nikhilbarhate99 / ppo-pytorch Goto Github PK
View Code? Open in Web Editor NEWMinimal implementation of clipped objective Proximal Policy Optimization (PPO) in PyTorch
License: MIT License
Minimal implementation of clipped objective Proximal Policy Optimization (PPO) in PyTorch
License: MIT License



















































































































Dear nikhilbarhate99,
First of all, thanks for sharing your work on Github.
About your code, I have a question in terms of the two neural networks, namely, self.action_layer and self.value_layer. To my understanding, those two NN are completely seperated, but are updated using the same loss function. Wouldn't it make more sense to share the parameters of the first two layers to increase training speed. Or am I missing something important?
Looking forward to your response.
0.002 (0.9, 0.999)
Episode 20 avg length: 85 reward: -228
Traceback (most recent call last):
File "/mnt/projects/PPO-PyTorch/PPO.py", line 179, in
ppo.update(memory)
File "/mnt/projects/PPO-PyTorch/PPO.py", line 122, in update
loss.mean().backward()
File "/usr/lib/python3.7/site-packages/torch/tensor.py", line 198, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/lib/python3.7/site-packages/torch/autograd/init.py", line 100, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: expected dtype Double but got dtype Float (validate_dtype at /pytorch/aten/src/ATen/native/TensorIterator.cpp:143)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x46 (0x7f3ece1e3536 in /usr/lib/python3.7/site-packages/torch/lib/libc10.so)
frame #1: at::TensorIterator::compute_types() + 0xce3 (0x7f3ea23c2a23 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #2: at::TensorIterator::build() + 0x44 (0x7f3ea23c5404 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #3: at::native::mse_loss_backward_out(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long) + 0x193 (0x7f3ea2212953 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #4: + 0xf903d7 (0x7f3e65d073d7 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #5: at::native::mse_loss_backward(at::Tensor const&, at::Tensor const&, at::Tensor const&, long) + 0x172 (0x7f3ea221b092 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #6: + 0xf9068f (0x7f3e65d0768f in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #7: + 0x10c2536 (0x7f3ea264b536 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #8: + 0x2a9ecdb (0x7f3ea4027cdb in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #9: + 0x10c2536 (0x7f3ea264b536 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #10: torch::autograd::generated::MseLossBackward::apply(std::vector<at::Tensor, std::allocatorat::Tensor >&&) + 0x1f7 (0x7f3ea3e2f777 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #11: + 0x2d89705 (0x7f3ea4312705 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #12: torch::autograd::Engine::evaluate_function(std::shared_ptrtorch::autograd::GraphTask&, torch::autograd::Node*, torch::autograd::InputBuffer&) + 0x16f3 (0x7f3ea430fa03 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #13: torch::autograd::Engine::thread_main(std::shared_ptrtorch::autograd::GraphTask const&, bool) + 0x3d2 (0x7f3ea43107e2 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #14: torch::autograd::Engine::thread_init(int) + 0x39 (0x7f3ea4308e59 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #15: torch::autograd::python::PythonEngine::thread_init(int) + 0x38 (0x7f3ed6fa6ac8 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
frame #16: + 0xc70f (0x7f3ed668770f in /usr/lib/python3.7/site-packages/torch/lib/libtorch.so)
frame #17: + 0x76ba (0x7f3edf5e06ba in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #18: clone + 0x6d (0x7f3edf31641d in /lib/x86_64-linux-gnu/libc.so.6)
Process finished with exit code 1
Openai has deprecated roboschool. I think it pybullet gym is to be used.
Dear @nikhilbarhate99,
Can I ask if we need to set the models to evaluation mode (nn.Module.eval()) in the test script to see if the weights are suitable?
Thank you!
In the update() method the discounted_reward is always calculated using a gamma of the previous discounted_reward, but there's no break between episodes so the reward from one episode is carried across to the next, which I assume cannot be correct.
Suggest adding terminal_states list to the Memory class, and then setting the discounted_reward = 0 when a new episode starts.
