stepjam / rlbench Goto Github PK
View Code? Open in Web Editor NEWA large-scale benchmark and learning environment.
Home Page: https://sites.google.com/corp/view/rlbench
License: Other
A large-scale benchmark and learning environment.
Home Page: https://sites.google.com/corp/view/rlbench
License: Other































































































































Hey folks,
This is a really nice work! I'm trying to use the embed function in IPython for creating interactive sessions so that it's easier to probe and play with the environment. However, after the environment starts simulation, I'm not able to call embed function, as the following error will appear:
Traceback (most recent call last): File "tmp.py", line 52, in <module> embed() File "/home/txiao/anaconda3/lib/python3.7/site-packages/IPython/terminal/embed.py", line 387, in embed frame.f_code.co_filename, frame.f_lineno), **kwargs) File "/home/txiao/anaconda3/lib/python3.7/site-packages/traitlets/config/configurable.py", line 412, in instance inst = cls(*args, **kwargs) File "/home/txiao/anaconda3/lib/python3.7/site-packages/IPython/terminal/embed.py", line 159, in __init__ super(InteractiveShellEmbed,self).__init__(**kw) File "/home/txiao/anaconda3/lib/python3.7/site-packages/IPython/terminal/interactiveshell.py", line 460, in __init__ self.init_prompt_toolkit_cli() File "/home/txiao/anaconda3/lib/python3.7/site-packages/IPython/terminal/interactiveshell.py", line 292, in init_prompt_toolkit_cli **self._extra_prompt_options()) File "/home/txiao/anaconda3/lib/python3.7/site-packages/prompt_toolkit/shortcuts/prompt.py", line 344, in __init__ output = output or get_default_output() File "/home/txiao/anaconda3/lib/python3.7/site-packages/prompt_toolkit/output/defaults.py", line 67, in get_default_output return create_output() File "/home/txiao/anaconda3/lib/python3.7/site-packages/prompt_toolkit/output/defaults.py", line 45, in create_output stdout, term=get_term_environment_variable()) File "/home/txiao/anaconda3/lib/python3.7/site-packages/prompt_toolkit/output/vt100.py", line 420, in from_pty isatty = stdout.isatty() ValueError: I/O operation on closed file
I'm wondering whether it's a desirable behavior, or I'm simply not supposed to do so.
Thanks!
New to the library — right now, gym.render only supports 'human', so it opens a window for the camera. Would it be possible to get the rgb_array for the scope camera just like for the wrist/shoulders, and return that from env.render("rgb_array", width, height)?
Hi! Thank you for RLBench!
I am running few_shot_rl.py example (using xvfb) and task.reset() takes a full minute to execute. It does not look like the correct behavior to me, so if you could give some advice on what the problem may be (or how to detect it), it would be very nice.
I tried setting OPENGL instead of OPENGL3 in all env cameras, but it did not help.
PC spec:
Ubuntu 18.04
Intel(R) Core(TM) i7-6700K
RAM: 60 Gb
GPUs: GTX 1080 (x2) and Titan V
I noticed when using dataset_generator.py that the low_dim_obs.pkl files are around 20MB each! I looked around a bit, and I think this might be because you don't None the mask images in obs before pickling.
I was collecting multiple demos for the OpenWineBottle task and noticed that it works fine on the first demo collected (cap is on bottle and robot removes cap from bottle), but on subsequent attempts the bottle is initialized with the cap on the table instead of the bottle, and the robot tries to plan its motion to the top of the bottle and then the environment just resets and puts the bottle in a different location. I've attached an image of the environment with the cap on the table, which is how it keeps being initialized after the first recorded demo.
