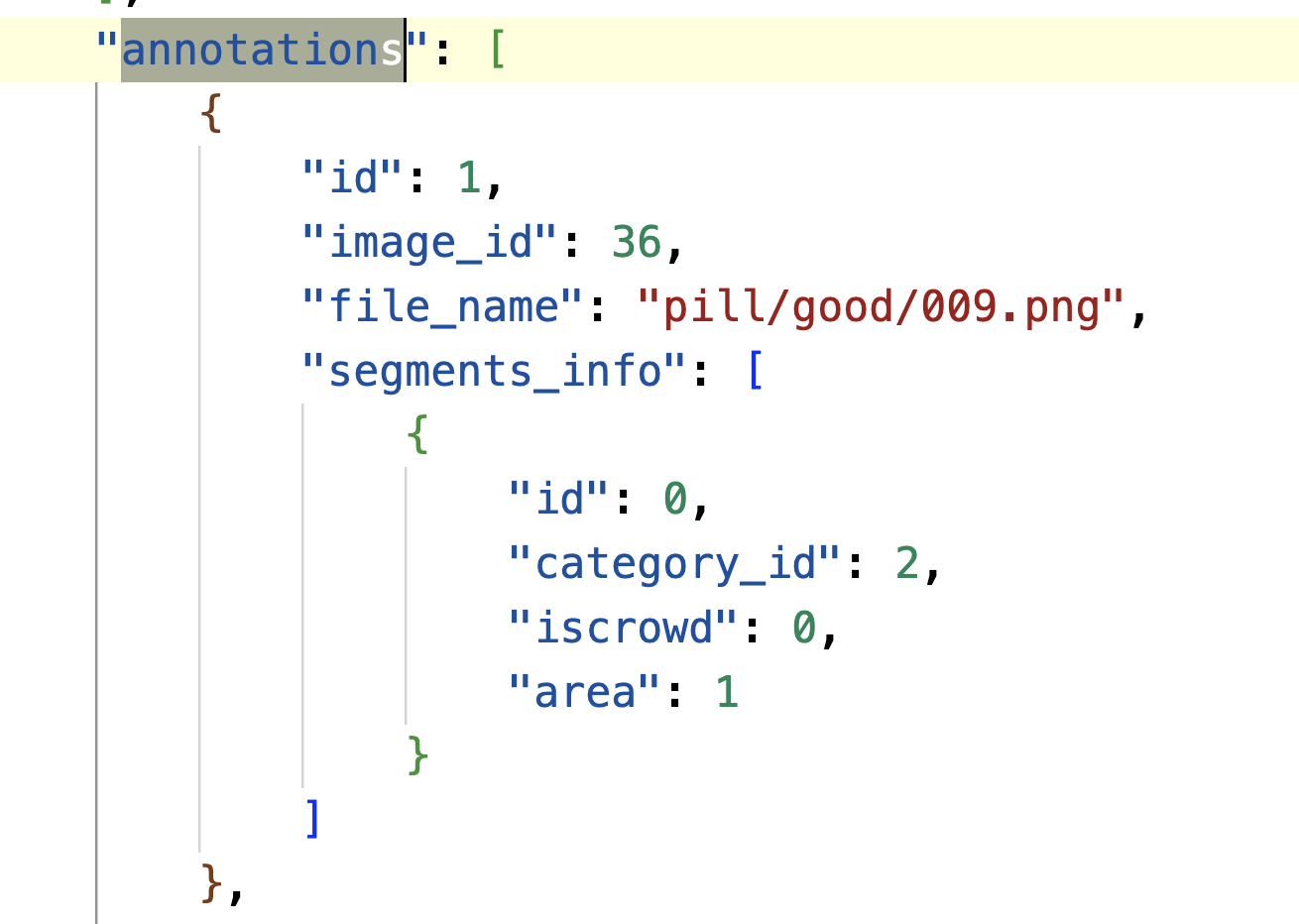
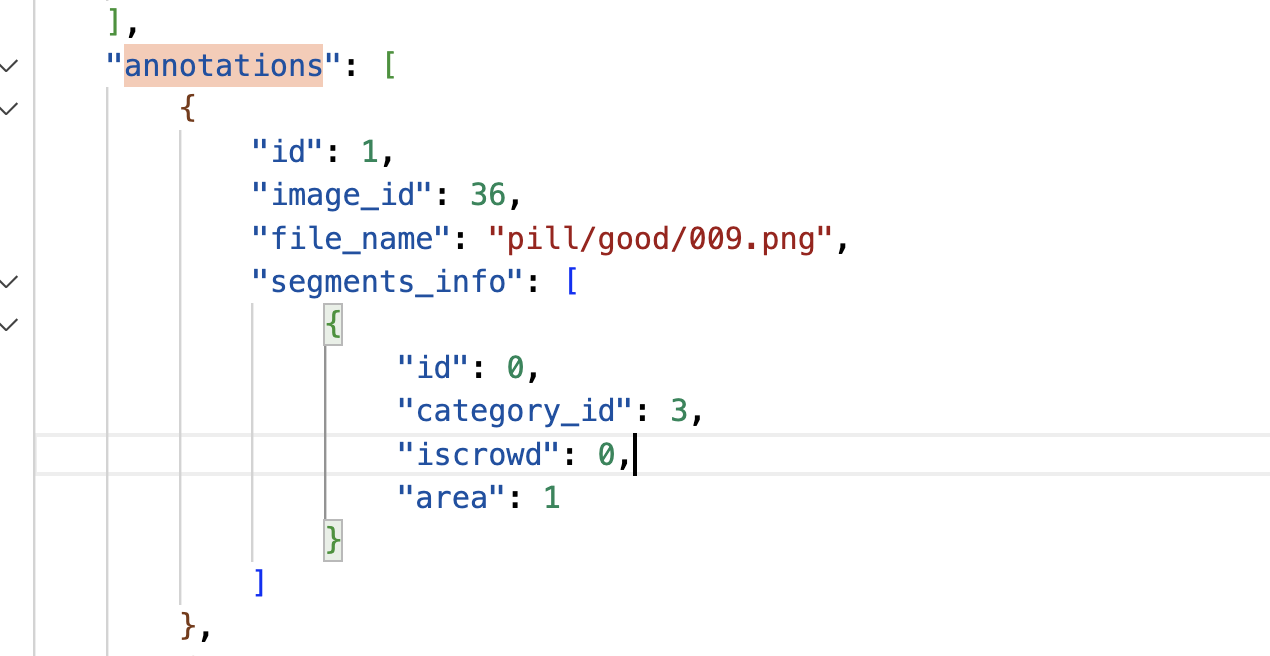
I'm working on finetuning the PSALM model after stage 2 for an anomaly detection task on my own dataset, which consists of two categories: 1. Defective 2. Good
① if an image is "defective" then it has the ground_truth mask with 2 categories (black and white)
2024-06-07 09:47:31,609] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-06-07 09:47:33,356] [WARNING] [runner.py:196:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2024-06-07 09:47:33,357] [INFO] [runner.py:555:main] cmd = /root/miniforge3/envs/psalm/bin/python3.10 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 --enable_each_rank_log=None psalm/train/finetune.py --deepspeed ./scripts/zero2.json --model_name_or_path /liujinxin/code/models/PSALM/models/PSALM --version llava_phi --panoptic_json_path /liujinxin/code/models/PSALM/datasets/coco_white_gray --image_folder /liujinxin/code/models/PSALM/datasets/coco_white_gray/train2017 --mm_vision_select_layer -2 --mm_use_im_start_end False --mm_use_im_patch_token False --fp16 True --output_dir ./checkpoint/PSALM_white_gray2 --num_train_epochs 10 --per_device_train_batch_size 4 --per_device_eval_batch_size 2 --gradient_accumulation_steps 1 --evaluation_strategy no --save_strategy steps --save_steps 15000 --save_total_limit 1 --learning_rate 6e-6 --weight_decay 0. --warmup_ratio 0.03 --lr_scheduler_type cosine --logging_steps 1 --tf32 False --model_max_length 2048 --gradient_checkpointing True --dataloader_num_workers 4 --lazy_preprocess True --report_to none --seg_task panoptic
[2024-06-07 09:47:34,975] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-06-07 09:47:37,134] [INFO] [launch.py:145:main] WORLD INFO DICT: {'localhost': [0]}
[2024-06-07 09:47:37,134] [INFO] [launch.py:151:main] nnodes=1, num_local_procs=1, node_rank=0
[2024-06-07 09:47:37,134] [INFO] [launch.py:162:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2024-06-07 09:47:37,134] [INFO] [launch.py:163:main] dist_world_size=1
[2024-06-07 09:47:37,134] [INFO] [launch.py:165:main] Setting CUDA_VISIBLE_DEVICES=0
[2024-06-07 09:47:39,886] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-06-07 09:47:41,309] [WARNING] [comm.py:152:init_deepspeed_backend] NCCL backend in DeepSpeed not yet implemented
[2024-06-07 09:47:41,309] [INFO] [comm.py:594:init_distributed] cdb=None
[2024-06-07 09:47:41,309] [INFO] [comm.py:625:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
using model PSALM
loading segmentation model
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
current model is psalm
Mask Decoder has been trained, init directly
current seg concat mode: False, seg_norm: False, seg_proj: True, seg_fuse_score: False
Loading checkpoint shards: 100%|██████████████████████████████████████████████| 2/2 [00:21<00:00, 10.98s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
coco_id_to_cont_id: {1: 0, 2: 1}
coco_class_name: ['defective', 'good']
total unify dataset number is 132
