aharley / simple_bev Goto Github PK
View Code? Open in Web Editor NEWA Simple Baseline for BEV Perception
License: MIT License
A Simple Baseline for BEV Perception
License: MIT License













































































































Hi!
I am currently training and testing the "Cam+Rad" and "Only Cam" BEV models on my dataset.
My dataset sensor configuration is as follows:
[Cam+Rad BEV]
First of all, the Cam+Rad BEV visualization results work just fine:

[Only Cam BEV]
However, there is a problem with the Only RGB cam BEV. The final learning result using Only RGB cam is as follows.

And, Only RGB cam visualization results are BEV weird..

What am I missing?
Thank you so much for always helping.
How much gpu memory needed for training this model at batch size 1(6 cams+radar) in normal input resolution(448×800)?
Single RTX3090 will do? (I only have one RTX3070)
Hi !
I tested it with the code committed on 31 Aug.
But now it seems that various files (vox.py, nuscenesdataset.py, train_nuscenes.py) have been updated.
What has changed?
hi, Adam W.
did you encounter single card training is normal, but there is nan with multiple cards

I am currently training the bev model with my dataset.
However, after enough steps, the total loss becomes negative as shown below.

After debugging, when calculating uncertainty_loss(ce_uncertainty_loss, center_uncertainty_loss, offset_uncertainty_loss),
weight(model.module.ce_weight, model.module.center_weight, model.module.offset_weight) is negative.

Are there any possible causes?
Hi,
thank you for the nice work and for sharing your code!
I believe that your implementation of BEVFormer has a small bug:
simple_bev/nets/bevformernet.py
Line 296 in be46f0e
It looks like the values for the parameters n_heads and n_points have been swapped compared to the normal initialization
See also the original implementation of BEVFormer:
def __init__(self, embed_dims=256, num_heads=8, num_levels=4, num_points=4,
https://github.com/fundamentalvision/BEVFormer/blob/20923e66aa26a906ba8d21477c238567fa6285e9/projects/mmdet3d_plugin/bevformer/modules/decoder.py#L160-L164
as well as the Deformable DETR paper:
M = 8 and K = 4 are set for deformable attentions by default.
K number of sampled keys in each feature level for each attention head
M number of attention heads
I am not sure how much of a difference it is going to make but just to warn other people.
Hi! First of all thank you for the great quality of this work, both the paper and the code.
I have a couple of doubts regarding the backbone:
Hello,
Thank you for your great work. I have a question concerning your results, especially the visibility filter that seems to be activated in your training code (cf. valid_bev_g during loss and metric calculation).
Did you use this filter for your tables in your paper ? It seems to have a big impact on metrics I got and some of the papers you compare with do not use this filter (cf. FIERY that overwrittes the filtering argument to False while training and evaluating).
Thank you in advance
For test, I'm trying to train a Cam+Rad BEV model with a NuScenes mini dataset.
But, iou_v is nan as shown below.

