graspnet / graspnet-baseline Goto Github PK
View Code? Open in Web Editor NEWBaseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
Home Page: https://graspnet.net/
License: Other
Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
Home Page: https://graspnet.net/
License: Other












































































































Hi, thanks for the code and interesting research! I found this repository via the AnyGrasp paper.
I am just wondering, how does this repository compare to the models used in that paper? Are the weights used in that paper available also?
How can we reproduce the results and training process from that paper?
Thanks very much!
I want to use your work, I want to build my own 3D data set, but what about the meta, grasp_label, dex_models file contents? Can you give me some information for reference?
thank you
I have a question about how to measure the estimation accuracy. In both training (train.py) and evaluation (test.py), the estimation accuracy seems to be calculated by loss.py. However, when I look at loss.py, I can't help but feel that it assumes that the answer is known before both training and evaluation. For example, the objectness_mask calculated by the compute_view_loss function is generated from the training data (objectness_label), but I think it should be generated from its own output (objectness_pred). Similarly, I thought the same could be said for the graspable_mask calculated by the compute_grasp_loss function. If I have misunderstood something, I would appreciate it if you could let me know.
Great article! I managed to get the code up and running and I am considering using it for my bachelor thesis in robotics.
My problem is that i cannot get nearly as good point-clouds as you have in your demo data. Did you use any filters or fused multi-view point clouds etc.?
E.g. this

Turns into this:

Hi~ I want to ask if there are mesh models like .dae files, so I can insert them to gazebo environment to simulate grasp.
Hoping for reply, thanks
@Fang-Haoshu @chenxi-wang
Thank for sharing great work !
I have 2 questions about your work :
Hope to hear your response soon.
@Fang-Haoshu @chenxi-wang
Thanks for this publication as well as the open source code.
I have a question reagarding the resulting grasps. Using the pretrained weights and the demo code, the network will sometimes not return any grasps on the object:

Do you have any idea how to make it work in this scenario?
Additionally, I do not understand how to use the grasp depth and height. I looked at this issue, but still do not get what this information represents.
Using a parallel gripper, shouldn't the translation and rotation be enough to determine where to grasp the object?
I have implemented your code on a Universal Robots manipulator mounted with Realsense d435 and OnRobot parallel gripper, and when sending the TCP to the grasp translation and rotation, it always seem to be a few cm short of gripping the object correct. Could this be related to not using the depth and height information?
Best regards,
Emil Holst
Hi everyone.
I was running the evaluation procedure, and I would like to have some clarification:
Thanks for your kind.
Hi,
Thank you for releasing the code, the repo is very nice!
Is there a chance you can share a pretrained model for paper's results verification/reproduction purposes?
Hi, thanks for sharing your work. It really facilitates robotic grasping. I am using your code recently in the gazebo. I found that the generated grasp points are on the edge of the table or inserts into the body of the can as in the figure below. The elevation of the camera is set to 45 degrees in my case. Could I ask if the graspnet is more suitable for top-down view( nearly 90 degrees to be perpendicular to the table) or top-down grasping?

Could you provide more detailed docs or tools for annotating grasp poses?
Thanks!
In the last step, is it necessary to artificially refine the gt grasp data set for generation?
If so, what tools are used to quickly mark up positive and negative samples?
Are there any other indicators of how accurate an object is to grasp? I would like to know how accurate the baseline is on common objects
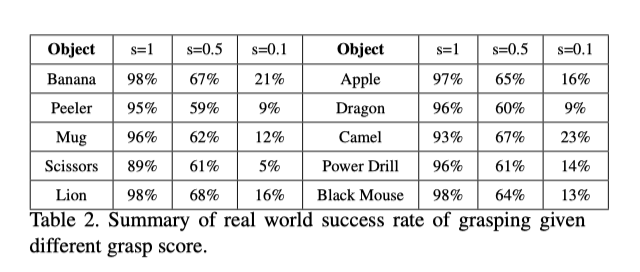
Hi,thanks for your great work!I have two questions about your code:
graspnet-baseline/dataset/graspnet_dataset.py
Line 199 in df67956
graspnet-baseline/dataset/graspnet_dataset.py
Line 255 in df67956
Hi,
First of all thanks for the great work. I wonder to know if you merge the multi-view captured view to register the point cloud before training the network or if you feed each captured view separately to the network?