Rank: 0 partition count [1, 1] and sizes[(1436624896, False), (623040, False)]
0%| | 0/330 [00:00<?, ?it/s]panoptic_coco
{'loss_mask': 49.85839080810547, 'loss_dice': 24.046592712402344, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.289311408996582, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0}
{'loss': 81.1943, 'learning_rate': 0.0, 'epoch': 0.03}
0%|▏ | 1/330 [00:04<26:22, 4.81s/it]panoptic_coco
{'loss_mask': 52.50733184814453, 'loss_dice': 23.399078369140625, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.860533237457275, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.03}
{'loss': 82.7669, 'learning_rate': 0.0, 'epoch': 0.06}
1%|▍ | 2/330 [00:05<12:59, 2.38s/it]panoptic_coco
{'loss_mask': 49.13460159301758, 'loss_dice': 23.756378173828125, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.406155586242676, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.06}
{'loss': 80.2971, 'learning_rate': 0.0, 'epoch': 0.09}
1%|▋ | 3/330 [00:06<08:44, 1.60s/it]panoptic_coco
{'loss_mask': 48.565338134765625, 'loss_dice': 24.029932022094727, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.697427272796631, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.09}
{'loss': 79.2927, 'learning_rate': 0.0, 'epoch': 0.12}
1%|▊ | 4/330 [00:06<06:47, 1.25s/it]panoptic_coco
{'loss_mask': 49.155311584472656, 'loss_dice': 24.500837326049805, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.502076148986816, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.12}
{'loss': 80.1582, 'learning_rate': 0.0, 'epoch': 0.15}
2%|█ | 5/330 [00:07<05:38, 1.04s/it]panoptic_coco
{'loss_mask': 48.19862365722656, 'loss_dice': 23.695858001708984, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.095686912536621, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.15}
{'loss': 78.9902, 'learning_rate': 0.0, 'epoch': 0.18}
2%|█▎ | 6/330 [00:08<04:57, 1.09it/s]panoptic_coco
{'loss_mask': 51.16276550292969, 'loss_dice': 23.66861343383789, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.111388206481934, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.18}
{'loss': 81.9428, 'learning_rate': 0.0, 'epoch': 0.21}
2%|█▌ | 7/330 [00:08<04:35, 1.17it/s]panoptic_coco
{'loss_mask': 49.68932342529297, 'loss_dice': 23.382747650146484, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.24033784866333, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.21}
{'loss': 80.3124, 'learning_rate': 0.0, 'epoch': 0.24}
2%|█▋ | 8/330 [00:09<04:23, 1.22it/s]panoptic_coco
{'loss_mask': 50.03607940673828, 'loss_dice': 23.745264053344727, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.563680648803711, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.24}
{'loss': 80.345, 'learning_rate': 6.000000000000001e-07, 'epoch': 0.27}
3%|█▉ | 9/330 [00:10<04:25, 1.21it/s]panoptic_coco
{'loss_mask': 51.757225036621094, 'loss_dice': 23.377241134643555, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.948200702667236, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.27}