The timestep should not be reset on line 182 in PPO.py, because it is used to prevent the episode running too long. Currently it does not affect the performance as the episode length will not exceed max_timesteps, but the logic is wrong. And the same for the continuous case as well.
I can see that your Actor network has tanh activation on the output layer but then I am totally lost as to what you do here:
def act(self, state, memory):
action_mean = self.actor(state)
dist = MultivariateNormal(action_mean, torch.diag(self.action_var).to(device))
action = dist.sample()
action_logprob = dist.log_prob(action)
Especially action_mean = self.actor(state). Does this mean you have one output node and assume that the output is the mean of a Gaussian distribution over the action space?
Then similar code appears here:
def evaluate(self, state, action):
action_mean = self.actor(state)
dist = MultivariateNormal(torch.squeeze(action_mean), torch.diag(self.action_var))
action_logprobs = dist.log_prob(torch.squeeze(action))
dist_entropy = dist.entropy()
state_value = self.critic(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
Also is self.policy like a dummy Actor Critic network that you use just to get updated parameters to load in to self.policy_old? I know this isn't stackoverflow but if you can look at my implementation and let me know how I can adapt it for a continuous action space, that'd be great.
Why is the value function compared with a monte carlo estimate instead of:
v(s_1) - (r + gamma * v(s_2))
Hello,
I am new to reinforcement learning. I find you set 'action_std' as a constant hyper-parameter in PPO_continuous.py, and only the 'action_mean' can be learned in the code. I don't know if it's a common operation in continuous action space problems or it's just in your method, as I think the 'action_std' should also be learned in the process. Can you give me some references to explain why you write it like this? Thank you very much!
Hey,
Thanks for sharing this awesome code!
I would like to export my result also as onnx model. However I have no idea how to use it then... currently it did not work for me:
This is how I export it:
torch_out = torch.onnx._export(ppo.policy, input_vector, path+".onnx", export_params=True)
To get this to work I had to implement a forward as well:
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, n_latent_var):
super(ActorCritic, self).__init__()
#... same as your code
def forward(self, state_input):
return torch.tensor(self.act(state_input, None))
def act(self, state, memory):
if type(state) is np.ndarray:
state = torch.from_numpy(state).float().to(device)
action_probs = self.action_layer(state)
# here make a filter for only possible actions!
#probs = probs * memory.leagalCards
dist = Categorical(action_probs)
action = dist.sample()
if memory is not None:
memory.states.append(state)
memory.actions.append(action)
memory.logprobs.append(dist.log_prob(action))
return action.item()
Now I tried to use my onnx model like this:
But it returns always the same action :(
def getOnnxAction(path, x):
'''Input:
x: 240x1 list binary values
path *.onnx (with correct model)'''
ort_session = onnxruntime.InferenceSession(path)
ort_inputs = {ort_session.get_inputs()[0].name: np.asarray(x, dtype=np.float32)}
ort_outs = ort_session.run(None, ort_inputs)
return np.asarray(ort_outs)[0]
Any ideas what is going wrong here?
Hi, thanks for your open-source code. Can you tell me which reward function that is used for training? Thanks again.
Hello in this step here, ratios = torch.exp(logprobs - old_logprobs.detach()) where, you are detaching the grad from the old_logprob variable. This is already performed in the previous step i.e. old_logprobs = torch.squeeze(torch.stack(memory.logprobs)).to(device).detach(). So should the ratios be like this ratios = torch.exp(logprobs - old_logprobs).detach() i.e. detaching the grads from the ratios ?
Hi @nikhilbarhate99, thank you for your great work!
However, I found in your Readme that: Number of actors for collecting experience = 1. This could be easily changed by creating multiple instances of ActorCritic networks in the PPO class and using them to collect experience (like A3C and standard PPO).
But how to change it? What should I modify for the gradient ascent part if there are multiple actors in parallel?
Thank you for your help!
Dear Barhate,
Hi!!! Thank you for your sharing of the code very much! I can reproduce your results and they look super cool!
During my playing around,
may I consult in file PPO.py. line 83, after
self.policy_old.load_state_dict(self.policy.state_dict())
Do we need a
self.policy_old.eval()
Will this line of code introduce some difference...That maybe you observed in the past?