Could you please share your training log for debugging?
Hey, really cool to see a simple BEV method which out performs many strong baseline.
I have a question about 3D object bounding box detection. Did the authors also tried object detection task along with the semantic segmentation task? Any insights would be appreciated. Thank You !
Hi, thanks again for the nice work!
With larger or lesser gradient accumulation, does it necessary to adjust the learning rate such as increasing and decreasing, respectively? Thanks again!
Hello, could you explain what GPU you used to train models, and how long does it take?
I can see that some other models is finished in “net” folder, such as "liftnet" and "bevformernet". I want to run these models. The root is
simple_bev/nets/bevformernet.py
Line 400 in be46f0e
I search this models with Pycharm, but I can't find anywhere to use these models.
The only model used is Segnet, where in
Line 362 in be46f0e
Would you please tell me how to run other models in nuscenes dataset? Where should I modify in code?
Thank you~
Hi,
I have tried converting the simpleBEV model to onnx using the torch.onnx.export , however I am facing an issue in generating the dummy input required for the forward pass in the conversion process.
I am getting this below error :
RuntimeError: Only tuples, lists and Variables are supported as JIT inputs/outputs. Dictionaries and strings are also accepted, but their usage is not recommended. Here, received an input of unsupported type: Vox_util
Hi,
Thank you for your research.
Could you give me some tips about "Lift" operation in Code,
may be here:
Lines 291 to 341 in be46f0e
Firstly i think the motivation of this paper is very insightful and the conclusion is solid enough, thanks the authors for your effort.
I'm curious about the "randomize reference cam augmentation" mentioned in this paper. I found the first camera and the randomized camera are swapped in code to make sure the 0th cam is randomized referenced camera, but i don't understand what the motivation of this augmentation is and how it's done in detail. Can you explain it or provide the reference paper (if exists). Besides, the paper mentioned "We have observed qualitatively that without this augmentation, the segmented cars have a slight bias forcertain orientations in certain positions; with the augmentation added, this bias disappears.", can you show us the badcase with image to make it more intutive?
Thanks for your great work.
When i read the code, i meet a question in the line 145 of "train_nuscenes.py".
xyz_cam0 = utils.geom.apply_4x4(cams_T_velo[:,0], xyz_velo0)
"cams_T_velo[:,0]" means the "camera0 to world" and "xyz_velo0" means the points in the world coordinate.
It seems that followed code is right.
xyz_cam0 = utils.geom.apply_4x4(velo_T_cams[:,0], xyz_velo0)
Except your reply.
Thanks.
Hi, thanks for releasing this cool work!
I have a question about Fig. 4 in your paper and the related paragraph. Since you train for 25k iterations with batch_size = 8, do you also increase (or decrease) the number of iterations when the batch size decreases (or increases, respectively), or is it always kept fixed at 25k?
Thank you in advance for the answer.
def get_center_and_offset_bev(self, lrtlist_cam, seg_bev):
......
......
offset = torch.stack([offset[:,0], offset[:,2]], dim=1)
min_offset = torch.min(offset, dim=3)[0]
max_offset = torch.max(offset, dim=3)[0]
offset = min_offset + max_offset
The meaning expressed by the sum of min_offset and max_offset?
What is the role of MIN_offset and max_offset?
Hi!
I have a question.
Checking seg_bev_g for analysis shows the following.

