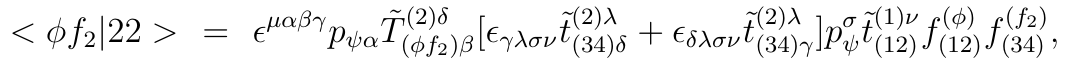Fastor is a high performance tensor (fixed multi-dimensional array) library for modern C++.
Fastor offers:
- High-level interface for manipulating multi-dimensional arrays in C++ that look and feel native to scientific programmers
- Bare metal performance for small matrix/tensor multiplications, contractions and tensor factorisations [LU, QR etc]. Refer to benchmarks to see how Fastor delivers performance on par with MKL JIT's dedicated API
- Compile time operation minimisation such as graph optimisation, greedy matrix-chain products and nearly symbolic manipulations to reduce the complexity of evaluation of BLAS or non-BLAS type expressions by orders of magnitude
- Explicit and configurable SIMD vectorisation supporting all numeric data types
float32,float64,complex float32andcomplex float64as well as integral types with - Optional SIMD backends such as sleef, Vc or even std::experimental::simd
- Optional JIT backend using Intel's MKL-JIT and LIBXSMM for performance portable code
- Ability to wrap existing data and operate on them using Fastor's highly optimised kernels
- Suitable linear algebra library for FPGAs, micro-controllers and embedded systems due to absolutely no dynamic allocations and no RTTI
- Light weight header-only library with no external dependencies offering fast compilation times
- Well-tested on most compilers including GCC, Clang, Intel's ICC and MSVC
Documenation can be found under the Wiki pages.
Fastor provides a high level interface for tensor algebra. To get a glimpse, consider the following
Tensor<double> scalar = 3.5; // A scalar
Tensor<float,3> vector3 = {1,2,3}; // A vector
Tensor<int,3,2> matrix{{1,2},{3,4},{5,6}}; // A second order tensor
Tensor<double,3,3,3> tensor_3; // A third order tensor with dimension 3x3x3
tensor_3.arange(0); // fill tensor with sequentially ascending numbers
tensor_3(0,2,1); // index a tensor
tensor_3(all,last,seq(0,2)); // slice a tensor tensor_3[:,-1,:2]
tensor_3.rank(); // get rank of tensor, 3 in this case
Tensor<float,2,2,2,2,2,2,4,3,2,3,3,6> t_12; // A 12th order tensorEinstein summation as well as summing over multiple (i.e. more than two) indices are supported. As a complete example consider
#include <Fastor/Fastor.h>
using namespace Fastor;
enum {I,J,K,L,M,N};
int main() {
// An example of Einstein summation
Tensor<double,2,3,5> A; Tensor<double,3,5,2,4> B;
// fill A and B
A.random(); B.random();
auto C = einsum<Index<I,J,K>,Index<J,L,M,N>>(A,B);
// An example of summing over three indices
Tensor<double,5,5,5> D; D.random();
auto E = inner(D);
// An example of tensor permutation
Tensor<float,3,4,5,2> F; F.random();
auto G = permute<Index<J,K,I,L>>(F);
// Output the results
print("Our big tensors:",C,E,G);
return 0;
}You can compile this by providing the following flags to your compiler -std=c++14 -O3 -march=native -DNDEBUG.