I am consulting as in this PyTorch web
https://pytorch.org/tutorials/beginner/saving_loading_models.html
It indicated we shall call an eval() ...
"Remember that you must call model.eval() to set dropout and batch normalization layers to evaluation mode before running inference. Failing to do this will yield inconsistent inference results."
But I didn't have a chance to fully test the difference yet, therefore come to consult maybe you already encountered something similar?
Thank you for reading!
Best Regards,
Xin
Hi
Thanks for your code sharing and your nice work!
I trained the agent on CartPole task and it works well. However, my agent and your agent are not perfect yet (sometimes the reward is less than 400). I guess this comes from your code's minimalism.
Episode: 1 Reward: 400.0 Episode: 2 Reward: 400.0 Episode: 3 Reward: 400.0 Episode: 4 Reward: 126.0 Episode: 5 Reward: 400.0
I am wondering what is the recommended way or trick to improve my agent's performance based on your code?
Thanks a lot
Ran into error running test.py (after installing unmentioned dependency, box2d-py).
RuntimeError: Error(s) in loading state_dict for ActorCritic:
Unexpected key(s) in state_dict: "affine.weight", "affine.bias".
Fix is to add "strict=False" to model loading.
ppo.policy_old.load_state_dict(torch.load(directory+filename), strict=False)
For environments like Pendulum-v0 or MountanCarContinuous-v0, the following RuntimError is raised:
File "D:\My C and Python Projects\Repos\PPO-PyTorch\train.py", line 301, in <module>
train()
File "D:\My C and Python Projects\Repos\PPO-PyTorch\train.py", line 229, in train
ppo_agent.update()
File "D:\My C and Python Projects\Repos\PPO-PyTorch\PPO.py", line 244, in update
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
File "D:\My C and Python Projects\Repos\PPO-PyTorch\PPO.py", line 129, in evaluate
action_logprobs = dist.log_prob(action)
File "D:\users\Aakarshan\miniconda3\envs\torch\lib\site-packages\torch\distributions\multivariate_normal.py", line 208, in log_prob
M = _batch_mahalanobis(self._unbroadcasted_scale_tril, diff)
File "D:\users\Aakarshan\miniconda3\envs\torch\lib\site-packages\torch\distributions\multivariate_normal.py", line 54, in _batch_mahalanobis
flat_L = bL.reshape(-1, n, n) # shape = b x n x n
RuntimeError: shape '[-1, 800, 800]' is invalid for input of size 800
I try to use your code as my algorithm to solve a navigation problem.
The problem that I can't handle for myself is how to get ratio in my problem.
my actions space has 3 parts:
I try to get log_prob from each distribution, get exp and calculate the mean of these three non-log probabilities, but the result is bad.
Any suggestion for me?
Do you have any knowledge of GAE to possibly implement as an extra PPO example?
Are you using a single Loss Function to update both actor and critic? If so, is there any difference between update seperately and togather?
It would really help if you can answer my question.
Good Day!
I want to use this for Atari games but I'm unsure about how to change it to use CNN layers. Can I just literally change the actor and critic models to have a Conv2d layer or do I need to change the replay buffer for multi-dimensional arrays?
advantages = rewards - state_values.detach()
after self.optimizer.step()
the network critic values' weights never change because detach()
Thank you for sharing your ppo implementation on this repository.
However, I have tried to run your code ppo_continuous.py and I figured that the average reward was not increasing at all. Doesn't that mean the model is not learning?
Hi
I got an error while running the program
Traceback (most recent call last):
File "C:\Users\admin\Documents\GitHub\PPO-PyTorch\train.py", line 302, in <module>
train()
File "C:\Users\admin\Documents\GitHub\PPO-PyTorch\train.py", line 218, in train
action = ppo_agent.select_action(state)
File "C:\Users\admin\Documents\GitHub\PPO-PyTorch\PPO.py", line 204, in select_action
action, action_logprob = self.policy_old.act(state)
File "C:\Users\admin\Documents\GitHub\PPO-PyTorch\PPO.py", line 107, in act
dist = MultivariateNormal(action_mean, cov_mat)
File "C:\ProgramData\Anaconda3\lib\site-packages\torch\distributions\multivariate_normal.py", line 149, in __init__
self._unbroadcasted_scale_tril = torch.cholesky(covariance_matrix)
RuntimeError: CUDA error: no kernel image is available for execution on the device
On line 107, I deleted .unsqueeze(dim=0),act function can run.But the evaluate function still reports an error, I don’t know how to modify it.
torch : 1.7.0+cu110
thanks
Dear nik:
I noticed that your code store train data into one buffer from different episode, but use GAE to calculation accumulative reward. I am a little confused here cause shouldn't GAE be used on one same episode?
