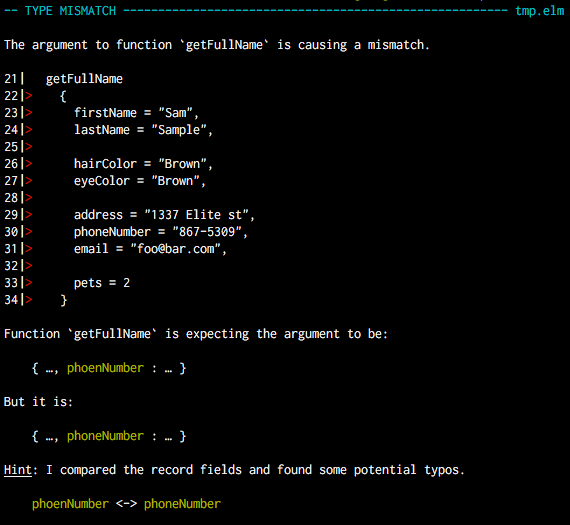
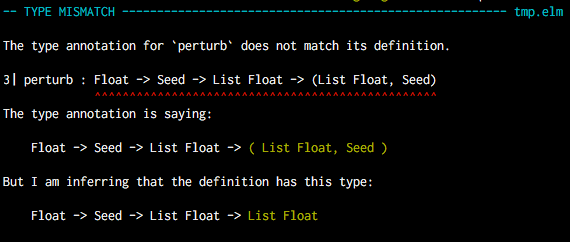
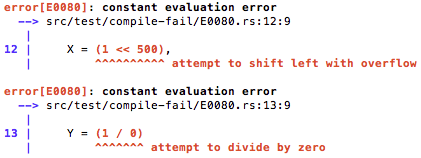
Beautiful diagnostic reporting for text-based programming languages.

Languages like Rust and Elm already support beautiful error reporting output,
but it can take a significant amount work to implement this for new programming
languages! The codespan-reporting crate aims to make beautiful error
diagnostics easy and relatively painless for everyone!
We're still working on improving the crate to help it support broader use cases, and improving the quality of the diagnostic rendering, so stay tuned for updates and please give us feedback if you have it. Contributions are also very welcome!
use codespan_reporting::diagnostic::{Diagnostic, Label};
use codespan_reporting::files::SimpleFiles;
use codespan_reporting::term::termcolor::{ColorChoice, StandardStream};
// `files::SimpleFile` and `files::SimpleFiles` help you get up and running with
// `codespan-reporting` quickly! More complicated use cases can be supported
// by creating custom implementations of the `files::Files` trait.
let mut files = SimpleFiles::new();
let file_id = files.add(
"FizzBuzz.fun",
unindent::unindent(
r#"
module FizzBuzz where
fizz₁ : Nat → String
fizz₁ num = case (mod num 5) (mod num 3) of
0 0 => "FizzBuzz"
0 _ => "Fizz"
_ 0 => "Buzz"
_ _ => num
fizz₂ : Nat → String
fizz₂ num =
case (mod num 5) (mod num 3) of
0 0 => "FizzBuzz"
0 _ => "Fizz"
_ 0 => "Buzz"
_ _ => num
"#,
),
);
// We normally recommend creating a custom diagnostic data type for your
// application, and then converting that to `codespan-reporting`'s diagnostic
// type, but for the sake of this example we construct it directly.
let diagnostic = Diagnostic::error()
.with_message("`case` clauses have incompatible types")
.with_code("E0308")
.with_labels(vec![
Label::primary(file_id, 328..331).with_message("expected `String`, found `Nat`"),
Label::secondary(file_id, 211..331).with_message("`case` clauses have incompatible types"),
Label::secondary(file_id, 258..268).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 284..290).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 306..312).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 186..192).with_message("expected type `String` found here"),
])
.with_notes(vec![unindent::unindent(
"
expected type `String`
found type `Nat`
",
)]);
// We now set up the writer and configuration, and then finally render the
// diagnostic to standard error.
let writer = StandardStream::stderr(ColorChoice::Always);
let config = codespan_reporting::term::Config::default();
term::emit(&mut writer.lock(), &config, &files, &diagnostic)?;To get an idea of what the colored CLI output looks like, clone the repository and run the following shell command:
cargo run --example termMore examples of using codespan-reporting can be found in the
examples directory.
codespan-reporting is currently used in the following projects:
There are a number of alternatives to codespan-reporting, including:
- annotate-snippets
- codemap
- language-reporting (a fork of codespan)
These are all ultimately inspired by rustc's excellent error reporting infrastructure.
A guide to contributing to codespan-reporting can be found here.
Please note that this project is released with a Code of Conduct. By participating in this project you agree to abide by its terms.



![dependabot-preview[bot] avatar](https://avatars.githubusercontent.com/in/2141?v=4 "dependabot-preview[bot]")

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")