Fastor provides powerful tensor views for block indexing, slicing and broadcasting familiar to scientific programmers. Consider the following examples
Tensor<double,4,3,10> A, B;
A.random(); B.random();
Tensor<double,2,2,5> C; Tensor<double,4,3,1> D;
// Dynamic views -> seq(first,last,step)
C = A(seq(0,2),seq(0,2),seq(0,last,2)); // C = A[0:2,0:2,0::2]
D = B(all,all,0) + A(all,all,last); // D = B[:,:,0] + A[:,:,-1]
A(2,all,3) = 5.0; // A[2,:,3] = 5.0
// Static views -> fseq<first,last,step>
C = A(fseq<0,2>(),fseq<0,2>(),fseq<0,last,2>()); // C = A[0:2,0:2,0::2]
D = B(all, all, fix<0>) + A(all, all, fix<last>()); // D = B[:,:,0] + A[:,:,-1]
A(2,all,3) = 5.0; // A[2,:,3] = 5.0
// Overlapping is also allowed without having undefined/aliasing behaviour
A(seq(2,last),all,all).noalias() += A(seq(0,last-2),all,all); // A[2::,:,:] += A[::-2,:,:]
// Note that in case of perfect overlapping noalias is not required
A(seq(0,last-2),all,all) += A(seq(0,last-2),all,all); // A[::2,:,:] += A[::2,:,:]
// If instead of a tensor view, one needs an actual tensor the iseq could be used
// iseq<first,last,step>
C = A(iseq<0,2>(),iseq<0,2>(),iseq<0,last,2>()); // C = A[0:2,0:2,0::2]
// Note that iseq returns an immediate tensor rather than a tensor view and hence cannot appear
// on the left hand side, for instance
A(iseq<0,2>(),iseq<0,2>(),iseq<0,last,2>()) = 2; // Will not compile, as left operand is an rvalue
// One can also index a tensor with another tensor(s)
Tensor<float,10,10> E; E.fill(2);
Tensor<int,5> it = {0,1,3,6,8};
Tensor<size_t,10,10> t_it; t_it.arange();
E(it,0) = 2;
E(it,seq(0,last,3)) /= -1000.;
E(all,it) += E(all,it) * 15.;
E(t_it) -= 42 + E;
// Masked and filtered views are also supported
Tensor<double,2,2> F;
Tensor<bool,2,2> mask = {{true,false},{false,true}};
F(mask) += 10;All possible combination of slicing and broadcasting is possible. For instance, one complex slicing and broadcasting example is given below
A(all,all) -= log(B(all,all,0)) + abs(B(all,all,1)) + sin(C(all,0,all,0)) - 102. - cos(B(all,all,0));All basic linear algebra subroutines for small matrices/tensors (where the overhead of calling vendor/optimised BLAS is typically high) are fully SIMD vectorised and efficiently implemented. Note that Fastor exposes two functionally equivalent interfaces for linear algebra functions, the more verbose names such as matmul, determinant, inverse etc that evaluate immediately and the less verbose ones (%, det, inv) that evaluate lazy
Tensor<double,3,3> A,B;
// fill A and B
auto mulab = matmul(A,B); // matrix matrix multiplication [or equivalently A % B]
auto norma = norm(A); // Frobenious norm of A
auto detb = determinant(B); // determinant of B [or equivalently det(B)]
auto inva = inverse(A); // inverse of A [or equivalently inv(A)]
auto cofb = cofactor(B); // cofactor of B [or equivalently cof(B)]
lu(A, L, U); // LU decomposition of A in to L and U
qr(A, Q, R); // QR decomposition of A in to Q and RA set of boolean operations are available that whenever possible are performed at compile time
isuniform(A); // does the tensor expression span equally in all dimensions - generalisation of square matrices
isorthogonal(A); // is the tensor expression orthogonal
isequal(A,B,tol); // Are two tensor expressions equal within a tolerance
doesbelongtoSL3(A); // does the tensor expression belong to the special linear 3D group
doesbelongtoSO3(A); // does the tensor expression belong to the special orthogonal 3D group
issymmetric<axis_1, axis_3>(A); // is the tensor expression symmetric in the axis_1 x axis_3 plane
isdeviatoric(A); // is the tensor expression deviatoric [trace free]
isvolumetric(A); // is the tensor expression volumetric [A = 1/3*trace(A) * I]
all_of(A < B); // Are all elements in A less than B
any_of(A >= B); // is any element in A greater than or equal to the corresponding element in B
none_of(A == B); // is no element in A and B equalAlernatively Fastor can be used as a pure wrapper over existing buffer. You can wrap C arrays or map any external piece of memory as Fastor tensors and operate on them just like you would on Fastor's tensors without making any copies, using the Fastor::TensorMap feature. For instance
double c_array[4] = {1,2,3,4};
// Map to a Fastor vector
TensorMap<double,4> tn1(c_array);
// Map to a Fastor matrix of 2x2
TensorMap<double,2,2> tn2(c_array);
// You can now operate on these. This will also modify c_array
tn1 += 1;
tn2(0,1) = 5;Expression templates are archetypal of array/tensor libraries in C++ as they provide a means for lazy evaluation of arbitrary chained operations. Consider the following expression
Tensor<float,16,16,16,16> tn1 ,tn2, tn3;
tn1.random(); tn2.random(); tn3.random();
auto tn4 = 2*tn1+sqrt(tn2-tn3);Here tn4 is not another tensor but rather an expression that is not yet evaluated. The expression is evaluated if you explicitly assign it to another tensor or call the free function evaluate on the expression
Tensor<float,16,16,16,16> tn5 = tn4;
// or
auto tn6 = evaluate(tn4);this mechanism helps chain the operations to avoid the need for intermediate memory allocations. Various re-structuring of the expression before evaluation is possible depending on the chosen policy.