Why are the value(=color) different for each object?
Thanks for the great research!
I have a few questions.
In the paper, little information is given on how to perform bilinear sampling during 2D-BEV transfer, anyone can explain it more detailedly?
During training, every time my GPU worked for 5.5 seconds, it had to wait 11 seconds for the Dataloader. I wonder if you or anyone else have encountered this problem.
I think this code may cause the Dataloader to get items more slowly:
Loops (nuscnensdataset.py L1130, L1174-1175),
Lots of list.appends and torch.stacks,
Redundant Tensor.clone operations(nuscnensdataset.py L990,996,997),
A lot of CPU (numpy) operations, rather than loading them onto the GPU and then using GPU (torch.Tensor) operations.
This could be a fatal problem, given the weak CPU of on-board devices such as NVIDIA Orin.
Besides, I have frequently encountered problems that child processes were not properly reclaimed when training program terminated, resulting in memory leaks.
Please check. Thank you for your work.
Hi, thanks a lot for sharing the nice work. I am wondering whether the ego car could be the scene center as the BEVFormer defined. It seems that the current center is defined in the front camera.
And another tiny question is that, in the code, there have some customized operations such as:
merge_intrinsics, split_intrinsics, safe_inverse.
I am wondering that would it cut down the performance if used common libraries such as PyTorch and NumPy, like torch.inverse(), np.linalg.inv().
Thanks again!
Thanks for your great work!
A small problem,when I run the command to download the pre-trained models,the error shows that https://www.dropbox.com/s/n93ryvrqyiram56 could not to be connected,is there any netdisk to download the models?
Why choose BEV segmentation rather than BEV object detection or 3D object detection?
hi,
The following error occurred when I used the recommended method for evaluation,
File "/home/zhwsh/code/simple_bev-main/nuscenesdataset.py", line 728, in sample_augmentation
H, W = self.data_aug_conf['H'], self.data_aug_conf['W']
KeyError: 'H'
Then I noticed that there was no 'H''W' defined in "data_aug_conf",what's the value of them?
data_aug_conf = {
'final_dim': final_dim,
'cams': ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT'],
'ncams': ncams,
}
Hi @aharley :
Thanks for your job, which give me some ideas.
In my BEV detection model, I Rasterisation the RADAR data and concatenated with the BEV feature output from LSS according to dimensions, but the result was 2-3 points lower.
Do you know why? Or tell me some potential problem.
Hello aharley, first thanks for your great work.
I'm trying to reproduce the code, but I'm running into problems, the CPU memory keeps growing during training, I'm wondering if this is normal? (I used 32GB of CPU memory and ended up at around 6000 itrers and the program was killed due to full CPU memory)
Any tips or help is greatly appreciated!
Hi there,
Thank you for your research.
Ref, Center, Mem, camA, camB, pix B coordinate in vox_util aren't well understood..
Could you explain about it easily?
Hello, I have a question in https://github.com/aharley/simple_bev/blob/main/utils/vox.py#L333, why z_pixB is zeros_like x? Why isn't z at different heights during sampling?
Thank you for this contribution it has been very educational for me!
I am trying to train this model on a custom data set.
Can you confirm a few assumtions I have made?
# COORDS:
# Z: forward (roll)
# Y: down (yaw)
# X: right (pitch)
#
#
# (forward) z
# \
# \
# *---------- x (right)
# |
# |
# |
# | Y (down)
Secondly, I have both my result & prediction for the segnet being flipped 180 deg. I am hoping you can give me any pointers on where to look.
Actual Values:

Expected Values:

Hi I have a couple of question regarding your NN architecture design and I would like to ask if you could give the the motivation for these particular design choices (or if they are copied from some other work point me to it):
For both ResNet backbones you stopped at the 3rd block and did not use the 4th block:
Line 164 in be46f0e
Line 68 in be46f0e
What is the motivation for the use of instance normalization in the decoders?
Line 78 in be46f0e
Why did you not use activation functions for the up-sampling layers in the BEV grid?
Line 45 in be46f0e
Hello, thank you for such a wonderful job!I have a question that I hope you can answer.

