, id_ = self._dataset.pull_item(idx)
File "%WORKSPACE%\StreamYOLO\exps\dataset\tal_flip_one_future_argoversedataset.py", line 227, in pull_item
img = self.load_resized_img(index)
File "%WORKSPACE%\StreamYOLO\exps\dataset\tal_flip_one_future_argoversedataset.py", line 180, in load_resized_img
img = self.load_image(index)
File "%WORKSPACE%\StreamYOLO\exps\dataset\tal_flip_one_future_argoversedataset.py", line 196, in load_image
assert img is not None
AssertionError
If anyone gets the similar error message, the content in For Developers may be helpful.
Well done, waiting for your code!
when I tried to train
File "/home/pe/projects/czy/StreamYOLO-main/exps/train_utils/double_trainer.py", line 314, in resume_train
ckpt = torch.load(ckpt_file, map_location=self.device)["model"]
│ │ │ │ └ 'cuda:0'
│ │ │ └ <exps.train_utils.double_trainer.Trainer object at 0x7fe2e69a3650>
│ │ └ '/home/pe/projects/czy/StreamYOLO-main/tools/yolox_s.pth'
│ └ <function load at 0x7fe2e8dc8710>
└ <module 'torch' from '/home/pe/anaconda3/envs/streamyolo/lib/python3.7/site-packages/torch/init.py'>
KeyError: 'model'
Could you tell me how to solve this?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.