Regards.
problem:init() got an unexpected keyword argument 'tags'. how can i solve it?
I tried running test.py (PPO.py) from scratch on LunarLander-v2 Environment, without using the pre-trained model, but it does not seem to learn till 15000episodes. The episodic returns are negative even after 15000 episodes. How many episodes did it take to get the trained model?
I've been looking over the code to get a better grasp of what it's doing, and the one thing that confuses me is in the update() method, why ratios aren't always 1?
The log probabilities are stored in memory which were obtained from policy_old, and then in update() it gets the log probabilities from policy via the evaluate() method, and the exp difference between them is the ratio. Afterwards policy_old weights are updated from policy, so they're the same. But if the same state is fed into exact copies of policy, then I don't understand why they'd produce different log probabilities? I'm obviously missing a piece of the puzzle, but I can't think what it is.
Hi, I'm using your great implementation of PPO (discrete) on another project of robot's obstacle avoidance.
Actually, I was using DDDQN to train the robot's motion. The training was successful. Then, I used the same network and reward function from DDDQN implementation for this PPO implementation. And I tried several different sets of hyper-parameters (to change the values of lr, update_timestep and k_epochs and etc). Nevertheless, none of them work for it.
Actually, the robot seems to have learnt nothing after even 10 hours of training. And the reward remains very low. Do you know what kind of problem it could be? Will this be the problem of hyper-parameters, network structures or just some kinds of logical error? And will python2 be a problem? (but actually, python2 works for this implementation on Cartpole)
Really look forward to your reply! And thank you again for your PPO implementation!