Thanks in advance for the response
您好,我在尝试使用多显卡训练的时候,设置参数如下:
os.environ["CUDA_VISIBLE_DEVICES"] = '0,3' net = nn.DataParallel(net.cuda())
但是模型加载数据的时候出现错误:
RuntimeError: Caught RuntimeError in replica 0 on device 0.
请问作者在多显卡训练的时候是否遇到过这个问题?
Thanks for your great job!
May I ask where can we find Supplementary materials(mentioned at the end of 3.2 part of paper)
Cause we want to know more details of your data collection process)
Thanks very much!
您好,我电脑上有两张显卡,一张2080Ti,一张1080,驱动为NVIDIA-SMI 450.66,CUDA10.1
我想在1080上跑测试,于是我将command_test.sh中的CUDA_VISIBLE_DEVICES=0改为了CUDA_VISIBLE_DEVICES=1
但当我运行sh command_test.sh时,会报如下错误:
CUDA kernel failed : no kernel image is available for execution on the device
void furthest_point_sampling_kernel_wrapper(int, int, int, const float*, float*, int*) at L:233 in /home/agent/grasp/graspnet-baseline/pointnet2/_ext_src/src/sampling_gpu.cu
该错误发生的位置大概是inference()中的
for batch_idx, batch_data in enumerate(TEST_DATALOADER)
请问是什么原因导致的呢?
what is the workspace mask? when i see doc/example_data/workspace_mask.png , it is a white picture. ICan it be used in any scen?
Hi everyone.
I am using your work in order to build a vision-based grasping system for my master thesis.
By running the demo.py and by observing the grasp score, there are grasps that have a score greater than 1, but from your paper, I would have expected a max grasp score of 1.
So, why are there grasps scores greater than 1?
Thanks.
I'm very interested in your research of Anygrasp, when will the code and paper of AnyGrasp be made publicly available?
Hi, thanks for sharing the code and it looks very interesting. I am try to run the code following the readme. But when I use GPU mode it runs into segmentation fault "net.to(device)". I tested both train.py and test.py and both have the same error. When I force device="CPU", it also fails. Do you know how to fix this?
My environment is:
RTX2080 Ti+ Ubuntu 18.04 + python 3.6 + cuda 10.1 + pytorch 1.6
Thanks so much for your help!
The red marker in the picture shows pose error from image 128 with scene 161.

Best regards,
Rui Cao
"Loading grasping" can be loaded, but "loading data path and collision labels" cannot be completely loaded and killed
When training graspnet-baseline in my own enviroment, I find that it will cosuming too much memory(about 60G). GPU memory is about 10G when batch size=2. It's hard for me to train it on some low memory server. I'm not sure if this is a bug and if not, is there any solution to reduce it?
Hello, it seems that all data you make is in real environment?
Will you make you data in simulation like pybullet or others like dex-net pipeline?
The dex-net pipeline means that all data is synthesis and robot can work in real environment, as far as i know, the competition OCRTOC, seems you have participated, may a good place to generate synthesis dataset, have you began to do so or?
Thank you~
Hi everyone.
I was trying to run the detector on new point clouds taken from Gazebo, through a plugin that simulates the Realsense-435 camera,
After the inference process, I obtained grasps that are on the "floor".

By reading issue #18 you talked about a possible wrong objectness mask due to incorrect coordinate frames.
I would like to know what did you mean in detail, and how could I resolve this problem?
I know that I could filter out the background point, but from the demo you have provided, it seems to me that, it is not performed any background subtraction, is it?
Thanks for your kind.
What means by grasp_height and grasp_width?
I read the source code models/graspnet.py:79,butI don't understand what grasp_height and grasp_depth mean.
I understand other parameters. For example, grasp_width is the gripper's gripping width.
thanks
Hi @chenxi-wang,
I was trying to transplanted this algorithm to the real robotic arm.