I added some convolution layers before segnet's self.bev_compressor. Why did my modification result in 100% utilization on GPU0, and 0% utilization on GPU1.2.3 even though there is the same memory footprint as GPU0? And the program neither reports errors nor continues running,it just stuck there.
Translation between different sensor modalities between frames is doable. For example, CAM_FRONT frame 0 to RADAR_FRONT frame 1 involves the transformations:
CAM_FRONT F0 -> GLOBAL COORDS -> RADAR_FRONT F1
It is possible to do so using the egopose records as done in get_radar_data() function from nuscenesdataset.py, this snippet shows the car_from_global transformation matrix which describes the transformation from GLOBAL to the RADAR FRONT ego frame:
# Get reference pose and timestamp.
ref_sd_token = sample_rec['data']['RADAR_FRONT']
ref_sd_rec = nusc.get('sample_data', ref_sd_token)
ref_pose_rec = nusc.get('ego_pose', ref_sd_rec['ego_pose_token'])
ref_cs_rec = nusc.get('calibrated_sensor', ref_sd_rec['calibrated_sensor_token'])
ref_time = 1e-6 * ref_sd_rec['timestamp']
# Homogeneous transformation matrix from global to _current_ ego car frame.
car_from_global = transform_matrix(ref_pose_rec['translation'], Quaternion(ref_pose_rec['rotation']),inverse=True)What I am looking for is a 'raw' transformation matrix which describes the transformation between different sensor modalities when the vehicle is stationary and not moving (CAM_FRONT to RADAR_FRONT for example). This is also the case for when the sensor modalities timestamp is EXACTLY the same, as this would mean the ego vehicle has the same global coordinates for both modalities. A case for this is when ref_sd_token = sample_rec['data']['RADAR_FRONT'] is not available.
As i stated, this raw transformation matrix be extracted when the timestamps between CAM_FRONT and RADAR_FRONT is 0. However, I could not find a case for when this occurs as radar and camera are asynchronous so it would be rare for this to occur. The closest I could get is 4 microseconds but I would like the exact raw transformation matrix if this is possible?
Thank you.
According to the read.me, I have comply the seconed requirements.txt which including fire and so on. whether the second file requirements.txt is needed.
Hi, I appreciate your outstanding work! can this project used to be 3D object detection task with adding some post-processing code?
@aharley Thanks for your sharing. I don't know if I understand correctly. The following code completes the conversion of ref to mem coordinate system. Mem is the coordinate of voxel, that is, the coordinate of bev feature. What does ref refer to?How do I determine this reference coordinate system? Can I specify a coordinate system at will? I understand that the code is cam_front. If I change to lidar_top as the reference coordinate system, does the code need to be changed? Looking forward to your reply, thank you very much!!
def get_mem_T_ref(self, B, Z, Y, X, assert_cube=False, device='cuda'):
Thanks for your excellent work.
I have doubts about figure4 in the paper. I saw the batch-size has such a significant effect. This is a vast difference from our common perception.
If we use the same 25000 iterations, the different batch-size represent a vast difference in the number of iterations over the data. So is this comparison unreasonable?
I would like to understand how this experiment was performed.
For example, if bevformer iterates 25,000 times at batch1, it will have trained only 1 epoch on the nuScenes dataset. while simpleBEV iterates 25,000 times at batch40, meaning it has trained 40 epochs on the nuScenes dataset. right?