I want to ask one more thing about the estimation of discounted reward. The variable discounted reward always starts with zero. However, if the episode is not ended, should it be the value estimation from the critic network?
In other words, I think the pseudo code for my suggestion is
if is_terminal:
discounted_reward = 0
else:
discounted_reward = critic_network(final_state)
Hi, thanks for creating this repo. I have been using your ppo_continuous code for training a robot in ROS. I am training it for 2500 episodes with 400 max time steps and also updating the weights after 400 steps with K_epochs as 80. I strangely find that after each update step there is a spike in the RAM memory. Although this shouldn't be happening because after the update step the clear_memory() gets called which basically deletes all the previous states, actions, log_probs, rewards and is_terminals. And also, in the K_epoch the gradients are made zero for K iterations.
Can you please provide a solution for this?
Have a look at this figure
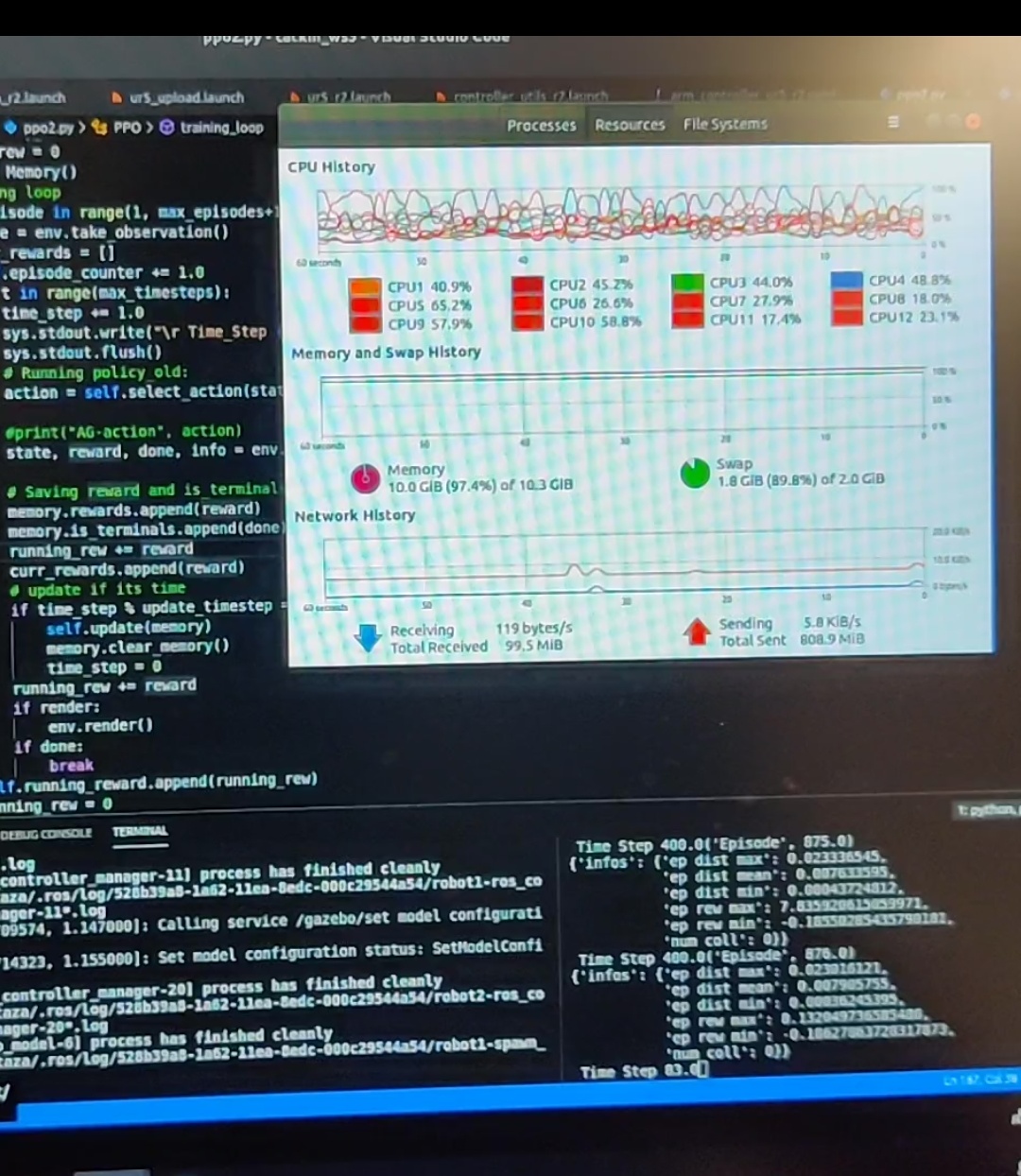
There is a spike in memory after every update
I have briefly described this issue on stack overflow as well
https://stackoverflow.com/q/59281995/10879393
I'm a bit new to PPO, but I think this line is out of place in PPO.py:
123 self.policy_old.load_state_dict(self.policy.state_dict())
I think it should be placed before the for loop, because otherwise policy and policy_old will be identical and the log probs should evaluate to the same value.
Hi, thanks for the great implementation. I learned a lot about PPO by reading your code.
I have one question regarding the state_values.detach() when updating PPO.
# Finding Surrogate Loss:
advantages = rewards - state_values.detach()
When you detach a tensor, it loses its computation record that is used in back propagation.
So I checked if the weights of the value layer of the policy get updated, and they did not.
Surprisingly, in my own experiment, the training performance was better with .detach() than the one without. But I still find it difficult to understand the use of detach() theoretically.
Thank you.