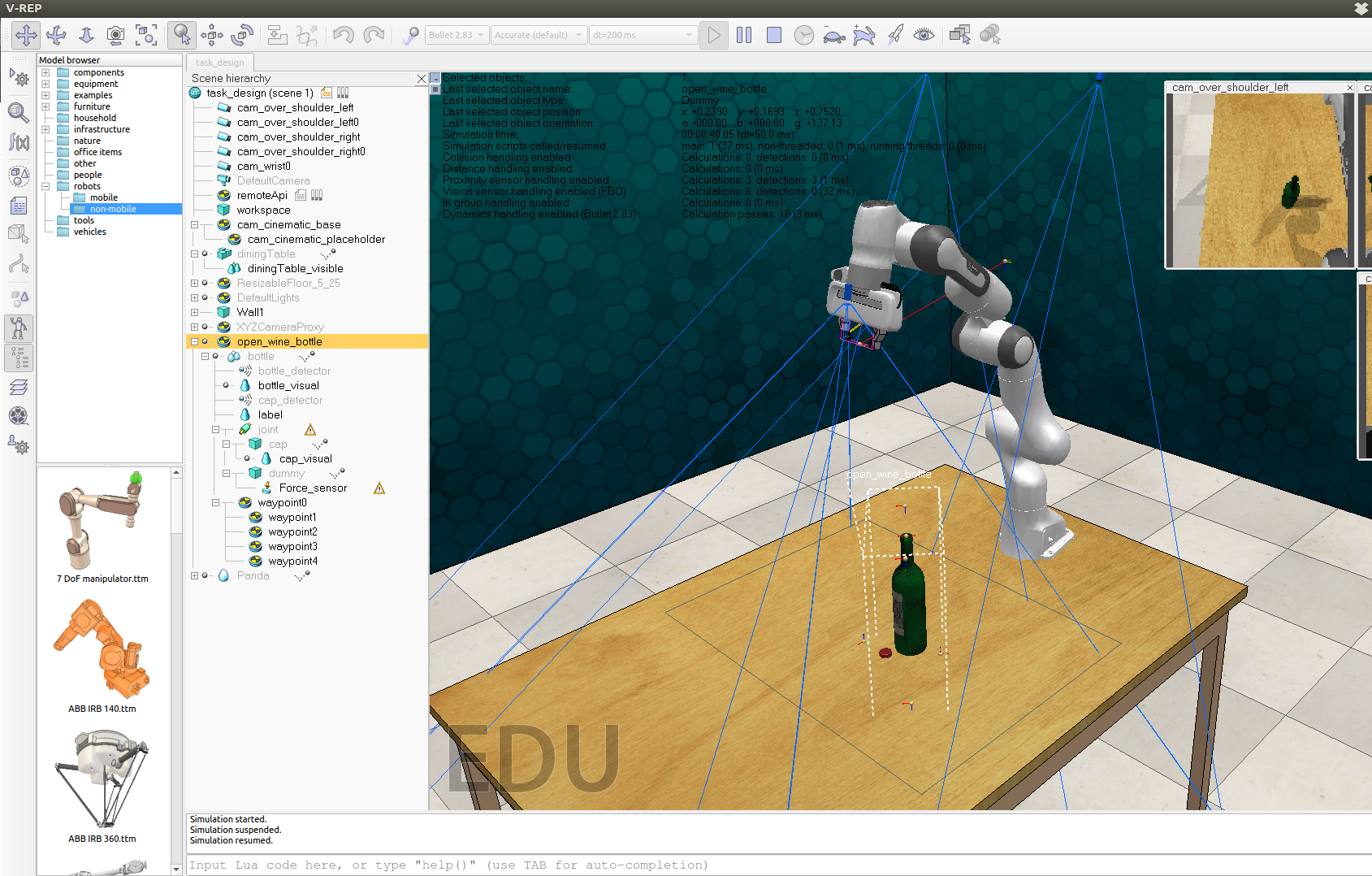
Hi, I'm really enjoying this fascinating environment you guys have released to facilitate the RL robotics research.
While I'm implementing some algorithms that is going to be tested on your environment, I encountered an error related to get_low_dim_data() method of Observation() class.
In
low_dim_data = [] if self.gripper_open is None else [self.gripper_open] for data in [self.joint_velocities, self.joint_positions, self.joint_forces, self.gripper_pose, self.gripper_joint_positions, self.gripper_touch_forces, self.task_low_dim_state]: if data is not None: low_dim_data.extend(data) return np.concatenate(low_dim_data),
the np.concatenate does not work since the gripper_open attribute is float, while others are np.ndarray, resulting the python complaining as
return np.concatenate(low_dim_data)
ValueError: zero-dimensional arrays cannot be concatenated
Is this a minor bug or am I using it in the wrong way?
Thanks in advance!
pyquaternion is required but not in requirements.txt
I got the following terminal output when trying the PutUmbrellaInUmbrellaStand task, which instructed me to raise an issue:
Traceback (most recent call last):
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 71, in reset
randomly_place=not self._static_positions)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/scene.py", line 104, in init_episode
raise e
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/scene.py", line 97, in init_episode
self._place_task()
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/scene.py", line 386, in _place_task
min_rotation=min_rot, max_rotation=max_rot)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/spawn_boundary.py", line 172, in sample
raise BoundaryError('Could not place within boundary.'
rlbench.backend.exceptions.BoundaryError: Could not place within boundary.Perhaps the object is too big for it?