{'loss': 82.0827, 'learning_rate': 1.2000000000000002e-06, 'epoch': 0.3}
3%|██ | 10/330 [00:11<04:30, 1.18it/s]panoptic_coco
{'loss_mask': 53.21855163574219, 'loss_dice': 23.796293258666992, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.505247116088867, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.3}
{'loss': 84.5201, 'learning_rate': 1.8e-06, 'epoch': 0.33}
3%|██▎ | 11/330 [00:12<04:35, 1.16it/s]panoptic_coco
{'loss_mask': 49.33003616333008, 'loss_dice': 23.544994354248047, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.133486747741699, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.33}
{'loss': 80.0085, 'learning_rate': 2.4000000000000003e-06, 'epoch': 0.36}
4%|██▌ | 12/330 [00:13<04:34, 1.16it/s]panoptic_coco
{'loss_mask': 50.854331970214844, 'loss_dice': 23.77133560180664, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.8431196212768555, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.36}
{'loss': 81.4688, 'learning_rate': 3e-06, 'epoch': 0.39}
4%|██▊ | 13/330 [00:14<04:32, 1.16it/s]panoptic_coco
{'loss_mask': 53.42914962768555, 'loss_dice': 23.217002868652344, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.458742141723633, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.39}
{'loss': 83.1049, 'learning_rate': 3e-06, 'epoch': 0.42}
4%|██▉ | 14/330 [00:14<04:18, 1.22it/s]panoptic_coco
{'loss_mask': 53.33277893066406, 'loss_dice': 23.60284423828125, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.294776916503906, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.42}
{'loss': 83.2304, 'learning_rate': 3.6e-06, 'epoch': 0.45}
5%|███▏ | 15/330 [00:15<04:25, 1.19it/s]panoptic_coco
{'loss_mask': 52.171478271484375, 'loss_dice': 23.656320571899414, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.994977951049805, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.45}
{'loss': 81.8228, 'learning_rate': 4.2e-06, 'epoch': 0.48}
5%|███▍ | 16/330 [00:16<04:26, 1.18it/s]panoptic_coco
{'loss_mask': 48.39109420776367, 'loss_dice': 23.990428924560547, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.271108627319336, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.48}
{'loss': 78.6526, 'learning_rate': 4.800000000000001e-06, 'epoch': 0.52}
5%|███▌ | 17/330 [00:17<04:26, 1.18it/s]panoptic_coco
{'loss_mask': 49.93635177612305, 'loss_dice': 23.715030670166016, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.401008605957031, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.52}
{'loss': 80.0524, 'learning_rate': 5.4e-06, 'epoch': 0.55}
5%|███▊ | 18/330 [00:18<04:24, 1.18it/s]panoptic_coco
{'loss_mask': 49.057777404785156, 'loss_dice': 24.252079010009766, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.318177700042725, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.55}
{'loss': 80.628, 'learning_rate': 6e-06, 'epoch': 0.58}
6%|████ | 19/330 [00:19<04:34, 1.13it/s]panoptic_coco