/usr/bin/python3 /opt/pycharm-2019.2.1/helpers/pydev/pydevd.py --multiproc --qt-support=auto --client 127.0.0.1 --port 38187 --file /mnt/projects/PPO-PyTorch/PPO.py
pydev debugger: process 3346 is connecting
Connected to pydev debugger (build 192.6262.63)
0.002 (0.9, 0.999)
Episode 20 avg length: 87 reward: -151
Traceback (most recent call last):
File "/opt/pycharm-2019.2.1/helpers/pydev/pydevd.py", line 2060, in
main()
File "/opt/pycharm-2019.2.1/helpers/pydev/pydevd.py", line 2054, in main
globals = debugger.run(setup['file'], None, None, is_module)
File "/opt/pycharm-2019.2.1/helpers/pydev/pydevd.py", line 1405, in run
return self._exec(is_module, entry_point_fn, module_name, file, globals, locals)
File "/opt/pycharm-2019.2.1/helpers/pydev/pydevd.py", line 1412, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "/opt/pycharm-2019.2.1/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "/mnt/projects/PPO-PyTorch/PPO.py", line 207, in
main()
File "/mnt/projects/PPO-PyTorch/PPO.py", line 179, in main
ppo.update(memory)
File "/mnt/projects/PPO-PyTorch/PPO.py", line 122, in update
loss.mean().backward()
File "/usr/lib/python3.7/site-packages/torch/tensor.py", line 198, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/lib/python3.7/site-packages/torch/autograd/init.py", line 100, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: expected dtype Double but got dtype Float (validate_dtype at /pytorch/aten/src/ATen/native/TensorIterator.cpp:143)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x46 (0x7ffb48860536 in /usr/lib/python3.7/site-packages/torch/lib/libc10.so)
frame #1: at::TensorIterator::compute_types() + 0xce3 (0x7ffb0209da23 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #2: at::TensorIterator::build() + 0x44 (0x7ffb020a0404 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #3: at::native::mse_loss_backward_out(at::Tensor&, at::Tensor const&, at::Tensor const&, at::Tensor const&, long) + 0x193 (0x7ffb01eed953 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #4: + 0xf903d7 (0x7ffac59e23d7 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #5: at::native::mse_loss_backward(at::Tensor const&, at::Tensor const&, at::Tensor const&, long) + 0x172 (0x7ffb01ef6092 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #6: + 0xf9068f (0x7ffac59e268f in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cuda.so)
frame #7: + 0x10c2536 (0x7ffb02326536 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #8: + 0x2a9ecdb (0x7ffb03d02cdb in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #9: + 0x10c2536 (0x7ffb02326536 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #10: torch::autograd::generated::MseLossBackward::apply(std::vector<at::Tensor, std::allocatorat::Tensor >&&) + 0x1f7 (0x7ffb03b0a777 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #11: + 0x2d89705 (0x7ffb03fed705 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #12: torch::autograd::Engine::evaluate_function(std::shared_ptrtorch::autograd::GraphTask&, torch::autograd::Node*, torch::autograd::InputBuffer&) + 0x16f3 (0x7ffb03feaa03 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #13: torch::autograd::Engine::thread_main(std::shared_ptrtorch::autograd::GraphTask const&, bool) + 0x3d2 (0x7ffb03feb7e2 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #14: torch::autograd::Engine::thread_init(int) + 0x39 (0x7ffb03fe3e59 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so)
frame #15: torch::autograd::python::PythonEngine::thread_init(int) + 0x38 (0x7ffb1e264ac8 in /usr/lib/python3.7/site-packages/torch/lib/libtorch_python.so)
frame #16: + 0xc70f (0x7ffb48cc870f in /usr/lib/python3.7/site-packages/torch/lib/libtorch.so)
frame #17: + 0x76ba (0x7ffb50d5d6ba in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #18: clone + 0x6d (0x7ffb50a9341d in /lib/x86_64-linux-gnu/libc.so.6)
Process finished with exit code 1
I am not sure why you detach the state values when computing the advantage functions? Specifically, I am talking about
advantages = rewards - state_values.detach()
Many thanks!
Hi, I am following your code for my implementation. But after seeing the results (which are good by the way) I want to give a shot with PPO. I know there are some implementations already in other repos but I find this one pretty easy to follow. I just want to ask what kind of modification I would need to do in your code for the PPO implementation? And is it recommended to do modifications in this code or follow other repo? There are some good repos out there but the problem is that they are specially made for ATARI and MUJOCO environments using baselines from deepmind which are difficult to modify for my environment and also I need Python 3.5+ to work with the baselines. But since I am working with ROS Melodic which comes with default Python 2.7 I can't really use those baselines. Any suggestions would be grateful.
Hi, in the original PPO paper, it runs T timesteps(e.g. 1 actor) and then update K times with mini-batch size M sampled from T memory. But in your implementation, you will do update every M steps within T memory. There are two differences in my understanding:
I wonder whether the above differences affect the performance of PPO and how?