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "collect_rlbench_data.py", line 94, in <module>
collect_demos(env, [task_class_name], h5_root, args.demos_per_task, len(args.task))
File "collect_rlbench_data.py", line 37, in collect_demos
demo = task.get_demos(1, live_demos=True)[0]
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 239, in get_demos
demos = self._get_live_demos(amount)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 248, in _get_live_demos
self.reset()
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 76, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_umbrella_in_umbrella_stand in the scene. This should not happen, please raise an issues on this task.
Here are the snippets from my code that are relevant:
obs_config = ObservationConfig()
obs_config.set_all(True)
action_mode = ActionMode(ArmActionMode.ABS_JOINT_VELOCITY)
env = Environment(action_mode, obs_config=obs_config, headless=args.headless)
env.launch()
task = env.get_task(PutUmbrellaInUmbrellaStand)
demo = task.get_demos(1, live_demos=True)[0]
My system:
venv)Continuation of #50 :
There are still errors with small delta (0.01). It is also really slow - taking around 2 seconds to find a path. Is this expected behavior?
I look this good framework for study.
When run single_task_rl.py with stackBlocks task it is stopped and raised this error.

How can I fix this?
Hi Stephen,
Thanks for sharing your hard work! This is quite impressive feat.
I'm trying to evaluate RLBench for an RL project, especially the rendering and simulation speed. I tried to measure the time it takes to take one step in the environment, but I'm getting inconsistent measurement. I'm running the following script from the example:
from rlbench.environment import Environment
from rlbench.action_modes import ArmActionMode, ActionMode
from rlbench.observation_config import ObservationConfig
from rlbench.tasks import ReachTarget
import numpy as np
import time
class Agent(object):
def __init__(self, action_size):
self.action_size = action_size
def act(self, obs):
return (np.random.normal(0.0, 0.1, size=(self.action_size,))).tolist()
obs_config = ObservationConfig()
obs_config.set_all(False)
obs_config.left_shoulder_camera.rgb = True
obs_config.right_shoulder_camera.rgb = True
action_mode = ActionMode(ArmActionMode.ABS_JOINT_VELOCITY)
env = Environment(
action_mode, obs_config=obs_config, headless=False)
env.launch()
task = env.get_task(ReachTarget)
agent = Agent(action_mode.action_size)
training_steps = 120
episode_length = 40
obs = None
for i in range(training_steps):
if i % episode_length == 0:
print('Reset Episode')
descriptions, obs = task.reset()
print(descriptions)
action = agent.act(obs)
b = time.time()
obs, reward, terminate = task.step(action)
print('time', time.time() - b)
print('Done')
env.shutdown()
The output I got is something like:
Reset Episode
['reach the red target', 'touch the red ball with the panda gripper', 'reach the red sphere']
time 0.4733397960662842
time 0.020693063735961914
time 0.019981861114501953
time 0.4483151435852051
time 0.02089381217956543
time 0.4511847496032715
time 0.4504091739654541
time 0.02108478546142578
time 0.451430082321167
time 0.44994044303894043
time 0.021603107452392578
time 0.4509134292602539
time 0.02010631561279297
time 0.45382070541381836
time 0.02047109603881836
time 0.020781755447387695
time 0.022526979446411133
time 0.4556691646575928
time 0.4509866237640381
time 0.44914793968200684
time 0.44646525382995605
time 0.45250749588012695
time 0.5030205249786377
time 0.0205843448638916
time 0.45667576789855957
time 0.021213293075561523
time 0.020083189010620117
time 0.020364046096801758
time 0.020453453063964844
time 0.021342992782592773
time 0.4546060562133789
time 0.02128005027770996
time 0.020647525787353516
time 0.45148324966430664
time 0.020636320114135742
time 0.4499623775482178
time 0.436708927154541
time 0.44021058082580566
time 0.020857810974121094
time 0.4387171268463135
Is this normal?
Also, how would you compare PyRep with Mujoco in terms of rendering speed? Thanks
There is probably a simple way to do this but I've been digging through source for a while and don't yet see it. Instead of randomly initializing a scene, I would like to place the objects in the scene at set poses in the workspace. My use case is I want to record demos where objects in the scene are placed randomly in the workspace, and then later I want to be able to recreate those same scene configurations. Is there a simple way to do this with the existing infrastructure?
I might be missing something, but it looks like an important step in creating the task in https://github.com/stepjam/RLBench/blob/master/tutorials/simple_task.md is to make the box not collidable. Otherwise the path will be planned around the box as opposed to through it.