I found that the rotation matrixs generated by the pretrained model have difference with the real camera frame.Specifically,I need to multiply a matrix to the left of the rotation matrixs generated by the pretrained model,then I can get the correct matrixs under the camera frame.And the matrix T which I need to multiply left is:[0,0,1;1,0,0;0,1,0]
Blow is a instance of my question,the frame A is the camera frame,the frame B is the target frame generated by the pretrained model,the frame C is multiply T to the left of the frame B,and this is the frame corrspond to real camera frame:
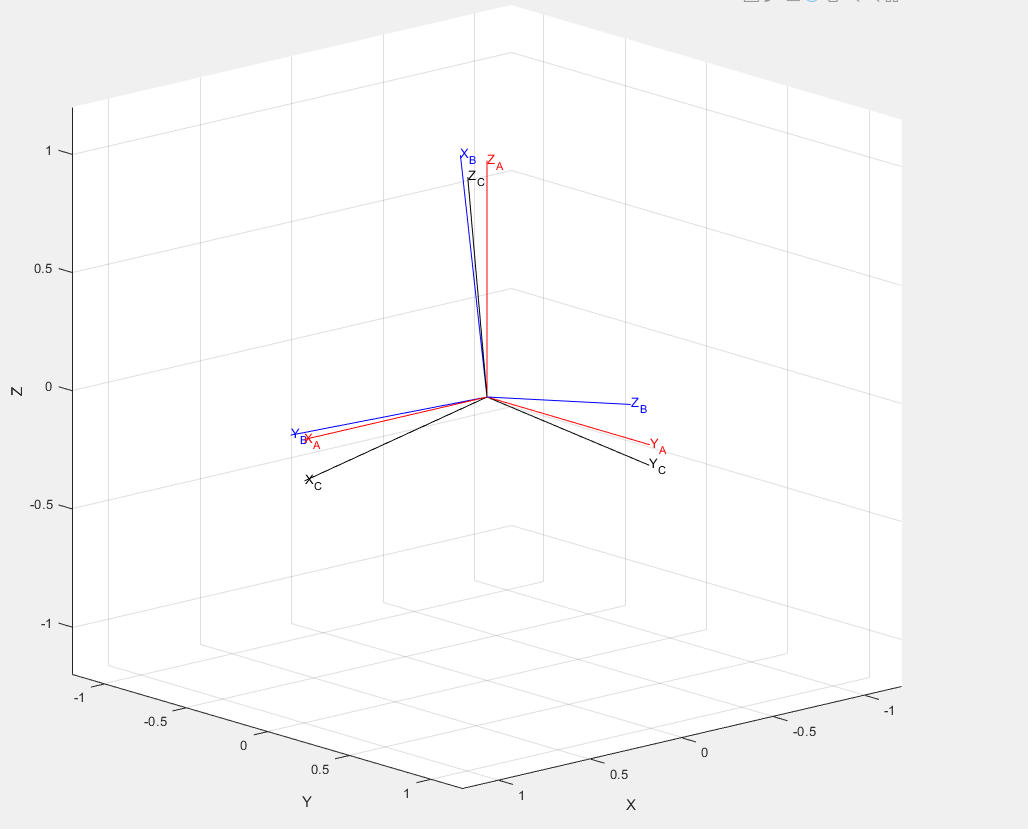
Can you tell me why I need to multiply a matrix to the left of the rotation matrixs generated by the pretrained model?Thanks!
Regards,
JingKang
$ bash command_train.sh
Traceback (most recent call last):
File "train.py", line 21, in <module>
from graspnet import GraspNet, get_loss
File "/home/weiwen/mnt0/mail2020/graspDL/graspnet-baseline/models/graspnet.py", line 22, in <module>
from label_generation import process_grasp_labels, match_grasp_view_and_label, batch_viewpoint_params_to_matrix
File "/home/weiwen/mnt0/mail2020/graspDL/graspnet-baseline/utils/label_generation.py", line 14, in <module>
from knn_modules import knn
File "/home/weiwen/mnt0/mail2020/graspDL/graspnet-baseline/knn/knn_modules.py", line 7, in <module>
from knn_pytorch import knn_pytorch
ModuleNotFoundError: No module named 'knn_pytorch'did I miss sth ?
I want to use this model in real robot experiment. And I want to use the rotate matrix of grasp to get the TCP value——"rx, ry, rz". But I can't get a right final position of gripper when multiply TCP rotate matrix with grasp rotate matrix to get "rx, ry, rz", the TCP rotate matrix is from foundation support to TCP. The gripper direction didn't match with the result in open3d visualization. Could you give me some details about using the grasp rotate matrix? Thanks.