Thanks.
When I am looking deeply into your codes, I am curious about why you choose to decay the variance of actor network?
We know that one of advantages of PPO is the stochastic policy it uses, and I just don't know why you set a determinate variance even though it decaying?
Thanks!
I was just wondering if i could use a shared network with this algorithm
Line 127 in 64376aa
Why do we even maintain two policies? The old policy has produced the old action distributions so, at the point where we compute the ratios during updates, we don't need it.
Old_log_probs might as well have been generated by the normal policy, then during updates we evaluate only the updated policy, compute the ratios with previously saved log_probs and we are golden. At no point do we need both at once.
Am I missing something?
Hey there,
you used Monte Carlo Estimate - would it no also be nice to have GAE (Generalized Advantage estimation?)
The function should be something like:
I am not sure how exactly I can include gae in the code....
def get_advantages(self, values, masks, rewards, gamma):
returns = []
gae = 0
for i in reversed(range(len(rewards))):
delta = rewards[i-1] + gamma * values[i] * masks[i-1] - values[i-1]
gae = delta + gamma * 0.95 * masks[i-1] * gae
returns.insert(0, gae + values[i-1])
adv = np.array(returns) - values.detach().numpy()
adv = torch.tensor(adv.astype(np.float32)).float()
# Normalizing advantages
return returns, (adv - adv.mean()) / (adv.std() + 1e-5)
# Monte Carlo estimate of rewards:
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
Hello, I am very interested in your work. I would like to ask about your specific environment configuration, such as python, gym, roboschool, etc.
I was going through ppo.py code.
Assuming I have 2 actions to predect for continuous actions, action_dims = 2
Let the standard deviation be initialized as .5
So variance is .25.
I found the fallowing, the mean of action is predected predected by the actor net
Say it is torch.tesor([.7,.9])
Then u use the variance to sample actions
If the sample draws actions which are over 1 or below -1 which is range of permitted action, what do we do?
Do we sample again?
Do we clip?
Is it a good idea to have a tanh activation on the sampled action? (But it will mess with the actor network)
hi,
I am new to RL, I was wondering can I use this for a game of chess?
either https://github.com/genyrosk/gym-chess or i can make my own env based on python-chess if needed.
I am confused mainly because chess is a two-player game. so after the ai move someone has to make move from as opponent. also because the reward is 1 if won else -1.
note: goal is not to train a start of the art chess ai
thanks for the help in advance.
I don't get it. In PPO.py-ActorCritic-evaluate, it only calculates the entropy of old_action, missing KLD between pi_old and pi like the paper of PPO said.
Hello, thank you for such a clear example of PPO in PyTorch. I wonder if you might know how the update() method might be modified to minimize rather than maximize? In my case I want to minimize a regret factor, rather than maximize a reward. Many thanks.
Another question; why use Tanh() activation instead of ReLU()?
whe i use other implementation such as stable-baselines3.
it does have Monotonic improvement, which means that the mean of the rewards get better after each update.
while using your implementation, there seems no monotonic garantee.
Can you help me explain the reason.
Thanks.
Hello.
Were you able to get >200 reward in Lunar Lander Continuous?
I'm currenty at ~40000 episode, but still the reward is max ~130.
I have no problems with discrete env, but do with continuous.
Can you give me some advice?
Should there be a self.policy_old.load_state_dict(self.policy.state_dict()) on line 85 of PPO.py, after the initialization of PPO object? PyTorch random initialization does not guarantee that these two policies will be the same. And the same issue for PPO_continuous.py.
/usr/bin/python3 /root/PycharmProjects/PPO-PyTorch/test.py
Traceback (most recent call last):
File "/root/PycharmProjects/PPO-PyTorch/test.py", line 36, in
ppo.policy_old.load_state_dict(torch.load(pathfile))
File "/usr/lib/python3.7/site-packages/torch/nn/modules/module.py", line 847, in load_state_dict
self.class.name, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for ActorCritic:
Unexpected key(s) in state_dict: "affine.weight", "affine.bias".
#ppo.policy_old.load_state_dict(torch.load(directory+filename))
loadweight = torch.load(pathfile)
ppo.policy_old.load_state_dict(loadweight) //////-> crash here
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.