This is just a question, not an issue.
Could you please share how you recorded your videos? I used the video recorder in V-REP, but the videos contain all the red or blue lines in simulation. Did you add a camera (with high resolution) and make it rotate programmtically? If so, could you please share that code?
The segmentation masks all have 3 channels, but only the first channel contains meaningful numbers and the other 2 channels are all zeros. Is there a reason behind this?
When I run the EmptyContainer task, I get the error:
Traceback (most recent call last):
File "collect_rlbench_data.py", line 192, in <module>
collect_demos(env, tasks, h5_root, args.n_demos_per_task, len(tasks))
File "collect_rlbench_data.py", line 103, in collect_demos
demo = task.get_demos(1, live_demos=True)[0]
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 239, in get_demos
demos = self._get_live_demos(amount)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 248, in _get_live_demos
self.reset()
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/task_environment.py", line 71, in reset
randomly_place=not self._static_positions)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/scene.py", line 93, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/tasks/empty_container.py", line 36, in init_episode
self.bin_objects = sample_procedural_objects(self.get_base(), 3)
File "/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/task_utils.py", line 10, in sample_procedural_objects
os.listdir(assets_dir), num_samples, replace=False)
FileNotFoundError: [Errno 2] No such file or directory: '/home/adam/venv3/lib/python3.5/site-packages/rlbench/backend/../assets/procedural_objects'
QObject::~QObject: Timers cannot be stopped from another thread
QMutex: destroying locked mutex
RLBench/rlbench/backend/task.py
Line 261 in 8ff9507
Am I missing something?
I tried running example/multi_task_rl.py and encountered the following error:
Reset Episode
['pick up the purple block and lift it up to the target', 'grasp the purple block to the target', 'lift the purple block up to the target']
Reset Episode ['pick up the purple block and lift it up to the target', 'grasp the purple block to the target', 'lift the purple block up to the target']
Reset Episode
Traceback (most recent call last): File "/home/costar/.local/lib/python3.6/site-packages/rlbench/task_environment.py", line 71, in reset
randomly_place=not self._static_positions)
File "/home/costar/.local/lib/python3.6/site-packages/rlbench/backend/scene.py", line 104, in init_episode
raise e
File "/home/costar/.local/lib/python3.6/site-packages/rlbench/backend/scene.py", line 97, in init_episode
self._place_task()
File "/home/costar/.local/lib/python3.6/site-packages/rlbench/backend/scene.py", line 386, in _place_task
min_rotation=min_rot, max_rotation=max_rot)
File "/home/costar/.local/lib/python3.6/site-packages/rlbench/backend/spawn_boundary.py", line 172, in sample
raise BoundaryError('Could not place within boundary.'
rlbench.backend.exceptions.BoundaryError: Could not place within boundary.Perhaps the object is too big for it?
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "multi_task_rl.py", line 44, in <module>
descriptions, obs = task.reset()
File "/home/costar/.local/lib/python3.6/site-packages/rlbench/task_environment.py", line 76, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task take_item_out_of_drawer in the scene. This should not happen, please raise an issues on this task.
QObject::~QObject: Timers cannot be stopped from another thread
QMutex: destroying locked mutex
Error: signal 11:
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libcoppeliaSim.so.1(_Z11_segHandleri+0x2b)[0x7fad08242eab]
/lib/x86_64-linux-gnu/libc.so.6(+0x3ef20)[0x7fad0a941f20]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Gui.so.5(_ZN15QGuiApplication13primaryScreenEv+0x13)[0x7fad06b0a463]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Gui.so.5(_ZN7QCursor3posEv+0x9)[0x7fad06b20b49]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libcoppeliaSim.so.1(_ZN13COpenglWidget38_handleMouseAndKeyboardAndResizeEventsEPvi+0x9a9)[0x7fad086b9d39]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libcoppeliaSim.so.1(_ZN13COpenglWidget16_timer100ms_fireEv+0x48)[0x7fad086ba888]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Core.so.5(_ZN11QMetaObject8activateEP7QObjectiiPPv+0x659)[0x7fad062acac9]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Core.so.5(_ZN6QTimer7timeoutENS_14QPrivateSignalE+0x27)[0x7fad062b9787]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Core.so.5(_ZN6QTimer10timerEventEP11QTimerEvent+0x28)[0x7fad062b9a58]
/home/costar/src/CoppeliaSim_Edu_V4_0_0_Ubuntu18_04/libQt5Core.so.5(_ZN7QObject5eventEP6QEvent+0x7b)[0x7fad062ad9db]
-> [1]
Hi, I was running the imitation learning code to get the velocities of the joints.