After following given instructions, i got errors while trying to run python setup.py install

Hi~ When I output the model to .pt file() [in demo.py]
` example = end_points['point_clouds']
traced_script_module = torch.jit.trace(net, example)
traced_script_module.save("model-graspnet.pt")`
[I have changed the input and output of the net to tensors to trace]
But I get error like this:
Traceback (most recent call last):
File "demo.py", line 162, in
demo(data_dir)
File "demo.py", line 147, in demo
traced_script_module.save("model-graspnet.pt")
File "/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/jit/init.py", line 1987, in save
return self._c.save(*args, **kwargs)
RuntimeError:
Could not export Python function call 'FurthestPointSampling'. Remove calls to Python functions before export. Did you forget add @script or @script_method annotation? If this is a nn.ModuleList, add it to constants:
/home/twilight/project/graspnet-baseline/pointnet2/pointnet2_modules.py(235): forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(704): _slow_forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(720): _call_impl
/home/twilight/project/graspnet-baseline/models/backbone.py(105): forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(704): _slow_forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(720): _call_impl
/home/twilight/project/graspnet-baseline/models/graspnet.py(33): forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(704): _slow_forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(720): _call_impl
/home/twilight/project/graspnet-baseline/models/graspnet.py(74): forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(704): _slow_forward
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/nn/modules/module.py(720): _call_impl
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/jit/init.py(1109): trace_module
/home/twilight/anaconda3/envs/graspnet/lib/python3.7/site-packages/torch/jit/init.py(955): trace
demo.py(145): demo
demo.py(162):
I don't know why, can you help me?
I tried to use sh command_test.sh to test a trained model, but it reported an error in loading dexnet model, as shown in the following. I would like to inquire if you have any ideas to solve this problem. Thanks very much.
Loading data path and collision labels...: 100%|████████████████████████| 90/90 [00:00<00:00, 219.96it/s]
23040
23040
-> loaded checkpoint logs/log_rs/checkpoint.tar (epoch: 12)
Loading data path...: 100%|█████████████████████████████████████████████| 90/90 [00:00<00:00, 205.90it/s]
multiprocessing.pool.RemoteTraceback:
"""
Traceback (most recent call last):
File "/home/amax/miniconda3/envs/py37/lib/python3.7/multiprocessing/pool.py", line 121, in worker
result = (True, func(*args, **kwds))
File "/home/amax/zzhaoao/Grasp/graspnetAPI/graspnetAPI/graspnet_eval.py", line 121, in eval_scene
model_list, dexmodel_list, _ = self.get_scene_models(scene_id, ann_id=0)
File "/home/amax/zzhaoao/Grasp/graspnetAPI/graspnetAPI/graspnet_eval.py", line 52, in get_scene_models
dexmodel = pickle.load(f)
AttributeError: 'ColorVisuals' object has no attribute 'crc'
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "test.py", line 119, in <module>
evaluate()
File "test.py", line 113, in evaluate
res, ap = ge.eval_all(cfgs.dump_dir, proc=cfgs.num_workers)
File "/home/amax/zzhaoao/Grasp/graspnetAPI/graspnetAPI/graspnet_eval.py", line 305, in eval_all
res = np.array(self.parallel_eval_scenes(scene_ids = list(range(100, 190)), dump_folder = dump_folder, proc = proc))
File "/home/amax/zzhaoao/Grasp/graspnetAPI/graspnetAPI/graspnet_eval.py", line 231, in parallel_eval_scenes
scene_acc_list.append(res.get())
File "/home/amax/miniconda3/envs/py37/lib/python3.7/multiprocessing/pool.py", line 657, in get
raise self._value
AttributeError: 'ColorVisuals' object has no attribute 'crc'
1.运行test.py时,torch.load()报错:
Traceback (most recent call last):
File "test.py", line 60, in
checkpoint = torch.load(cfgs.checkpoint_path)
File "/home/xup/anaconda3/envs/pytorch11/lib/python3.6/site-packages/torch/serialization.py", line 387, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "/home/xup/anaconda3/envs/pytorch11/lib/python3.6/site-packages/torch/serialization.py", line 560, in _load
raise RuntimeError("{} is a zip archive (did you mean to use torch.jit.load()?)".format(f.name))
RuntimeError: logs/log_rs/checkpoint.tar is a zip archive (did you mean to use torch.jit.load()?)