The radar points are got via the get_radar_data() function inside of nuscenesdataset.py and the points are translated into the egopose realtive to the RADAR_FRONT:
# Get reference pose and timestamp.
ref_sd_token = sample_rec['data']['RADAR_FRONT']
ref_sd_rec = nusc.get('sample_data', ref_sd_token)
ref_pose_rec = nusc.get('ego_pose', ref_sd_rec['ego_pose_token'])
ref_cs_rec = nusc.get('calibrated_sensor', ref_sd_rec['calibrated_sensor_token'])
ref_time = 1e-6 * ref_sd_rec['timestamp']
# Homogeneous transformation matrix from global to _current_ ego car frame.
car_from_global = transform_matrix(ref_pose_rec['translation'], Quaternion(ref_pose_rec['rotation']),inverse=True)A similar thing happens via get_lidar_data(), these points are translated into the egopose relative to the LIDAR_TOP:
# Get reference pose and timestamp.
ref_sd_token = sample_rec['data']['LIDAR_TOP']
ref_sd_rec = nusc.get('sample_data', ref_sd_token)
ref_pose_rec = nusc.get('ego_pose', ref_sd_rec['ego_pose_token'])
ref_cs_rec = nusc.get('calibrated_sensor', ref_sd_rec['calibrated_sensor_token'])
ref_time = 1e-6 * ref_sd_rec['timestamp']
# Homogeneous transformation matrix from global to _current_ ego car frame.
car_from_global = transform_matrix(ref_pose_rec['translation'], Quaternion(ref_pose_rec['rotation']),
inverse=True)Then these points are translated to CAM_FRONT coordinates in train_nuscenes.py via these transformation matrices:
cams_T_velo = __u(utils.geom.safe_inverse(__p(velo_T_cams)))And finally translated:
xyz_cam0 = utils.geom.apply_4x4(cams_T_velo[:,0], xyz_velo0)
# apply transformation of radar to camera coords (1st camera coords [:,0])
rad_xyz_cam0 = utils.geom.apply_4x4(cams_T_velo[:,0], xyz_rad)I do not understand how this is correct. How would one transformation matrix correctly transform both RADAR and LIDAR into the CAM_FRONT frame if both RADAR and LIDAR are stored in different coordinate systems (egopose relative to their sensors?).
I am sure I am missing something/ have a misunderstaning and would someone be able to point me in the right direction? Thanks
Thanks for your wonderful work.
I am trying to reproduce it, and the result looks great.
So I want to further analyze the result.
Could you share your visualization command?
Hello, I want to know why need to calculate xyz_camB in thisline and what is z after that line? And another is why the vertical dimension is Y instead of Z?
Please enlighten me!
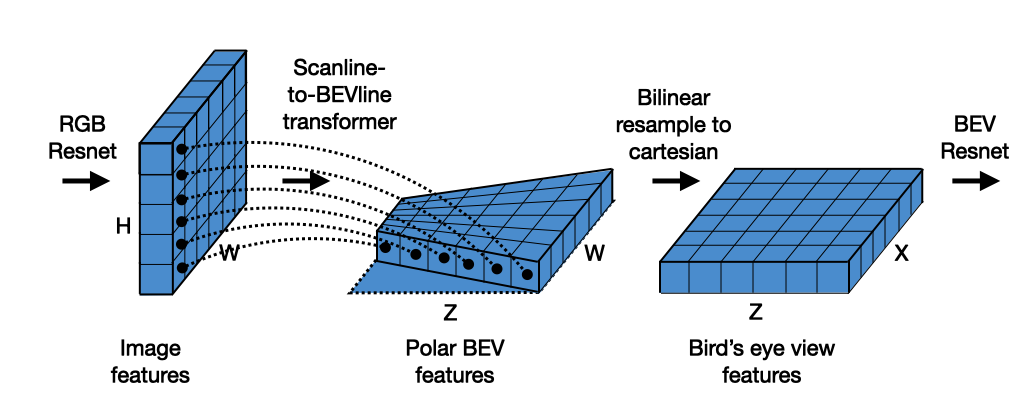
Your work is great! I want to know what software you use to make figures like this, especially the polar BEV features with irregular shape.
Thank you!
You will also need to download nuScenes and its dependencies. For a beginner, it is difficult to me. if it is convenient for you, please give me a detailed procedure. thank you very much!
Thansk to the excellent work! I have a question about reduce_masked_mean.
in oder to fuse every camera feature, you get "mask_mems" by mask_mems = (torch.abs(feat_mems) > 0).float(), and get in reduce_masked_mean, but in vox_util.unproject_image_to_mem function , there is a "valid_mem" from valid_mem = (x_valid & y_valid & z_valid).reshape(B, 1, Z, Y, X).float(), and adapt to values by values = values * valid_mem , I'm confused about this, why not using "valid_mem" from vox_util.unproject_image_to_mem ,but get a new "mask_mems" by mask_mems = (torch.abs(feat_mems) > 0).float()? seems not make sense to me.