from rlbench.environment import Environment
from rlbench.action_modes import ArmActionMode, ActionMode
from rlbench.tasks import ReachTarget
import numpy as np
# To use 'saved' demos, set the path below
DATASET = 'PATH/TO/YOUR/DATASET'
action_mode = ActionMode(ArmActionMode.ABS_JOINT_VELOCITY)
env = Environment(action_mode, DATASET)
env.launch()
task = env.get_task(ReachTarget)
demos = task.get_demos(2) # -> List[List[Observation]]
demos = np.array(demos).flatten()
batch = np.random.choice(demos, replace=False)
batch_images = [obs.left_shoulder_rgb for obs in batch]
predicted_actions = predict_action(batch_images)
ground_truth_actions = [obs.joint_velocities for obs in batch]
loss = behaviour_cloning_loss(ground_truth_actions, predicted_actions)
ground_truth_actions variable is returning a list of None not float. I wanted to train this task with tensorflow but I am enable to get the velocities of the joints. Is it possible to extract them?
Hi, Awesome framework :)! It would be great if you can clarify some points about the simulator.
In the complex task tutorial, it is mentioned that "As previously mentioned, the physics engine runs far faster and smoother when all shapes for which it makes calculations are non-convex." I am not completely sure how having non-convex objects lead to faster simulations. Should the objects rather be convex as then calculations like collision detection would be must faster? Also, this seems to contradict the next line in the document "If a merge would result in a non-convex object being created, potential problems arise." Am I missing something here? Can you please also elaborate on what the potential problems are?
Related to the earlier question, can you please elaborate on "In this case, a merging would result in a non-convex shape, so we could instead make the mug body a child of the handle and hope that the body never has a force applied onto it that is not also applied to the handle" What could one expect to happen when a dynamic force is applied on the body of the cup?
It is mentioned that "Rather than rely on friction and reactionary force as a person would when picking something up, RLBench and PyRep simplify physics calculations (and thus speed up and smooth out simulation) by making any object upon which the Panda's gripper closes on a child of the Panda tip, as long as said object has been registered as graspable in the python file." I assume there must be some kind of distance threshold being set between the object and the tip of the gripper. Am I correct in assuming that the relative size of the gripper and the object does not matter here if the size threshold is set correctly i.e. something larger than the gripper can also be grasped? Further, if a distance threshold is calculated, is it based on the nearest coordinate in the object mesh or just the object centroid? I am asking this as the later case could be problematic with objects like stick which have skewed dimensions? Lastly, does the angle between the gripper and the object matter?
Also what kind of forces and constraints come into play for an object with hinges, for example, the door? (It would be great if there is some tutorial describing how to make such a task :)) Are unmovable part of the objects assumed to be static and unaffected by any force. Also, will the simulator ignore any actions that would potentially lead to violation of the "hinge constraint" like pulling the door when grasped? Further, what kind of forces come into play in the "rope" manipulation example? Can the simulator also handle some spring constrains?
Thanks in advance! Pardon me if this info is already available somewhere else.
This is a feature request. I think it would be nice to have a way of viewing an execution of each task without actually having to load up the simulator and run it. Your YouTube video that gives an overview of RLBench is very nice, but I'm still finding that I see a task name and, though it's descriptive, I ideally could watch a video of it so I know exactly what the robot is going to try to do.
If this is impractical then you can close, but a couple thoughts are having a readme page with GIFs that show each task, or having YouTube videos of each task that you can just click to and watch the video.
My current use case is I've recorded demos for every task in a headless manner. I'm now trying to divide the data into train/test sets so I know if they were seen/unseen environments in testing, but it's hard for me to tell without actually launching the simulator or trying to see if it's shown in your overview YouTube video.
I'm looking into using RLBench, thanks for creating it! Are any baseline algorithms already integrated in this repository or another one?
So you’re saying there is no other RL repository which already has this one integrated? Correct me if I’m mistaken, but if there are no known, working, and integrated clients I feel like there will be a lot of debugging to do in this project and it may not be ready for use unless one is willing to go through debugging the whole API themselves. I'm not trying to criticize, rather I’m asking to understand the scope of work if I were to use this project seriously. I have a paper & project which uses the vrep api and I’m figuring out the possibility of integrating that with this work https://github.com/jhu-lcsr/good_robot.
Sorry for duplicating #25, but my followup question seems to have been lost, and I can't figure out how to reopen it.
Hi Stephen,
Thanks for open sourcing your work! Is there a way to add more arms into the environment and design tasks that use multiple arms?
Thanks!
Hi,
I installed PyRep and RLBenchmark. They together seem promising. I have encountered two bugs while following the "Simple Task Walkthrough".