2.把checkpoint.tar解压后,把模型载入路径改为./checkpoint_rs/archive/data.pkl,则报错:
Traceback (most recent call last):
File ".../graspnet-baseline/test.py", line 60, in
checkpoint = torch.load(cfgs.checkpoint_path)
File "/home/xup/anaconda3/envs/pytorch11/lib/python3.6/site-packages/torch/serialization.py", line 387, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "/home/xup/anaconda3/envs/pytorch11/lib/python3.6/site-packages/torch/serialization.py", line 564, in _load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: A load persistent id instruction was encountered,
but no persistent_load function was specified.
通过网上查询,说该报错应该是torch版本问题,需要训练和预测时版本一致,但是我测了pytorch1.1/1.6.0/1.8.0都报同样的错误。
请问该预训练权重是pytorch什么版本报错的?或者知道是其他什么原因导致吗?谢谢
您好,我在进行graspnet模型训练大约5小时后,第一个epoch还没有结束时,程序突然变的异常缓慢,batch: 12800 。我的服务器环境为:RTX3090 CUDA11.1 Pytorch1.7 python3.6,CPU内存128GB,batch_size = 2,epoch = 18,加载了所有的数据,包括100个测试场景和30个见过的物体,消耗CPU内存大概70G。
这是显卡占用情况,显存占用较高,但是功率很低(刚开始是正常):

这是截止到当时的训练结果:

请问您在训练的时候遇到过这个问题吗?最后的损失在0.6左右,请问您的模型训练多次时间,总损失为多少?感谢您的回复
备注:刚开始训练时,一切正常,只是在几小时后异常缓慢
Hi~
I want to run the forward demo on windows, but when I run "python setup.py install" in knn file, occured error:
vision.obj : error LNK2001: 无法解析的外部符号 "struct THCState * state" (?state@@3PEAUTHCState@@ea)
build\lib.win-amd64-3.6\knn_pytorch\knn_pytorch.cp36-win_amd64.pyd : fatal error LNK1120: 2 个无法解析的外部命令
error: command 'P:\VisualStudio2019\VC\Tools\MSVC\14.28.29910\bin\HostX86\x64\link.exe' failed with exit status 1120
I don't know why, I run successfully on ubuntu, but I need to run on windows, can you help me?
Hope for your reply, thanks ^^
Thanks for your great job.Your annotation method is Brilliant.
I noticed your annotation method including two main parts:
May I ask could you please provide detailed tools for annotating the second part: Grasp pose ?Cause we are helpless for this part annotation.
Thanks very much.
ERROR: Could not find a version that satisfies the requirement open3d==0.8 (from -r requirements.txt (line 5)) (from versions: 0.10.0.0, 0.11.0, 0.11.1, 0.11.2, 0.12.0)
ERROR: No matching distribution found for open3d==0.8 (from -r requirements.txt (line 5))
I am in python 3.8
I dont konw why, my another machine with python3.6 is fine
should I change to python 3.6?
Trying to run the demo.py on cuda 11.8, torch 1.10.0 on Ubuntu 22.04
This is the terminal output
python3 demo.py --checkpoint_path checkpoint-kn.tar
WARNING:root:Failed to import ros dependencies in rigid_transforms.py
WARNING:root:autolab_core not installed as catkin package, RigidTransform ros methods will be unavailable
Traceback (most recent call last):
File "/home/nicknair/graspnet-baseline/pointnet2/pointnet2_utils.py", line 26, in <module>
import pointnet2._ext as _ext
ImportError: /home/nicknair/anaconda3/envs/py3-mink/lib/python3.8/site-packages/pointnet2-0.0.0-py3.8-linux-x86_64.egg/pointnet2/_ext.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor6deviceEv
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "demo.py", line 22, in <module>
from graspnet import GraspNet, pred_decode
File "/home/nicknair/graspnet-baseline/models/graspnet.py", line 18, in <module>
from backbone import Pointnet2Backbone
File "/home/nicknair/graspnet-baseline/models/backbone.py", line 14, in <module>
from pointnet2_modules import PointnetSAModuleVotes, PointnetFPModule
File "/home/nicknair/graspnet-baseline/pointnet2/pointnet2_modules.py", line 21, in <module>
import pointnet2_utils
File "/home/nicknair/graspnet-baseline/pointnet2/pointnet2_utils.py", line 29, in <module>
raise ImportError(
ImportError: Could not import _ext module.
Please see the setup instructions in the README: https://github.com/erikwijmans/Pointnet2_PyTorch/blob/master/README.rst
您好,在视频中的小物体的都可以精准的抓取到,请问您是用哪种手眼标定的方法。
Hello @Fang-Haoshu.