When I tried to train bevformer2, I used two 3090 GPUs for training and reported an error of ERROR: torch. distributed. final. multiprocessing. api: failed (exitcode: -6) local rank: 1 (pid: 26301). This error does not occur every time, but the probability of occurrence is high.
I noticed that the code has already commented that using multi-scale feature will not work.
After checking the code, I found that there was an issue with the parameters of VanillaSelfAttention. and SpatialCrossAttention.
When using multi-scale features, n_levels needs to be set to the number of multi-scale features of 3 to solve the problem.
Hi, Dr.Harley, simple-bev is really a nice work, however, when running the code to reproduce the results in “table1” I meet some problems:
log of Q2:
segnet:
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000356/376; rtime 0.06; itime 0.69 (783.48 ms); loss 2.87869; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000357/376; rtime 0.07; itime 0.80 (783.53 ms); loss 0.26470; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000358/376; rtime 0.07; itime 0.69 (783.27 ms); loss -0.71782; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000359/376; rtime 0.06; itime 0.66 (782.94 ms); loss 0.30850; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000360/376; rtime 0.08; itime 0.66 (782.60 ms); loss -0.15269; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000361/376; rtime 0.04; itime 0.63 (782.17 ms); loss -0.56200; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000362/376; rtime 0.04; itime 0.62 (781.73 ms); loss 0.11772; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000363/376; rtime 0.04; itime 0.63 (781.31 ms); loss 0.36632; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000364/376; rtime 0.04; itime 0.62 (780.87 ms); loss 1.63898; iou_ev 47.6
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000365/376; rtime 0.05; itime 0.64 (780.47 ms); loss 5.04701; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000366/376; rtime 0.04; itime 0.64 (780.08 ms); loss 1.01278; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000367/376; rtime 0.05; itime 0.65 (779.72 ms); loss 0.95337; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000368/376; rtime 0.05; itime 0.66 (779.39 ms); loss 0.78735; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000369/376; rtime 0.05; itime 0.65 (779.04 ms); loss 2.96054; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000370/376; rtime 0.04; itime 0.62 (778.62 ms); loss 2.15018; iou_ev 47.5
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000371/376; rtime 0.04; itime 0.72 (778.45 ms); loss 4.13992; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000372/376; rtime 0.05; itime 0.64 (778.07 ms); loss 1.97022; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000373/376; rtime 0.05; itime 0.63 (777.67 ms); loss 0.56684; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000374/376; rtime 0.04; itime 0.63 (777.27 ms); loss 1.27457; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000375/376; rtime 0.05; itime 0.64 (776.91 ms); loss 3.13456; iou_ev 47.4
8x5_3e-4s_segnet_reproduce_19:22:27_16_eval_20:55:09; step 000376/376; rtime 0.05; itime 0.64 (776.55 ms); loss 1.49759; iou_ev 47.4
final trainval mean iou 47.43055910993624
bevformer
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000351/376; rtime 0.04; itime 1.57 (1583.65 ms); loss 1.46815; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000352/376; rtime 0.05; itime 1.54 (1583.52 ms); loss 1.36396; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000353/376; rtime 0.04; itime 1.52 (1583.35 ms); loss 1.52722; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000354/376; rtime 0.04; itime 1.52 (1583.18 ms); loss 1.45763; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000355/376; rtime 0.05; itime 1.55 (1583.09 ms); loss 2.03853; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000356/376; rtime 0.07; itime 1.54 (1582.97 ms); loss 1.00910; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000357/376; rtime 0.04; itime 1.51 (1582.76 ms); loss 0.24750; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000358/376; rtime 0.04; itime 1.52 (1582.60 ms); loss 0.00532; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000359/376; rtime 0.04; itime 1.52 (1582.43 ms); loss 0.19061; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000360/376; rtime 0.04; itime 1.52 (1582.24 ms); loss 0.04461; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000361/376; rtime 0.04; itime 1.51 (1582.06 ms); loss -0.15120; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000362/376; rtime 0.04; itime 1.51 (1581.86 ms); loss 0.19511; iou_ev 47.5
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000363/376; rtime 0.04; itime 1.51 (1581.67 ms); loss 0.41124; iou_ev 47.5
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000364/376; rtime 0.05; itime 1.54 (1581.56 ms); loss 0.64006; iou_ev 47.5