When trying to run the task builder, it was not able to find the task validator. So I needed to change the import at the start of task builder
from
from tools.task_validator import task_smoke, TaskValidationError
to
from task_validator import task_smoke, TaskValidationError
While trying to create a non-existing task, at first it says that it does not exist in the system, would you like to create it. However, when you want to create it the system throws errors as follows: (XXXX is the new task name)
ModuleNotFoundError: No module named 'rlbench.tasks.XXXX'
rlbench.utils.InvalidTaskName: The task file 'XXXX' does not exist or cannot be compiled.
And a small note, the task in the tutorial slide_block_to_target already exists, you may want to change it as in the screenshot to slide_block
Best
When I create a Vision sensor in the environment, even if I don't invoke capture_rgb(), the task steps become dramatically slower. Using cProfile shows some of the calls taking .17s and the others taking 2-4 seconds, and this is occurring in the task.step() function (and further down the stack, in sim.py extstep.) In comparison, without, it takes about ~0.008 for some and ~0.155 for others. Could you explain the discrepancy in the speeds for the vision, as well as the discrepancy in the speeds between the calls?
I tried to work around this, and in the scenario that I load in the Vision sensor in the task (in the ttm) itself, I see the same calls to the step (not the capture_rgb()) taking .02s & .6s. Is there rendering being done in the step? This is still too slow for our purposes. What is the proper way to add a vision sensor to speed up as fast as possible?
Debugging: Looks like the calls that take longer are due to calling extstep 20 times versus once.
I'm also seeing:
pyrep.py:209: UserWarning: Could no
t change simulation timestep. You may need to change it to "custom dt" using simulation
settings dialog.
which may be related.
I'm trying to to change the arm to Mico in imitation learning script. But I got some problems as:
File "/home/ggb/.local/lib/python3.6/site-packages/pyrep/robots/end_effectors/gripper.py", line 146, in get_touch_sensor_forces
raise NotImplementedError('No touch sensors for this robot!')
NotImplementedError: No touch sensors for this robot!
I tried mico,jaco,swayer in several tasks, all they went wrong with no touch sensor error. So I set the obs_config/gripper_touch_forces to False and try ReachTarget task since I think this task may not need touch sensors. But it come to the second problem.
Warning: SBL: Skipping invalid goal state (invalid bounds)
at line 310 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Warning: SBL: Skipping invalid goal state (invalid bounds)
at line 310 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
the arm has no action and the scene keeps changing. I think it may because the get_demos() function cannot get proper planning.
So can you give me some advice for how I can adjust task to different arms in imitation learning to get right demos.
Hi, I am using jaco for reinforcement in RLBench. I tried the RLBench/examples/single_task_rl.py and I have two questions:
env = Environment(action_mode=action_mode, robot_configuration='jaco', obs_config=obs_config, headless=False)Traceback (most recent call last):
File "rlbench_test.py", line 44, in <module>
obs, reward, terminate = task.step(action)
File "/home/gck/.local/lib/python3.6/site-packages/rlbench/task_environment.py", line 147, in step
(len(self._robot.arm.joints),))
File "/home/gck/.local/lib/python3.6/site-packages/rlbench/task_environment.py", line 109, in _assert_action_space
str(expected_shape), str(np.shape(action))))
RuntimeError: Expected the action shape to be: (6,), but was shape: (7,)
QObject::~QObject: Timers cannot be stopped from another thread
QMutex: destroying locked mutex
I think this is because the action number is not set correctly, so I go to your code (action_modes.py) and find how to set it. Then I add two lines and it runs normal:
action_mode.arm.action_size = 6
action_mode.action_size = action_mode.arm.action_size + action_mode.gripper.action_size
I don't know if this is a proper way, so I want to ask you for suggestion.
for i in range(training_steps):
if i % episode_length == 0:
print('Reset Episode')
descriptions, obs = task.reset()
print(descriptions)
action = agent.act(obs)
print(action)
obs, reward, terminate = task.step(action)
print('steps:',i)
In the simulation, one 'step' function sometimes lasts for 1s or 2s sometimes only for 1ms. It looks like this. You can see that it seems like sometimes the step function just stucks.
If I want to replace the default arm with another robotic arm in the lab, how can make it?
Would it be possible to add a full working example with tf2.0 keras? The current examples seem to only have numpy random actions
The latest changes to setup.py apparently doesn't copy the task_ttms to site-packages, and then running the imitation_learning.py cannot find the task ttm file and fails. I'm using python 3.6.9.
For slide_block_to_target task, the object and target are not rendered correctly in cameras (see attached screenshots. I haven't seen this issue in any other task.