Would you mind give me a quick explain about the meaning of each field inside your
meta.mat file.
{'__header__': b'MATLAB 5.0 MAT-file Platform: posix, Created on: Tue Mar 17 14:51:33 2020',
'__version__': '1.0',
'__globals__': [],
'poses': array([[[-0.9756758 , 0.20997444, 0.71809477, -0.10539012,
0.28258908, 0.9570219 , -0.6063459 , 0.6341392 ,
-0.95235777],
[-0.05635871, 0.7769375 , -0.6932231 , -0.9939491 ,
-0.95306253, -0.1432863 , -0.11288764, 0.7661504 ,
-0.22686528],
[ 0.21185002, -0.59353083, -0.06149539, -0.0309534 ,
-0.10869765, -0.25214702, 0.7871474 , 0.10431238,
-0.20383038],
[ 0.1117 , -0.0714 , -0.0837 , -0.1092 ,
0.0027 , -0.2043 , -0.0069 , -0.1581 ,
0.0391 ]],
[[ 0.21893798, 0.14432675, -0.64941216, 0.9167016 ,
0.8435303 , -0.24861187, 0.7650126 , -0.66297054,
-0.28011078],
[-0.2993843 , -0.6250445 , -0.6992277 , -0.08504111,
0.30085424, 0.04236081, -0.3529656 , 0.6081769 ,
0.915004 ],
[ 0.9286739 , -0.76713043, 0.2989055 , -0.39041796,
-0.44490823, -0.96767646, 0.53867525, -0.4365672 ,
0.29035428],
[ 0.0326 , 0.0548 , -0.0858 , 0.135 ,
-0.0408 , 0.0057 , -0.1437 , -0.0485 ,
0.0349 ]],
[[ 0.0110857 , -0.9669956 , -0.25020745, 0.38542327,
0.45672753, 0.14933594, 0.21702617, -0.39791653,
0.1206343 ],
[ 0.95246667, 0.07541542, -0.17470661, -0.06952123,
0.03403645, 0.9887743 , 0.9288012 , 0.20768833,
0.33361623],
[ 0.30444106, -0.24337623, -0.95229924, 0.9201172 ,
0.8889553 , 0.00491755, 0.30037972, 0.8936039 ,
-0.9349586 ],
[ 0.4197 , 0.473 , 0.4442 , 0.5089 ,
0.4402 , 0.471 , 0.3932 , 0.4459 ,
0.4803 ]]], dtype=float32),
'cls_indexes': array([[ 1, 3, 6, 9, 23, 27, 52, 62, 39]]),
'intrinsic_matrix': array([[631.54864502, 0. , 638.43517329],
[ 0. , 631.20751953, 366.49904066],
[ 0. , 0. , 1. ]]),
'factor_depth': array([[1000.]])}Thanks
My environment is :
OS:Ubuntu 22.04.1 LTS
CUDA:11.7 sm_86
Pytorch:1.8.0
Since I couldn't successfully install pytorch_knn_cuda repo, I installed https://github.com/unlimblue/KNN_CUDA this one instead. And simply replaced "knn" function by the "KNN".
As a result, when running demo.py with the pretrained checkpoint, no matter using "rs" or "kn", I get this prediction:

Is this right? Or should I figure out how to install the old pytorch_knn_cuda ?
Thanks.
In line 129 of models/backbone.py
129: end_points['fp2_inds'] = end_points['sa1_inds'][:,0:num_seed] # indices among the entire input point clouds
why just 0:num_seed ? It seems the results are not fp2_inds.
$ bash command_test.sh
WARNING:root:Failed to import geometry msgs in rigid_transformations.py.