Aside from basic expression templates, by employing further template metaprogrommaing techniques Fastor can mathematically transform expressions and/or apply compile time graph optimisation to find optimal contraction indices of complex tensor networks, for instance. This gives Fastor the ability to re-structure or completely re-write an expression and simplify it rather symbolically. As an example, consider the expression trace(matmul(transpose(A),B)) which is O(n^3) in computational complexity. Fastor can determine this to be inefficient and will statically dispatch the call to an equivalent but much more efficient routine, in this case A_ij*B_ij or inner(A,B) which is O(n^2). Further examples of such mathematical transformation include (but certainly not exclusive to)
det(inv(A)); // transformed to 1/det(A), O(n^3) reduction in computation
trans(cof(A)); // transformed to adj(A), O(n^2) reduction in memory access
trans(adj(A)); // transformed to cof(A), O(n^2) reduction in memory access
A % B % b; // transformed to A % (B % b), O(n) reduction in computation [% is the operator matrix multiplication]
// and many moreThese expressions are not treated as special cases but rather the Einstein indicial notation of the whole expression is constructed under the hood and by simply simplifying/collapsing the indices one obtains the most efficient form that an expression can be evaluated. The expression is then sent to an optimised kernel for evaluation. Note that there are situations that the user may write a complex chain of operations in the most verbose/obvious way perhaps for readibility purposes, but Fastor delays the evaluation of the expression and checks if an equivalent but efficient expression can be computed.
For tensor networks comprising of many higher rank tensors, a full generalisation of the above mathematical transformation can be performed through a constructive graph search optimisation. This typically involves finding the most optimal pattern of tensor contraction by studying the indices of contraction wherein tensor pairs are multiplied, summed over and factorised out in all possible combinations in order to come up with a cost model. Once again, knowing the dimensions of the tensor and the contraction pattern, Fastor performs this operation minimisation step at compile time and further checks the SIMD vectorisability of the tensor contraction loop nest (i.e. full/partial/strided vectorisation). In a nutshell, it not only minimises the the number of floating point operations but also generates the most optimal vectorisable loop nest for attaining theoretical peak for those remaining FLOPs. The following figures show the benefit of operation minimisation (FLOP optimal) over a single expression evaluation (Memory-optimal - as temporaries are not created) approach (for instance, NumPy's einsum uses the single expression evaluation technique where the whole expression in einsum is computed without being broken up in to smaller computations) in contracting a three-tensor-network fitting in L1, L2 and L3 caches, respectively



A set of specialised tensors are available that provide optimised tensor algebraic computations, for instance SingleValueTensor or IdentityTensor. Some of the computations performed on these tensors have almost zero cost no matter how big the tensor is. These tensors work in the exact same way as the Tensor class and can be assigned to one another. Consider for example the einsum between two SingleValueTensors. A SingleValueTensor is a tensor of any dimension and size whose elements are all the same (a matrix of ones for instance).
SingleValueTensor<double,20,20,30> a(3.51);
SingleValueTensor<double,20,30> b(2.76);
auto c = einsum<Index<0,1,2>,Index<0,2>>(a,b);This will incur almost no runtime cost. As where if the tensors were of type Tensor then a heavy computation would ensue.
Fastor gets frequently tested against the following compilers (on Ubuntu 16.04/18.04/20.04, macOS 10.13+ and Windows 10)
- GCC 5.1, GCC 5.2, GCC 5.3, GCC 5.4, GCC 6.2, GCC 7.3, GCC 8, GCC 9.1, GCC 9.2, GCC 9.3, GCC 10.1
- Clang 3.6, Clang 3.7, Clang 3.8, Clang 3.9, Clang 5, Clang 7, Clang 8, Clang 10.0.0
- Intel 16.0.1, Intel 16.0.2, Intel 16.0.3, Intel 17.0.1, Intel 18.2, Intel 19.3
- MSVC 2019
For academic purposes, Fastor can be cited as
@Article{Poya2017,
author="Poya, Roman and Gil, Antonio J. and Ortigosa, Rogelio",
title = "A high performance data parallel tensor contraction framework: Application to coupled electro-mechanics",
journal = "Computer Physics Communications",
year="2017",
doi = "http://dx.doi.org/10.1016/j.cpc.2017.02.016",
url = "http://www.sciencedirect.com/science/article/pii/S0010465517300681"
}