Hi! Amazing framework - I was playing around with it and an issue occured that requested I raise it here -
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Warning: SBL: Skipping invalid start state (invalid state)
at line 248 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/base/src/Planner.cpp
Error: SBL: Motion planning start tree could not be initialized!
at line 101 in /home/marc/Documents/ompl-1.4.2-Source/src/ompl/geometric/planners/sbl/src/SBL.cpp
Traceback (most recent call last):
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 70, in reset
randomly_place=not self._static_positions)
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/backend/scene.py", line 93, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/tasks/put_knife_in_knife_block.py", line 31, in init_episode
self.boundary.sample(self.chopping_board)
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/backend/spawn_boundary.py", line 176, in sample
'Could not place the object within the boundary due to '
rlbench.backend.exceptions.BoundaryError: Could not place the object within the boundary due to collision with other objects in the boundary.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "single_task_rl_with_demos.py", line 35, in <module>
demos = task.get_demos(20, live_demos=live_demos)
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 238, in get_demos
demos = self._get_live_demos(amount)
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 248, in _get_live_demos
self.reset()
File "/home/sholto/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 75, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_knife_in_knife_block in the scene. This should not happen, please raise an issues on this task.
QObject::~QObject: Timers cannot be stopped from another thread
QMutex: destroying locked mutex
For the imitation learning example script, is it possible to send the predicted actions to the scene instead of just computing the loss?
By this I mean, can I test the robot with my networks' prediction?
I basically know how to do this with PyRep, but not with RLBench. Would really appreciate it if you can advise.
Thanks for the great work and effort you are putting on this!
I'm printing out the gripper touch forces on the observation state and I see it is a vector of 6 floats. Am I to interpret that as the 3-D contact force felt by each of the two fingers (e.g. first 3 values are force for one finger and the last 3 are forces for the other finger)? Or is it a 6-D wrench with 3 force values and 3 torque values?
>>> import rlbench Traceback (most recent call last): File "<stdin>", line 1, in <module> File /vrep/lib/python3.5/site-packages/rlbench-1.0-py3.5.egg/rlbench/__init__.py", line 5, in <module> from rlbench.sim2real.domain_randomization import RandomizeEvery ImportError: No module named 'rlbench.sim2real'
Hi there, after I install rlbench, the following error occurs. Thanks.
I ran python3 dataset_generator.py --episodes_per_task 1 --processes 5
I can't tell if there was a speed-up or not from using multiple processes, but that's for me to investigate further at my end.
4 out of those 5 processes errored out at some point on put_plate_in_colored_dish_rack:
i)
Process Process-2:
Traceback (most recent call last):
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 81, in reset
randomly_place=not self._static_positions)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/scene.py", line 97, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/tasks/put_plate_in_colored_dish_rack.py", line 56, in init_episode
self.boundary.sample(self.dish_rack, min_distance=0.2)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/spawn_boundary.py", line 176, in sample
'Could not place the object within the boundary due to '
rlbench.backend.exceptions.BoundaryError: Could not place the object within the boundary due to collision with other objects in the boundary.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "dataset_generator.py", line 165, in run
obs, descriptions = task_env.reset()
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 86, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_plate_in_colored_dish_rack in the scene. This should not happen, please raise an issues on this task.
ii)
Process Process-3:
Traceback (most recent call last):
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 81, in reset
randomly_place=not self._static_positions)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/scene.py", line 97, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/tasks/put_plate_in_colored_dish_rack.py", line 56, in init_episode
self.boundary.sample(self.dish_rack, min_distance=0.2)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/spawn_boundary.py", line 176, in sample
'Could not place the object within the boundary due to '
rlbench.backend.exceptions.BoundaryError: Could not place the object within the boundary due to collision with other objects in the boundary.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "dataset_generator.py", line 165, in run
obs, descriptions = task_env.reset()
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 86, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_plate_in_colored_dish_rack in the scene. This should not happen, please raise an issues on this task.
iii)
Process Process-4:
Traceback (most recent call last):
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 81, in reset
randomly_place=not self._static_positions)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/scene.py", line 97, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/tasks/put_plate_in_colored_dish_rack.py", line 56, in init_episode
self.boundary.sample(self.dish_rack, min_distance=0.2)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/spawn_boundary.py", line 176, in sample
'Could not place the object within the boundary due to '
rlbench.backend.exceptions.BoundaryError: Could not place the object within the boundary due to collision with other objects in the boundary.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "dataset_generator.py", line 165, in run
obs, descriptions = task_env.reset()
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 86, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_plate_in_colored_dish_rack in the scene. This should not happen, please raise an issues on this task.