WARNING:root:Failed to import ros dependencies in rigid_transforms.py
WARNING:root:autolab_core not installed as catkin package, RigidTransform ros methods will be unavailable
Loading data path and collision labels...: 100%|█████████████████████████████████████████████████████████████████████████████| 90/90 [00:00<00:00, 328.38it/s]
23040
23040
-> loaded checkpoint logs/log_rs/checkpoint-rs.tar (epoch: 18)
Traceback (most recent call last):
File "test.py", line 117, in <module>
inference()
File "test.py", line 71, in inference
for batch_idx, batch_data in enumerate(TEST_DATALOADER):
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 363, in __next__
data = self._next_data()
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 989, in _next_data
return self._process_data(data)
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 1014, in _process_data
data.reraise()
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/_utils.py", line 395, in reraise
raise self.exc_type(msg)
OSError: Caught OSError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 185, in _worker_loop
data = fetcher.fetch(index)
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/mnt/ssd/chenweiwen/baseline-graspnet/dataset/graspnet_dataset.py", line 102, in __getitem__
return self.get_data(index)
File "/mnt/ssd/chenweiwen/baseline-graspnet/dataset/graspnet_dataset.py", line 105, in get_data
color = np.array(Image.open(self.colorpath[index]), dtype=np.float32) / 255.0
File "/home/ubuntu/miniconda/envs/grasp/lib/python3.6/site-packages/PIL/Image.py", line 2904, in open
fp = builtins.open(filename, "rb")
OSError: [Errno 40] Too many levels of symbolic links: '/data/Benchmark/graspnet/scenes/scene_0100/realsense/rgb/0000.png'
作者您好,首先感谢您团队能开源这么棒的工作。我在阅读您论文的过程中,发现抓取分数的计算准则一直在变化:
(1)在CVPR2020 GraspNet-1Billion中,您定义的抓取分数是:s = 1.1-u
(2)在开源的代码中,采取的抓取分数是:s = ln(Umax / u)
(3)在最新的ICCV2021中,采取的抓取分数是:s = lu(Umax / u) / ln(Umax/Umin),分数被归一化到[0, 1]
所以,请问为什么要进行这种变化?(3)与(2)相比,归一化到[0, 1]有助于模型训练吗?期待您的回复,感谢。
Hi, I encountered an error as follows:
import numpy as np
data_root = '/media/wind/Share/DataSet/GraspNet1Billion'
collision_label = np.load(os.path.join(data_root, 'collision_label/scene_0110/collision_labels.npz'))
print(collision_label.files)
print(collision_label['arr_8'].shape)Output:
['arr_0', 'arr_4', 'arr_5', 'arr_2', 'arr_3', 'arr_7', 'arr_1', 'arr_8', 'arr_6']
OSError Traceback (most recent call last)
in ()
3 collision_label = np.load(os.path.join(data_root, 'collision_label/scene_0110/collision_labels.npz'))
4 print(collision_label.files)
----> 5 print(collision_label['arr_8'].shape)
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/site-packages/numpy/lib/npyio.py in getitem(self, key)
253 return format.read_array(bytes,
254 allow_pickle=self.allow_pickle,
--> 255 pickle_kwargs=self.pickle_kwargs)
256 else:
257 return self.zip.read(key)
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/site-packages/numpy/lib/format.py in read_array(fp, allow_pickle, pickle_kwargs)
761 read_count = min(max_read_count, count - i)
762 read_size = int(read_count * dtype.itemsize)
--> 763 data = _read_bytes(fp, read_size, "array data")
764 array[i:i+read_count] = numpy.frombuffer(data, dtype=dtype,
765 count=read_count)
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/site-packages/numpy/lib/format.py in _read_bytes(fp, size, error_template)
890 # done about that. note that regular files can't be non-blocking
891 try:
--> 892 r = fp.read(size - len(data))
893 data += r
894 if len(r) == 0 or len(data) == size:
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/zipfile.py in read(self, n)
897 self._offset = 0
898 while n > 0 and not self._eof:
--> 899 data = self._read1(n)
900 if n < len(data):
901 self._readbuffer = data
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/zipfile.py in _read1(self, n)
967 data += self._read2(n - len(data))
968 else:
--> 969 data = self._read2(n)
970
971 if self._compress_type == ZIP_STORED:
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/zipfile.py in _read2(self, n)
997 n = min(n, self._compress_left)
998
--> 999 data = self._fileobj.read(n)
1000 self._compress_left -= len(data)
1001 if not data:
/home/wind/anaconda3/envs/pytorch160/lib/python3.7/zipfile.py in read(self, n)
740 "Close the writing handle before trying to read.")
741 self._file.seek(self._pos)
--> 742 data = self._file.read(n)
743 self._pos = self._file.tell()
744 return data
OSError: [Errno 5] Input/output error
Thank you for your excellent research achievements.
I have a question about the in-plane rotation.
Where is the starting position of the angle defined?
If there is an explanation in paper, please remind me, thank you!
感谢您出色的研究成果。
有关于in-plane rotation我有一个问题。
请问in-plane rotation的初始位置,也就是0度位置定义在何处?
如果在文章中有说明,麻烦您提示一下,谢谢!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.