{'loss_mask': 47.64111328125, 'loss_dice': 23.820335388183594, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.369119644165039, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.58}
{'loss': 78.8306, 'learning_rate': 5.999855426877984e-06, 'epoch': 0.61}
6%|████▏ | 20/330 [00:20<04:49, 1.07it/s]panoptic_coco
{'loss_mask': 45.717586517333984, 'loss_dice': 23.78108024597168, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.449423789978027, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.61}
{'loss': 75.9481, 'learning_rate': 5.999421721446195e-06, 'epoch': 0.64}
6%|████▍ | 21/330 [00:21<04:57, 1.04it/s]panoptic_coco
{'loss_mask': 44.83399200439453, 'loss_dice': 24.038347244262695, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.863902568817139, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.64}
{'loss': 74.7362, 'learning_rate': 5.998698925506064e-06, 'epoch': 0.67}
7%|████▋ | 22/330 [00:22<05:05, 1.01it/s]panoptic_coco
{'loss_mask': 45.72657012939453, 'loss_dice': 24.009532928466797, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.071250915527344, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.67}
{'loss': 75.8074, 'learning_rate': 5.997687108722169e-06, 'epoch': 0.7}
7%|████▉ | 23/330 [00:23<04:53, 1.05it/s]panoptic_coco
{'loss_mask': 45.27854919433594, 'loss_dice': 24.46664047241211, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.600783348083496, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.7}
{'loss': 75.346, 'learning_rate': 5.996386368615517e-06, 'epoch': 0.73}
7%|█████ | 24/330 [00:24<04:53, 1.04it/s]panoptic_coco
{'loss_mask': 42.8742790222168, 'loss_dice': 22.759302139282227, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.884395122528076, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.73}
8%|███▏ | 25/330 [00:25<04:44, 1.07it/s]{'loss': 71.518, 'learning_rate': 5.994796830554148e-06, 'epoch': 0.76}
8%|███▏ | 25/330 [00:25<04:44, 1.07it/s]panoptic_coco
{'loss_mask': 42.58303451538086, 'loss_dice': 24.098745346069336, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.326217174530029, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.76}
{'loss': 73.008, 'learning_rate': 5.992918647741047e-06, 'epoch': 0.79}
8%|█████▌ | 26/330 [00:25<04:39, 1.09it/s]panoptic_coco
{'loss_mask': 43.64096450805664, 'loss_dice': 23.229507446289062, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.295878887176514, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.79}
{'loss': 73.1663, 'learning_rate': 5.990752001199384e-06, 'epoch': 0.82}
8%|█████▋ | 27/330 [00:26<04:39, 1.08it/s]panoptic_coco
{'loss_mask': 43.896018981933594, 'loss_dice': 22.761449813842773, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.161799430847168, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.82}
{'loss': 72.8193, 'learning_rate': 5.988297099755062e-06, 'epoch': 0.85}
8%|█████▉ | 28/330 [00:27<04:35, 1.10it/s]panoptic_coco
{'loss_mask': 41.98052978515625, 'loss_dice': 23.672922134399414, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.856027603149414, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.85}