iv)
Process Process-5:
Traceback (most recent call last):
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 81, in reset
randomly_place=not self._static_positions)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/scene.py", line 97, in init_episode
descriptions = self._active_task.init_episode(index)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/tasks/put_plate_in_colored_dish_rack.py", line 56, in init_episode
self.boundary.sample(self.dish_rack, min_distance=0.2)
File "/home/user/.local/lib/python3.7/site-packages/rlbench/backend/spawn_boundary.py", line 176, in sample
'Could not place the object within the boundary due to '
rlbench.backend.exceptions.BoundaryError: Could not place the object within the boundary due to collision with other objects in the boundary.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/home/user/alpha/taskemb/env/lib/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "dataset_generator.py", line 165, in run
obs, descriptions = task_env.reset()
File "/home/user/.local/lib/python3.7/site-packages/rlbench/task_environment.py", line 86, in reset
% self._task.get_name()) from e
rlbench.task_environment.TaskEnvironmentError: Could not place the task put_plate_in_colored_dish_rack in the scene. This should not happen, please raise an issues on this task.
when calling render, I'm getting a penalty of 30x on my step time. Is this to be expected? Are there ways to improve step time while rendering? Like, for example, speeding up simulation time or something?
I'm curious, because I'm currently runinng experiments where I want to inspect the robot at different time steps but I don't know when these appear beforehand. One solution would be recording a video of every time step but given the insane slow down I consider this infeasible.
As an alternative I thought of recording all actions which would allow me to "replay" certain parts of the simulation. For that to work I would need to be able to restore the simulator state for arbitrary time points. Is this possible and if yes what is the suggested approach for this?
Setting action_mode = ActionMode(ArmActionMode.DELTA_EE_POSE) for the gym reach_target task, for example, gives rlbench.task_environment.InvalidActionError: Could not find a path. This is due to the action_space giving out of bounds possibilities.
Edit: after looking into this it seems that the IK breaks even with tiny epsilon (< 0.0005) movement, perhaps when colliding into an object? not sure.
Hi, stepjam!
I really appreciate what you've done and this is a good benchmark for researchers in robotics. But I hope if you can make the tasks be compatible with OpenAI's gym environment since there are a lot of RL algorithms developed by others which we can use as the baseline performance easily. Thanks.
Using the gym environment.
When working with print(), it seems that after calling env.reset(), print outputs are getting buffered i.e. not synchronously outputted to the console.
Invoking python with -u does not seem to make a difference.
I just want to replace the Panda arm with Mico arm, I just simply edited the task.ttt where I changed the Panda arm to Mico arm. Then I edited the code:
self._robot = Robot(Mico(), MicoGripper())
And when I run the demo script I got the error message.
So is there anybody have success experience to replace the arm ?
Or is there some detailed descriptions for changing arm?
I have tried collecting demos in the TvOn, TvOff, and ChangeChannel tasks, as well as PushButton and PushButtons, but none of them complete successfully. They all get initialized correctly and the robot plans and executes the motions, but it seems the actual button presses are maybe not being registered? The environment just keeps resetting and executing the task without success.
What's the supported way to edit environments (the task ttms) programmatically?
The segmentation mask for the wrist camera seems to stay where it was initialized, instead of tracking with the movement of the hand. This can be seen in the GIF below that shows the wrist RGB and wrist segmentation mask side-by-side synchronized in time. I'll emphasize that the segmentation mask is not from one of the shoulder cams, it actually is associated with the wrist camera.

In RLBench_env.py, step() function should return {} instead of None
What stepping speeds are you seeing for the base (i.e., delta joint velocity), no cameras? I'm seeing 0.008s flat, but this seems to be too slow for our research. For example, mujocopy sees 0.0024s per step.
Hi Stephen, first of all thank you so much for building this amazing tool.
I am trying to use your dataset_generator.py file but I am getting this error
Traceback (most recent call last): File "/usr/lib/python3.5/multiprocessing/process.py", line 249, in _bootstrap self.run() File "/usr/lib/python3.5/multiprocessing/process.py", line 93, in run self._target(*self._args, **self._kwargs) File "dataset_generator.py", line 148, in run if my_variation_count >= task_env.variation_count(): AttributeError: 'TaskEnvironment' object has no attribute 'variation_count' Data collection done!
Any guidance on this would be hugely appreciated!
Thanks so much,
Sambhav
Hello,
I downloaded lots of demos for which I needed the images also loaded in the Observation object when I do task.get_demos(n,live_demos=False). I noticed that in the code you have kept a bool on image_paths. Is there going to be support in the future for loading those images to memory ?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.