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000365/376; rtime 0.05; itime 1.53 (1581.42 ms); loss 1.81830; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000366/376; rtime 0.04; itime 1.53 (1581.29 ms); loss 0.45757; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000367/376; rtime 0.04; itime 5.94 (1593.17 ms); loss 0.35694; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000368/376; rtime 0.07; itime 1.55 (1593.07 ms); loss 0.77848; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000369/376; rtime 0.05; itime 1.52 (1592.87 ms); loss 1.30311; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000370/376; rtime 0.04; itime 1.50 (1592.63 ms); loss 1.00361; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000371/376; rtime 0.04; itime 1.51 (1592.39 ms); loss 2.16301; iou_ev 47.3
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000372/376; rtime 0.04; itime 1.52 (1592.19 ms); loss 0.88017; iou_ev 47.3
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000373/376; rtime 0.04; itime 1.52 (1592.00 ms); loss 0.48593; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000374/376; rtime 0.04; itime 1.52 (1591.81 ms); loss 0.77463; iou_ev 47.4
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000375/376; rtime 0.04; itime 1.51 (1591.59 ms); loss 1.96368; iou_ev 47.3
8x5_3e-4s_bevformer_21:07:58_16_eval_01:13:41; step 000376/376; rtime 0.04; itime 1.51 (1591.38 ms); loss 0.78340; iou_ev 47.4
final trainval mean iou 47.36635237197667
log of Q3:
bevformer
8x5_3e-4s_bevformer_21:07:58; step 005610/25000; rtime 0.23; itime 7.22; loss 1.94302; iou_t 29.3; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005611/25000; rtime 0.29; itime 7.15; loss 1.96159; iou_t 28.7; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005612/25000; rtime 0.26; itime 7.15; loss 1.57377; iou_t 26.5; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005613/25000; rtime 0.21; itime 7.30; loss 2.18127; iou_t 25.8; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005614/25000; rtime 0.17; itime 7.03; loss 2.06807; iou_t 25.9; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005615/25000; rtime 0.24; itime 7.30; loss 1.96291; iou_t 25.6; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005616/25000; rtime 0.20; itime 7.23; loss 1.79805; iou_t 26.3; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005617/25000; rtime 0.19; itime 7.26; loss 1.75140; iou_t 26.8; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005618/25000; rtime 0.22; itime 7.31; loss 1.84597; iou_t 27.1; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005619/25000; rtime 0.18; itime 7.34; loss 1.59728; iou_t 27.1; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005620/25000; rtime 0.30; itime 7.09; loss 2.27120; iou_t 26.8; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005621/25000; rtime 0.23; itime 7.14; loss 1.91050; iou_t 26.6; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005622/25000; rtime 0.15; itime 6.57; loss 1.78379; iou_t 27.5; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005623/25000; rtime 0.16; itime 6.59; loss 1.61208; iou_t 28.0; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005624/25000; rtime 0.15; itime 6.66; loss 1.95314; iou_t 27.8; iou_v 29.8
8x5_3e-4s_bevformer_21:07:58; step 005625/25000; rtime 0.19; itime 7.05; loss 1.64065; iou_t 28.0; iou_v 29.8
bevformer2
8x5_3e-4s_bevformer_MS_00:06:32; step 005610/25000; rtime 0.35; itime 5.87; loss 1.30963; iou_t 39.2; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005611/25000; rtime 0.21; itime 5.83; loss 0.97845; iou_t 39.6; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005612/25000; rtime 0.20; itime 6.03; loss 1.67607; iou_t 39.3; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005613/25000; rtime 0.23; itime 6.03; loss 1.30028; iou_t 39.3; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005614/25000; rtime 0.19; itime 6.19; loss 1.44862; iou_t 39.6; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005615/25000; rtime 0.20; itime 5.56; loss 1.33884; iou_t 39.1; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005616/25000; rtime 0.25; itime 6.23; loss 1.39724; iou_t 38.7; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005617/25000; rtime 0.24; itime 5.57; loss 1.90144; iou_t 38.5; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005618/25000; rtime 0.22; itime 6.27; loss 1.33009; iou_t 38.3; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005619/25000; rtime 0.30; itime 5.66; loss 1.22954; iou_t 37.7; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005620/25000; rtime 0.33; itime 5.83; loss 1.67304; iou_t 38.3; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005621/25000; rtime 0.23; itime 6.05; loss 1.51381; iou_t 37.9; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005622/25000; rtime 0.20; itime 4.56; loss 1.54351; iou_t 38.8; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005623/25000; rtime 0.15; itime 4.39; loss 1.39122; iou_t 38.1; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005624/25000; rtime 0.16; itime 5.98; loss 1.22388; iou_t 38.6; iou_v 5.5
8x5_3e-4s_bevformer_MS_00:06:32; step 005625/25000; rtime 0.17; itime 7.95; loss 2.08057; iou_t 38.4; iou_v 5.5
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.