{'loss': 72.5095, 'learning_rate': 5.985554180016591e-06, 'epoch': 0.88}
9%|██████▏ | 29/330 [00:28<04:31, 1.11it/s]panoptic_coco
{'loss_mask': 40.907073974609375, 'loss_dice': 23.011926651000977, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.6860032081604, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.88}
{'loss': 70.605, 'learning_rate': 5.982523506352285e-06, 'epoch': 0.91}
9%|██████▎ | 30/330 [00:29<04:28, 1.12it/s]panoptic_coco
{'loss_mask': 40.939064025878906, 'loss_dice': 22.917320251464844, 'loss_SEG_class': 0.0, 'loss_class_name_class': 7.153843879699707, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.91}
{'loss': 71.0102, 'learning_rate': 5.979205370864779e-06, 'epoch': 0.94}
9%|██████▌ | 31/330 [00:30<04:23, 1.13it/s]panoptic_coco
{'loss_mask': 40.88875961303711, 'loss_dice': 23.06298828125, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.79106330871582, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.94}
{'loss': 69.7428, 'learning_rate': 5.9756000933628785e-06, 'epoch': 0.97}
10%|██████▊ | 32/330 [00:31<04:27, 1.11it/s]panoptic_coco
{'loss_mask': 40.81318283081055, 'loss_dice': 21.933622360229492, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.372218132019043, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 0.97}
{'loss': 69.119, 'learning_rate': 5.971708021330732e-06, 'epoch': 1.0}
10%|███████ | 33/330 [00:32<04:35, 1.08it/s]panoptic_coco
{'loss_mask': 39.913272857666016, 'loss_dice': 20.571090698242188, 'loss_SEG_class': 0.0, 'loss_class_name_class': 6.420867919921875, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 1.0}
{'loss': 66.9052, 'learning_rate': 5.967529529894344e-06, 'epoch': 1.03}
10%|███████▏ | 34/330 [00:34<06:03, 1.23s/it]panoptic_coco
{'loss_mask': 35.99129104614258, 'loss_dice': 18.98656463623047, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.745621204376221, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 1.03}
{'loss': 60.7235, 'learning_rate': 5.963065021785414e-06, 'epoch': 1.06}
11%|███████▍ | 35/330 [00:35<05:29, 1.12s/it]panoptic_coco
{'loss_mask': 34.689720153808594, 'loss_dice': 20.849706649780273, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.4378204345703125, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 1.06}
{'loss': 60.9772, 'learning_rate': 5.958314927302526e-06, 'epoch': 1.09}
11%|███████▋ | 36/330 [00:35<05:05, 1.04s/it]panoptic_coco
{'loss_mask': 31.195430755615234, 'loss_dice': 17.665014266967773, 'loss_SEG_class': 0.0, 'loss_class_name_class': 5.153102874755859, 'loss_region_class': 0.0, 'loss_llm': 0.0, 'epoch': 1.09}
{'loss': 54.0135, 'learning_rate': 5.953279704269675e-06, 'epoch': 1.12}
11%|███████▊ | 37/330 [00:36<04:48, 1.02it/s]
PS: ①if the training set is with the mask which is all with category 1, it works like this:
......
......
















































")
























")






")